What is RDDs
The full English name is Resilient Distributed Datasets, which translates elastic distributed datasets
The Spark The Definitive Guide describes as follows: RDD represents an immutable, partitioned collection of records that can be operated on in parallel. In my personal understanding, rdd is a kind of distributed object collection, in which each record is an object, and we can perform distributed operations on these objects.
1.RDDs type
For users, we only need to focus on two types of RDDs, generic RDD and key value RDD.
Characterization of five aspects of RDD
1.A list of Paritions
2.A function for cumputing each split
3.A list of dependencies on other RDDs
4. For RDD S of key value type, partition can be selected. Personal understanding is to define hash rules
5.
2.RDD creation
1. Convert dataframe to RDD, and the RDD of Row type will be obtained
spark.range(10).rdd
spark.range(10).toDF("id").rdd.map(lambda row:row[0])
# Convert rdd to dataframe
spark.range(10).rdd.toDF("id")
If you want to implement other types, you can use flatMap:
df.select("").rdd.flatMap(lambda x:x)
Through flatMap operation, rdd basic elements can be transformed into a list like format
dataframe:
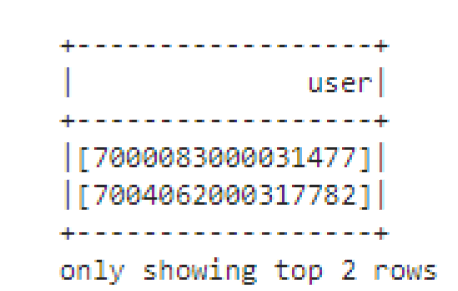
Output:

2. Create rdd based on local variables
myCollection = "Spark The Definitive Guide : Big Data Processing Made Simple"\
.split(" ")
words = spark.sparkContext.parallelize(myCollection, 2) # Two partition s are artificially divided here
# name rdd to show up in the Spark UI according to a given name
words.setName("mywords")
words.name
# Show mywords
3. Based on data source
# Read text file line by line
spark.sparkContext.textFile("/some/textFiles")
3. General operation of some RDD S
3.1 Tranformations
# filter
def startsWithS(individual):
return individual.startswith("S")
rds.filter(lambda word: startsWithsS(word)).collect()
Map
Map is a data conversion based on element granularity: given the mapping function f, map(f) converts RDD data based on element granularity. F can be a named function with an explicit signature or an anonymous function. It must be noted that its formal parameter type must be consistent with the element type of RDD, and the output type is left to the discretion of the developer
# Anonymous function implementation # The output of this example is word, and the output is a tuple(word, the first element of word, whether word starts with S) rds.map(lambda word:(word, word[0], word.startsWithS(word))) # Named function
3.2 actions
spark rdd is still a mechanism to maintain lazy execution. The actions method allows spark programs to perform operations such as output
# reduce spark.sparkContext.parallelize(range(1, 21)).reduce(lambda x,y:x+y) # 210 def wordLengthReducer(leftWord, rightWord): if len(leftWord) > len(rightWord): return leftWord else: return rightWord words.reduce(wordLengthReducer)
rdd gradually reads to the driver side
#toLocalIterator
for tmp in rdd.toLocalIterator():
some_operator(tmp)
3.3 checkpointing
Save the rrd to the hard disk, and then the operations that depend on the rdd can be directly on the hard disk instead of tracing back to the original data source of the rdd. The checkpoint here is a bit like caching in the hard disk.
spark.sparkContext.setCheckpointDir("/some/path/for/checkpointing")
words.checkpoint()
3.4 pipe
Through the pipe method, we can use system commands to operate rdd.
Where RDD is input according to partitions, and each line of each partition is separated by a newline character.
Pipe is the underlying function of the implementation, and other methods are based on pipe.
# pipe
words.pipe("wc -l").collect()
# mapPartitions
# Define the program with partition as a parameter
words.mapPartitions(lambda part: [1]).sum() # 2
# mapPartitionsWithIndex
# The index of the partition and the partition Iterator can be used as parameters for program definition
def indexedFunc(partitionIndex, withinPartIterator):
return ["partition: {} => {}".format(partitionIndex,
x) for x in withinPartIterator]
words.mapPartitionsWithIndex(indexedFunc).collect()
Mind map
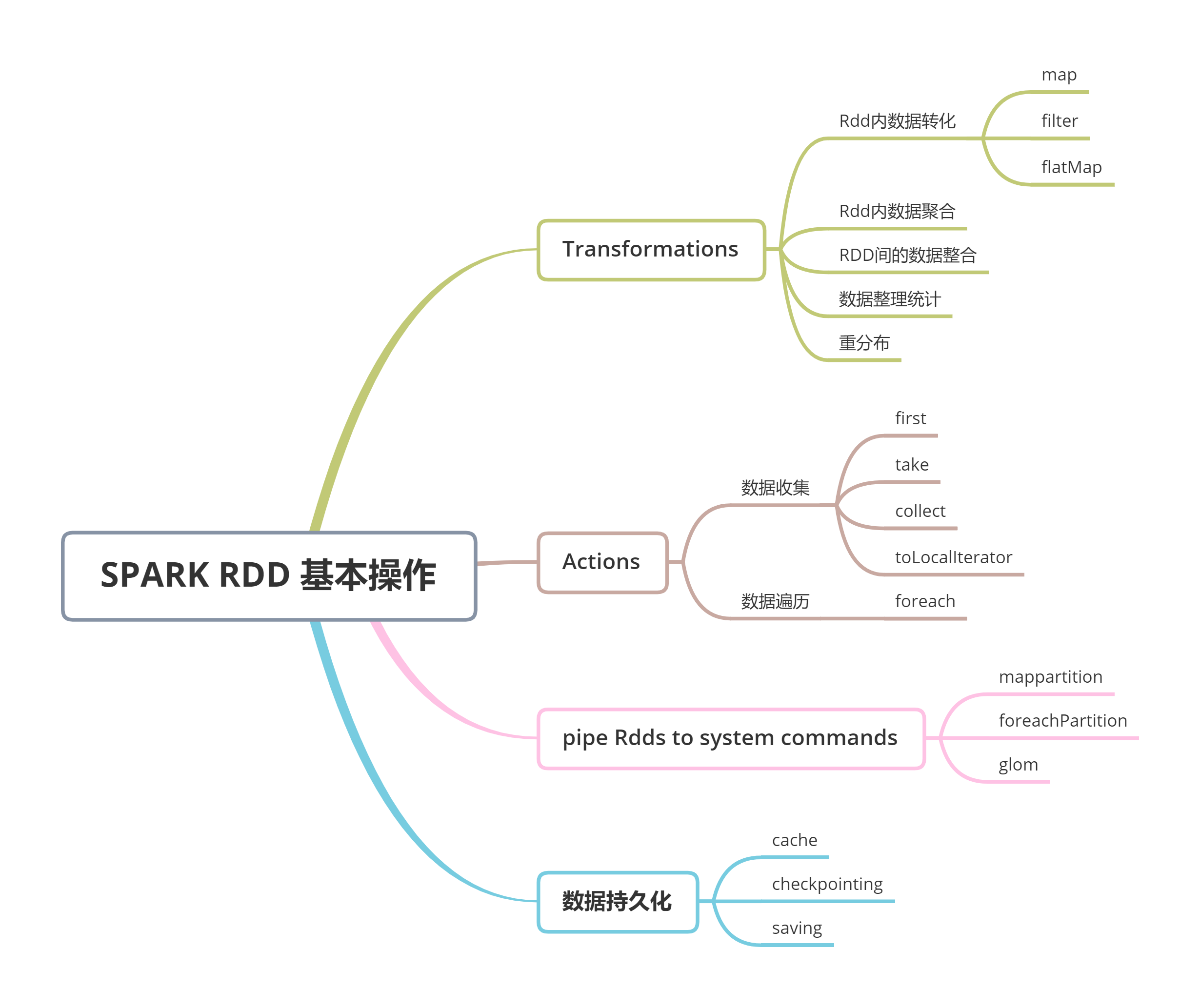
Reference: