I've written two articles about Sleuth before
Spring cloud Alibaba (13) -- sleuth overview
Spring cloud Alibaba (14) -- spring cloud Alibaba integrates Sleuth
In the last article, we saw the complete link of a request by printing the log. However, when there are more and more microservices, there will be more and more log files, and the query will become more and more troublesome. Therefore, this article is carried out through Zipkin
Link tracking. Zipkin can aggregate logs for visual display and full-text retrieval.
1, Zipkin client setup
1. Quick start
Zipkin runs through jar, so we go to the official to download the corresponding jar package
https://github.com/openzipkin/zipkin
Download the official jar package directly from the link below quick start. The current version is zipkin-server-2.23.2-exec Jar, run through java command.
java -jar zipkin-server-2.23.2-exec.jar
Access the zipkin address after startup
http://127.0.0.1:9411/zipkin/
It can be seen that Zipkin's client has been built.
Next, we add the relevant zipkin configuration to our project.
2, Spring cloudalibaba integrates Zipkin
Note that this article also integrates Zipkin based on the integration of Sleuth in the previous article, so all the code is not copied here, and the complete project code will be put on github.
1,pom.xml
Add spring cloud starter Zipkin dependency to the items requiring link tracking (service gateway, commodity service, order service).
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
2,application.yml
spring:
zipkin:
base-url: http://127.0.0.1:9411/ #zipkin address
discovery-client-enabled: false #Do not turn on service discovery
sleuth:
sampler:
probability: 1.0 #Sampling percentage
Here is the sampling percentage: if the service traffic is large, the pressure of all collection on transmission and storage is relatively large. At this time, the sampling rate can be set (if it is configured as 1.0, the sampling rate is 100%, and all tracking data of the service can be collected),
If not configured, the default sampling rate is 0.1 (i.e. 10%). Here, in order to make the demonstration more obvious later, 100% extraction is set.
3. Testing
Here, the whole request link is shown as follows:
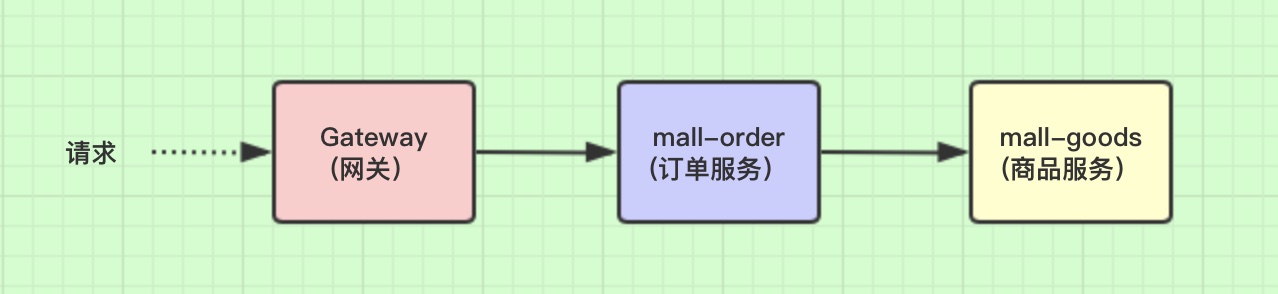
A complete link here is a request that passes through the gateway service, and then forwards it to the order micro service, and then the order micro service will call the commodity service.
The access address is as follows:
#Access order service through gateway http://localhost:8001/mall-order/api/v1/goods_order/getGoodsByFeign?goodsId=1
The request has been successful. Next, let's look at the zipkin client
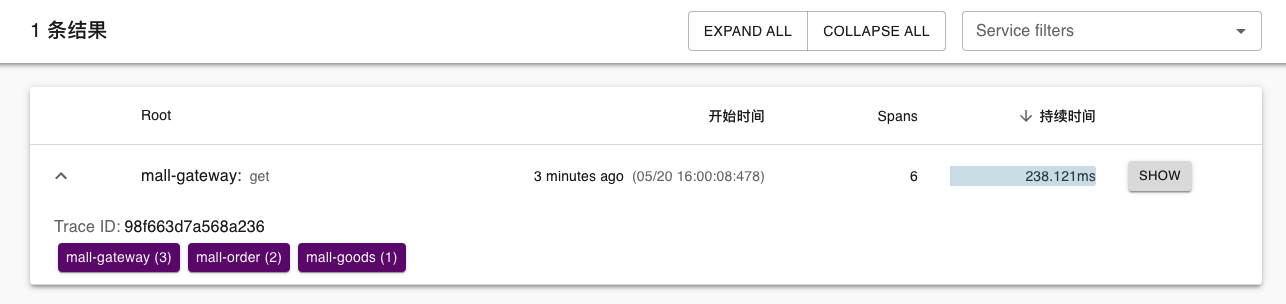
It is found that the client already has a link, and the order is mall gateway (3) - > mall order (2) - > mall goods (1), which is consistent with the order of our actual request.
At the same time, we can also see the execution time of each micro service
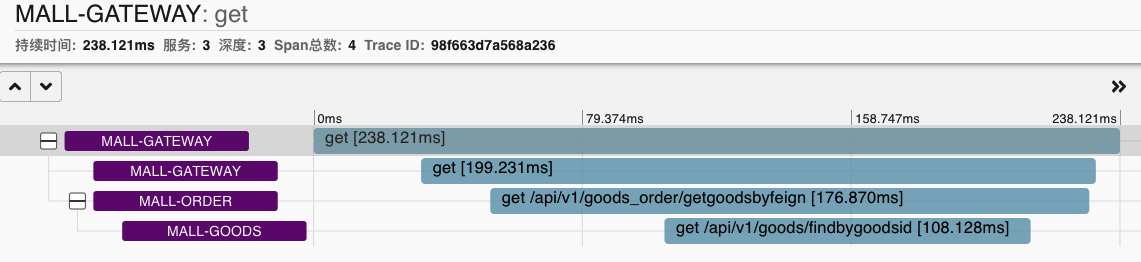
From this figure, we can see the total time spent on the whole request link and the execution time of each microservice. In this way, in the actual production scenario, if the current request response is very slow, we can see which service through the zipkin client
The execution time is slow, which leads to optimization.
3, Zipkin+Mysql persistence
Zipkin Server stores tracking data into memory by default. This method is not suitable for the production environment. Once the Server is shut down and restarted or the service crashes, the historical data will disappear. Zipkin supports modifying storage policies and using other
Storage component, supporting MySQL, Elasticsearch, etc.
1. Mysql database script
Open the MySQL database, create the zipkin library, and execute the following SQL script.
Official website address: https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
All sql statements are as follows
CREATE TABLE IF NOT EXISTS zipkin_spans ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL, `id` BIGINT NOT NULL, `name` VARCHAR(255) NOT NULL, `remote_service_name` VARCHAR(255), `parent_id` BIGINT, `debug` BIT(1), `start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL', `duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query', PRIMARY KEY (`trace_id_high`, `trace_id`, `id`) ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds'; ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames'; ALTER TABLE zipkin_spans ADD INDEX(`remote_service_name`) COMMENT 'for getTraces and getRemoteServiceNames'; ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range'; CREATE TABLE IF NOT EXISTS zipkin_annotations ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id', `span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id', `a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1', `a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB', `a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation', `a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp', `endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address', `endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null' ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds'; ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames'; ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces and autocomplete values'; ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces and autocomplete values'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job'; CREATE TABLE IF NOT EXISTS zipkin_dependencies ( `day` DATE NOT NULL, `parent` VARCHAR(255) NOT NULL, `child` VARCHAR(255) NOT NULL, `call_count` BIGINT, `error_count` BIGINT, PRIMARY KEY (`day`, `parent`, `child`) ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
2. Deploy Zipkin
The above is that we directly use Java - jar zipkin-server-2.23.2-exec Jar is started. Here, we specify the Mysql configuration information when starting
java -jar zipkin-server-2.23.2-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=localhost --MYSQL_TCP_PORT=3306 --MYSQL_USER=root --MYSQL_PASS=root --MYSQL_DB=zipkin
After startup, we can access the above interface
#Access order service through gateway http://localhost:8001/mall-order/api/v1/goods_order/getGoodsByFeign?goodsId=1
After the request is successful, we are looking at the database
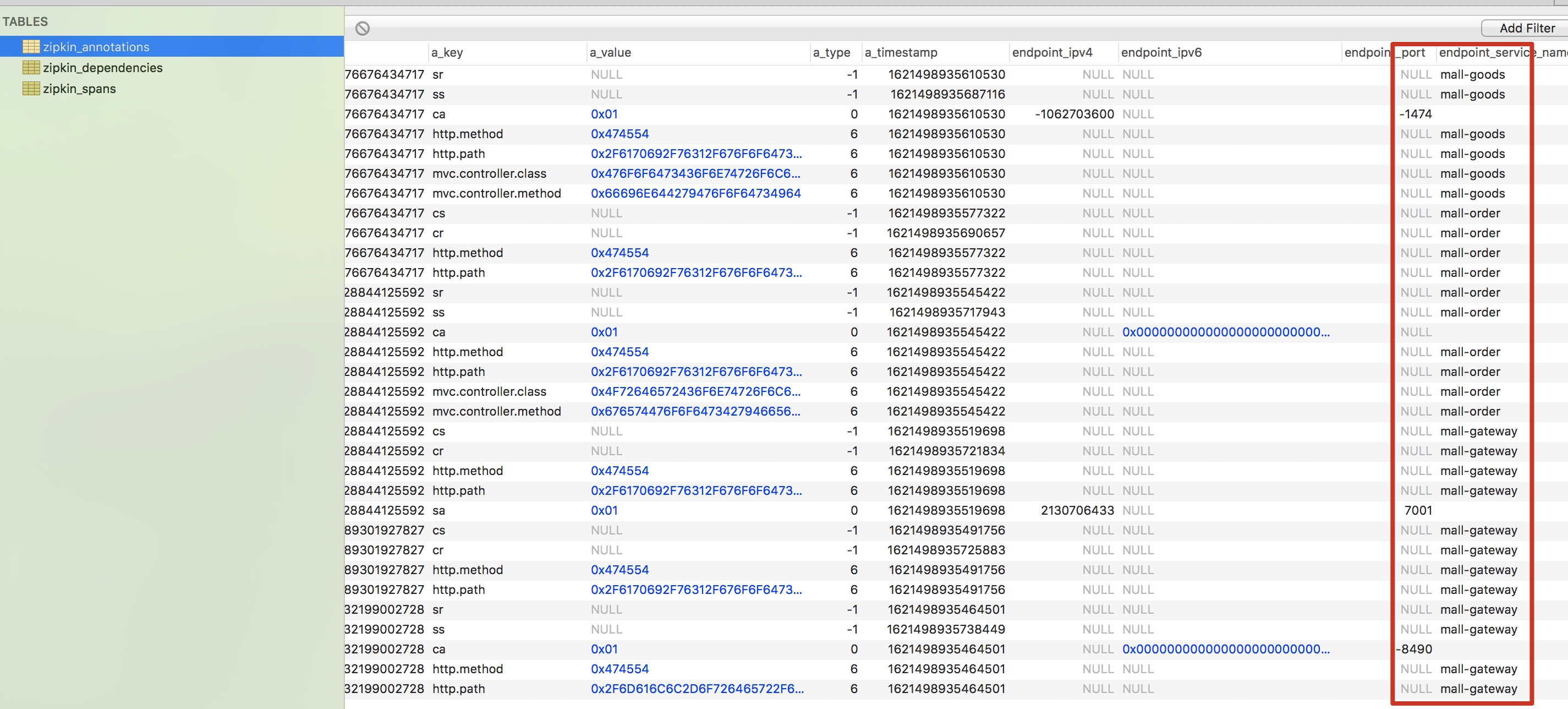
Obviously, the database has solidified the data. In this way, even if we restart zipkin, the data will not be lost, and the client can always query it.
This concludes the series of articles on Spring Cloud Alibaba. I will summarize the actual production problems encountered in the later development.
github address: Nacos feign sentinel Gatway Sleuth
Say less and do more,Every sentence will be valued by others; Say more and do less,Every sentence will be ignored by others.(15)