Spark supports the use of spark shell, spark SQL and spark submit, but the final calling code is submitted through spark submit. The example of spark submit introduced in the previous article:
# spark local mode submit job ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local /path/to/examples.jar \ 1000
Let's analyze the whole process of spark submit.
1. Spark submit script analysis
Spark submit script uses spark class to call SparkSubmit as the main class of the program:
#spark-submit.sh
#!/usr/bin/env bash
#Judge whether to configure the ${SPARK_HOME} variable. If not, execute the find spark home script to set it
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
# Call the SparkSubmit class with all parameters
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
Spark submit the spark before submitting the job_ Determine the home variable. If it is not set, the find spark home script will be called to configure it according to the current spark package directory.
# find-spark-home.sh
#!/usr/bin/env bash
# Attempts to find a proper value for SPARK_HOME. Should be included using "source" directive.
FIND_SPARK_HOME_PYTHON_SCRIPT="$(cd "$(dirname "$0")"; pwd)/find_spark_home.py"
# Short circuit if the user already has this set.
if [ ! -z "${SPARK_HOME}" ]; then
exit 0
elif [ ! -f "$FIND_SPARK_HOME_PYTHON_SCRIPT" ]; then
# If we are not in the same directory as find_spark_home.py we are not pip installed so we don't
# need to search the different Python directories for a Spark installation.
# Note only that, if the user has pip installed PySpark but is directly calling pyspark-shell or
# spark-submit in another directory we want to use that version of PySpark rather than the
# pip installed version of PySpark.
export SPARK_HOME="$(cd "$(dirname "$0")"/..; pwd)"
else
# We are pip installed, use the Python script to resolve a reasonable SPARK_HOME
# Default to standard python interpreter unless told otherwise
if [[ -z "$PYSPARK_DRIVER_PYTHON" ]]; then
PYSPARK_DRIVER_PYTHON="${PYSPARK_PYTHON:-"python"}"
fi
export SPARK_HOME=$($PYSPARK_DRIVER_PYTHON "$FIND_SPARK_HOME_PYTHON_SCRIPT")
fi
Then, calling spark-class to construct the job submission command is eventually submitted in java mode.
#!/usr/bin/env bash
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# Use load spark env SH script loads environment variables and sets logs, hadoop configuration, JVM, classpath, etc
. "${SPARK_HOME}"/bin/load-spark-env.sh
# Get the java path. If java is not configured_ Home, it is obtained through the java command, otherwise an error is reported
if [ -n "${JAVA_HOME}" ]; then
RUNNER="${JAVA_HOME}/bin/java"
else
if [ "$(command -v java)" ]; then
RUNNER="java"
else
echo "JAVA_HOME is not set" >&2
exit 1
fi
fi
# Set SPARK_JARS_DIR, if Park_ If the jars directory does not exist in home, set it to the assembly directory
if [ -d "${SPARK_HOME}/jars" ]; then
SPARK_JARS_DIR="${SPARK_HOME}/jars"
else
SPARK_JARS_DIR="${SPARK_HOME}/assembly/target/scala-$SPARK_SCALA_VERSION/jars"
fi
#If SPARK_JARS_DIR Directory does not exist and is not set SPARK_TESTING or SPARK_SQL_TESTING Error reporting. If it exists, then#Setup starts LAUNCH_CLASSPATH
if [ ! -d "$SPARK_JARS_DIR" ] && [ -z "$SPARK_TESTING$SPARK_SQL_TESTING" ]; then
echo "Failed to find Spark jars directory ($SPARK_JARS_DIR)." 1>&2
echo "You need to build Spark with the target \"package\" before running this program." 1>&2
exit 1
else
LAUNCH_CLASSPATH="$SPARK_JARS_DIR/*"
fi
# Add the launcher build dir to the classpath if requested.
if [ -n "$SPARK_PREPEND_CLASSES" ]; then
LAUNCH_CLASSPATH="${SPARK_HOME}/launcher/target/scala-$SPARK_SCALA_VERSION/classes:$LAUNCH_CLASSPATH"
fi
# For tests
if [[ -n "$SPARK_TESTING" ]]; then
unset YARN_CONF_DIR
unset HADOOP_CONF_DIR
fi
# The launcher library will print arguments separated by a NULL character, to allow arguments with
# characters that would be otherwise interpreted by the shell. Read that in a while loop, populating
# an array that will be used to exec the final command.
#
# The exit code of the launcher is appended to the output, so the parent shell removes it from the
# command array and checks the value to see if the launcher succeeded.
# Construct java startup command and load launch_ Add the jar package under classpath, and use org apache. spark. launcher. Main is the main class and carries the parameters in spark submit
build_command() {
"$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@"
printf "%d\0" $?
}
# Turn off posix mode because it does not allow process substitution
set +o posix
CMD=()
while IFS= read -d '' -r ARG; do
CMD+=("$ARG")
done < <(build_command "$@")
COUNT=${#CMD[@]}
LAST=$((COUNT - 1))
LAUNCHER_EXIT_CODE=${CMD[$LAST]}
# Some JVM failures can cause errors to be printed to stdout (instead of stderr), which can cause confusion in the code that parses the initiator output. In these cases, check whether the exit code is an integer, and if not, treat it as a special error case.
if ! [[ $LAUNCHER_EXIT_CODE =~ ^[0-9]+$ ]]; then
echo "${CMD[@]}" | head -n-1 1>&2
exit 1
fi
if [ $LAUNCHER_EXIT_CODE != 0 ]; then
exit $LAUNCHER_EXIT_CODE
fi
CMD=("${CMD[@]:0:$LAST}")
# The final constructed submission command is: env LD_LIBRARY_PATH=/usr/hdp/current/hadoop-client/lib/native:/usr/hdp/current/hadoop-client/lib/native/Linux-amd64-64 /usr/local/jdk/bin/java -cp /usr/hdp/current/spark2-client/conf/:/usr/hdp/current/spark2-client/jars/*:/usr/hdp/current/spark2-client/jars/../hive/*:/usr/hdp/3.0.1.0-187/hadoop/conf/:/usr/hdp/current/spark2-thriftserver/jars/ranger-spark-plugin-impl/*:/usr/hdp/current/spark2-thriftserver/jars/servlet-api/*:/usr/hdp/3.0.1.0-187/spark2/jars/dragon_jars/* -Xmx1g -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5055 org.apache.spark.deploy.SparkSubmit --master local --conf spark.driver.extraJavaOptions=-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5055 --class org.apache.spark.examples.SparkPi spark-examples_2.11-2.4.0-cdh6.2.0.jar
exec "${CMD[@]}"
2. SparkSubmit calling process
After the job is submitted, org.org is finally called apache. Spark. deploy. SparkSubmit is the main class. Through debugging, you can also see that the Spark program entry is the main method of SparkSubmit: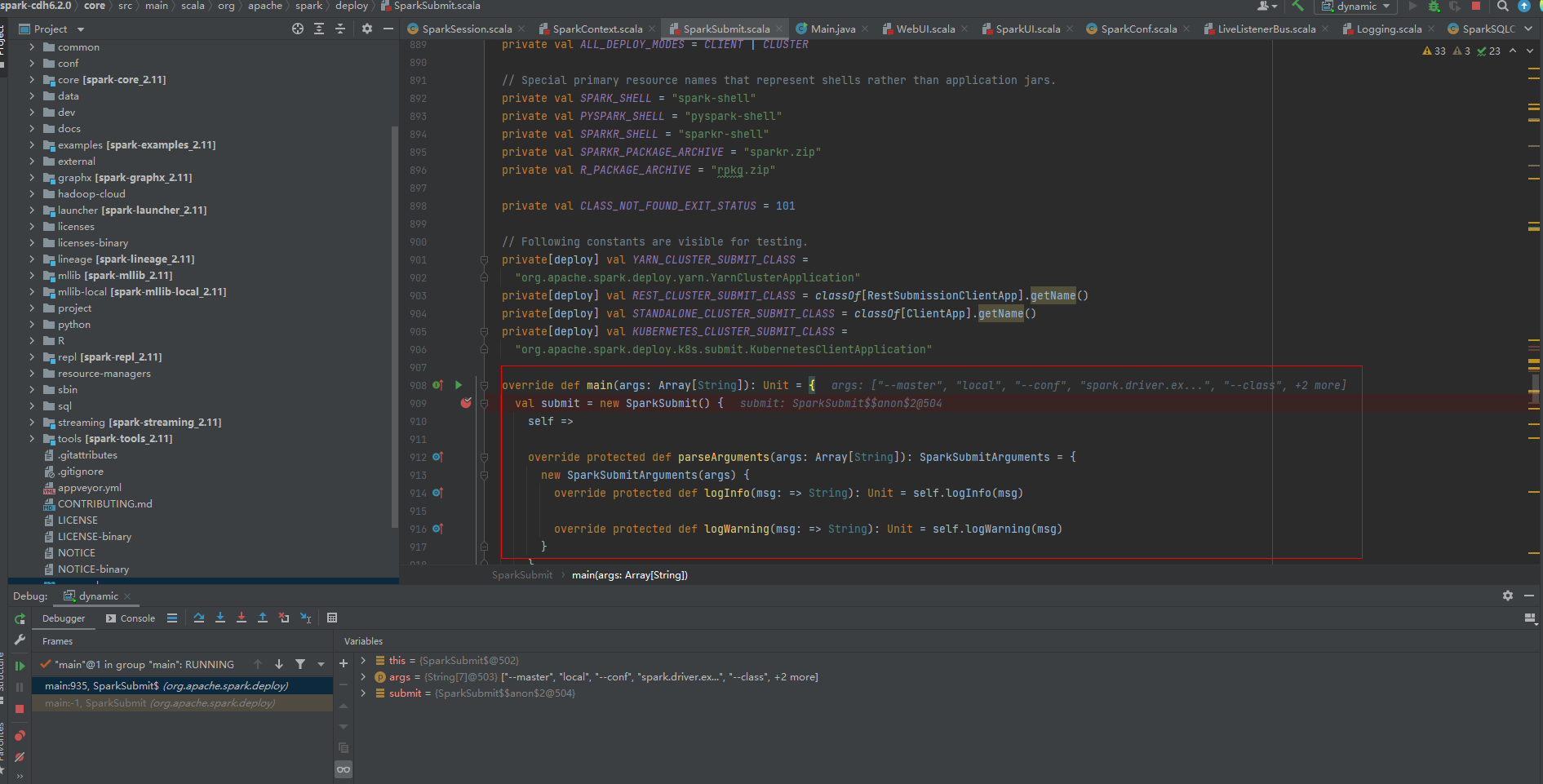
After entering the main method, the call constructs the SparkSubmit object, calls the doSubmit method, and internally calls loadEnvironmentArguments to construct the parameter in the environment variable to the SparkSubmitArguments object, carries master, driverMemory, executorMemory and other information:
def doSubmit(args: Array[String]): Unit = {
// Initialize logging before submitting and track whether logging needs to be reset before the application starts. Log4j defaults is used by default Properties file log configuration.
val uninitLog = initializeLogIfNecessary(true, silent = true)
// The parsing parameters are constructed as SparkSubmitArguments object, and loadEnvironmentArguments is called internally to parse the master, driverMemory, executorMemory and other running parameters
val appArgs = parseArguments(args)
if (appArgs.verbose) {
logInfo(appArgs.toString)
}
// Perform specific operations according to different operation types. Spark submit supports several parameter types -- kill, -- status, -- status, among which -- kill, -- status are used in standalone mode to kill spark jobs and query status
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
case SparkSubmitAction.PRINT_VERSION => printVersion()
}
}
// Load environment variable parameters, which can be carried through the spark summit command, or in spark default Conf configuration file, and the corresponding parameter name is shown in the following code
private def loadEnvironmentArguments(): Unit = {
master = Option(master)
.orElse(sparkProperties.get("spark.master"))
.orElse(env.get("MASTER"))
.orNull
driverExtraClassPath = Option(driverExtraClassPath)
.orElse(sparkProperties.get("spark.driver.extraClassPath"))
.orNull
driverExtraJavaOptions = Option(driverExtraJavaOptions)
.orElse(sparkProperties.get("spark.driver.extraJavaOptions"))
.orNull
driverExtraLibraryPath = Option(driverExtraLibraryPath)
.orElse(sparkProperties.get("spark.driver.extraLibraryPath"))
.orNull
driverMemory = Option(driverMemory)
.orElse(sparkProperties.get("spark.driver.memory"))
.orElse(env.get("SPARK_DRIVER_MEMORY"))
.orNull
driverCores = Option(driverCores)
.orElse(sparkProperties.get("spark.driver.cores"))
.orNull
executorMemory = Option(executorMemory)
.orElse(sparkProperties.get("spark.executor.memory"))
.orElse(env.get("SPARK_EXECUTOR_MEMORY"))
.orNull
executorCores = Option(executorCores)
.orElse(sparkProperties.get("spark.executor.cores"))
.orElse(env.get("SPARK_EXECUTOR_CORES"))
.orNull
totalExecutorCores = Option(totalExecutorCores)
.orElse(sparkProperties.get("spark.cores.max"))
.orNull
name = Option(name).orElse(sparkProperties.get("spark.app.name")).orNull
jars = Option(jars).orElse(sparkProperties.get("spark.jars")).orNull
files = Option(files).orElse(sparkProperties.get("spark.files")).orNull
pyFiles = Option(pyFiles).orElse(sparkProperties.get("spark.submit.pyFiles")).orNull
ivyRepoPath = sparkProperties.get("spark.jars.ivy").orNull
ivySettingsPath = sparkProperties.get("spark.jars.ivySettings")
packages = Option(packages).orElse(sparkProperties.get("spark.jars.packages")).orNull
packagesExclusions = Option(packagesExclusions)
.orElse(sparkProperties.get("spark.jars.excludes")).orNull
repositories = Option(repositories)
.orElse(sparkProperties.get("spark.jars.repositories")).orNull
deployMode = Option(deployMode)
.orElse(sparkProperties.get("spark.submit.deployMode"))
.orElse(env.get("DEPLOY_MODE"))
.orNull
numExecutors = Option(numExecutors)
.getOrElse(sparkProperties.get("spark.executor.instances").orNull)
queue = Option(queue).orElse(sparkProperties.get("spark.yarn.queue")).orNull
keytab = Option(keytab).orElse(sparkProperties.get("spark.yarn.keytab")).orNull
principal = Option(principal).orElse(sparkProperties.get("spark.yarn.principal")).orNull
dynamicAllocationEnabled =
sparkProperties.get("spark.dynamicAllocation.enabled").exists("true".equalsIgnoreCase)
// Try to set main class from JAR if no --class argument is given
if (mainClass == null && !isPython && !isR && primaryResource != null) {
val uri = new URI(primaryResource)
val uriScheme = uri.getScheme()
uriScheme match {
case "file" =>
try {
Utils.tryWithResource(new JarFile(uri.getPath)) { jar =>
// Note that this might still return null if no main-class is set; we catch that later
mainClass = jar.getManifest.getMainAttributes.getValue("Main-Class")
}
} catch {
case _: Exception =>
error(s"Cannot load main class from JAR $primaryResource")
}
case _ =>
error(
s"Cannot load main class from JAR $primaryResource with URI $uriScheme. " +
"Please specify a class through --class.")
}
}
// Global defaults. These should be keep to minimum to avoid confusing behavior.
master = Option(master).getOrElse("local[*]")
// In YARN mode, app name can be set via SPARK_YARN_APP_NAME (see SPARK-5222)
if (master.startsWith("yarn")) {
name = Option(name).orElse(env.get("SPARK_YARN_APP_NAME")).orNull
}
// Set name from main class if not given
name = Option(name).orElse(Option(mainClass)).orNull
if (name == null && primaryResource != null) {
name = new File(primaryResource).getName()
}
// Action should be SUBMIT unless otherwise specified
action = Option(action).getOrElse(SUBMIT)The submit method parses the environment variables, gets the class name, parameters and classpath information of the concrete execution class, then calls the runMain method to adjust the specific execution class through the reflection mechanism.
private def submit(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
// The first step is to prepare the startup environment by setting the appropriate classpath, system properties, and application parameters to run the sub main classes based on the cluster manager and deployment mode.
val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
// Use this startup environment to call the main method of the child main class
def doRunMain(): Unit = {
if (args.proxyUser != null) {
// When submitting a job, if -- proxy user is used to set the proxy user, the proxy user will be used to run the job
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose)
}
})
} catch {
case e: Exception =>
// Hadoop's AuthorizationException suppresses the exception's stack trace, which
// makes the message printed to the output by the JVM not very helpful. Instead,
// detect exceptions with empty stack traces here, and treat them differently.
if (e.getStackTrace().length == 0) {
error(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}")
} else {
throw e
}
}
} else {
runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose)
}
} private def runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sparkConf: SparkConf,
childMainClass: String,
verbose: Boolean): Unit = {
// Print out detailed class name, parameters, classpath, default configuration information, etc. in verbose mode
if (verbose) {
logInfo(s"Main class:\n$childMainClass")
logInfo(s"Arguments:\n${childArgs.mkString("\n")}")
// sysProps may contain sensitive information, so redact before printing
logInfo(s"Spark config:\n${Utils.redact(sparkConf.getAll.toMap).mkString("\n")}")
logInfo(s"Classpath elements:\n${childClasspath.mkString("\n")}")
logInfo("\n")
}
// Judgment parameter spark driver. Whether userclasspathfirst is set. The default value is false. When set to true, a variable class loader ChildFirstURLClassLoader is constructed. When loading classes and resources, it takes precedence over the parent class loader to provide its own URL.
val loader =
if (sparkConf.get(DRIVER_USER_CLASS_PATH_FIRST)) {
new ChildFirstURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
} else {
new MutableURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
}
Thread.currentThread.setContextClassLoader(loader)
//Load the jar package under childClasspath
for (jar <- childClasspath) {
addJarToClasspath(jar, loader)
}
var mainClass: Class[_] = null
try {
mainClass = Utils.classForName(childMainClass)
} catch {
case e: ClassNotFoundException =>
logWarning(s"Failed to load $childMainClass.", e)
if (childMainClass.contains("thriftserver")) {
logInfo(s"Failed to load main class $childMainClass.")
logInfo("You need to build Spark with -Phive and -Phive-thriftserver.")
}
throw new SparkUserAppException(CLASS_NOT_FOUND_EXIT_STATUS)
case e: NoClassDefFoundError =>
logWarning(s"Failed to load $childMainClass: ${e.getMessage()}")
if (e.getMessage.contains("org/apache/hadoop/hive")) {
logInfo(s"Failed to load hive class.")
logInfo("You need to build Spark with -Phive and -Phive-thriftserver.")
}
throw new SparkUserAppException(CLASS_NOT_FOUND_EXIT_STATUS)
}
// Judge whether the program main class is a subclass of SparkApplication. If not, it will be constructed as JavaMainApplication class. JavaMainApplication is also a subclass of SparkApplication, which is equivalent to making a layer of encapsulation and reflecting the mainclass through the start method of SparkApplication
val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.newInstance().asInstanceOf[SparkApplication]
} else {
// SPARK-4170
if (classOf[scala.App].isAssignableFrom(mainClass)) {
logWarning("Subclasses of scala.App may not work correctly. Use a main() method instead.")
}
new JavaMainApplication(mainClass)
}
@tailrec
def findCause(t: Throwable): Throwable = t match {
case e: UndeclaredThrowableException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: InvocationTargetException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: Throwable =>
e
}
try {
//Call the SparkApplicationstart method to make reflection calls. The following two lines reflect code
app.start(childArgs.toArray, sparkConf)
//val mainMethod = klass.getMethod("main", new Array[String](0).getClass)
//mainMethod.invoke(null, args)
} catch {
case t: Throwable =>
throw findCause(t)
}
}So far, the steps of submitting Spark Application program through spark submit are completed, and then the next step is to enter the specific application code. In this example, to realize the calculation of SparkPi, first construct SparkSession (build SparkContext internally), and then implement the specific algorithm through the transform and action operators provided by spark and submit it for execution.
object SparkPi {
def main(args: Array[String]) {
val spark = SparkSession
.builder
.appName("Spark Pi")
.getOrCreate()
val slices = if (args.length > 0) args(0).toInt else 2
val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow
val count = spark.sparkContext.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y <= 1) 1 else 0
}.reduce(_ + _)
println(s"Pi is roughly ${4.0 * count / (n - 1)}")
spark.stop()
}
}3. SparkSession structure
When developing Spark programs in earlier versions of Spark, sparkcontext is used as the entry. RDD is an important API in Spark, but its creation and operation must use the API provided by sparkcontext; For things other than RDD, we need to use other Context. For example, for stream processing, we have to use StreamingContext; SqlContext is used for SQL; For hive, use HiveContext. However, the APIs provided by DataSet and Dataframe are gradually called new standard APIs. We need a pointcut to build them. Therefore, a new entry point: SparkSession is introduced in Spark 2.0.
SparkSession is essentially a combination of SQLContext, HiveContext and StreamingContext, so the API s available on SQLContext and HiveContext can also be used on SparkSession. SparkSession encapsulates sparkContext internally, so the calculation is actually completed by sparkContext.
The design of SparkSession follows the factory design pattern. In the Spark program, the SparkSession.builder object is first used for a series of configurations, including appName (setting program name), master (running mode: local, yarn, standalone, etc.), enablehivesupport (enabling hive metadata, i.e. using HiveContext) Withextensions (inject custom extensions into [[SparkSession]]. This allows users to add analyzer rules, optimizer rules, planning policies or custom parsers). It also provides config method, setting custom parameters, etc.
The getOrCreate method initializes specific sparkcentertext (described in the next issue) and SparkSession objects:
def getOrCreate(): SparkSession = synchronized {
assertOnDriver()
// Get the Session object from the current Session thread. If it is still active, you only need to reload the next configuration
var session = activeThreadSession.get()
if ((session ne null) && !session.sparkContext.isStopped) {
options.foreach { case (k, v) => session.sessionState.conf.setConfString(k, v) }
if (options.nonEmpty) {
logWarning("Using an existing SparkSession; some configuration may not take effect.")
}
return session
}
// Locking ensures that the defaultsession is set only once
SparkSession.synchronized {
// If the current thread has no active session, get from the global session
session = defaultSession.get()
if ((session ne null) && !session.sparkContext.isStopped) {
options.foreach { case (k, v) => session.sessionState.conf.setConfString(k, v) }
if (options.nonEmpty) {
logWarning("Using an existing SparkSession; some configuration may not take effect.")
}
return session
}
// There are no active or global default sessions. Create a new This is created through sparkContext
val sparkContext = userSuppliedContext.getOrElse {
val sparkConf = new SparkConf()
options.foreach { case (k, v) => sparkConf.set(k, v) }
// set a random app name if not given.
if (!sparkConf.contains("spark.app.name")) {
sparkConf.setAppName(java.util.UUID.randomUUID().toString)
}
//When you create a sparkcontext object, you will eventually call new Context(SparkConf) for construction
SparkContext.getOrCreate(sparkConf)
// Do not update `SparkConf` for existing `SparkContext`, as it's shared by all sessions.
}
applyExtensions(
sparkContext.getConf.get(StaticSQLConf.SPARK_SESSION_EXTENSIONS).getOrElse(Seq.empty),
extensions)
session = new SparkSession(sparkContext, None, None, extensions)
options.foreach { case (k, v) => session.initialSessionOptions.put(k, v) }
setDefaultSession(session)
setActiveSession(session)
//Register the successfully instantiated context with singleton. This should be at the end of the class definition so that the singleton is updated only if there are no exceptions in the instance's construction.
sparkContext.addSparkListener(new SparkListener {
override def onApplicationEnd(applicationEnd: SparkListenerApplicationEnd): Unit = {
defaultSession.set(null)
}
})
}
return session
}
}