Author: Dream Chasing 1819
Original: https://www.cnblogs.com/yanfei1819/p/10910059.html
Copyright Statement: This article is the original article of the blogger. Please attach a link to the blog article for reprinting.
Preface
In the previous chapters, we introduced ORM frameworks such as JDBCTemplate and MyBatis. Let's introduce Spring Data JPA in minimalist mode.
Spring Data JPA
brief introduction
Let's start with a few basic concepts and try to figure out the relationship between them.
1,JPA
JPA is the abbreviation of Java Persistence API, Chinese name Java Persistence API, produced by SUN Company. JDK 5.0 annotations or XML describe the mapping relationship between object and relational tables, and persist the runtime entity objects to the database.
_Its emergence aims at two aspects:
- Simplify database access layer;
- Realize the unification of ORM framework (not yet fully achieved).
2. The relationship between JPA and hibernate
JPA is an abstraction of Hibernate, like the relationship between JDBC and JDBC drivers.
JPA is an ORM specification and a subset of Hibernate functions.
Hibernate is an implementation of JPA.
3,Spring Data
As we all know, Spring is a big family, a technological ecosphere, which integrates all kinds of contents. Spring Data xxx series is the integration of data persistence layer in Spring ecosystem.
Spring Data is Spring's solution for data access. It includes a large number of relational databases and data persistence layer access solutions for NoSQL databases. It includes Spring Data JPA, Spring Data MongoDB, Spring Data Neo4j, Spring Data GernFile, Spring Data Cassandra, etc.
_At present, there are Spring-data-jpa, Spring-data-template, Spring-data-mongodb, Spring-data-redis and so on. Of course, it also includes the integration of mybatis-spring, MyBatis and Spring.
So Spring-data-jpa, the integration of Spring and JPA, appeared.
See details. Introduction to Spring Data Official Website .
4. About "dao"
In Java web projects, we often see this package name or class name with its suffix name. It represents the database persistence layer, which is short for Data Access Object. But sometimes we see mapper and so on. In fact, they all mean the same thing, representing the database persistence layer.
In JDBC emplate, you may use "dao", in MyBatis, you may use "mapper" (corresponding to xxxMapper.xml file), in JPA, you may use "repository" and so on.
In fact, the name is completely customized, but developers will have some customary habits when developing, that's all.
5,Spring Data JPA
As mentioned above, Spring Data JPA is the integration of Spring and JPA. It is based on JPA's enhanced support for database access layer. The purpose is to simplify the database access layer and reduce the workload.
See details. Spring Data JPA Official Website.
Core concepts
For developers, it's easy to use. Let's look at the core concepts of Spring Data JPA.
Repository: The top-level interface is an empty interface. The purpose is to unify all types of Repository and to automatically identify components when they are scanned.
-
CrudRepository: It is a sub-interface of Repository and provides CRUD functions.
@NoRepositoryBean public interface CrudRepository<T, ID> extends Repository<T, ID> { <S extends T> S save(S entity); <S extends T> Iterable<S> saveAll(Iterable<S> entities); Optional<T> findById(ID id); boolean existsById(ID id); Iterable<T> findAll(); Iterable<T> findAllById(Iterable<ID> ids); long count(); void deleteById(ID id); void delete(T entity); void deleteAll(Iterable<? extends T> entities); void deleteAll(); } -
JpaRepository is a sub-interface of PagingAndSorting Repository, which adds some practical functions, such as batch operation, etc.
@NoRepositoryBean public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> { List<T> findAll(); List<T> findAll(Sort var1); List<T> findAllById(Iterable<ID> var1); <S extends T> List<S> saveAll(Iterable<S> var1); void flush(); <S extends T> S saveAndFlush(S var1); void deleteInBatch(Iterable<T> var1); void deleteAllInBatch(); T getOne(ID var1); <S extends T> List<S> findAll(Example<S> var1); <S extends T> List<S> findAll(Example<S> var1, Sort var2); } -
PagingAndSorting Repository is a sub-interface of CrudRepository, which adds paging and sorting functions.
@NoRepositoryBean public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> { Iterable<T> findAll(Sort sort); Page<T> findAll(Pageable pageable); } -
Specification: It is a query specification provided by Spring Data JPA. To make complex queries, you only need to set query conditions around this specification.
public interface Specification<T> extends Serializable { long serialVersionUID = 1L; static <T> Specification<T> not(Specification<T> spec) { return Specifications.negated(spec); } static <T> Specification<T> where(Specification<T> spec) { return Specifications.where(spec); } default Specification<T> and(Specification<T> other) { return Specifications.composed(this, other, CompositionType.AND); } default Specification<T> or(Specification<T> other) { return Specifications.composed(this, other, CompositionType.OR); } @Nullable Predicate toPredicate(Root<T> var1, CriteriaQuery<?> var2, CriteriaBuilder var3); } -
Jpa Specification Executor: Used as the interface responsible for queries.
public interface JpaSpecificationExecutor<T> { Optional<T> findOne(@Nullable Specification<T> var1); List<T> findAll(@Nullable Specification<T> var1); Page<T> findAll(@Nullable Specification<T> var1, Pageable var2); List<T> findAll(@Nullable Specification<T> var1, Sort var2); long count(@Nullable Specification<T> var1); }
Use of Spring Data JPA
_Let's demonstrate the use of several JPA s.
Using built-in methods
_Build SpringBook project by introducing maven dependencies:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>Then configure the relevant information in application.properties:
server.address=
server.servlet.context-path=
server.port=8082
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://192.168.1.88:3306/test?serverTimezone=GMT%2B8
spring.datasource.username=root
spring.datasource.password=pass123
# For the first time create,Later use update
# Otherwise, every re-system engineering will delete the table before creating a new one.
spring.jpa.hibernate.ddl-auto=create
# Console Printing sql
spring.jpa.show-sql=trueNext, create the entity class User:
package com.yanfei1819.jpademo.entity;
import javax.persistence.*;
/**
* Created by Dream pursuit 1819 on 2019-05-05.
*/
@Entity
@Table(name="user")
public class User {
@Id
// Automatic field generation
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private int age;
private String name;
// set/get ellipsis
}Furthermore, create a dao layer:
package com.yanfei1819.jpademo.repository;
import com.yanfei1819.jpademo.entity.User;
import org.springframework.data.jpa.repository.JpaRepository;
/**
* Created by Dream pursuit 1819 on 2019-05-05.
*/
public interface UserRepository extends JpaRepository<User,Long> {
}Finally, create the controller layer (the service layer is omitted here to simplify the code):
package com.yanfei1819.jpademo.web.controller;
import com.yanfei1819.jpademo.entity.User;
import com.yanfei1819.jpademo.repository.UserRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.ResponseBody;
import java.util.List;
/**
* Created by Dream pursuit 1819 on 2019-05-05.
*/
@Controller
public class UserController {
@Autowired
private UserRepository userRepository;
@ResponseBody
@GetMapping("/queryUser")
public List<User> queryUser(){
// Query through jpa built-in method
return userRepository.findAll();
}
}In the above example, we use JPA's built-in method findAll(), and there are many other methods, as follows:
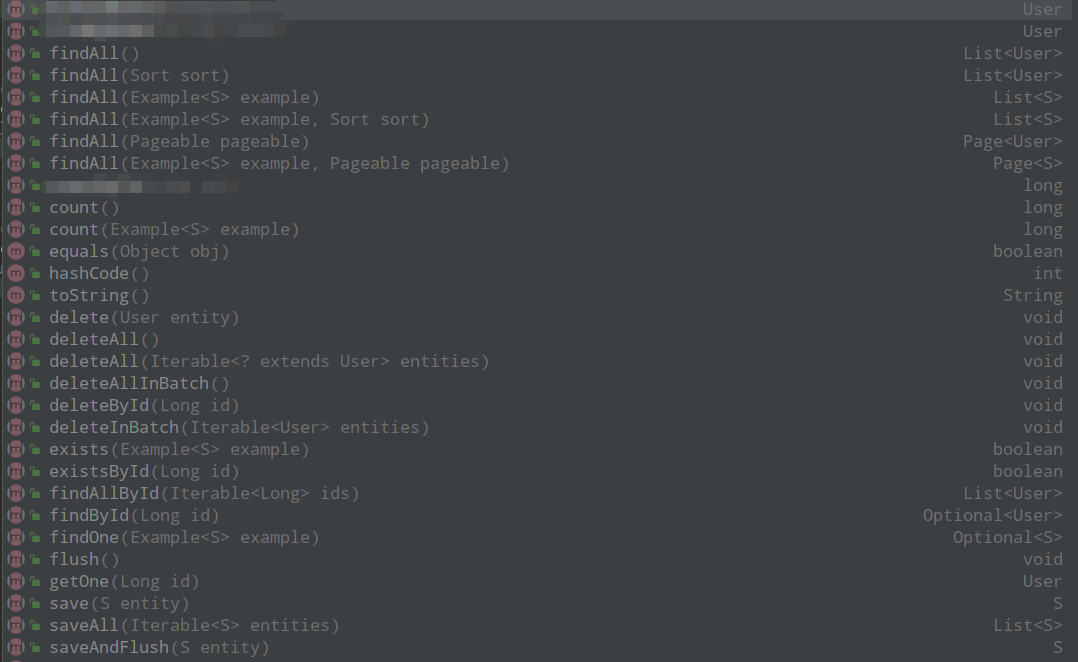
_wrote several query methods.
Create query methods
On the basis of the above examples, we add a new method:
UserController:
@ResponseBody
@GetMapping("/queryUser/{name}")
public User queryUserByName(@PathVariable String name){
// Queries through custom methods
return userRepository.findByName(name);
}UserRepository:
User findByName(String name);_spring-data-jpa automatically generates sql statements based on the name of the method. Spring Data JPA supports defining queries by defining the name of the method in the Repository interface. The name of the method is determined by the attribute name of the entity class. We just need to follow the rules defined by the method. findBy keywords can be replaced by find, read, readBy, query, queryBy, get, getBy.
_This method not only limits this simple parameter support, but also limits the results of queries returned, streaming queries returned, asynchronous queries, etc. See examples:
// Restrict query results
User findTopByOrderByAgeDesc();
Page<User> queryFirst10ByLastname(String lastname, Pageable pageable);
// Returns streaming query results
Stream<User> readAllByFirstnameNotNull();
// Asynchronous Query
@Async
Future<User> findByFirstname(String firstname); @ Query query
_Add a new method to the above example:
UserController:
@ResponseBody
@GetMapping("/queryUser2/{id}")
public User queryUserById(@PathVariable Long id){
// Query through the @Query annotation
return userRepository.withIdQuery(id);
}UserRepository:
// @Query("select u from User u where u.id = :id ")
@Query(value = "select u from User u where u.id = ?1 ",nativeQuery = true)
User withIdQuery(@Param("id") Long id);_Using this named query to declare entity query is an effective method for a small number of queries. The @Query annotation above should be noted that:
If set to true, the nativeQuery attribute in_1, @Query (value = select u from User u where u.id = 1) means that native SQL statements can be executed, so-called native sql, that is to say, this SQL is copied to the database, and then the parameter values can be run by giving them a little. The SQL generated is the real field, the real table name. If set to false, it is not the original sql, not the real table name corresponding to the database, but the corresponding entity name, and the field name in SQL is not the real field name in the database, but the field name of the entity.
_2. nativeQuery @Query ("select u from User u where u.id = 1") is false by default if it is not set.
_3, @Query ("select u from User u where u.id = 1") can be written as @Query ("select u from User u where u.id = id").
_4. If deletion and modification are involved, add @Modifying. You can also add @Transactional support for things, query timeout settings, etc.
@ NamedQuery query
In the above example, in order to distinguish the User entity class, we re-create an entity class UserVo:
package com.yanfei1819.jpademo.entity;
import javax.persistence.*;
/**
* Created by Dream chase 1819 on 2019-05-23.
*/
@Entity
@Table(name = "user")
@NamedQuery(name = "findAll",query = "select u from User u")
public class UserVo {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
@Column(name = "age")
private int age;
@Column(name = "name")
private String name;
// get/set ellipsis
}Add a method to UserController:
@Autowired
private EntityManager entityManager;
@ResponseBody
@GetMapping("/queryUserByNameQuery")
public List<UserVo> queryUserByNameQuery(){
// Query through the @Query annotation
return entityManager.createNamedQuery("findAll").getResultList();
}Start the program and visit http://localhost:8082/queryUserByNameQuery to query all users:
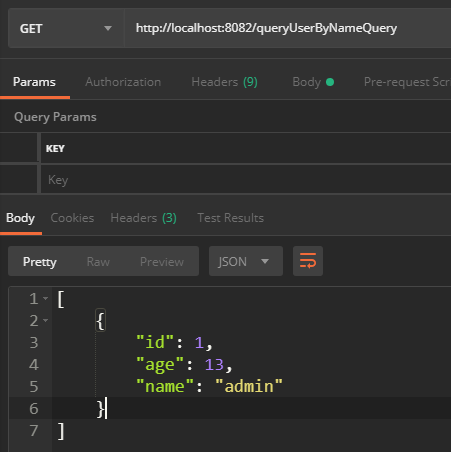
Look at the console print results again.

Note that if you have multiple queries, you can use @NamedQuerys.
In fact, the author does not recommend the use of this custom method, because it pollutes the entity class seriously. Not good for readability.
summary
JPA can be used independently, but SpringBook is a big platform to introduce this technology.
JPA is also a big branch. There are many details. The author thinks that only three aspects should be paid attention to in learning JPA.
_1) ORM maps metadata and supports two forms of metadata: XML and JDK annotations.
_2) Core API;
_3) Query Language: JPQL.
Of course, if you are interested, you can study JPA's. Official Documents Read the source code in depth. Because of the limitation of space, I will not elaborate one by one here. There will be time to open a JPA column, which will focus on this major branch, and you are welcome to continue to pay attention to it.
On the other hand, as mentioned in the previous chapters, each ORM technical framework has its own advantages and disadvantages, and none of them is absolutely perfect. The selection of technology and framework is not necessary to pursue the latest and the most suitable.
Source code: My GitHub