By default, if an external variable is used in an operator function, the value of this variable will be copied to each task. At this time, each task can only operate its own copy of the variable. If multiple tasks want to share a variable, this method cannot be done.
Spark provides two shared variables for this purpose:
- One is broadcast variable
- The other is accumulator
Broadcast Variable
Broadcast Variable will copy only one copy of the variables used for each node, not for each task. Therefore, its greatest function is to reduce the network transmission consumption of variables to each node and the memory consumption on each node
Create a broadcast variable for a variable by calling the broadcast() method of SparkContext
Note: Broadcast variables are read-only
Then, when the broadcast variable is used in the operator function, each node will only copy one copy. You can use the value() method of the broadcast variable to get the value.
Next, let's take a look at a figure and have a deep understanding
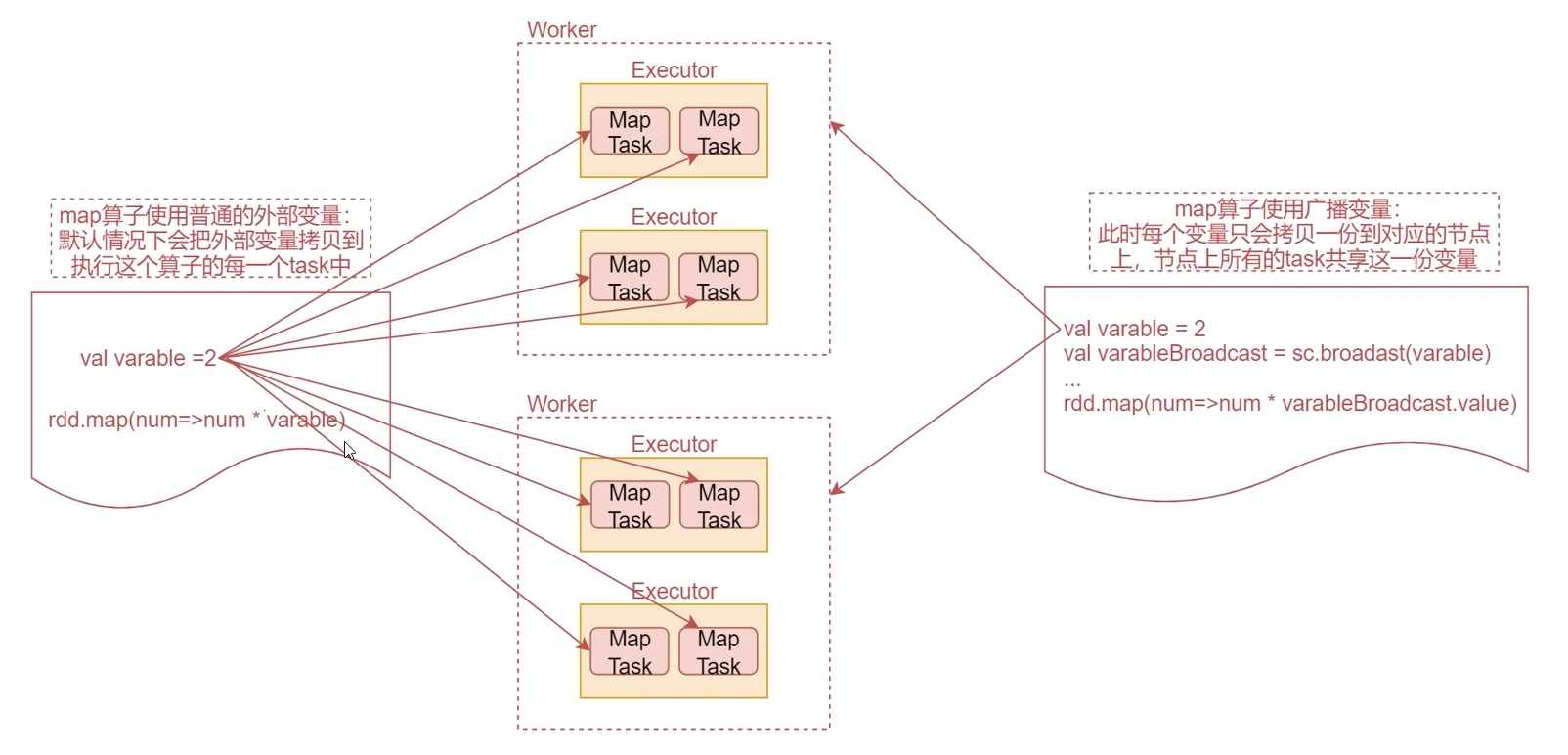
First look at the code on the left
This is the code of a map operator we often use. The map operator performs the operation of multiplying each element by a fixed variable. At this time, the fixed variable belongs to an external variable.
By default, the external variables used in the operator function will be copied to each task executing the operator
Look at the MapTask in the middle of the figure. These are tasks generated by the map operator, that is, the external variable will be copied to each task.
If the external variable is a collection with hundreds of millions of data, the network transmission will be very time-consuming, and each task will occupy a lot of memory space
If the external variable used in the operator function is a broadcast variable, only one copy of each variable will be copied to each node. All task s on the node will share this variable, which can reduce the time consumed by network transmission and memory occupation.
You can imagine an extreme case. If the map operator has 10 task s, which happen to be on a worker node, then the external variables used by the map operator will save 10 copies on the worker node, which will occupy a lot of memory.
Let's use this broadcast variable
Scala version
import org.apache.spark.{SparkConf, SparkContext}
object BoradcastOpScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("BoradcastOpScala")
.setMaster("local")
val sc = new SparkContext(conf)
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
val varable = 2
//dataRDD.map(_ * varable)
//1: Define broadcast variables
val varableBroadcast = sc.broadcast(varable)
//2: Use the broadcast variable and call its value method
dataRDD.map(_ * varableBroadcast.value).foreach(println(_))
sc.stop()
}
}
Java version
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.broadcast.Broadcast;
import java.util.Arrays;
public class BroadcastOpJava {
public static void main(String[] args) {
//Create JavaSparkContext
SparkConf conf = new SparkConf();
conf.setAppName("BroadcastOpJava")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
int varable = 2;
//1: Define broadcast variables
Broadcast<Integer> varableBroadcast = sc.broadcast(varable);
//2: Using broadcast variables
dataRDD.map(new Function<Integer, Integer>() {
@Override
public Integer call(Integer i1) throws Exception {
return i1 * varableBroadcast.value();
}
}).foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer i) throws Exception {
System.out.println(i);
}
});
sc.stop();
}
}
Accumulator
The Accumulator provided by Spark is mainly used for shared operation of multiple nodes on a variable.
Under normal circumstances, in Spark tasks, because an operator may generate multiple tasks to be executed in parallel, the aggregation calculation performed inside the operator is local. To realize global aggregation calculation for multiple tasks, you need to use the shared accumulation variable Accumulator.
Note: the Accumulator only provides the function of accumulation. In task, you can only accumulate the Accumulator and cannot read its value. The Accumulator value can only be read in the Driver process.
Let's write a case
Scala version
import org.apache.spark.{SparkConf, SparkContext}
object AccumulatorOpScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("AccumulatorOpScala")
.setMaster("local")
val sc = new SparkContext(conf)
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
//Therefore, to realize the accumulation operation, you need to use the accumulation variable
//1: Define cumulative variables
val sumAccumulator = sc.longAccumulator
//2: Use cumulative variables
dataRDD.foreach(num=>sumAccumulator.add(num))
//Note: the result of accumulating variables can only be obtained in the Driver process
println(sumAccumulator.value)
sc.stop()
}
}
Java version
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.util.LongAccumulator;
import java.util.Arrays;
public class AccumulatorOpJava {
public static void main(String[] args) {
//Create JavaSparkContext
SparkConf conf = new SparkConf();
conf.setAppName("AccumulatorOpJava")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
//1: Define cumulative variables
LongAccumulator sumAccumulator = sc.sc().longAccumulator();
//2: Use cumulative variables
dataRDD.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer i) throws Exception {
sumAccumulator.add(i);
}
});
//Gets the value of the cumulative variable
System.out.println(sumAccumulator.value());
sc.stop();
}
}