Spark Day03: Spark basic environment
02 - [understand] - outline of today's course content
It mainly explains two aspects: what is Spark on YARN cluster and RDD
1,Spark on YARN take Spark Application, submit run to YARN On the cluster, the vast majority of operation modes in enterprises must be mastered - How to configure - Submit application run - Spark There are two kinds of applications running on the cluster Deploy-Mode - yarn-client pattern - yarn-cluster pattern 2,RDD What is it? RDD,Elastic distributed data sets, abstract concepts, are equivalent to collections, such as lists List,Distributed collection, storing massive data introduce RDD data structure RDD Official definitions, from documentation and source code RDD 5 Big features (interview must ask) word frequency count WordCount see RDD What are there RDD Creation method, how to encapsulate data into RDD In the collection, there are 2 ways establish RDD How to deal with small files (interview)
03 - [Master] - attribute configuration and service startup of Spark on YARN
It is very important to submit spark applications to run on the YARN cluster. Most enterprises run on YANR file: http://spark.apache.org/docs/2.4.5/running-on-yarn.html
When the Spark Application runs on yarn, you can specify the master as yarn when submitting the application. At the same time, you need to inform yarn of cluster configuration information (such as ResourceManager address information). In addition, you need to monitor the Spark Application and configure the relevant properties of the history server.

In the actual project, you only need to configure: 6.1.1 to 6.1.4. Since it is tested on the virtual machine, configure 6.1.5 to remove the resource check restriction.
04 - [Master] - Spark on YARN submission application
First submit PI program and run it on YARN. The command is as follows:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \
10The screenshot of YARN monitoring page after operation is completed is as follows
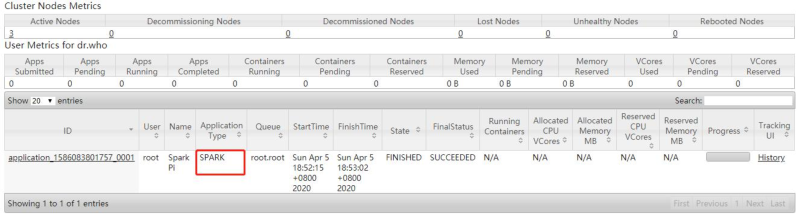
Set the resource information, submit and run the WordCount program to YARN, and the command is as follows:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 2 \
--queue default \
--class cn.itcast.spark.submit.SparkSubmit \
hdfs://node1.itcast.cn:8020/spark/apps/spark-day02_2.11-1.0.0.jar \
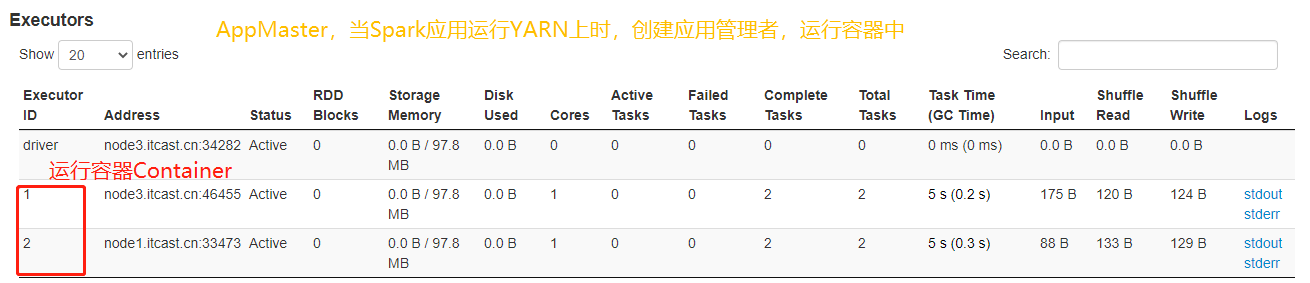
/datas/wordcount.data /datas/swcy-outputWhen the WordCount application runs on YARN, click the application history service connection from the 8080 WEB UI page to view the application running status information.
05 - [Master] - DeployMode differences between the two modes
Spark Application submission runtime deployment mode deployment mode refers to the place where the Driver Program runs, either the client: client submitting the application, or the slave node (Standalone: Worker, YARN: NodeManager): cluster in the cluster.

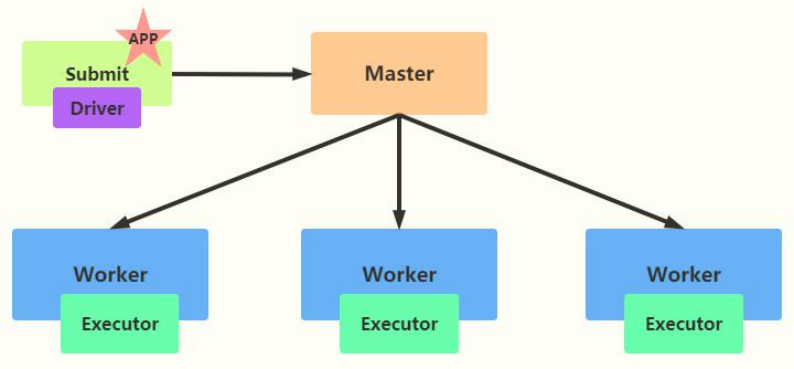
- client mode
The default DeployMode is Client, which means that the application Driver Program runs on the Client host that submits the application (starts the JVM Process). The diagram is as follows:
Assuming that PI program is run and client mode is adopted, the command is as follows:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master spark://node1.itcast.cn:7077,node2.itcast.cn:7077 \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--total-executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \
10- cluster mode
If the application is run in cluster mode, the application Driver Program runs on a machine of the cluster slave node Worker.
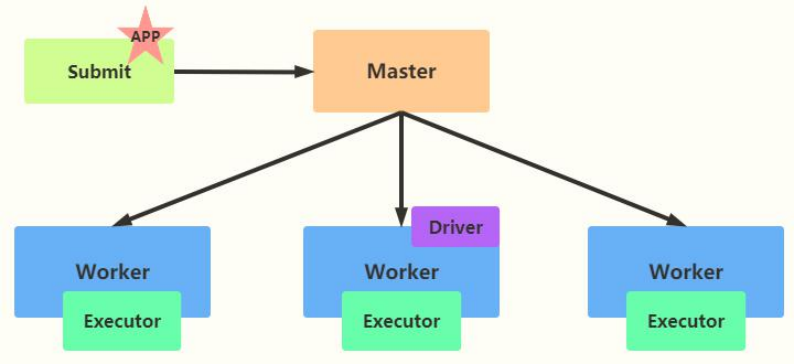
Assuming that PI program is run and cluster mode is adopted, the command is as follows:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master spark://node1.itcast.cn:7077,node2.itcast.cn:7077 \
--deploy-mode cluster \
--supervise \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--total-executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \
1006 - [Master] - YARN Client mode of Spark on YARN
When the application runs on YARN, it consists of two parts:
- AppMaster, the application manager, applies for resources and schedules Job execution
- Process, process running on NodeManager, Task running
When the Spark application runs on the cluster, it also has two parts:
- Driver Program, the application manager, applies for resources, runs Executors and schedules Job execution
- Executors, which runs the JVM process, which executes Task tasks and caches data
When the Spark application runs on the YARN cluster, what is the running architecture like????
- YARN Client mode
When Spark runs in YARN cluster and client DeployMode is adopted, there are three processes as follows:
- AppMaster, request resources, run Executors
- Driver Program, scheduling Job execution and monitoring
- Executors, which runs the JVM process, which executes Task tasks and caches data
- YARN Cluster mode
When Spark runs in a YARN cluster and adopts clusterDeployMode, there are two processes as follows:
- The Driver Program (AppMaster) performs both resource application and Job scheduling
- Executors, which runs the JVM process, which executes Task tasks and caches data
Therefore, when Spark Application runs on YARN, the architecture is different when different deployment modes are adopted. The actual production environment of the enterprise is still dominated by cluster mode, and the client mode is used for development and testing. The difference between the two is often asked in interviews.
In the YARN Client mode, the Driver runs on the local machine where the task is submitted. The schematic diagram is as follows:
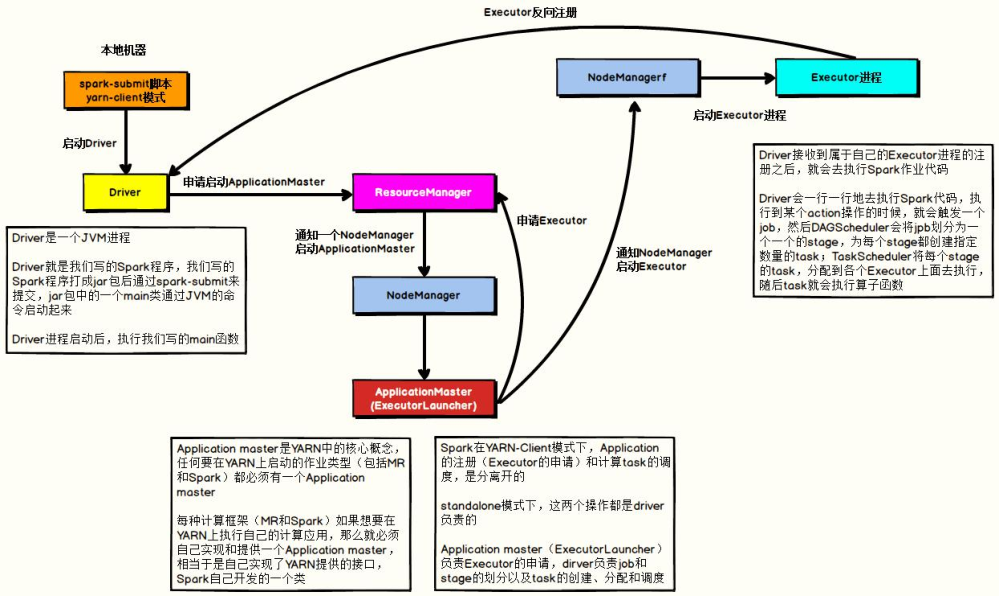
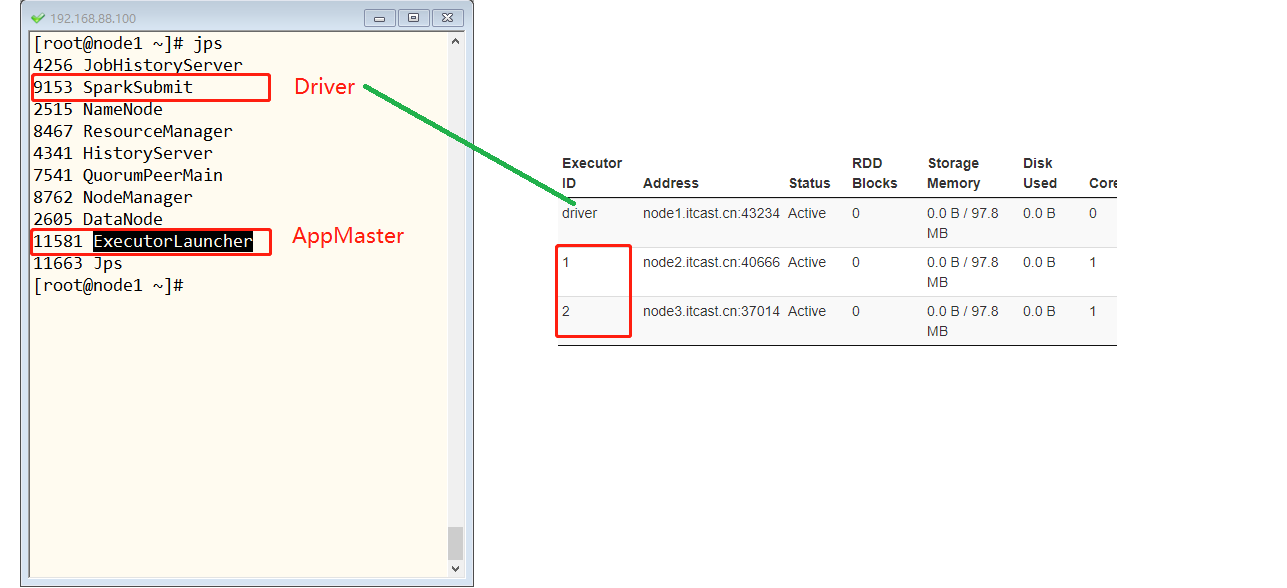
Run the WordCount program of word frequency statistics in Yan client mode
/export/server/spark/bin/spark-submit \ --master yarn \ --deploy-mode client \ --driver-memory 512m \ --executor-memory 512m \ --executor-cores 1 \ --num-executors 2 \ --queue default \ --class cn.itcast.spark.submit.SparkSubmit \ hdfs://node1.itcast.cn:8020/spark/apps/spark-day02_2.11-1.0.0.jar \ /datas/wordcount.data /datas/swcy-client
07 - [Master] - YARN Cluster mode of Spark on YARN
In the YARN Cluster mode, the Driver runs in the nodemanager container. At this time, the Driver is integrated with the AppMaster. The schematic diagram is as follows:
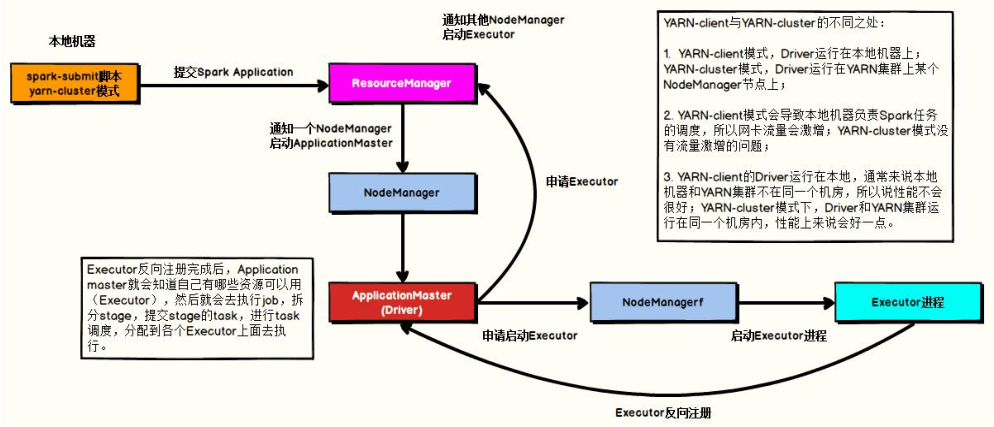
Take running WordCount program of word frequency statistics as an example, submit the following command:
/export/server/spark/bin/spark-submit \ --master yarn \ --deploy-mode cluster \ --driver-memory 512m \ --executor-memory 512m \ --executor-cores 1 \ --num-executors 2 \ --queue default \ --class cn.itcast.spark.submit.SparkSubmit \ hdfs://node1.itcast.cn:8020/spark/apps/spark-day02_2.11-1.0.0.jar \ /datas/wordcount.data /datas/swcy-cluster
08 - [understand] - Spark application MAIN function code execution
When the Spark Application is running, regardless of the client or cluster deployment mode, the code of the MAIN function in the application should be executed after the DriverProgram and Executors are started. Take the word frequency statistics WordCount program as an example.

In the above picture, A and B are executed in the Executor because RDD data operations are executed in the Driver when C has no return value, such as when calling count, first and other functions.

09 - [understand] - introduction of RDD concept
For a large amount of data, Spark uses a data structure called resilient distributed datasets (RDD) to store calculations internally. All operations and operations are based on the RDD data structure In the Spark framework, data is encapsulated into a collection: RDD. If you want to process data, you can call the functions in the collection RDD.

In other words, the core points of RDD design are:
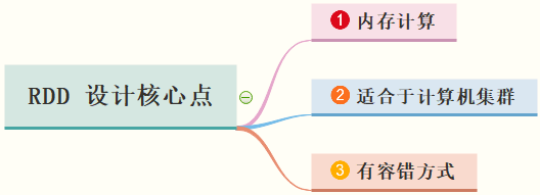
file: http://spark.apache.org/docs/2.4.5/rdd-programming-guide.html
10 - [Master] - official definition of RDD concept
RDD (Resilient Distributed Dataset) is called elastic distributed dataset. It is the most basic data abstraction in Spark. It represents an immutable, divisible and parallel computing set of elements.

Split the core points in three aspects:

It can be considered that RDD is a distributed List or Array, and an abstract data structure. RDD is an abstract class AbstractClass and generic Generic Type:

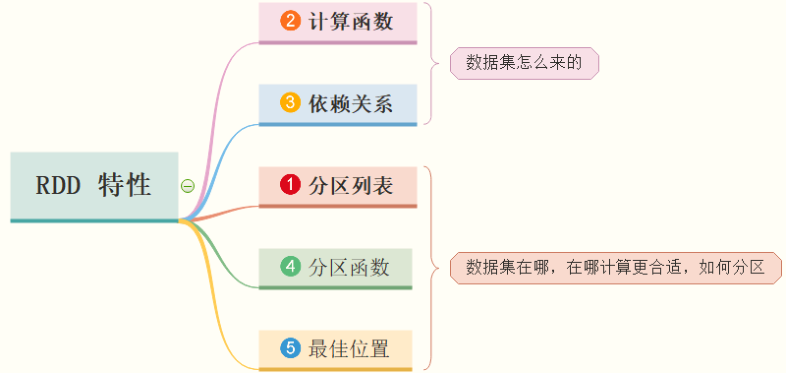
The core points of RDD elastic distributed dataset are as follows:
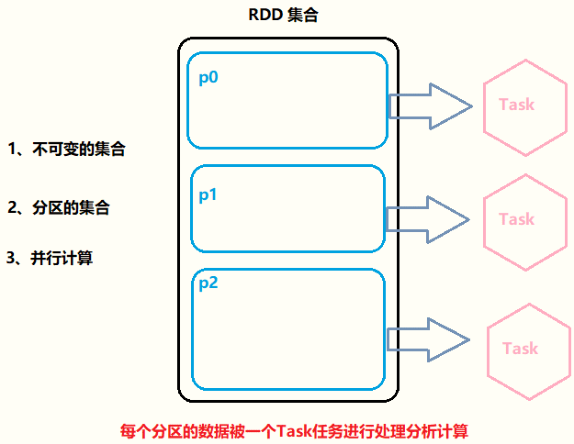
11 - [Master] - Analysis of five characteristics of RDD concept
There are five features inside the RDD data structure (excerpt from the RDD source code): the first three features must be included; The last 2 features are optional.

- First: a list of partitions

- Second: A function for computing each split
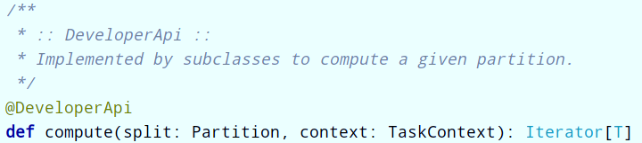
- Third: A list of dependencies on other RDDs
In the RDD class, there is a corresponding method:

- Fourth: optionally, a partitioner for key value RDDS

- Fifth: optically, a list of preferred locations to compute each split on
- Find the best location list when calculating each partition data in RDD
- When calculating the data, consider the local row of data, where the data is, and try to put the Task where it is, so as to quickly read the data for processing

RDD is a representation of a data set. It not only represents the data set, but also shows where the data set comes from and how to calculate it. The main attributes include five aspects (it must be borne in mind that to deepen understanding through coding, interviews often ask):
12 - [Master] - word frequency statistics of RDD concept RDD in WordCount
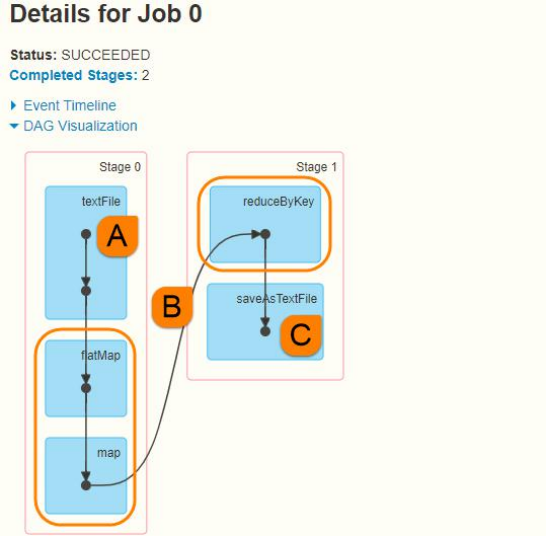
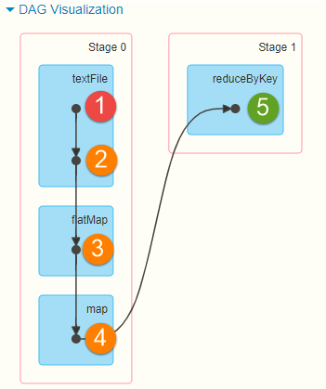
Take the WordCount program of word frequency statistics as an example to view the RDD types and dependencies in the whole Job. The WordCount program code is as follows:

After running the program, view the WEB UI monitoring page. This Job (triggered by RDD calling foreach) executes DAG diagram:
13 - [Master] - two ways to create RDD
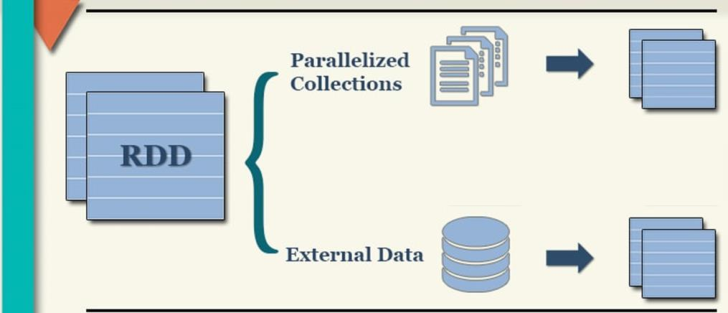
There are two main ways to encapsulate data into RDD sets: parallelizing local sets (in Driver Program) and loading data sets of external storage systems (such as HDFS, Hive, HBase, Kafka, Elasticsearch, etc.) by reference.
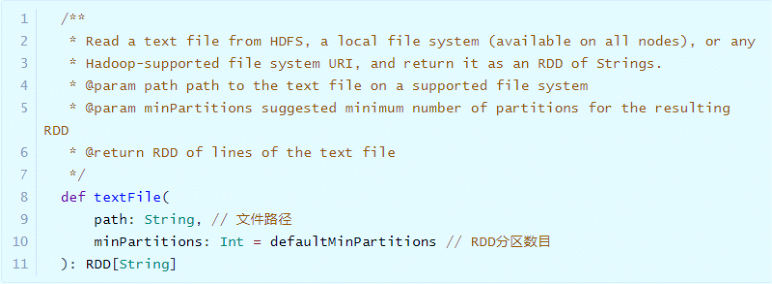
The most commonly used method: textFile, read the text file on HDFS or LocalFS, and specify the file path and the number of RDD partitions.
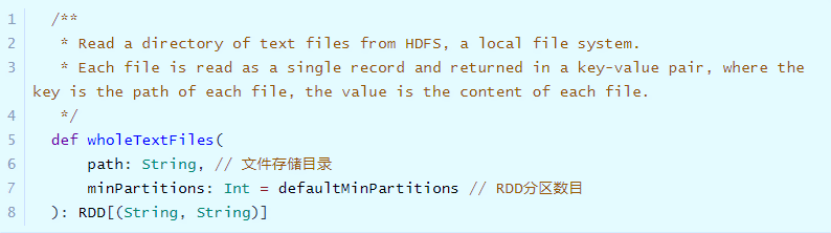
14 - [Master] - small file reading when creating RDD
In actual projects, sometimes the data files processed belong to small files (each file has a small amount of data, such as KB, tens of MB, etc.), and the number of files is large. If each file is read as a partition of RDD, the calculation of data is time-consuming and the performance is low. Use the wholeTextFiles class provided in SparkContext to specifically read small file data.
Example demonstration: read 100 small file data, each file size is less than 1MB, and set the number of RDD partitions to 2.
package cn.itcast.spark.source
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Use the SparkContext#wholeTextFiles() method to read small files
*/
object _02SparkWholeTextFileTest {
def main(args: Array[String]): Unit = {
val sc: SparkContext = {
// sparkConf object
val sparkConf = new SparkConf()
// _01SparkParallelizeTest$ ->(.stripSuffix("$")) -> _01SparkParallelizeTest
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// sc instance object
SparkContext.getOrCreate(sparkConf)
}
/*
def wholeTextFiles(
path: String,
minPartitions: Int = defaultMinPartitions
): RDD[(String, String)]
Key: Name and path of each small file
Value: Contents of each small file
*/
val inputRDD: RDD[(String, String)] = sc.wholeTextFiles("datas/ratings100", minPartitions = 2)
println(s"RDD Number of partitions = ${inputRDD.getNumPartitions}")
inputRDD.take(2).foreach(tuple => println(tuple))
// After application, close the resource
sc.stop()
}
}