[source code analysis] PyTtorch distributed Autograd (6) -- engine (Part 2)
0x00 summary
Above, we introduced how the engine obtains the dependencies of the backward calculation graph. In this paper, we will then look at how the engine propagates backward according to these dependencies. Through the study of this article, you can:
- To understand how RecvRpcBackward sends RPC messages to the corresponding downstream nodes, you can comb the interaction process of backward propagation between worker s again.
- Learn how AccumulateGrad accumulates gradients in context.
Other PyTorch distributed articles are as follows:
Automatic differentiation of deep learning tools (1)
Automatic differentiation of deep learning tools (2)
[Source code analysis] automatic differentiation of deep learning tools (3) -- example interpretation
[Source code analysis] how PyTorch implements forward propagation (1) -- basic class (I)
[Source code analysis] how PyTorch implements forward propagation (2) -- basic classes (Part 2)
[Source code analysis] how PyTorch implements forward propagation (3) -- specific implementation
[Source code analysis] how pytoch implements backward propagation (1) -- call engine
[Source code analysis] how pytoch implements backward propagation (2) -- engine static structure
[Source code analysis] how pytoch implements backward propagation (3) -- engine dynamic logic
[Source code analysis] how PyTorch implements backward propagation (4) -- specific algorithm
[Source code analysis] PyTorch distributed (1) -- history and overview
[Source code analysis] PyTorch distributed (2) -- dataparallel (Part 1)
[Source code analysis] PyTorch distributed (3) -- dataparallel (Part 2)
[Source code analysis] PyTorch distributed (4) -- basic concept of distributed application
[Source code analysis] PyTorch distributed (5) -- overview of distributeddataparallel & how to use
[Source code analysis] PyTorch distributed (6) -- distributeddataparallel -- initialization & store
[Source code analysis] PyTorch distributed (7) -- process group of distributeddataparallel
[Source code analysis] PyTorch distributed (8) -- distributed dataparallel
[Source code analysis] PyTorch distributed (9) -- initialization of distributeddataparallel
[Source code analysis] PyTorch distributed (12) -- distributeddataparallel forward propagation
[Source code analysis] PyTorch distributed (13) -- back propagation of distributed dataparallel
[Source code analysis] PyTorch distributed Autograd (1) -- Design
[Source code analysis] PyTorch distributed autograd (2) -- RPC Foundation
[Source code analysis] PyTorch distributed Autograd (3) -- context sensitive
[Source code analysis] PyTorch distributed Autograd (4) -- how to cut into the engine
[Source code analysis] PyTorch distributed Autograd (5) -- engine (I)
For better explanation, the code in this article will be simplified according to the specific situation.
0x01 review
We first review the FAST mode algorithm. The algorithm is as follows. This paper needs to discuss the following parts.
- Let's start with a worker with a back propagation root (all roots must be local).
- Find all send functions of the current Distributed Autograd Context.
- Starting with the root provided and all the send functions we retrieved, we calculate the dependencies locally.
- After calculating the dependencies, start the local autograd engine using the provided root.
- When the autograd engine executes the recv function, the recv function sends the input gradient to the appropriate worker via RPC. Each recv function knows the target worker id because it is recorded as part of the forward propagation. Through autograd_context_id and autograd_message_id the recv function is sent to the remote host.
- When the remote host receives this request, we use autograd_context_id and autograd_message_id to find the appropriate send function.
- If this is the first time a worker has received an autograd for a given_ context_ ID, which will calculate the dependency locally as described in points 1-3 above.
- The send method received at point 6 is then inserted into the queue for execution on the worker's local autograd engine.
- Finally, instead of accumulating grads on Tensor's. grad, we accumulate grads on each Distributed Autograd Context. Gradients are stored in Dict[Tensor, Tensor]. Dict[Tensor, Tensor] is basically a mapping from tensor to its associated gradients, and you can use get_ The gradients () API retrieves the mapping.
Secondly, let's look at the overall execution code. The overall execution is completed in DistEngine::execute, which is divided into the following steps:
- Use contextId to get the forward context.
- Validate using validateRootsAndRetrieveEdges.
- Construct a GraphRoot and use it to drive backward propagation, which can be regarded as a virtual root.
- Use compute dependencies to calculate dependencies.
- Back propagation calculations are performed using runEngineAndAccumulateGradients.
- Use clearAndWaitForOutstandingRpcsAsync to wait for RPC completion.
void DistEngine::execute(
int64_t contextId,
const variable_list& roots,
bool retainGraph) {
// Retrieve the context for the given context_id. This will throw if the
// context_id is invalid.
auto autogradContext =
DistAutogradContainer::getInstance().retrieveContext(contextId);
// Perform initial pre-processing.
edge_list rootEdges;
variable_list grads;
validateRootsAndRetrieveEdges(roots, rootEdges, grads);
// Construct a GraphRoot and use it to drive backward propagation, which can be regarded as a virtual root
std::shared_ptr<Node> graphRoot =
std::make_shared<GraphRoot>(rootEdges, grads);
edge_list outputEdges;
// Compute dependencies locally, starting from all roots and all 'send'
// functions.
{
std::lock_guard<std::mutex> guard(initializedContextIdsLock_);
// Context should not have been initialized already.
TORCH_INTERNAL_ASSERT(
initializedContextIds_.find(autogradContext->contextId()) ==
initializedContextIds_.end());
// Computational dependency
computeDependencies(
autogradContext, rootEdges, grads, graphRoot, outputEdges, retainGraph);
// Mark the autograd context id as initialized.
initializedContextIds_.insert(autogradContext->contextId());
}
BackwardPassCleanupGuard guard(autogradContext);
// This needs to be blocking and as a result we wait for the future to
// complete.
runEngineAndAccumulateGradients(autogradContext, graphRoot, outputEdges)
->waitAndThrow(); // Back propagation calculation
// Wait for all of the outstanding rpcs to complete.
autogradContext->clearAndWaitForOutstandingRpcsAsync()->waitAndThrow();
}
Thirdly, as we know from the above, dependencies have been processed in computedependences, and all function information to be calculated is located in GraphTask.exec_info_ above. Let's take a look at how to calculate, namely runengineandacumulategradients and clearAndWaitForOutstandingRpcsAsync.
0x02 execute GraphTask
Let's first look at how to use runEngineAndAccumulateGradients for back-propagation calculation and cumulative gradients.
2.1 runEngineAndAccumulateGradients
In the engine, runengineandacumulategradients is called first. It mainly encapsulates a NodeTask and then calls execute_graph_task_until_ready_queue_empty. Where at::launch is used to start the thread.
c10::intrusive_ptr<c10::ivalue::Future> DistEngine::
runEngineAndAccumulateGradients(
const ContextPtr& autogradContext,
const std::shared_ptr<Node>& graphRoot,
const edge_list& outputEdges,
bool incrementOutstandingTasks) {
// Cleanup previous state for outstanding RPCs. Outstanding RPCs could be
// lingering if we're running backward multiple times and some of the
// passes ran into errors.
autogradContext->clearOutstandingRpcs();
// Get GraphTask
auto graphTask = autogradContext->retrieveGraphTask();
// Started a thread to run execute_graph_task_until_ready_queue_empty
at::launch([this, graphTask, graphRoot, incrementOutstandingTasks]() {
execute_graph_task_until_ready_queue_empty(
/*node_task*/ NodeTask(graphTask, graphRoot, InputBuffer(0)),
/*incrementOutstandingTasks*/ incrementOutstandingTasks);
});
// Use a reference here to avoid refcount bump on futureGrads.
// Processing results
auto& futureGrads = graphTask->future_result_;
// Build a future that waits for the callbacks to execute (since callbacks
// execute after the original future is completed). This ensures we return a
// future that waits for all gradient accumulation to finish.
auto accumulateGradFuture =
c10::make_intrusive<c10::ivalue::Future>(c10::NoneType::get());
futureGrads->addCallback(
[autogradContext, outputEdges, accumulateGradFuture](c10::ivalue::Future& futureGrads) {
if (futureGrads.hasError()) {
// Omit the error handling section
return;
}
try {
const variable_list& grads =
futureGrads.constValue().toTensorVector();
// Identification has ended
accumulateGradFuture->markCompleted(c10::IValue());
} catch (std::exception& e) {
accumulateGradFuture->setErrorIfNeeded(std::current_exception());
}
});
return accumulateGradFuture;
}
at::launch is located in aten/src/ATen/ParallelThreadPoolNative.cpp, where online Cheng Zhizhong calls the incoming func.
void launch(std::function<void()> func) {
internal::launch_no_thread_state(std::bind([](
std::function<void()> f, ThreadLocalState thread_locals) {
ThreadLocalStateGuard guard(std::move(thread_locals));
f();
},
std::move(func),
ThreadLocalState()
));
}
namespace internal {
void launch_no_thread_state(std::function<void()> fn) {
#if AT_EXPERIMENTAL_SINGLE_THREAD_POOL
intraop_launch(std::move(fn));
#else
get_pool().run(std::move(fn));
#endif
}
}
Let's take a look at how these internal methods are implemented one by one.
2.2 execute_graph_task_until_ready_queue_empty
This function is similar to Engine::thread_main to complete the execution of this GraphTask through a NodeTask, where evaluate_function will constantly report to the cpu_ready_queue inserts a new NodeTask. engine_. evaluate_ The function method will:
- First, initialize the native engine thread.
- Second, each call establishes a cpu_ready_queue, used to get from root_to_execute starts traversing the graph_task, which allows parallel execution of GraphTask with different threads, which is a CPU related queue.
- Put the incoming node_ Insert task into cpu_ready_queue.
- Start from the root to the leaf node along the reverse calculation diagram.
-
-
The leaf nodes here are AccumulateGrad or RecvRpcBackward.
-
If it is an intermediate node, the calculation is normal.
-
If it is RecvRpcBackward, an RPC message will be sent to the corresponding downstream node.
-
If AccumulateGrad, the gradient is accumulated in the context.
-
The specific codes are as follows:
void DistEngine::execute_graph_task_until_ready_queue_empty(
NodeTask&& node_task,
bool incrementOutstandingTasks) {
// Initialize native engine thread
engine_.initialize_device_threads_pool();
// Create a ready queue per call to traverse the graph_task from
// root_to_execute This allow concurrent execution of the same GraphTask from
// different threads
// A ready queue is created for each call to start from root_to_execute starts traversing the graph_task, which allows parallel execution of GraphTask with different threads, which is a CPU related queue
std::shared_ptr<ReadyQueue> cpu_ready_queue = std::make_shared<ReadyQueue>();
auto graph_task = node_task.base_.lock();
if (graph_task == nullptr) {
LOG(ERROR) << "GraphTask has expired for NodeTask: "
<< node_task.fn_->name() << ", skipping execution.";
return;
}
cpu_ready_queue->push(std::move(node_task), incrementOutstandingTasks);
torch::autograd::set_device(torch::autograd::CPU_DEVICE);
graph_task->owner_ = torch::autograd::CPU_DEVICE;
while (!cpu_ready_queue->empty()) {
std::shared_ptr<GraphTask> local_graph_task;
{
// Scope this block of execution since NodeTask is not needed after this
// block and can be deallocated (release any references to grad tensors
// as part of inputs_)
NodeTask task = cpu_ready_queue->pop(); // Take out a NodeTask
if (!(local_graph_task = task.base_.lock())) {
continue;
}
if (task.fn_ && !local_graph_task->has_error_.load()) {
AutoGradMode grad_mode(local_graph_task->grad_mode_);
try {
GraphTaskGuard guard(local_graph_task);
engine_.evaluate_function( // The function corresponding to the specific Node will be called here
local_graph_task, task.fn_.get(), task.inputs_, cpu_ready_queue);
} catch (std::exception& e) {
engine_.thread_on_exception(local_graph_task, task.fn_, e);
// break the loop in error so that we immediately stop the execution
// of this GraphTask, mark it completed if necessary and return the
// future with proper ErrorMessage
break;
}
}
}
// Decrement the outstanding task.
--local_graph_task->outstanding_tasks_; // A NodeTask was processed
}
// Check if we've completed execution.
if (graph_task->completed()) {
// We don't need to explicitly notify the owner thread, since
// 'mark_as_completed_and_run_post_processing' would mark the Future as
// completed and this would notify the owner thread that the task has been
// completed.
graph_task->mark_as_completed_and_run_post_processing();
}
}
In addition, there are three places to call execute_graph_task_until_ready_queue_empty.
- Runengineandacumulategradients will be called. Here is the case where the user actively calls backward, which is described in this section.
- executeSendFunctionAsync will be called, which corresponds to the operation after a node receives the gradient from the previous node of back propagation, which will be described in the next section.
- globalCpuThread will be called. This is a special thread for CPU work, which will be introduced shortly.
- In engine.evaluate_ In function, the gradient will be accumulated for AccumulateGrad.
- In engine.evaluate_ In function, RecvRpcBackward will be called to send messages to the downstream of back propagation.
Let's summarize several processes for calculating the gradient, which correspond to the following three numbers.
User Training Script RPC BACKWARD_AUTOGRAD_REQ
+ +
| |
| 1 | 2
v v
backward RequestCallbackNoPython.processRpc
+ +
| |
| |
v v
DistEngine.execute RequestCallbackNoPython.processBackwardAutogradReq
+ +
| |
| |
| v
| +----------+ DistEngine.executeSendFunctionAsync
| | +
| | |
v v |
DistEngine.computeDependencies |
| |
| |
v |
DistEngine.runEngineAndAccumulateGradients | DistEngine.globalCpuThread
+ | +
| +------------------+ |
| | | 3
| | +------------------------+
| | |
| | |
v v v
DistEngine.execute_graph_task_until_ready_queue_empty
+
|
|
v
DistEngine.evaluate_function
+
|
+--------------------------------------------------------------+
| |
| 4 AccumulateGrad | 5 RecvRpcBackward
v v
(*hook)(captured_grad) call_function(graph_task, func, inputs)
2.3 evaluate_function
In the above code, the evaluate of the native engine will actually be called_ Function to complete the operation.
Let's see how to use exec_info_, If it is not set to be executed, it is not processed. Here, we can see how recvBackwardEdges mentioned above works with exec_info_ Interaction.
Traverse the recvBackwardEdges. For each recvBackward, click GraphTask.exec_info_ It is set above the corresponding item in the to be executed.
The specific codes are as follows:
- Accumulate gradients for AccumulateGrad.
- Call RecvRpcBackward to send a message downstream of back propagation.
void Engine::evaluate_function(
std::shared_ptr<GraphTask>& graph_task,
Node* func,
InputBuffer& inputs,
const std::shared_ptr<ReadyQueue>& cpu_ready_queue) {
// If exec_info_ is not empty, we have to instrument the execution
auto& exec_info_ = graph_task->exec_info_;
if (!exec_info_.empty()) {
auto& fn_info = exec_info_.at(func);
if (auto* capture_vec = fn_info.captures_.get()) {
// Lock mutex for writing to graph_task->captured_vars_.
std::lock_guard<std::mutex> lock(graph_task->mutex_);
for (const auto& capture : *capture_vec) {
auto& captured_grad = graph_task->captured_vars_[capture.output_idx_];
captured_grad = inputs[capture.input_idx_];
for (auto& hook : capture.hooks_) {
captured_grad = (*hook)(captured_grad); //The hook called here is the operator() captured of DistAccumulateGradCaptureHook_ Grad is the cumulative gradient
}
}
}
if (!fn_info.needed_) {
// Skip execution if we don't need to execute the function.
return; // If no settings need to be executed, return directly. recvBackward will be set to be executed
}
}
// Here is the call to recvBackward
auto outputs = call_function(graph_task, func, inputs);
// Subsequent code omission
2.4 globalCpuThread
See the [GPU to CPU continuations] section above for globalCpuThread. globalCpuThread is a worker thread that pops up nodetasks from the ready queue and executes them.
For globalCpuThread, its parameter is ready_queue is global_cpu_ready_queue_
void DistEngine::globalCpuThread(
const std::shared_ptr<ReadyQueue>& ready_queue) {
while (true) {
NodeTask task = ready_queue->pop();
if (task.isShutdownTask_) {
// Need to shutdown this thread.
break;
}
auto graphTask = task.base_.lock();
if (graphTask == nullptr) {
// GraphTask has expired, ignore and continue processing.
continue;
}
// Launch the execution on a JIT thread.
at::launch([this,
graphTask,
graphRoot = task.fn_,
variables =
InputBuffer::variables(std::move(task.inputs_))]() mutable {
InputBuffer inputs(variables.size());
for (size_t i = 0; i < variables.size(); i++) {
inputs.add(i, std::move(variables[i]), c10::nullopt, c10::nullopt);
}
execute_graph_task_until_ready_queue_empty( // This will call
/*node_task*/ NodeTask(graphTask, graphRoot, std::move(inputs)),
/*incrementOutstandingTasks*/ false);
});
}
}
For ordinary engines, a cpu specific queue will also be set.
auto graph_task = std::make_shared<GraphTask>(
/* keep_graph */ keep_graph,
/* create_graph */ create_graph,
/* depth */ not_reentrant_backward_call ? 0 : total_depth + 1,
/* cpu_ready_queue */ local_ready_queue);
2.5 summary
The main differences between distributed engine and ordinary engine in the calculation part are as follows:
-
If it is RecvRpcBackward, an RPC message will be sent to the corresponding downstream node.
-
If AccumulateGrad, the gradient is accumulated in the context.
So let's take a look at how to deal with these two parts.
0x03 RPC call
In the previous article, we saw how the receiver handles back propagation RPC calls. Next, we'll look at how the engine initiates back propagation RPC calls, that is, how to call the recv method.
This applies to the case where worker 0 calls recv and the execution comes to worker 1. The corresponding design documents are as follows.
When the autograd engine executes the recv function, the recv function sends the input gradient to the appropriate worker via RPC. Each recv function knows the target worker id because it is recorded as part of the forward propagation. Through autograd_context_id and autograd_message_id the recv function is sent to the remote host.
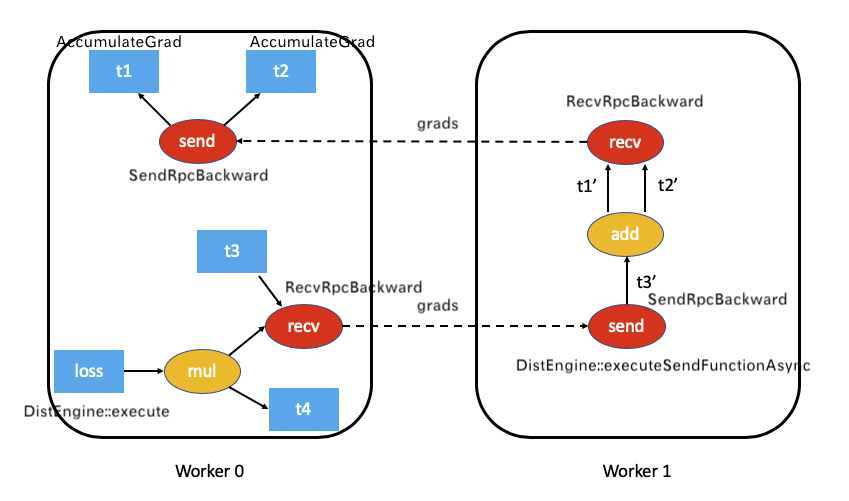
Let's see how to execute the recv function.
Specifically, when combined with the distributed engine, when the engine finds that a Node is RecvRpcBackward, it calls its apply function.
void Engine::evaluate_function(
std::shared_ptr<GraphTask>& graph_task,
Node* func,
InputBuffer& inputs,
const std::shared_ptr<ReadyQueue>& cpu_ready_queue) {
// If exec_info_ is not empty, we have to instrument the execution
auto& exec_info_ = graph_task->exec_info_;
if (!exec_info_.empty()) {
// The gradient accumulation code is omitted. For details, see the above chapter
if (!fn_info.needed_) {
// Skip execution if we don't need to execute the function.
return; // If no settings need to be executed, return directly. recvBackward will be set to be executed
}
}
// Here is to call the recvBackward.apply function
auto outputs = call_function(graph_task, func, inputs);
// Subsequent code omission
3.1 RecvRpcBackward
3.1.1 definitions
RecvRpcBackward is defined as follows:,
class TORCH_API RecvRpcBackward : public torch::autograd::Node {
public:
explicit RecvRpcBackward(
const AutogradMetadata& autogradMetadata,
std::shared_ptr<DistAutogradContext> autogradContext,
rpc::worker_id_t fromWorkerId,
std::unordered_map<c10::Device, c10::Device> deviceMap);
torch::autograd::variable_list apply(
torch::autograd::variable_list&& grads) override;
private:
const AutogradMetadata autogradMetadata_;
// Hold a weak reference to the autograd context to avoid circular
// dependencies with the context (since it holds a reference to
// RecvRpcBackward).
std::weak_ptr<DistAutogradContext> autogradContext_;
// The worker id from which the RPC was received. During the backward pass,
// we need to propagate the gradients to this workerId.
rpc::worker_id_t fromWorkerId_;
// Device mapping for tensors sent over RPC.
const std::unordered_map<c10::Device, c10::Device> deviceMap_;
};
3.1.2 construction
The constructor is as follows.
RecvRpcBackward::RecvRpcBackward(
const AutogradMetadata& autogradMetadata,
ContextPtr autogradContext,
rpc::worker_id_t fromWorkerId,
std::unordered_map<c10::Device, c10::Device> deviceMap)
: autogradMetadata_(autogradMetadata),
autogradContext_(std::move(autogradContext)),
fromWorkerId_(fromWorkerId),
deviceMap_(std::move(deviceMap)) {}
3.1.3 apply
torch/csrc/distributed/autograd/functions/recvrpc_backward.cpp defines its apply function, which is used to:
- Put the incoming gradient grads into outputGrads because it needs to be output to the next link.
- Build PropagateGradientsReq, which is BACKWARD_AUTOGRAD_REQ.
- Send RPC to the next link.
variable_list RecvRpcBackward::apply(variable_list&& grads) {
std::vector<Variable> outputGrads;
for (size_t i = 0; i < grads.size(); i++) { // The following is to put the incoming gradient grads into outputGrads
const auto& grad = grads[i];
if (grad.defined()) {
outputGrads.emplace_back(grad);
} else {
// Put in zeros for a tensor with no grad.
outputGrads.emplace_back(input_metadata(i).zeros_like());
}
}
auto sharedContext = autogradContext_.lock();
// Send the gradients over the wire and record the future in the autograd
// context.
PropagateGradientsReq gradCall( // Build PropagateGradientsReq
autogradMetadata_,
outputGrads,
sharedContext->retrieveGraphTask()->keep_graph_);
// Send the gradients over to the appropriate node.
auto rpcAgent = rpc::RpcAgent::getCurrentRpcAgent();
auto jitFuture = rpcAgent->send( // Send RPC
rpcAgent->getWorkerInfo(fromWorkerId_),
std::move(gradCall).toMessage(), // toMessageImpl called
rpc::kUnsetRpcTimeout,
deviceMap_);
// Record the future in the context.
sharedContext->addOutstandingRpc(jitFuture);
// 'recv' function sends the gradients over the wire using RPC, it doesn't
// need to return anything for any downstream autograd function.
return variable_list();
}
Because PropagateGradientsReq is sent here, let's continue.
3.2 PropagateGradientsReq
3.2.1 definitions
PropagateGradientsReq extends RpcCommandBase.
// Used to propagate gradients from one node to another during a distributed
// backwards pass. This RPC call is invoked when we hit a `recv` autograd
// function during backward pass execution.
class TORCH_API PropagateGradientsReq : public rpc::RpcCommandBase {
public:
PropagateGradientsReq(
const AutogradMetadata& autogradMetadata,
std::vector<torch::autograd::Variable> grads,
bool retainGraph = false);
const AutogradMetadata& getAutogradMetadata();
const std::vector<torch::autograd::Variable>& getGrads();
// Serialization and deserialization methods.
rpc::Message toMessageImpl() && override;
static std::unique_ptr<PropagateGradientsReq> fromMessage(
const rpc::Message& message);
// Whether or not to retain the autograd graph.
bool retainGraph();
private:
AutogradMetadata autogradMetadata_;
std::vector<torch::autograd::Variable> grads_;
bool retainGraph_;
};
Its toMessageImpl indicates that this message is BACKWARD_AUTOGRAD_REQ.
Message PropagateGradientsReq::toMessageImpl() && {
std::vector<at::IValue> ivalues;
// Add all the grad tensors.
for (const auto& grad : grads_) {
ivalues.emplace_back(grad);
}
// Now add autograd metadata.
ivalues.emplace_back(autogradMetadata_.autogradContextId);
ivalues.emplace_back(autogradMetadata_.autogradMessageId);
// Add retain graph.
ivalues.emplace_back(retainGraph_);
// Now pickle using JIT pickler.
std::vector<torch::Tensor> tensorTable;
std::vector<char> payload =
jit::pickle(c10::ivalue::Tuple::create(std::move(ivalues)), &tensorTable);
return Message(
std::move(payload),
std::move(tensorTable),
MessageType::BACKWARD_AUTOGRAD_REQ); // The message type is indicated here.
}
3.3 recipient
For completeness, let's look at how the receiver handles back propagation.
3.3.1 accept message
When generating TensorPipeAgent, configure RequestCallbackImpl as a callback function. This is the unified response function of agent. When we mentioned the agent receiving logic earlier, we will enter the requestcallback nopthon:: processrpc function. You can see a pair of backward_ AUTOGRAD_ Processing logic of req.
This is the normal process of RPC.
void RequestCallbackNoPython::processRpc(
RpcCommandBase& rpc,
const MessageType& messageType,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture,
std::shared_ptr<LazyStreamContext> ctx) const {
switch (messageType) {
case MessageType::BACKWARD_AUTOGRAD_REQ: {
processBackwardAutogradReq(rpc, messageId, responseFuture); // Call here
return;
};
3.3.2 processBackwardAutogradReq
In processBackwardAutogradReq:
- Get DistAutogradContainer.
- Gets the context.
- Call executeSendFunctionAsync for engine processing.
From this, we can see that there are two ways to enter the engine:
- One is that the sample code explicitly calls backward, and then calls DistEngine::getInstance().execute, which is worker 0.
- One is to passively call DistEngine::getInstance().executeSendFunctionAsync, which is worker 1.
void RequestCallbackNoPython::processBackwardAutogradReq(
RpcCommandBase& rpc,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture) const {
auto& gradientsCall = static_cast<PropagateGradientsReq&>(rpc);
const auto& autogradMetadata = gradientsCall.getAutogradMetadata();
// Retrieve the appropriate autograd context.
auto autogradContext = DistAutogradContainer::getInstance().retrieveContext(
autogradMetadata.autogradContextId); // Get the context id of the sender
// Lookup the appropriate 'send' function to enqueue.
std::shared_ptr<SendRpcBackward> sendFunction = // sendFunction is obtained according to the sender context id and message id
autogradContext->retrieveSendFunction(autogradMetadata.autogradMessageId);
// Attach the gradients to the send function.
sendFunction->setGrads(gradientsCall.getGrads()); // Set gradient
// Now execute the autograd graph using the "distributed engine."
auto execFuture = DistEngine::getInstance().executeSendFunctionAsync( // Call engine
autogradContext, sendFunction, gradientsCall.retainGraph());
// Our response is satisfied when the rpcs come back.
execFuture->addCallback([responseFuture, messageId](JitFuture& execFuture) {
if (!execFuture.hasError()) {
Message m = std::move(PropagateGradientsResp()).toMessage();
m.setId(messageId);
responseFuture->markCompleted(
IValue(c10::make_intrusive<Message>(std::move(m))));
} else {
responseFuture->setError(execFuture.exception_ptr());
}
});
}
3.3.3 executeSendFunctionAsync
executeSendFunctionAsync starts to enter the engine here. Note that the receiver also enters the engine and performs calculations on the receiver. executeSendFunctionAsync calls execute directly_ graph_ task_ until_ ready_ queue_ Empty, or calculate the dependency first and then continue the execution. Here you can refer to the following in the design:
- 6) When the remote host receives this request, we use autograd_context_id and autograd_message_id to find the appropriate send function.
- 7) If this is the first time a worker has received an autograd for a given_ context_ ID, which will calculate the dependency locally as described in points 1-3 above.
- 8) The send method received at point 6 is then inserted into the queue for execution on the worker's local autograd engine.
The specific codes are as follows:
c10::intrusive_ptr<c10::ivalue::Future> DistEngine::executeSendFunctionAsync(
const ContextPtr& autogradContext,
const std::shared_ptr<SendRpcBackward>& sendFunction,
bool retainGraph) {
// Typically the local autograd engine ensures stream synchronizations between
// nodes in the graph. However, for distributed autograd the sendFunction
// inputs might have been retrieved over the wire on a separate stream and the
// sendFunction itself runs on a different stream. As a result, we need to
// manually synchronize those two streams here.
const auto& send_backward_stream = sendFunction->stream(c10::DeviceType::CUDA);
if (send_backward_stream) { // Get the Stream corresponding to this execution
for (const auto& grad : sendFunction->getGrads()) {
const auto guard = c10::impl::VirtualGuardImpl{c10::DeviceType::CUDA};
const auto default_stream = guard.getStream(grad.device());
if (send_backward_stream != default_stream) {
auto event = c10::Event{c10::DeviceType::CUDA};
event.record(default_stream);
send_backward_stream->wait(event); // Synchronization is required to ensure that the current operation is completed
}
}
}
std::unique_lock<std::mutex> lock(initializedContextIdsLock_);
if (initializedContextIds_.find(autogradContext->contextId()) ==
initializedContextIds_.end()) { // Traverse to find out whether the context corresponding to sendFunction has been recorded in this node
// Context not found, dependency needs to be calculated
edge_list outputEdges;
// Pass in a dummy graphRoot since all send functions are the roots.
auto dummyRoot = std::make_shared<GraphRoot>(edge_list(), variable_list());
computeDependencies( // Computational dependency
autogradContext, {}, {}, dummyRoot, outputEdges, retainGraph);
// Mark the autograd context id as initialized and unlock.
initializedContextIds_.insert(autogradContext->contextId());
lock.unlock();
// Enqueue the current send function.
auto graphTask = autogradContext->retrieveGraphTask();
// Run the autograd engine.
auto accumulateGradFuture = runEngineAndAccumulateGradients( // Calculated gradient
autogradContext,
sendFunction,
outputEdges,
/*incrementOutstandingTasks=*/false);
// Build the 'uber' future that waits for everything.
auto callbackFuture =
c10::make_intrusive<c10::ivalue::Future>(c10::NoneType::get());
// Registering Callbacks
accumulateGradFuture->addCallback([autogradContext,
callbackFuture](c10::ivalue::Future& accumulateGradFuture) {
try {
if (accumulateGradFuture.hasError()) {
// Perform cleanup at the end of the backward pass (before we mark
// the future as completed).
DistEngine::getInstance().cleanupBackwardPass(autogradContext);
// Skip any further processing on errors.
callbackFuture->setError(accumulateGradFuture.exception_ptr());
return;
}
// Wait for all RPCs after the autograd engine is done.
auto rpcFuture = autogradContext->clearAndWaitForOutstandingRpcsAsync();
rpcFuture->addCallback([callbackFuture, autogradContext](c10::ivalue::Future& rpcFuture) {
try {
// Perform cleanup at the end of the backward pass (before
// we mark the future as completed).
DistEngine::getInstance().cleanupBackwardPass(autogradContext);
} catch (std::exception& e) {
callbackFuture->setErrorIfNeeded(std::current_exception());
return;
}
// Finally mark the 'uber' future as completed.
if (!rpcFuture.hasError()) {
callbackFuture->markCompleted(c10::IValue());
} else {
callbackFuture->setError(rpcFuture.exception_ptr());
}
});
} catch (std::exception& e) {
callbackFuture->setErrorIfNeeded(std::current_exception());
}
});
// Return the future which waits for all async processing to be done.
return callbackFuture;
} else { // The context can be found in the current Node
lock.unlock();
auto graphTask = autogradContext->retrieveGraphTask();
at::launch([this, graphTask, sendFunction]() {
execute_graph_task_until_ready_queue_empty(
/*node_task*/ NodeTask(graphTask, sendFunction, InputBuffer(0)),
/*incrementOutstandingTasks*/ false);
});
auto fut = c10::make_intrusive<c10::ivalue::Future>(c10::NoneType::get());
fut->markCompleted(c10::IValue());
return fut;
}
}
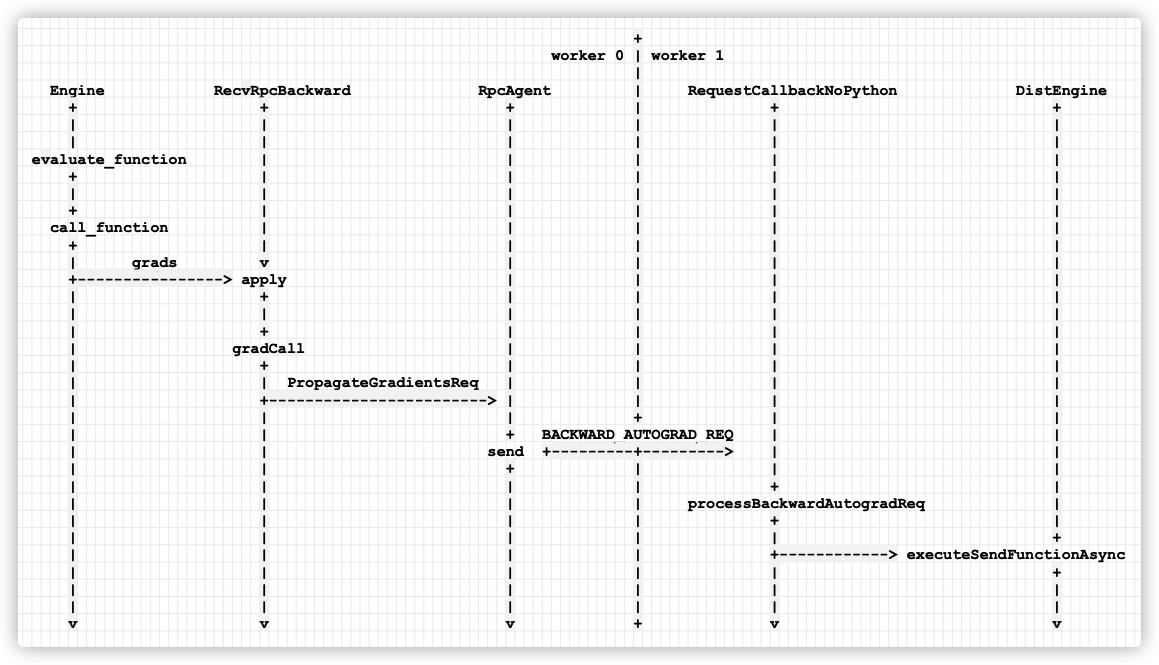
See the following figure for details:
+
worker 0 | worker 1
|
Engine RecvRpcBackward RpcAgent | RequestCallbackNoPython DistEngine
+ + + | + +
| | | | | |
| | | | | |
evaluate_function | | | | |
+ | | | | |
| | | | | |
+ | | | | |
call_function | | | | |
+ | | | | |
| grads v | | | |
+----------------> apply | | | |
| + | | | |
| | | | | |
| + | | | |
| gradCall | | | |
| + | | | |
| | PropagateGradientsReq | | | |
| +------------------------> | | | |
| | | + | |
| | + BACKWARD_AUTOGRAD_REQ | |
| | send +---------+---------> | |
| | + | | |
| | | | + |
| | | | processBackwardAutogradReq |
| | | | + |
| | | | | +
| | | | +------------> executeSendFunctionAsync
| | | | | +
| | | | | |
| | | | | |
v v v + v v
Mobile phones are as follows:
0x04 DistAccumulateGradCaptureHook
At present, it seems that the overall logic has been completed, but there is actually a missing piece, which corresponds to the following in the design document:
Finally, instead of accumulating grads on Tensor's. grad, we accumulate grads on each Distributed Autograd Context. Gradients are stored in Dict[Tensor, Tensor]. Dict[Tensor, Tensor] is basically a mapping from tensor to its associated gradients, and you can use get_ The gradients () API retrieves the mapping.
It is to accumulate remote / local gradients into the local context, so let's analyze DistAccumulateGradCaptureHook again.
4.1 definitions
DistAccumulateGradCaptureHook has three functions:
-
Call the pre hooks of the original AccumulateGrad to modify the input gradient.
-
Accumulate grad to RPC context.
-
Call the post hooks of the original AccumulateGrad.
It is defined as follows:
// This hook does 3 things:
// 1. Call pre hooks of the original AccumulateGrad to modify the input grad.
// 2. Accumuate the gard to RPC context.
// 3. Call post hooks of the original AccumulateGrad.
class DistAccumulateGradCaptureHook
: public GraphTask::ExecInfo::Capture::GradCaptureHook {
public:
DistAccumulateGradCaptureHook(
std::shared_ptr<AccumulateGrad> accumulateGrad,
ContextPtr autogradContext)
: accumulateGrad_(std::move(accumulateGrad)),
autogradContext_(std::move(autogradContext)) {}
at::Tensor operator()(const at::Tensor& grad) override {
ThreadLocalDistAutogradContext contextGuard{ContextPtr(autogradContext_)};
variable_list inputGrads = {grad};
// It's intended that pre/post hooks are still called even if the grad is
// undenfined here.
for (const auto& hook : accumulateGrad_->pre_hooks()) {
inputGrads = (*hook)(inputGrads); // Call pre hooks
}
// It is possible that the grad is not defined since a separate
// invocation of the autograd engine on the same node might actually
// compute this gradient.
if (inputGrads[0].defined()) {
// There are 3 internal references to 'inputGrads[0]' at this moment:
// 1. 'inputGrads[0]' in this function.
// 2. 'graph_task->captured_vars_' on the callsite in the local engine.
// 3. 'InputBuffer& inputs' on the callsite as the inputs of the
// function node.
autogradContext_->accumulateGrad( // Cumulative gradient
accumulateGrad_->variable, inputGrads[0], 3 /* num_expected_refs */);
}
const variable_list kEmptyOuput;
for (const auto& hook : accumulateGrad_->post_hooks()) {
(*hook)(kEmptyOuput, inputGrads); // Call Post hooks
}
return inputGrads[0];
}
private:
std::shared_ptr<AccumulateGrad> accumulateGrad_; // This is the target vector that needs to be accumulated, and subsequent operations are based on it
ContextPtr autogradContext_;
};
4.2 generation
How to generate DistAccumulateGradCaptureHook? DistAccumulateGradCaptureHook is generated when calculating dependency, but it is recorded in capture. Hooks_ push_ Back.
This is to handle AccumulateGrad.
-
AccumulateGrad must be a leaf node, which does not need to be executed, but needs to accumulate gradients on it, but RecvRpcBackward needs to be executed.
-
AccumulateGrad is saved in DistAccumulateGradCaptureHook.
void DistEngine::computeDependencies(
const ContextPtr& autogradContext,
const edge_list& rootEdges,
const variable_list& grads,
const std::shared_ptr<Node>& graphRoot,
edge_list& outputEdges,
bool retainGraph) {
if (!outputEdges.empty()) {
// Compute 'needed execution' starting from all 'send' functions and the
// original graphRoot.
edge_list edges;
// Create some dummy edges (input_nr not important for init_to_execute).
for (const auto& mapEntry : sendFunctions) {
edges.emplace_back(mapEntry.second, 0);
}
// Add the original graphRoot as an edge.
edges.emplace_back(graphRoot, 0);
// Create a dummy GraphRoot and run init_to_execute with it.
GraphRoot dummyRoot(edges, {});
graphTask->init_to_execute(dummyRoot, outputEdges, /*accumulate_grad=*/false, /*min_topo_nr=*/0);
for (auto& mapEntry : graphTask->exec_info_) {
auto& execInfo = mapEntry.second;
if (!execInfo.captures_) {
continue;
}
auto fn = mapEntry.first;
// There may be nodes other than 'AccumulateGrad', e.g. RecvRPCBackward,
// to be captured.
if (auto accumulateGradFn = dynamic_cast<AccumulateGrad*>(fn)) {
for (auto& capture : *execInfo.captures_) {
capture.hooks_.push_back( // This will generate
std::make_unique<DistAccumulateGradCaptureHook>(
std::dynamic_pointer_cast<AccumulateGrad>( // AccumulateGrad is saved
accumulateGradFn->shared_from_this()),
autogradContext));
}
}
}
// Mark all 'RecvRPCBackward' as needing execution.
for (const auto& recvBackwardEdge : recvBackwardEdges) {
graphTask->exec_info_[recvBackwardEdge.function.get()].needed_ = true;
}
}
}
4.3 use
The code is a reduced version.
First, execute_graph_task_until_ready_queue_empty will call the original engine engine evaluate_ function.
void DistEngine::execute_graph_task_until_ready_queue_empty(
NodeTask&& node_task,
bool incrementOutstandingTasks) {
while (!cpu_ready_queue->empty()) {
std::shared_ptr<GraphTask> local_graph_task;
{
NodeTask task = cpu_ready_queue->pop();
if (task.fn_ && !local_graph_task->has_error_.load()) {
AutoGradMode grad_mode(local_graph_task->grad_mode_);
GraphTaskGuard guard(local_graph_task);
engine_.evaluate_function( // Call the original engine
local_graph_task, task.fn_.get(), task.inputs_, cpu_ready_queue);
}
}
// Decrement the outstanding task.
--local_graph_task->outstanding_tasks_;
}
}
Secondly, hooks is called in the original engine code.
void Engine::evaluate_function(
std::shared_ptr<GraphTask>& graph_task,
Node* func,
InputBuffer& inputs,
const std::shared_ptr<ReadyQueue>& cpu_ready_queue) {
// If exec_info_ is not empty, we have to instrument the execution
auto& exec_info_ = graph_task->exec_info_;
if (!exec_info_.empty()) {
auto& fn_info = exec_info_.at(func);
if (auto* capture_vec = fn_info.captures_.get()) {
// Lock mutex for writing to graph_task->captured_vars_.
std::lock_guard<std::mutex> lock(graph_task->mutex_);
for (const auto& capture : *capture_vec) {
auto& captured_grad = graph_task->captured_vars_[capture.output_idx_];
captured_grad = inputs[capture.input_idx_];
for (auto& hook : capture.hooks_) {
captured_grad = (*hook)(captured_grad); // The hook called here is the operator() captured of DistAccumulateGradCaptureHook_ Grad is the cumulative gradient
}
}
}
}
// Subsequent omission
In the operator() method of DistAccumulateGradCaptureHook, the following will be called to accumulate the gradient.
autogradContext_->accumulateGrad(
accumulateGrad_->variable, inputGrads[0], 3 /* num_expected_refs */);
4.4 cumulative gradient
4.4.1 context accumulation
void DistAutogradContext::accumulateGrad(
const torch::autograd::Variable& variable, // Variable is the target variable
const torch::Tensor& grad, // grad is the gradient, which needs to be accumulated on the variable
size_t num_expected_refs) {
std::lock_guard<std::mutex> guard(lock_);
auto it = accumulatedGrads_.find(variable);
at::Tensor old_grad;
if (it != accumulatedGrads_.end()) {
// Accumulate multiple grads on the same variable.
old_grad = it->value();
}
// Gradients are computed using the forward streams. Local autograd
// engine uses AccumulateGrad function to retrieve and apply forward
// stream during the backward computation. In distributed autograd,
// we directly call AccumulateGrad::accumulateGrad, and skip the
// CUDA stream restoration from autograd function. Hence, we manually
// call it here to get the streams correct.
auto forward_stream =
torch::autograd::impl::grad_accumulator(variable)->stream(
grad.device().type());
c10::OptionalStreamGuard stream_guard(forward_stream);
// No higher order gradients supported in distributed autograd.
AutoGradMode grad_mode(false);
at::Tensor new_grad = AccumulateGrad::callHooks(variable, grad); // calculation
AccumulateGrad::accumulateGrad( // Call operator functions to accumulate gradients
variable,
old_grad,
new_grad,
// Add +1 here since we can't std::move(grad) when call
// AccumulateGrad::callHooks, since it is a const ref, and that incurs a
// refcount bump for the new_grad.
num_expected_refs + 1,
[this, &variable](at::Tensor&& grad_update) {
auto device = grad_update.device();
accumulatedGrads_.insert(variable, std::move(grad_update));
recordGradEvent(device);
});
}
4.4.2 operator accumulation
The code is located in torch / CSR / autograd / functions / accumulate_ grad.h. AccumulateGrad is defined as follows:
struct TORCH_API AccumulateGrad : public Node {
explicit AccumulateGrad(Variable variable_);
variable_list apply(variable_list&& grads) override;
static at::Tensor callHooks(
const Variable& variable,
at::Tensor new_grad) {
for (auto& hook : impl::hooks(variable)) {
new_grad = (*hook)({new_grad})[0];
}
return new_grad;
}
// Given a variable with its current grad as variable_grad, accumulates
// new_grad into variable_grad if in place accumulation is possible.
// Otherwise, uses 'update_grad' to update the grad for the variable.
// "Gradient Layout Contract"
//
// AccumulateGrad tries to stash strided (non-sparse) grads with memory layout
// (strides) such that variables and grads interact efficiently in later
// optimizer kernels, and grads interact efficiently with c10d::Reducer.cpp.
//
// Specifically, AccumulateGrad tries to ensure the following
// (cf torch/csrc/autograd/utils/grad_layout_contract.h):
// (1) if variable.is_non_overlapping_and_dense(), the stashed grad's
// strides match variable.
// (2) else, stashed grad is rowmajor contiguous.
// If variable's grad does not exist (!variable_grad.defined())
// AccumulateGrad steals new_grad if it's stealable and obeys the contract
// already, otherwise it deep copies new_grad into an obedient clone.
//
// If variable's grad already exists (variable_grad.defined()), new_grad must
// be added to variable_grad. If we aren't setting up for double backward
// (!GradMode::is_enabled()), AccumulateGrad performs "variable_grad += new_grad"
// in-place, which keeps variable_grad's layout. We assume (hope) variable_grad
// was created obeying (1) or (2) at some point in the past.
//
// If we are setting up for double backward, AccumulateGrad updates the grad
// out-of-place via "variable_grad + new_grad." TensorIterator operator+ decides
// result's layout. Typically TensorIterator matches strides of the first arg,
// so we once again assume (hope) variable_grad was originally created obeying
// (1) or (2).
//
// AccumulateGrad does not enforce the contract with 100% certainty. Examples:
// - If a user manually permutes a param or its grad, then runs a fwd+bwd,
// variable_grad += new_grad keeps variable_grad's layout without rechecking
// the contract.
// - If TensorIterator changes its corner cases about operator+'s result
// (for example, giving more or less priority to channels_last inputs, see
// https://github.com/pytorch/pytorch/pull/37968) the result may not obey.
//
// Fortunately, if a given grad doesn't satisfy (1) or (2), the penalty is
// degraded performance in Reducer.cpp or optimizer kernels, not death by
// assert or silently bad numerics.
// variable: the variable whose grad we're accumulating.
// variable_grad: the current grad for the variable.
// new_grad: new grad we want to acummulate for the variable.
// num_expected_refs: the number of refs we expect to hold internally
// such that it is safe to avoid cloning the grad
// if use_count() of the grad is less than or equal
// to this value (in addition to post_hooks).
// update_grad: Function that is used to update grad for the variable.
// The argument to the function is a Tensor which
// is used to set a new value for the grad.
template <typename T>
static void accumulateGrad( // Specific cumulative gradients will be performed here
const Variable& variable,
at::Tensor& variable_grad,
const at::Tensor& new_grad,
size_t num_expected_refs,
const T& update_grad) {
if (!variable_grad.defined()) {
if (!GradMode::is_enabled() &&
!new_grad.is_sparse() &&
new_grad.use_count() <= num_expected_refs &&
(new_grad.is_mkldnn() || utils::obeys_layout_contract(new_grad, variable))) {
// we aren't setting up for double-backward
// not sparse
// no other user-visible tensor references new_grad
// new_grad obeys the "Gradient Layout Contract", there has a special case,
// For MKLDNN tensor, which is a opaque tensor, assuming it obeys layout_contract.
// Under these conditions, we can steal new_grad without a deep copy.
update_grad(new_grad.detach());
} else if (
!GradMode::is_enabled() && new_grad.is_sparse() &&
new_grad._indices().is_contiguous() &&
new_grad._values().is_contiguous() &&
// Use count for indices and values should always be <=1 since the
// SparseTensor should be the only one holding a reference to these.
new_grad._indices().use_count() <= 1 &&
new_grad._values().use_count() <= 1 &&
new_grad.use_count() <= num_expected_refs) {
// Can't detach sparse tensor (since metadata changes are not allowed
// after detach), so just create a new one for the grad which is a
// shallow copy. We need a shallow copy so that modifying the original
// grad tensor doesn't modify the grad we accumulate.
// We only skip clone if indices and values themselves are contiguous
// for backward compatiblity reasons. Since without this optimization,
// earlier we would clone the entire SparseTensor which cloned indices
// and values.
// For details see https://github.com/pytorch/pytorch/issues/34375.
update_grad(at::_sparse_coo_tensor_unsafe(
new_grad._indices(),
new_grad._values(),
new_grad.sizes(),
new_grad.options()));
} else {
if (new_grad.is_sparse()) {
update_grad(new_grad.clone());
} else {
if (new_grad.is_mkldnn()) {
update_grad(new_grad.clone());
} else {
// Deep copies new_grad according to the "Gradient Layout Contract."
update_grad(utils::clone_obey_contract(new_grad, variable));
}
}
}
} else if (!GradMode::is_enabled()) {
// This case is not strictly necessary, but it makes the first-order only
// case slightly more efficient.
if (variable_grad.is_sparse() && !new_grad.is_sparse()) {
// If `variable_grad` is sparse and `new_grad` is not sparse, their
// sum is not sparse, and we must change the TensorImpl type of
// `variable_grad` for it to store the result. However, changing the
// TensorImpl type of a tensor requires changing the tensor itself, and
// thus in this case we have to change the grad tensor.
auto result = new_grad + variable_grad;
CHECK_RESULT(result, variable);
update_grad(std::move(result));
} else if (!at::inplaceIsVmapCompatible(variable_grad, new_grad)) {
// Ideally we'd perform an in-place operation to avoid changing
// the grad tensor. However, if that's impossible because the grads
// are vmap-incompatible (See NOTE: [vmap-incompatible in-place operations]),
// then we just add them out-of-place.
auto result = variable_grad + new_grad;
CHECK_RESULT(result, variable);
update_grad(std::move(result));
} else {
// In this case we can avoid changing the grad tensor. There are three
// scenarios when we'll hit this case:
//
// 1. `variable_grad` is sparse, and `new_grad` is sparse.
// 2. `variable_grad` is dense, and `new_grad` is sparse.
// 3. `variable_grad` is dense, and `new_grad` is dense.
// 4. `variable_grad` is mkldnn, and `new_grad` is mkldnn.
//
// In all of these four cases, `variable_grad += new_grad` is a
// valid operation which adds `new_grad` to `variable_grad` in
// place. `variable_grad` is thus still referring to the same tensor
// after the operation.
// Also DistributedDataParallel(DDP) package relies on grad being
// mutated in place for saving peak memory usage. DDP will still
// work correctly if it is mutated out of place here, but DDP will
// maintain one extra copy of grad tensors in buffer and thus
// increase peak memory usage.
variable_grad += new_grad;
CHECK_RESULT(variable_grad, variable);
// ^ We could enforce the contract more aggressively here by writing:
// if (variable_grad.is_sparse() || new_grad.is_sparse()) {
// variable_grad += new_grad;
// } else if (obeys_layout_contract(variable_grad, variable)) {
// variable_grad += new_grad;
// } else {
// result = at::empty_strided(variable.sizes(), variable.strides(),
// variable.options().memory_format(c10::nullopt));
// update_grad(at::native::add_out(result, variable_grad, new_grad, 1.0);
// }
// However, that accumulation is sometimes in place and sometimes not,
// which may break user code.
}
} else {
at::Tensor result;
if (variable_grad.is_sparse() && !new_grad.is_sparse()) {
// CPU backend throws an error on sparse + dense, so prefer dense + sparse here.
result = new_grad + variable_grad;
} else {
// Assumes operator+ result typically matches strides of first arg,
// and hopes variable_grad was originally created obeying layout contract.
result = variable_grad + new_grad;
}
CHECK_RESULT(result, variable);
update_grad(std::move(result));
// ^ We could enforce the contract more aggressively here by saying
// if (obeys_layout_contract(new_grad, variable)) {
// update_grad(new_grad + variable_grad);
// } else {
// update_grad(variable_grad + new_grad);
// }
// such that the stashed grad is likely to have the right strides if
// either variable_grad or new_grad already has the right strides.
// We could enforce the contract with certainty by saying
// auto result = variable_grad + new_grad (or vice versa), checking result's
// layout, and copying to an obedient clone if necessary before update_grad.
// The copy would require another gmem pass. We can't create empty result with
// the right layout then add_out into it with a single kernel, because GradMode
// is enabled in this branch, and add_out isn't differentiable.
// Maybe more trouble than it's worth.
}
}
Variable variable;
};
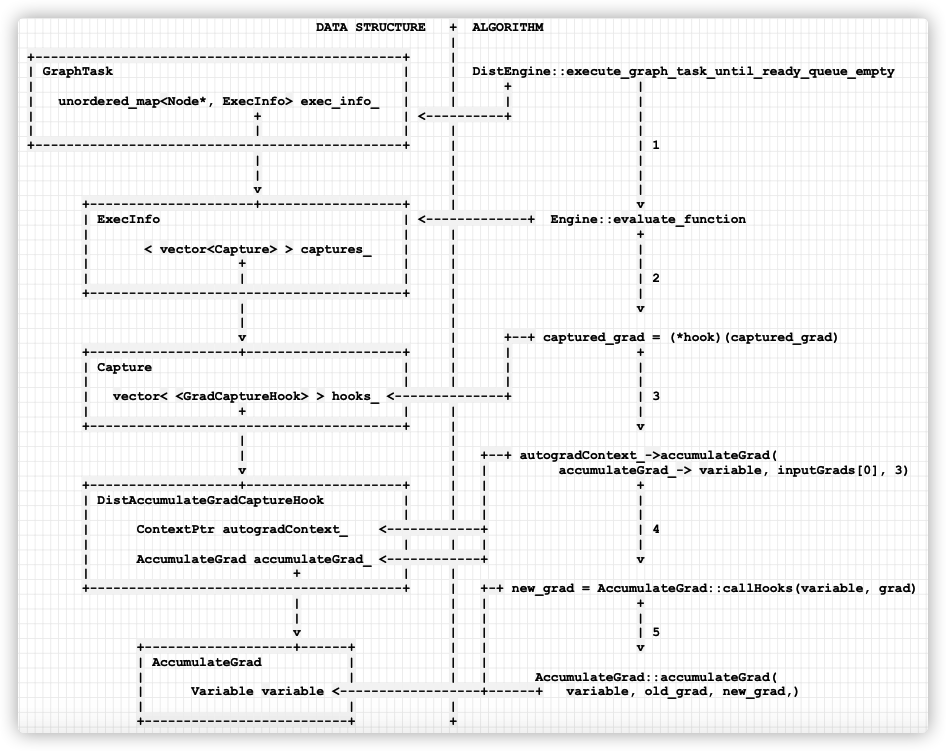
As shown in the following figure, the data structure is on the left, the algorithm process is on the right, and the serial number on the right indicates that the execution is from top to bottom. The data structure on the left will be used in the execution process. The calling relationship between the algorithm and the data structure is represented by the horizontal arrow.
- The distributed engine calls execute_graph_task_until_ready_queue_empty to execute a specific GraphTask.
- Engine::evaluate_function calls ExecInfo in GraphTask.
- Then access GradCaptureHook and call hook. The operator function of hook will call autogradcontext - > accumulateGrad.
- autogradContext_ accumulateGrad will be executed, and the accumulateGrad saved in hook (DistAccumulateGradCaptureHook) will be updated_ Do the operation.
- AccumulateGrad::accumulateGrad completes the final gradient update operation.
DATA STRUCTURE + ALGORITHM
|
+-----------------------------------------------+ |
| GraphTask | | DistEngine::execute_graph_task_until_ready_queue_empty
| | | + |
| unordered_map<Node*, ExecInfo> exec_info_ | | | |
| + | <----------+ |
| | | | |
+-----------------------------------------------+ | | 1
| | |
| | |
v | |
+---------------------+------------------+ | v
| ExecInfo | <-------------+ Engine::evaluate_function
| | | +
| < vector<Capture> > captures_ | | |
| + | | |
| | | | | 2
+----------------------------------------+ | |
| | v
| |
v | +--+ captured_grad = (*hook)(captured_grad)
+-------------------+--------------------+ | | +
| Capture | | | |
| | | | |
| vector< <GradCaptureHook> > hooks_ <--------------+ | 3
| + | | |
+----------------------------------------+ | v
| |
| | +--+ autogradContext_->accumulateGrad(
v | | accumulateGrad_-> variable, inputGrads[0], 3)
+-------------------+--------------------+ | | +
| DistAccumulateGradCaptureHook | | | |
| | | | |
| ContextPtr autogradContext_ <------------+ | 4
| | | | |
| AccumulateGrad accumulateGrad_ <------------+ v
| + | |
+----------------------------------------+ | +-+ new_grad = AccumulateGrad::callHooks(variable, grad)
| | | +
| | | |
v | | | 5
+-------------------+------+ | | v
| AccumulateGrad | | |
| | | | AccumulateGrad::accumulateGrad(
| Variable variable <------------------+------+ variable, old_grad, new_grad,)
| | |
+--------------------------+ +
Mobile phones are as follows:
0x05 waiting for completion
Finally, the distributed engine calls clearAndWaitForOutstandingRpcsAsync to wait for processing to complete.
c10::intrusive_ptr<c10::ivalue::Future> DistAutogradContext::
clearAndWaitForOutstandingRpcsAsync() {
std::unique_lock<std::mutex> lock(lock_);
auto outStandingRpcs = std::move(outStandingRpcs_);
lock.unlock();
struct State {
explicit State(int32_t count)
: future(
c10::make_intrusive<c10::ivalue::Future>(c10::NoneType::get())),
remaining(count) {}
c10::intrusive_ptr<c10::ivalue::Future> future;
std::atomic<int32_t> remaining;
std::atomic<bool> alreadySentError{false};
};
auto state = std::make_shared<State>(outStandingRpcs.size());
if (outStandingRpcs.empty()) {
state->future->markCompleted(c10::IValue());
} else {
for (auto& rpc : outStandingRpcs) {
rpc->addCallback([state](rpc::JitFuture& future) {
if (future.hasError()) {
// If there's an error, we want to setError() on the future,
// unless another error has already been sent - use a CAS to
// guard.
//
// Don't decrement num remaining here! (We don't need to, since
// memory handling is separate). If we simply don't decrement on
// errors, reaching 0 means that there were no errors - and hence,
// we can just markCompleted() without any other checking there.
bool expectedAlreadySent = false;
if (state->alreadySentError.compare_exchange_strong(
expectedAlreadySent, true)) {
state->future->setError(future.exception_ptr());
}
return;
}
if (--state->remaining == 0) {
state->future->markCompleted(c10::IValue());
}
});
}
}
return state->future;
}
Support. The analysis of distributed autograd has been completed. As mentioned earlier, there are four kings of distributed processing. We introduced RPC and RRef and analyzed the distributed engine. Starting from the next article, we will analyze the remaining distributed optimizers. This series may include 4 ~ 6 articles.
0xFF reference
PyTorch source code interpretation of distributed training to understand?
https://pytorch.org/docs/stable/distributed.html
https://pytorch.apachecn.org/docs/1.7/59.html
https://pytorch.org/docs/stable/distributed.html#module-torch.distributed
https://pytorch.org/docs/master/notes/autograd.html
https://pytorch.org/docs/master/rpc/distributed_autograd.html
https://pytorch.org/docs/master/rpc/rpc.html
https://www.w3cschool.cn/pytorch/pytorch-cdva3buf.html
PyTorch distributed Autograd design
Getting started with Distributed RPC Framework
Implementing a Parameter Server using Distributed RPC Framework
Combining Distributed DataParallel with Distributed RPC Framework