catalogue
1, SparkSession, DataFrame and Dataset
2. sql syntax parsing key objects
2. LogicalPlan class structure system
3. Generated by analyzed logicalplan
1, SparkSession, DataFrame and Dataset
1. To use the sparksql function, you need to create a SparkSession object and use {SparkSession Builder () method to create:
val session = SparkSession
.builder()
.appName("Spark Hive Example")
.master("local[2]")
.getOrCreate()2. The DataFrame in spark SQL is similar to a relational data table. Query operations on a single table or in a relational database can be implemented by calling its API interface in the DataFrame. The difference between Dataset and DateFrame is that the generic class T in Dataset is a certain type, which needs to be determined by displaying the specified schema. DataFrame is a specific generic class of Dataset: type DataFrame = Dataset[Row]. There are three ways to create a DataFrame:
- Based on existing memory data objects, such as List, RDD, etc.:
//Create based on List object val peopleList = List(People(1, "zhangsan"), People(2, "Lisi")) val dfFromList = session.createDataFrame(peopleList) //Create based on Rdd val textRdd = session.sparkContext.makeRDD(peopleList) val dfFromRdd = session.createDataFrame(textRdd)
- Use the api of DataFrameReader class, which supports reading text, csv, json and other files, as well as reading table data through jdbc connection:
val dataReader = session.read dataReader.csv("/tmp/test.txt") dataReader.jdbc("jdbc:mysql://localhost:3306", "user", new Properties()) dataReader.json("/data1/people.json") - Using session SQL () method reads Hive table data:
val session = SparkSession .builder() .appName("Spark Hive Example") .config("spark.sql.warehouse.dir", "/apps/hive/warehouse") .config("spark.driver.memory", "1024m") .master("local[2]") .enableHiveSupport() .getOrCreate() session.sql("select * from people where age > 18")
2, Spark Sql parsing
1. Overall overview
Generally speaking, for Spark SQL system, the execution from SQL to RDD in Spark needs to go through two major stages: logical plan and physical plan, as shown in the following figure:
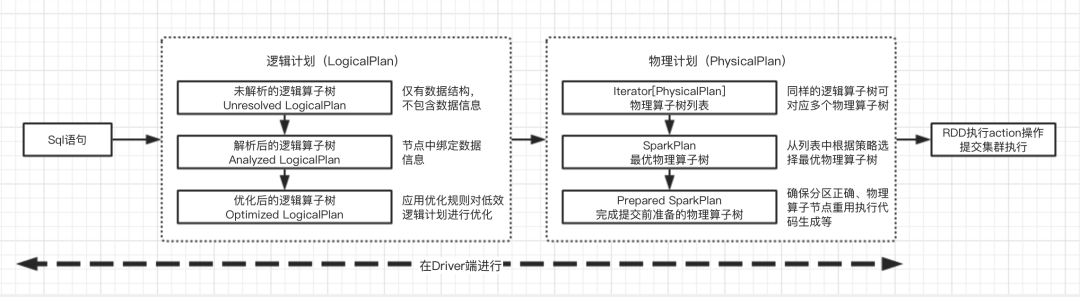
Spark sql module provides sql syntax analysis and compilation functions, allowing us to write sql code to query table data without calling complex APIs. The syntax analysis module uses the antlr4 framework to generate a syntax tree under the sql/catalyst directory of the spark source code. sql syntax analysis goes through three stages:
- Lexical analysis: divide sql statements into token s according to rules.
- Syntax analysis: the top-down recursive descent analysis method is used to generate the syntax tree. Each node of the tree is represented in antlr4 by the subclass ParserRuleContext of ParseTree interface, which is inherited in spark to represent each node.
- Syntax tree traversal: antlr4 {visitor mode} is used to access these tree nodes to generate different objects.
Three key roles are required to implement the above process: SqlParser, parsing sql and generating syntax tree. Visitor, the visitor, traverses the tree node; ParseDriver, driver class, driver code running. The whole can be represented by pseudo code as follows:
public class MyVisitor extends SqlBaseBaseVisitor<String> {
public String visitSingleStatement(SqlBaseParser.SingleStatementContext ctx) {
System.out.println("visitSingleStatement");
return visitChildren(ctx);
}
public String visitSingleExpression(SqlBaseParser.SingleExpressionContext ctx) {
System.out.println("visitSingleExpression");
return visitChildren(ctx);
}
// ... Other codes are omitted
}
public class ParserDriver {
public static void main(String[] args) {
String query = "select * from people where age > 18".toUpperCase();
SqlBaseLexer lexer = new SqlBaseLexer(new ANTLRInputStream(query));
SqlBaseParser parser = new SqlBaseParser(new CommonTokenStream(lexer));
MyVisitor visitor = new MyVisitor();
String res = visitor.visitSingleStatement(parser.singleStatement());
System.out.println("res="+res);
}
}2. sql syntax parsing key objects
2.1 SparkSqlParser
Spark uses the SparkSqlParser class to parse sql statements in sparksession Used in sql () method:
def sql(sqlText: String): DataFrame = {
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}The class diagram structure of SparkSqlParser is as follows:
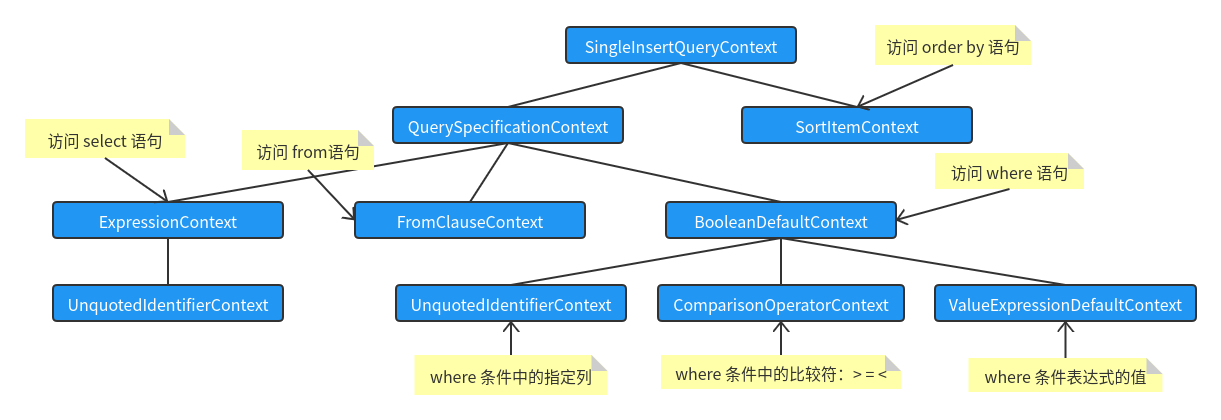
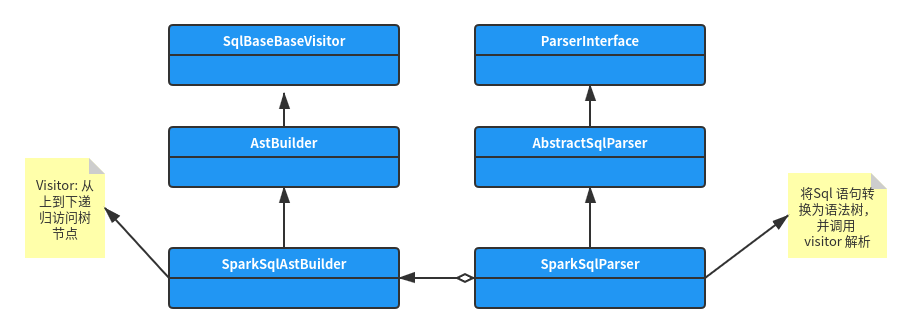 As mentioned above, in Catalyst, the SQL syntax is parsed, and the generated abstract syntax tree node is named at the end of Context. Taking select id, name, age, sex , from people where age > 18 order by ID desc as an example, the generated syntax tree structure is as follows (I only draw the key tree nodes in the figure, and the actual nodes are much more complex):
As mentioned above, in Catalyst, the SQL syntax is parsed, and the generated abstract syntax tree node is named at the end of Context. Taking select id, name, age, sex , from people where age > 18 order by ID desc as an example, the generated syntax tree structure is as follows (I only draw the key tree nodes in the figure, and the actual nodes are much more complex):
 After the SparkSqlParser converts sql statements into idiom trees, it will use its instance attribute val astBuilder = new SparkSqlAstBuilder(conf) to traverse these tree nodes. From the above class diagram, we know that this class is a subclass of SqlBaseBaseVistor and a visitor. Most of the logic is implemented in the AstBuilder class.
After the SparkSqlParser converts sql statements into idiom trees, it will use its instance attribute val astBuilder = new SparkSqlAstBuilder(conf) to traverse these tree nodes. From the above class diagram, we know that this class is a subclass of SqlBaseBaseVistor and a visitor. Most of the logic is implemented in the AstBuilder class.
2.2 AstBuilder
From the above, we know that AstBuilder is a visitor used to traverse the syntax tree. Let's take a look at the definition of this class and some methods:
class AstBuilder(conf: SQLConf) extends SqlBaseBaseVisitor[AnyRef] with Logging {
override def visitSingleStatement(ctx: SingleStatementContext): LogicalPlan = withOrigin(ctx) {
visit(ctx.statement).asInstanceOf[LogicalPlan]
}
override def visitSingleExpression(ctx: SingleExpressionContext): Expression = withOrigin(ctx) {
visitNamedExpression(ctx.namedExpression)
}
override def visitSingleTableIdentifier(
ctx: SingleTableIdentifierContext): TableIdentifier = withOrigin(ctx) {
visitTableIdentifier(ctx.tableIdentifier)
}
override def visitSingleFunctionIdentifier(
ctx: SingleFunctionIdentifierContext): FunctionIdentifier = withOrigin(ctx) {
visitFunctionIdentifier(ctx.functionIdentifier)
}
}This class duplicates some methods of the parent class. When accessing each tree node (Context object), these methods actually call the accept() method of the Context class. The general implementation logic of the accept methods of various Context classes is as follows:
- If the tree node (Context) is not a leaf node, let the visitor recursively access its own child node.
- If the tree node (Context) is a leaf node (TerminalNodeImpl), call the visitTerminal() method of the visitor. By default, this method is implemented as calling the defaultResult() method of the visitor itself.
The object type returned by the visitXXX() method of the AstBuilder class is LogicalPlan or Expression. This class is the definition class of Spark SQL logic plan at the code level.
3, Spark LogicalPlan
1. Overall overview
Through the above analysis, we know that Spark Sql traverses the syntax tree nodes (various Context objects) through the visitor and returns multiple LogicalPlan objects, which also maintain a tree relationship.
From the generation of unresolved logicalplan through SparkSqlParser parsing of sql statement to the final generation of Optimized LogicalPlan, this process mainly goes through three stages, as shown in the following figure:
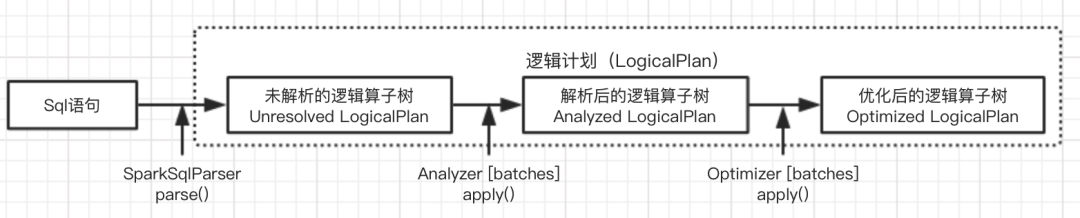
The optimized logical plan is passed to the next stage for the generation of the physical execution plan.
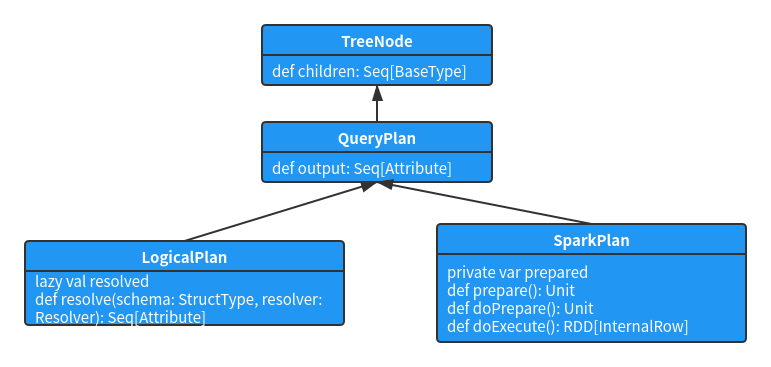
2. LogicalPlan class structure system
Before introducing LogicalPlan, it is necessary to introduce its parent class QueryPlan. The main operations of QueryPlan are divided into six modules:
- Input and output: the input and output of QueryPlan defines five methods to represent the output of the node itself and receive the input of its child nodes.
- Basic attribute: it represents some basic information in the QueryPlan node. The schema corresponds to the schema information of the output attribute.
- String: this part of the method is mainly used to output and print the QueryPlan tree structure information, in which the schema information will also be displayed in tree form.
- Standardization
- Expression operation
- constraint
The class inheritance relationship of LogicalPlan is shown in the following figure:
LogicalPlan is still an abstract class. According to the number of child nodes, most logicalplans can be divided into three types: leaf node type (no child nodes), UnaryNode type (only one child node) and binary node type (including two child nodes). The class structure relationship is shown in the following figure:
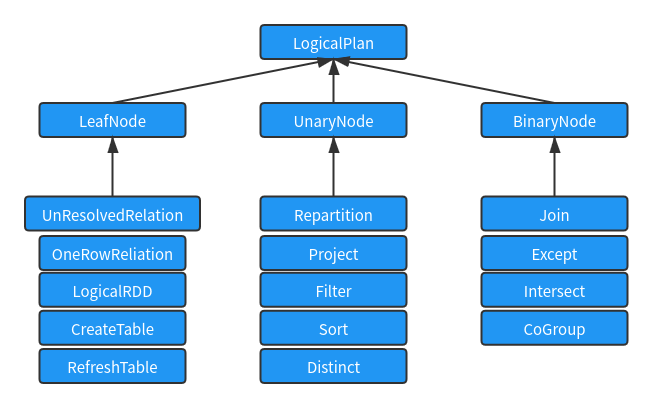
The LogicalPlan node of the LeafNode type corresponds to the data Table and Command (Command) related logic, so a large part of these {LeafNode subclasses belong to datasources package and comand package. There are 12 cases related to commands, including database related commands, Table related commands, View related commands, DDL related commands, Function related commands and Resource related commands
The Unary LogicalPlan indicates that the node is a non leaf node, but has only one child node. It is used to convert the data of the obtained child nodes, such as Sort, Filter, Distinct, Sample, etc
The BinaryNode type LogicalPlan indicates that the node has two child nodes, the most common of which is Join.
Logically, the access operation to the root node will recursively access its child nodes (ctx.statement, which is the StatementDefaultContext node by default). In this way, it will be called recursively step by step until a LogicalPlan can be constructed when accessing a child node, and then passed to the parent node. Therefore, the returned results can be converted to LogicalPlan type.
In general, the process of generating the unresolved logicalplan is shown in the following figure (the picture is reproduced from the user's knowledge):
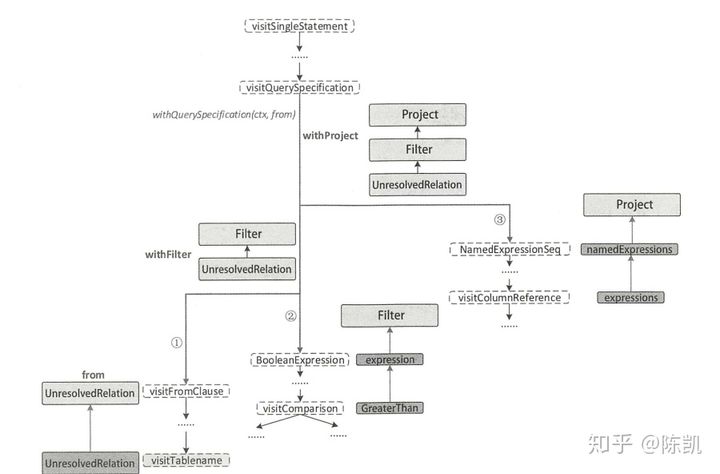
3. Generated by analyzed logicalplan
After the processing of AstBuilder in the previous stage, the Unresolved LogicalPlan has been obtained. Let's look back at sparksession SQL method code:
class SparkSession {
def sql(sqlText: String): DataFrame = {
// Call the method of the following Dataset class
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}
}
private[sql] object Dataset {
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame = {
// Call the method of the SessionState class below to generate the QueryExecution object
val qe = sparkSession.sessionState.executePlan(logicalPlan)
qe.assertAnalyzed()
new Dataset[Row](sparkSession, qe, RowEncoder(qe.analyzed.schema))
}
}
private[sql] class SessionState {
def executePlan(plan: LogicalPlan): QueryExecution = createQueryExecution(plan)
}From the above code, we can see that the sql method first obtains LogicalPlan and then calls Dataset.. The ofRows () method generates the Dataset object, and the ofRows method first calls the executePlan method of the SessionState class to generate the QueryExecution object, and then calls its assertAnalyzed method to analyze Unresolved LogicalPlan.
QueryExecution class is an important class, and its subsequent methods for generating PhysicalPlan from LogicalPlan are provided by this class.