Source code analysis Mybatis series:
1,Scanning and Construction of Mapper Objects Initialized by Mybatis MapperProxy for Source Code Analysis
2,Creation process of Mybatis MappedStatement for source code analysis
3,Detailed description of four basic components for Mybatis to execute SQL
This article will introduce the whole process of execution of Mybatis SQL statement in detail. This article has some relevance with the previous one. It is suggested to read the first three articles in this series, focusing on the initialization process of Mybatis Mapper class, because in Mybatis, Mapper is the entry to execute SQL statement, similar to the following code:
@Service public UserService implements IUserService { @Autowired private UserMapper userMapper; public User findUser(Integer id) { return userMapper.find(id); } }
Starting with the theme of this article, we analyze the popularity of Mybatis executing SQL statements by means of source code, and use sharding-jdbc, a database sub-database and sub-table middleware, which is version 1.4.1 of sharding-jdbc.
In order to facilitate the source code analysis of this article, the method call sequence diagram of the core class at Mybatis level is given first.
1. SQL Execution Sequence Diagram
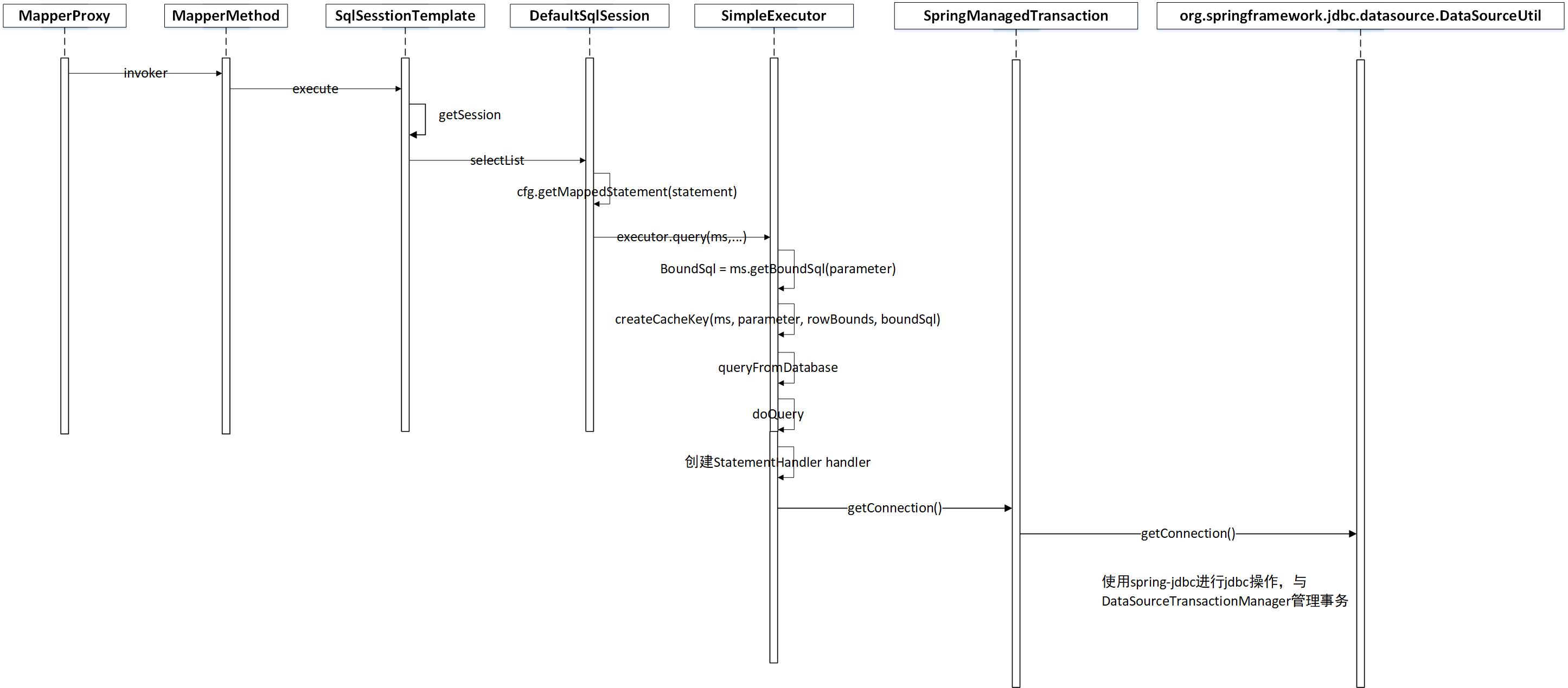
2. Source code parsing SQL execution process
Next, it is analyzed from the point of view of source code.
Warm Tip: At the end of this article, a detailed Mybatis Sharing JDBC statement execution flow chart will be given. Don't miss it.
2.1 MapperProxy#invoker
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { if (Object.class.equals(method.getDeclaringClass())) { try { return method.invoke(this, args); } catch (Throwable t) { throw ExceptionUtil.unwrapThrowable(t); } } final MapperMethod mapperMethod = cachedMapperMethod(method); // @1 return mapperMethod.execute(sqlSession, args); // @2 }
Code @1: Create and cache MapperMethod objects.
Code @2: Call the execute method of the MapperMethod object, that is, each method defined in the mapperInterface will eventually correspond to a MapperMethod.
2.2 MapperMethod#execute
public Object execute(SqlSession sqlSession, Object[] args) { Object result; if (SqlCommandType.INSERT == command.getType()) { Object param = method.convertArgsToSqlCommandParam(args); result = rowCountResult(sqlSession.insert(command.getName(), param)); } else if (SqlCommandType.UPDATE == command.getType()) { Object param = method.convertArgsToSqlCommandParam(args); result = rowCountResult(sqlSession.update(command.getName(), param)); } else if (SqlCommandType.DELETE == command.getType()) { Object param = method.convertArgsToSqlCommandParam(args); result = rowCountResult(sqlSession.delete(command.getName(), param)); } else if (SqlCommandType.SELECT == command.getType()) { if (method.returnsVoid() && method.hasResultHandler()) { executeWithResultHandler(sqlSession, args); result = null; } else if (method.returnsMany()) { result = executeForMany(sqlSession, args); } else if (method.returnsMap()) { result = executeForMap(sqlSession, args); } else { Object param = method.convertArgsToSqlCommandParam(args); result = sqlSession.selectOne(command.getName(), param); } } else { throw new BindingException("Unknown execution method for: " + command.getName()); } if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) { throw new BindingException("Mapper method '" + command.getName() + " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ")."); } return result; }
This method mainly executes corresponding logic according to the type of SQL, insert, update, select and other operations. In this paper, we use query statements to track and enter the executeForMany(sqlSession, args) method.
2.3 MapperMethod#executeForMany
private <E> Object executeForMany(SqlSession sqlSession, Object[] args) { List<E> result; Object param = method.convertArgsToSqlCommandParam(args); if (method.hasRowBounds()) { RowBounds rowBounds = method.extractRowBounds(args); result = sqlSession.<E>selectList(command.getName(), param, rowBounds); } else { result = sqlSession.<E>selectList(command.getName(), param); } // issue #510 Collections & arrays support if (!method.getReturnType().isAssignableFrom(result.getClass())) { if (method.getReturnType().isArray()) { return convertToArray(result); } else { return convertToDeclaredCollection(sqlSession.getConfiguration(), result); } } return result; }
This method is also relatively simple, and finally calls the selectList method through SqlSession.
2.4 DefaultSqlSession#selectList
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) { try { MappedStatement ms = configuration.getMappedStatement(statement); // @1 List<E> result = executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER); // @2 return result; } catch (Exception e) { throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }
Code @1: Get the corresponding MappedStatement object according to the resource name, when the state is the resource name, such as com.demo.UserMapper.findUser. The generation of MappedStatement objects was described in detail at the time of initialization in the previous section, and will not be repeated here.
Code @2: Call Executor's query method. Let me show you that the CachingExecutor query method actually starts with the CachingExecutor. Since the Executor delegate attribute of CachingExecutor defaults to SimpleExecutor, it eventually ends up with SimpleExecutor query.
Next we go to the query method of BaseExecutor, the parent of SimpleExecutor.
2.5 BaseExecutor#query
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { // @1 ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId()); if (closed) throw new ExecutorException("Executor was closed."); if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); } List<E> list; try { queryStack++; list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; // @2 if (list != null) { handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); // @3 } } finally { queryStack--; } if (queryStack == 0) { for (DeferredLoad deferredLoad : deferredLoads) { deferredLoad.load(); } deferredLoads.clear(); // issue #601 if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { // @4 clearLocalCache(); // issue #482 } } return list; }
Code @1: First of all, I will introduce the parameters of this method. These classes are important classes of Mybatis.
- MappedStatement ms
Mapping statement, a MappedStatemnet object representing a method in a Mapper, is the most basic object of mapping. - Object parameter
The parameter list of the SQL statement. - RowBounds rowBounds
Line boundary objects are actually paging parameters limit and size. - ResultHandler resultHandler
Result processing Handler. - CacheKey key
Mybatis Cache Key - BoundSql boundSql
SQL binding information with parameters, from which the SQL statements in the mapping file can be obtained.
Code @2: First, it is retrieved from the cache. Mybatis supports one-level caching (SqlSession) and two-level caching (multiple SqlSessions shared).
Code @3: Query the results from the database, and then go into the doQuery method to perform the real query action.
Code @4: If the first level cache is statement level, delete the cache after the statement has been executed.
2.6 SimpleExecutor#doQuery
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null; try { Configuration configuration = ms.getConfiguration(); StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); // @1 stmt = prepareStatement(handler, ms.getStatementLog()); // @2 return handler.<E>query(stmt, resultHandler); // @3 } finally { closeStatement(stmt); } }
Code @1: Create StatementHandler, where Mybatis plug-in extension mechanism will be added (described in detail in the next article), as shown in the figure:
Code @2: Create a Statement object. Note that this is the java.sql.Statement object of the JDBC protocol.
Code @3: Execute the SQL statement using the Statment object.
Next, the process of creating and executing Statement object is introduced in detail, that is, the code @2 and code @3 of Distributed Detailed Tracking.
3. Statement Object Creation Process
3.1 java.sql.Connection object creation
3.1.1 SimpleExecutor#prepareStatement
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException { Statement stmt; Connection connection = getConnection(statementLog); // @1 stmt = handler.prepare(connection); // @2 handler.parameterize(stmt); // @3 return stmt; }
Create a Statement object in three steps:
Code @1: Create a java.sql.Connection object.
Code @2: Create a Statment object using the Connection object.
Code @3: Extra processing of Statement, especially PrepareStatement parameter handler.
3.1.2 SimpleExecutor#getConnection
The getConnection method, according to the flow chart above, first enters into the org. mybatis. spring. transaction. Spring ManagedTransaction, and then obtains the connection through the spring-jdbc framework using DataSourceUtils. The code is as follows:
public static Connection doGetConnection(DataSource dataSource) throws SQLException { Assert.notNull(dataSource, "No DataSource specified"); ConnectionHolder conHolder = (ConnectionHolder) TransactionSynchronizationManager.getResource(dataSource); if (conHolder != null && (conHolder.hasConnection() || conHolder.isSynchronizedWithTransaction())) { conHolder.requested(); if (!conHolder.hasConnection()) { conHolder.setConnection(dataSource.getConnection()); } return conHolder.getConnection(); } // Else we either got no holder or an empty thread-bound holder here. logger.debug("Fetching JDBC Connection from DataSource"); Connection con = dataSource.getConnection(); // @1 // The code related to transaction processing is omitted here. return con; }
Code @1: Get connection through DataSource. Who is DataSource here? Look at the configuration of our project:
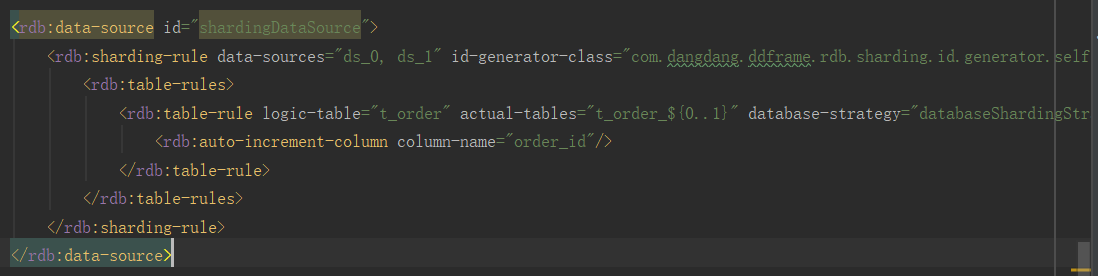
So the final connection obtained by dataSouce.getConnection is from Spring Sharing DataSource.
com.dangdang.ddframe.rdb.sharding.jdbc.ShardingDataSource#getConnection public ShardingConnection getConnection() throws SQLException { MetricsContext.init(shardingProperties); return new ShardingConnection(shardingContext); }
The results returned are as follows: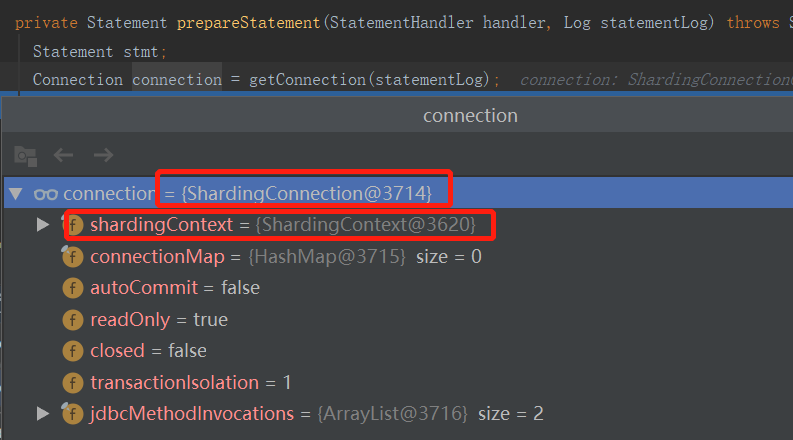
Note: Only a ShardingConnection object is returned, which contains the context of the sub-database and sub-table, but no specific sub-database operation (switching data sources) is performed at this time.
After the Connection acquisition process is clear, let's move on to the creation of Statemnet objects.
3.2 java.sql.Statement object creation
stmt = prepareStatement(handler, ms.getStatementLog());
The call chain of the above statement: Routing Statement Handler - "BaseStatement Handler"
3.2.1 BaseStatementHandler#prepare
public Statement prepare(Connection connection) throws SQLException { ErrorContext.instance().sql(boundSql.getSql()); Statement statement = null; try { statement = instantiateStatement(connection); // @1 setStatementTimeout(statement); // @2 setFetchSize(statement); // @3 return statement; } catch (SQLException e) { closeStatement(statement); throw e; } catch (Exception e) { closeStatement(statement); throw new ExecutorException("Error preparing statement. Cause: " + e, e); } }
Code @1: Create a Statement object based on the Connection object (ShardingConnection in this article), whose default implementation class is the PreparedStatementHandler#instantiateStatement method.
Code @2: Set the timeout for Statement.
Code @3: Set fetchSize.
3.2.2 PreparedStatementHandler#instantiateStatement
protected Statement instantiateStatement(Connection connection) throws SQLException { String sql = boundSql.getSql(); if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) { String[] keyColumnNames = mappedStatement.getKeyColumns(); if (keyColumnNames == null) { return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS); } else { return connection.prepareStatement(sql, keyColumnNames); } } else if (mappedStatement.getResultSetType() != null) { return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY); } else { return connection.prepareStatement(sql); } }
In fact, the creation of Statement object is relatively simple, since Connection is Sharing Connection, then take a look at its corresponding prepareStatement method.
3.2.2 ShardingConnection#prepareStatement
public PreparedStatement prepareStatement(final String sql) throws SQLException { // sql, to configure sql statements in mybatis xml files return new ShardingPreparedStatement(this, sql); } ShardingPreparedStatement(final ShardingConnection shardingConnection, final String sql, final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability) { super(shardingConnection, resultSetType, resultSetConcurrency, resultSetHoldability); preparedSQLRouter = shardingConnection.getShardingContext().getSqlRouteEngine().prepareSQL(sql); }
When building Sharding PreparedStatement object, parser objects parsing SQL routing are created according to the SQL statement, but the related routing calculation is not performed at this time. After the creation of PreparedStatement object, it begins to enter the SQL execution process.
4. SQL Execution Process
Next, let's move on to step 3 of the SimpleExecutor doQuery method to execute the SQL statement:
handler.<E>query(stmt, resultHandler).
The first step is to enter the Routing StatementHandler class for Mybatis-level routing (mainly based on the Statement type)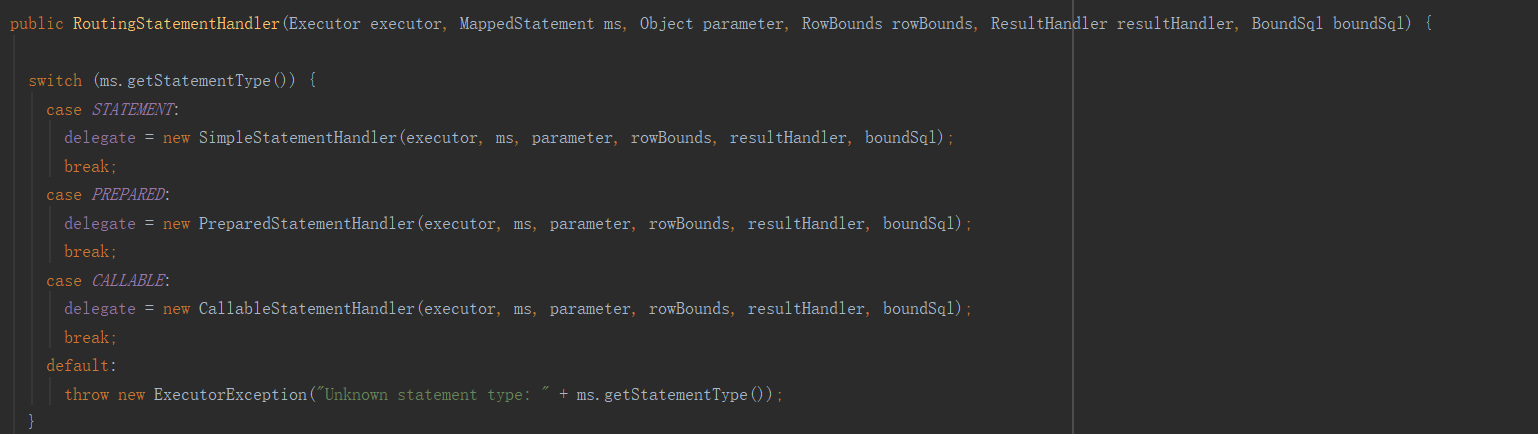
Then go into PreparedStatementHandler#query.
4.1 PreparedStatementHandler#query
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException { PreparedStatement ps = (PreparedStatement) statement; ps.execute(); // @1 return resultSetHandler.<E> handleResultSets(ps); // @2 }
Code @1: Call the execute method of PreparedStatement, because this example uses Sharing-jdbc sub-library table, at this time the specific implementation of the call is Sharing PreparedStatement.
Code @2: Processing results.
We will follow up execute and result processing respectively.
4.2 ShardingPreparedStatement#execute
public boolean execute() throws SQLException { try { return new PreparedStatementExecutor(getShardingConnection().getShardingContext().getExecutorEngine(), routeSQL()).execute(); // @1 } finally { clearRouteContext(); } }
The key points are as follows:
1) Create a PreparedStatementExecutor object with two core parameters:
-
Executor Engine executor Engine: Sharing JDBC execution engine.
- Collection< PreparedStatementExecutorWrapper> preparedStatemenWrappers
A collection. Each collection is a wrapper class of PreparedStatement. How does this collection come from?
- Collection< PreparedStatementExecutorWrapper> preparedStatemenWrappers
2) Prepared Statement enWrappers are generated by routeSQL method.
3) The execute of the PreparedStatementExecutor method is finally called to execute.
Next, take a look at routeSQL and execute methods, respectively.
4.3 ShardingPreparedStatement#routeSQL
private List<PreparedStatementExecutorWrapper> routeSQL() throws SQLException { List<PreparedStatementExecutorWrapper> result = new ArrayList<>(); SQLRouteResult sqlRouteResult = preparedSQLRouter.route(getParameters()); // @1 MergeContext mergeContext = sqlRouteResult.getMergeContext(); setMergeContext(mergeContext); setGeneratedKeyContext(sqlRouteResult.getGeneratedKeyContext()); for (SQLExecutionUnit each : sqlRouteResult.getExecutionUnits()) { // @2 PreparedStatement preparedStatement = (PreparedStatement) getStatement(getShardingConnection().getConnection(each.getDataSource(), sqlRouteResult.getSqlStatementType()), each.getSql()); // @3 replayMethodsInvocation(preparedStatement); getParameters().replayMethodsInvocation(preparedStatement); result.add(wrap(preparedStatement, each)); } return result; }
Code @1: According to the parameters of SQL routing calculation, this paper does not pay attention to its specific implementation details, which will be detailed in the specific analysis of Sharing-jdbc, here we can see the results intuitively:
Code @2, @3: Traverse the results of the database sub-table, and then use the underlying Datasource to create Connection and PreparedStatement objects.
routeSQL is mentioned for the time being. From here we know that we will create corresponding Connection and PreparedStatement objects using the underlying specific data sources according to the routing results.
4.4 PreparedStatementExecutor#execute
public boolean execute() { Context context = MetricsContext.start("ShardingPreparedStatement-execute"); eventPostman.postExecutionEvents(); final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown(); final Map<String, Object> dataMap = ExecutorDataMap.getDataMap(); try { if (1 == preparedStatementExecutorWrappers.size()) { // @1 PreparedStatementExecutorWrapper preparedStatementExecutorWrapper = preparedStatementExecutorWrappers.iterator().next(); return executeInternal(preparedStatementExecutorWrapper, isExceptionThrown, dataMap); } List<Boolean> result = executorEngine.execute(preparedStatementExecutorWrappers, new ExecuteUnit<PreparedStatementExecutorWrapper, Boolean>() { // @2 @Override public Boolean execute(final PreparedStatementExecutorWrapper input) throws Exception { synchronized (input.getPreparedStatement().getConnection()) { return executeInternal(input, isExceptionThrown, dataMap); } } }); return (null == result || result.isEmpty()) ? false : result.get(0); } finally { MetricsContext.stop(context); } }
Code @1: If the calculated routing information is one, it is executed synchronously.
Code @2: If the calculated routing information has more than one, the thread pool is used for asynchronous execution.
Then there's another question, how do you return the result after execution through the PreparedStatement#execute method? Especially asynchronous execution.
In fact, as mentioned above:
4.4 DefaultResultSetHandler#handleResultSets
public List<Object> handleResultSets(Statement stmt) throws SQLException { ErrorContext.instance().activity("handling results").object(mappedStatement.getId()); final List<Object> multipleResults = new ArrayList<Object>(); int resultSetCount = 0; ResultSetWrapper rsw = getFirstResultSet(stmt); // @1 //Some code is omitted, and the complete code can see the DefaultResultSetHandler method. return collapseSingleResultList(multipleResults); } private ResultSetWrapper getFirstResultSet(Statement stmt) throws SQLException { ResultSet rs = stmt.getResultSet(); // @2 while (rs == null) { // move forward to get the first resultset in case the driver // doesn't return the resultset as the first result (HSQLDB 2.1) if (stmt.getMoreResults()) { rs = stmt.getResultSet(); } else { if (stmt.getUpdateCount() == -1) { // no more results. Must be no resultset break; } } } return rs != null ? new ResultSetWrapper(rs, configuration) : null; }
Let's look at its key code as follows:
Code @1: Call the Statement#getResultSet() method. If shardingJdbc is used, ShardingStatement#getResultSet() will be called, and the merging of result sets of sub-database and sub-table will be handled. This section will not be described in detail here. This section will analyze in detail in the shardingjdbc column.
Code @2: The general way to get the result set in JDBC state is not introduced too much here.
mybatis shardingjdbc SQL execution process is introduced here. In order to facilitate your understanding of the above process, the flow chart of SQL execution is given at last.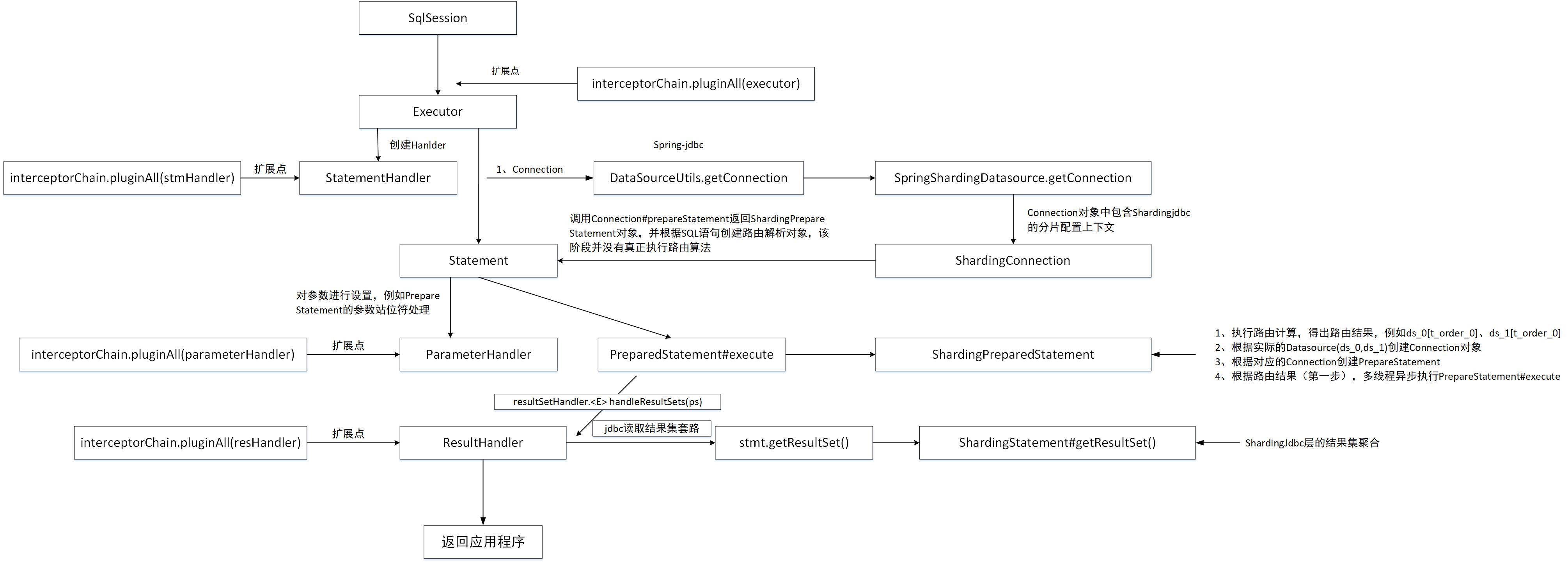
Mybatis Sharing-Jdbc's SQL execution process is described here. You can also see clearly the plug-in mechanism of Mybatis from the figure, which will be described in detail below.
The original publication date is: 2019-05-28
Author: Ding Wei, author of RocketMQ Technology Insider.
This article comes from Interest Circle of Middleware To learn about relevant information, you can pay attention to it. Interest Circle of Middleware.