Spark Doris Connector is a new feature introduced by Doris in version 0.12. Users can use this function to directly read and write the data stored in Doris through spark, and support SQL, Dataframe, RDD and other methods.
From the perspective of Doris, introducing its data into Spark can use a series of rich ecological products of Spark, broaden the imagination of products, and make the joint query between Doris and other data sources possible
1. Technical selection
In the early scheme, we directly provided Doris's JDBC interface to Spark. For the JDBC data source, the working principle of the Spark side is that the Spark Driver accesses the FE of Doris through the JDBC protocol to obtain the Schema of the corresponding Doris table. Then, according to a certain field, the query is divided into multiple Partition sub query tasks and distributed to multiple Spark executors. Executors convert the Partition they are responsible for into the corresponding JDBC query, and directly access Doris's FE interface to obtain the corresponding data. This scheme hardly needs to change the code, but because Spark can't perceive Doris's data distribution, it will cause great query pressure to Doris.
So the community developed a new data source for Doris, spark Doris connector. Under this scheme, Doris can expose Doris data and distribute it to spark. Spark Driver accesses Doris FE to obtain the Schema and underlying data distribution of Doris table. Then, according to this data distribution, reasonably allocate data query tasks to Executors. Finally, spark Executors access different BE for query. It greatly improves the efficiency of query.
2. Usage
Compile doris-spark-1.0.0-SNAPSHOT.jar in the extension / Spark Doris connector / directory of Doris code base. Add this jar package to Spark's ClassPath to use Spark on Doris function
2.1 reading
2.1.1 SQL
CREATE TEMPORARY VIEW spark_doris USING doris OPTIONS( "table.identifier"="$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME", "fenodes"="$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT", "user"="$YOUR_DORIS_USERNAME", "password"="$YOUR_DORIS_PASSWORD" ); SELECT * FROM spark_doris;
2.1.2 DataFrame
val dorisSparkDF = spark.read.format("doris")
.option("doris.table.identifier", "$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME")
.option("doris.fenodes", "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT")
.option("user", "$YOUR_DORIS_USERNAME")
.option("password", "$YOUR_DORIS_PASSWORD")
.load()
dorisSparkDF.show(5)
2.1.3 RDD
import org.apache.doris.spark._
val dorisSparkRDD = sc.dorisRDD(
tableIdentifier = Some("$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME"),
cfg = Some(Map(
"doris.fenodes" -> "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT",
"doris.request.auth.user" -> "$YOUR_DORIS_USERNAME",
"doris.request.auth.password" -> "$YOUR_DORIS_PASSWORD"
))
)
dorisSparkRDD.collect()
2.2 writing
2.2.1 SQL mode
CREATE TEMPORARY VIEW spark_doris
USING doris
OPTIONS(
"table.identifier"="$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME",
"fenodes"="$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT",
"user"="$YOUR_DORIS_USERNAME",
"password"="$YOUR_DORIS_PASSWORD"
);
INSERT INTO spark_doris VALUES ("VALUE1","VALUE2",...);
# or
INSERT INTO spark_doris SELECT * FROM YOUR_TABLE
2.2.2 DataFrame(batch/stream) mode
## batch sink
val mockDataDF = List(
(3, "440403001005", "21.cn"),
(1, "4404030013005", "22.cn"),
(33, null, "23.cn")
).toDF("id", "mi_code", "mi_name")
mockDataDF.show(5)
mockDataDF.write.format("doris")
.option("doris.table.identifier", "$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME")
.option("doris.fenodes", "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT")
.option("user", "$YOUR_DORIS_USERNAME")
.option("password", "$YOUR_DORIS_PASSWORD")
.save()
## stream sink(StructuredStreaming)
val kafkaSource = spark.readStream
.option("kafka.bootstrap.servers", "$YOUR_KAFKA_SERVERS")
.option("startingOffsets", "latest")
.option("subscribe", "$YOUR_KAFKA_TOPICS")
.format("kafka")
.load()
kafkaSource.selectExpr("CAST(key AS STRING)", "CAST(value as STRING)")
.writeStream
.format("doris")
.option("checkpointLocation", "$YOUR_CHECKPOINT_LOCATION")
.option("doris.table.identifier", "$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME")
.option("doris.fenodes", "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT")
.option("user", "$YOUR_DORIS_USERNAME")
.option("password", "$YOUR_DORIS_PASSWORD")
.start()
.awaitTermination()
2.3 applicable scenarios
2.3.1 processing historical data changes
Before Spark Doris Connector, Doris had a high cost of modifying data, but data modification and deletion requirements often appeared in real business.
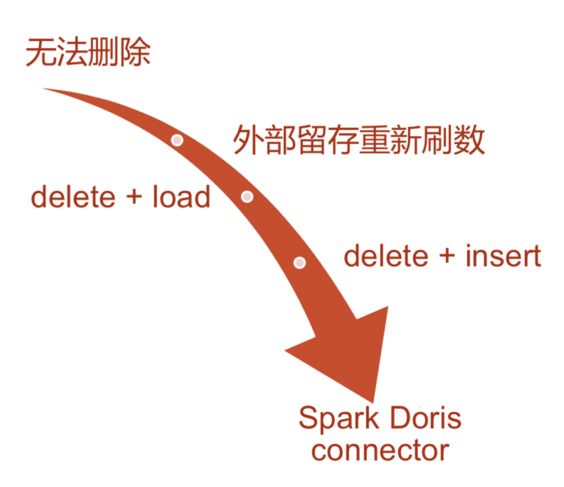
Before Spark Doris Connector
Scheme 1: do not delete the wrong data imported before. Use the replace method to pour all the wrong data into a negative value, brush the value to 0, and then import the correct data.
Scheme 2: delete the wrong data, and then insert the correct data.
There is a problem with the above schemes, that is, there is always a period of time when the data value is 0. This is intolerable for external systems. For example, advertisers need to view their account information. If the account is displayed as 0 due to data change, it will be unacceptable and unfriendly.
Spark Doris Connector solution
With Spark Doris Connector, it will be more convenient to handle historical data changes

As shown in the above figure, the first line is error data and the second line is correct data. Spark can link two streams. One stream uses Spark Doris Connector to connect Doris, and the other stream connects external correct data (such as Parquet file generated by business department). Do the diff operation in spark and calculate the diff value of all values, that is, the result of the last line in the figure. Import it into Doris. The advantage of this is that it can eliminate the intermediate time window, and it is also convenient for the business parties that often use spark to operate. It is very friendly.
Use Spark to jointly analyze the data in Doris and other data sources
Many business departments put their data on different storage systems, such as some online analysis and report data in Doris, some structured retrieval data in Elasticsearch, and some data that need things in MySQL, etc. Businesses often need to analyze across multiple storage sources. After connecting Spark and Doris through Spark Doris Connector, businesses can directly use Spark to jointly query and calculate the data in Doris with multiple external data sources.
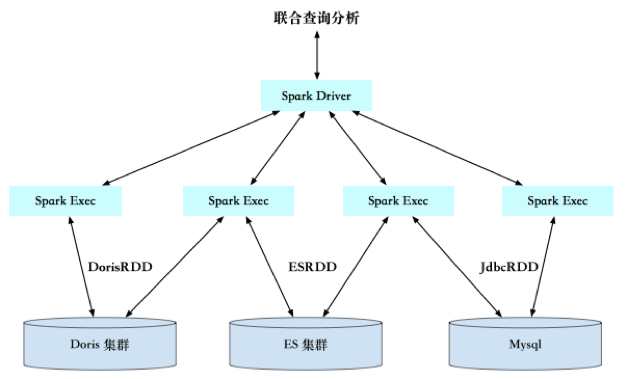
2.3.2 data real-time processing and writing
At present, Spark doris connector supports reading data from the data source through SQL and DataFrame, and writing data to doris through SQL and DataFrame. At the same time, Spark's computing power can also be used to perform some real-time calculations on the data.
3. Relevant configuration parameters
3.1 general configuration
| Key | Default Value | Comment |
|---|---|---|
| doris.fenodes | – | Doris FE http address, supports multiple addresses, separated by commas |
| doris.table.identifier | – | Doris table name, such as db1.tbl1 |
| doris.request.retries | 3 | Number of retries to send a request to Doris |
| doris.request.connect.timeout.ms | 30000 | Connection timeout for sending request to Doris |
| doris.request.read.timeout.ms | 30000 | Read timeout for sending request to Doris |
| doris.request.query.timeout.s | 3600 | The timeout for querying doris. The default value is 1 hour, - 1 means there is no timeout limit |
| doris.request.tablet.size | Integer.MAX_VALUE | The number of Doris tablets corresponding to an RDD Partition. The smaller this value is, the more partitions will be generated. So as to improve the parallelism of Spark side, but at the same time, it will cause greater pressure on Doris. |
| doris.batch.size | 1024 | The maximum number of rows to read data from BE at a time. Increase this value to reduce the number of connections between Spark and Doris. So as to reduce the additional time overhead caused by network delay. |
| doris.exec.mem.limit | 2147483648 | Memory limit for a single query. The default is 2GB in bytes |
| doris.deserialize.arrow.async | false | Does it support asynchronous conversion of Arrow format to RowBatch required for spark Doris connector iteration |
| doris.deserialize.queue.size | 64 | Asynchronously convert the internal processing queue in Arrow format. It takes effect when doris.deserialize.arrow.async is true |
3.2 SQL and Dataframe proprietary configuration
| Key | Default Value | Comment |
|---|---|---|
| user | – | User name to access Doris |
| password | – | Password to access Doris |
| doris.filter.query.in.max.count | 100 | The maximum number of in expression value list elements in predicate pushdown. If this number is exceeded, the in expression conditional filtering is processed on the Spark side. |
3.3 RDD proprietary configuration
| Key | Default Value | Comment |
|---|---|---|
| doris.request.auth.user | – | User name to access Doris |
| doris.request.auth.password | – | Password to access Doris |
| doris.read.field | – | Read the column name list of Doris table, and use commas to separate multiple columns |
| doris.filter.query | – | Filter the expression for reading data, which is transmitted to Doris. Doris uses this expression to complete source side data filtering. |
3.4 Doris and Spark column type mapping
| Doris Type | Spark Type |
|---|---|
| NULL_TYPE | DataTypes.NullType |
| BOOLEAN | DataTypes.BooleanType |
| TINYINT | DataTypes.ByteType |
| SMALLINT | DataTypes.ShortType |
| INT | DataTypes.IntegerType |
| BIGINT | DataTypes.LongType |
| FLOAT | DataTypes.FloatType |
| DOUBLE | DataTypes.DoubleType |
| DATE | DataTypes.StringType1 |
| DATETIME | DataTypes.StringType1 |
| BINARY | DataTypes.BinaryType |
| DECIMAL | DecimalType |
| CHAR | DataTypes.StringType |
| LARGEINT | DataTypes.StringType |
| VARCHAR | DataTypes.StringType |
| DECIMALV2 | DecimalType |
| TIME | DataTypes.DoubleType |
| HLL | Unsupported datatype |
- Note: in Connector, DATE and DATETIME are mapped to string. Due to the processing logic of Doris's underlying storage engine, when the time type is used directly, the covered time range cannot meet the requirements. So use String Type directly returns the corresponding time readable text