High frequency interview question: how does Spring solve circular dependency?
In the interview about Spring, we are often asked a question: how does Spring solve the problem of circular dependency.
This question is a high-frequency interview question about Spring, because if you don't deliberately study it, I believe that even if you have read the source code, the interviewer may not be able to think about the mystery at once.
This paper mainly aims at this problem and explains its implementation principle from the perspective of source code.
1. Process demonstration
The creation of spring beans is essentially the creation of an object. Since it is an object, readers must understand that a complete object includes two parts: the instantiation of the current object and the instantiation of object properties.
In Spring, object instantiation is realized through reflection, and object properties are set in a certain way after object instantiation.
This process can be understood as follows:
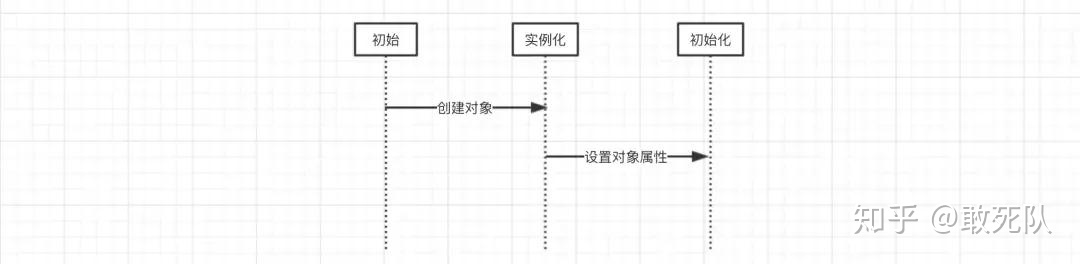
After understanding this point, the understanding of circular dependency has been A big step. Let's take two classes A and B as examples to explain, as follows are the declarations of A and B:
@Component
public class A {
private B b;
public void setB(B b) {
this.b = b;
}
}
@Component
public class B {
private A a;
public void setA(A a) {
this.a = a;
}
}
As you can see, each of A and B takes the other as their global attribute. The first thing to note here is that Spring instantiates bean s through ApplicationContext GetBean () method.
If the object to be obtained depends on another object, it will first create the current object, and then recursively call ApplicationContext GetBean () method to obtain the dependent object, and finally inject the obtained object into the current object.
Here, we will take the above example of initializing A object as an example.
First, Spring tries to use ApplicationContext The getBean () method obtains an instance of the A object. Since there is no A object instance in the Spring container, it will create an A object
Then it is found that it depends on the B object, so it will try to pass ApplicationContext recursively The getBean () method gets an instance of the B object
However, there is no instance of B object in the Spring container at this time, so it will create an instance of B object first.
Readers should pay attention to this time point. At this time, both a object and B object have been created and saved in the Spring container, but the attribute B of a object and attribute a of B object have not been set.
After Spring created the B object earlier, Spring found that the B object depends on attribute A, so it will still try to call ApplicationContext recursively The getBean () method obtains an instance of the A object
Because there is already an instance of an A object in Spring, although it is only A semi-finished product (its property b has not been initialized), it is still A target bean, so the instance of the A object will be returned.
At this point, the attribute a of the B object is set, and then the ApplicationContext The getBean () method returns recursively, that is, returns the instance of B object. At this time, the instance will be set to the property B of a object.
At this time, note that both attribute B of object a and attribute a of object B have set the instance of the target object
Readers may be confused that when setting attribute a for object B, this type a attribute is still a semi-finished product. However, it should be noted that this a is a reference, which is essentially the a object instantiated at the beginning.
At the end of the above recursive process, Spring sets the obtained B object instance to the attribute B of A object
The a object here is actually the same object as the semi-finished product a object previously set to instance B, and its reference address is the same. Here, the value is set for the B attribute of the a object, that is, the value is set for the a attribute of the semi-finished product.
Let's explain this process through a flow chart:
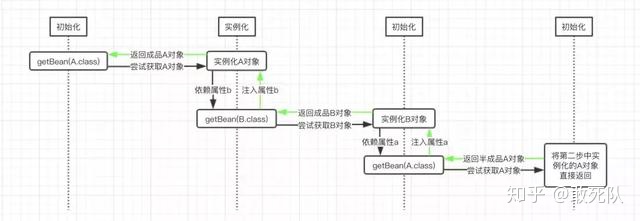
In the figure, getBean() means calling the ApplicationContext of Spring getBean() method, and the parameters in this method represent the target object we want to try to get.
The black arrow in the figure indicates the direction of the method call at the beginning. At the end, after returning the A object cached in Spring, it indicates that the recursive call has returned. At this time, it is represented by A green arrow.
We can clearly see from the figure that the a attribute of object B is the semi-finished product a object injected in the third step, and the B attribute of object a is the finished product B object injected in the second step. At this time, the a object of semi-finished product becomes the a object of finished product because its attribute has been set.
2. Explanation of source code
The way Spring handles circular dependency is actually easy to understand through the above flowchart
One thing to pay attention to is how Spring marks the start of generation. The A object is A semi-finished product, and how to save the A object.
The markup work here is saved by Spring using the ApplicationContext property setsingtonscurrentlyincreation, while the A object of the semi-finished product is saved by MapsingletonFactories
The ObjectFactory here is a factory object, and the target object can be obtained by calling its getObject() method. In abstractbeanfactory The method of obtaining objects in dogetbean() method is as follows:
protected T doGetBean(final String name, @Nullable final Class requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
// Try to get the target bean object through the bean name, such as the A object here
Object sharedInstance = getSingleton(beanName);
// The target objects here are all singletons
if (mbd.isSingleton()) {
// Here, try to create the target object. The second parameter passes an object of ObjectFactory type. Here is lamada using java 8
// The expression is written. As long as the return value of the above getSingleton() method is null, the getSingleton() method here will be called to create the
// Target object
sharedInstance = getSingleton(beanName, () -> {
try {
// Attempt to create target object
return createBean(beanName, mbd, args);
} catch (BeansException ex) {
throw ex;
}
});
}
return (T) bean;
}
The doGetBean() method here is a very key method (other code is omitted), and there are two main steps above
The function of getSingleton() method in the first step is to try to get the target object from the cache. If not, try to get the target object of semi-finished products; If the first step does not get an instance of the target object, proceed to the second step
The getSingleton() method of the second step is to try to create the target object and inject the properties it depends on.
This is actually the backbone logic. As indicated in the previous figure, the doGetBean() method will be called three times in the whole process
The first call will attempt to obtain the A object instance. At this time, the first getSingleton() method will be used. Since there is no finished product or semi-finished product of the created A object, the result here is null
Then, the second getSingleton() method will be called to create an instance of object A, and then the doGetBean() method will be called recursively to try to obtain an instance of object B and inject it into object A
At this time, since there is no finished product or semi-finished product of B object in the Spring container, we will still go to the second getSingleton() method to create an instance of B object in this method
After the creation is completed, try to get the instance of A it depends on as its property, so the doGetBean() method will still be called recursively
At this time, it should be noted that since there is already an instance of A semi-finished A object, the first getSingleton() method will be used when trying to obtain an instance of A object at this time
In this method, an instance of a semi-finished object will be obtained, and then the instance will be returned and injected into the attribute a of B object. At this time, the instantiation of B object is completed.
Then, the instantiated B object is returned recursively. At this time, the instance will be injected into the A object, so as to get A finished A object.
Here we can read the first getSingleton() method above:
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Try to get the target object of the finished product from the cache. If it exists, it will be returned directly
Object singletonObject = this.singletonObjects.get(beanName);
// If the target object does not exist in the cache, judge whether the current object is already in the process of creation. In the previous explanation, try to obtain the A object for the first time
// After the instance of A, the A object will be marked as being created, so when you finally try to obtain the A object, the if judgment here will be true
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// singletonFactories here is a Map, the key is the name of the bean, and the value is an ObjectFactory type
// Object. Here, for A and B, the getObject() method of the call graph returns instances of A and B objects, whether semi-finished or not
ObjectFactory singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// Gets an instance of the target object
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
Here, we will have A problem: how to instantiate the semi-finished instance of A, and then how to encapsulate it as an ObjectFactory object and put it in the singletonFactories attribute above.
This is mainly because in the previous second getSingleton() method, it will eventually call the createBean() method through the second parameter passed in. The final call of this method is delegated to another doCreateBean() method
There is the following code:
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// Instantiate the bean object you are trying to get, such as A object and B object, which are instantiated here
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// Judge whether Spring is configured to support exposing target beans in advance, that is, whether it supports exposing semi-finished beans in advance
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences
&& isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
// If it is supported, the currently generated semi-finished bean s will be placed in singletonFactories
// This is the singletonfactors attribute used in the first getSingleton() method, that is, here
// A place to encapsulate semi-finished beans. In essence, getEarlyBeanReference() here is the third parameter that will be directly put into, that is
// The target bean returns directly
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
try {
// After initializing the instance, this is to judge whether the current bean depends on other beans. If so,
// The getBean() method will be called recursively to try to get the target bean
populateBean(beanName, mbd, instanceWrapper);
} catch (Throwable ex) {
// Omit
}
return exposedObject;
}
So far, the whole implementation idea of Spring to solve the problem of circular dependency has been relatively clear. For the overall process, readers only need to understand two points:
- Spring obtains the target bean and the bean it depends on recursively;
- Spring instantiates a bean in two steps. First, instantiate the target bean, and then inject properties into it.
Combining these two points, that is, when Spring instantiates a bean, it first recursively instantiates all the beans it depends on until a bean does not depend on other beans. At this time, it will return the instance, and then anti recursively set the obtained beans as the properties of each upper bean.