1, What is distributed
Distributed computing is a new computing method proposed in recent years. The so-called distributed computing is that two or more software share information with each other. These software can run on the same computer or multiple computers connected through the network.
In distributed system principles and models, it is defined as follows: "distributed system is the combination of several independent computers, which are like a single related system to users".
Distributed system is a software system based on network. It is precisely because of the characteristics of software that distributed system has high cohesion and transparency. Therefore, the difference between network and distributed system lies more in high-level software (especially operating system) than hardware.
When the performance of a single node cannot meet the service requirements and the cost of upgrading hardware is very high, we will consider the distributed system. The problems solved by distributed system and stand-alone system are the same, but because there are many distributed nodes, there will be many problems that stand-alone system does not have. In order to solve the problems brought by distributed system, new mechanisms and protocols are introduced.
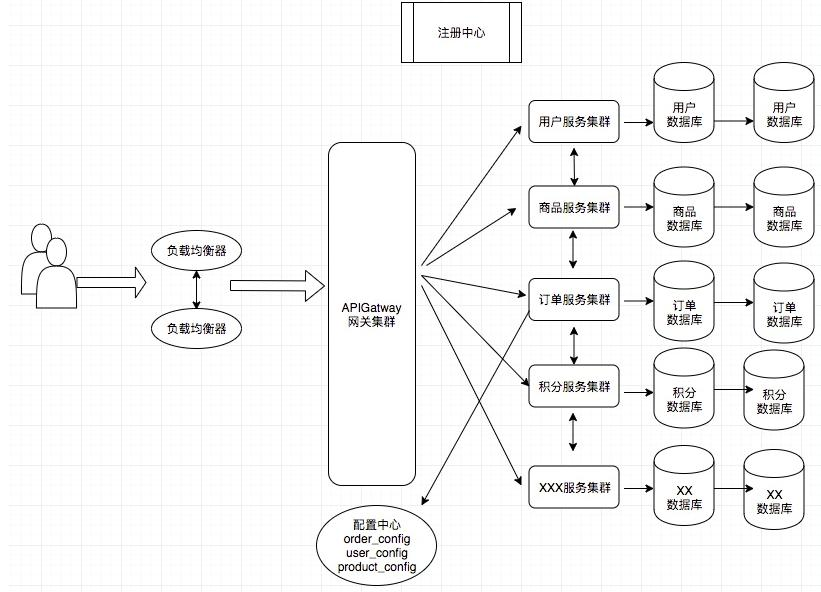
2, Evolution of application architecture
1. Single application architecture
When the traffic of the website is very small, we only need one application to deploy all functions together, so as to reduce the deployment and cost of nodes. At this time, the database access framework (ORM: Object Relational Mapping) used to simplify addition, deletion, modification and query is the key.
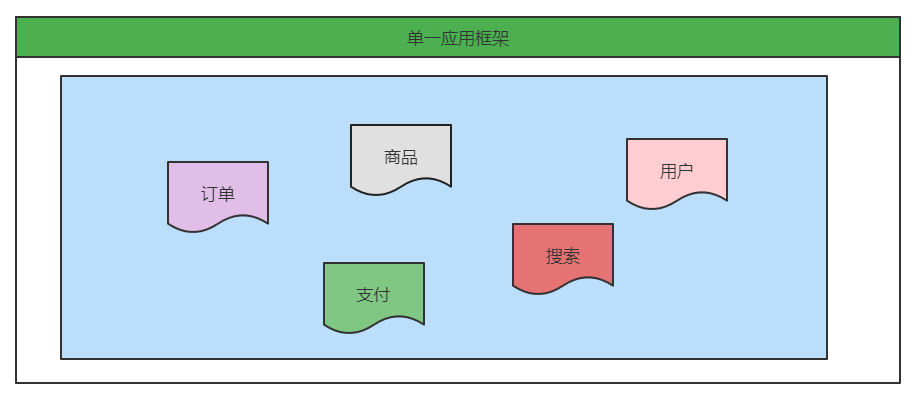
Advantages: it is suitable for small websites, and all functions are deployed to one server, which is simple and easy to use.
Disadvantages: difficult performance expansion, collaborative development problems, and not conducive to upgrade and maintenance
2. Vertical application architecture
When the traffic increases, the speed of a single application becomes smaller and smaller. We split the application into several unrelated applications to improve efficiency. Therefore, the Web framework (MVC: Model View Controller) used to accelerate front-end page development is the key.
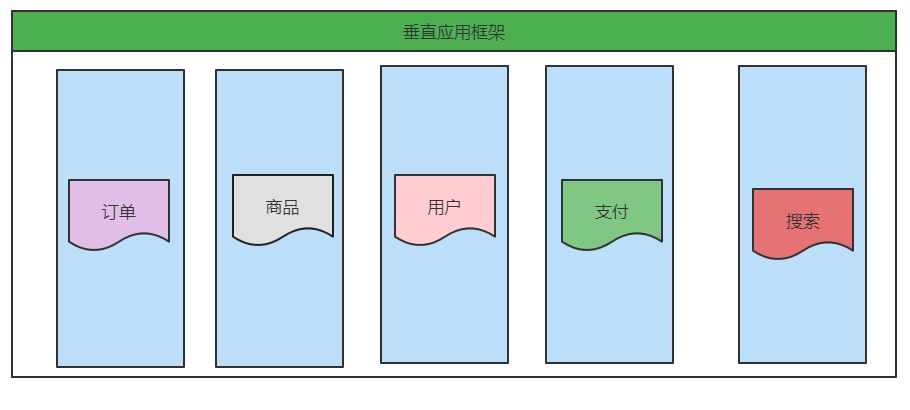
Advantages: through business segmentation, the independent deployment of functional modules is realized, the difficulty of dimension and deployment is reduced, and the performance expansion is convenient
Disadvantages: common modules cannot be reused
3. Distributed service architecture
With the increasing number of vertical applications, the interaction between applications is inevitable. The core business is separated as an independent service, and a stable service center is gradually formed, so that the front-end applications can respond to the market demand faster. At this point. The distributed service framework (RPC: Remote Procedure Call) used to improve business reuse and integration is the key.
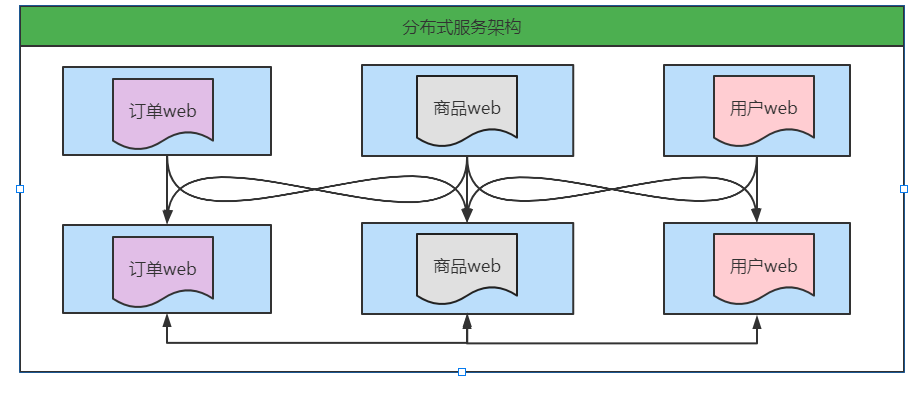
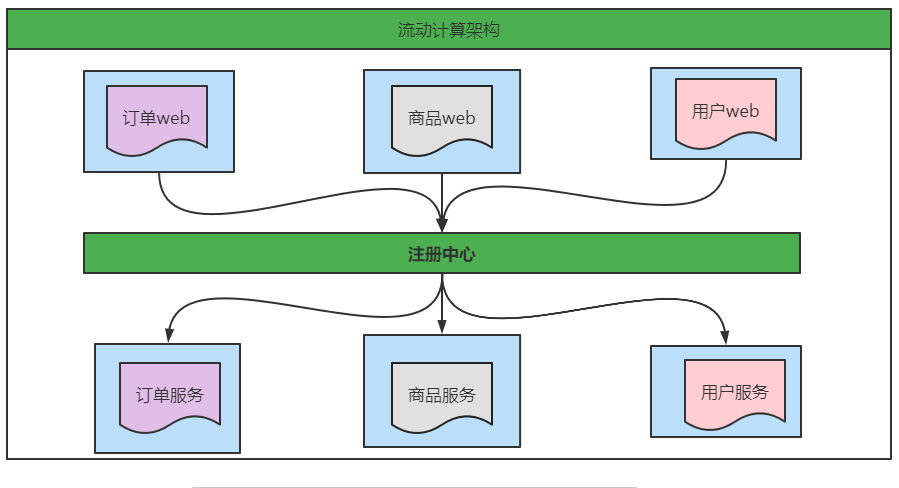
Error correction: the order web, commodity web and user web in the second line in the figure above should be changed to order service, commodity service and user service.
4. Flow computing architecture
With more and more services, problems such as capacity evaluation and waste of small service resources gradually appear. At this time, a dispatching center needs to manage the cluster capacity in real time based on the access pressure to improve the cluster utilization. At this time, the resource call center (SOA: Service Oriented architect true) used to improve the machine utilization is the key.
3, RPC
1. What is RPC
RPC (Remote Procedure Call) is a Remote Procedure Call. It is simply understood that one node (server) requests services provided by another node (server).
Local procedure call: if you need to add the age+1 of the local student object, you can implement an addAge() method to pass in the student object and return after updating the age. The function body of the local method call is specified through the function pointer.
Remote procedure call: during the above operations, if the addAge() method is on the server and the function body executing the function is on the remote machine, how can the machine be told to call this method?
-
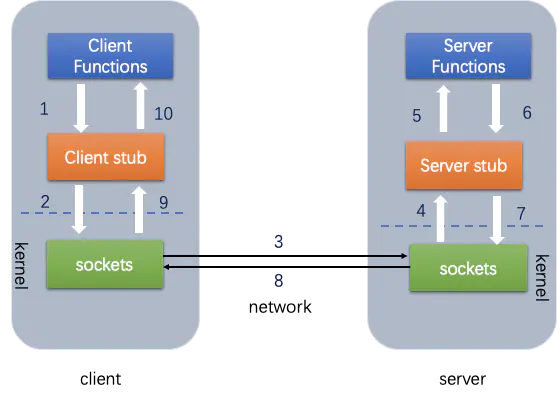
First, the client needs to tell the server the function to be called. There is a mapping between the function and the process ID. when the client calls remotely, it needs to check the function, find the corresponding ID, and then execute the code of the function.
-
The client needs to pass the local parameters to the remote function. In the process of local call, it can directly press the stack, but in the process of remote call, it is no longer in the same memory, and the parameters of the function cannot be directly passed, Therefore, the client needs to convert the parameters into a byte stream (serialization) and pass it to the server, and then the server converts the byte stream into a format that it can read (deserialization). It is a process of serialization and deserialization.
-
How to transmit the data when it is ready? The network transport layer needs to pass the calling ID and serialized parameters to the server, and then serialize the calculated results to the client. Therefore, the TCP layer can complete the above process. The HTTP 2 protocol is used in gRPC.
2. Why do I need RPC
Because the computer capability needs to be expanded horizontally, that is, the application needs to be deployed on a polymorphic computer (server) cluster. Then, a method call may not be completed in one computer (local call) and needs to be called through (remote call), so RPC is born.
4, Dubbo
1. Introduction
Dubbo is a microservice development framework, which provides two key capabilities: RPC communication and microservice governance. This means that the micro services developed by Dubbo will have mutual remote discovery and communication capabilities. At the same time, the rich service governance capabilities provided by Dubbo can realize service governance demands such as service discovery, load balancing and traffic scheduling. At the same time, Dubbo is highly scalable. Users can customize their own implementation at almost any function point to change the default behavior of the framework to meet their business needs.
Dubbo offers six core competencies:
Interface proxy oriented high-performance RPC call: it provides high-performance proxy based remote call capability. The service takes the interface as the granularity and shields the underlying details of remote call for developers.
Intelligent fault tolerance and load balancing: a variety of load balancing strategies are built in to intelligently sense the health status of downstream nodes, significantly reduce call delay and improve system throughput.
Automatic service registration and discovery: support a variety of registry services, and real-time perception of service instances on and off the line.
Highly scalable capability: following the design principle of microkernel + plug-in, all core capabilities such as Protocol, Transport and Serialization are designed as extension points, and the built-in implementation and third-party implementation are treated equally.
Traffic scheduling during operation: built in routing strategies such as conditions and scripts. By configuring different routing rules, it is easy to realize gray-scale publishing and give priority to the same computer room.
Visual service governance and operation and maintenance: provide rich service governance and operation and maintenance tools: query service metadata, service health status and call statistics at any time, issue routing policies and adjust configuration parameters in real time.
Dobbo's architecture diagram:
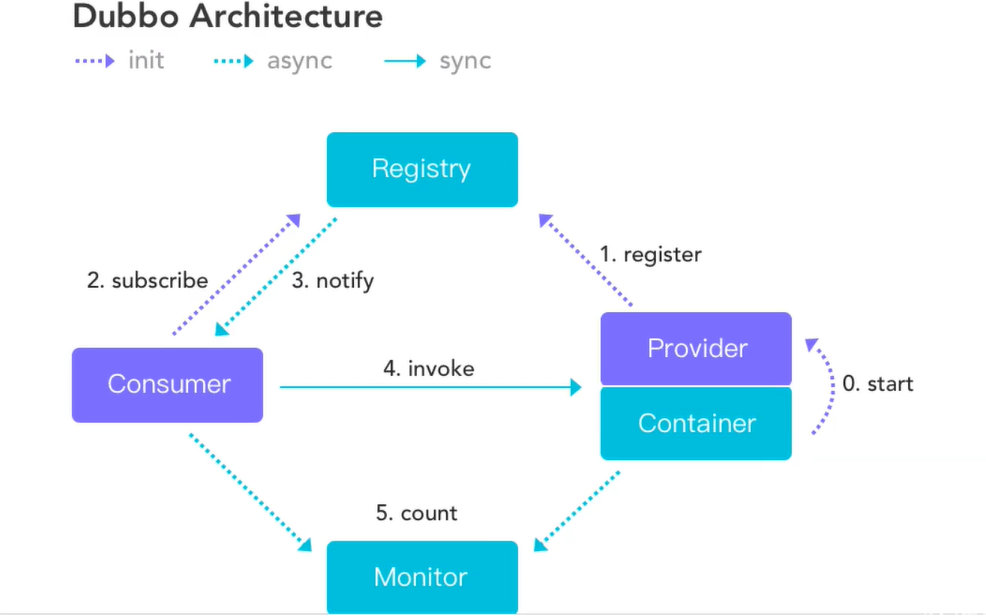
Provider: the service provider that exposes the service. The service provider registers its own service with the registry at startup.
Consumer (service consumer): the service consumer who calls the remote service. When starting, the service consumer subscribes to the registry for the services they need. The service consumer selects one provider from the provider address table based on the soft load balancing algorithm to call. If the call fails, it selects the next one.
Registry: the registry returns the service provider address list to the consumer. If there is any change, the registry will push the change data to the consumer based on the long connection.
Monitor (monitoring center): the cumulative call times and call times in memory of service consumers and providers, and regularly send statistical data to the monitoring center every minute.
2. Environment construction of Zookeeper
Zookeeper acts as a Registry in Dubbo to manage the registration and discovery of services
Step 1: Download zookeeper
Download address of zookeeper: https://dlcdn.apache.org/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
Step 2: unzip apache-zookeeper-3.7 0-bin. Tar pack

Step 3: enter apache-zookeeper-3.7 0-bin \ conf directory, copy zoo_sample.cfg and renamed zoo cfg. (if this step is not carried out, the start flash may occur)

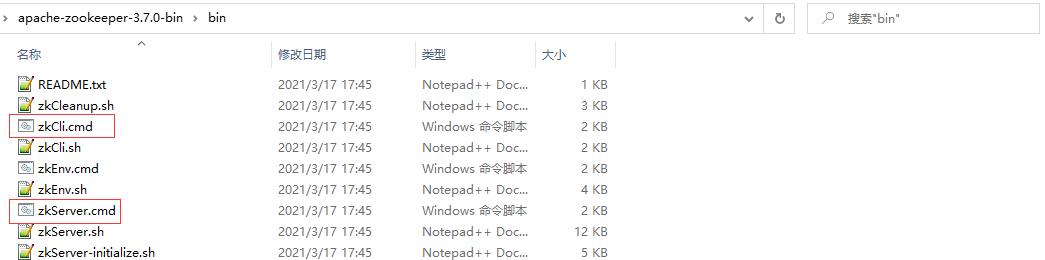
Step 4: enter apache-zookeeper-3.7 0-bin \ bin directory, double-click zkserver CMD start service; Double click zkcli CMD open client
Step 5: Test
ls /: list all nodes

create -e / node name node value: create a node and assign a value


Get / node name: get the value of the node

5, Service registration and discovery practice
In order to simulate that the service is deployed on different servers, we start two spring boot projects through two different port numbers (8081 and 8082) to achieve the simulation effect.
Premise: zookeeper is installed on the computer (server) you are using.
1. Correlation dependency
<!-- Dubbo rely on -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>2.7.8</version>
</dependency>
<!--introduce zookeeper-->
<!-- zookeeper Client dependency-->
<dependency>
<groupId>com.github.sgroschupf</groupId>
<artifactId>zkclient</artifactId>
<version>0.1</version>
</dependency>
<!-- zookeeper Server dependency -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>
<!-- zookeeper rely on -->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.14</version>
<!--Log conflicts: Exclusion slf4j-log4j12-->
<exclusions>
<exclusion>
<groupId>org.slf4j<groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
2. Create service provider
Step 1: create a springboot project
Slightly
Step 2: import dependencies in 1
Slightly
Step 3: write a service
package com.tiger.service;
public interface DemoService {
String demo();
}
@Component: the effect is the same as spring's @ Service effect.
@Service: This @ service is dubbo's @ service.
package com.tiger.service;
import org.apache.dubbo.config.annotation.Service;
import org.springframework.stereotype.Component;
@Component //After using Dubbo, we try to inject this class into the Spring container using the Component annotation,
//Do not use @ Service, because there is also a @ Service in dubbo.
@Service //It can be scanned and registered in zookeeper after the project has been started (this service is dubbo's service)
public class DemoServiceImpl implements DemoService {
@Override
public String demo() {
return "there is provider-server:DemoServiceImpl-demo()";
}
}
Step 4: configure Dubbo
dubbo.scan.base-packages=com.tiger.service: means com tiger. All services under service will be registered in zookeeper.
server.port=8081 # Service application name dubbo.application.name=provider-server # Address of Registration Center dubbo.registry.address=zookeeper://127.0.0.1:2181 # Which services are to be registered dubbo.scan.base-packages=com.tiger.service
3. Create a service consumer
Step 1: create a springboot project
Slightly
Step 2: import dependencies in 1
Slightly
Step 3: write a service
To get the services provided by the provider server, you need to go to the registration center. The function of @ Reference refers to the remote interface. Usually, we can refer to the remote interface by pom coordinates, but now we can refer to the remote interface by defining the same interface name
@Service: spring's @ service annotation
@Reference: reference remote interface
package com.tiger.service;
import org.apache.dubbo.config.annotation.Reference;
import org.springframework.stereotype.Service;
/**
* @author huxuehao
* @create 2021-08-22-15:25
*/
@Service //spring @ Service
public class UserService {
// To get the services provided by the provider server, you need to go to the registration center to get them
@Reference //Remote reference
DemoService demoService;
public String getDemo(){
return demoService.demo();
}
}
The path of this interface and the interface in 2 should be the same, and the methods inside should also be the same
package com.tiger.service;
public interface DemoService {
String demo();
}
Step 4: configure Dubbo
server.port=8082 # The consumer registration center needs to expose its own name to obtain relevant interfaces dubbo.application.name=consumer-server # Address of the registry dubbo.registry.address=zookeeper://127.0.0.1:2181
Step 5: write front-end test interface
package com.tiger.controller;
import com.tiger.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class DemoController {
@Autowired
UserService userService;
@RequestMapping("/getdemo")
public String demo(){
return userService.getDemo();
}
}
4. Testing
Now our environment and simple cases have been built, and the service has been started for testing
Step 1: start zookeeper
Step 2: start the service provider application
Slightly
Step 2: start the service consumer application
Slightly
Test successful:

As long as we work in one direction, everything will become handy
