Today is the third day of the lunar new year. Monkey Sai Lei
Small talk
These days, I send her a red envelope every night, a new year's red envelope, and an expression package can be added. I feel that the Chinese New Year is good and there is no new year flavor. My throat hurts when I eat melon seeds.
There are many operators in Spark, including Value type and double Value type. What I wrote these days is Value type. Yesterday I talked about map mapping.
Let's talk about the remaining operators today
glom
The glom operator turns each partition in the RDD into an array and places it in the RDD. The element types in the array are the same as those in the original partition. Originally, the number in this partition is scattered. After glom, the elements in this partition will become an array.
def glom(): RDD[Array[T]] = withScope {
new MapPartitionsRDD[Array[T], T]
(this, (_, _, iter) => Iterator(iter.toArray))It can be seen that the bottom layer of the glom uses the MapPartitionsRDD object. The bottom layer of the MapPartitionsRDD object rewrites the getPartitions method. This method uses the dependency of RDD, keeps the partition data unchanged, and then converts the partition data into array type.
Take an example to calculate the sum of the maximum values of all partitions.
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sparkContext = new SparkContext(sparkConf)
// Two zones 12 in zone 1 and 35 in zone 2
val value = sparkContext.makeRDD(List(1, 2, 3, 5), 2)
//Array glom for each partition
val value1 = value.glom()
//Find the maximum value of each array
val value2 = value1.map(array => array.max)
//Sum the maximum value of each array
val sum = value2.collect().sumZone maximum summation
Maximum value of zone 1: 2 maximum value of zone 2: 5
After collect ion, each node returns the maximum value of each array to the Driver, and then adds it
groupBy
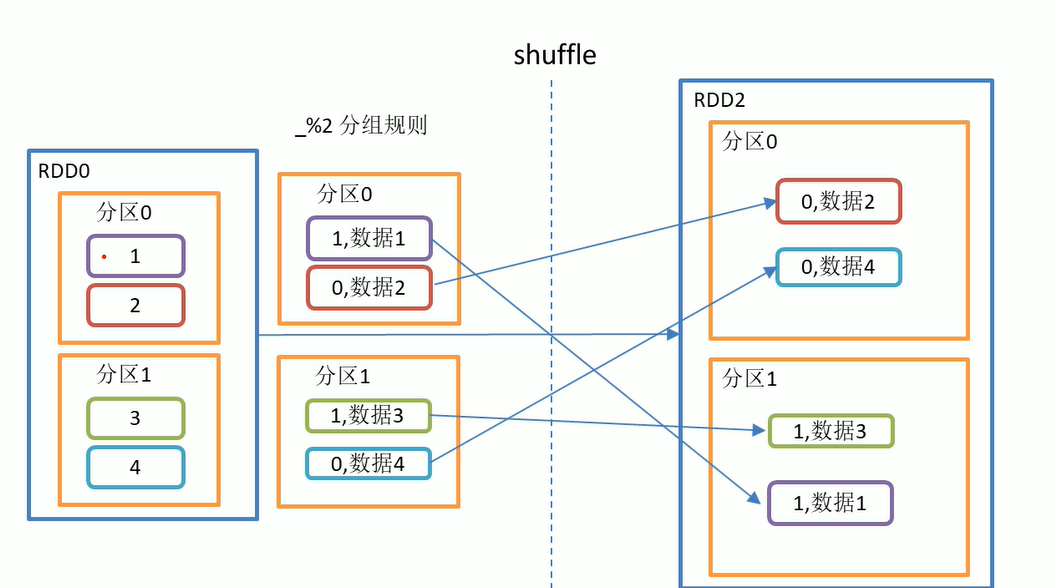
The data is grouped according to the specified rules. The partition remains unchanged by default, but the grouped data may not be the original partition, and the data will be disrupted. Such an operation is Shuffle. In extreme cases, the data may be divided into the same partition.
Divide the data of the same key into an iterator.
Here is an example
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
//Group the data according to the specified rules
val value = sparkContext.makeRDD(List(1, 2, 3, 4), 2)
val value1 = value.groupBy(_ % 2 == 0)
value1.collect().foreach(println(_))Just started two partitions
Partition 1:1 2 partition 2:3 4
After group by, the data changes and only one partition has data
(1,(false,CompactBuffer(1, 3))) (1,(true,CompactBuffer(2, 4)))
It can be seen that the data after partition is not as illustrated above, because Shuffle occurs
In order to reflect the role of group by, the List("Hello", "hive", "hbase", "Hadoop") will be grouped according to the initial letter of the word.
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List("Hello", "hbase", "Hive", "Hadoop"), 2)
val value1 = value.groupBy(_.charAt(0))
value1.collect().foreach(println(_)) }Look at the results
(h,CompactBuffer(hbase)) (H,CompactBuffer(Hello, Hive, Hadoop))
The characters in front are the basis of our grouping, and the iterators behind are the elements after grouping
WordCount
When learning mr, the first example is to find WordCount. Spark is also used for operation, which is a simple wc. First, separate each word. After separation, count each word (word, 1). After counting, group according to the words. After word grouping, calculate the size of the iterator.
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List("Hello Spark", "Hello Scala"), 2)
//First divide the words one by one
val value1 = value.flatMap(_.split(" "))
//Count each word
val value2 = value1.map((_, 1))
//grouping
val value3 = value2.groupBy(_._1)
val value5 = value3.map {
case (word, iter) => (word, iter.size) }
value5.collect().foreach(println(_))
Filter
The data will be filtered according to the specified rules. The data that meets the rules will be retained and the data that does not meet the rules will be discarded. After filtering the data, the partition remains unchanged, but the data in the partition may be unbalanced, which may cause data skew.
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List(1, 2, 3, 4))
val value1 = value.filter(_ != 1)
value1.collect().foreach(println(_))Distinct
De duplication of duplicate data in data set

val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List(1, 2, 3, 4,4))
val value1 = value.distinct()If there are no parameters in distinct, the final result is 1,2,3,4
If there is a parameter in distinct, such as 2, the final result will have two partitions. The original partition (because the setMaster is set to Local, the default partition) and the data of the original partition are scattered into two partitions to generate shuffle
coalesce
Reduce partitions according to the amount of data. If there are too many partitions, you can reduce them.
The parameter in the coalesce operator has a shuffle. If it is True, the coalesce will shuffle the data and disrupt the data. If it is False, the data will not be disrupted.
Let's take a look at the example first
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
//Four data, three partitions 1 2 34
val value = sparkContext.makeRDD(List(1, 2, 3, 4),3)
//Reduce the number of partitions to two. shuffle defaults to False and will not disturb the data
val value1 = value.coalesce(2)
//You can see the partition of data
val value2 = value1.mapPartitionsWithIndex(
(index, iter) => { iter.map(num => (index, num)) })
value2.collect().foreach(println(_))First look at the previous partition
Partition 1:1 partition 2:2 partition 3:3 4
Now let's take a look at the partition when the shuffle parameter is False

It can be seen that the partitions are really reduced. Obviously, the data is no longer in the third partition, but in the second partition, and the data is not disturbed.
In fact, it's not. Take a look at the data of partition 3. The data of partition 3 and 4 enter the second partition together, and the data of partition 3 is not disturbed. This is called shuffle. It doesn't disturb the data, but puts the original data into other partitions.
Now look at the case where the shuffle parameter is True
If there is a Shuffle, 1, 2, 3 and 4 are divided into two partitions,
Zone 1:1 3 zone 2:2 4
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
//Four data, three partitions 1 2 34
val value = sparkContext.makeRDD(List(1, 2, 3, 4),3)
//Reduce the partition to two. If the shuffle parameter is true, there will be a shuffle phase
val value1 = value.coalesce(2,true)
//You can see the partition of data
val value2 = value1.mapPartitionsWithIndex(
(index, iter) => { iter.map(num => (index, num)) })
value2.collect().foreach(println(_))
It can be seen that the data in the original first partition and the second partition do not change, but the data in the third partition is put into the two partitions
repartition
The repartition operator is basically the same as the coalesce operator, but the number of partitions can be reduced or increased by the reation operator. Whether it is increased or decreased, the repartition operator will have a shuffle stage and will disrupt the data.

You can see that the shuffle parameter is true by default.
It will change the partition of data
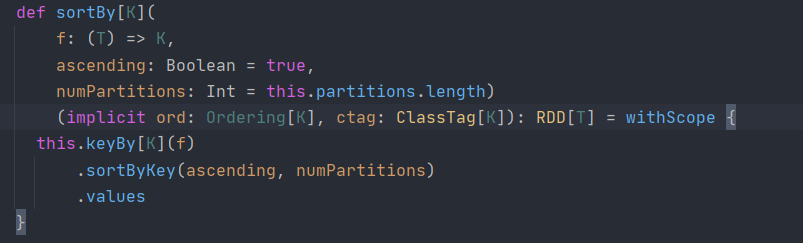
sortBy
This operation is used to sort data. Before sorting, the data can be processed through the f function, and then processed according to the f function
Sort the results of. The default is ascending. The number of partitions of the newly generated RDD after sorting is the same as that of the original RDD
To. There is a shuffle process in the middle
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List(4, 3, 1, 2))
val value1 = value.sortBy(num => num)
value1.collect().foreach(println(_))Final result

You can see that it is sorted in ascending order. If you want to sort in descending order, add a parameter false
The default is true, sorted in ascending order
summary
Today, I've finally finished talking about the operator of Value type. Tomorrow, I'll finish talking about the operator of double Value type.
This year is the third day of the lunar new year. We should also study during the new year