Spark independent cluster (just understand), how spark runs on Yan
Cluster mode
Here is just a record of how Spark Standalone -- independent cluster mode is built
The standalone model is generally not applicable in the company, because the company generally has yarn and does not need to develop two resource management frameworks
So there is no need to build
Standalone architecture diagram
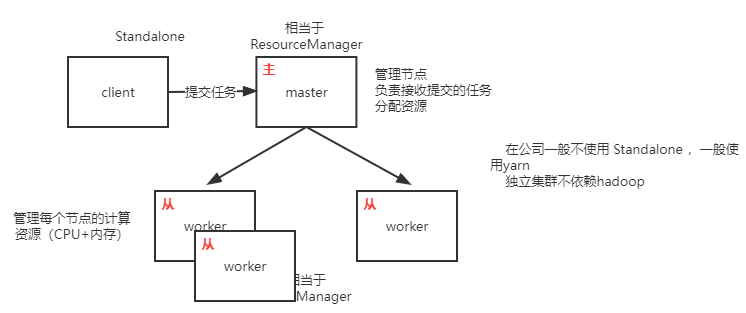
Construction of Standalone
1. Upload, unzip and rename
cd /usr/local/module tar -zxvf /usr/local/module/spark-2.4.5-bin-hadoop2.7.tgz -C /usr/local/soft/ mv spark-2.4.5-bin-hadoop2.7 spark-2.4.5
2. Configure environment variables
vim /etc/profile export SPARK_HOME=/usr/local/soft/spark-2.4.5 export PATH=$PATH:$SPARK_HOME/bin source /etc/profile
3. Modify configuration file conf
cd /usr/local/soft/spark-2.4.5/conf cp spark-env.sh.template spark-env.sh #Add configuration -- spark env SH file export SPARK_MASTER_IP=master export SPARK_MASTER_PORT=7077 export SPARK_WORKER_CORES=2 export SPARK_WORKER_INSTANCES=1 export SPARK_WORKER_MEMORY=2g export JAVA_HOME=/usr/local/soft/jdk1.8.0_171 ------------------------------------------------- cp slaves.template slaves #Add -- slave file node1 node2
4. Synchronize to other nodes
scp -r spark-2.4.5 node1:`pwd` scp -r spark-2.4.5 node2:`pwd`
5. Start and close
Start and stop the cluster master Medium execution cd /usr/local/soft/spark-2.4.5/sbin # start-up ./start-all.sh # close ./stop-all.sh
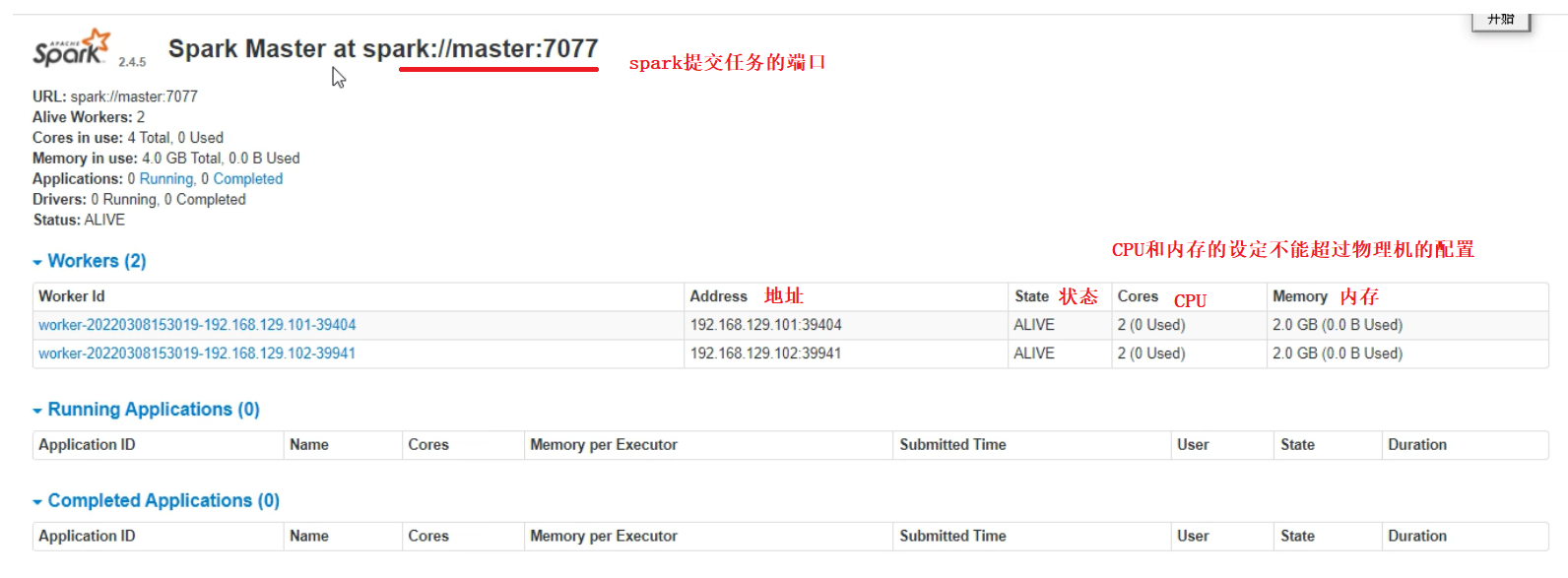
Accessing spark web interface
http://master:8080/
Two modes of Spark task submission
You need to enter spark examples_ 2.11-2.4.5. Execute in the directory where the jar package is located
spark-examples_2.11-2.4.5.jar -- an example officially provided by Spark to test whether Spark is successfully built
-
The standard client mode log is output locally and is generally used for pre online testing (executed under bin /)
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-examples_2.11-2.4.5.jar 100 spark-submit -- The submit command starts with this --class -- Specify class name org.apache.spark.examples.SparkPi -- Class name --master -- Specify operation mode spark://master:7077 -- specifies the port on which Spark submits tasks --executor-memory -- Specify task run resources --total-executor-cores -- Specify task run resources spark-examples_2.11-2.4.5.jar -- appoint jar package 100 -- afferent main()Parameters, here main()It is in the class specified above
-
The standalone cluster mode is used online, and the log will not be printed locally
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512M --total-executor-cores 1 --deploy-mode cluster spark-examples_2.11-2.4.5.jar 100 --deploy-mode -- Specify deployment mode cluster -- Cluster mode Can pass web View the running results in the interface
How to submit your own code to Spark and run it?
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo20Submit {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
/**
* Submit the code to the cluster for operation without specifying the master (operation mode)
* Specified in the submit command of spark
*/
//conf.setMaster("local")
conf.setAppName("Demo20Submit")
val sc = new SparkContext(conf)
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9))
val sum: Double = listRDD.sum()
println(s"sum is:$sum")
/**
* Submit the code to the cluster for running
* 1,Package and upload the project to the cluster
* 2,spark-submit --class com.shujia.spark.Demo20Submit --master spark://master:7077 spark-1.0.jar
* You need to submit the task at the location where the jar is located
* Note: when running, if an error is reported, say spark-1.0 If the jar cannot be found in the worker, you need to add spark-1.0 Distribute jar to node1 and node2
* scp spark-1.0.jar node1:`pwd`
* scp spark-1.0.jar node2:`pwd`
*/
}
}
yarn -- run on yarn
The standalone model is generally not applicable in the company, because the company generally has yarn and does not need to develop two resource management frameworks
Integrate yarn (build an environment where spark runs on yarn)
1. Stop building an independent Spark cluster
Stop the cluster in master Medium execution cd /usr/local/soft/spark-2.4.5/sbin # close ./stop-all.sh
2. Spark integration yarn only needs to integrate in one node, and all spark files in node1 and node2 can be deleted
3. Modify profile
Note: if the above Spark Standalone - independent cluster mode is not set up, you need to upload and decompress and configure environment variables
The modifications made to the configuration file during the independent cluster built above can be deleted or ignored
cd /usr/local/soft/spark-2.4.5/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
#Add configuration -- spark env SH file
export HADOOP_CONF_DIR=/usr/local/soft/hadoop-2.7.6/etc/hadoop
#Because Spark needs to get the configuration information of hadoop
-------------------------------------------------------------------------
to yarn Two configurations need to be added to submit the task yarn-site.xml (/usr/local/soft/hadoop-2.7.6/etc/hadoop/yarn-site.xml)
Close first yarn
stop-yarn.sh
# Add -- yarn site XML file
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
4,yarn-site. Synchronize XML to other nodes and restart yarn
scp -r yarn-site.xml node1:`pwd` scp -r yarn-site.xml node2:`pwd` start-up yarn start-yarn.sh
Then you can run the spark task through yarn
Run org.com on yarn apache. spark. examples. SparkPi
Submit on master
First switch to the cd /usr/local/soft/spark-2.4.5/examples/jars directory
Local -- where the task is submitted, it is local
-
The spark on yarn client mode log is output locally and is generally used for pre online testing
spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --executor-memory 512M --num-executors 2 spark-examples_2.11-2.4.5.jar 100
-
spark on yarn cluster mode is used online, and detailed logs will not be printed locally to reduce io
spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster --executor-memory 512m --num-executors 2 --executor-cores 1 spark-examples_2.11-2.4.5.jar 100
View run log
spark on yarn cluster mode does not print logs and results
obtain yarn The program execution log can only be obtained after successful execution yarn logs -applicationId application_1560967444524_0003 application_1560967444524_0003 -- Program running id
How to submit the spark code written by yourself to yarn and run it?
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo21ClazzNum {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
/**
* Submit the code to the cluster for operation without specifying the master (operation mode)
* Specified in the submit command of spark
*/
//conf.setMaster("local")
conf.setAppName("Demo21ClazzNum")
val sc = new SparkContext(conf)
/**
* Read files in hdfs
* The premise is that there must be data files in the directory of HDFS
*/
val studentsRDD: RDD[String] = sc.textFile("/data/students.txt")
val kvRDD: RDD[(String, Int)] = studentsRDD.map(stu => {
val clazz: String = stu.split(",")(4)
(clazz, 1)
})
//Count the number of classes
val clazzNumRDD: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
//Organize data
val resultRDD: RDD[String] = clazzNumRDD.map {
case (clazz: String, num: Int) =>
s"$clazz\t$num"
}
//Save the data to hdfs and specify the output directory
resultRDD.saveAsTextFile("/data/clazz_num")
/**
* Submit the code to yarn and run it
* 1,Upload the files to be processed to hdfs
* 2,Package and upload the project to the cluster
* 3,Submit task
* spark-submit --class com.shujia.spark.Demo21ClazzNum --master yarn-client spark-1.0.jar
* 4,View results
* hadoop dfs -ls /data
*/
}
}