background
Recently, during the operation of several projects, customers have proposed whether the file upload size limit can be set larger. Users often need to upload several G data files, such as drawings and videos, and need to optimize the process of uploading large files, display the progress bar in real time, and expand and upgrade the framework file upload after technical evaluation, The extension interface supports large file fragment upload processing to reduce the instantaneous memory pressure of the server. After the upload of the same file fails, the breakpoint can be continued from the successful upload fragment location. After the file is uploaded successfully, it does not need to wait for seconds to achieve the effect of second transmission, so as to optimize the user's interactive experience. The specific implementation process is shown in the figure below
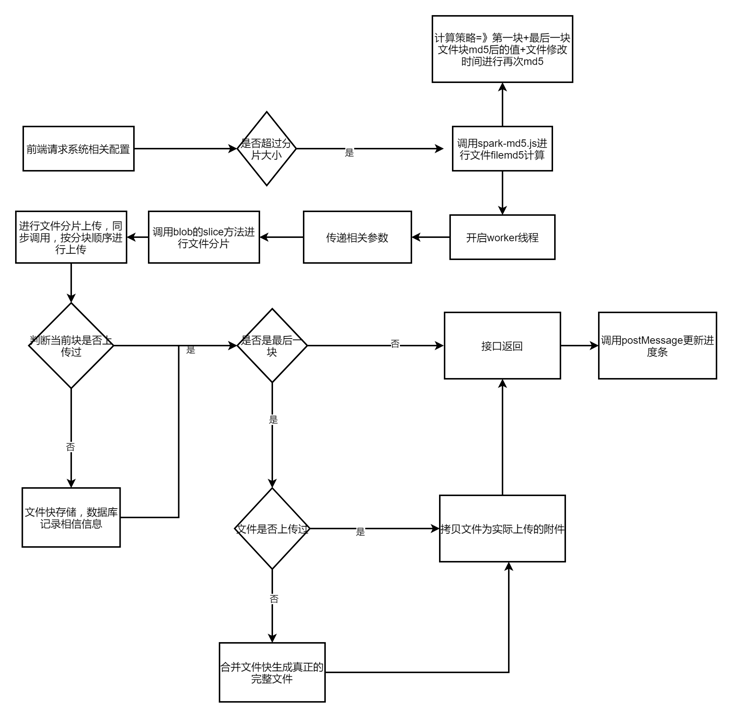
File MD5 calculation
For the calculation of file MD5, we use the spark-md5 third-party library. For large files, we can calculate them separately and then merge them to save time. However, after testing, it takes about 20s for 1G files to calculate MD5, Therefore, after optimization, we extract part of the feature information of the file (the first piece of file + the last piece of file + file modification time) to ensure the relative uniqueness of the file, it only takes about 2s to greatly improve the front-end computing efficiency. For the reading of the front-end file content block, we need to use the fileReader.readAsArrayBuffer method in the api of html5. Because it is triggered asynchronously, the encapsulated method provides a callback function for use
createSimpleFileMD5(file, chunkSize, finishCaculate) {
var fileReader = new FileReader();
var blobSlice = File.prototype.mozSlice || File.prototype.webkitSlice || File.prototype.slice;
var chunks = Math.ceil(file.size / chunkSize);
var currentChunk = 0;
var spark = new SparkMD5.ArrayBuffer();
var startTime = new Date().getTime();
loadNext();
fileReader.onload = function() {
spark.append(this.result);
if (currentChunk == 0) {
currentChunk = chunks - 1;
loadNext();
} else {
var fileMD5 = hpMD5(spark.end() + file.lastModifiedDate);
finishCaculate(fileMD5)
}
};
function loadNext() {
var start = currentChunk * chunkSize;
var end = start + chunkSize >= file.size ? file.size : start + chunkSize;
fileReader.readAsArrayBuffer(blobSlice.call(file, start, end));
}
}Document slice cutting
By defining the file fragment size, we use the file supported by the blob object Slice method cuts files, and fragment upload requests need to be synchronized in order. Because synchronization requests are used, the front-end ui will be blocked and cannot be clicked. You need to start the worker thread for operation. After completion, send a message to the main page through the postMessage method to inform the ui of the update of the progress bar. It should be noted that the worker thread method does not support window objects, Therefore, try not to use a third-party library. Use the native XMLHttpRequest object to initiate the request. The required parameters are obtained through the onmessage method
The page upload request method is as follows
upload() {
var file = document.getElementById("file").files[0];
if (!file) {
alert("Please select the file to upload");
return;
}
if (file.size < pageData.chunkSize) {
alert("Please select a file larger than" + pageData.chunkSize / 1024 / 1024 + "M")
}
var filesize = file.size;
var filename = file.name;
pageData.chunkCount = Math.ceil(filesize / pageData.chunkSize);
this.createSimpleFileMD5(file, pageData.chunkSize, function(fileMD5) {
console.log("Calculation file MD: " + fileMD5);
pageData.showProgress = true;
var worker = new Worker('worker.js');
var param = {
token: GetTokenID(),
uploadUrl: uploadUrl,
filename: filename,
filesize: filesize,
fileMD5: fileMD5,
groupguid: pageData.groupguid1,
grouptype: pageData.grouptype1,
chunkCount: pageData.chunkCount,
chunkSize: pageData.chunkSize,
file: file
}
worker.onmessage = function(event) {
var workresult = event.data;
if (workresult.code == 0) {
pageData.percent = workresult.percent;
if (workresult.percent == 100) {
pageData.showProgress = false;
worker.terminate();
}
} else {
pageData.showProgress = false;
worker.terminate();
}
}
worker.postMessage(param);
})
}worker.js execution method is as follows
function FormAjax_Sync(token, data, url, success) {
var xmlHttp = new XMLHttpRequest();
xmlHttp.open("post", url, false);
xmlHttp.setRequestHeader("token", token);
xmlHttp.onreadystatechange = function() {
if (xmlHttp.status == 200) {
var result = JSON.parse(this.responseText);
var status = this.status
success(result, status);
}
};
xmlHttp.send(data);
}
onmessage = function(evt) {
var data = evt.data;
console.log(data)
//Parameters passed
var token = data.token
var uploadUrl = data.uploadUrl
var filename = data.filename
var fileMD5 = data.fileMD5
var groupguid = data.groupguid
var grouptype = data.grouptype
var chunkCount = data.chunkCount
var chunkSize = data.chunkSize
var filesize = data.filesize
var filename = data.filename
var file = data.file
var start = 0;
var end;
var index = 0;
var startTime = new Date().getTime();
while (start < filesize) {
end = start + chunkSize;
if (end > filesize) {
end = filesize;
}
var chunk = file.slice(start, end); //Cut file
var formData = new FormData();
formData.append("file", chunk, filename);
formData.append("fileMD5", fileMD5);
formData.append("chunkCount", chunkCount)
formData.append("chunkIndex", index);
formData.append("chunkSize", end - start);
formData.append("groupguid", groupguid);
formData.append("grouptype", grouptype);
//Upload file
FormAjax_Sync(token, formData, uploadUrl, function(result, status) {
var code = 0;
var percent = 0;
if (result.code == 0) {
console.log("Slice total" + chunkCount + "individual" + ",Successfully uploaded page" + index + "individual")
percent = parseInt((parseInt(formData.get("chunkIndex")) + 1) * 100 / chunkCount);
} else {
filesize = -1;
code = -1
console.log("Slice section" + index + "Failed to upload")
}
self.postMessage({ code: code, percent: percent });
})
start = end;
index++;
}
console.log("Total upload time:" + (new Date().getTime() - startTime));
console.log("Slice completion");
}
File fragment receiving
After the front-end file fragmentation processing is completed, let's introduce the back-end file acceptance processing scheme in detail. Fragmentation processing needs to support users to interrupt uploading and repeatedly upload files at any time. We create a new table f_attachchunk to record the details of file fragmentation. The table structure is designed as follows
CREATE TABLE `f_attachchunk` ( `ID` int(11) NOT NULL AUTO_INCREMENT, `ChunkGuid` varchar(50) NOT NULL, `FileMD5` varchar(100) DEFAULT NULL, `FileName` varchar(200) DEFAULT NULL, `ChunkSize` int(11) DEFAULT NULL, `ChunkCount` int(11) DEFAULT NULL, `ChunkIndex` int(11) DEFAULT NULL, `ChunkFilePath` varchar(500) DEFAULT NULL, `UploadUserGuid` varchar(50) DEFAULT NULL, `UploadUserName` varchar(100) DEFAULT NULL, `UploadDate` datetime DEFAULT NULL, `UploadOSSID` varchar(200) DEFAULT NULL, `UploadOSSChunkInfo` varchar(1000) DEFAULT NULL, `ChunkType` varchar(50) DEFAULT NULL, `MergeStatus` int(11) DEFAULT NULL, PRIMARY KEY (`ID`) ) ENGINE=InnoDB AUTO_INCREMENT=237 DEFAULT CHARSET=utf8mb4;
- FileMD5: unique identification file
- FileName: file name
- ChunkSize: slice size
- ChunkCount: total number of slices
- ChunkIndex: slice corresponding serial number
- ChunkFilePath: fragmented storage path (used by local storage file scheme)
- UploadUserGuid: uploader's primary key
- UploadUserName: name of the uploader
- UploadDate: uploader's date
- UploadOSSID: batch ID of fragment upload (used by cloud storage scheme)
- UploadOSSChunkInfo: upload monolithic information in pieces (for cloud storage scheme)
- ChunkType: piecemeal storage mode (local storage, Alibaba cloud, Huawei cloud, Minio logo)
- MergeStatus: fragment merging status (not merged, merged)
The back-end of file fragmentation storage is divided into three steps. Check fragmentation = "" save fragmentation = "" merge fragmentation. Let's take local file storage as an example to explain. The idea of cloud storage is the same, and the corresponding api methods will be provided later
Check slice
Check the partition. The uniqueness of the partition is determined by the combination of FIleMD5 and ChunkIndex of the partition record of the database file. Because the local partition temp file is stored as a temporary file, there may be a problem of manually clearing the cast disk space. Therefore, there are records in the database. We also need to check the actual file situation accordingly
boolean existChunk = false;
AttachChunkDO dbChunk = attachChunkService.checkExistChunk(fileMD5, chunkIndex, "Local");
if (dbChunk != null) {
File chunkFile = new File(dbChunk.getChunkFilePath());
if (chunkFile.exists()) {
if (chunkFile.length() == chunkSize) {
existChunk = true;
} else {
//Delete database record
attachChunkService.delete(dbChunk.getChunkGuid());
}
} else {
//Delete database record
attachChunkService.delete(dbChunk.getChunkGuid());
}
}Save slice
The saved partition is divided into two pieces. The file is stored locally. After success, the database inserts the corresponding partition information
//Get the attachment upload folder in the configuration
String filePath = frameConfig.getAttachChunkPath() + "/" + fileMD5 + "/";
//Create folder based on attachment guid
File targetFile = new File(filePath);
if (!targetFile.exists()) {
targetFile.mkdirs();
}
if (!existChunk) {
//Save file to folder
String chunkFileName = fileMD5 + "-" + chunkIndex + ".temp";
FileUtil.uploadFile(FileUtil.convertStreamToByte(fileContent), filePath, chunkFileName);
//Insert chunk table
AttachChunkDO attachChunkDO = new AttachChunkDO(fileMD5, fileName, chunkSize, chunkCount, chunkIndex, filePath + chunkFileName, "Local");
attachChunkService.insert(attachChunkDO);
}Merge fragmentation
In the upload fragmentation method, if the current partition is the last one, we will merge the files and update the database consolidation status after uploading. The next time the same file is uploaded, we can directly copy the previously merged files as new attachments to reduce the I/O operation in the consolidation step, When merging files, we use BufferedOutputStream and BufferedInputStream to fix the buffer size
if (chunkIndex == chunkCount - 1) {
//Merge files
String merageFileFolder = frameConfig.getAttachPath() + groupType + "/" + attachGuid;
File attachFolder = new File(merageFileFolder);
if (!attachFolder.exists()) {
attachFolder.mkdirs();
}
String merageFilePath = merageFileFolder + "/" + fileName;
merageFile(fileMD5, merageFilePath);
attachChunkService.updateMergeStatusToFinish(fileMD5);
//Insert into attachment Library
//Set attachment unique guid
attachGuid = CommonUtil.getNewGuid();
attachmentDO.setAttguid(attachGuid);
attachmentService.insert(attachmentDO);
} public void merageFile(String fileMD5, String targetFilePath) throws Exception {
String merageFilePath = frameConfig.getAttachChunkPath()+"/"+fileMD5+"/"+fileMD5+".temp";
File merageFile = new File(merageFilePath);
if(!merageFile.exists()){
BufferedOutputStream destOutputStream = new BufferedOutputStream(new FileOutputStream(merageFilePath));
List<AttachChunkDO> attachChunkDOList = attachChunkService.selectListByFileMD5(fileMD5, "Local");
for (AttachChunkDO attachChunkDO : attachChunkDOList) {
File file = new File(attachChunkDO.getChunkFilePath());
byte[] fileBuffer = new byte[1024 * 1024 * 5];//File read / write cache
int readBytesLength = 0; //Bytes per read
BufferedInputStream sourceInputStream = new BufferedInputStream(new FileInputStream(file));
while ((readBytesLength = sourceInputStream.read(fileBuffer)) != -1) {
destOutputStream.write(fileBuffer, 0, readBytesLength);
}
sourceInputStream.close();
}
destOutputStream.flush();
destOutputStream.close();
}
FileUtil.copyFile(merageFilePath,targetFilePath);
}Cloud file fragment upload
The difference between cloud file upload and local file upload is that segmented files are directly uploaded to the cloud, and then the cloud storage api is called for file consolidation and file copy. There is little difference in database related records and checks
Alibaba cloud OSS
Before uploading fragments, the fragment upload group ID uploadid of the file needs to be generated
public String getUplaodOSSID(String key){
key = "chunk/" + key + "/" + key;
TenantParams.attach appConfig = getAttach();
OSSClient ossClient = InitOSS(appConfig);
String bucketName = appConfig.getBucketname_auth();
InitiateMultipartUploadRequest request = new InitiateMultipartUploadRequest(bucketName, key);
InitiateMultipartUploadResult upresult = ossClient.initiateMultipartUpload(request);
String uploadId = upresult.getUploadId();
ossClient.shutdown();
return uploadId;
}When uploading fragments, we need to specify uploadid. At the same time, we need to serialize the returned fragment information PartETag and save it in the database for subsequent file merging
public String uploadChunk(InputStream stream,String key, int chunkIndex, int chunkSize, String uploadId){
key = "chunk/" + key + "/" + key;
String result = "";
try{
TenantParams.attach appConfig = getAttach();
OSSClient ossClient = InitOSS(appConfig);
String bucketName = appConfig.getBucketname_auth();
UploadPartRequest uploadPartRequest = new UploadPartRequest();
uploadPartRequest.setBucketName(bucketName);
uploadPartRequest.setKey(key);
uploadPartRequest.setUploadId(uploadId);
uploadPartRequest.setInputStream(stream);
// Set the slice size. Except for the last partition, there is no size limit, and the minimum size of other partitions is 100 KB.
uploadPartRequest.setPartSize(chunkSize);
// Set the slice number. Each uploaded partition has a partition number, ranging from 1 to 10000. If this range is exceeded, the OSS will return an InvalidArgument error code.
uploadPartRequest.setPartNumber(chunkIndex+1);
// Each partition does not need to be uploaded in order, and can even be uploaded on different clients. The OSS will sort according to the partition number to form a complete file.
UploadPartResult uploadPartResult = ossClient.uploadPart(uploadPartRequest);
PartETag partETag = uploadPartResult.getPartETag();
result = JSON.toJSONString(partETag);
ossClient.shutdown();
}catch (Exception e){
logger.error("OSS Upload file Chunk fail:" + e.getMessage());
}
return result;
}When merging fragments, the operation is carried out by passing the PartETag object array that saves the fragments. For the independence and uniqueness of attachments, we do not directly use the merged file, but copy the file through the api
public boolean merageFile(String uploadId, List<PartETag> chunkInfoList,String key,AttachmentDO attachmentDO,boolean checkMerge){
key = "chunk/" + key + "/" + key;
boolean result = true;
try{
TenantParams.attach appConfig = getAttach();
OSSClient ossClient = InitOSS(appConfig);
String bucketName = appConfig.getBucketname_auth();
if(!checkMerge){
CompleteMultipartUploadRequest completeMultipartUploadRequest = new CompleteMultipartUploadRequest(bucketName, key, uploadId, chunkInfoList);
CompleteMultipartUploadResult completeMultipartUploadResult = ossClient.completeMultipartUpload(completeMultipartUploadRequest);
}
String attachKey = getKey(attachmentDO);
ossClient.copyObject(bucketName,key,bucketName,attachKey);
ossClient.shutdown();
}catch (Exception e){
e.printStackTrace();
logger.error("OSS Failed to merge files:" + e.getMessage());
result = false;
}
return result;
}Huawei cloud OBS
Huawei cloud api is roughly the same as Alibaba cloud api, with only individual parameter names being different. You can use the code directly
public String getUplaodOSSID(String key) throws Exception {
key = "chunk/" + key + "/" + key;
TenantParams.attach appConfig = getAttach();
ObsClient obsClient = InitOBS(appConfig);
String bucketName = appConfig.getBucketname_auth();
InitiateMultipartUploadRequest request = new InitiateMultipartUploadRequest(bucketName, key);
InitiateMultipartUploadResult result = obsClient.initiateMultipartUpload(request);
String uploadId = result.getUploadId();
obsClient.close();
return uploadId;
}
public String uploadChunk(InputStream stream, String key, int chunkIndex, int chunkSize, String uploadId) {
key = "chunk/" + key + "/" + key;
String result = "";
try {
TenantParams.attach appConfig = getAttach();
ObsClient obsClient = InitOBS(appConfig);
String bucketName = appConfig.getBucketname_auth();
UploadPartRequest uploadPartRequest = new UploadPartRequest();
uploadPartRequest.setBucketName(bucketName);
uploadPartRequest.setUploadId(uploadId);
uploadPartRequest.setObjectKey(key);
uploadPartRequest.setInput(stream);
uploadPartRequest.setOffset(chunkIndex * chunkSize);
// Set the slice size. Except for the last partition, there is no size limit, and the minimum size of other partitions is 100 KB.
uploadPartRequest.setPartSize((long) chunkSize);
// Set the slice number. Each uploaded partition has a partition number, ranging from 1 to 10000. If this range is exceeded, the OSS will return an InvalidArgument error code.
uploadPartRequest.setPartNumber(chunkIndex + 1);
// Each partition does not need to be uploaded in order, and can even be uploaded on different clients. The OSS will sort according to the partition number to form a complete file.
UploadPartResult uploadPartResult = obsClient.uploadPart(uploadPartRequest);
PartEtag partETag = new PartEtag(uploadPartResult.getEtag(), uploadPartResult.getPartNumber());
result = JSON.toJSONString(partETag);
obsClient.close();
} catch (Exception e) {
e.printStackTrace();
logger.error("OBS Upload file Chunk:" + e.getMessage());
}
return result;
}
public boolean merageFile(String uploadId, List<PartEtag> chunkInfoList, String key, AttachmentDO attachmentDO, boolean checkMerge) {
key = "chunk/" + key + "/" + key;
boolean result = true;
try {
TenantParams.attach appConfig = getAttach();
ObsClient obsClient = InitOBS(appConfig);
String bucketName = appConfig.getBucketname_auth();
if (!checkMerge) {
CompleteMultipartUploadRequest request = new CompleteMultipartUploadRequest(bucketName, key, uploadId, chunkInfoList);
obsClient.completeMultipartUpload(request);
}
String attachKey = getKey(attachmentDO);
obsClient.copyObject(bucketName, key, bucketName, attachKey);
obsClient.close();
} catch (Exception e) {
e.printStackTrace();
logger.error("OBS Failed to merge files:" + e.getMessage());
result = false;
}
return result;
}Minio
File storage Minio is widely used. The framework also supports its own independently deployed Minio file storage system. Minio does not have corresponding fragment upload api support. After uploading fragment files, we can use the composeObject method to merge files
public boolean uploadChunk(InputStream stream, String key, int chunkIndex) {
boolean result = true;
try {
MinioClient minioClient = InitMinio();
String bucketName = frameConfig.getMinio_bucknetname();
PutObjectOptions option = new PutObjectOptions(stream.available(), -1);
key = "chunk/" + key + "/" + key;
minioClient.putObject(bucketName, key + "-" + chunkIndex, stream, option);
} catch (Exception e) {
logger.error("Minio upload Chunk File failed:" + e.getMessage());
result = false;
}
return result;
}
public boolean merageFile(String key, int chunkCount, AttachmentDO attachmentDO, boolean checkMerge) {
boolean result = true;
try {
MinioClient minioClient = InitMinio();
String bucketName = frameConfig.getMinio_bucknetname();
key = "chunk/" + key + "/" + key;
if (!checkMerge) {
List<ComposeSource> sourceObjectList = new ArrayList<ComposeSource>();
for (int i = 0; i < chunkCount; i++) {
ComposeSource composeSource = ComposeSource.builder().bucket(bucketName).object(key + "-" + i).build();
sourceObjectList.add(composeSource);
}
minioClient.composeObject(ComposeObjectArgs.builder().bucket(bucketName).object(key).sources(sourceObjectList).build());
}
String attachKey = getKey(attachmentDO);
minioClient.copyObject(
CopyObjectArgs.builder()
.bucket(bucketName)
.object(attachKey)
.source(
CopySource.builder()
.bucket(bucketName)
.object(key)
.build())
.build());
} catch (Exception e) {
logger.error("Minio Failed to merge files:" + e.getMessage());
result = false;
}
return result;
}