Multi data source configuration is mostly used for automatic switching between read-write libraries or master-slave libraries. However, in some cases, it is also necessary to switch data sources in business
The core principles of the current mainstream multi data source schemes, whether using the existing framework or customization, are similar. This example is to simulate the use scenario of multi data sources in the business and customize the switching rules to realize the switching of multi data sources
The implementation logic of the instance is:
Where there are annotations, the data sources marked with annotations shall be used preferentially;
If the annotation does not specify a data source, the URL will be parsed to automatically match the data source;
If annotations are not used, the default data source is used
The principle used is to maintain the data source variables inside the thread. When the request comes in, use the aspect to specify the data source and pass it inside the thread
Because the variables used are maintained inside the thread, when there is thread switching, the data source will be lost. At this time, it is necessary to manually transfer the data source, or use feasible technologies to realize dynamic switching according to the corresponding technologies, but the principles are the same
Many core logics in the instance can be extended or customized to meet the needs of different businesses
Framework and technology used:
springboot mybatis mysql
ThreadLocal AOP DynamicDataSource
Code display
First show the file structure of the example:

The main documents are described below:
application.yml
# apply name
spring:
profiles:
# Introducing the application-jdbc.properties configuration file
active: jdbc
application:
name: database
# Database driven
datasource:
db1:
driver-class-name: com.mysql.cj.jdbc.Driver
username: ${db1.username}
password: ${db1.password}
jdbc-url: ${db1.url}
db2:
driver-class-name: com.mysql.cj.jdbc.Driver
username: ${db2.username}
password: ${db2.password}
jdbc-url: ${db2.url}
server:
port: 80
servlet:
context-path: /db
# Specifies the Mapper file for Mybatis
mybatis:
mapper-locations: classpath:mappers/*xml
type-aliases-package: jin.panpan.database.entity
#Log configuration
logging:
config: classpath:log4j2.xml
Copy codeIn addition to the basic application name, port, path, log and other configurations, the configuration file mainly depends on the database driven configuration. Unlike the usual single data source configuration, we need to configure multiple data sources. In the configuration file of the above example, there are two points of note:
- db1 and db2 are our custom data source names, which we will use in the MybatisConfig file later
- The configuration JDBC url in the data source corresponds to the url in the single data source configuration. If the url is used here, the injection will fail
- ${db1.username} are the configuration values in the imported application-jdbc.properties file
application-jdbc.properties
db1.username = user db1.password = db1.url = jdbc:mysql://xx.xx.xx.xx:3306/db1 db2.username = user db2.password = db2.url = jdbc:mysql://xx.xx.xx.xx:3306/db2 Copy code
Key value structure. Key can be referenced by ${key} in the configuration imported into this file
Here we use two databases, but the table structure of the database is consistent (at least the tables involved in multiple data sources need to be consistent), so as to avoid not sharing a set of code
DataSourceType
public enum DataSourceType {
//NONE is used to return to the default
NONE(""),
DB1("db1"),
DB2("db2"),
;
//Omit some codes
}
Copy codeThis file is an enumeration of data sources. For the enumeration here, we only configure one parameter, which can be extended according to the business. The value of this enumeration represents the name of the data source and corresponds to the configuration in the configuration file
In addition, NONE is used to represent the default data source. It is added for programming convenience and is not necessary
DataSourceUtil
public class DataSourceUtil {
private static final ThreadLocal<DataSourceType> localDataSource = new ThreadLocal<>();
private DataSourceUtil(){
}
public static DataSourceType get() {
return localDataSource.get();
}
public static void set(DataSourceType type){
localDataSource.set(type);
}
public static void remove() {
localDataSource.remove();
}
}
Copy codeThe core of the data source switching tool class is ThreadLocal < datasourcetype > variable. ThreadLocal has been used for document analysis before, which is mainly used to maintain internal variables of threads, including:
-
The get() method is used to get the data source
-
The set() method is used to set the data source
-
remove() is used to clear the data source
MybatisConfig*
@Configuration
@MapperScan("jin.panpan.database.dao")
public class MybatisConfig {
//Default data source
@Primary
@Bean("db1")
@ConfigurationProperties(prefix = "spring.datasource.db1")
public DataSource dataSource1(){
return DataSourceBuilder.create().build();
}
@Bean("db2")
@ConfigurationProperties(prefix = "spring.datasource.db2")
public DataSource dataSource2(){
return DataSourceBuilder.create().build();
}
//Dynamic data source selection
@Bean
public DynamicDataSource dynamicDataSource(@Qualifier("db1") DataSource db1,
@Qualifier("db2") DataSource db2){
Map<Object, Object> map = new HashMap<>();
//The key here should be consistent with the return value of determineCurrentLookupKey method of DynamicDataSource class
map.put(DataSourceType.DB1.getDatabase(), db1);
map.put(DataSourceType.DB2.getDatabase(), db2);
DynamicDataSource dynamicDataSource = new DynamicDataSource();
dynamicDataSource.setTargetDataSources(map);
//Set the default database. The selected database Bean should be injected with @ Primary annotation
dynamicDataSource.setDefaultTargetDataSource(db1);
return dynamicDataSource;
}
//Session factory configuration
@Bean
public SqlSessionFactory sqlSessionFactory(DynamicDataSource dynamicDataSource) throws Exception {
SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();
factoryBean.setDataSource(dynamicDataSource);
Resource[] resources = new PathMatchingResourcePatternResolver()
.getResources("classpath:mappers/*xml");
factoryBean.setMapperLocations(resources);
return factoryBean.getObject();
}
//Transaction management configuration
@Bean
public PlatformTransactionManager transactionManager(DynamicDataSource dynamicDataSource){
return new DataSourceTransactionManager(dynamicDataSource);
}
}
Copy codeThis class is mainly used to configure and inject mybatis related configuration bean s, mainly including the following steps:
-
Auto scan mapper interface configuration
@MapperScan("jin.panpan.database.dao")
It is generally configured in general. If multiple data sources are not configured, it is generally annotated on the entry class
-
Data source injection
@ConfigurationProperties imports the configuration in the configuration file
@Bean specifies the data source name
@Primary tag default data source
-
Data source dynamic selection Bean injection
Load multiple data sources, and specify the default data source if necessary
Note that the key of the data source container Map must be consistent with the field value in the DataSourceType, otherwise it cannot be switched
-
Session factory Bean configuration
In case of single data source, manual configuration is generally not required; When there are multiple data sources, the session factory needs to be specified manually, but the configuration is modeled
-
Transaction management Bean configuration
The configuration of transaction management is also modular. Generally, there is no special processing
DynamicDataSource*
public class DynamicDataSource extends AbstractRoutingDataSource {
private static final Logger logger = LoggerFactory.getLogger(DynamicDataSource.class);
@Override
protected Object determineCurrentLookupKey() {
String database = DataSourceUtil.get() == null ? null : DataSourceUtil.get().getDatabase();
logger.info("DynamicDataSource, Dynamic data source return={}", database);
return database;
}
}
Copy codeThis class is actually the core class of the dynamic routing data source. Extend the AbstractRoutingDataSource class and override the determineCurrentLookupKey method. The return value of the determineCurrentLookupKey method is the dynamic data source. The return value needs to correspond to the configuration file and MybatisConfig one by one
DataSource and DataSourceAspect*
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Documented
public @interface DataSource {
DataSourceType value() default DataSourceType.NONE;
}
Copy codeDataSource is a method annotation used as a data source switching entry point. Here, you can use class annotation or directly regular weave into the point you want to monitor
DataSourceAspect is the implementation of annotation and the core implementation
@Aspect
@Component
public class DataSourceAspect {
private static final Logger logger = LoggerFactory.getLogger(DataSourceAspect.class);
@Pointcut("@annotation(jin.panpan.database.dynamic.datasource.annotate.DataSource)")
public void pointCut() {
}
@SneakyThrows
@Around("pointCut()")
public Object around(ProceedingJoinPoint pjp) {
//data source
DataSourceType dataSourceType = null;
//Method object
MethodSignature signature = (MethodSignature) pjp.getSignature();
Method method = signature.getMethod();
//notes
DataSource dynamicDataSource = method.getAnnotation(DataSource.class);
String path = null;
//If the data source is specified in the comment, the data source in the database is used
if(dynamicDataSource.value()!=null && dynamicDataSource.value() != DataSourceType.NONE){
dataSourceType = dynamicDataSource.value();
}
//Otherwise, get from the request path
if(dataSourceType == null){
HttpServletRequest request = ((ServletRequestAttributes) Objects.requireNonNull(RequestContextHolder.getRequestAttributes())).getRequest();
path = request.getRequestURL().toString();
//TODO to be optimized needs to intercept the domain name for inspection
if(path.contains(DataSourceType.DB1.getDatabase())){
dataSourceType = DataSourceType.DB1;
}
if(path.contains(DataSourceType.DB2.getDatabase())){
dataSourceType = DataSourceType.DB2;
}
}
logger.info("DataSource, method={}, data source={}, route={}, Annotation has its own data source={}",
method.getName(), dataSourceType==null ? null : dataSourceType.getDatabase(),
path, dynamicDataSource.value());
if(dataSourceType == null){
throw new Exception("Illegal data source");
}
//Specify database
DataSourceUtil.set(dataSourceType);
Object result = pjp.proceed();
//Clear database
logger.info("DataSource, Clear data source, method={}, data source={}, route={}, Annotation has its own data source={}",
method.getName(), dataSourceType.getDatabase(),
path, dynamicDataSource.value());
DataSourceUtil.remove();
return result;
}
}
Copy codeThe important steps have been annotated, and the completed work is:
- Get data source from annotation / from path
- specify data source
- Clear data source after call
The core step is to switch data sources through DataSourceUtil
This method is the core method to realize the switching logic. The specific switching logic should be determined by the business logic. This is just a demonstration
Logical verification
Here are the test data:
Two databases: db1 and DB2
There is a data id=1 in db1
There is no data in db2
The core code also has logs, which can be used to observe the data source
In order to distinguish paths, the following configurations are added to hosts to distinguish paths in different environments:
127.0.0.1 db1.db.com 127.0.0.1 db2.db.com 127.0.0.1 db.com Copy code
No data source is specified and no data source annotation is enabled
@GetMapping("queryById/{id}")
public Result<BasTableEntity> selectById(@PathVariable("id") Long id){
BasTableEntity entity;
try {
entity = basTableService.queryById(id);
}catch (Exception e){
logger.error("Query exception, error={}", e.getMessage(), e);
return Result.fail(null, "Query exception");
}
return Result.success(entity);
}
Copy codeUsing the default data source db1 as expected, you can query a piece of data

Enable annotation without specifying a data source
@DataSource
@GetMapping("queryByIdj/{id}")
public Result<BasTableEntity> selectByIdj(@PathVariable("id") Long id){
BasTableEntity entity;
try {
entity = basTableService.queryById(id);
}catch (Exception e){
logger.error("Query exception, error={}", e.getMessage(), e);
return Result.fail(null, "Query exception");
}
return Result.success(entity);
}
Copy codeAddress matching data sources will be enabled as expected
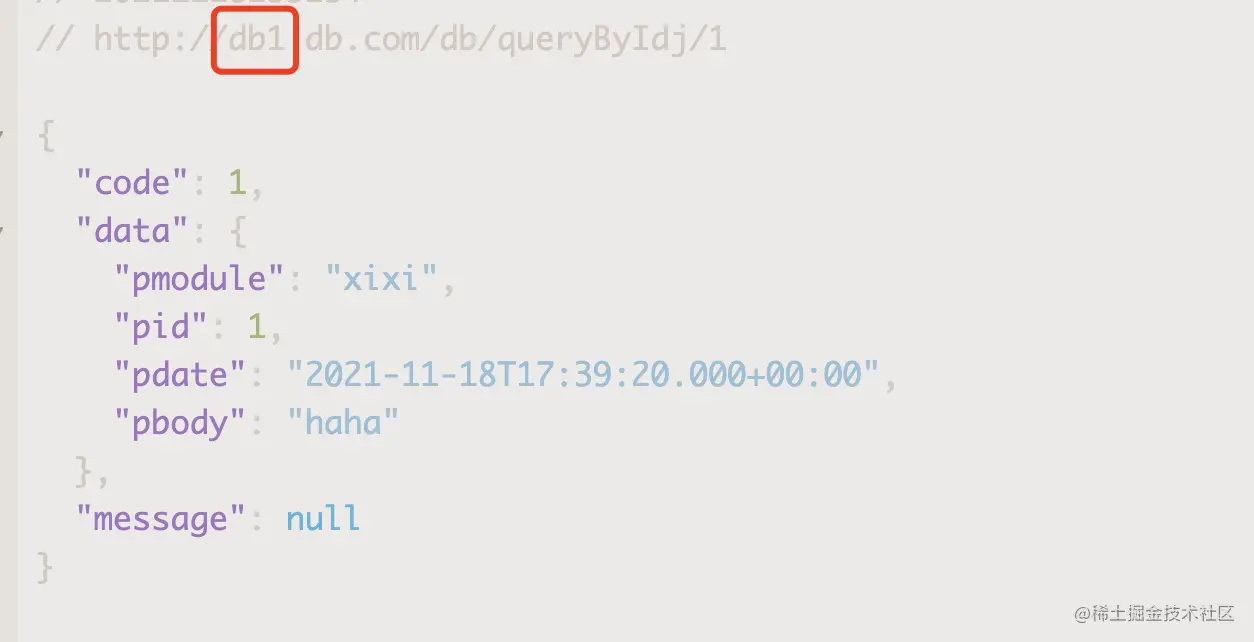

Enable annotation to specify the data source
@DataSource(DataSourceType.DB2)
@GetMapping("queryByIdp/{id}")
public Result<BasTableEntity> selectByIdp(@PathVariable("id") Long id){
BasTableEntity entity;
try {
entity = basTableService.queryById(id);
}catch (Exception e){
logger.error("Query exception, error={}", e.getMessage(), e);
return Result.fail(null, "Query exception");
}
return Result.success(entity);
}
Copy codeThe specified data source 2 will be used as expected
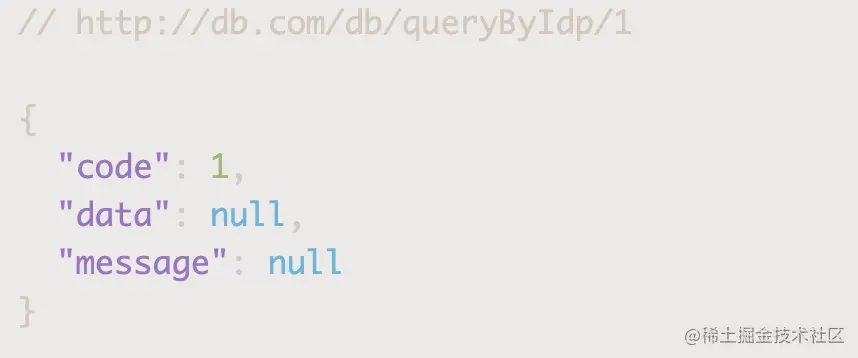
Data source loss caused by switching between processes during testing
@SneakyThrows
@DataSource(DataSourceType.DB2)
@GetMapping("queryByIda/{id}")
public Result<BasTableEntity> selectByIda(@PathVariable("id") Long id){
logger.info("1.basTable={}", DataSourceUtil.get());
//Thread pool, which simulates business actions to be performed in a multithreaded environment
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
Future<BasTableEntity> future;
BasTableEntity entity;
try {
future = newCachedThreadPool.submit(() -> {
logger.info("2.basTable={}", DataSourceUtil.get());
return basTableService.queryById(id);
});
}catch (Exception e){
logger.error("Query exception, error={}", e.getMessage(), e);
return Result.fail(null, "Query exception");
}
logger.info("3.basTable={}", DataSourceUtil.get());
entity = future.get();
newCachedThreadPool.shutdown();
return Result.success(entity);
}
Copy code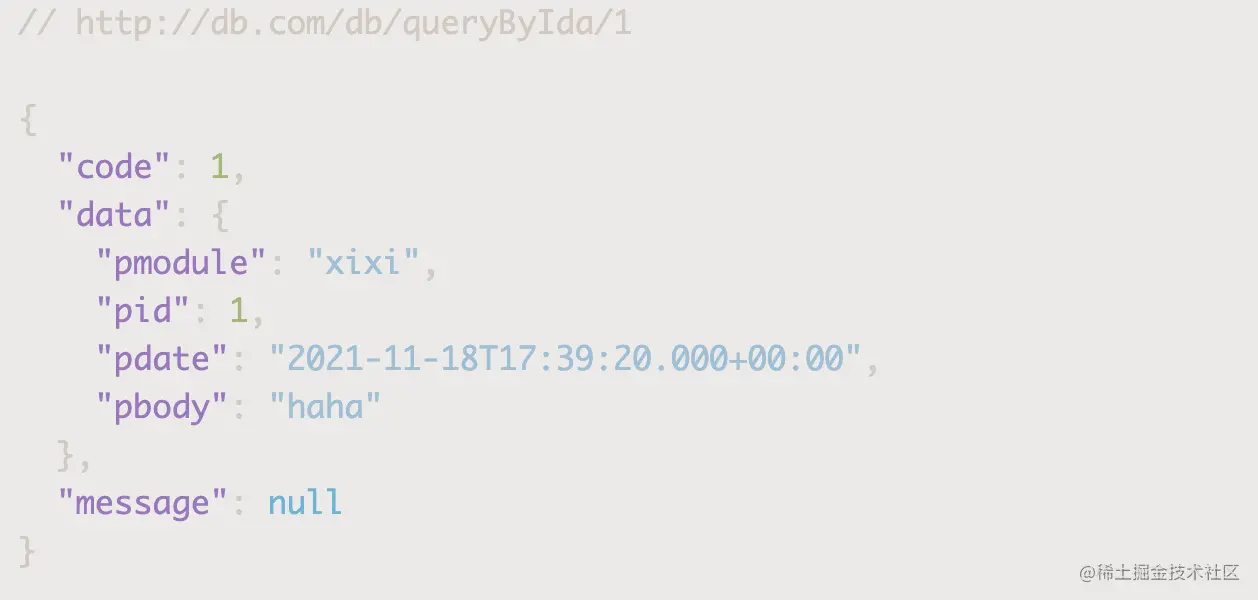
It can be seen that although db2 is specified, the data is still queried, indicating that the default data source is used, and it can also be seen from logs

The data source in the thread (2.basTable =) is lost because the thread is no longer the original thread
The problem of data source loss caused by inter process switching is solved
@SneakyThrows
@DataSource(DataSourceType.DB2)
@GetMapping("queryByIdt/{id}")
public Result<BasTableEntity> selectByIdt(@PathVariable("id") Long id){
//Get data source
DataSourceType type = DataSourceUtil.get();//****Core code 1****
logger.info("1.basTable={}", type);
//Thread pool, which simulates business actions to be performed in a multithreaded environment
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
Future<BasTableEntity> future;
BasTableEntity entity;
try {
future = newCachedThreadPool.submit(() -> {
//Enter a new thread and pass the data source
DataSourceUtil.set(type);//****Core code 2****
logger.info("2.basTable={}", DataSourceUtil.get());
return basTableService.queryById(id);
});
}catch (Exception e){
logger.error("Query exception, error={}", e.getMessage(), e);
return Result.fail(null, "Query exception");
}
logger.info("3.basTable={}", DataSourceUtil.get());
entity = future.get();
newCachedThreadPool.shutdown();
return Result.success(entity);
}
Copy code
Look at the log:

Data source delivery succeeded
This method can be used when other data sources may be lost
Link: https://juejin.cn/post/7031940424713371655