Introduction: Course Overview
Reprint (invasion and deletion): https://gitee.com/eson15/springboot_study
Course catalogue
- Introduction: Course Overview
- Lesson 01: Spring Boot development environment setup and project startup
- Lesson 02: Spring Boot returns Json data and data encapsulation
- Lesson 03: Spring Boot using slf4j for logging
- Lesson 04: project property configuration in Spring Boot
- Lesson 05: MVC support in Spring Boot
- Lesson 06: Spring Boot integrates Swagger2 to present online interface documents
- Lesson 07: Spring Boot integrates Thymeleaf template engine
- Lesson 08: Global exception handling in Spring Boot
- Lesson 09: facet AOP processing in Spring Boot
- Lesson 10: integrating MyBatis in Spring Boot
- Lesson 11: Spring Boot transaction configuration management
- Lesson 12: using listeners in Spring Boot
- Lesson 13: using interceptors in Spring Boot
- Lesson 14: integrating Redis in Spring Boot
- Lesson 15: integrating ActiveMQ in Spring Boot
- Lesson 16: integrating Shiro in Spring Boot
- Lesson 17: Lucence in Spring Boot
- Lesson 18: Spring Boot architecture in actual project development
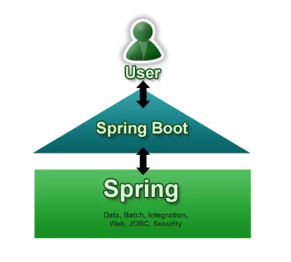
1. What is spring boot
We know that Spring has been developing rapidly since 2002, and now it has become a real standard in the development of Java EE (Java Enterprise Edition). However, with the development of technology, the use of Spring in Java EE has gradually become cumbersome, and a large number of XML files exist in the project. Cumbersome configuration and the configuration problem of integrating the third-party framework lead to the reduction of development and deployment efficiency.
In October 2012, Mike Youngstrom created a function request in Spring jira to support the container less Web application architecture in the spring framework. He talked about configuring Web container services within the main container boot spring container. This is an excerpt from jira's request:
I think Spring's Web application architecture can be greatly simplified if it provides tools and reference architecture to use Spring components and configuration model from top to bottom. Embed and unify the configuration of these common Web container services in the Spring container guided by the simple. main() method.
This requirement prompted the research and development of the Spring Boot project started in early 2013. Today, the version of Spring Boot has reached 2.0.3 RELEASE. Spring Boot is not a solution to replace spring, but a tool closely combined with the spring framework to improve the spring developer experience.
It integrates a large number of commonly used third-party library configurations. In Spring Boot applications, these third-party libraries can be almost out of the box with zero configuration. Most Spring Boot applications only need a very small amount of configuration code (Java based configuration), and developers can focus more on business logic.
2. Why learn Spring Boot
2.1 from the official point of view of Spring
We open Spring's Official website , you can see the following figure:

We can see the official positioning of Spring Boot in the figure: Build Anything, Build Anything. Spring Boot is designed to start and run as quickly as possible, with minimal pre spring configuration. At the same time, let's take a look at the official positioning of the latter two:
Spring cloud: Coordinate Anything;
SpringCloud Data Flow: Connect everything.
Carefully taste the wording of Spring Boot, Spring cloud and Spring cloud data flow on the official website of Spring. At the same time, it can be seen that Spring officials attach great importance to these three technologies and are the focus of learning now and in the future (the courses related to Spring cloud will also be launched at that time).
2.2 from the advantages of Spring Boot
What are the advantages of Spring Boot? What problems have been solved for us? Let's illustrate with the following figure:
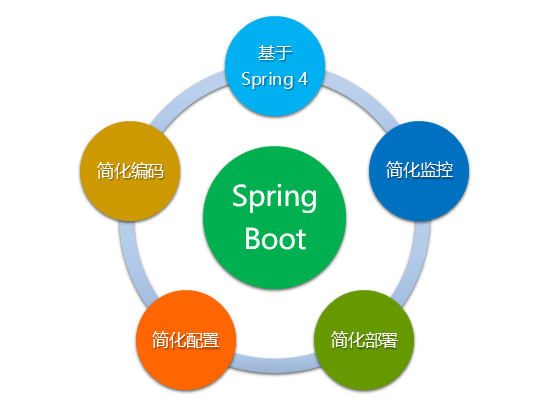
2.2.1 good genes
Spring Boot was born with Spring 4.0. Literally, Boot means Boot. Therefore, spring Boot aims to help developers quickly build the spring framework. Spring Boot inherits the excellent gene of the original spring framework, making spring more convenient and fast in use.
2.2.2 simplified coding
For example, if we want to create a web project, friends who use Spring know that when using Spring, we need to add multiple dependencies in the pom file, and Spring Boot will help develop a web container to quickly start. In Spring Boot, we just need to add the following starter web dependency in the pom file.
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency>
After clicking to enter the dependency, we can see that the starter web of Spring Boot already contains multiple dependencies, including those that need to be imported in the Spring project. Let's take a look at some of them, as follows:
<!-- .....Omit other dependencies -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>5.0.7.RELEASE</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.0.7.RELEASE</version>
<scope>compile</scope>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
It can be seen that Spring Boot greatly simplifies our coding. We don't need to import dependencies one by one, just one dependency.
2.2.3 simplified configuration
Although spring makes Java EE a lightweight framework, it was once considered a "configuration hell" because of its cumbersome configuration. Various XML and Annotation configurations will dazzle people, and if there are many configurations, it is difficult to find the reason if there is an error. Spring Boot uses Java Config to configure spring. for instance:
I create a new class, but I don't need @ Service annotation, that is, it is an ordinary class. So how can we make it a Bean and let Spring manage it? Only @ Configuration , and @ Bean annotations are required, as follows:
public class TestService {
public String sayHello () {
return "Hello Spring Boot!";
}
}
- 1
- 2
- 3
- 4
- 5
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class JavaConfig {
@Bean
public TestService getTestService() {
return new TestService();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
@Configuration indicates that this class is a configuration class, @ Bean indicates that this method returns a Bean. In this way, TestService is managed by Spring as a Bean. In other places, if we need to use the Bean, we can use it directly by injecting @ Resource annotation as before, which is very convenient.
@Resource private TestService testService;
- 1
- 2
In addition, in terms of deployment configuration, the original Spring has multiple xml and properties configurations, and only one application is required in Spring Boot YML is enough.
2.2.4 simplified deployment
When using Spring, we need to deploy tomcat on the server during project deployment, and then type the project into a war package and throw it into tomcat. After using Spring Boot, we don't need to deploy tomcat on the server, because tomcat is embedded in Spring Boot. We only need to type the project into a jar package and use Java - jar XXX Jar one click launch project.
In addition, it also reduces the basic requirements for the operating environment. JDK can be included in the environment variable.
2.2.5 simplified monitoring
We can introduce the Spring Boot start actor dependency and directly use REST to obtain the runtime performance parameters of the process, so as to achieve the purpose of monitoring, which is more convenient. However, Spring Boot is only a micro framework, which does not provide the corresponding supporting functions of service discovery and registration, no peripheral monitoring integration scheme, and no peripheral security management scheme. Therefore, Spring Cloud is also required to be used together in the micro service architecture.
2.3 from the perspective of future development trend
Microservices are the trend of future development. The project will slowly shift from traditional architecture to microservice architecture, because microservices can enable different teams to focus on a smaller range of work responsibilities, use independent technologies, and deploy more safely and frequently. It inherits the excellent features of spring, comes down in one continuous line with spring, and supports the implementation of various rest APIs. Spring Boot is also a technology strongly recommended by the government. It can be seen that Spring Boot is a general trend in the future.
3. What can be learned from this course
This course uses the latest version of Spring Boot 2.0.3 RELEASE. The course articles are scenes and demo s separated from the actual project by the author. The goal is to lead learners to quickly get started with Spring Boot and quickly apply Spring Boot related technical points to microservice projects. The whole chapter is divided into two parts: basic chapter and advanced chapter.
The basic part (lessons 01-10) mainly introduces some of the most commonly used function points of Spring Boot in projects, which aims to lead learners to quickly master the knowledge points needed in the development of Spring Boot and be able to apply Spring Boot related technologies to the actual project architecture. This part takes the Spring Boot framework as the main line, including Json data encapsulation, logging, attribute configuration MVC Support, online documents, template engine, exception handling, AOP processing, persistence layer integration, etc.
The advanced part (lessons 11-17) mainly introduces the technical points of Spring Boot in the project, including some integrated components, in order to lead learners to quickly integrate and complete the corresponding functions when they encounter specific scenes in the project. This part takes the Spring Boot framework as the main line, including interceptors, listeners, caching, security authentication, word segmentation plug-ins, message queues and so on.
After carefully reading this series of articles, learners will quickly understand and master the most commonly used technical points of Spring Boot in the project. At the end of the course, the author will build an empty architecture of Spring Boot project based on the course content. This architecture is also separated from the actual project, and learners can use this architecture in the actual project, Have the ability to use Spring Boot for actual project development.
All source codes of the course are available for free download: Download address.
5. The course development environment and plug-ins
The development environment of this course:
- Development tool: IDEA 2017
- JDK version: JDK 1.8
- Spring Boot version: 2.0.3 RELEASE
- Maven version: 3.5.2
Plug ins involved:
- FastJson
- Swagger2
- Thymeleaf
- MyBatis
- Redis
- ActiveMQ
- Shiro
- Lucence
Lesson 01: Spring Boot development environment setup and project startup
The previous section introduced the features of Spring Boot. This section mainly explains and analyzes the configuration of Spring Boot jdk, the construction and startup of Spring Boot project, and the structure of Spring Boot project.
1. jdk configuration
This course is developed using the IDEA. The way to configure jdk in the IDEA is very simple. Open file - > project structure, as shown in the following figure:
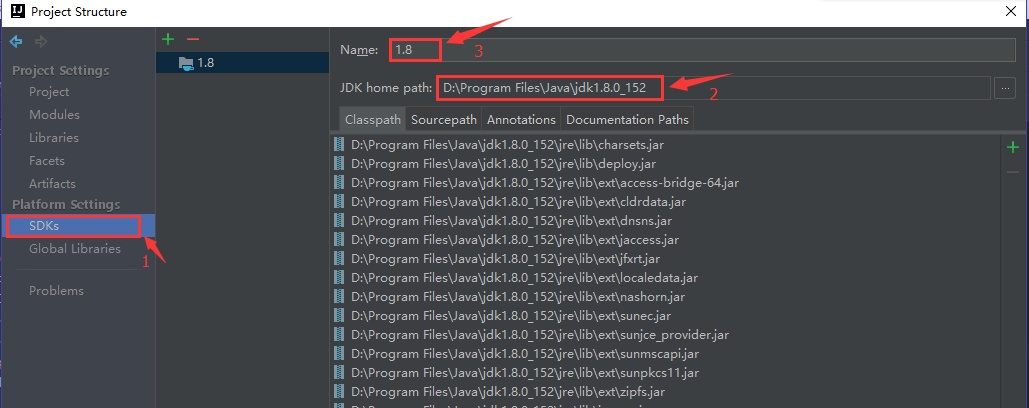
- Select SDKs
- Select the installation directory of the local jdk in JDK home path
- Custom Name for jdk in Name
Through the above three steps, you can import the locally installed jdk. If you are a friend Using STS or eclipse, you can add it in two steps:
- Window - > preference - > java - > guided jres to add local jdk s.
- Window -- > preference -- > java -- > compiler selects jre, which is consistent with jdk.
2. Construction of spring boot project
2.1 IDEA quick build
In IDEA, you can quickly build a Spring Boot project through file - > New - > project. As follows, select Spring Initializr, select the jdk we just imported in the Project SDK, and click Next to the project configuration information.
- Group: fill in the enterprise domain name. This course uses com itcodai
- Artifact: fill in the project name. The project name of each course in this course is based on the command of course + course number. course01 is used here
- Dependencies: you can add the dependency information required in our project according to the actual situation. This course only needs to select Web.
2.2 official construction
The second method can be built through official. The steps are as follows:
- visit http://start.spring.io/ .
- Enter the corresponding Spring Boot version, Group and Artifact information and project dependencies on the page, and then create the project.
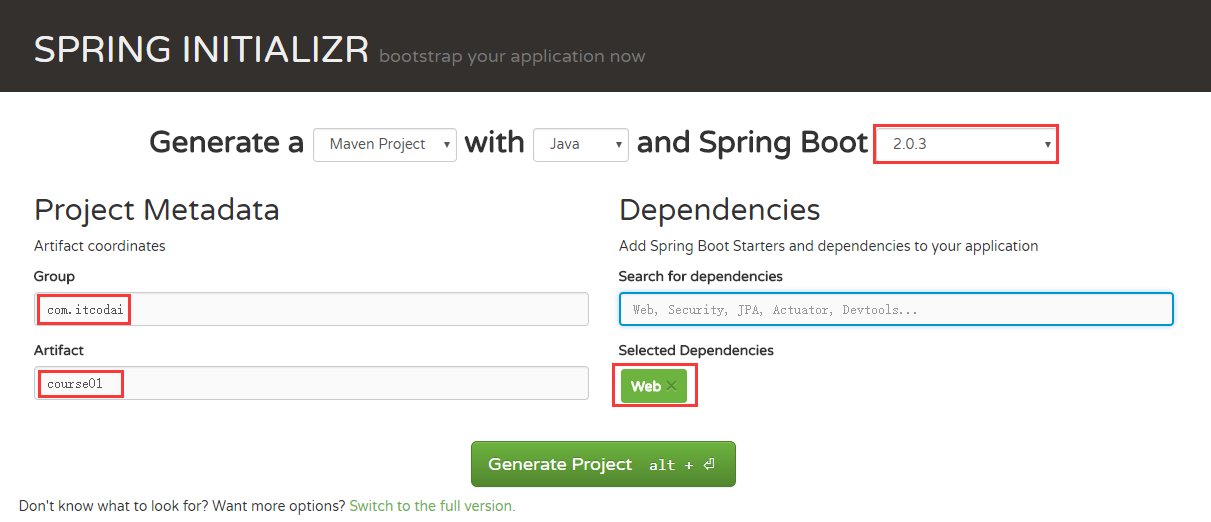
- After decompression, use IDEA to import the maven project: File - > New - > model from existing source, and then select the extracted project folder. If you are a friend using eclipse, you can import - > existing maven Projects - > next, and then select the extracted project folder.
2.3 maven configuration
After creating the Spring Boot project, you need to configure Maven. Open file - > settings, search maven, and configure the local Maven information. As follows:
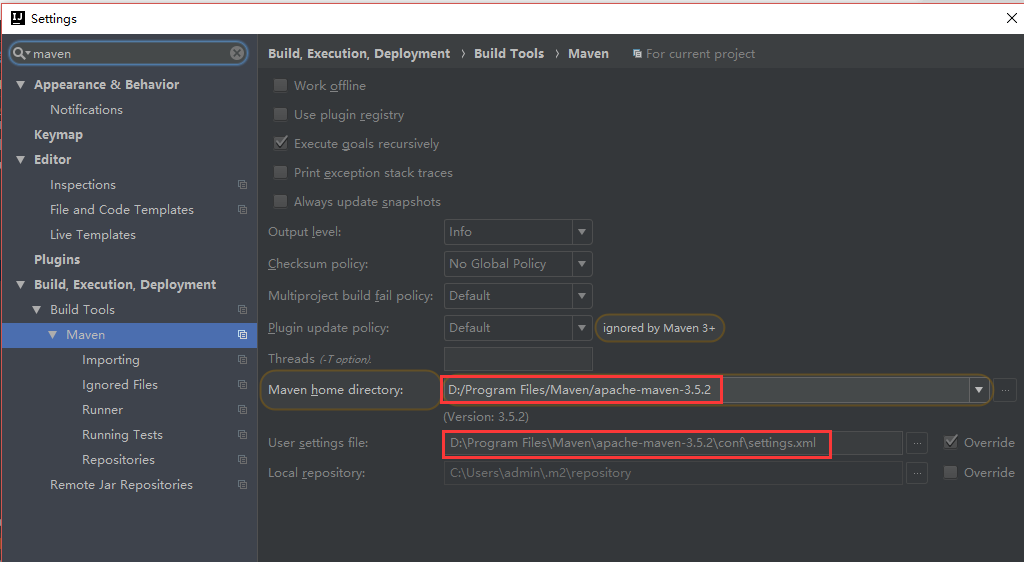
Select the installation path of local Maven in Maven home directory; In User settings file, select the path where the local Maven configuration file is located. In the configuration file, we configure the image of domestic Alibaba, so that the download speed of Maven dependency is very fast.
<mirror> <id>nexus-aliyun</id> <mirrorOf>*</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror>
- 1
- 2
- 3
- 4
- 5
- 6
If you are a friend using eclipse, you can configure it through window -- > preference -- > Maven -- > user settings in the same way as above.
2.4 coding configuration
Similarly, after a new project is created, we generally need to configure coding, which is very important. Many beginners will forget this step, so we should form good habits.
In IDEA, still open file - > settings, search encoding, and configure the local encoding information. As follows:
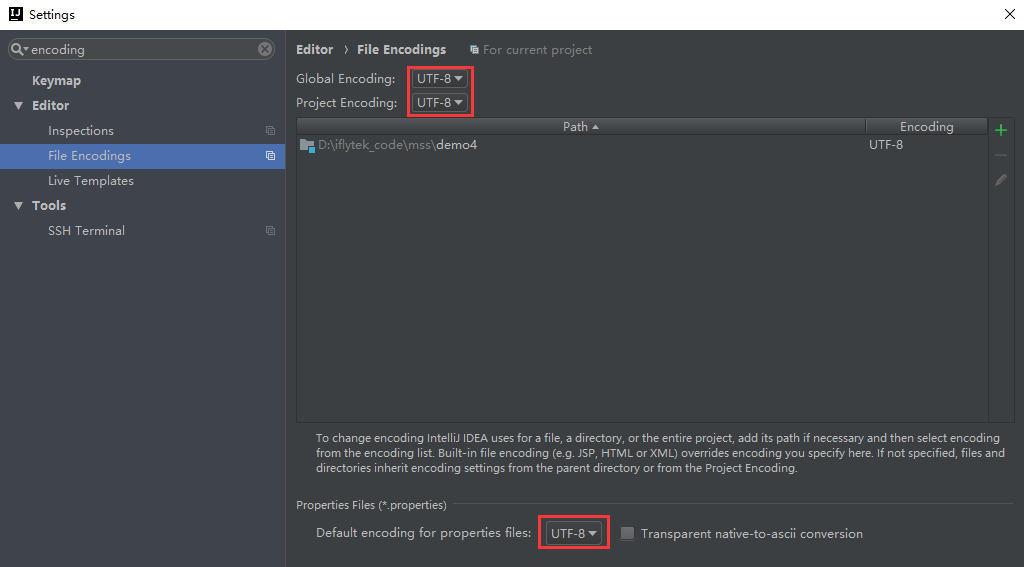
If you are a friend using eclipse, you need to set the following code in two places:
- window – > qualifications – > General – > workspace, change Text file encoding to utf-8
- window – > privileges – > General – > content types, select Text, and fill Default encoding in utf-8
OK, after the code setting is completed, the project can be started.
3. Engineering structure of spring boot project
The Spring Boot project has three modules in total, as shown in the following figure:
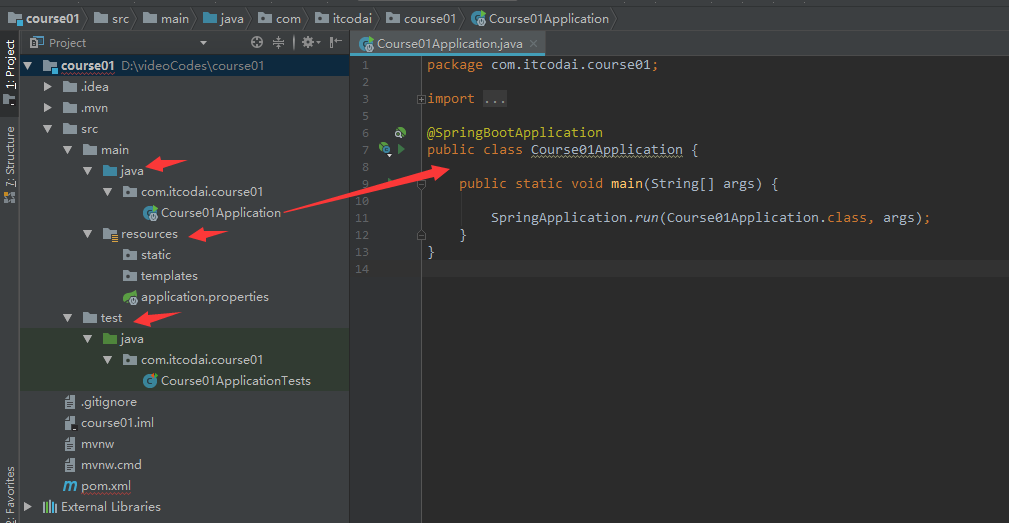
- src/main/java path: mainly write business programs
- src/main/resources path: store static files and configuration files
- src/test/java path: mainly write test programs
By default, as shown in the above figure, a startup class Course01Application will be created. There is a @ SpringBootApplication annotation on this class, and there is a main method in this startup class. Yes, it is very convenient to start Spring Boot by running the main method. In addition, tomcat is integrated in Spring Boot. We don't need to manually configure tomcat. Developers only need to pay attention to the specific business logic.
So far, the Spring Boot has been started successfully. In order to see the effect clearly, we write a Controller to test it, as follows:
package com.itcodai.course01.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/start")
public class StartController {
@RequestMapping("/springboot")
public String startSpringBoot() {
return "Welcome to the world of Spring Boot!";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Re run the main method to start the project, enter "localhost:8080/start/springboot" in the browser, and if you see "Welcome to the world of Spring Boot!", Congratulations on the successful launch of the project! Spring Boot is so simple and convenient! The default port number is 8080. If you want to modify it, you can click application Use {server. In the YML file Port to specify the port artificially, such as 8001 port:
server: port: 8001
- 1
- 2
4. Summary
In this section, we quickly learned how to import jdk in IDEA, how to configure maven and coding using IDEA, and how to quickly create and start Spring Boot projects. IDEA's support for Spring Boot is very friendly. I suggest you use IDEA to develop Spring Boot. From the next lesson, we will really enter the learning of Spring Boot.
Course source code download address: Poke me to download
Lesson 02: Spring Boot returns Json data and data encapsulation
In the project development, the data transmission between interfaces and between front and rear ends uses the Json format. In Spring Boot, the interface returns data in the Json format. You can use the @ RestController annotation in the Controller to return data in the Json format. The @ RestController is also a new annotation in Spring Boot, Let's click in to see what the annotation contains.
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Controller
@ResponseBody
public @interface RestController {
String value() default "";
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
It can be seen that the @ respontroller 'annotation contains the original @ Controller' and @ ResponseBody 'annotations. Friends who have used Spring have a good understanding of the @ Controller' annotation, which will not be repeated here. The @ ResponseBody 'annotation is to convert the returned data structure into Json format. Therefore, by default, the @ RestController annotation is used to convert the returned data structure into Json format. The default Json parsing technology framework used in Spring Boot is jackson. Let's open POM For the Spring Boot starter web dependency in XML, you can see a Spring Boot starter Json dependency:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-json</artifactId>
<version>2.0.3.RELEASE</version>
<scope>compile</scope>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
Spring Boot has well encapsulated dependencies. You can see many dependencies of Spring Boot starter XXX series. This is one of the characteristics of Spring Boot. There is no need to introduce many related dependencies artificially. Starter XXX series directly contains the necessary dependencies, so we click the above Spring Boot starter JSON dependency again, You can see:
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.6</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jdk8</artifactId>
<version>2.9.6</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
<version>2.9.6</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.module</groupId>
<artifactId>jackson-module-parameter-names</artifactId>
<version>2.9.6</version>
<scope>compile</scope>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
So far, we know that the default JSON parsing framework used in Spring Boot is jackson. Let's take a look at the conversion of common data types to JSON by the default jackson framework.
1. Spring Boot handles Json by default
In actual projects, the commonly used data structures are all class objects, List objects and Map objects. Let's take a look at the format of the default jackson framework after converting these three commonly used data structures into json.
1.1 create User entity class
To test, we need to create an entity class. Here we will use User to demonstrate.
public class User {
private Long id;
private String username;
private String password;
/* Omit get, set, and construction methods with parameters */
}
- 1
- 2
- 3
- 4
- 5
- 6
1.2 create Controller class
Then we create a Controller and return the User object, list < User > and map < string, Object > respectively.
import com.itcodai.course02.entity.User;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@RestController
@RequestMapping("/json")
public class JsonController {
@RequestMapping("/user")
public User getUser() {
return new User(1, "Ni Shengwu", "123456");
}
@RequestMapping("/list")
public List<User> getUserList() {
List<User> userList = new ArrayList<>();
User user1 = new User(1, "Ni Shengwu", "123456");
User user2 = new User(2, "Talent class", "123456");
userList.add(user1);
userList.add(user2);
return userList;
}
@RequestMapping("/map")
public Map<String, Object> getMap() {
Map<String, Object> map = new HashMap<>(3);
User user = new User(1, "Ni Shengwu", "123456");
map.put("Author information", user);
map.put("Blog address", "http://blog.itcodai.com");
map.put("CSDN address", "http://blog.csdn.net/eson_15");
map.put("Number of fans", 4153);
return map;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
1.3 test json returned by different data types
OK, the interface is written, and a User object, a List set and a Map set are returned respectively. The value in the Map set contains different data types. Next, let's test the effect in turn.
Enter localhost:8080/json/user in the browser, and the returned json is as follows:
{"id":1,"username":"Ni Shengwu","password":"123456"}
- 1
Enter localhost:8080/json/list in the browser, and the returned json is as follows:
[{"id":1,"username":"Ni Shengwu","password":"123456"},{"id":2,"username":"Talent class","password":"123456"}]
- 1
Enter localhost:8080/json/map in the browser, and the returned json is as follows:
{"Author information":{"id":1,"username":"Ni Shengwu","password":"123456"},"CSDN address":"http://blog.csdn.net/eson_15 "," number of fans ": 4153," blog address ": http://blog.itcodai.com "}
- 1
It can be seen that no matter what data type is in the map, it can be converted to the corresponding json format, which is very convenient.
1.4 handling of null in Jackson
In actual projects, we will inevitably encounter some null values. When we convert json, we don't want these null values to appear. For example, we expect all nulls to become empty strings such as "" when we convert json. What should we do? In Spring Boot, we can configure it to create a jackson configuration class:
import com.fasterxml.jackson.core.JsonGenerator;
import com.fasterxml.jackson.databind.JsonSerializer;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializerProvider;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.http.converter.json.Jackson2ObjectMapperBuilder;
import java.io.IOException;
@Configuration
public class JacksonConfig {
@Bean
@Primary
@ConditionalOnMissingBean(ObjectMapper.class)
public ObjectMapper jacksonObjectMapper(Jackson2ObjectMapperBuilder builder) {
ObjectMapper objectMapper = builder.createXmlMapper(false).build();
objectMapper.getSerializerProvider().setNullValueSerializer(new JsonSerializer<Object>() {
@Override
public void serialize(Object o, JsonGenerator jsonGenerator, SerializerProvider serializerProvider) throws IOException {
jsonGenerator.writeString("");
}
});
return objectMapper;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
Then we modify the interface of the map returned above and change several values to null to test:
@RequestMapping("/map")
public Map<String, Object> getMap() {
Map<String, Object> map = new HashMap<>(3);
User user = new User(1, "Ni Shengwu", null);
map.put("Author information", user);
map.put("Blog address", "http://blog.itcodai.com");
map.put("CSDN address", null);
map.put("Number of fans", 4153);
return map;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Restart the project and enter: localhost:8080/json/map again. You can see that jackson has turned all null fields into empty strings.
{"Author information":{"id":1,"username":"Ni Shengwu","password":""},"CSDN address":"","Number of fans":4153,"Blog address":"http://blog.itcodai.com"}
- 1
2. Use Alibaba fastjason settings
2.1 comparison between Jackson and fastjason
Many friends are used to using Alibaba's fastjason for json conversion in the project. At present, Alibaba's fastjason is used in our project. What are the differences between jackson and fastjason? The following table is obtained according to the comparison of information published online.
| option | fastJson | jackson |
|---|---|---|
| Ease of use | easily | secondary |
| Advanced feature support | secondary | rich |
| Official documents, Example support | chinese | english |
| Processing json speed | Slightly faster | fast |
There are a lot of information about the comparison between fastjason and jackson on the Internet, mainly to select the appropriate framework according to their actual project situation. From the perspective of expansion, fastjason is not as flexible as jackson. From the perspective of speed or starting difficulty, fastjason can be considered. Alibaba's fastjason is currently used in our project, which is very convenient.
2.2 fastjason dependency import
Using fastjason requires importing dependencies. This course uses version 1.2.35. The dependencies are as follows:
<dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.35</version> </dependency>
- 1
- 2
- 3
- 4
- 5
2.2 using fastjason to handle null
When using fastjason, the processing of null is somewhat different from jackson. We need to inherit the WebMvcConfigurationSupport class, and then override the configureMessageConverters method. In the method, we can select and configure the scenario to realize null conversion. As follows:
import com.alibaba.fastjson.serializer.SerializerFeature;
import com.alibaba.fastjson.support.config.FastJsonConfig;
import com.alibaba.fastjson.support.spring.FastJsonHttpMessageConverter;
import org.springframework.context.annotation.Configuration;
import org.springframework.http.MediaType;
import org.springframework.http.converter.HttpMessageConverter;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurationSupport;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
@Configuration
public class fastJsonConfig extends WebMvcConfigurationSupport {
/**
* Use Ali FastJson as JSON MessageConverter
* @param converters
*/
@Override
public void configureMessageConverters(List<HttpMessageConverter<?>> converters) {
FastJsonHttpMessageConverter converter = new FastJsonHttpMessageConverter();
FastJsonConfig config = new FastJsonConfig();
config.setSerializerFeatures(
// Leave empty fields
SerializerFeature.WriteMapNullValue,
// Convert null of String type to ''
SerializerFeature.WriteNullStringAsEmpty,
// Convert null of type Number to 0
SerializerFeature.WriteNullNumberAsZero,
// Convert null of List type to []
SerializerFeature.WriteNullListAsEmpty,
// Convert null of Boolean type to false
SerializerFeature.WriteNullBooleanAsFalse,
// Avoid circular references
SerializerFeature.DisableCircularReferenceDetect);
converter.setFastJsonConfig(config);
converter.setDefaultCharset(Charset.forName("UTF-8"));
List<MediaType> mediaTypeList = new ArrayList<>();
// To solve the problem of Chinese garbled code is equivalent to adding an attribute products = "application / JSON" to @ RequestMapping on the Controller
mediaTypeList.add(MediaType.APPLICATION_JSON);
converter.setSupportedMediaTypes(mediaTypeList);
converters.add(converter);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
3. Encapsulate the unified returned data structure
The above are some representative examples of json returned by Spring Boot, but in actual projects, in addition to encapsulating data, we often need to add some other information to the returned json, such as returning some status codes and returning some msg to the caller, so that the caller can make some logical judgments according to the code or MSG. Therefore, in the actual project, we need to encapsulate a unified json return structure to store the return information.
3.1 define a unified json structure
Because the type of encapsulated json data is uncertain, we need to use generics when defining a unified json structure. The attributes in the unified json structure include data, status code and prompt information. The construction method can be added according to the actual business needs. Generally speaking, there should be a default return structure and a user specified return structure. As follows:
public class JsonResult<T> {
private T data;
private String code;
private String msg;
/**
* If no data is returned, the default status code is 0 and the prompt message is: operation succeeded!
*/
public JsonResult() {
this.code = "0";
this.msg = "Operation succeeded!";
}
/**
* If no data is returned, you can manually specify the status code and prompt information
* @param code
* @param msg
*/
public JsonResult(String code, String msg) {
this.code = code;
this.msg = msg;
}
/**
* When data is returned, the status code is 0, and the default prompt message is: operation succeeded!
* @param data
*/
public JsonResult(T data) {
this.data = data;
this.code = "0";
this.msg = "Operation succeeded!";
}
/**
* There is data return, the status code is 0, and the prompt information is manually specified
* @param data
* @param msg
*/
public JsonResult(T data, String msg) {
this.data = data;
this.code = "0";
this.msg = msg;
}
// Omit the get and set methods
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
3.2 modify the return value type and test in the Controller
Because JsonResult uses generics, all return value types can use this unified structure. In specific scenarios, you can replace generics with specific data types, which is very convenient and easy to maintain. In actual projects, encapsulation can be continued. For example, an enumeration type can be defined for status code and prompt information. In the future, we only need to maintain the data in this enumeration type (it will not be expanded in this course). According to the above JsonResult, let's rewrite the Controller as follows:
@RestController
@RequestMapping("/jsonresult")
public class JsonResultController {
@RequestMapping("/user")
public JsonResult<User> getUser() {
User user = new User(1, "Ni Shengwu", "123456");
return new JsonResult<>(user);
}
@RequestMapping("/list")
public JsonResult<List> getUserList() {
List<User> userList = new ArrayList<>();
User user1 = new User(1, "Ni Shengwu", "123456");
User user2 = new User(2, "Talent class", "123456");
userList.add(user1);
userList.add(user2);
return new JsonResult<>(userList, "Get user list succeeded");
}
@RequestMapping("/map")
public JsonResult<Map> getMap() {
Map<String, Object> map = new HashMap<>(3);
User user = new User(1, "Ni Shengwu", null);
map.put("Author information", user);
map.put("Blog address", "http://blog.itcodai.com");
map.put("CSDN address", null);
map.put("Number of fans", 4153);
return new JsonResult<>(map);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
We re-enter localhost:8080/jsonresult/user in the browser. The returned json is as follows:
{"code":"0","data":{"id":1,"password":"123456","username":"Ni Shengwu"},"msg":"Operation succeeded!"}
- 1
Enter: localhost:8080/jsonresult/list, and return json as follows:
{"code":"0","data":[{"id":1,"password":"123456","username":"Ni Shengwu"},{"id":2,"password":"123456","username":"Talent class"}],"msg":"Get user list succeeded"}
- 1
Enter: localhost:8080/jsonresult/map, and return json as follows:
{"code":"0","data":{"Author information":{"id":1,"password":"","username":"Ni Shengwu"},"CSDN address":null,"Number of fans":4153,"Blog address":"http://blog.itcodai.com"},"msg ":" operation succeeded! "}
- 1
Through encapsulation, we not only transfer the data to the front end or other interfaces through json, but also bring the status code and prompt information, which is widely used in actual project scenarios.
4. Summary
This section mainly analyzes the return of json data in Spring Boot in detail, and explains their configuration from the default jackson framework of Spring Boot to Alibaba's fastjason framework. In addition, combined with the actual project situation, the json encapsulation structure used in the actual project is summarized, and the status code and prompt information are added to make the returned json data information more complete.
Course source code download address: Poke me to download
Lesson 03: Spring Boot using slf4j for logging
In development, we often use {system out. Println () to print some information, but it's not good because it uses a lot of {system Out will increase the consumption of resources. In our actual project, slf4j's logback is used to output logs, which is very efficient. Spring Boot provides a logging system, and logback is the best choice.
1. slf4j introduction
Quote a passage from Baidu Encyclopedia:
SLF4J, the Simple Logging Facade for Java, is not a specific logging solution. It only serves a variety of logging systems. According to the official statement, SLF4J is a simple Facade for logging system, which allows end users to use their desired logging system when deploying their applications.
The general meaning of this paragraph is: you only need to write the code to record the log in a unified way, and you don't need to care about which log system and style the log is output through. Because they depend on the logging system that is bound when the project is deployed. For example, if slf4j is used to record logs in the project and log4j is bound (that is, import corresponding dependencies), the logs will be output in the style of log4j; Later, you need to output the log in the style of logback. You only need to replace log4j with logback without modifying the code in the project. This has almost zero learning cost for different log systems introduced by third-party components. Moreover, its advantages include not only this one, but also the use of concise placeholders and log level judgment.
Because sfl4j has so many advantages, Alibaba has taken slf4j as their log framework. In Alibaba Java Development Manual (official version), Article 1 of the log specification requires the use slf4j:
1. [mandatory] the API in the log system (Log4j, Logback) cannot be directly used in the application, but the API in the log framework SLF4J should be used. The log framework in facade mode is used, which is conducive to the unification of maintenance and log processing methods of various classes.
The word "mandatory" reflects the advantages of slf4j, so it is recommended to use slf4j as its own logging framework in practical projects. Using slf4j logging is very simple. You can directly use LoggerFactory to create logs.
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Test {
private static final Logger logger = LoggerFactory.getLogger(Test.class);
// ......
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2. application. Log configuration in YML
Spring Boot supports slf4j very well. Slf4j has been integrated internally. Generally, we will configure slf4j when using it. application. The yml file is the only file that needs to be configured in Spring Boot. At the beginning of creating the project, it is application The properties file is more detailed. The yml file is used because the hierarchy of the yml file is particularly good and looks more intuitive. However, the format requirements of the yml file are relatively high. For example, there must be a space after the English colon, otherwise the project is estimated to be unable to start and no error is reported. Either properties or yml depends on personal habits. This course uses yml.
Let's take a look at application Log configuration in YML file:
logging:
config: logback.xml
level:
com.itcodai.course03.dao: trace
- 1
- 2
- 3
- 4
logging.config is used to specify which configuration file to read when the project is started. The log configuration file specified here is logback under the root path XML} files and related configuration information about logs are placed in logback In the XML} file. logging.level , is used to specify the output level of logs in a specific mapper. The above configuration indicates , com itcodai. course03. The output level of all mapper logs under Dao # package is trace, which will print out the sql operating the database. During development, it is set to trace to facilitate problem location. In the production environment, it is sufficient to set this log level to error level (the mapper layer will not be discussed in this lesson, but will be discussed in detail later when Spring Boot integrates MyBatis).
The common log levels are ERROR, WARN, INFO and DEBUG from high to low.
3. logback.xml configuration file parsing
Click application In the YML ¢ file, we specify the log configuration file ¢ logback xml,logback. The XML file is mainly used to configure logs. In logback In XML #, we can define the log output format, path, console output format, file size, save time, etc. Let's analyze:
3.1 define log output format and storage path
<configuration>
<property name="LOG_PATTERN" value="%date{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n" />
<property name="FILE_PATH" value="D:/logs/course03/demo.%d{yyyy-MM-dd}.%i.log" />
</configuration>
- 1
- 2
- 3
- 4
Let's take a look at the meaning of this definition: first, define a format named "LOG_PATTERN". In this format,% date represents the date,% thread represents the thread name,% - 5level represents the five character width of the level from the left,% logger{36} represents the longest 36 characters of the logger name,% msg} represents the log message, and% n} is the newline character.
Then define a file path named "FILE_PATH" where logs will be stored.% n i indicates the ith file. When the log file reaches the specified size, the log will be generated into a new file. Here, i is the file index. The allowable size of the log file can be set, which will be explained below. It should be noted here that the log storage path must be absolute in both windows and Linux systems.
3.2 define console output
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<!-- As configured above LOG_PATTERN To print the log -->
<pattern>${LOG_PATTERN}</pattern>
</encoder>
</appender>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Use the < appender > node to set the configuration of a CONSOLE output (class="ch.qos.logback.core.ConsoleAppender"), which is defined as "CONSOLE". Use the output format (LOG_PATTERN) defined above to output, and use ${} to reference it.
3.3 define relevant parameters of log file
<configuration>
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- As configured above FILE_PATH Path to save the log -->
<fileNamePattern>${FILE_PATH}</fileNamePattern>
<!-- Keep the log for 15 days -->
<maxHistory>15</maxHistory>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<!-- If the maximum of a single log file exceeds, a new log file store will be created -->
<maxFileSize>10MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<encoder>
<!-- As configured above LOG_PATTERN To print the log -->
<pattern>${LOG_PATTERN}</pattern>
</encoder>
</appender>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Use < appender > to define a FILE configuration named "FILE", which is mainly used to configure the saving time of log files, the storage size of a single log FILE, the saving path of files and the output format of logs.
3.4 define log output level
<configuration> <logger name="com.itcodai.course03" level="INFO" /> <root level="INFO"> <appender-ref ref="CONSOLE" /> <appender-ref ref="FILE" /> </root> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
After having the above definitions, finally, we use < logger > to define the default log output level in the project. Here, we define the level as INFO. Then, for the log of INFO level, we use < root > to refer to the parameters of console log output and log file defined above. So logback The configuration in the XML file is set.
4. Use Logger to print logs in the project
In the code, we generally use the Logger object to print out some log information. You can specify the log level to print out and support placeholders, which is very convenient.
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/test")
public class TestController {
private final static Logger logger = LoggerFactory.getLogger(TestController.class);
@RequestMapping("/log")
public String testLog() {
logger.debug("=====Test log debug Level printing====");
logger.info("======Test log info Level printing=====");
logger.error("=====Test log error Level printing====");
logger.warn("======Test log warn Level printing=====");
// You can use placeholders to print out some parameter information
String str1 = "blog.itcodai.com";
String str2 = "blog.csdn.net/eson_15";
logger.info("======Ni Shengwu's personal blog:{};Ni Shengwu's CSDN Blog:{}", str1, str2);
return "success";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
Start the project and enter localhost:8080/test/log in the browser to see the console log record:
======Test log info Level printing===== =====Test log error Level printing==== ======Test log warn Level printing===== ======Ni Shengwu's personal blog: blog.itcodai.com;Ni Shengwu's CSDN Blog: blog.csdn.net/eson_15
- 1
- 2
- 3
- 4
Because the INFO level is higher than the DEBUG level, the DEBUG message is not printed. If logback If the log level in XML is set to DEBUG, all four statements will be printed out. Let's test it ourselves. At the same time, you can open the D:\logs\course03 \ directory, which contains all the log records generated after the project has just started. After the project is deployed, we mostly locate the problem by viewing the log file.
5. Summary
This lesson mainly introduces slf4j briefly, explains in detail how to use slf4j to output logs in Spring Boot, and focuses on the analysis of slf4j logback Configuration of log related information in XML} file, including different levels of logs. Finally, for these configurations, use the Logger to print out some in the code for testing. In actual projects, these logs are very important information in the process of troubleshooting.
Course source code download address: Poke me to download
Lesson 04: project property configuration in Spring Boot
We know that in the project, we often need to use some configuration information. These information may have different configurations in the test environment and production environment, and may be modified later according to the actual business situation. In view of this situation, we can't write these configurations in the code, and we'd better write them in the configuration file. For example, you can write this information to application YML file.
1. A small amount of configuration information
For example, in the microservice architecture, the most common is that a service needs to call other services to obtain the relevant information provided by it, so the service address to be called needs to be configured in the service configuration file. For example, in the current service, we need to call the order microservice to obtain the order related information. Suppose the port number of the order service is 8002, Then we can configure as follows:
server: port: 8001 # Configure the address of the microservice url: # Address of the order micro service orderUrl: http://localhost:8002
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Then, how to get the configured order service address in the business code? We can use @ Value annotation to solve this problem. Add an attribute to the corresponding class and use the @ Value annotation on the attribute to obtain the configuration information in the configuration file, as follows:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/test")
public class ConfigController {
private static final Logger LOGGER = LoggerFactory.getLogger(ConfigController.class);
@Value("${url.orderUrl}")
private String orderUrl;
@RequestMapping("/config")
public String testConfig() {
LOGGER.info("=====The order service address obtained is:{}", orderUrl);
return "success";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
@The Value value corresponding to the key in the configuration file can be obtained through ${key} on the Value annotation. Let's start the project and enter localhost:8080/test/config in the browser to request the service. You can see that the console will print the address of the order service:
=====The order service address obtained is: http://localhost:8002
- 1
It indicates that we have successfully obtained the order micro service address in the configuration file, which is also used in the actual project. Later, if the address of a service needs to be modified due to server deployment, just modify it in the configuration file.
2. Multiple configuration information
Here is another problem. With the increase of business complexity, there may be more and more microservices in a project. A module may need to call multiple microservices to obtain different information, so it is necessary to configure the addresses of multiple microservices in the configuration file. However, in the code that needs to call these microservices, it is too cumbersome and unscientific to use @ Value annotation to introduce the corresponding microservice address one by one.
Therefore, in the actual project, when the business is cumbersome and the logic is complex, it is necessary to consider encapsulating one or more configuration classes. For example: in the current service, if a business needs to call order microservice, user microservice and shopping cart microservice at the same time, obtain the relevant information of order, user and shopping cart respectively, and then do some logical processing for these information. In the configuration file, we need to configure the addresses of these microservices:
# Configure addresses of multiple microservices url: # Address of the order micro service orderUrl: http://localhost:8002 # Address of user microservice userUrl: http://localhost:8003 # Address of shopping cart micro service shoppingUrl: http://localhost:8004
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Maybe in the actual business, there are far more than these three micro services, or even more than a dozen. In this case, we can first define a MicroServiceUrl class to store the url of the microservice, as follows:
@Component
@ConfigurationProperties(prefix = "url")
public class MicroServiceUrl {
private String orderUrl;
private String userUrl;
private String shoppingUrl;
// get and set methods are omitted
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Careful friends should see that you can use @ ConfigurationProperties' annotation and prefix to specify a prefix, and then the property name in this class is the name after removing the prefix in the configuration, one-to-one correspondence. That is, prefix name + attribute name is the key defined in the configuration file. At the same time, the class needs to be annotated with @ Component. Put the class as a Component in the Spring container and let Spring manage it. We can inject it directly when we use it.
Note that using @ ConfigurationProperties annotation requires importing its dependencies:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> <optional>true</optional> </dependency>
- 1
- 2
- 3
- 4
- 5
OK, so far, we have written the configuration, and then write a Controller to test it. At this time, you don't need to introduce the URLs of these micro services one by one in the code. You can directly inject the newly written configuration class through the @ Resource annotation, which is very convenient. As follows:
@RestController
@RequestMapping("/test")
public class TestController {
private static final Logger LOGGER = LoggerFactory.getLogger(TestController.class);
@Resource
private MicroServiceUrl microServiceUrl;
@RequestMapping("/config")
public String testConfig() {
LOGGER.info("=====The order service address obtained is:{}", microServiceUrl.getOrderUrl());
LOGGER.info("=====The obtained user service address is:{}", microServiceUrl.getUserUrl());
LOGGER.info("=====The shopping cart service address obtained is:{}", microServiceUrl.getShoppingUrl());
return "success";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
Start the project again, and you can see the following information printed on the console, indicating that the configuration file is effective and the content of the configuration file is obtained correctly:
=====The order service address obtained is: http://localhost:8002 =====The order service address obtained is: http://localhost:8002 =====The obtained user service address is: http://localhost:8003 =====The shopping cart service address obtained is: http://localhost:8004
- 1
- 2
- 3
- 4
3. Specify project profile
As we know, in actual projects, there are generally two environments: development environment and production environment. The configuration in the development environment is often different from that in the production environment, such as environment, port, database, related address, etc. After debugging the development environment and deploying to the production environment, it is impossible for us to modify all the configuration information into the configuration of the production environment. This is too troublesome and unscientific.
The best solution is to have a set of configuration information for both the development environment and the production environment. Then, when we are developing, we specify to read the configuration of the development environment. After we deploy the project to the server, we specify to read the configuration of the production environment.
We create two new configuration files: application-dev.yml , and application-pro YML is used to configure the development environment and production environment respectively. For convenience, we set two access port numbers, 8001 for development environment and 8002 for production environment
# Development environment profile server: port: 8001
- 1
- 2
- 3
# Development environment profile server: port: 8002
- 1
- 2
- 3
Then in application Specify which configuration file to read in the yml} file. For example, in the development environment, we specify to read the {applicationn-dev.yml} file, as follows:
spring:
profiles:
active:
- dev
- 1
- 2
- 3
- 4
In this way, you can specify to read the "application-dev.yml" file during development, and use port 8001 when accessing. After deployment to the server, you only need to add "application Change the file specified in YML to application pro YML #, and then use 8002 port to access, which is very convenient.
4. Summary
This lesson mainly explains how to read relevant configurations in business code in Spring Boot, including single configuration and multiple configuration items. This is very common in microservices. There are often many other microservices to call, so it is a good way to encapsulate a configuration class to receive these configurations. In addition, for example, database related connection parameters can also be placed in a configuration class. Other similar scenarios can be handled in this way. Finally, the fast switching mode of development environment and production environment configuration is introduced, which eliminates the modification of many configuration information during project deployment.
Course source code download address: Poke me to download
Lesson 05: MVC support in Spring Boot
The MVC support of Spring Boot mainly introduces the most commonly used annotations in actual projects, including @ RestController, @ RequestMapping, @ PathVariable, @ RequestParam and @ RequestBody. This paper mainly introduces the common usage and characteristics of these annotations.
1. @RestController
@RestController , is a new annotation for Spring Boot. Let's see what the annotation contains.
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Controller
@ResponseBody
public @interface RestController {
String value() default "";
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
It can be seen that the @ respontroller 'annotation contains the original @ Controller' and @ ResponseBody 'annotations. Friends who have used Spring have a good understanding of the @ Controller' annotation, which will not be repeated here. The @ ResponseBody 'annotation is to convert the returned data structure into Json format. So @ RestController can be regarded as a combination of @ Controller and @ ResponseBody, which is equivalent to stealing laziness. We don't need to use @ Controller after using @ RestController. However, there is a problem to be noted: if the front and rear ends are separated and there is no template rendering, for example Thymeleaf In this case, you can directly use @ RestController , to transfer the data to the front end in json format, and the front end can parse it after getting it; However, if the front and back ends are not separated and the template is needed for rendering, the Controller will generally return to the specific page, so @ RestController cannot be used at this time, for example:
public String getUser() {
return "user";
}
- 1
- 2
- 3
In fact, you need to return to user For HTML pages, if @ RestController , is used, the user will be returned as a string, so we need to use @ Controller , annotation at this time. This will be explained in the next section Spring Boot integrated Thymeleaf template engine.
2. @RequestMapping
@RequestMapping} is an annotation used to handle request address mapping. It can be used on classes or methods. Annotations at the class level will map a specific request or request pattern to a controller, indicating that all methods in the class responding to requests take this address as the parent path; The mapping relationship further specified to the processing method is represented at the method level.
The annotation has six attributes. Generally, there are three attributes commonly used in projects: value, method and produces.
- value attribute: Specifies the actual address of the request. value can be omitted
- method attribute: Specifies the type of request, mainly including GET, PUT, POST and DELETE. The default is GET
- Productions attribute: Specifies the type of returned content, such as productions = "application/json; charset=UTF-8"
@The RequestMapping} annotation is relatively simple. For example:
@RestController
@RequestMapping(value = "/test", produces = "application/json; charset=UTF-8")
public class TestController {
@RequestMapping(value = "/get", method = RequestMethod.GET)
public String testGet() {
return "success";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
This is very simple. Start the project and enter localhost:8080/test/get in the browser to test it.
There are corresponding annotations for the four different request methods. You don't need to add the method attribute to the @ RequestMapping} annotation every time. The above GET method requests can directly use the @ GetMapping("/get") annotation with the same effect. Accordingly, the annotations corresponding to PUT mode, POST mode and DELETE mode are @ PutMapping, @ PostMapping , and @ DeleteMapping , respectively.
3. @PathVariable
@The PathVariable annotation is mainly used to obtain url parameters. Spring Boot supports restful URLs. For example, a GET request carries a parameter id. we receive the id as a parameter. You can use the @ PathVariable annotation. As follows:
@GetMapping("/user/{id}")
public String testPathVariable(@PathVariable Integer id) {
System.out.println("Obtained id Is:" + id);
return "success";
}
- 1
- 2
- 3
- 4
- 5
One problem to note here is that if you want the id value in the placeholder in the url to be directly assigned to the parameter id, you need to ensure that the parameters in the url are consistent with the method receiving parameters, otherwise it cannot be received. If it is inconsistent, it can also be solved. You need to specify the corresponding relationship with the value attribute in @ PathVariable *. As follows:
@RequestMapping("/user/{idd}")
public String testPathVariable(@PathVariable(value = "idd") Integer id) {
System.out.println("Obtained id Is:" + id);
return "success";
}
- 1
- 2
- 3
- 4
- 5
For the url to be accessed, the position of the placeholder can be anywhere, not necessarily at the end, for example: / xxx/{id}/user. In addition, the url also supports multiple placeholders. Method parameters are received with the same number of parameters. The principle is the same as that of one parameter, for example:
@GetMapping("/user/{idd}/{name}")
public String testPathVariable(@PathVariable(value = "idd") Integer id, @PathVariable String name) {
System.out.println("Obtained id Is:" + id);
System.out.println("Obtained name Is:" + name);
return "success";
}
- 1
- 2
- 3
- 4
- 5
- 6
Run the project and request localhost:8080/test/user/2/zhangsan in the browser. You can see the console output the following information:
Obtained id Is: 2 Obtained name Is: zhangsan
- 1
- 2
Therefore, it supports the reception of multiple parameters. Similarly, if the parameter names in the url are different from those in the method, you also need to use the value attribute to bind the two parameters.
4. @RequestParam
@As the name suggests, the RequestParam annotation is also used to obtain request parameters. We introduced above that the @ PathVariable annotation is also used to obtain request parameters. What is the difference between @ RequestParam and @ PathVariable? The main difference is that @ PathVariable @ is to obtain parameter values from the url template, that is, this style of url: http://localhost:8080/user/{id} ; And @ RequestParam gets the parameter value from the request, that is, the url of this style: http://localhost:8080/user?id=1 . We use the url with parameter ID to test the following code:
@GetMapping("/user")
public String testRequestParam(@RequestParam Integer id) {
System.out.println("Obtained id Is:" + id);
return "success";
}
- 1
- 2
- 3
- 4
- 5
id information can be printed out from the console normally. Similarly, the parameters above the url should be consistent with the parameters of the method. If they are inconsistent, the value attribute should also be used to explain. For example, the url is: http://localhost:8080/user?idd=1
@RequestMapping("/user")
public String testRequestParam(@RequestParam(value = "idd", required = false) Integer id) {
System.out.println("Obtained id Is:" + id);
return "success";
}
- 1
- 2
- 3
- 4
- 5
In addition to the value attribute, there are two more common attributes:
- required attribute: true indicates that the parameter must be passed, otherwise 404 error will be reported, and false indicates optional.
- defaultValue property: default value, which indicates the default value if there is no parameter with the same name in the request.
It can be seen from the url that when the @ RequestParam annotation is used on the GET request, it receives the parameters spliced in the url. In addition, this annotation can also be used for POST requests to receive the parameters submitted by the front-end form. If the front-end submits two parameters username and password through the form, we can use @ RequestParam to receive them. The usage is the same as above.
@PostMapping("/form1")
public String testForm(@RequestParam String username, @RequestParam String password) {
System.out.println("Obtained username Is:" + username);
System.out.println("Obtained password Is:" + password);
return "success";
}
- 1
- 2
- 3
- 4
- 5
- 6
Let's use postman to simulate form submission and test the interface:
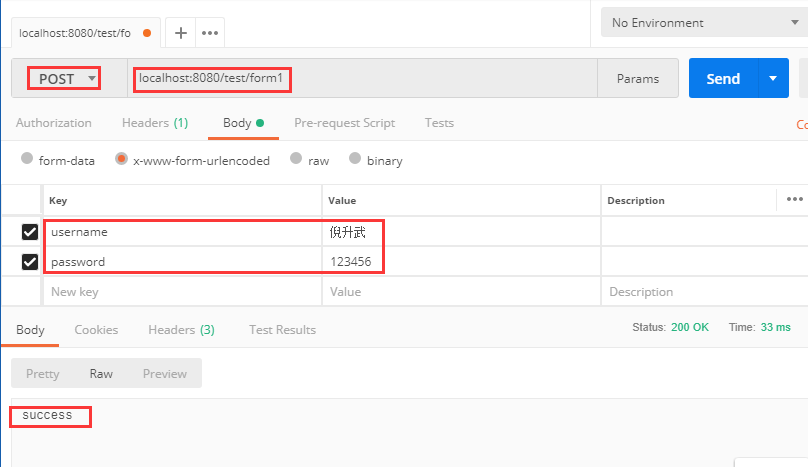
The problem is that if the form has a lot of data, we can't write many parameters in the background method, and each parameter needs @ RequestParam annotation. In this case, we need to encapsulate an entity class to receive these parameters. The attribute name in the entity is consistent with the parameter name in the form.
public class User {
private String username;
private String password;
// set get
}
- 1
- 2
- 3
- 4
- 5
If using entity receiving, we can't add @ RequestParam annotation in front, just use it directly.
@PostMapping("/form2")
public String testForm(User user) {
System.out.println("Obtained username Is:" + user.getUsername());
System.out.println("Obtained password Is:" + user.getPassword());
return "success";
}
- 1
- 2
- 3
- 4
- 5
- 6
Use postman to test the form submission again and observe the return value and the log printed out by the console. In actual projects, an entity class is usually encapsulated to receive form data, because there are usually a lot of form data in actual projects.
5. @RequestBody
@The RequestBody annotation is used to receive the entity from the front end, and the receiving parameters are also corresponding entities. For example, the front end sends two parameters username and password through json submission. At this time, we need to encapsulate an entity at the back end to receive. When more parameters are passed, it is very convenient to use @ RequestBody @ to receive. For example:
public class User {
private String username;
private String password;
// set get
}
- 1
- 2
- 3
- 4
- 5
@PostMapping("/user")
public String testRequestBody(@RequestBody User user) {
System.out.println("Obtained username Is:" + user.getUsername());
System.out.println("Obtained password Is:" + user.getPassword());
return "success";
}
- 1
- 2
- 3
- 4
- 5
- 6
We use the postman tool to test the effect. Open postman, and then enter the request address and parameters. We use json to simulate the parameters, as shown in the figure below. After calling, we return success.
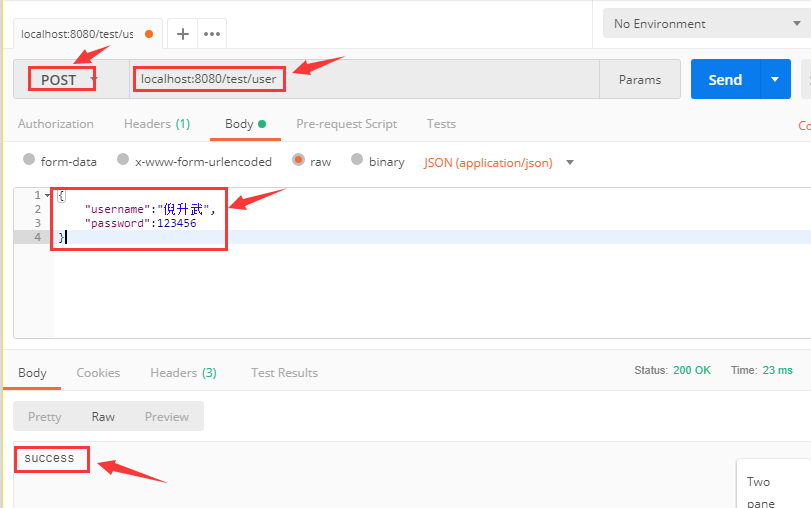
At the same time, look at the log output from the background console:
Obtained username Ni Shengwu Obtained password Is: 123456
- 1
- 2
It can be seen that the @ RequestBody @ annotation is used on POST requests to receive json entity parameters. It is somewhat similar to the form submission described above, except that the format of parameters is different. One is json entity and the other is form submission. In the actual project, you can use corresponding annotations according to specific scenarios and needs.
6. Summary
This lesson mainly explains the support for MVC in Spring Boot, and analyzes the use of @ RestController, @ RequestMapping, @ PathVariable, @ RequestParam and @ RequestBody. Since @ ResponseBody is integrated in @ RestController , the annotation of returning json will not be repeated. The above four annotations are frequently used annotations, which will be encountered in all practical projects. You should master them skillfully.
Course source code download address: Poke me to download
Lesson 06: Spring Boot integration Swagger 2 show online interface documents
1. Introduction to swagger
1.1 problems solved
With the development of Internet technology, the current website architecture has basically changed from the original back-end rendering to the form of front-end and back-end separation, and the front-end technology and back-end technology are farther and farther on their respective roads. The only connection between the front-end and the back-end has become the API interface, so the API document has become the link between the front-end and back-end developers, becoming more and more important.
Then the problem comes. With the continuous updating of code, after developers develop new interfaces or update old interfaces, due to the heavy development tasks, it is often difficult to continuously update the documents. Swagger is an important tool to solve this problem. For those who use interfaces, developers do not need to provide them with documents, As long as you tell them a swagger address, you can display the online API interface documents. In addition, the personnel calling the interface can also test the interface data online. Similarly, when developing the interface, developers can also use swagger online interface documents to test the interface data, which provides convenience for developers.
1.2 Swagger official
We open Swagger official website , the official definition of Swagger is:
The Best APIs are Built with Swagger Tools
The best API is built using Swagger tools. It can be seen that Swagger officials are very confident in its function and position. Because it is very easy to use, the official positioning is also reasonable. As shown in the figure below:

This article mainly explains how to import Swagger2 tool in Spring Boot to show the interface documents in the project. The Swagger version used in this lesson is 2.2.2. Let's start the Swagger2 tour.
2. Swagger2's maven dependence
When using Swagger2 tool, you must import maven dependency. At present, the highest official version is 2.8.0. I tried it. Personally, I feel that the effect of page display is not very good, and it is not compact enough, which is not conducive to operation. In addition, the latest version is not necessarily the most stable version. At present, we use version 2.2.2 in our actual project. This version is stable and friendly. Therefore, this lesson mainly focuses on version 2.2.2. The dependencies are as follows:
<dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger2</artifactId> <version>2.2.2</version> </dependency> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger-ui</artifactId> <version>2.2.2</version> </dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3. Swagger2 configuration
Swagger2 needs to be configured. Swagger2 Configuration in Spring Boot is very convenient. Create a new Configuration class. In addition to adding the necessary @ Configuration annotation, you also need to add the @ enableswager2 annotation on the swagger2 Configuration class.
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.builders.RequestHandlerSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
import springfox.documentation.swagger2.annotations.EnableSwagger2;
/**
* @author shengwu ni
*/
@Configuration
@EnableSwagger2
public class SwaggerConfig {
@Bean
public Docket createRestApi() {
return new Docket(DocumentationType.SWAGGER_2)
// Specify how to build the details of the api document: apiInfo()
.apiInfo(apiInfo())
.select()
// Specify the package path to generate api interfaces. Here, take controller as the package path to generate all interfaces in controller
.apis(RequestHandlerSelectors.basePackage("com.itcodai.course06.controller"))
.paths(PathSelectors.any())
.build();
}
/**
* Build api documentation details
* @return
*/
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
// Set page title
.title("Spring Boot integrate Swagger2 Interface Overview")
// Set interface description
.description("Learn with brother Wu Spring Boot Lesson 06")
// Set contact information
.contact("Ni Shengwu," + "CSDN: http://blog.csdn.net/eson_15")
// Set version
.version("1.0")
// structure
.build();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
In this configuration class, the function of each method has been explained in detail with comments, which will not be repeated here. So far, we have configured Swagger2. Now we can test whether the configuration is effective. Start the project and enter localhost: 8080 / swagger UI in the browser HTML, you can see the interface page of Swagger2, as shown in the figure below, indicating that Swagger2 integration is successful.

Combined with the figure, you can clearly know the role of each method in the configuration class by comparing the configuration in the Swagger2 configuration file above. In this way, it is easy to understand and master the configuration in Swagger2. It can also be seen that the Swagger2 configuration is very simple.
[friendly note] many friends may encounter the following situations when configuring Swagger, and they can't turn it off. This is caused by the browser cache. Empty the browser cache to solve the problem.
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-gbvzvwz7-1595163751524)( http://p99jlm9k5.bkt.clouddn.com/blog/images/1/error.png )]
4. Use of swagger2
Swagger2 has been configured and tested, and its function is normal. Next, we start to use swagger2 to introduce several common annotations in swagger2, respectively on entity class, Controller class and methods in Controller. Finally, let's see how swagger2 presents online interface documents on the page, And test the data in the interface in combination with the methods in the Controller.
4.1 entity class annotation
In this section, we will create a User entity class, mainly introduce the @ ApiModel and @ ApiModelProperty annotations in Swagger2, and prepare for the following tests.
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
@ApiModel(value = "User entity class")
public class User {
@ApiModelProperty(value = "User unique ID")
private Long id;
@ApiModelProperty(value = "User name")
private String username;
@ApiModelProperty(value = "User password")
private String password;
// Omit the set and get methods
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Explain the @ ApiModel , and @ ApiModelProperty , notes below:
@ApiModel annotation is used for entity classes to describe the class. It is used to receive parameters with entity classes.
@ApiModelProperty annotation is used for properties in the class to indicate the description of the model property or data operation changes.
The specific effect of this annotation in the online API document is described below.
4.2 relevant notes in controller class
Let's write a TestController, write several interfaces, and then learn the notes related to Swagger2 in the Controller.
import com.itcodai.course06.entiy.JsonResult;
import com.itcodai.course06.entiy.User;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import io.swagger.annotations.ApiParam;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/swagger")
@Api(value = "Swagger2 Online interface documentation")
public class TestController {
@GetMapping("/get/{id}")
@ApiOperation(value = "Obtain user information according to the user's unique ID")
public JsonResult<User> getUserInfo(@PathVariable @ApiParam(value = "User unique ID") Long id) {
// Obtain User information according to id in the simulation database
User user = new User(id, "Ni Shengwu", "123456");
return new JsonResult(user);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
Let's learn about @ Api, @ ApiOperation, @ ApiParam annotation.
@Api} annotation is used on a class to indicate that this class is a resource of swagger.
@The ApiOperation annotation is used for the method to represent the operation of an http request.
@ApiParam annotation is used on parameters to indicate parameter information.
What is returned here is JsonResult, which is the entity encapsulated when learning to return json data in lesson 02. The above are the five most commonly used annotations in Swagger. Next, run the project, and enter localhost: 8080 / Swagger UI in the browser HTML} take a look at the interface status of the Swagger page.
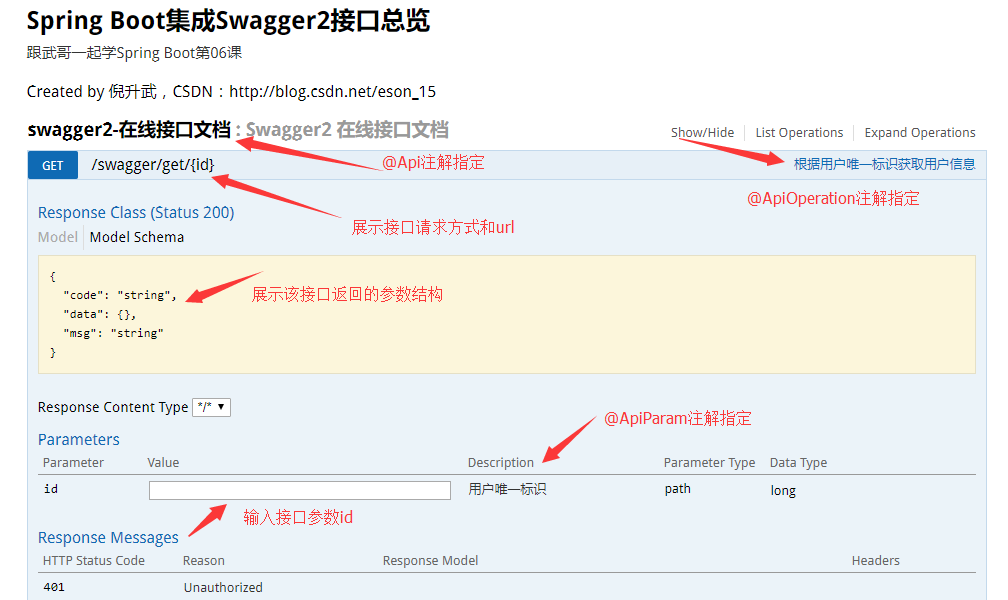
It can be seen that the Swagger page displays the information of the interface very comprehensively. The function and display place of each annotation have been indicated in the figure above. All the information of the interface can be known through the page. Then we can directly test the information returned by the interface online. Enter id 1 to see the returned data:
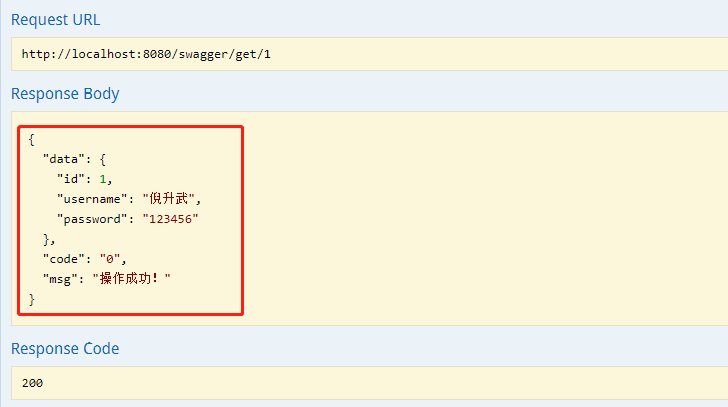
It can be seen that json format data is returned directly on the page, and developers can directly use the online interface to test whether the data is correct or not, which is very convenient. The above is the input of a single parameter. If the input parameter is an object, what does Swagger look like? Let's write another interface.
@PostMapping("/insert")
@ApiOperation(value = "Add user information")
public JsonResult<Void> insertUser(@RequestBody @ApiParam(value = "User information") User user) {
// Process add logic
return new JsonResult<>();
}
- 1
- 2
- 3
- 4
- 5
- 6
Restart the project and enter localhost: 8080 / swagger UI in the browser HTML} let's see the effect:
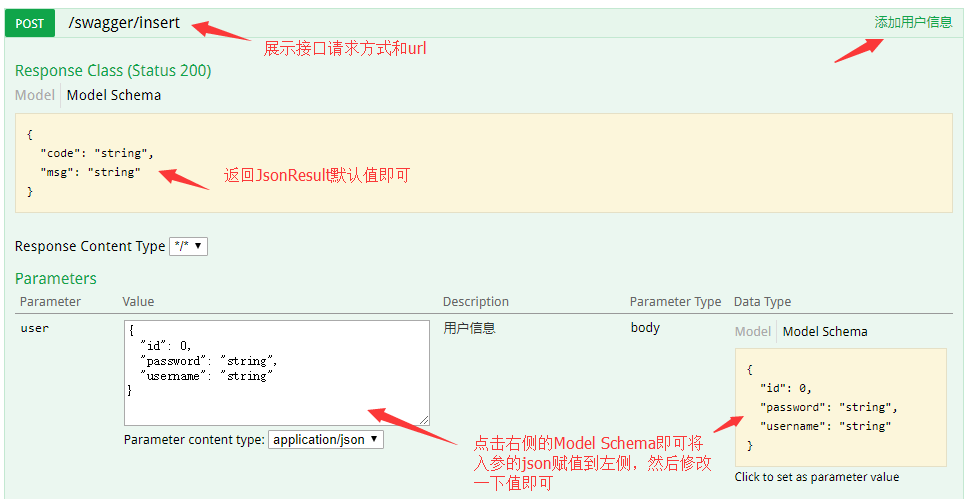
5. Summary
OK, this lesson analyzes in detail the advantages of Swagger and how Spring Boot integrates Swagger2, including configuration, explanation of relevant annotations, involving entity classes and interface classes, and how to use them. Finally, through the page test, I experienced the power of Swagger, which is basically one of the necessary tools in each project team, so it is not difficult to master the use of this tool.
Course source code download address: Poke me to download
Lesson 07: Spring Boot integrates Thymeleaf template engine
1. Introduction to thymeleaf
Thymeleaf is a modern server-side Java template engine for Web and stand-alone environments.
The main goal of Thymeleaf is to bring elegant natural templates to your development workflow - HTML that can be displayed correctly in the browser or used as static prototypes, so as to achieve more powerful collaboration among the development team.
The above is translated from the official website of thymeleaf. The traditional JSP+JSTL combination is a thing of the past. Thymeleaf is the template engine of modern server. Different from traditional JSP, thymeleaf can be opened directly by browser, because the expansion attribute can be ignored, which is equivalent to opening the native page, which also brings some convenience to the front-end personnel.
What do you mean? In other words, thymeleaf can run in local environment or network environment. Because thymeleaf supports html prototypes and additional attributes in html tags to achieve the display mode of "template + data", artists can directly view the page effect in the browser. After the service is started, they can also let background developers view the dynamic page effect with data. For example:
<div class="ui right aligned basic segment">
<div class="ui orange basic label" th:text="${blog.flag}">Static original information</div>
</div>
<h2 class="ui center aligned header" th:text="${blog.title}">This is a static title</h2>
- 1
- 2
- 3
- 4
Similar to the above, the static information will be displayed on the static page. After the service is started and the data in the database is dynamically obtained, the dynamic data can be displayed. The th:text tag is used to dynamically replace the text, which will be described below. This example shows that when the browser interprets html, it ignores the undefined tag attributes in html (such as {th:text), so the Thymeleaf template can run statically; When data is returned to the page, the Thymeleaf tag will dynamically replace the static content to make the page dynamically display data.
2. Dependency import
To use the Thymeleaf template in Spring Boot, you need to import dependencies. You can check Thymeleaf when creating a project or manually import it after creation, as shown below:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
- 1
- 2
- 3
- 4
In addition, if you want to use the thymeleaf template on an html page, you need to introduce the following in the page tag:
<html xmlns:th="http://www.thymeleaf.org">
- 1
3. Thymeleaf related configuration
Because Thymeleaf already has a default configuration, we don't need to configure it too much. It should be noted that Thymeleaf turns on the page cache by default, so it is necessary to turn off the page cache during development. The configuration is as follows.
spring:
thymeleaf:
cache: false #Close cache
- 1
- 2
- 3
Otherwise, there will be a cache, resulting in the page can not see the updated effect in time. For example, when you modify a file, it has been updated to tomcat, but the page is still the previous page, which is caused by the cache.
4. Use of thymeleaf
4.1 accessing static pages
This has nothing to do with Thymeleaf. It should be said that it is general. The reason why I write it here is that when we make a website, we usually make a 404 page and 500 page, so as to give users a friendly display in case of errors, rather than throwing out a pile of abnormal information. In Spring Boot, 404. 0 in the templates directory (templates /) will be automatically recognized html and 500 html file. We will create a new error folder under the templates / directory to place the wrong html pages, and then print some information respectively. At 404 html as an example:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
This is page 404
</body>
</html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Let's write another controller to test 404 and 500 pages:
@Controller
@RequestMapping("/thymeleaf")
public class ThymeleafController {
@RequestMapping("/test404")
public String test404() {
return "index";
}
@RequestMapping("/test500")
public String test500() {
int i = 1 / 0;
return "index";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
When we enter "localhost:8080/thymeleaf/test400" in the browser, we deliberately make an error and cannot find the corresponding method, so we will jump to 404 HTML display.
When we enter "localhost:8088/thymeleaf/test505" in the browser, an exception will be thrown, and then we will automatically jump to 500 HTML display.
[note] there is a problem to be noted here. In the previous course, we said that there will be front-end and back-end separation in microservices. We use @ RestController 'annotation on the Controller layer, which will automatically convert the returned data into json format. However, when using the template engine, the Controller layer cannot annotate with @ RestController , because when using the thymeleaf template, the view file name is returned, for example, in the above Controller, it is returned to index For HTML pages, if @ RestController @, the index will be parsed as a String and returned directly to the page instead of looking for index HTML page, you can try. Therefore, when using the template, use @ Controller annotation.
4.2 processing objects in thymeleaf
Let's take a look at how to handle the object information in the thymeleaf template. If we need to transmit the relevant information of the blogger to the front end to display when we are doing a personal blog, we will package it into a blogger object, such as:
public class Blogger {
private Long id;
private String name;
private String pass;
// Omit set and get
}
- 1
- 2
- 3
- 4
- 5
- 6
Then initialize in the controller layer:
@GetMapping("/getBlogger")
public String getBlogger(Model model) {
Blogger blogger = new Blogger(1L, "Ni Shengwu", "123456");
model.addAttribute("blogger", blogger);
return "blogger";
}
- 1
- 2
- 3
- 4
- 5
- 6
We first initialize a blogger object, then put the object into the Model, and then return to blogger HTML page to render. Next, let's write another blogger HTML to render blogger information:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Blogger information</title>
</head>
<body>
<form action="" th:object="${blogger}" >
User No.:<input name="id" th:value="${blogger.id}"/><br>
User name:<input type="text" name="username" th:value="${blogger.getName()}" /><br>
Login password:<input type="text" name="password" th:value="*{pass}" />
</form>
</body>
</html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
It can be seen that in the thymeleaf template, use th:object = "${}" to obtain object information, and then there are three ways to obtain object attributes in the form. As follows:
Use th:value = "* {attribute name}"
Using "th:value =" ${object. Attribute name} ", the object refers to the object obtained by using" th:object "above
Use the "th:value =" ${object. get method} ". The object refers to the object obtained by using" th:object "above
It can be seen that in Thymeleaf, you can write code like java, which is very convenient. Let's test the data by typing {localhost:8080/thymeleaf/getBlogger} in the browser:

4.3 List processing in thymeleaf
Processing List is similar to processing the objects described above, but it needs to be traversed in thymeleaf. Let's simulate a List in the Controller first.
@GetMapping("/getList")
public String getList(Model model) {
Blogger blogger1 = new Blogger(1L, "Ni Shengwu", "123456");
Blogger blogger2 = new Blogger(2L, "Talent class", "123456");
List<Blogger> list = new ArrayList<>();
list.add(blogger1);
list.add(blogger2);
model.addAttribute("list", list);
return "list";
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Next, let's write a list HTML to get the list information, and then in the list Traverse the list in HTML. As follows:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Blogger information</title>
</head>
<body>
<form action="" th:each="blogger : ${list}" >
User No.:<input name="id" th:value="${blogger.id}"/><br>
User name:<input type="text" name="password" th:value="${blogger.name}"/><br>
Login password:<input type="text" name="username" th:value="${blogger.getPass()}"/>
</form>
</body>
</html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
It can be seen that it is almost the same as processing the information of a single object. Thymeleaf uses , th:each , to traverse, ${} to take the parameters passed from the model, and then customize each object taken from the list, which is defined here as a blogger. In the form, you can directly use ${object. Attribute name} to obtain the attribute value of the object in the list, or use ${object. get method}. This is the same as the object information processed above, but you can't use * {attribute name} to obtain the attribute in the object, which can't be obtained by thymeleaf template.
4.4 other common thymeleaf operations
Let's summarize some common tag operations in thymeleaf, as follows:
| label | function | example |
|---|---|---|
| th:value | Assign values to attributes | <input th:value="${blog.name}" /> |
| th:style | Set style | th:style="'display:'+@{(${sitrue}?'none':'inline-block')} + ''" |
| th:onclick | Click event | th:onclick="'getInfo()'" |
| th:if | Conditional judgment | <a th:if="${userId == collect.userId}" > |
| th:href | Hyperlinks | <a th:href="@{/blogger/login}">Login</a> /> |
| th:unless | Conditional judgment is opposite to th:if | <a th:href="@{/blogger/login}" th:unless=${session.user != null}>Login</a> |
| th:switch | Fit th:case | <div th:switch="${user.role}"> |
| th:case | Cooperate with th:switch | <p th:case="'admin'">administator</p> |
| th:src | Address introduction | <img alt="csdn logo" th:src="@{/img/logo.png}" /> |
| th:action | Address of form submission | <form th:action="@{/blogger/update}"> |
There are many other uses of Thymeleaf, which will not be summarized here. For details, please refer to Thymeleaf Official documents (v3.0) . We mainly need to learn how to use thymeleaf in Spring Boot. If you encounter the corresponding tags or methods, you can refer to the official documents.
5. Summary
Thymeleaf is widely used in Spring Boot. This lesson mainly analyzes the advantages of thymeleaf and how to integrate and use thymeleaf templates in Spring Boot, including dependency, configuration, acquisition of relevant data, and some precautions. Finally, some commonly used tags in thymeleaf are listed. You can master them by using them more in actual projects. Some tags or methods in thymeleaf don't need to memorize by rote. The key is to integrate them in Spring Boot. Practice makes perfect.
Course source code download address: Poke me to download
Lesson 08: Global exception handling in Spring Boot
In the process of project development, whether it is the operation process of the underlying database, the processing process of the business layer or the processing process of the control layer, it is inevitable to encounter all kinds of predictable and unpredictable exceptions to be handled. If exceptions are handled separately for each process, the code coupling degree of the system will become very high. In addition, the development workload will increase and it is difficult to unify, which also increases the code maintenance cost.
In view of this actual situation, we need to decouple all types of exception handling from each processing process, which not only ensures the single function of relevant processing processes, but also realizes the unified processing and maintenance of exception information. At the same time, we don't want to throw the exception directly to the user. We should deal with the exception, encapsulate the error information, and then return a friendly information to the user. This section mainly summarizes how to use Spring Boot in the project and how to intercept and handle global exceptions.
1. Define the returned unified json structure
When the front end or other services request the interface of the service, the interface needs to return the corresponding json data. Generally, the service only needs to return the required parameters. However, in the actual project, we need to encapsulate more information, such as status code, related information msg, etc. on the one hand, there can be a unified return structure in the project, The whole project team is applicable. On the other hand, it is convenient to combine the global exception handling information, because in the exception handling information, we generally need to feed back the status code and exception content to the caller.
This unified json structure can be referred to Lesson 02: return JSON data and data encapsulation by Spring Boot For the unified json structure encapsulated in, we can simplify the content of this section and only keep the status code and exception information msg. As follows:
public class JsonResult {
/**
* Exception code
*/
protected String code;
/**
* Abnormal information
*/
protected String msg;
public JsonResult() {
this.code = "200";
this.msg = "Operation succeeded";
}
public JsonResult(String code, String msg) {
this.code = code;
this.msg = msg;
}
// get set
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2. Handling system exceptions
Create a GlobalExceptionHandler global exception handling class, and then add the @ ControllerAdvice @ annotation to intercept the exceptions thrown in the project, as follows:
@ControllerAdvice
@ResponseBody
public class GlobalExceptionHandler {
// Print log
private static final Logger logger = LoggerFactory.getLogger(GlobalExceptionHandler.class);
// ......
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
We can see by clicking the @ ControllerAdvice annotation that the @ ControllerAdvice annotation contains the @ Component annotation, which indicates that when Spring Boot starts, this class will also be handed over to Spring as a component for management. In addition, the annotation also has a "basePackages" attribute, which is used to intercept exception information in which package. Generally, we do not specify this attribute, but we intercept all exceptions in the project@ The ResponseBody annotation is used to output json format encapsulated data to the caller after exception handling.
How to use it in the project? In Spring Boot, it is very simple to specify the specific exception on the method through the @ ExceptionHandler annotation, then process the exception information in the method, and finally return the result to the caller through the unified json structure. Let's give some examples to illustrate how to use it.
2.1 processing parameter missing exception
In the front-end and back-end separated architecture, the front-end requests and the back-end interfaces are called through the rest style. Sometimes, for example, POST requests need to carry some parameters, but sometimes the parameters are omitted. In addition, in the microservice architecture, this may also happen when the interface calls between multiple microservices are involved. At this time, we need to define a method to deal with the exception of missing parameters to prompt a friendly message to the front end or caller.
When the parameter is missing, an HttpMessageNotReadableException will be thrown. We can intercept the exception and handle it friendly, as follows:
/**
* Missing request parameter exception
* @param ex HttpMessageNotReadableException
* @return
*/
@ExceptionHandler(MissingServletRequestParameterException.class)
@ResponseStatus(value = HttpStatus.BAD_REQUEST)
public JsonResult handleHttpMessageNotReadableException(
MissingServletRequestParameterException ex) {
logger.error("Missing request parameters,{}", ex.getMessage());
return new JsonResult("400", "The required request parameters are missing");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Let's write a simple Controller to test the exception and receive two parameters through POST request: name and password.
@RestController
@RequestMapping("/exception")
public class ExceptionController {
private static final Logger logger = LoggerFactory.getLogger(ExceptionController.class);
@PostMapping("/test")
public JsonResult test(@RequestParam("name") String name,
@RequestParam("pass") String pass) {
logger.info("name: {}", name);
logger.info("pass: {}", pass);
return new JsonResult();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Then use Postman to call the interface. When calling, only pass the name and no password, and the missing parameter exception will be thrown. After the exception is caught, it will enter the logic written by us and return a friendly message to the caller, as follows:
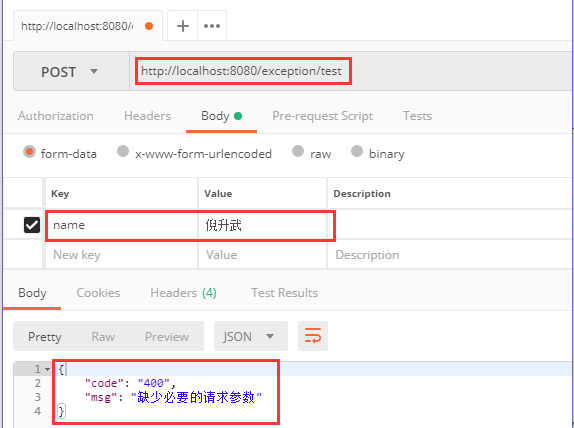
2.2 handling null pointer exceptions
Null pointer exception is a common thing in development. What are the common places?
Let's talk about some points for attention first. For example, in microservices, other services are often called to obtain data. This data is mainly in json format, but it may appear empty in the process of parsing json. Therefore, when we obtain a jsonObject and then obtain relevant information through the jsonObject, we should first make a non empty judgment.
Another common place is the data queried from the database. Whether querying a record encapsulated in an object or querying multiple records encapsulated in a List, we have to deal with the data next, so there may be null pointer exceptions, because no one can guarantee that the things found from the database will not be null, Therefore, when using data, you must first make non empty judgment.
The handling of null pointer exceptions is very simple. Like the above logic, you can replace the exception information. As follows:
@ControllerAdvice
@ResponseBody
public class GlobalExceptionHandler {
private static final Logger logger = LoggerFactory.getLogger(GlobalExceptionHandler.class);
/**
* Null pointer exception
* @param ex NullPointerException
* @return
*/
@ExceptionHandler(NullPointerException.class)
@ResponseStatus(value = HttpStatus.INTERNAL_SERVER_ERROR)
public JsonResult handleTypeMismatchException(NullPointerException ex) {
logger.error("Null pointer exception,{}", ex.getMessage());
return new JsonResult("500", "Null pointer exception");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
I won't test this. In the code, the ExceptionController has a "testNullPointException" method, which simulates a null pointer exception. We can see the returned information by requesting the corresponding url in the browser:
{"code":"500","msg":"Null pointer exception"}
- 1
2.3 once and for all?
Of course, there are many exceptions, such as RuntimeException, and some query or operation exceptions in the database. Because Exception exception is the parent class, all exceptions will inherit the Exception, so we can directly intercept Exception exceptions and do it once and for all:
@ControllerAdvice
@ResponseBody
public class GlobalExceptionHandler {
private static final Logger logger = LoggerFactory.getLogger(GlobalExceptionHandler.class);
/**
* System exception unexpected exception
* @param ex
* @return
*/
@ExceptionHandler(Exception.class)
@ResponseStatus(value = HttpStatus.INTERNAL_SERVER_ERROR)
public JsonResult handleUnexpectedServer(Exception ex) {
logger.error("System exception:", ex);
return new JsonResult("500", "An exception occurred in the system. Please contact the administrator");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
However, in the project, we generally intercept some common exceptions in detail. Although intercepting exceptions can be done once and for all, it is not conducive for us to troubleshoot or locate problems. In the actual project, you can write the intercepted Exception at the bottom of GlobalExceptionHandler. If it is not found, finally intercept the Exception to ensure that the output information is friendly.
3. Intercept custom exceptions
In actual projects, in addition to intercepting some system exceptions, we need to customize some business exceptions in some businesses. For example, in micro services, the mutual calls between services are very ordinary and common. To handle the call of a service, the call may fail or timeout. At this time, we need to customize an exception, throw the exception when the call fails, and give it to the GlobalExceptionHandler to catch.
3.1 define exception information
There are many exceptions in the business, and different prompt information may be given for different businesses. Therefore, in order to facilitate the project exception information management, we will generally define an exception information enumeration class. For example:
/**
* Business exception prompt information enumeration class
* @author shengwu ni
*/
public enum BusinessMsgEnum {
/** Parameter exception */
PARMETER_EXCEPTION("102", "Parameter exception!"),
/** Wait timeout */
SERVICE_TIME_OUT("103", "Service call timeout!"),
/** Parameter too large */
PARMETER_BIG_EXCEPTION("102", "The number of pictures entered cannot exceed 50!"),
/** 500 : Once and for all tips can also be defined here */
UNEXPECTED_EXCEPTION("500", "The system is abnormal, please contact the administrator!");
// You can also define more business exceptions
/**
* Message code
*/
private String code;
/**
* Message content
*/
private String msg;
private BusinessMsgEnum(String code, String msg) {
this.code = code;
this.msg = msg;
}
// set get method
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
3.2 intercept custom exceptions
Then we can define a business exception. When a business exception occurs, we can throw the custom business exception. For example, we define a BusinessErrorException exception as follows:
/**
* Custom business exception
* @author shengwu ni
*/
public class BusinessErrorException extends RuntimeException {
private static final long serialVersionUID = -7480022450501760611L;
/**
* Exception code
*/
private String code;
/**
* Exception prompt information
*/
private String message;
public BusinessErrorException(BusinessMsgEnum businessMsgEnum) {
this.code = businessMsgEnum.code();
this.message = businessMsgEnum.msg();
}
// get set method
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
In the construction method, we pass in the above customized exception enumeration class. Therefore, in the project, if new exception information needs to be added, we can directly add it in the enumeration class. It is very convenient to maintain it uniformly, and then obtain it when intercepting the exception.
@ControllerAdvice
@ResponseBody
public class GlobalExceptionHandler {
private static final Logger logger = LoggerFactory.getLogger(GlobalExceptionHandler.class);
/**
* Intercept business exceptions and return business exception information
* @param ex
* @return
*/
@ExceptionHandler(BusinessErrorException.class)
@ResponseStatus(value = HttpStatus.INTERNAL_SERVER_ERROR)
public JsonResult handleBusinessError(BusinessErrorException ex) {
String code = ex.getCode();
String message = ex.getMessage();
return new JsonResult(code, message);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
In the business code, we can directly simulate throwing business exceptions and test:
@RestController
@RequestMapping("/exception")
public class ExceptionController {
private static final Logger logger = LoggerFactory.getLogger(ExceptionController.class);
@GetMapping("/business")
public JsonResult testException() {
try {
int i = 1 / 0;
} catch (Exception e) {
throw new BusinessErrorException(BusinessMsgEnum.UNEXPECTED_EXCEPTION);
}
return new JsonResult();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Run the project and test it. The returned json is as follows, indicating that our customized business exception is successfully captured:
{"code":"500","msg":"The system is abnormal, please contact the administrator!"}
- 1
4. Summary
This course mainly explains the global exception handling of Spring Boot, including the encapsulation of exception information, the capture and processing of exception information, as well as the capture and processing of custom exception enumeration classes and business exceptions used in actual projects. They are widely used in projects. Basically, global exception handling is required in every project.
Course source code download address: Poke me to download
Lesson 09: facet AOP processing in Spring Boot
1. What is AOP
AOP: abbreviation of Aspect Oriented Programming, which means Aspect Oriented Programming. The goal of Aspect Oriented Programming is to separate concerns. What are the concerns? Is the focus, is what you have to do. If you are a childe and have no goal in life, you only know one thing all day: play (this is your focus, as long as you do this)! But there is a problem. Before you play, you still need to get up, wear clothes, wear shoes, fold quilts, make breakfast, etc., but you don't want to pay attention to these things. You just want to play, so what should you do?
yes! All these things are left to the servants. You have A special servant A to help you dress, servant B to help you wear shoes, servant C to help you fold the quilt, and servant D to help you cook. Then you start eating and playing (this is your business of the day). After you finish your business, you come back, and then A series of servants start to help you do this and that, and then the day is over!
This is AOP. The advantage of AOP is that you only need to do your business and others do other things for you. Maybe one day, if you want to run naked and don't want to wear clothes, you just fire servant A! Maybe one day, before you go out, you want to bring some money, so you hire A servant E to help you get money! This is AOP. Each person performs his own duties and combines flexibly to achieve A configurable and pluggable program structure.
2. AOP processing in spring boot
2.1 AOP dependency
To use AOP, you first need to introduce AOP dependencies.
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency>
- 1
- 2
- 3
- 4
2.2 realize AOP section
Using AOP in Spring Boot is very simple. If we want to print some logs in the project, after introducing the above dependencies, we will create a new class LogAspectHandler to define aspects and processing methods. Just add an @ Aspect annotation to the class@ The Aspect} annotation is used to describe an Aspect class, which needs to be marked when defining the Aspect class@ The Component annotation leaves this class to Spring to manage.
@Aspect
@Component
public class LogAspectHandler {
}
- 1
- 2
- 3
- 4
- 5
Here we mainly introduce several common annotations and their use:
1.@Pointcut: define an aspect, that is, the entry of something of concern described above.
2.@Before: something done before doing something.
3.@After: something done after doing something.
4.@AfterReturning: after doing something, enhance its return value.
5.@AfterThrowing: handle when an exception is thrown when doing something.
2.2.1 @Pointcut annotation
@Pointcut annotation: used to define an aspect (entry point), that is, the entry point of something concerned above. Pointcuts determine what join points focus on, allowing us to control when notifications are executed.
@Aspect
@Component
public class LogAspectHandler {
/**
* Define a section to intercept com itcodai. course09. All methods under the controller package and sub package
*/
@Pointcut("execution(* com.itcodai.course09.controller..*.*(..))")
public void pointCut() {}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
@The Pointcut annotation specifies a section and defines what needs to be intercepted. Here are two common expressions: one is to use {execution(), and the other is to use} annotation().
Execute (* com. Itcodai. Course09. Controller.. *. * (..)) As an example, the syntax is as follows:
execution() is the body of the expression
Position of the first * sign: indicates the return value type, * indicates all types
Package name: indicates the name of the package to be intercepted. The following two periods represent the current package and all sub packages of the current package. Com itcodai. course09. Controller: methods of all classes under package and sub package
Position of the second * sign: indicates the class name, * indicates all classes
*(..) : This asterisk represents the method name, * represents all methods, the following parentheses represent the method parameters, and two periods represent any parameters
annotation() is used to define facets for an annotation. For example, we can define facets for methods with @ GetMapping annotation as follows:
@Pointcut("@annotation(org.springframework.web.bind.annotation.GetMapping)")
public void annotationCut() {}
- 1
- 2
Then, if you use this aspect, you will cut into the method whose annotation is @ GetMapping #. In actual projects, different annotations may have different logical processing, such as @ GetMapping, @ PostMapping, @ DeleteMapping, etc. Therefore, this entry method according to annotations is also very common in practical projects.
2.2.2 @Before annotation
@The method specified by Before annotation is executed Before cutting into the target method. You can do some log processing or statistics of information, such as obtaining the user's request url and user's ip address. This can be used when making a personal site. It is a common method. For example:
@Aspect
@Component
public class LogAspectHandler {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
/**
* Execute this method before the slice method defined above
* @param joinPoint jointPoint
*/
@Before("pointCut()")
public void doBefore(JoinPoint joinPoint) {
logger.info("====doBefore Method entered====");
// Get signature
Signature signature = joinPoint.getSignature();
// Get the package name
String declaringTypeName = signature.getDeclaringTypeName();
// Gets the name of the method to be executed
String funcName = signature.getName();
logger.info("The method to be executed is: {},belong to{}package", funcName, declaringTypeName);
// It can also be used to record some information, such as the url and ip of the request
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = attributes.getRequest();
// Get request url
String url = request.getRequestURL().toString();
// Get request ip
String ip = request.getRemoteAddr();
logger.info("User requested url Is:{},ip The address is:{}", url, ip);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
JointPoint object is very useful. You can use it to obtain a signature, and then use the signature to obtain the requested package name, method name, including parameters (obtained through joinPoint.getArgs()), and so on.
2.2.3 @After annotation
@The After annotation corresponds to the @ Before annotation. The specified method is executed After cutting into the target method. You can also do some log processing After completing a method.
@Aspect
@Component
public class LogAspectHandler {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
/**
* Define a section to intercept com itcodai. course09. All methods under the controller package
*/
@Pointcut("execution(* com.itcodai.course09.controller..*.*(..))")
public void pointCut() {}
/**
* This method is executed after the slice method defined above
* @param joinPoint jointPoint
*/
@After("pointCut()")
public void doAfter(JoinPoint joinPoint) {
logger.info("====doAfter Method entered====");
Signature signature = joinPoint.getSignature();
String method = signature.getName();
logger.info("method{}Has been executed", method);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
Here, let's write a Controller to test the execution results. Create an AopController as follows:
@RestController
@RequestMapping("/aop")
public class AopController {
@GetMapping("/{name}")
public String testAop(@PathVariable String name) {
return "Hello " + name;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Start the project, enter localhost:8080/aop/CSDN in the browser, and observe the output information of the console:
====doBefore Method entered==== The method to be executed is: testAop,belong to com.itcodai.course09.controller.AopController package User requested url Is: http://localhost:8080/aop/name, ip address: 0:0:0:0:0:0:1 ====doAfter Method entered==== method testAop Has been executed
- 1
- 2
- 3
- 4
- 5
From the printed log, we can see the logic and order of program execution, and can intuitively grasp the actual role of @ Before and @ After annotations.
2.2.4 @AfterReturning annotation
@The AfterReturning annotation is somewhat similar to @ After @. The difference is that the @ AfterReturning annotation can be used to capture the return value After the entry method is executed, and enhance the business logic of the return value, for example:
@Aspect
@Component
public class LogAspectHandler {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
/**
* After the facet method defined above returns, execute the method to capture or enhance the return object
* @param joinPoint joinPoint
* @param result result
*/
@AfterReturning(pointcut = "pointCut()", returning = "result")
public void doAfterReturning(JoinPoint joinPoint, Object result) {
Signature signature = joinPoint.getSignature();
String classMethod = signature.getName();
logger.info("method{}After execution, the return parameters are:{}", classMethod, result);
// In actual projects, specific return value enhancements can be made according to the business
logger.info("Business enhancement of return parameters:{}", result + "Enhanced version");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
It should be noted that in the @ AfterReturning annotation, the value of the attribute {returning} must be consistent with the parameter, otherwise it will not be detected. The second input parameter in this method is the return value of the cut method. In the {doAfterReturning} method, the return value can be enhanced and encapsulated accordingly according to business needs. Let's restart the service and test it again (I won't post the redundant log s):
method testAop After execution, the return parameters are: Hello CSDN Business enhancement of return parameters: Hello CSDN Enhanced version
- 1
- 2
2.2.5 @AfterThrowing annotation
As the name suggests, @ AfterThrowing , annotation is that when an exception is thrown during the execution of the cut method, it will be executed in the @ AfterThrowing , annotated method. Some exception handling logic can be done in this method. Note that the value of the {throwing} attribute must be consistent with the parameter, otherwise an error will be reported. The second input parameter in the method is the exception thrown.
/**
* Processing log s using AOP
* @author shengwu ni
* @date 2018/05/04 20:24
*/
@Aspect
@Component
public class LogAspectHandler {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
/**
* Execute the slice method defined above when throwing exceptions
* @param joinPoint jointPoint
* @param ex ex
*/
@AfterThrowing(pointcut = "pointCut()", throwing = "ex")
public void afterThrowing(JoinPoint joinPoint, Throwable ex) {
Signature signature = joinPoint.getSignature();
String method = signature.getName();
// Logic for handling exceptions
logger.info("Execution method{}Error with exception:{}", method, ex);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
I won't test this method. You can test it yourself.
3. Summary
This lesson explains AOP in Spring Boot in detail. It mainly introduces the introduction of AOP in Spring Boot, the use of common annotations, the use of parameters, and the introduction of common APIs. AOP is very useful in practical projects. Before and after the execution of the aspect method, you can do corresponding preprocessing or enhancement processing according to the specific business. At the same time, it can also be used as exception capture processing. You can use AOP reasonably according to the specific business scenario.
Course source code download address: Poke me to download
Lesson 10: Spring Boot integrates MyBatis
1. Introduction to mybatis
As we all know, mybatis framework is a persistence layer framework and a top-level project under Apache. Mybatis allows developers to focus on sql and generate sql statements that meet their needs freely and flexibly through the mapping method provided by mybatis. Use simple XML or annotations to configure and map native information, and map interfaces and Java POJOs into records in the database, which accounts for half of the country. This course mainly explains the Spring Boot integration mybatis in two ways. Focus on the annotation based approach. Because annotations are used more and more succinctly in actual projects, which saves a lot of XML configuration (this is not absolute, and some project groups may also use XML).
2. MyBatis configuration
2.1 dependency import
Spring Boot integrates with MyBatis. You need to import the dependencies of MyBatis Spring Boot starter and mysql. The version we use here is 1.3.2, as follows:
<dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>1.3.2</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
When we click on the "mybatis Spring Boot starter" dependency, we can see the familiar dependencies when we use Spring. As I introduced at the beginning of the course, Spring Boot is committed to simplifying coding and integrating relevant dependencies with the starter series. Developers do not need to pay attention to cumbersome configuration, which is very convenient.
<!-- Omit other -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.2 properties.yml configuration
Let's take a look again. When integrating MyBatis, you need to use properties What are the basic configurations in the YML configuration file?
# Service port number
server:
port: 8080
# Database address
datasource:
url: localhost:3306/blog_test
spring:
datasource: # Database configuration
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${datasource.url}?useSSL=false&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&autoReconnect=true&failOverReadOnly=false&maxReconnects=10
username: root
password: 123456
hikari:
maximum-pool-size: 10 # Maximum number of connection pools
max-lifetime: 1770000
mybatis:
# Specifies that the package set by the alias is all entities
type-aliases-package: com.itcodai.course10.entity
configuration:
map-underscore-to-camel-case: true # Hump naming specification
mapper-locations: # mapper mapping file location
- classpath:mapper/*.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
Let's briefly introduce the above configurations: I won't explain the related configurations of the database in detail. I believe you are very skilled. Configure the user name, password, database connection, etc. the connection pool used here is hikari from Spring Boot. Interested friends can go to Baidu or Google to find out.
Here's an explanation. Map underscore to camel case: true is used to open the hump naming standard. This is easy to use. For example, the field name in the database is user_name, the attribute can be defined as "username" in the entity class (it can even be written as "username", which can also be mapped). It will be automatically matched to the hump attribute. If it is not configured in this way, it will not be mapped to the hump attribute according to the different field name and attribute name.
3. xml based integration
To use the original xml method, you need to create a new usermapper xml file, in the above application In the YML configuration file, we have defined the path of the xml file: classpath: mapper / * xml, so we create a mapper folder under the resources directory, and then create a UserMapper.xml XML file.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itcodai.course10.dao.UserMapper">
<resultMap id="BaseResultMap" type="com.itcodai.course10.entity.User">
<id column="id" jdbcType="BIGINT" property="id" />
<result column="user_name" jdbcType="VARCHAR" property="username" />
<result column="password" jdbcType="VARCHAR" property="password" />
</resultMap>
<select id="getUserByName" resultType="User" parameterType="String">
select * from user where user_name = #{username}
</select>
</mapper>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
This is the same as integrating Spring. The corresponding Mapper is specified in the namespace, and the corresponding entity class, User, is specified in < resultmap >. Then, you can internally specify that the fields of the table correspond to the attributes of the entity. Here we write an sql to query users according to their User names.
There are id, username and password in the entity class. I won't post the code here. You can download the source code to view it. UserMapper. Just write an interface in the java file:
User getUserByName(String username);
- 1
Omit the service code in the middle. Let's write a Controller to test:
@RestController
public class TestController {
@Resource
private UserService userService;
@RequestMapping("/getUserByName/{name}")
public User getUserByName(@PathVariable String name) {
return userService.getUserByName(name);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Start the project and enter in the browser: http://localhost:8080/getUserByName/CSDN You can query the user information with the user name CSDN in the database table (you can get two data in advance):
{"id":2,"username":"CSDN","password":"123456"}
- 1
Here we need to pay attention to: how does Spring Boot know this mapper? One method is to add @ mapper annotation on the classes corresponding to the mapper layer above, but this method has a disadvantage. When we have many mappers, we have to add @ mapper annotation on each class. Another simple method is to add the @ MaperScan @ annotation on the Spring Boot startup class to scan all mappers under a package. As follows:
@SpringBootApplication
@MapperScan("com.itcodai.course10.dao")
public class Course10Application {
public static void main(String[] args) {
SpringApplication.run(Course10Application.class, args);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
In that case, com itcodai. course10. All mapper s under Dao} package will be scanned.
4. Annotation based integration
xml configuration files are not required for annotation based integration. MyBatis mainly provides @ Select, @ Insert, @ Update and Delete. These four annotations are very common and simple. They can be followed by the corresponding sql statement. Let's take an example:
@Select("select * from user where id = #{id}")
User getUser(Long id);
- 1
- 2
This is the same as writing sql statements in xml files, so there is no need for xml files. However, someone may ask, what if it is two parameters? If there are two parameters, we need to use the @ Param annotation to specify the corresponding relationship of each parameter, as follows:
@Select("select * from user where id = #{id} and user_name=#{name}")
User getUserByIdAndName(@Param("id") Long id, @Param("name") String username);
- 1
- 2
It can be seen that the parameter specified by @ Param should be the same as the parameter name taken in #{} sql, otherwise it cannot be taken. You can test yourself in the controller. The interfaces are in the source code. I won't post the test code and results in the article.
There is a problem that we should pay attention to. Generally, after designing table fields, we will generate entity classes according to the automatic generation tool. In this way, entity classes can basically correspond to table fields, at least humps. Since hump configuration is enabled in the above configuration file, the fields can be matched. But what if there is something wrong? We also have a solution, using the @ Results} annotation.
@Select("select * from user where id = #{id}")
@Results({
@Result(property = "username", column = "user_name"),
@Result(property = "password", column = "password")
})
User getUser(Long id);
- 1
- 2
- 3
- 4
- 5
- 6
@The @ Result annotation in Results is used to specify the corresponding relationship between each attribute and field, so that the above problem can be solved.
Of course, we can also combine xml and annotation. At present, we also use mixed methods in our actual projects, because sometimes xml is convenient and sometimes annotation is convenient. For example, for the above problem, if we define the above usermapper xml, we can use @ ResultMap , annotation instead of @ Results , annotation, as follows:
@Select("select * from user where id = #{id}")
@ResultMap("BaseResultMap")
User getUser(Long id);
- 1
- 2
- 3
@Where do the values in the ResultMap annotation come from? The corresponding is usermapper id value corresponding to < ResultMap > defined in XML file:
<resultMap id="BaseResultMap" type="com.itcodai.course10.entity.User">
- 1
This combination of xml and annotations is also very common, and it also reduces a lot of code. Because xml files can be generated by automatic generation tools without manual typing, this use is also very common.
5. Summary
This lesson mainly systematically explains the process of Spring Boot integrating MyBatis, which is divided into xml based and annotation based forms. Through the actual configuration, it explains the use of MyBatis in Spring Boot, and explains the solutions to common problems according to the annotation method, which has strong practical significance. In the actual project, it is recommended to determine which method to use according to the actual situation. Generally, xml and annotations are used.
Course source code download address: Poke me to download
Lesson 11: Spring Boot transaction configuration management
1. Transaction related
Scenario: when we are developing enterprise applications, due to the sequential execution of data operations, there may be various unpredictable problems on the line. Exceptions may occur in any step of operation, which will lead to the failure of subsequent operations. At this time, because the business logic is not completed correctly, the action of operating the database before is not reliable. In this case, it is necessary to roll back the data.
The function of transaction is to ensure that every operation of the user is reliable. Every operation in the transaction must be executed successfully. As long as there is an exception, it will fall back to the state where no operation is carried out at the beginning of the transaction. It's easy to understand. Transfer, ticket purchase, etc. can only be successfully executed after the whole event process is completed. You can't transfer money to half. The system is dead, the money of the transferor is gone, and the money of the payee hasn't arrived yet.
Transaction management is one of the most commonly used functions in the Spring Boot framework. In actual application development, we basically add transactions when processing business logic in the service layer. Of course, sometimes it may be required by the scenario, There is no need to add transactions (for example, we need to insert data into a table, which has no influence on each other. How much is inserted. We can't roll back all the previously inserted data because a certain data hangs).
2. Spring Boot transaction configuration
2.1 dependency import
To use transactions in Spring Boot, you need to import mysql dependencies:
<dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>1.3.2</version> </dependency>
- 1
- 2
- 3
- 4
- 5
After importing mysql dependencies, Spring Boot will automatically inject DataSourceTransactionManager. We can use @ Transactional annotation for transactions without any other configuration. The configuration of mybatis has been explained in the previous lesson. Here, just use the configuration of mybatis in the previous lesson.
2.2 transaction testing
We first insert a piece of data into the database table:
| id | user_name | password |
|---|---|---|
| 1 | Ni Shengwu | 123456 |
Then we write an inserted mapper:
public interface UserMapper {
@Insert("insert into user (user_name, password) values (#{username}, #{password})")
Integer insertUser(User user);
}
- 1
- 2
- 3
- 4
- 5
OK, next, let's test the transaction processing in Spring Boot. At the service layer, we manually throw an exception to simulate the actual exception, and then observe whether the transaction is rolled back. If there is no new record in the database, the transaction rollback is successful.
@Service
public class UserServiceImpl implements UserService {
@Resource
private UserMapper userMapper;
@Override
@Transactional
public void isertUser(User user) {
// Insert user information
userMapper.insertUser(user);
// Throw exception manually
throw new RuntimeException();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Let's test:
@RestController
public class TestController {
@Resource
private UserService userService;
@PostMapping("/adduser")
public String addUser(@RequestBody User user) throws Exception {
if (null != user) {
userService.isertUser(user);
return "success";
} else {
return "false";
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
We use postman to call this interface, because an exception is thrown in the program, which will cause transaction rollback. We refresh the database without adding a record, indicating that the transaction is effective. The business is very simple. We usually don't have many problems when using it, but it's not just that
3. Summary of common problems
As can be seen from the above content, the use of transactions in Spring Boot is very simple, and the @ Transactional annotation can solve the problem. That's what I say. However, in the actual project, there are many small pits waiting for us. These small pits are not noticed when we write code, and they are not easy to find under normal circumstances. When the project is written large, One day, there was a problem suddenly. It was very difficult to find the problem. At that time, it must be blind. It took a lot of energy to find the problem.
In this section, I specifically summarize the details related to affairs that often appear in actual projects. I hope readers can implement them into their own projects and benefit from them after reading them.
3.1 the exception is not "caught"
First of all, The exception is not caught, which leads to the transaction not being rolled back. We may have considered the existence of the exception in the business layer code, or the editor has prompted us to throw an exception, but there is something to pay attention to: it does not mean that if we throw the exception, the transaction will be rolled back. Let's take an example:
@Service
public class UserServiceImpl implements UserService {
@Resource
private UserMapper userMapper;
@Override
@Transactional
public void isertUser2(User user) throws Exception {
// Insert user information
userMapper.insertUser(user);
// Throw exception manually
throw new SQLException("Database exception");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Let's look at the above code. In fact, there is no problem. Manually throw a SQLException to simulate the exceptions that occur in the actual operation of the database. In this method, since an exception is thrown, the transaction should be rolled back, but it is not. Readers can use the controller interface in my source code and test it through postman, You can still insert a piece of user data.
So what's the problem? Because the default transaction rule of Spring Boot is to roll back only in case of RuntimeException and program Error. For example, there is no problem with the RuntimeException thrown in our example above, but the SQLException thrown cannot be rolled back. For non runtime exceptions, if you want to roll back a transaction, you can use the rollback for attribute in the @ Transactional annotation to specify the exception, such as @ Transactional (rollback for = exception. Class), so there is no problem. Therefore, in the actual project, you must specify the exception.
3.2 abnormal is "eaten"
This title is very funny. How can exceptions be eaten? Or return to the real project. When dealing with exceptions, we have two ways: either throw them out and let the upper layer capture and handle them; Or try to catch the exception and handle it where the exception occurs. Because of this try... Catch, the exception is "eaten" and the transaction cannot be rolled back. Let's look at the above example, but simply modify the code:
@Service
public class UserServiceImpl implements UserService {
@Resource
private UserMapper userMapper;
@Override
@Transactional(rollbackFor = Exception.class)
public void isertUser3(User user) {
try {
// Insert user information
userMapper.insertUser(user);
// Throw exception manually
throw new SQLException("Database exception");
} catch (Exception e) {
// Exception handling logic
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Readers can use the controller interface in my source code and test it through postman. They will find that a piece of user data can still be inserted, indicating that the transaction has not been rolled back because an exception is thrown. This detail is often more difficult to find than the pit above, because our thinking can easily lead to the generation of try... catch code. Once this problem occurs, it is often difficult to find it. Therefore, we must think more and pay more attention to this detail when writing code, and try to avoid burying a pit for ourselves.
How to solve this problem? Just throw it up and give it to the next level. Don't "eat" yourself in the business.
3.3 scope of transaction
Transaction scope is deeper than the above two pits! The reason why I wrote this is because I met this in an actual project before. I will not simulate this scene in this course. I will write a demo for you to see and remember this pit. When I encounter concurrency problems in writing code in the future, I will pay attention to this pit, so this class will be valuable.
Let me write a demo:
@Service
public class UserServiceImpl implements UserService {
@Resource
private UserMapper userMapper;
@Override
@Transactional(rollbackFor = Exception.class)
public synchronized void isertUser4(User user) {
// Specific business in practice
userMapper.insertUser(user);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
As you can see, to consider concurrency, I added a synchronized keyword to the method of business layer code. Let me cite a practical scenario. For example, in a database, there is only one record for a user. When the next insertion action comes, it will first judge whether there are the same users in the database. If there are, they will not be inserted, they will be updated, and if not, they will be inserted. Therefore, theoretically, there will always be the same user information in the database, There will not be two pieces of information of the same user inserted into the same database.
However, during pressure measurement, the above problems will occur. There are indeed two pieces of information of the same user in the database. According to analysis, the reason lies in the scope of transaction and the scope of lock.
As can be seen from the above method, a transaction is added to the method, that is, when the method is executed, the transaction is started, and after execution, the transaction is closed. But synchronized doesn't work. In fact, the root cause is that the scope of transactions is larger than that of locks. In other words, after the execution of the locked part of the code, the lock is released, but the transaction is not over. At this time, another thread comes in. If the transaction is not over, when the second thread comes in, the database state is the same as that of the first thread. That is, since the default isolation level of mysql Innodb engine is repeatable (in the same transaction, the result of SELECT is the state at the time point when the transaction starts), when the transaction of thread 2 starts, thread 1 has not been committed, resulting in the read data has not been updated. The second thread also does the insertion action, resulting in dirty data.
This problem can be avoided. First, remove the transaction (not recommended); Second, lock the place where the service is called to ensure that the scope of the lock is larger than that of the transaction.
4. Summary
This chapter mainly summarizes how to use transactions in Spring Boot. As long as you use @ Transactional annotation, it is very simple and convenient. In addition, three possible pitfalls in the actual project are summarized, which is very meaningful, because it is OK that there are no problems with affairs, and it is difficult to troubleshoot problems. Therefore, I hope these three points of attention summarized can help friends in development.
Course source code download address: Poke me to download
Lesson 12: using listeners in Spring Boot
1. Introduction to listener
What is a web listener? Web listener is a special class in Servlet, which can help developers listen to specific events in the web, such as the creation and destruction of ServletContext, httpsession and ServletRequest; Creation, destruction and modification of variables. Processing can be added before and after some actions to realize monitoring.
2. Use of listener in spring boot
There are many usage scenarios for web listeners, such as listening to servlet context to initialize some data, listening to http session to obtain the number of people currently online, listening to servlet request object requested by client to obtain user access information, and so on. In this section, we will mainly learn about the use of listeners in Spring Boot through these three actual use scenarios.
2.1 listening for Servlet context objects
Listening servlet context objects can be used to initialize data for caching. What do you mean? Let me cite a very common scenario. For example, when users click on the home page of a site, they generally display some information of the home page, which remains unchanged basically or most of the time, but these information comes from the database. If users need to obtain data from the database every time they click, it is acceptable to have a small number of users. If the number of users is very large, it is also a great expense to the database.
If most of the home page data are not updated frequently, we can cache them. Every time the user clicks, we take them directly from the cache, which can not only improve the access speed of the home page, but also reduce the pressure on the server. If you are more flexible, you can add a timer to update the home page cache regularly. It is similar to the change of ranking in the home page of CSDN personal blog.
Let's write a demo for this function. In practice, readers can fully apply the code to realize the relevant logic in their own project. First, write a Service to simulate querying data from the database:
@Service
public class UserService {
/**
* Get user information
* @return
*/
public User getUser() {
// In practice, the corresponding information will be queried from the database according to the specific business scenario
return new User(1L, "Ni Shengwu", "123456");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Then write a listener, implement the {applicationlister < ContextRefreshedEvent > interface, override the} onApplicationEvent} method, and pass in the ContextRefreshedEvent object. If we want to refresh our preloaded resources when loading or refreshing the application context, we can do this by listening to ContextRefreshedEvent. As follows:
/**
* Use ApplicationListener to initialize some data to the listener in the application domain
* @author shengni ni
* @date 2018/07/05
*/
@Component
public class MyServletContextListener implements ApplicationListener<ContextRefreshedEvent> {
@Override
public void onApplicationEvent(ContextRefreshedEvent contextRefreshedEvent) {
// Get the application context first
ApplicationContext applicationContext = contextRefreshedEvent.getApplicationContext();
// Get the corresponding service
UserService userService = applicationContext.getBean(UserService.class);
User user = userService.getUser();
// Get the application domain object and put the found information into the application domain
ServletContext application = applicationContext.getBean(ServletContext.class);
application.setAttribute("user", user);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
As described in the note, first obtain the application context through the contextRefreshedEvent, and then obtain the UserService bean through the application context. In the project, you can obtain other beans according to the actual business scenario, then call your own business code to obtain the corresponding data, and finally store it in the application domain, In this way, when the front end requests corresponding data, we can directly obtain information from the application domain to reduce the pressure on the database. Next, write a Controller to get user information directly from the application domain to test.
@RestController
@RequestMapping("/listener")
public class TestController {
@GetMapping("/user")
public User getUser(HttpServletRequest request) {
ServletContext application = request.getServletContext();
return (User) application.getAttribute("user");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Start the project and enter in the browser http://localhost:8080/listener/user Test it. If the user information is returned normally, it indicates that the data has been cached successfully. However, the application is cached in memory, which will consume memory. I will talk about redis in later courses. I will introduce redis cache to you at that time.
2.2 listening to HTTP Session object
Another common use of the listener is to listen to the session object to obtain the number of online users. Now many developers have their own websites. Listening to the session to obtain the current number of users is a very common use scenario. Let's introduce how to use it.
/**
* Listener that uses HttpSessionListener to count the number of online users
* @author shengwu ni
* @date 2018/07/05
*/
@Component
public class MyHttpSessionListener implements HttpSessionListener {
private static final Logger logger = LoggerFactory.getLogger(MyHttpSessionListener.class);
/**
* Record the number of online users
*/
public Integer count = 0;
@Override
public synchronized void sessionCreated(HttpSessionEvent httpSessionEvent) {
logger.info("New users are online");
count++;
httpSessionEvent.getSession().getServletContext().setAttribute("count", count);
}
@Override
public synchronized void sessionDestroyed(HttpSessionEvent httpSessionEvent) {
logger.info("The user is offline");
count--;
httpSessionEvent.getSession().getServletContext().setAttribute("count", count);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
It can be seen that the listener needs to implement the HttpSessionListener interface first, then override the {sessionCreated} and {sessionDestroyed} methods, pass an HttpSessionEvent object in the {sessionCreated} method, and then add 1 to the number of users in the current session. The sessionDestroyed} method is just the opposite and will not be repeated. Then we write a Controller to test it.
@RestController
@RequestMapping("/listener")
public class TestController {
/**
* Get the current number of online people. There is a bug in this method
* @param request
* @return
*/
@GetMapping("/total")
public String getTotalUser(HttpServletRequest request) {
Integer count = (Integer) request.getSession().getServletContext().getAttribute("count");
return "Number of people currently online:" + count;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
In the Controller, you can directly obtain the number of users in the current session, start the server, enter localhost:8080/listener/total in the browser, and you can see that the returned result is 1. Then open a browser, request the same address, and you can see that the count is 2, which is no problem. However, if you close a browser and open it again, it should still be 2 in theory, but the actual test is 3. The reason is that the session destruction method is not executed (you can observe the log printing on the background console). When it is reopened, the server cannot find the user's original session, so a session is re created. How to solve this problem? We can transform the above Controller method:
@GetMapping("/total2")
public String getTotalUser(HttpServletRequest request, HttpServletResponse response) {
Cookie cookie;
try {
// Record the sessionId in the browser
cookie = new Cookie("JSESSIONID", URLEncoder.encode(request.getSession().getId(), "utf-8"));
cookie.setPath("/");
//Set the validity of the cookie to 2 days, and set it to be longer
cookie.setMaxAge( 48*60 * 60);
response.addCookie(cookie);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
Integer count = (Integer) request.getSession().getServletContext().getAttribute("count");
return "Number of people currently online:" + count;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
It can be seen that the processing logic is to make the server remember the original session, that is, record the original sessionId in the browser, and pass the sessionId to the server when it is opened next time, so that the server will not be re created. Restart the server and test it again in the browser to avoid the above problems.
2.3 listen to the Servlet Request object requested by the client
It is easy to use the listener to obtain the user's access information. You can implement the ServletRequestListener interface, and then obtain some information through the request object. As follows:
/**
* Get access information using ServletRequestListener
* @author shengwu ni
* @date 2018/07/05
*/
@Component
public class MyServletRequestListener implements ServletRequestListener {
private static final Logger logger = LoggerFactory.getLogger(MyServletRequestListener.class);
@Override
public void requestInitialized(ServletRequestEvent servletRequestEvent) {
HttpServletRequest request = (HttpServletRequest) servletRequestEvent.getServletRequest();
logger.info("session id Is:{}", request.getRequestedSessionId());
logger.info("request url Is:{}", request.getRequestURL());
request.setAttribute("name", "Ni Shengwu");
}
@Override
public void requestDestroyed(ServletRequestEvent servletRequestEvent) {
logger.info("request end");
HttpServletRequest request = (HttpServletRequest) servletRequestEvent.getServletRequest();
logger.info("request Saved in domain name The value is:{}", request.getAttribute("name"));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
This is relatively simple and will not be repeated. Next, write a Controller to test it.
@GetMapping("/request")
public String getRequestInfo(HttpServletRequest request) {
System.out.println("requestListener Initialized in name Data:" + request.getAttribute("name"));
return "success";
}
- 1
- 2
- 3
- 4
- 5
3. Custom event listening in spring boot
In actual projects, we often need to customize some events and listeners to meet business scenarios. For example, in microservices, microservices A needs to notify microservices B to process another logic after processing A logic, or microservices A needs to synchronize data to microservices B after processing A logic. This scenario is very common, At this time, we can customize events and listeners to listen. Once we listen to an event in microservice A, we will notify microservice B to process the corresponding logic.
3.1 user defined events
Custom events need to inherit the ApplicationEvent object, define a User object in the event to simulate data, and transfer the User object in the construction method for initialization. As follows:
/**
* Custom event
* @author shengwu ni
* @date 2018/07/05
*/
public class MyEvent extends ApplicationEvent {
private User user;
public MyEvent(Object source, User user) {
super(source);
this.user = user;
}
// get and set methods are omitted
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3.2 custom listener
Next, customize a listener to listen to the MyEvent event event defined above. The custom listener needs to implement the application listener interface. As follows:
/**
* Customize the listener to listen for MyEvent events
* @author shengwu ni
* @date 2018/07/05
*/
@Component
public class MyEventListener implements ApplicationListener<MyEvent> {
@Override
public void onApplicationEvent(MyEvent myEvent) {
// Get the information in the event
User user = myEvent.getUser();
// Handle events. In the actual project, you can notify other microservices or handle other logic, etc
System.out.println("user name:" + user.getUsername());
System.out.println("password:" + user.getPassword());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Then override the {onApplicationEvent} method to pass in the custom MyEvent event event, because in this event, we define the User object (this object is actually the data to be processed, which will be simulated below), and then we can use the information of this object.
OK, after defining the event and listener, you need to publish the event manually so that the listener can listen. This needs to be triggered according to the actual business scenario. For the example in this article, I write a trigger logic, as follows:
/**
* UserService
* @author shengwu ni
*/
@Service
public class UserService {
@Resource
private ApplicationContext applicationContext;
/**
* Publish event
* @return
*/
public User getUser2() {
User user = new User(1L, "Ni Shengwu", "123456");
// Publish event
MyEvent event = new MyEvent(this, user);
applicationContext.publishEvent(event);
return user;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
Inject ApplicationContext into the service. After the business code is processed, manually publish the MyEvent event event through the ApplicationContext object, so that our custom listener can listen and process the business logic written in the listener.
Finally, write an interface in the Controller to test:
@GetMapping("/request")
public String getRequestInfo(HttpServletRequest request) {
System.out.println("requestListener Initialized in name Data:" + request.getAttribute("name"));
return "success";
}
- 1
- 2
- 3
- 4
- 5
Enter in the browser http://localhost:8080/listener/publish , and then observe the user name and password printed on the console to indicate that the custom listener has taken effect.
4. Summary
This lesson systematically introduces the principle of listener and how to use listener in Spring Boot, and lists three common cases of listener, which has good practical significance. Finally, it explains how to customize events and listeners in the project, and gives specific code models combined with common scenarios in microservices, which can be applied to practical projects. I hope readers can digest them carefully.
Course source code download address: Poke me to download
Lesson 13: using interceptors in Spring Boot
The principle of interceptor is very simple. It is an implementation of AOP. It specifically intercepts background requests for dynamic resources, that is, intercepts requests for the control layer. There are many usage scenarios to judge whether the user has permission to request the background. There are also higher-level usage scenarios. For example, interceptors can be used in combination with websocket to intercept websocket requests and then handle them accordingly. The interceptor will not intercept static resources. The default static directory of Spring Boot is resources/static. The static pages, js, css, pictures, etc. in this directory will not be intercepted (it also depends on how to implement it. In some cases, it will also be intercepted, which I will point out below).
1. Rapid use of interceptors
Using interceptors is simple and requires only two steps: defining interceptors and configuring interceptors. In the configuration interceptor, the version after Spring Boot 2.0 is different from the previous version. I will focus on the possible pitfalls here.
1.1 defining interceptors
To define an interceptor, you only need to implement the HandlerInterceptor interface. The HandlerInterceptor interface is the ancestor of all custom interceptors or interceptors provided by Spring Boot. Therefore, let's first understand this interface. There are three methods in this interface: preHandle(...), postHandle(...), and {afterCompletion(...).
preHandle(...) method: the execution time of this method is when a url has been matched to a method in the corresponding Controller and before this method is executed. Therefore, the pre handle (...) method can decide whether to release the request, which is determined by the return value. If it returns true, it will be released, and if it returns false, it will not be executed backward.
postHandle(...) method: the execution time of this method is when a url has been matched to a method in the corresponding Controller, and after the method is executed, but before the dispatcher servlet view is rendered. Therefore, there is a ModelAndView parameter in this method, which can be modified here.
afterCompletion(...) method: as the name suggests, this method is executed after the entire request processing is completed (including view rendering). At this time, some resources are cleaned up. This method will be executed only after the pre handle (...) is successfully executed and returns true.
Now that you know the interface, you can customize an interceptor.
/**
* custom interceptor
* @author shengwu ni
* @date 2018/08/03
*/
public class MyInterceptor implements HandlerInterceptor {
private static final Logger logger = LoggerFactory.getLogger(MyInterceptor.class);
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
HandlerMethod handlerMethod = (HandlerMethod) handler;
Method method = handlerMethod.getMethod();
String methodName = method.getName();
logger.info("====Method intercepted:{},Execute before the method executes====", methodName);
// If true is returned, execution will continue. If false is returned, the current request will be canceled
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
logger.info("Execute after executing the method(Controller After method call),However, view rendering has not yet been performed");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
logger.info("The whole request has been processed, DispatcherServlet The corresponding view is also rendered. At this time, I can do some cleaning work");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
OK, so far, the interceptor has been defined. The next step is to configure the interceptor.
1.2 configure interceptors
Before Spring Boot 2.0, we directly inherited the WebMvcConfigurerAdapter class, and then overridden the addInterceptors method to implement interceptor configuration. However, after Spring Boot 2.0, this method has been abandoned (of course, it can continue to be used) and replaced by the WebMvcConfigurationSupport method, as follows:
@Configuration
public class MyInterceptorConfig extends WebMvcConfigurationSupport {
@Override
protected void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new MyInterceptor()).addPathPatterns("/**");
super.addInterceptors(registry);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
In this configuration, rewrite the , addInterceptors , method to add our customized interceptors above. The , addPathPatterns , method is to add requests to be intercepted. Here we intercept all requests. Then the interceptor is configured. Next, write a Controller to test:
@Controller
@RequestMapping("/interceptor")
public class InterceptorController {
@RequestMapping("/test")
public String test() {
return "hello";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Let it jump to hello HTML page, directly in hello Just output "hello interceptor" in HTML. Start the project, enter localhost:8080/interceptor/test in the browser to see the console log:
====Method intercepted: test,Execute before the method executes==== Execute after executing the method(Controller After method call),However, view rendering has not yet been performed The whole request has been processed, DispatcherServlet The corresponding view is also rendered. At this time, I can do some cleaning work
- 1
- 2
- 3
It can be seen that the interceptor has been effective and its execution sequence can be seen.
1.3 solve the problem of static resources being intercepted
The definition and configuration of interceptors have been introduced above, but is this OK? In fact, if we use the above configuration, we will find a defect that static resources are intercepted. You can place a picture resource or html file in the resources/static / directory, and then start the project to access it directly to see the inaccessible phenomenon.
In other words, although Spring Boot 2.0 discards the WebMvcConfigurerAdapter, WebMvcConfigurationSupport will cause the default static resources to be intercepted, which requires us to release the static resources manually.
How to let go? In addition to overriding the addInterceptors method in the MyInterceptorConfig configuration class, you also need to override another method: addResourceHandlers to release static resources:
/**
* It is used to specify that static resources are not intercepted. Otherwise, it inherits WebMvcConfigurationSupport, which will make static resources inaccessible directly
* @param registry
*/
@Override
protected void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler("/**").addResourceLocations("classpath:/static/");
super.addResourceHandlers(registry);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
After this configuration, restart the project and the static resources can be accessed normally. If you are good at learning or research, you will certainly not stop here. Yes, the above method can indeed solve the problem that static resources cannot be accessed, but there are more convenient ways to configure them.
Instead of inheriting the WebMvcConfigurationSupport class, we can directly implement the WebMvcConfigurer interface, and then override the "addInterceptors" method to add a custom interceptor, as follows:
@Configuration
public class MyInterceptorConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
// Implementing WebMvcConfigurer will not cause static resources to be intercepted
registry.addInterceptor(new MyInterceptor()).addPathPatterns("/**");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
This is very convenient. If the WebMvcConfigure interface is implemented, the default static resources of Spring Boot will not be intercepted.
Both of these two methods are OK. For the details between them, interested readers can do further research. Due to the differences between these two methods, the method of inheriting WebMvcConfigurationSupport class can be used in projects with front and back ends separated. The background does not need to access static resources (there is no need to release static resources); The way to implement the WebMvcConfigure interface can be used in projects that are not separated from the front and back, because you need to read some pictures, css, js files, and so on.
2. Use examples of interceptors
2.1 judge whether the user has logged in
For the general user login function, we can either write a user in the session or generate a token for each user. The second method is better. For the second method, if the user logs in successfully, the user's token will be brought with each request. If the user does not log in, there will be no token, The server can detect the presence or absence of the token parameter to judge whether the user has logged in, so as to realize the interception function. Let's modify the # preHandle # method as follows:
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
HandlerMethod handlerMethod = (HandlerMethod) handler;
Method method = handlerMethod.getMethod();
String methodName = method.getName();
logger.info("====Method intercepted:{},Execute before the method executes====", methodName);
// Judge whether the user has logged in. Generally, the logged in user has a corresponding token
String token = request.getParameter("token");
if (null == token || "".equals(token)) {
logger.info("The user is not logged in and has no permission to execute... Please log in");
return false;
}
// If true is returned, execution will continue. If false is returned, the current request will be canceled
return true;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
Restart the project, enter "localhost:8080/interceptor/test" in the browser and check the console log. It is found that it is intercepted. If you enter "localhost:8080/interceptor/test" in the browser? If token = 123 , you can go down normally.
2.2 cancel interception
According to the above, if I want to intercept all url requests starting with / Admin, I need to add this prefix to the interceptor configuration. However, in an actual project, there may be a scenario where a request also starts with / Admin, but cannot be intercepted, such as / admin/login. In this case, it needs to be configured. So, can I make something similar to a switch? Where there is no need to intercept, I will get a switch to make this flexible and pluggable effect?
Yes, we can define an annotation that is specifically used to cancel the interception operation. If we don't need to intercept a method in a Controller, we can add our custom annotation to the method. First define an annotation:
/**
* This annotation is used to specify that a method does not need to be intercepted
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface UnInterception {
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Then add the annotation on a method in the Controller, and add the annotation in the interceptor processing method to cancel the interception, as follows:
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
HandlerMethod handlerMethod = (HandlerMethod) handler;
Method method = handlerMethod.getMethod();
String methodName = method.getName();
logger.info("====Method intercepted:{},Execute before the method executes====", methodName);
// Through the method, you can obtain the user-defined annotation on the method, and then judge whether the method should be intercepted through the annotation
// @UnInterception is our custom annotation
UnInterception unInterception = method.getAnnotation(UnInterception.class);
if (null != unInterception) {
return true;
}
// If true is returned, execution will continue. If false is returned, the current request will be canceled
return true;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
See the source code for the method code in the Controller. Restart the project and enter it in the browser http://localhost:8080/interceptor/test2?token=123 Test it and you can see that the annotated method will not be intercepted.
3. Summary
This section mainly introduces the use of interceptors in Spring Boot, and makes a detailed analysis from the creation and configuration of interceptors to the impact of interceptors on static resources. After Spring Boot 2.0, interceptors can be configured in two ways. You can choose different configurations according to the actual situation. Finally, combined with the actual use, two common scenarios are given, hoping that readers can seriously digest and master the use of interceptors.
Course source code download address: Poke me to download
Lesson 14: integrating Redis in Spring Boot
1. Introduction to redis
Redis is a non relational database (NoSQL). NoSQL is stored in the form of key value. Unlike the traditional relational database, it does not necessarily follow some basic requirements of the traditional database, such as SQL standard, ACID attribute, table structure, etc. this kind of database mainly has the following characteristics: non relational, distributed, open source Horizontally scalable.
The usage scenarios of NoSQL include high concurrent reading and writing of data, efficient storage and access of massive data, high scalability and high availability of data, etc.
Redis key s can be strings, hashes, linked lists, collections, and ordered collections. There are many types of value, including String, list, set and zset. These data types support push/pop, add/remove, intersection and union, and more and richer operations. Redis also supports sorting in different ways. In order to ensure efficiency, the data is cached in memory. It can also periodically write the updated data to disk or write the modification operation to the additional record file. What are the benefits of redis? For a simple example, see the following figure:
Redis cluster and MySQL are synchronized. First, data will be obtained from redis. If redis hangs up, data will be obtained from MySQL so that the website will not hang up. For more information about redis and usage scenarios, you can Google and Baidu. I won't repeat it here.
2. Redis installation
This course is to install redis (centos 7) in vmvare virtual machine. If you have your own Alibaba cloud server, you can also install redis in Alibaba cloud. As long as you can ping the ip of the virtual machine or virtual machine, and then release the corresponding port in the virtual machine or virtual machine (or turn off the firewall), you can access redis. Let's introduce the installation process of redis:
- Install gcc compilation
Because redis needs to be compiled later, you have to install gcc compilation first. Alicloud hosts already have gcc installed by default. If you are installing your own virtual machine, you need to install gcc first:
yum install gcc-c++
- 1
- Download redis
There are two ways to download the installation package. One is to download it on the official website( https://redis.io ), and then add the installation package to centos. Another method is to directly use wget to download:
wget http://download.redis.io/releases/redis-3.2.8.tar.gz
- 1
If wget has not been installed, you can install it through the following command:
yum install wget
- 1
- Decompression installation
Unzip the installation package:
tar –vzxf redis-3.2.8.tar.gz
- 1
Then put the extracted folder redis-3.2.8 under / usr/local /, and the general installation software is under / usr/local /. Then enter the / usr/local/redis-3.2.8 / folder and execute the command "make" to complete the installation.
[note] if make fails, you can try the following command:
make MALLOC=libc make install
- 1
- 2
- Modify profile
After the installation is successful, you need to modify the configuration file, including the allowed access ip, allowing background execution, setting password, etc.
Open redis configuration file: VI redis conf
In the command mode, enter / bind , to find the bind configuration, and press n to find the next one. After finding the configuration, configure bind to 0.0.0.0, allowing any server to access redis, that is:
bind 0.0.0.0
- 1
Using the same method, change the daemon to yes (no by default), allowing redis to execute in the background.
Open the requirepass comment and set the password to 123456 (the password is set by yourself).
- Start redis
In the redis-3.2.8 directory, specify the newly modified configuration file redis Conf to start redis:
redis-server ./redis.conf
- 1
Restart the redis client:
redis-cli
- 1
Since we have set the password, after starting the client, enter "auth 123456" to log in to the client.
Then let's test and insert a data into redis:
set name CSDN
- 1
Then get the name
get name
- 1
If CSDN is obtained normally, there is no problem.
3. Spring Boot integrates Redis
3.1 dependency import
It is convenient for Spring Boot to integrate redis. You only need to import a redis starter dependency. As follows:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--Alibaba fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.35</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Alibaba's fastjson is also imported here to save an entity later. In order to facilitate the conversion of the entity into a json string and save it.
3.2 Redis configuration
After importing the dependency, we are in application redis is configured in the YML file:
server:
port: 8080
spring:
#redis related configuration
redis:
database: 5
# To configure the host address of redis, you need to change it to your own
host: 192.168.48.190
port: 6379
password: 123456
timeout: 5000
jedis:
pool:
# The maximum free connection in the connection pool. The default value is 8.
max-idle: 500
# The minimum free connection in the connection pool. The default value is 0.
min-idle: 50
# If the value is - 1, it means no restriction; If the pool has allocated maxActive jedis instances, the status of the pool is exhausted
max-active: 1000
# The maximum time to wait for an available connection, in milliseconds. The default value is - 1, which means never timeout. If the waiting time is exceeded, the JedisConnectionException will be thrown directly
max-wait: 2000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
3.3 introduction to common APIs
Spring Boot's support for redis has been very perfect, and the rich APIs are enough for our daily development. Here I introduce some of the most commonly used APIs for you to learn. I hope you can learn and study more about other APIs yourself. Use it to check.
There are two redis templates: RedisTemplate and StringRedisTemplate. We do not use RedisTemplate. RedisTemplate provides us with operation objects. When operating objects, we usually store them in json format, but when storing them, we will use redis's default internal serializer; What we put in is garbled code and so on. Of course, we can define serialization ourselves, but it is troublesome, so we use the StringRedisTemplate template template. StringRedisTemplate mainly provides us with string operations. We can convert entity classes into json strings. After taking them out, they can also be converted into corresponding objects. That's why I imported Ali fastjson above.
3.3.1 redis:string type
Create a RedisService, inject StringRedisTemplate, and use StringRedisTemplate Opsforvalue() can obtain the value operations < string, string > object, which can be used to read and write the redis database. As follows:
public class RedisService {
@Resource
private StringRedisTemplate stringRedisTemplate;
/**
* set redis: string type
* @param key key
* @param value value
*/
public void setString(String key, String value){
ValueOperations<String, String> valueOperations = stringRedisTemplate.opsForValue();
valueOperations.set(key, value);
}
/**
* get redis: string type
* @param key key
* @return
*/
public String getString(String key){
return stringRedisTemplate.opsForValue().get(key);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
This object operates on strings. We can also store entity classes. We just need to convert the entity classes into json strings. Let's test:
@RunWith(SpringRunner.class)
@SpringBootTest
public class Course14ApplicationTests {
private static final Logger logger = LoggerFactory.getLogger(Course14ApplicationTests.class);
@Resource
private RedisService redisService;
@Test
public void contextLoads() {
//Test the string type of redis
redisService.setString("weichat","Programmer's private dishes");
logger.info("My official account for WeChat is:{}", redisService.getString("weichat"));
// If it is an entity, we can use the json tool to convert it into a json string,
User user = new User("CSDN", "123456");
redisService.setString("userInfo", JSON.toJSONString(user));
logger.info("User information:{}", redisService.getString("userInfo"));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
Start redis first, then run the test case, and observe the log printed on the console as follows:
My WeChat official account is: programmer private food.
User information:{"password":"123456","username":"CSDN"}
- 1
- 2
3.3.2 redis:hash type
In fact, the principle of hash type is the same as that of string, but there are two keys. Use string redistemplate Opsforhash() can get the hashoperations < string, object, Object > object. For example, we need to store order information. All order information is placed under order. Order entities of different users can be distinguished by user id, which is equivalent to two keys.
@Service
public class RedisService {
@Resource
private StringRedisTemplate stringRedisTemplate;
/**
* set redis: hash type
* @param key key
* @param filedKey filedkey
* @param value value
*/
public void setHash(String key, String filedKey, String value){
HashOperations<String, Object, Object> hashOperations = stringRedisTemplate.opsForHash();
hashOperations.put(key,filedKey, value);
}
/**
* get redis: hash type
* @param key key
* @param filedkey filedkey
* @return
*/
public String getHash(String key, String filedkey){
return (String) stringRedisTemplate.opsForHash().get(key, filedkey);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
It can be seen that hash is no different from string, except that there are multiple parameters. The operation of redis in Spring Boot is very simple and convenient. Let's test:
@SpringBootTest
public class Course14ApplicationTests {
private static final Logger logger = LoggerFactory.getLogger(Course14ApplicationTests.class);
@Resource
private RedisService redisService;
@Test
public void contextLoads() {
//Test the hash type of redis
redisService.setHash("user", "name", JSON.toJSONString(user));
logger.info("User name:{}", redisService.getHash("user","name"));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.3.3 redis:list type
Use stringredistemplate Opsforlist() can obtain the list object of ^ listoperations < string, string > listoperations ^ redis. The list is a simple string list, which can be added from the left or from the right. A list can contain 2 ^ 32 - 1 elements at most.
@Service
public class RedisService {
@Resource
private StringRedisTemplate stringRedisTemplate;
/**
* set redis:list type
* @param key key
* @param value value
* @return
*/
public long setList(String key, String value){
ListOperations<String, String> listOperations = stringRedisTemplate.opsForList();
return listOperations.leftPush(key, value);
}
/**
* get redis:list type
* @param key key
* @param start start
* @param end end
* @return
*/
public List<String> getList(String key, long start, long end){
return stringRedisTemplate.opsForList().range(key, start, end);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
It can be seen that these APIs are in the same form, which is convenient for memory and use. I won't expand the specific api details. You can read the api documents yourself. In fact, these APIs can also know what they are used for according to the parameters and return values. Let's test:
@RunWith(SpringRunner.class)
@SpringBootTest
public class Course14ApplicationTests {
private static final Logger logger = LoggerFactory.getLogger(Course14ApplicationTests.class);
@Resource
private RedisService redisService;
@Test
public void contextLoads() {
//Test the list type of redis
redisService.setList("list", "football");
redisService.setList("list", "basketball");
List<String> valList = redisService.getList("list",0,-1);
for(String value :valList){
logger.info("list There are:{}", value);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
4. Summary
This section mainly introduces the use scenario and installation process of redis, as well as the detailed steps of integrating redis in Spring Boot. In actual projects, redis is usually used as the cache. When querying the database, you will first look it up from redis. If there is information, you will get it from redis; If not, check from the database and synchronize it to redis. It will be available in the next redis. The same is true for updates and deletions. Both need to be synchronized to redis. Redis is widely used in high concurrency scenarios.
Course source code download address: Poke me to download
Lesson 15: integrating ActiveMQ in Spring Boot
1. Introduction to JMS and ActiveMQ
1.1 what is JMS
Explanation of Baidu Encyclopedia:
JMS, the Java Message Service application program interface, is an API for message oriented middleware (MOM) in the Java platform. It is used to send messages between two applications or in distributed systems for asynchronous communication. Java Message Service is a platform independent API, and most mom providers support JMS.
JMS is just an interface. Different providers or open source organizations have different implementations of it. ActiveMQ is one of them. It supports JMS and is launched by Apache. There are several object models in JMS:
Connection factory: ConnectionFactory
JMS Connection: Connection
JMS Session: Session
JMS destination: Destination
JMS Producer: Producer
JMS consumer: Consumer
There are two types of JMS messages: peer-to-peer and publish / subscribe.
It can be seen that JMS is actually a bit similar to JDBC. JDBC is an API that can be used to access many different relational databases, while JMS provides the same vendor independent access methods to access messaging services. This article mainly uses ActiveMQ.
1.2 ActiveMQ
ActiveMQ is a powerful open source message bus from Apache. ActiveMQ fully supports JMS 1 1 and J2EE 1.4 specifications. Although the JMS specification has been issued for a long time, JMS still plays a special role in today's Java EE applications. ActiveMQ is used for asynchronous message processing. The so-called asynchronous message means that the message sender does not need to wait for the processing and return of the message receiver, or even care whether the message is sent successfully.
Asynchronous messages mainly have two destination types, queue and topic. Queue is used for point-to-point message communication, and topic is used for publish / subscribe message communication. This chapter is mainly to learn how to use these two forms of messages in Spring Boot.
2. ActiveMQ installation
To use ActiveMQ, you first need to download it from the official website. The address of the official website is: http://activemq.apache.org/
The version used in this course is apache-activemq-5.15.3. After downloading and decompressing, there will be a folder named apache-activemq-5.15.3. Yes, it is installed. It is very simple and can be used out of the box. Open the folder and you will see an active mq-all-5.15.3 Jar. We can add this jar to the project, but we don't need this jar if maven is used.
Before using ActiveMQ, you must start it first. There is a bin directory in the extracted directory, which contains win32 and win64 directories. Select one of them according to your computer to open and run ActiveMQ Bat to start ActiveMQ.
The message producer publishes the message to the queue, and then the message consumer takes it out of the queue and consumes the message. It should be noted here that after the message is consumed by the consumer, there is no storage in the queue, so the message consumer cannot consume the consumed message. Queue supports multiple message consumers, but for a message, only one consumer can consume it
After startup, enter in the browser http://127.0.0.1:8161/admin/ To access the server of ActiveMQ, the user name and password are admin/admin. As follows:
We can see that there are two options: Queues and Topics. These two options are the viewing window for peer-to-peer messages and publish / subscribe messages respectively. What are peer-to-peer messaging and publish / subscribe messaging?
Peer to peer message: the message producer publishes the message to the queue, and then the message consumer takes it out of the queue and consumes the message. It should be noted here that after the message is consumed by the consumer, there is no storage in the queue, so the message consumer cannot consume the consumed message. Queue supports multiple message consumers, but for a message, only one consumer can consume it.
Publish / subscribe message: the message producer (publisher) publishes the message to topic, and multiple message consumers (subscribers) consume the message at the same time. Unlike the peer-to-peer method, messages published to topic will be consumed by all subscribers. The specific implementation is analyzed below.
3. ActiveMQ integration
3.1 dependency import and configuration
To integrate ActiveMQ in Spring Boot, you need to import the following starter dependencies:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-activemq</artifactId> </dependency>
- 1
- 2
- 3
- 4
Then in application In the YML configuration file, configure activemq as follows:
spring:
activemq:
# activemq url
broker-url: tcp://localhost:61616
in-memory: true
pool:
# If it is set to true here, the dependent package of ActiveMQ pool needs to be added, otherwise the automatic configuration will fail and the JmsMessagingTemplate cannot be injected
enabled: false
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.2 creation of queue and Topic
First, we need to create two types of messages, Queue and Topic, which we create in ActiveMqConfig, as follows:
/**
* activemq Configuration of
* @author shengwu ni
*/
@Configuration
public class ActiveMqConfig {
/**
* Publish / subscribe mode queue name
*/
public static final String TOPIC_NAME = "activemq.topic";
/**
* Peer to peer mode queue name
*/
public static final String QUEUE_NAME = "activemq.queue";
@Bean
public Destination topic() {
return new ActiveMQTopic(TOPIC_NAME);
}
@Bean
public Destination queue() {
return new ActiveMQQueue(QUEUE_NAME);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
It can be seen that Queue and Topic messages can be created by using new ActiveMQQueue and new ActiveMQTopic, respectively, followed by the name of the corresponding message. In this way, these two messages can be directly injected as components elsewhere.
3.3 message sending interface
In Spring Boot, we can quickly send messages by injecting JmsMessagingTemplate template, as follows:
/**
* message sender
* @author shengwu ni
*/
@Service
public class MsgProducer {
@Resource
private JmsMessagingTemplate jmsMessagingTemplate;
public void sendMessage(Destination destination, String msg) {
jmsMessagingTemplate.convertAndSend(destination, msg);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
In the convertAndSend method, the first parameter is the destination of the message, and the second parameter is the specific message content.
3.4 point to point message production and consumption
3.4.1 production of peer-to-peer messages
We put the production of messages into the Controller. Since the components of Queue messages have been generated above, we can inject them directly into the Controller. Then we call the above message sending method sendMessage to produce a message successfully.
/**
* ActiveMQ controller
* @author shengwu ni
*/
@RestController
@RequestMapping("/activemq")
public class ActiveMqController {
private static final Logger logger = LoggerFactory.getLogger(ActiveMqController.class);
@Resource
private MsgProducer producer;
@Resource
private Destination queue;
@GetMapping("/send/queue")
public String sendQueueMessage() {
logger.info("===Start sending peer-to-peer messages===");
producer.sendMessage(queue, "Queue: hello activemq!");
return "success";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
3.4.2 consumption of peer-to-peer messages
The consumption of peer-to-peer messages is very simple. As long as we specify the destination, the jms listener has been monitoring whether there is a message coming. If so, it will be consumed.
/**
* Message consumer
* @author shengwu ni
*/
@Service
public class QueueConsumer {
/**
* Receive point-to-point messages
* @param msg
*/
@JmsListener(destination = ActiveMqConfig.QUEUE_NAME)
public void receiveQueueMsg(String msg) {
System.out.println("The message received is:" + msg);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
It can be seen that the @ JmsListener} annotation is used to specify the destination to listen to. In the message receiving method, we can do corresponding logical processing according to specific business requirements.
3.4.3 test
Start the project and enter in the browser: http://localhost:8081/activemq/send/queue , observe the output log of the console. The following log shows that the message is sent and consumed successfully.
The message received is: Queue: hello activemq!
- 1
3.5 production and consumption of publish / subscribe messages
3.5.1 production of publish / subscribe messages
Like peer-to-peer messages, we can send subscription messages by injecting topic and calling the producer's {sendMessage} method, as follows, which will not be repeated:
@RestController
@RequestMapping("/activemq")
public class ActiveMqController {
private static final Logger logger = LoggerFactory.getLogger(ActiveMqController.class);
@Resource
private MsgProducer producer;
@Resource
private Destination topic;
@GetMapping("/send/topic")
public String sendTopicMessage() {
logger.info("===Start sending subscription message===");
producer.sendMessage(topic, "Topic: hello activemq!");
return "success";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3.5.2 consumption of publish / subscribe messages
The consumption of publish / subscribe messages is different from that of peer-to-peer messages. Subscription messages support multiple consumers to consume together. Secondly, the default point-to-point message in Spring Boot will not work when topic is used. We need to add it in the configuration file application Add a configuration to YML:
spring:
jms:
pub-sub-domain: true
- 1
- 2
- 3
If the configuration is false, it is a point-to-point message, which is also the default of Spring Boot. This can solve the problem, but if configured in this way, the point-to-point messages mentioned above cannot be consumed normally. Therefore, we can't have both. This is not a good solution.
A better solution is to define a factory. By default, the @ JmsListener @ annotation only receives queue messages. If you want to receive topic messages, you need to set containerFactory. We also add the following to the ActiveMqConfig configuration class above:
/**
* activemq Configuration of
*
* @author shengwu ni
*/
@Configuration
public class ActiveMqConfig {
// Omit other contents
/**
* JmsListener Annotation only receives queue messages by default. If you want to receive topic messages, you need to set containerFactory
*/
@Bean
public JmsListenerContainerFactory topicListenerContainer(ConnectionFactory connectionFactory) {
DefaultJmsListenerContainerFactory factory = new DefaultJmsListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
// Equivalent to in application Configuration in YML: spring jms. pub-sub-domain=true
factory.setPubSubDomain(true);
return factory;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
After this configuration, when consuming, we can specify this container factory in the @ JmsListener} annotation to consume topic messages. As follows:
/**
* Topic Message consumer
* @author shengwu ni
*/
@Service
public class TopicConsumer1 {
/**
* Receive subscription messages
* @param msg
*/
@JmsListener(destination = ActiveMqConfig.TOPIC_NAME, containerFactory = "topicListenerContainer")
public void receiveTopicMsg(String msg) {
System.out.println("The message received is:" + msg);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Specify the containerFactory property as the topicListenerContainer configured above. Since topic messages can be consumed by multiple users, you can copy several of the consuming classes and test them together. I won't post the code here. You can refer to my source code test.
3.5.3 test
Start the project and enter in the browser: http://localhost:8081/activemq/send/topic , observe the output log of the console. The following log shows that the message is sent and consumed successfully.
The message received is: Topic: hello activemq! The message received is: Topic: hello activemq!
- 1
- 2
4. Summary
This chapter mainly introduces the related concepts of jms and activemq, and the installation and startup of activemq. The configuration, message production and consumption modes of point-to-point message and publish / subscribe message in Spring Boot are analyzed in detail. activemq is a powerful open source message bus, which is very useful in asynchronous message processing. I hope you can digest it.
Course source code download address: Poke me to download
Lesson 16: integrating Shiro in Spring Boot
Shiro is a powerful and easy-to-use Java security framework, which is mainly used for more convenient authentication, authorization, encryption, session management, etc., and can provide security for any application. This course mainly introduces Shiro's authentication and authorization functions.
1. Three core components of Shiro
Shiro has three core components: Subject, SecurityManager, and real. Let's look at the relationship between them first.
- Subject: authentication subject. It contains two pieces of information: Principals and Credentials. Let's see what these two messages are.
Principals: identity. It can be user name, e-mail, mobile phone number, etc. to identify the identity of a login subject;
Credentials: credentials. Common are password, digital certificate and so on.
To put it bluntly, it is something that needs authentication. The most common is the user name and password. For example, when a user logs in, Shiro needs to authenticate his identity, so he needs to authenticate the Subject.
-
SecurityManager: security administrator. This is the core of Shiro architecture. It is like the umbrella of all the original components in Shiro. We generally configure the SecurityManager in the project, and most of the developers focus on the Subject authentication Subject. When we interact with the Subject, the SecurityManager actually performs some security operations behind the scenes.
-
Realms: realms is a domain. It is a bridge connecting Shiro and specific applications. When it is necessary to interact with secure data, such as user accounts and access control, Shiro will find it from one or more realms. We usually customize the Realm ourselves, which will be described in detail below.
1. Shiro identity and authority authentication
1.2 Shiro authentication
Let's analyze the process of Shiro identity authentication and take a look at an official authentication diagram:
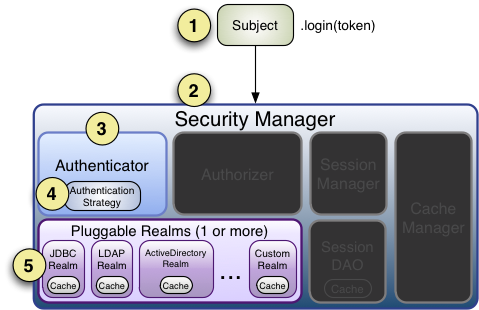
Step 1: the application code is calling subject After the login (token) method, an AuthenticationToken instance token representing the identity and credentials of the end user is passed in.
Step 2: delegate the Subject instance to the application's SecurityManager (Shiro's security management) to start the actual authentication. The real certification work begins here.
Step 3, 4, 5: then the security manager will perform security authentication according to the specific realm. As can be seen from the figure, the realm can be customized.
1.3 Shiro authority authentication
Permission authentication, that is, access control, controls who can access which resources in the application. In authority authentication, the three core elements are: authority, role and user.
permission: the right to operate resources, such as the right to access a page and the right to add, modify, delete and view the data of a module;
Role: refers to the role played by the user. A role can have multiple permissions;
User: in Shiro, it represents the user accessing the system, that is, the Subject authentication Subject mentioned above.
The relationship between them can be represented by the following figure:
A user can have multiple roles, and different roles can have different permissions or the same permissions. For example, there are three roles: 1 is an ordinary role, 2 is also an ordinary role, 3 is an administrator, role 1 can only view information, role 2 can only add information, administrators can, and can delete information, similar to this.
2. Spring Boot integration Shiro process
2.1 dependency import
Spring Boot 2.0.3 integration Shiro needs to import the following starter dependencies:
<dependency>
<groupId>org.apache.shiro</groupId>
<artifactId>shiro-spring</artifactId>
<version>1.4.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
2.2 database table data initialization
There are three tables involved here: user table, role table and permission table. In fact, in the demo, we can simulate it ourselves without creating tables. However, in order to be closer to the actual situation, we still add mybatis to operate the database. The following is the script for the database table.
CREATE TABLE `t_role` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Primary key', `rolename` varchar(20) DEFAULT NULL COMMENT 'Role name', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 CREATE TABLE `t_user` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'User primary key', `username` varchar(20) NOT NULL COMMENT 'user name', `password` varchar(20) NOT NULL COMMENT 'password', `role_id` int(11) DEFAULT NULL COMMENT 'Foreign key Association role surface', PRIMARY KEY (`id`), KEY `role_id` (`role_id`), CONSTRAINT `t_user_ibfk_1` FOREIGN KEY (`role_id`) REFERENCES `t_role` (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 CREATE TABLE `t_permission` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Primary key', `permissionname` varchar(50) NOT NULL COMMENT 'Permission name', `role_id` int(11) DEFAULT NULL COMMENT 'Foreign key Association role', PRIMARY KEY (`id`), KEY `role_id` (`role_id`), CONSTRAINT `t_permission_ibfk_1` FOREIGN KEY (`role_id`) REFERENCES `t_role` (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Where, t_user,t_ Roles and t_permission stores user information, role information and permission information respectively. After the table is established, we insert some test data into the table.
t_user table:
| id | username | password | role_id |
|---|---|---|---|
| 1 | csdn1 | 123456 | 1 |
| 2 | csdn2 | 123456 | 2 |
| 3 | csdn3 | 123456 | 3 |
t_role table:
| id | rolename |
|---|---|
| 1 | admin |
| 2 | teacher |
| 3 | student |
t_permission table:
| id | permissionname | role_id |
|---|---|---|
| 1 | user:* | 1 |
| 2 | student:* | 2 |
Explain the permissions here: user: * indicates that the permissions can be user:create or others, and * indicates a placeholder, which can be defined by ourselves. The details will be described in Shiro configuration below.
2.2 custom Realm
After we have the database tables and data, we start to customize the realm. The customized realm needs to inherit the authorizing realm class, because this class encapsulates many methods, and it also inherits from the realm class step by step. After inheriting the authorizing realm class, we need to rewrite two methods:
doGetAuthenticationInfo() method: used to authenticate the currently logged in user and obtain authentication information
doGetAuthorizationInfo() method: used to grant permissions and roles to users who have successfully logged in
The specific implementation is as follows. The relevant explanations are put in the comments of the code, which is more convenient and intuitive:
/**
* Custom realm
* @author shengwu ni
*/
public class MyRealm extends AuthorizingRealm {
@Resource
private UserService userService;
@Override
protected AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principalCollection) {
// Get user name
String username = (String) principalCollection.getPrimaryPrincipal();
SimpleAuthorizationInfo authorizationInfo = new SimpleAuthorizationInfo();
// Set the role for the user. The role information exists t_ Fetch from role table
authorizationInfo.setRoles(userService.getRoles(username));
// Set permissions for the user. Permission information exists t_ From permission table
authorizationInfo.setStringPermissions(userService.getPermissions(username));
return authorizationInfo;
}
@Override
protected AuthenticationInfo doGetAuthenticationInfo(AuthenticationToken authenticationToken) throws AuthenticationException {
// Get the user name according to the token. If you don't know how the token came from, you can ignore it first. It will be explained below
String username = (String) authenticationToken.getPrincipal();
// Query the user from the database according to the user name
User user = userService.getByUsername(username);
if(user != null) {
// Save the current user into the session
SecurityUtils.getSubject().getSession().setAttribute("user", user);
// Pass in the user name and password for identity authentication, and return the authentication information
AuthenticationInfo authcInfo = new SimpleAuthenticationInfo(user.getUsername(), user.getPassword(), "myRealm");
return authcInfo;
} else {
return null;
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
It can be seen from the above two methods: during identity verification, the user corresponding to the user name is found from the database according to the user name entered by the user. At this time, the password is not involved. That is, at this step, the user can be found even if the password entered by the user is wrong, Then encapsulate the correct information of the user into authcInfo and return it to Shiro. The next thing is Shiro. It will verify the user name and password entered by the user on the front desk according to the real information. At this time, it also needs to verify the password. If the verification passes, let the user log in, otherwise jump to the specified page. Similarly, during permission verification, the roles and permissions related to the user name are obtained from the database according to the user name, and then encapsulated in the authorization info and returned to Shiro.
2.3 Shiro configuration
After the custom realm is written, Shiro needs to be configured. We mainly configure three things: Custom realm, security manager, SecurityManager and Shiro filter. As follows:
Configure custom realm:
@Configuration
public class ShiroConfig {
private static final Logger logger = LoggerFactory.getLogger(ShiroConfig.class);
/**
* Inject custom realm
* @return MyRealm
*/
@Bean
public MyRealm myAuthRealm() {
MyRealm myRealm = new MyRealm();
logger.info("====myRealm Registration complete=====");
return myRealm;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
To configure the security manager SecurityManager:
@Configuration
public class ShiroConfig {
private static final Logger logger = LoggerFactory.getLogger(ShiroConfig.class);
/**
* Injection Security Manager
* @return SecurityManager
*/
@Bean
public SecurityManager securityManager() {
// Add custom realm
DefaultWebSecurityManager securityManager = new DefaultWebSecurityManager(myAuthRealm());
logger.info("====securityManager Registration complete====");
return securityManager;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
When configuring the SecurityManager, you need to add the above custom realm, so that Shiro can go to the custom realm.
To configure Shiro filters:
@Configuration
public class ShiroConfig {
private static final Logger logger = LoggerFactory.getLogger(ShiroConfig.class);
/**
* Inject Shiro filter
* @param securityManager Security Manager
* @return ShiroFilterFactoryBean
*/
@Bean
public ShiroFilterFactoryBean shiroFilter(SecurityManager securityManager) {
// Define shiroFactoryBean
ShiroFilterFactoryBean shiroFilterFactoryBean=new ShiroFilterFactoryBean();
// Set custom securityManager
shiroFilterFactoryBean.setSecurityManager(securityManager);
// Set the default login url, which will be accessed if authentication fails
shiroFilterFactoryBean.setLoginUrl("/login");
// Set the link to jump after success
shiroFilterFactoryBean.setSuccessUrl("/success");
// Set the unauthorized interface. If the authority authentication fails, the url will be accessed
shiroFilterFactoryBean.setUnauthorizedUrl("/unauthorized");
// LinkedHashMap is ordered and configured as a sequential interceptor
Map<String,String> filterChainMap = new LinkedHashMap<>();
// Configure addresses that can be accessed anonymously. You can add them according to the actual situation and release some static resources. anon means release
filterChainMap.put("/css/**", "anon");
filterChainMap.put("/imgs/**", "anon");
filterChainMap.put("/js/**", "anon");
filterChainMap.put("/swagger-*/**", "anon");
filterChainMap.put("/swagger-ui.html/**", "anon");
// Login url release
filterChainMap.put("/login", "anon");
// "/user/admin" The first one needs identity authentication, and authc means identity authentication
filterChainMap.put("/user/admin*", "authc");
// "/user/student" The first one needs role authentication and is allowed only if it is "admin"
filterChainMap.put("/user/student*/**", "roles[admin]");
// The beginning of "/ user/teacher" requires permission authentication and is allowed only when it is "user:create"
filterChainMap.put("/user/teacher*/**", "perms[\"user:create\"]");
// Configure logout filter
filterChainMap.put("/logout", "logout");
// Set the FilterChainDefinitionMap of shiroFilterFactoryBean
shiroFilterFactoryBean.setFilterChainDefinitionMap(filterChainMap);
logger.info("====shiroFilterFactoryBean Registration complete====");
return shiroFilterFactoryBean;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
When configuring Shiro filter, a security manager will be passed in. It can be seen that this is one ring after another, reall - > SecurityManager - > filter. In the filter, we need to define a shiroFactoryBean, and then add the SecurityManager. In combination with the above code, we can see that the main things to be configured are:
Default login url: this url will be accessed if authentication fails
url to jump after successful authentication
If the authority authentication fails, the url will be accessed
URLs that need to be intercepted or released: These are all placed in a map
As can be seen from the above code, there are different permission requirements for different URLs in the map. Here are some common permissions.
| Filter | explain |
|---|---|
| anon | Open permissions can be understood as anonymous users or tourists who can access directly |
| authc | Authentication required |
| logout | Log out and directly jump to shirofilterfactorybean setLoginUrl(); Set the url, that is, the login page |
| roles[admin] | Multiple parameters can be written, indicating that one or some roles can pass. When there are multiple parameters, write roles ["admin, user"]. When there are multiple parameters, each parameter must pass |
| perms[user] | You can write multiple parameters, which means you need some or some permissions to pass. When there are multiple parameters, write perms ["user, admin"]. When there are multiple parameters, you must pass each parameter |
2.4 certification with Shiro
Here, we have finished the preparation of Shiro, and then we start to use Shiro for authentication. Let's first design several interfaces:
Interface I: use http://localhost:8080/user/admin To verify authentication
Interface 2: use http://localhost:8080/user/student To verify role authentication
Interface 3: use http://localhost:8080/user/teacher To verify authority authentication
Interface 4: use http://localhost:8080/user/login To achieve user login
Then come to the certification process:
Process 1: directly access interface 1 (not logged in at this time), authentication fails, and jump to login The HTML page allows the user to log in, and the login will request interface 4 to realize the user login function. At this time, Shiro has saved the user information.
Process 2: access interface 1 again (at this time, the user has logged in), the authentication is successful, and jump to success HTML page to display user information.
Process 3: access interface 2, test whether the role authentication is successful.
Process 4: access interface 3, test whether the authority authentication is successful.
2.4.1 identity, role and authority authentication interface
@Controller
@RequestMapping("/user")
public class UserController {
/**
* Authentication test interface
* @param request
* @return
*/
@RequestMapping("/admin")
public String admin(HttpServletRequest request) {
Object user = request.getSession().getAttribute("user");
return "success";
}
/**
* Role authentication test interface
* @param request
* @return
*/
@RequestMapping("/student")
public String student(HttpServletRequest request) {
return "success";
}
/**
* Authority authentication test interface
* @param request
* @return
*/
@RequestMapping("/teacher")
public String teacher(HttpServletRequest request) {
return "success";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
These three interfaces are very simple. You can directly return to the specified page for display. As long as the authentication is successful, you will jump normally. If the authentication fails, you will jump to the page configured in shreoconfig above for display.
2.4.2 user login interface
@Controller
@RequestMapping("/user")
public class UserController {
/**
* User login interface
* @param user user
* @param request request
* @return string
*/
@PostMapping("/login")
public String login(User user, HttpServletRequest request) {
// Create a token based on the user name and password
UsernamePasswordToken token = new UsernamePasswordToken(user.getUsername(), user.getPassword());
// Get subject authentication principal
Subject subject = SecurityUtils.getSubject();
try{
// Start authentication. This step will jump to our custom realm
subject.login(token);
request.getSession().setAttribute("user", user);
return "success";
}catch(Exception e){
e.printStackTrace();
request.getSession().setAttribute("user", user);
request.setAttribute("error", "Wrong user name or password!");
return "login";
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Let's focus on the analysis of this login interface. First, we will create a token according to the user name and password passed from the front end, then use SecurityUtils to create an authentication subject, and then start calling {subject Login (token) starts identity authentication. Note that the token just created is passed here. As described in the note, this step will jump to our custom realm and enter the {doGetAuthenticationInfo} method. So here, you will understand the parameter token in this method. Then, as analyzed above, start identity authentication.
2.4.3 test
Finally, start the project and test:
Browser request http://localhost:8080/user/admin Identity authentication will be performed. Because you are not logged in at this time, you will jump to the / login # interface in IndexController, and then jump to # login HTML} page lets us log in. After logging in with the user name and password csdn/123456, we request in the browser http://localhost:8080/user/student Interface, role authentication will be performed. Because the user role of csdn1 in the database is admin, it is consistent with that in the configuration, and the authentication is passed; We ask again http://localhost:8080/user/teacher Interface, permission authentication will be performed. Because the user permission of csdn1 in the database is , user: *, which meets the , user:create in the configuration, the authentication passes.
Next, we click exit, the system will log out and let us log in again. We log in using csdn2. Repeat the above operations. When we perform role authentication and permission authentication, the authentication fails. Because the role and permission of csdn2 in the database are different from those in the configuration, the authentication fails.
3. Summary
This section mainly introduces the integration of Shiro security framework and Spring Boot. First, it introduces the three core components of Shiro and their functions; Then it introduces Shiro's identity authentication, role authentication and authority authentication; Finally, combined with the code, this paper introduces in detail how Shiro is integrated in Spring Boot, designs a set of test process, and gradually analyzes Shiro's workflow and principle, so that readers can more intuitively experience Shiro's whole workflow. Shiro is widely used. I hope readers can master it and apply it to practical projects.
Course source code download address: Poke me to download
Lesson 17: integrating Lucence in Spring Boot
1. Lucence and full text search
What is Lucene? Take a look at Baidu Encyclopedia:
Lucene is an open source library for full-text retrieval and search, supported and provided by the Apache Software Foundation. Lucene provides a simple but powerful application interface, which can do full-text indexing and search. Lucene is a mature free and open source tool in the java development environment. In itself, Lucene is the most popular free Java information retrieval library at present and in recent years—— Baidu Encyclopedia
1.1 full text search
The concept of full-text retrieval is mentioned here. Let's first analyze what full-text retrieval is. After understanding full-text retrieval, it's very simple to understand the principle of Lucene.
What is full text retrieval? For example, if you want to find a string in a file now, the most direct idea is to retrieve it from the beginning. If you find it, it's OK. This is very practical for files with a small amount of data, but it's a little difficult for files with a large amount of data. Or to find a file containing a string, the same is true. If you find it in a hard disk with dozens of G, it is conceivable that the efficiency is very low.
The data in the file belongs to unstructured data, that is, it has no structure. To solve the efficiency problem mentioned above, first we have to extract and reorganize some information in unstructured data to make it have a certain structure, and then search these data with a certain structure, so as to achieve the purpose of relatively fast search. This is called full-text search. That is, the process of establishing an index first and then searching the index.
1.2 indexing method of Lucene
So how is the index built in Lucene? Suppose there are two articles, as follows:
The content of Article 1 is: Tom lives in Guangzhou, I live in Guangzhou too
The content of Article 2 is: He once lived in Shanghai
The first step is to pass the document to the Tokenizer, which will divide the document into words and remove punctuation and stop words. The so-called stop words refer to words without special meaning, such as a, the, too, etc. in English. After word segmentation, a Token is obtained. As follows:
The result of Article 1 after word segmentation: [Tom] [lives] [Guangzhou] [I] [live] [Guangzhou]
The result of Article 2 after word segmentation: [He] [lives] [Shanghai]
Then pass the word element to the language processing component. For English, the language processing component will generally change the letter to lowercase, reduce the word to the root form, such as "lives" to "live", and change the word to the root form, such as "drop" to "drive". Then get the word (Term). As follows:
The processed result of Article 1: [tom] [live] [guangzhou] [i] [live] [guangzhou]
The processed result of Article 2: [he] [live] [shanghai]
Finally, the obtained words are passed to the Indexer. After processing, the Indexer obtains the following index structure:
| key word | Article No. [frequency] | Occurrence position |
|---|---|---|
| guangzhou | 1[2] | 3,6 |
| he | 2[1] | 1 |
| i | 1[1] | 4 |
| live | 1[2],2[1] | 2,5,2 |
| shanghai | 2[1] | 3 |
| tom | 1[1] | 1 |
The above is the core part of Lucene index structure. Its keywords are arranged in character order, so Lucene can quickly locate keywords with binary search algorithm. When implemented, Lucene saves the above three columns as Term Dictionary, frequencies and positions respectively. The dictionary file not only stores each keyword, but also retains the pointer to the frequency file and location file. The frequency information and location information of the keyword can be found through the pointer.
The search process is to search the dictionary binary and find the word, read out all article numbers through the pointer to the frequency file, and then return the results, and then find the word according to the location in the specific article. Therefore, Lucene may be slow to establish the index for the first time, but it will not need to establish the index every time in the future. It will be fast.
After understanding the word segmentation principle of Lucene, we integrate Lucene in Spring Boot and realize the functions of index and search.
2. Lucence is integrated in spring boot
2.1 dependency import
First, you need to import the dependencies of Lucene. There are several dependencies, as follows:
<!-- Lucence Core package --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>5.3.1</version> </dependency> <!-- Lucene Query parsing package --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>5.3.1</version> </dependency> <!-- Regular word segmentation (English) --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>5.3.1</version> </dependency> <!--Support word segmentation highlighting --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-highlighter</artifactId> <version>5.3.1</version> </dependency> <!--Support Chinese word segmentation --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-smartcn</artifactId> <version>5.3.1</version> </dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
The last dependency is used to support Chinese word segmentation, because English is supported by default. The highlighted word segmentation depends on that. Finally, I want to do a search, and then highlight the found content to simulate the current practice on the Internet, which can be applied to practical projects.
2.2 quick start
According to the above analysis, full-text retrieval has two steps: first establish the index, and then retrieve. So to test this process, I created two new java classes, one for indexing and the other for retrieval.
2.2.1 indexing
Let's get some files ourselves, put them in the "D:\lucene\data" directory, and create a new Indexer class to realize the indexing function. First, initialize the standard word splitter and write index instance in the construction method.
public class Indexer {
/**
* Write index instance
*/
private IndexWriter writer;
/**
* Constructor, instantiate IndexWriter
* @param indexDir
* @throws Exception
*/
public Indexer(String indexDir) throws Exception {
Directory dir = FSDirectory.open(Paths.get(indexDir));
//The standard word splitter will automatically remove the blank, is a the and other words
Analyzer analyzer = new StandardAnalyzer();
//Configure the standard word splitter into the configuration for writing indexes
IndexWriterConfig config = new IndexWriterConfig(analyzer);
//Instantiate write index object
writer = new IndexWriter(dir, config);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
In the construction release, pass a folder path to store the index, then build a standard word splitter (this is in English), and then use the standard word splitter to instantiate the write index object. Next, I'll start to build the index. I'll put the explanation in the code comments for everyone to follow up.
/**
* Index all files in the specified directory
* @param dataDir
* @return
* @throws Exception
*/
public int indexAll(String dataDir) throws Exception {
// Get all files under this path
File[] files = new File(dataDir).listFiles();
if (null != files) {
for (File file : files) {
//Call the indexFile method below to index each file
indexFile(file);
}
}
//Returns the number of files indexed
return writer.numDocs();
}
/**
* Index the specified file
* @param file
* @throws Exception
*/
private void indexFile(File file) throws Exception {
System.out.println("Path to index file:" + file.getCanonicalPath());
//Call the following getDocument method to get the document of the file
Document doc = getDocument(file);
//Add doc to index
writer.addDocument(doc);
}
/**
* Get the document and set each field in the document, which is similar to a row of records in the database
* @param file
* @return
* @throws Exception
*/
private Document getDocument(File file) throws Exception {
Document doc = new Document();
//Start adding fields
//Add content
doc.add(new TextField("contents", new FileReader(file)));
//Add the file name and save this field in the index file
doc.add(new TextField("fileName", file.getName(), Field.Store.YES));
//Add file path
doc.add(new TextField("fullPath", file.getCanonicalPath(), Field.Store.YES));
return doc;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
So the index is established. Let's write a main method in this class to test:
public static void main(String[] args) {
//The path to which the index is saved
String indexDir = "D:\\lucene";
//The directory where the file data to be indexed is stored
String dataDir = "D:\\lucene\\data";
Indexer indexer = null;
int indexedNum = 0;
//Record index start time
long startTime = System.currentTimeMillis();
try {
// Start building index
indexer = new Indexer(indexDir);
indexedNum = indexer.indexAll(dataDir);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (null != indexer) {
indexer.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
//Record index end time
long endTime = System.currentTimeMillis();
System.out.println("Indexing time" + (endTime - startTime) + "millisecond");
System.out.println("Co indexed" + indexedNum + "Files");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
I got two tomcat related files and put them under "D:\lucene\data". After execution, I see the console output:
Path to index file: D:\lucene\data\catalina.properties Path to index file: D:\lucene\data\logging.properties Indexing took 882 milliseconds A total of 2 files were indexed
- 1
- 2
- 3
- 4
Then we can see some index files in the D:\lucene \ directory. These files cannot be deleted. If they are deleted, we need to rebuild the index. Otherwise, without the index, we can't retrieve the content.
####2.2.2 search content
After indexing the two files, we can write a search program to find specific words in the two files.
public class Searcher {
public static void search(String indexDir, String q) throws Exception {
//Get the path to query, that is, the location of the index
Directory dir = FSDirectory.open(Paths.get(indexDir));
IndexReader reader = DirectoryReader.open(dir);
//Building IndexSearcher
IndexSearcher searcher = new IndexSearcher(reader);
//The standard word splitter will automatically remove the blank, is a the and other words
Analyzer analyzer = new StandardAnalyzer();
//query parser
QueryParser parser = new QueryParser("contents", analyzer);
//Obtain the query object by parsing the String to be queried, and q is the transmitted String to be queried
Query query = parser.parse(q);
//Record index start time
long startTime = System.currentTimeMillis();
//Start the query, query the first 10 pieces of data, and save the records in docs
TopDocs docs = searcher.search(query, 10);
//Record index end time
long endTime = System.currentTimeMillis();
System.out.println("matching" + q + "Total time" + (endTime-startTime) + "millisecond");
System.out.println("Found" + docs.totalHits + "Records");
//Fetch each query result
for(ScoreDoc scoreDoc : docs.scoreDocs) {
//scoreDoc.doc is equivalent to docID, which is used to obtain documents
Document doc = searcher.doc(scoreDoc.doc);
//fullPath is a field defined when the index is just created, which represents the path. Other contents can also be taken, as long as we have a definition when building the index.
System.out.println(doc.get("fullPath"));
}
reader.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ok, so we have finished writing the retrieved code. Each step explains the comments I wrote in the code. Here is a main method to test:
public static void main(String[] args) {
String indexDir = "D:\\lucene";
//Query this string
String q = "security";
try {
search(indexDir, q);
} catch (Exception e) {
e.printStackTrace();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Check the string "security" and execute it to see the results printed on the console:
matching security It took 23 milliseconds 1 record found D:\lucene\data\catalina.properties
- 1
- 2
- 3
As you can see, it took 23 milliseconds to find the security string in the two files and output the file name. I wrote the above code in detail. This code is relatively complete and can be used in the production environment.
2.3 highlight practice of Chinese word segmentation retrieval
The code for indexing and retrieval has been written above, but in actual projects, we often display some query results in combination with the page. For example, I want to check a keyword, display the relevant information points after finding it, and highlight the query keyword, etc. This requirement is very common in practical projects, and most websites will have this effect. So in this section, we use Lucene to achieve this effect.
2.3.1 Chinese word segmentation
We create a new ChineseIndexer class to create a Chinese index. The creation process is the same as that of an English index, except that the Chinese word splitter is used. In addition, we don't need to read the file to establish the index here. Let's simulate the establishment with string, because in the actual project, most of the time, we get some text strings, and then query the relevant content according to some keywords. The code is as follows:
public class ChineseIndexer {
/**
* Where to store the index
*/
private Directory dir;
//Prepare the data for the test
//Used to identify documents
private Integer ids[] = {1, 2, 3};
private String citys[] = {"Shanghai", "Nanjing", "Qingdao"};
private String descs[] = {
"Shanghai is a prosperous city.",
"Nanjing is a cultural city. Nanjing, referred to as Nanjing for short, is the capital of Jiangsu Province. It is located in eastern China, in the lower reaches of the Yangtze River, near the river and offshore. There are 11 districts under the jurisdiction of the city, with a total area of 6597 square kilometers. In 2013, the built-up area was 752 square kilometers.83 Square kilometers, with a permanent population of 818.78 Million, of which the urban population is 659.1 Ten thousand people.[1-4] "As a beautiful place in the south of the Yangtze River and an imperial state of Jinling, Nanjing has a civilization history of more than 6000 years, a city history of nearly 2600 years and a capital history of nearly 500 years. It is one of the four ancient capitals in China. It is known as the "ancient capital of Six Dynasties" and "capital of ten dynasties". It is an important birthplace of Chinese civilization. It has blessed the new moon of China for several times in history and has long been the political, economic and cultural center of southern China, It has profound cultural heritage and rich historical relics.[5-7] Nanjing is an important national science and education center. Since ancient times, it has been a city that advocates culture and education. It has the reputation of "the world's cultural hub" and "the first learning in the Southeast". As of 2013, there were 75 colleges and universities in Nanjing, including 8 211 colleges and universities, second only to Beijing and Shanghai; There are 25 state key laboratories, 169 state key disciplines and 83 academicians of the two academies, ranking third in China.[8-10] . ",
"Qingdao is a beautiful city."
};
/**
* Generate index
* @param indexDir
* @throws Exception
*/
public void index(String indexDir) throws Exception {
dir = FSDirectory.open(Paths.get(indexDir));
// First call getWriter to get the IndexWriter object
IndexWriter writer = getWriter();
for(int i = 0; i < ids.length; i++) {
Document doc = new Document();
// The above data are indexed and identified by id, city and desc respectively
doc.add(new IntField("id", ids[i], Field.Store.YES));
doc.add(new StringField("city", citys[i], Field.Store.YES));
doc.add(new TextField("desc", descs[i], Field.Store.YES));
//Add document
writer.addDocument(doc);
}
//Only when it is close d can it be really written to the document
writer.close();
}
/**
* Get IndexWriter instance
* @return
* @throws Exception
*/
private IndexWriter getWriter() throws Exception {
//Use Chinese word splitter
SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();
//Configure the Chinese word splitter into the configuration of writing index
IndexWriterConfig config = new IndexWriterConfig(analyzer);
//Instantiate write index object
IndexWriter writer = new IndexWriter(dir, config);
return writer;
}
public static void main(String[] args) throws Exception {
new ChineseIndexer().index("D:\\lucene2");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
Here, we use id, city and desc to represent id, city name and city description respectively, and use them as keywords to establish the index. Later, when we get the content, we mainly get the city description. I deliberately wrote a longer description of Nanjing, because when searching below, different parts of information will be retrieved according to different keywords, and there is a concept of weight in it.
Then execute the main method to save the index to D:\lucene2 \.
2.3.2 Chinese word segmentation query
The logic of the Chinese word segmentation query code is similar to the default query. There are some differences in that we need to mark the queried keywords in red and bold, and need to calculate a score segment. What does this mean? For example, when I search for "Nanjing Culture" and "Nanjing civilization", the two search results should be different according to the location of the keyword. This will be tested below. Let's look at the code and comments first:
public class ChineseSearch {
private static final Logger logger = LoggerFactory.getLogger(ChineseSearch.class);
public static List<String> search(String indexDir, String q) throws Exception {
//Get the path to query, that is, the location of the index
Directory dir = FSDirectory.open(Paths.get(indexDir));
IndexReader reader = DirectoryReader.open(dir);
IndexSearcher searcher = new IndexSearcher(reader);
//Use Chinese word splitter
SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();
//The query parser is initialized by the Chinese word splitter
QueryParser parser = new QueryParser("desc", analyzer);
//Obtain the query object by parsing the String to be queried
Query query = parser.parse(q);
//Record index start time
long startTime = System.currentTimeMillis();
//Start the query, query the first 10 pieces of data, and save the records in docs
TopDocs docs = searcher.search(query, 10);
//Record index end time
long endTime = System.currentTimeMillis();
logger.info("matching{}Total time{}millisecond", q, (endTime - startTime));
logger.info("Found{}Records", docs.totalHits);
//If no parameter is specified, it is bold by default, that is < b > < B / >
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<b><font color=red>","</font></b>");
//Calculate the score according to the query object and initialize a score with the highest query result
QueryScorer scorer = new QueryScorer(query);
//Based on this score, a segment is calculated
Fragmenter fragmenter = new SimpleSpanFragmenter(scorer);
//Highlight the keywords in this clip with the highlighted format initialized above
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, scorer);
//Set the clip to display
highlighter.setTextFragmenter(fragmenter);
//Fetch each query result
List<String> list = new ArrayList<>();
for(ScoreDoc scoreDoc : docs.scoreDocs) {
//scoreDoc.doc is equivalent to docID, which is used to obtain documents
Document doc = searcher.doc(scoreDoc.doc);
logger.info("city:{}", doc.get("city"));
logger.info("desc:{}", doc.get("desc"));
String desc = doc.get("desc");
//Show highlight
if(desc != null) {
TokenStream tokenStream = analyzer.tokenStream("desc", new StringReader(desc));
String summary = highlighter.getBestFragment(tokenStream, desc);
logger.info("Highlighted desc:{}", summary);
list.add(summary);
}
}
reader.close();
return list;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
I wrote the notes of each step in detail, so I won't repeat them here. Next, let's test the effect.
2.3.3 test
Here we use thymeleaf to write a simple page to display the obtained data and highlight it. In the controller, we specify the index directory and the string to query, as follows:
@Controller
@RequestMapping("/lucene")
public class IndexController {
@GetMapping("/test")
public String test(Model model) {
// Directory where the index is located
String indexDir = "D:\\lucene2";
// Characters to query
// String q = "Nanjing civilization";
String q = "Nanjing Culture";
try {
List<String> list = ChineseSearch.search(indexDir, q);
model.addAttribute("list", list);
} catch (Exception e) {
e.printStackTrace();
}
return "result";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
Return directly to result HTML page, which mainly displays the data in the model.
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div th:each="desc : ${list}">
<div th:utext="${desc}"></div>
</div>
</body>
</html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Note here that you cannot use th:test, otherwise the html tags in the string will be escaped and will not be rendered to the page. Next, start the service and enter in the browser http://localhost:8080/lucene/test , test the effect. We are searching for "Nanjing Culture".

Then change the search keyword in the controller to "Nanjing civilization" to see the hit effect.

It can be seen that for different keywords, it will calculate a score segment, that is, different keywords will hit the content in different positions, and then highlight the keywords according to the form we set ourselves. It can be seen from the results that Lucene can also intelligently split and hit keywords, which will be very useful in practical projects.
3. Summary
This lesson first analyzes the theoretical rules of full-text retrieval in detail, and then systematically describes the integration steps in Spring Boot in combination with Lucene. Firstly, it quickly leads you to intuitively feel how Lucene establishes index retrieval. Secondly, it shows the wide application of Lucene in full-text retrieval through specific examples of Chinese retrieval. Lucene is not difficult. The main thing is that there are many steps. You don't have to memorize the code. You can make corresponding modifications in the project according to the actual situation.
Course source code download address: Poke me to download
Lesson 18: Spring Boot architecture in actual project development
In the previous course, I mainly explained some technical points commonly used in Spring Boot. These technical points may not be used in actual projects, because different projects may use different technologies, but I hope everyone can master how to use them and expand them according to the needs of actual projects.
I don't know that you don't understand the single chip microcomputer. There is a minimum system in the single chip microcomputer. After the minimum system is built, it can be artificially expanded on this basis. What we need to do in this lesson is to build a "Spring Boot minimum system architecture". With this architecture, you can expand it according to the actual needs.
To build an environment from scratch, we should mainly consider the following points: unified encapsulated data structure, adjustable interface, json processing, the use of template engine (this article does not write this item, because most projects are separated from the front and rear, but considering that there are also non front and rear separated projects, I also add thymeleaf to the source code), the integration of persistence layer Interceptors (this is also optional) and global exception handling. Generally, if these things are included, basically a Spring Boot project environment is almost the same, and then it is extended according to the specific situation.
Combined with the previous courses and the above points, this class will lead you to build a Spring Boot architecture that can be used in actual project development. The whole project is shown in the figure below. When learning, you can combine my source code, so the effect will be better.
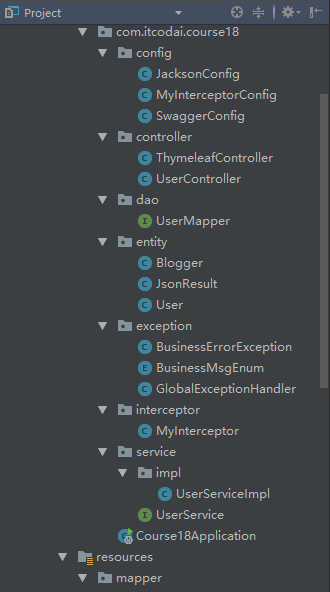
1. Unified data encapsulation
Because the type of encapsulated json data is uncertain, we need to use generics when defining a unified json structure. The attributes in the unified json structure include data, status code and prompt information. The construction method can be added according to the actual business needs. Generally speaking, there should be a default return structure and a user specified return structure. As follows:
/**
* Unified return object
* @author shengwu ni
* @param <T>
*/
public class JsonResult<T> {
private T data;
private String code;
private String msg;
/**
* If no data is returned, the default status code is 0 and the prompt message is: operation succeeded!
*/
public JsonResult() {
this.code = "0";
this.msg = "Operation succeeded!";
}
/**
* If no data is returned, you can manually specify the status code and prompt information
* @param code
* @param msg
*/
public JsonResult(String code, String msg) {
this.code = code;
this.msg = msg;
}
/**
* When data is returned, the status code is 0, and the default prompt message is: operation succeeded!
* @param data
*/
public JsonResult(T data) {
this.data = data;
this.code = "0";
this.msg = "Operation succeeded!";
}
/**
* There is data return, the status code is 0, and the prompt information is manually specified
* @param data
* @param msg
*/
public JsonResult(T data, String msg) {
this.data = data;
this.code = "0";
this.msg = msg;
}
/**
* Use custom exceptions as parameters to pass status codes and prompts
* @param msgEnum
*/
public JsonResult(BusinessMsgEnum msgEnum) {
this.code = msgEnum.code();
this.msg = msgEnum.msg();
}
// get and set methods are omitted
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
You can reasonably modify the field information in the unified structure according to some things you need in your project.
2. json processing
There are many Json processing tools, such as Alibaba's fastjson. However, fastjson cannot convert some unknown types of nulls into empty strings. This may be a defect of fastjson itself and its scalability is not very good, but it is easy to use and used by many people. In this lesson, we mainly integrate jackson from Spring Boot. It is mainly to configure jackson to null, and then it can be used in the project.
/**
* jacksonConfig
* @author shengwu ni
*/
@Configuration
public class JacksonConfig {
@Bean
@Primary
@ConditionalOnMissingBean(ObjectMapper.class)
public ObjectMapper jacksonObjectMapper(Jackson2ObjectMapperBuilder builder) {
ObjectMapper objectMapper = builder.createXmlMapper(false).build();
objectMapper.getSerializerProvider().setNullValueSerializer(new JsonSerializer<Object>() {
@Override
public void serialize(Object o, JsonGenerator jsonGenerator, SerializerProvider serializerProvider) throws IOException {
jsonGenerator.writeString("");
}
});
return objectMapper;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
We won't test here. After swagger2 is configured, let's test it together.
3. swagger2 online adjustable interface
With swagger, developers do not need to provide interface documents to other personnel. Just tell them a swagger address to display the online API interface documents. In addition, the personnel calling the interface can also test the interface data online. Similarly, when developing the interface, developers can also use swagger online interface documents to test the interface data, This provides convenience for developers. To use swagger, you need to configure it:
/**
* swagger to configure
* @author shengwu ni
*/
@Configuration
@EnableSwagger2
public class SwaggerConfig {
@Bean
public Docket createRestApi() {
return new Docket(DocumentationType.SWAGGER_2)
// Specify how to build the details of the api document: apiInfo()
.apiInfo(apiInfo())
.select()
// Specify the package path to generate api interfaces. Here, take controller as the package path to generate all interfaces in controller
.apis(RequestHandlerSelectors.basePackage("com.itcodai.course18.controller"))
.paths(PathSelectors.any())
.build();
}
/**
* Build api documentation details
* @return
*/
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
// Set page title
.title("Spring Boot Build the architecture developed in the actual project")
// Set interface description
.description("Learn with brother Wu Spring Boot Lesson 18")
// Set contact information
.contact("Ni Shengwu," + "WeChat official account: programmers' private dishes")
// Set version
.version("1.0")
// structure
.build();
}
}
Here, you can test it first, write a Controller and get a static interface to test the integrated content above.
@RestController
@Api(value = "User information interface")
public class UserController {
@Resource
private UserService userService;
@GetMapping("/getUser/{id}")
@ApiOperation(value = "Obtain user information according to the user's unique ID")
public JsonResult<User> getUserInfo(@PathVariable @ApiParam(value = "User unique ID") Long id) {
User user = new User(id, "Ni Shengwu", "123456");
return new JsonResult<>(user);
}
}
Then start the project and enter localhost: 8080 / swagger - UI in the browser HTML # you can see the swagger interface document page. Call the above interface to see the returned json data.
4. Persistence layer integration
Each project must have a persistence layer to interact with the database. Here, we mainly integrate mybatis. The first step to integrate mybatis is is in application YML.
# Service port number
server:
port: 8080
# Database address
datasource:
url: localhost:3306/blog_test
spring:
datasource: # Database configuration
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${datasource.url}?useSSL=false&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&autoReconnect=true&failOverReadOnly=false&maxReconnects=10
username: root
password: 123456
hikari:
maximum-pool-size: 10 # Maximum number of connection pools
max-lifetime: 1770000
mybatis:
# Specifies that the package set by the alias is all entities
type-aliases-package: com.itcodai.course18.entity
configuration:
map-underscore-to-camel-case: true # Hump naming specification
mapper-locations: # mapper mapping file location
- classpath:mapper/*.xml
After the configuration is completed, let's write about the dao layer. In practice, we use more annotations because it is more convenient. Of course, we can also use xml, or even use both at the same time. Here we mainly use annotation to integrate. For xml, you can check the previous courses. In practice, it depends on the project situation.
public interface UserMapper {
@Select("select * from user where id = #{id}")
@Results({
@Result(property = "username", column = "user_name"),
@Result(property = "password", column = "password")
})
User getUser(Long id);
@Select("select * from user where id = #{id} and user_name=#{name}")
User getUserByIdAndName(@Param("id") Long id, @Param("name") String username);
@Select("select * from user")
List<User> getAll();
}
I won't write code about the service layer in this article. You can learn from my source code. This section mainly leads you to build an empty Spring Boot architecture. Finally, don't forget to add annotation scan @ MapperScan("com.itcodai.course18.dao") on the startup class
5. Interceptor
Interceptors are used in many projects (but not absolutely), such as intercepting some top URLs, making some judgments and processing, etc. In addition, you also need to release commonly used static pages or swagger pages. These static resources cannot be intercepted. First, customize an interceptor.
public class MyInterceptor implements HandlerInterceptor {
private static final Logger logger = LoggerFactory.getLogger(MyInterceptor.class);
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
logger.info("Execute before executing method(Controller Before method call)");
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
logger.info("Execute after executing the method(Controller After method call),However, view rendering has not yet been performed");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
logger.info("The whole request has been processed, DispatcherServlet The corresponding view is also rendered. At this time, I can do some cleaning work");
}
}
Then add the customized interceptor to the interceptor configuration.
@Configuration
public class MyInterceptorConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
// Implementing WebMvcConfigurer will not cause static resources to be intercepted
registry.addInterceptor(new MyInterceptor())
// Block all URLs
.addPathPatterns("/**")
// Release swagger
.excludePathPatterns("/swagger-resources/**");
}
}
In Spring Boot, we usually store some static resources in the following directory:
classpath:/static
classpath:/public
classpath:/resources
classpath:/META-INF/resources
The / * * configured in the above code intercepts all URLs, but we implement the WebMvcConfigurer interface, which will not cause Spring Boot to intercept static resources in these directories. However, the swagger we usually visit will be blocked, so we need to release it. The swagger page is in the swagger resources directory. Just release all files in this directory.
Then enter the swagger page in the browser. If swagger can be displayed normally, it indicates that the release is successful. At the same time, the order of code execution can be determined according to the background print log.
6. Global exception handling
Global exception handling is something that must be used in each project. In specific exceptions, we may do specific handling, but for exceptions that are not handled, there is generally a unified global exception handling. Before exception handling, it is best to maintain an exception prompt information enumeration class, which is specially used to save exception prompt information. As follows:
public enum BusinessMsgEnum {
/** Parameter exception */
PARMETER_EXCEPTION("102", "Parameter exception!"),
/** Wait timeout */
SERVICE_TIME_OUT("103", "Service call timeout!"),
/** Parameter too large */
PARMETER_BIG_EXCEPTION("102", "The number of pictures entered cannot exceed 50!"),
/** 500 : exception occurred */
UNEXPECTED_EXCEPTION("500", "The system is abnormal, please contact the administrator!");
/**
* Message code
*/
private String code;
/**
* Message content
*/
private String msg;
private BusinessMsgEnum(String code, String msg) {
this.code = code;
this.msg = msg;
}
public String code() {
return code;
}
public String msg() {
return msg;
}
}
In the global unified Exception handling class, we generally handle custom business exceptions first, then handle some common system exceptions, and finally an Exception once and for all.
@ControllerAdvice
@ResponseBody
public class GlobalExceptionHandler {
private static final Logger logger = LoggerFactory.getLogger(GlobalExceptionHandler.class);
/**
* Intercept business exceptions and return business exception information
* @param ex
* @return
*/
@ExceptionHandler(BusinessErrorException.class)
@ResponseStatus(value = HttpStatus.INTERNAL_SERVER_ERROR)
public JsonResult handleBusinessError(BusinessErrorException ex) {
String code = ex.getCode();
String message = ex.getMessage();
return new JsonResult(code, message);
}
/**
* Null pointer exception
* @param ex NullPointerException
* @return
*/
@ExceptionHandler(NullPointerException.class)
@ResponseStatus(value = HttpStatus.INTERNAL_SERVER_ERROR)
public JsonResult handleTypeMismatchException(NullPointerException ex) {
logger.error("Null pointer exception,{}", ex.getMessage());
return new JsonResult("500", "Null pointer exception");
}
/**
* System exception unexpected exception
* @param ex
* @return
*/
@ExceptionHandler(Exception.class)
@ResponseStatus(value = HttpStatus.INTERNAL_SERVER_ERROR)
public JsonResult handleUnexpectedServer(Exception ex) {
logger.error("System exception:", ex);
return new JsonResult(BusinessMsgEnum.UNEXPECTED_EXCEPTION);
}
}
Among them, BusinessErrorException is a custom business exception. Just inherit the RuntimeException. See my source code for details. The code will not be pasted in this article.
There is a testException method in UserController to test global exceptions. Open the swagger page and call the interface. You can see that the user prompt message is returned: "the system has an exception, please contact the administrator! ". of course, in practice, different information needs to be prompted according to different businesses.
7. Summary
This paper mainly leads you to quickly build a Spring Boot empty architecture that can be used in a project, mainly from the unified encapsulated data structure, adjustable interface, json processing, the use of template engine (reflected in the code), the integration of persistence layer, interceptor and global exception handling. Generally, if these things are included, basically a Spring Boot project environment is almost the same, and then it is extended according to the specific situation.
Course source code download address: Poke me to download
Author information
This course starts from CSDN GitChat talent course "learning Spring Boot with brother Wu", which is a detailed note of the course.
Author: Ni Shengwu (brother Wu)
WeChat official account: Wu brother chat programming
Copyright statement: This course is free, but the copyright belongs to CSDN and the author. Without permission, the notes shall not be used for commercial purposes or other improper purposes, otherwise they shall be investigated for legal responsibility.