1 Spark SQL overview
1.1 what is Spark SQL
Spark SQL is a module used by spark to process structured data. It provides two programming abstractions: DataFrame and DataSet, and acts as a distributed SQL query engine.
We have learned about Hive, which converts Hive SQL into MapReduce and then submits it to the cluster for execution, which greatly simplifies the complexity of writing MapReduce programs. Due to the slow execution efficiency of MapReduce computing model. All Spark SQL came into being. It converts Spark SQL into RDD and then submits it to the cluster for execution. The execution efficiency is very fast!
1.2 features of spark SQL
1) Easy integration

2) Unified data access

3) Compatible with Hive
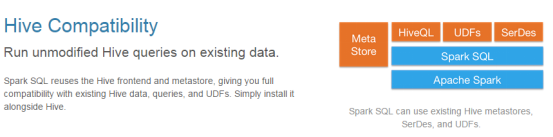
4) Standard data connection

1.3 what is a DataFrame
Similar to RDD, DataFrame is also a distributed data container. However, DataFrame is more like the two-dimensional table of traditional database. In addition to data, it also records the structure information of data, that is, schema. At the same time, like Hive, DataFrame also supports nested data types (struct, array and map). From the perspective of API ease of use, DataFrame API provides a set of high-level relational operations, which is more friendly and lower threshold than functional RDD API.
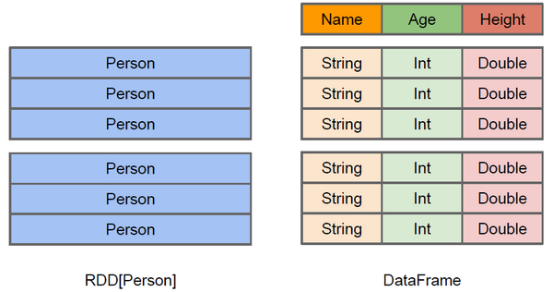
The figure above intuitively shows the difference between DataFrame and RDD. Although the RDD[Person] on the left takes Person as the type parameter, the Spark framework itself does not understand the internal structure of the Person class. The DataFrame on the right provides detailed structure information, so that Spark SQL can clearly know which columns are included in the dataset, and what is the name and type of each column. DataFrame is a view that provides a Schema for data. It can be treated as a table in the database, and the DataFrame is lazy to execute. The performance is higher than RDD. The main reasons are as follows:
Optimized execution plan: the query plan is optimized through spark catalyst optimizer.
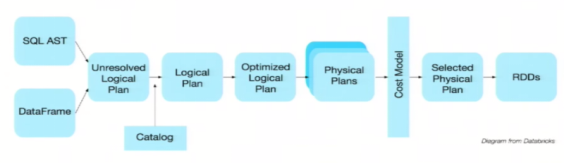
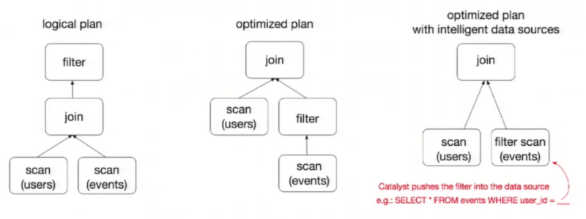
To illustrate query optimization, let's take a look at the example of population data analysis shown in the figure above. In the figure, two dataframes are constructed. After joining them, a filter operation is performed. If the implementation plan is implemented intact, the final implementation efficiency is not high. Because join is a costly operation, it may also produce a large data set. If we can push the filter down below the join, filter the DataFrame first, and then join the smaller result set after filtering, we can effectively shorten the execution time. The query optimizer of Spark SQL does exactly that. In short, logical query plan optimization is a process of replacing high-cost operations with low-cost operations by using equivalent transformation based on relational algebra.
1.4 what is a DataSet
1) It is an extension of Dataframe API and the latest data abstraction of Spark.
2) The user-friendly API style has both type safety check and query optimization characteristics of Dataframe.
3) Dataset supports codec. When it needs to access data on non heap, it can avoid deserializing the whole object and improve efficiency.
4) The sample class is used to define the structure information of data in the dataset. The name of each attribute in the sample class is directly mapped to the field name in the dataset.
5) Dataframe is a special column of Dataset, DataFrame=Dataset[Row], so you can convert dataframe to Dataset through the as method. Row is a type. Like Car and Person, all table structure information is represented by row.
6) DataSet is strongly typed. For example, there can be Dataset[Car], Dataset[Person]
7) DataFrame only knows the field, but does not know the field type, so there is no way to check whether the type fails during compilation when performing these operations. For example, you can subtract a String and report an error when executing. DataSet not only knows the field, but also knows the field type, so there is more strict error checking. It's like the analogy between JSON objects and class objects.
2 SparkSQL programming
2.1 SparkSession
In the old version, SparkSQL provides two starting points for SQL queries: one is SQLContext, which is used for SQL queries provided by Spark itself; One is called HiveContext, which is used to connect Hive queries.
SparkSession is the starting point of Spark's latest SQL query, which is essentially a combination of SQLContext and HiveContext. Therefore, the API s available on SQLContext and HiveContext can also be used on SparkSession. SparkSession encapsulates sparkContext internally, so the calculation is actually completed by sparkContext.
2.2 DataFrame
2.2.1 create
In Spark SQL, SparkSession is the entrance to create DataFrame and execute SQL. There are three ways to create DataFrame: through Spark data source; Convert from an existing RDD; You can also query and return from Hive Table.
1) Create from Spark data source
(1) View the file format created by Spark data source
scala> spark.read. csv format jdbc json load option options orc parquet schema table text textFile
(2) Read json file and create DataFrame
scala> val df = spark.read.json("/opt/modules/spark/examples/src/main/resources/people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
(3) Show results
scala> df.show +----+-------+ | age| name| +----+-------+ |null|Michael| | 30| Andy| | 19| Justin| +----+-------+
2.2.2 SQL style syntax
1) Create a DataFrame
scala> val df = spark.read.json("/opt/modules/spark/examples/src/main/resources/people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2) Create a temporary table for the DataFrame
scala> df.createOrReplaceTempView("people")
3) Query the whole table through SQL statement
scala> val sqlDF = spark.sql("SELECT * FROM people")
sqlDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
4) Result display
scala> sqlDF.show +----+-------+ | age| name| +----+-------+ |null|Michael| | 30| Andy| | 19| Justin| +----+-------+
Note: the temporary table is within the range of Session. After the Session exits, the table will become invalid. If you want to be effective in the application range, you can use the global table. Note that full path access is required when using global tables, such as global_temp.people
5) Create a global table for DataFrame
scala> df.createGlobalTempView("people")
6) Query the whole table through SQL statement
scala> spark.sql("SELECT * FROM global_temp.people").show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
scala> spark.newSession().sql("SELECT * FROM global_temp.people").show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
2.2.3 DSL style syntax
1) Create a DateFrame
scala> val df = spark.read.json("/opt/modules/spark/examples/src/main/resources/people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2) View Schema information of DataFrame
scala> df.printSchema root |-- age: long (nullable = true) |-- name: string (nullable = true)
3) View only the "name" column data
scala> df.select("name").show()
+-------+
| name|
+-------+
|Michael|
| Andy|
| Justin|
+-------+
4) View "name" column data and "age+1" data
scala> df.select($"name", $"age" + 1).show() +-------+---------+ | name|(age + 1)| +-------+---------+ |Michael| null| | Andy| 31| | Justin| 20| +-------+---------+
5) View data with age greater than 21
scala> df.filter($"age" > 21).show() +---+----+ |age|name| +---+----+ | 30|Andy| +---+----+
6) Group by "age" to view the number of data pieces
scala> df.groupBy("age").count().show()
+----+-----+
| age|count|
+----+-----+
| 19| 1|
|null| 1|
| 30| 1|
+----+-----+
2.2.4 converting RDD to DateFrame
Note: if you need to operate between RDD and DF or DS, you need to import spark implicits._ [spark is not the package name, but the name of the sparkSession object]
Precondition: import implicit transformation and create an RDD
scala> import spark.implicits._
import spark.implicits._
scala> val peopleRDD = sc.textFile("examples/src/main/resources/people.txt")
peopleRDD: org.apache.spark.rdd.RDD[String] = examples/src/main/resources/people.txt MapPartitionsRDD[3] at textFile at <console>:27
1) Determine the conversion manually
scala> peopleRDD.map{x=>val para = x.split(",");(para(0),para(1).trim.toInt)}.toDF("name","age")
res1: org.apache.spark.sql.DataFrame = [name: string, age: int]
2) Determined by reflection (sample class is required)
(1) Create a sample class
scala> case class People(name:String, age:Int)
(2) Convert RDD to DataFrame according to the sample class
scala> peopleRDD.map{ x => val para = x.split(",");People(para(0),para(1).trim.toInt)}.toDF
res2: org.apache.spark.sql.DataFrame = [name: string, age: int]
3) By programming
(1) Import required types
scala> import org.apache.spark.sql.types._ import org.apache.spark.sql.types._
(2) Create Schema
scala> val structType: StructType = StructType(StructField("name", StringType) :: StructField("age", IntegerType) :: Nil)
structType: org.apache.spark.sql.types.StructType = StructType(StructField(name,StringType,true), StructField(age,IntegerType,true))
(3) Import required types
scala> import org.apache.spark.sql.Row import org.apache.spark.sql.Row
(4) Creates a binary RDD based on the given type
scala> val data = peopleRDD.map{ x => val para = x.split(",");Row(para(0),para(1).trim.toInt)}
data: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[6] at map at <console>:33
(5) Create a DataFrame based on the data and the given schema
scala> val dataFrame = spark.createDataFrame(data, structType) dataFrame: org.apache.spark.sql.DataFrame = [name: string, age: int]
2.2.5 converting dateframe to RDD
Just call rdd directly
1) Create a DataFrame
scala> val df = spark.read.json("/opt/moduleS/spark/examples/src/main/resources/people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2) Convert DataFrame to RDD
scala> val dfToRDD = df.rdd dfToRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[19] at rdd at <console>:29
3) Print RDD
scala> dfToRDD.collect res13: Array[org.apache.spark.sql.Row] = Array([Michael, 29], [Andy, 30], [Justin, 19])
2.3 DataSet
Dataset is a data set with strong type, and the corresponding type information needs to be provided.
2.3.1 create
1) Create a sample class
scala> case class Person(name: String, age: Long) defined class Person
2) Create DataSet
scala> val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]
2.3.2 converting RDD to DataSet
SparkSQL can automatically convert the RDD containing the case class into DataFrame. The case class defines the structure of the table, and the case class attribute becomes the column name of the table through reflection.
1) Create an RDD
scala> val peopleRDD = sc.textFile("examples/src/main/resources/people.txt")
peopleRDD: org.apache.spark.rdd.RDD[String] = examples/src/main/resources/people.txt MapPartitionsRDD[3] at textFile at <console>:27
2) Create a sample class
scala> case class Person(name: String, age: Long) defined class Person
3) Convert RDD to DataSet
scala> peopleRDD.map(line => {val para = line.split(",");Person(para(0),para(1).trim.toInt)}).toDS()
2.3.3 conversion of dataset to RDD
Just call the rdd method.
1) Create a DataSet
scala> val DS = Seq(Person("Andy", 32)).toDS()
DS: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]
2) Convert DataSet to RDD
scala> DS.rdd res11: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[15] at rdd at <console>:28
2.4 interoperability between dataframe and DataSet
- Convert DataFrame to DataSet
1) Create a DateFrame
scala> val df = spark.read.json("examples/src/main/resources/people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2) Create a sample class
scala> case class Person(name: String, age: Long) defined class Person
3) Convert DateFrame to DataSet
scala> df.as[Person] res14: org.apache.spark.sql.Dataset[Person] = [age: bigint, name: string]
- Convert DataSet to DataFrame
1) Create a sample class
scala> case class Person(name: String, age: Long) defined class Person
2) Create DataSet
scala> val ds = Seq(Person("Andy", 32)).toDS()
ds: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]
3) Convert DataSet to DataFrame
scala> val df = ds.toDF df: org.apache.spark.sql.DataFrame = [name: string, age: bigint]
4) Display
scala> df.show +----+---+ |name|age| +----+---+ |Andy| 32| +----+---+
2.4.1 transferring dataset to DataFrame
This is very simple, because it just encapsulates the case class into Row
(1) Import implicit conversion
import spark.implicits._
(2) Conversion
val testDF = testDS.toDF
2.4.2 conversion of dataframe to DataSet
(1) Import implicit conversion
import spark.implicits._
(2) Create a sample class
case class Coltest(col1:String,col2:Int)extends Serializable //Define field name and type
(3) Conversion
val testDS = testDF.as[Coltest]
After giving the type of each column, this method uses the as method to convert it to Dataset, which is very convenient when the data type is DataFrame and needs to be processed for each field. When using some special operations, be sure to add import spark implicits._ Otherwise, toDF and toDS cannot be used.
2.5 RDD,DataFrame,DataSet
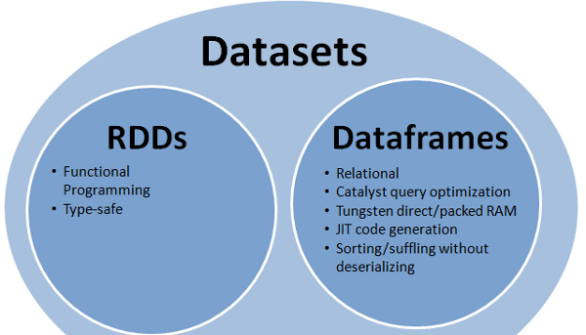
In SparkSQL, Spark provides us with two new abstractions: DataFrame and DataSet. What's the difference between them and RDD? First of all, from the perspective of version generation:
RDD (Spark1.0) —> Dataframe(Spark1.3) —> Dataset(Spark1.6)
If the same data is given to these three data structures, they will give the same results after calculation respectively. The difference is their execution efficiency and execution mode.
In later versions of Spark, DataSet will gradually replace RDD and DataFrame as the only API interface.
2.5.1 commonality of the three
1. RDD, DataFrame and Dataset are all distributed elastic data sets under spark platform, which provide convenience for processing super large data
2. All three have inert mechanisms. They will not be executed immediately when creating and converting, such as map method. They will start traversing operations only when they encounter actions such as foreach.
3. All three will automatically cache operations according to the memory condition of spark, so that even if the amount of data is large, there is no need to worry about memory overflow.
4. All three have the concept of partition
5. The three have many common functions, such as filter, sorting and so on
6. When operating on DataFrame and Dataset, many operations need to be supported by this package
import spark.implicits._
7. Both DataFrame and Dataset can use pattern matching to obtain the value and type of each field
DataFrame:
testDF.map{
case Row(col1:String,col2:Int)=>
println(col1);println(col2)
col1
case _=>
""
}
Dataset:
case class Coltest(col1:String,col2:Int)extends Serializable //Define field name and type
testDS.map{
case Coltest(col1:String,col2:Int)=>
println(col1);println(col2)
col1
case _=>
""
}
2.5.2 differences among the three
- RDD:
1) RDD is generally used together with spark mlib
2) The sparksql operation is not supported by RDD - DataFrame:
1) Unlike RDD and Dataset, the type of each Row of DataFrame is fixed as Row, and the value of each column cannot be accessed directly. The value of each field can be obtained only through parsing, such as:
testDF.foreach{
line =>
val col1=line.getAs[String]("col1")
val col2=line.getAs[String]("col2")
}
2) DataFrame and Dataset are generally not used together with spark mlib
3) Both DataFrame and Dataset support sparksql operations, such as select and groupby. They can also register temporary tables / windows for sql statement operations, such as:
dataDF.createOrReplaceTempView("tmp")
spark.sql("select ROW,DATE from tmp where DATE is not null order by DATE").show(100,false)
4) DataFrame and Dataset support some particularly convenient saving methods, such as saving as csv, which can be carried with the header, so that the field name of each column is clear at a glance
//preservation
val saveoptions = Map("header" -> "true", "delimiter" -> "\t", "path" -> "hdfs://cluster/test")
datawDF.write.format("com.jackyan.spark.csv").mode(SaveMode.Overwrite).options(saveoptions).save()
//read
val options = Map("header" -> "true", "delimiter" -> "\t", "path" -> "hdfs://hadoop102:9000/test")
val datarDF= spark.read.options(options).format("com.jackyan.spark.csv").load()
With this saving method, the correspondence between field names and columns can be easily obtained, and the delimiter can be specified freely.
- Dataset:
1) Dataset and DataFrame have exactly the same member functions, except that the data type of each row is different.
2) DataFrame can also be called Dataset[Row]. The type of each Row is Row, which is not parsed. It is impossible to know which fields each Row has and what types each field is. You can only use the getAS method mentioned above or the pattern matching mentioned in Article 7 of the commonality to take out specific segments. In the Dataset, the type of each Row is not certain. After customizing the case class, you can get the information of each Row freely
case class Coltest(col1:String,col2:Int)extends Serializable //Define field name and type
/**
rdd
("a", 1)
("b", 1)
("a", 1)
**/
val test: Dataset[Coltest]=rdd.map{line=>
Coltest(line._1,line._2)
}.toDS
test.map{
line=>
println(line.col1)
println(line.col2)
}
It can be seen that Dataset is very convenient when you need to access a field in the column. However, if you want to write some functions with strong adaptability, if you use Dataset, the type of row is uncertain, which may be various case class es, which can not realize adaptation. At this time, you can better solve the problem by using DataFrame, that is, Dataset[Row]
2.6 IDEA creating SparkSQL program
The packaging and running mode of programs in IDEA are similar to that of SparkCore. New dependencies need to be added to Maven dependencies:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.8</version>
</dependency>
The procedure is as follows:
object HelloWorld {
def main(args: Array[String]) {
//Create SparkConf() and set App name
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
val df = spark.read.json("data/people.json")
// Displays the content of the DataFrame to stdout
df.show()
df.filter($"age" > 21).show()
df.createOrReplaceTempView("persons")
spark.sql("SELECT * FROM persons where age > 21").show()
spark.stop()
}
}
2.7 user defined functions
In the Shell window, you can use spark UDF function users can customize functions.
2.7.1 user defined UDF functions
scala> val df = spark.read.json("examples/src/main/resources/people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> df.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
scala> spark.udf.register("addName", (x:String)=> "Name:"+x)
res5: org.apache.spark.sql.expressions.UserDefinedFunction = UserDefinedFunction(<function1>,StringType,Some(List(StringType)))
scala> df.createOrReplaceTempView("people")
scala> spark.sql("Select addName(name), age from people").show()
+-----------------+----+
|UDF:addName(name)| age|
+-----------------+----+
| Name:Michael|null|
| Name:Andy| 30|
| Name:Justin| 19|
+-----------------+----+
2.7.2 user defined aggregate function
Both strongly typed Dataset and weakly typed DataFrame provide related aggregation functions, such as count(), countDistinct(), avg(), max(), min(). In addition, users can set their own custom aggregation functions.
Weak type user-defined aggregate function: implement user-defined aggregate function by inheriting UserDefinedAggregateFunction. The following shows a user-defined aggregate function for calculating average salary.
object MyAverage extends UserDefinedAggregateFunction {
// The data type of the input parameter of the aggregate function
def inputSchema: StructType = StructType(StructField("inputColumn", LongType) :: Nil)
// Data type in aggregate buffer
def bufferSchema: StructType = {
StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil)
}
// Data type of return value
def dataType: DataType = DoubleType
// Whether the same output is always returned for the same input.
def deterministic: Boolean = true
// initialization
def initialize(buffer: MutableAggregationBuffer): Unit = {
// Total amount of wages deposited
buffer(0) = 0L
// Number of salary deposits
buffer(1) = 0L
}
// Data consolidation between the same Execute.
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
}
// Data merging between different executes
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// Calculate the final result
def evaluate(buffer: Row): Double = buffer.getLong(0).toDouble / buffer.getLong(1)
}
// Register function
spark.udf.register("myAverage", MyAverage)
val df = spark.read.json("examples/src/main/resources/employees.json")
df.createOrReplaceTempView("employees")
df.show()
// +-------+------+
// | name|salary|
// +-------+------+
// |Michael| 3000|
// | Andy| 4500|
// | Justin| 3500|
// | Berta| 4000|
// +-------+------+
val result = spark.sql("SELECT myAverage(salary) as average_salary FROM employees")
result.show()
// +--------------+
// |average_salary|
// +--------------+
// | 3750.0|
// +--------------+
Strong type user-defined aggregate function: the strong type user-defined aggregate function is implemented by inheriting the Aggregator, which is also used to calculate the average salary
// Since it is a strong type, there may be a case class
case class Employee(name: String, salary: Long)
case class Average(var sum: Long, var count: Long)
object MyAverage extends Aggregator[Employee, Average, Double] {
// Define a data structure to save the total wages and total wages, which are initially 0
def zero: Average = Average(0L, 0L)
// Combine two values to produce a new value. For performance, the function may modify `buffer`
// and return it instead of constructing a new object
def reduce(buffer: Average, employee: Employee): Average = {
buffer.sum += employee.salary
buffer.count += 1
buffer
}
// Aggregate the results of different executions
def merge(b1: Average, b2: Average): Average = {
b1.sum += b2.sum
b1.count += b2.count
b1
}
// Calculation output
def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count
// The encoder of setting value type shall be converted into case class
// Encoders.product is the encoder for scala tuple and case class conversion
def bufferEncoder: Encoder[Average] = Encoders.product
// Encoder for setting the final output value
def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
import spark.implicits._
val ds = spark.read.json("examples/src/main/resources/employees.json").as[Employee]
ds.show()
// +-------+------+
// | name|salary|
// +-------+------+
// |Michael| 3000|
// | Andy| 4500|
// | Justin| 3500|
// | Berta| 4000|
// +-------+------+
// Convert the function to a `TypedColumn` and give it a name
val averageSalary = MyAverage.toColumn.name("average_salary")
val result = ds.select(averageSalary)
result.show()
// +--------------+
// |average_salary|
// +--------------+
// | 3750.0|
// +--------------+
3 SparkSQL data source
3.1 general loading / saving method
3.1.1 manually specify options
The DataFrame interface of Spark SQL supports the operation of multiple data sources. A DataFrame can be operated in RDDs mode or registered as a temporary table. After registering the DataFrame as a temporary table, you can execute SQL queries on the DataFrame.
The default data source of Spark SQL is Parquet format. When the data source is a Parquet file, Spark SQL can easily perform all operations. Modify the configuration item Spark SQL. sources. Default to modify the default data source format.
val df = spark.read.load("examples/src/main/resources/users.parquet") df.select("name", "favorite_color").write.save("namesAndFavColors.parquet")
When the data source format is not a parquet format file, you need to manually specify the format of the data source. The data source format needs to specify the full name (for example: org.apache.spark.sql.parquet). If the data source format is a built-in format, you only need to specify the abbreviation JSON, parquet, JDBC, ORC, libsvm, CSV and text to specify the data format.
You can use the read provided by SparkSession The load method is used to load data in general and save data with write and save.
val peopleDF = spark.read.format("json").load("examples/src/main/resources/people.json")
peopleDF.write.format("parquet").save("hdfs://hadoop102:9000/namesAndAges.parquet")
In addition, you can run SQL directly on the file:
val sqlDF = spark.sql("SELECT * FROM parquet.`hdfs://hadoop102:9000/namesAndAges.parquet`")
sqlDF.show()
scala> val peopleDF = spark.read.format("json").load("examples/src/main/resources/people.json")
peopleDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> peopleDF.write.format("parquet").save("hdfs://hadoop102:9000/namesAndAges.parquet")
scala> peopleDF.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
scala> val sqlDF = spark.sql("SELECT * FROM parquet.`hdfs:// hadoop102:9000/namesAndAges.parquet`")
17/09/05 04:21:11 WARN ObjectStore: Failed to get database parquet, returning NoSuchObjectException
sqlDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> sqlDF.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
3.1.2 file saving options
You can use SaveMode to perform storage operations. SaveMode defines the processing mode of data. It should be noted that these save modes do not use any locking, not atomic operation. In addition, when the Overwrite mode is used, the original data has been deleted before the new data is output. SaveMode is detailed in the following table:
| Scala/Java | Any Language | Meaning |
|---|---|---|
| SaveMode.ErrorIfExists(default) | "error"(default) | If the file exists, an error is reported |
| SaveMode.Append | "append" | Add |
| SaveMode.Overwrite | "overwrite" | Overwrite |
| SaveMode.Ignore | "ignore" | Ignore if data exists |
3.2 JSON file
Spark SQL can automatically infer the structure of JSON dataset and load it as a Dataset[Row] You can use sparksession read. JSON () to load a JSON file.
Note: This JSON file is not a traditional JSON file. Each line must be a JSON string.
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
// Primitive types (Int, String, etc) and Product types (case classes) encoders are
// supported by importing this when creating a Dataset.
import spark.implicits._
// A JSON dataset is pointed to by path.
// The path can be either a single text file or a directory storing text files
val path = "examples/src/main/resources/people.json"
val peopleDF = spark.read.json(path)
// The inferred schema can be visualized using the printSchema() method
peopleDF.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Creates a temporary view using the DataFrame
peopleDF.createOrReplaceTempView("people")
// SQL statements can be run by using the sql methods provided by spark
val teenagerNamesDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19")
teenagerNamesDF.show()
// +------+
// | name|
// +------+
// |Justin|
// +------+
// Alternatively, a DataFrame can be created for a JSON dataset represented by
// a Dataset[String] storing one JSON object per string
val otherPeopleDataset = spark.createDataset(
"""{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)
val otherPeople = spark.read.json(otherPeopleDataset)
otherPeople.show()
// +---------------+----+
// | address|name|
// +---------------+----+
// |[Columbus,Ohio]| Yin|
3.3 Parquet file
Parquet is a popular columnar storage format, which can efficiently store records with nested fields. Parquet format is often used in Hadoop ecosystem. It also supports all data types of spark SQL. Spark SQL provides a method to directly read and store parquet format files.
import spark.implicits._
val peopleDF = spark.read.json("examples/src/main/resources/people.json")
peopleDF.write.parquet("hdfs://hadoop102:9000/people.parquet")
val parquetFileDF = spark.read.parquet("hdfs:// hadoop102:9000/people.parquet")
parquetFileDF.createOrReplaceTempView("parquetFile")
val namesDF = spark.sql("SELECT name FROM parquetFile WHERE age BETWEEN 13 AND 19")
namesDF.map(attributes => "Name: " + attributes(0)).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
3.4 JDBC
Spark SQL can create a DataFrame by reading data from the relational database through JDBC. After a series of calculations on the DataFrame, you can also write the data back to the relational database.
Note: you need to put the relevant database drivers under the classpath of spark.
(1) Start spark shell
$ bin/spark-shell
(2) Method 1 of loading data from Mysql database
val jdbcDF = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://hadoop102:3306/rdd")
.option("dbtable", "rddtable")
.option("user", "root")
.option("password", "000000")
.load()
(3) Loading data from Mysql database mode 2
val connectionProperties = new Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "root")
val jdbcDF2 = spark.read
.jdbc("jdbc:mysql://hadoop101:3306/rdd", "rddtable", connectionProperties)
(4) Write data to Mysql mode 1
jdbcDF.write
.format("jdbc")
.option("url", "jdbc:mysql://hadoop101:3306/rdd")
.option("dbtable", "dftable")
.option("user", "root")
.option("password", "root")
.save()
(5) Write data to Mysql mode 2
jdbcDF2.write
.jdbc("jdbc:mysql://hadoop102:3306/rdd", "db", connectionProperties)
3.5 Hive database
Apache Hive is the SQL Engine on Hadoop. Spark SQL can be compiled with or without Hive support. Spark SQL with Hive support can support Hive table access, UDF (user-defined function) and Hive query language (HiveQL/HQL). It should be emphasized that if you want to include Hive libraries in spark SQL, you do not need to install Hive in advance. Generally speaking, it is better to introduce Hive support when compiling spark SQL, so that these features can be used. If you download a binary version of spark, it should have added Hive support at compile time.
To connect spark SQL to a deployed Hive, you must connect Hive site XML to spark's configuration file directory ($SPARK_HOME/conf). Spark SQL can run even if Hive is not deployed. It should be noted that if you do not deploy Hive, spark SQL will create its own Hive metadata warehouse called Metastore in the current working directory_ db. In addition, if you try to use the CREATE TABLE (not CREATE EXTERNAL TABLE) statement in HiveQL to create tables, these tables will be placed in the / user/hive/warehouse directory in your default file system (if you have a configured hdfs-site.xml in your classpath, the default file system is HDFS, otherwise it is the local file system).
3.5.1 embedded Hive application
If you want to use the embedded Hive, you don't have to do anything, just use it directly.
You can specify the data warehouse address for the first time by adding parameters:
--conf spark.sql.warehouse.dir=hdfs://hadoop101/spark-wearhouse
Note: if you use the internal Hive, in spark2 After 0, spark sql. warehouse. Dir is used to specify the address of the data warehouse. If you need to use HDFS as the path, you need to set the core site XML and HDFS site XML is added to the Spark conf directory, otherwise only the warehouse directory on the master node will be created, and the file cannot be found during query. This is because HDFS needs to be used, so the metastore needs to be deleted and the cluster needs to be restarted.
3.5.2 external Hive application
If you want to connect the Hive that has been deployed externally, you need to go through the following steps.
1) Put Hive site in Hive XML copy or soft connect to the conf directory under the Spark installation directory.
2) Open the spark shell and pay attention to the JDBC client accessing Hive metabase
$ bin/spark-shell --jars mysql-connector-java-5.1.49-bin.jar
3.5.3 running Spark SQL CLI
Spark SQL CLI can easily run Hive metadata service locally and perform query tasks from the command line. Execute the following command in spark directory to start Spark SQL CLI:
./bin/spark-sql
3.5.4 use Hive in code
(1) Add dependency:
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
(2) hive support needs to be added when creating a SparkSession
val warehouseLocation: String = new File("spark-warehouse").getAbsolutePath
val spark = SparkSession
.builder()
.appName("Spark Hive Example")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate()
Note: to use the built-in Hive, you need to specify a Hive warehouse address. If external Hive is used, Hive site Add XML to ClassPath.