Foreword: At this stage of high concurrency, MySQL must be read-write separated. In fact, most Internet websites or App s read more and write less. So in this case, if you write a master library, but the master library hangs multiple slaves and reads from multiple slaves, can't that support higher read concurrency pressure?
1. MySQL Read-Write Separation
1.1. How to achieve read-write separation of MySQL?
It's really simple, based on the master-slave replication architecture. Simply put, set up a master library, hang up multiple slave libraries, then we just write to the master library, and the master library will automatically synchronize the data to the slave library, and the slave libraries will be used for reading.
Read-write separation is about which database a SQL should choose to execute. There are two things about who should choose the database, either using the middleware for us or the program itself. Generally speaking, there are two ways to achieve read-write separation. The first is to rely on the middleware MyCat, which means that the application connects to the middleware and the middleware helps us do the SQL separation to select the specified data source. The second is that the application separates itself. Here I do it by myself, mainly using the routing data sources provided by Spring, as well as AOP.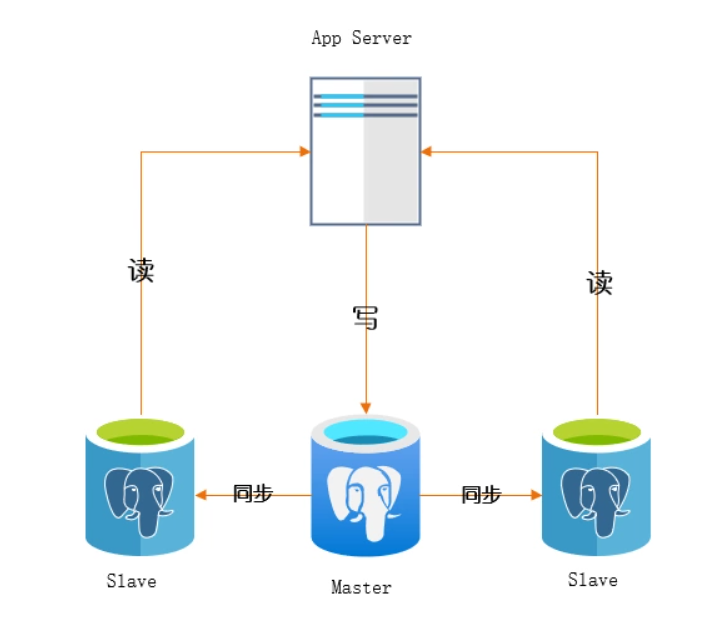
1.2. Principle of MySQL master-slave replication?
After the primary library writes changes to the binlog log, and then connects from the library to the primary library, there is an IO thread from the library that copies the binlog log of the primary library to its own local location and writes to a relay relay log. Next, an SQL thread from the library reads the binlog from the relay log and executes the contents of the binlog log, which is to execute the SQL again locally to ensure that it is the same as the primary database's data.
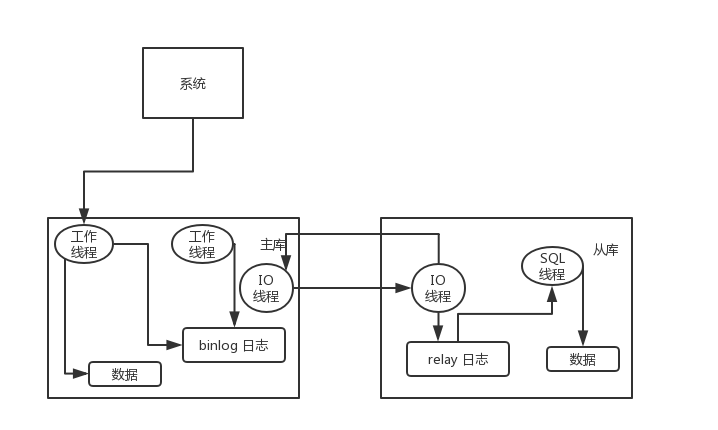 mysql-master-slave
mysql-master-slave
One of the most important points here is that the process of synchronizing data from the master library is serialized, that is, parallel operations from the master library are executed serially from the slave library. So this is a very important point, because of the characteristics of copying logs from the master library from the slave library and executing SQL serially, in high concurrency scenarios, the data from the slave database will be slower and more delayed than that from the master library. As a result, it often occurs that data that has just been written to the primary database may not be readable, taking tens of milliseconds or even hundreds of milliseconds to read.
Another problem here is that if the main library suddenly goes down and the data is not synchronized to the slave library, some data may be missing from the library and some data may be lost.
So MySQL actually has two mechanisms in this block, one is semi-synchronous replication, which solves the problem of data loss in the primary database. One is parallel replication, which solves the master-slave synchronization delay problem.
This so-called semi-sync replication, also known as semi-sync replication, means that once the primary library has written a binlog, it will be forced to synchronize the data to the slave library immediately. After the log has been written to its local relay log from the library, a ack will be returned to the primary library. The primary library will not consider the write operation complete until it receives at least one ack from the library.
Parallel replication refers to opening multiple threads from a library, reading the logs of different libraries in the relay log in parallel, and replaying the logs of different libraries in parallel, which is library level parallelism.
1.3. MySQL Master-Slave Synchronization Delay (essence)
Online, you'll find that there's always some data every day, and we expect to update some important data states, but not during rush hour. User feedback to customer service, and customer service feedback to us.
Reasons for Master-Slave Synchronization Delay
A server opens N links to clients to connect, so there will be large concurrent updates, but there is only one thread reading binlog from the server. When a SQL executes from the server for a slightly longer period of time or because a SQL wants to lock tables, a large backlog of SQL from the master server is not synchronized to the slave server. This leads to master-slave inconsistency, which is master-slave delay.
Solutions for Master-Slave Synchronization Delay
Generally speaking, if the master-slave delay is serious, there are the following solutions:
-
Repositories: Split a primary library into multiple primary libraries, and write concurrency for each primary library is reduced several times, with master-slave latencies negligible.
-
A mandatory master library query requiring a master library: If there really is one that must be inserted first, the query will be requested immediately, and then the reverse operation will be performed immediately to set up a direct master library for this query.
-
Rewrite the code: The students who write the code should be careful, the query may not find the data immediately when inserting it.
2. SpringBoot+AOP+MyBatis for MySQL Read-Write Separation
The code environment is Springboot+MyBatis+AOP. To separate read from write, multiple data sources need to be configured. Write operations select the data source for writing (primary library) and read operations select the data source for reading (secondary library).
2.1,AbstractRoutingDataSource
SpringBoot provides the AbstractRoutingDataSource class to select the current data source based on user-defined rules so that we can set the data source to use before executing the query. Implements dynamically routable data sources that are executed before each database query operation. Its Abstract method, determineCurrentLookupKey(), determines which data source to use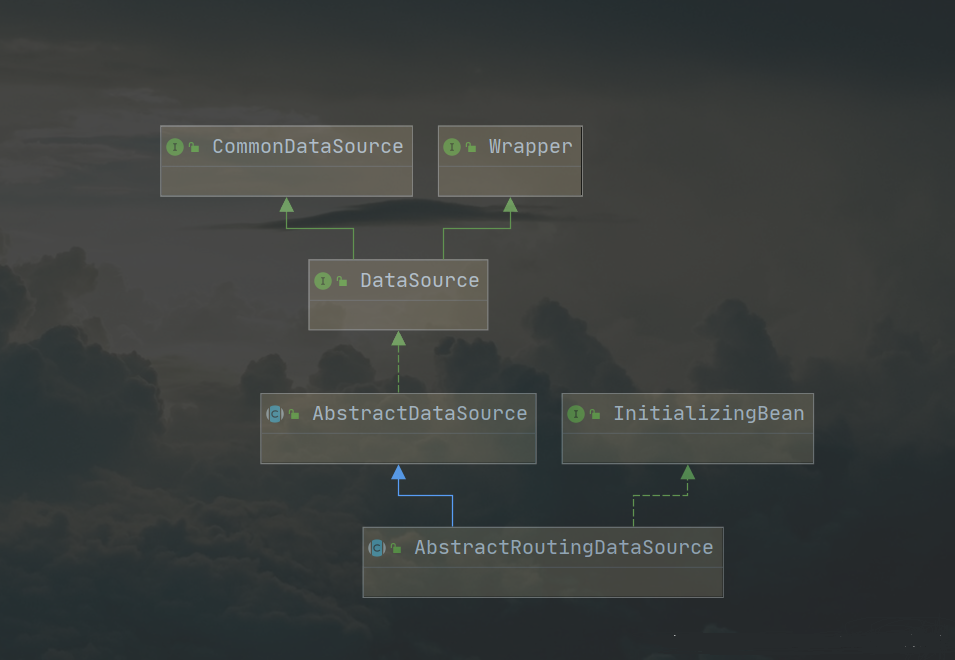
To separate read from write, you need to configure multiple data sources. Writing is the data source you choose to write to, and reading is the data source you choose to read from. There are two key points:
-
How to switch data sources
-
How to choose the right data source based on different methods
2.2. How to switch data sources
_springboot is usually used with its default configuration, just define the connection properties in the configuration file, but now we need to configure it ourselves. spring supports multiple data sources. Multiple data sources are placed in one HashMapTarget datasource, and key is obtained from dertermineCurrentLookupKey to determine which data source to use. So our goal is clear: to set up multiple datasources to put in the TargetDataSource and override the dertermineCurrentLookupKey method to determine which key to use.
2.3. How to select a data source
_Transactions are typically annotated at the Service layer, so to determine the data source when starting this service method call, what general method can operate on before starting a method call? Believe you've thought that's ** Slice **. There are two ways to cut it:
-
Annotatory, which defines a read-only annotation labeled with the data using the Read Library
-
Method name, write a cut point based on the method name, such as getXXX with a read library, setXXX with a write library
3. Code implementation
3.0, Project Directory Structure
3.1. Introducing Maven Dependency
<dependencies>
<!--SpringBoot Integrate Aop Start Dependency-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<!--SpringBoot Integrate WEB Start Dependency-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--mybatis Integrate SpringBoot Start Dependency-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.3</version>
</dependency>
<!--MySQL drive-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--SpringBoot Unit Test Dependency-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
3.2. Write a configuration file to configure master-slave data sources
spring:
datasource:
#Main Configuration Source
master:
name: test
jdbc-url: jdbc:mysql://39.106.49.9:3306/test?allowMultiQueries=true&useSSL=false&useUnicode=true&characterEncoding=utf-8
username: root
password: hs123456
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
maximum-pool-size: 20
max-lifetime: 30000
idle-timeout: 30000
data-source-properties:
prepStmtCacheSize: 250
prepStmtCacheSqlLimit: 2048
cachePrepStmts: true
useServerPrepStmts: true
#From Configuration Source
slave:
name: test
jdbc-url: jdbc:mysql://8.131.82.44:3306/test?allowMultiQueries=true&useSSL=false&useUnicode=true&characterEncoding=utf-8
username: root
password: hs123456
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
maximum-pool-size: 20
max-lifetime: 30000
idle-timeout: 30000
data-source-properties:
prepStmtCacheSize: 250
prepStmtCacheSqlLimit: 2048
cachePrepStmts: true
useServerPrepStmts: true
#MyBatis:
# mapper-locations: classpath:mapper/*.xml
# type-aliases-package: com.hs.demo.entity3.3, Enum class, defining master library and slave Library
Define an enumeration class to represent these three data sources
package com.hs.demo.config;
/**
* Enum Class that defines two data sources for the master library and the slave Library
*/
public enum DBTypeEnum {
MASTER, SLAVE;
}3.4, ThreadLocal defines data source switching
Bind data sources to each thread context through ThreadLocal
package com.hs.demo.config;
/**
*ThreadLocal Define data source switches to bind data sources to each thread context through ThreadLocal
*/
public class DBContextHolder {
/**
* ThreadLocal Not Thread, it is a data storage class within a thread through which data can be stored in a specified thread. After data storage, the stored data can only be retrieved in a thread, but not for other threads.
* Roughly speaking, ThreadLocal provides the ability to store variables within threads, which differ in that each thread reads variables independently of each other, and the values for the current thread can be obtained by get and set methods.
*/
private static final ThreadLocal<DBTypeEnum> contextHolder = new ThreadLocal<>();
public static void set(DBTypeEnum dbTypeEnum){
contextHolder.set(dbTypeEnum);
}
public static DBTypeEnum get() {
return contextHolder.get();
}
public static void master() {
set(DBTypeEnum.MASTER);
System.out.println("--------The following actions are master(Write operations)--------");
}
public static void slave() {
set(DBTypeEnum.SLAVE);
System.out.println("--------The following actions are slave(Read Operation)--------");
}
public static void clear() {
contextHolder.remove();
}
}3.5, Override Routing Selection Class
Override the determineCurrentLookupKey method to get the routing key bound on the current thread. Spring uses this method to decide which database source to use when starting a database operation, so here we call the getDbType() method of the DbContextHolder class above to get the current operation category.
package com.hs.demo.config;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import org.springframework.lang.Nullable;
/**
* AbstractRoutingDataSource The getConnection() method of lookup () makes calls to different target data sources based on finding the lookup key key key, usually through (but not necessarily) the context of something bound by certain threads.
* AbstractRoutingDataSource The core logic of dynamic switching of multiple data sources is to weave the data source into the program dynamically through AbstractRoutingDataSource while the program is running, and to switch the data source flexibly.
* Dynamic switching of multiple data sources based on AbstractRoutingDataSource can achieve read-write separation, which has obvious drawbacks and can not dynamically increase data sources.
*
* Override routing class: Get the routing key bound on the current thread
*/
public class MyRoutingDataSource extends AbstractRoutingDataSource {
/**
* determineCurrentLookupKey()Method determines which data source to use,
* Get information about the data source from Key, hook of the upper abstract function
*/
@Nullable
@Override
protected Object determineCurrentLookupKey() {
return DBContextHolder.get();
}
}3.6. Configuring multiple data sources
There are three data sources configured, one master, one slave, and one routing data source. The first two data sources are designed to generate a third data source, and we will only use this last routing data source later.
package com.hs.demo.config;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
/**
* After adding the configuration file DataSourceConfig, you need to add a Hikari connection pool, which will not occur when a single data source is automatically loaded
* Questions like this
*
* @Configuration The comment indicates that this is a configuration class that indicates that a class declares one or more @bean-declared methods and is managed uniformly by the Spring container to generate a definition of beans and a class of service requests for these beans at run time.
*/
@Configuration
public class DataSourceConfig {
/**
* Inject Primary Library Data Source
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource masterDataSource() {
return DataSourceBuilder.create().build();
//DataSourceProperties properties are placed in method parameters
// return DataSourceBuilder.create(properties.getClassLoader())
// .type(HikariDataSource.class)
// .driverClassName(properties.getDriverClassName())
// .url(properties.getUrl())
// .username(properties.getUsername())
// .password(properties.getPassword())
// .build();
}
/**
* Injection from Library Data Source
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaveDataSource() {
return DataSourceBuilder.create().build();
}
/**
* Configure Selection Data Source
* @param masterDataSource
* @param slaveDataSource
* @return DataSource
*/
@Bean
public DataSource myRoutingDataSource(@Qualifier("masterDataSource") DataSource masterDataSource, @Qualifier("slaveDataSource") DataSource slaveDataSource)
{
Map<Object, Object> targetDataSource = new HashMap<>();
targetDataSource.put(DBTypeEnum.MASTER, masterDataSource);
targetDataSource.put(DBTypeEnum.SLAVE, slaveDataSource);
MyRoutingDataSource myRoutingDataSource = new MyRoutingDataSource();
//Default data source not found
myRoutingDataSource.setDefaultTargetDataSource(masterDataSource);
//Select a target data source
myRoutingDataSource.setTargetDataSources(targetDataSource);
return myRoutingDataSource;
}
}3.7. Configure Mybatis to specify a data source
Modify SqlSessionFactory and Transaction Manager
package com.hs.demo.config;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import javax.annotation.Resource;
import javax.sql.DataSource;
/**
* Configure Mybatis to specify the data source: SqlSessionFactory and Transaction Manager
*/
@Configuration
@EnableTransactionManagement
public class MyBatisConfig {
/**
* Inject your own overridden data source
*/
@Resource(name = "myRoutingDataSource")
private DataSource myRoutingDataSource;
/**
* Configure SqlSessionFactory
* @return SqlSessionFactory
* @throws Exception
*/
@Bean
public SqlSessionFactory sqlSessionFactory() throws Exception
{
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(myRoutingDataSource);
//ResourcePatternResolver defines getResources to find resources
//PathMatchingResourcePatternResolver provides a wildcard query starting with classpath, otherwise the ResourceLoader's getResource method will be called to find
// ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
// sqlSessionFactoryBean.setMapperLocations(resolver.getResources(mapperLocation));
return sqlSessionFactoryBean.getObject();
}
/**
* Transaction Manager
* Do not write, transaction will not take effect
*/
@Bean
public PlatformTransactionManager platformTransactionManager() {
return new DataSourceTransactionManager(myRoutingDataSource);
}
// /**
// * When customizing a data source, the user must override the SqlSessionTemplate to turn on BATCH processing mode
// *
// * @param sqlSessionFactory
// * @return
// */
// @Bean
// public SqlSessionTemplate sqlSessionTemplate(@Qualifier("sqlSessionFactory") SqlSessionFactory sqlSessionFactory) {
// return new SqlSessionTemplate(sqlSessionFactory, ExecutorType.BATCH);
// }
}
3.8, AOP facets for data source switching
Set the routing key to use with Aop's pre-notification
package com.hs.demo.config;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
/**
* By default, all queries go from the main library and insert/modify/delete from the main library. We distinguish operation types (CRUD s) by method names
*
* Faces cannot be built on the DAO layer, transactions are opened on the service layer, and then switch data sources to the Dao layer, the transaction is scrapped
*
*/
@Aspect
@Component
public class DataSourceAop {
/**
* First "*" Symbol Represents any type of return value;
* com.sample.service.impl AOP The package name of the service being cut, that is, our business section
* "." Represents the current package and subpackages
* Second"*" Represents the class name, * that is, all classes. Customizable here, with examples below
* .*(..) Represents any method name, parentheses represent parameters, and two points represent any parameter type
*/
@Pointcut("!@annotation(com.hs.demo.config.Master) " +
"&& (execution(* com.hs.demo.service.*.select*(..)) " +
"|| execution(* com.hs.demo.service..*.find*(..)))")
public void readPointcut() {
}
@Pointcut("@annotation(com.hs.demo.config.Master) " +
"|| execution(* com.hs.demo.service..*.save*(..)) " +
"|| execution(* com.hs.demo.service..*.add*(..)) " +
"|| execution(* com.hs.demo.service..*.insert*(..)) " +
"|| execution(* com.hs.demo.service..*.update*(..)) " +
"|| execution(* com.hs.demo.service..*.edit*(..)) " +
"|| execution(* com.hs.demo..*.delete*(..)) " +
"|| execution(* com.hs.demo..*.remove*(..))")
public void writePointcut() {
}
@Before("readPointcut()")
public void read(JoinPoint pjp) {
//Get current method information
MethodSignature methodSignature = (MethodSignature) pjp.getSignature();
Method method = methodSignature.getMethod();
//Determine if there is a comment @Master on the method
boolean present = method.isAnnotationPresent(Master.class);
if (!present)
{
//If not, read from library by default
DBContextHolder.slave();
}
else
{
//If present, read from the main library
DBContextHolder.master();
}
}
@Before("writePointcut()")
public void write() {
DBContextHolder.master();
}
/**
* Another way to write it: if...else...determine which slave databases to read from and the rest of the master databases
*/
// @Before("execution(* com.cjs.example.service.impl.*.*(..))")
// public void before(JoinPoint jp) {
// String methodName = jp.getSignature().getName();
//
// if (StringUtils.startsWithAny(methodName, "get", "select", "find")) {
// DBContextHolder.slave();
// }else {
// DBContextHolder.master();
// }
// }
}
3.9. If you have operations that force you to take ownership of the repository, you can define notes
package com.hs.demo.config;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* Sometimes master-slave delays require a forced read of the main library's comments
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Master
{
String value();//Set Data Source Type
}3.10. Define your own read and write operations and run them as shown in the following figure

Summary: Use AOP to determine the type of data source used, and then use routing for data source selection.
Reference link:
springboot for read-write separation (based on Mybatis, mysql)