The so-called action operator is the method to trigger job execution
reduce
Function signature: def reduce (F: (T, t) = > t): t
Function Description: aggregate all elements in RDD, first aggregate data in partitions, and then aggregate data between partitions
@Test
def reduce(): Unit = {
val rdd = sc.makeRDD(List(1,2,3,4))
//Direct results, unlike transformation operators, change from one RDD to another
val i: Int = rdd.reduce(_+_)
println(i)
}
Result display

collect
Function signature: def collect(): Array[T]
Function Description: in the driver, all elements of the data set are returned in the form of Array array
@Test
def collect(): Unit = {
val rdd = sc.makeRDD(List(1,2,3,4))
//Collect will collect the data of different partitions into the Driver side memory according to the partition order to form an array
val ints: Array[Int] = rdd.collect()
println(ints.mkString(","))
}
Result display

count
function signature: def count(): Long
Function Description: returns the number of elements in RDD
@Test
def count(): Unit = {
val rdd = sc.makeRDD(List(1, 2, 3, 4))
//Number of elements
val cnt = rdd.count()
println(cnt)
}
Result display

first
function signature: def first(): T
Function Description: returns the first element in the RDD
@Test
def first(): Unit = {
val rdd = sc.makeRDD(List(1, 2, 3, 4))
//Returns the first element
println(rdd.first())
}
Result display

take
Function signature: def take(num: Int): Array[T]
Function Description: returns an array composed of the first n elements of RDD
@Test
def takeOrdered(): Unit = {
val rdd = sc.makeRDD(List(1, 2, 3, 4))
//Returns the first few elements
println(rdd.take(2).mkString(","))
}
Result display

takeOrdered
Function signature: def takeordered (Num: int) (implicit order: ordering [t]): array [t]
Function Description: returns an array composed of the first n elements sorted by the RDD
@Test
def takeOrdered(): Unit = {
val rdd = sc.makeRDD(List(1, 6, 2, 4))
//Returns the first few in order
println(rdd.takeOrdered(2).mkString(","))
}
Result display

aggregate
function signature
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
Function Description: the data in the partition is aggregated through the initial value and the data in the partition, and then the data in the partition is aggregated with the initial value
@Test
def aggregate(): Unit = {
val rdd = sc.makeRDD(List(1, 2, 3, 4))
println(rdd.aggregate(1)(_+_,_+_))
}
Result display

aggravat will not only participate in the calculation within partitions, but also participate in the calculation between partitions
fold
function signature: def fold (zerovalue: T) (OP: (T, t) = > t): t
Function Description: folding operation, simplified version of aggregate operation
Simplified operation of
@Test
def fold(): Unit = {
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
println(rdd.fold(1)(_ + _))
}
Result display

countByKey
Function signature: def countByKey(): Map[K, Long]
Function Description: count the number of key s of each type
@Test
def countByKey(): Unit = {
val rdd = sc.makeRDD(List(("a",1),("b",1),("c",1),("a",1),("c",1)), 2)
println(rdd.countByKey())
}
Result display

save correlation operator
function signature
def saveAsTextFile(path: String): Unit def saveAsObjectFile(path: String): Unit def saveAsSequenceFile( path: String, codec: Option[Class[_ <: CompressionCodec]] = None): Unit
Function Description: save data to files in different formats
@Test
def save(): Unit = {
val rdd = sc.makeRDD(List(("a", 1), ("b", 1), ("c", 1), ("a", 1), ("c", 1)), 2)
rdd.saveAsTextFile("output")
rdd.saveAsObjectFile("output1")
rdd.saveAsSequenceFile("output2")
}
Result display
saveAsSequenceFile requires that the data format must be KV type
Jump top
foreach
function signature
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}
Function Description: traverse each element in RDD in a distributed manner and call the specified function
@Test
def foreach(): Unit = {
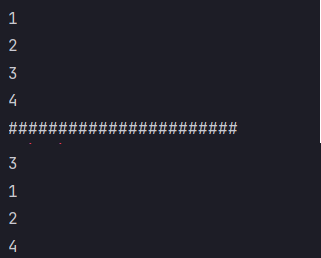
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
rdd.collect().foreach(println(_))
println("#######################")
rdd.foreach(println)
}
Result display