Code Address
Sharding_ Sphere_ Demo: Getting started with shardingJDBC
Introduction to ShardingSphere
ShardingSphere is an application framework that originated within Dangdang. Born in Dandang in 2015, it was originally called ShardingJDBC. In 2016, Zhang Liang, one of the main developers, brought to Jingdong Department of Mathematics, and the component team continued to develop. In China, it has experienced the test of many large Internet enterprises such as Dangdang Net, Telecom Wing Payment, Jingdong Number of Sections, etc. and started to open source in 2017. Gradually, Harding JDBC, originally focused on relational database enhancement tools, was upgraded to a complete data ecosystem based on data fragmentation, renamed ShardingSphere. By April 2020, it had become the top project of the Apache Software Foundation. ShardingSphere contains three important products, ShardingJDBC, ShardingProxy, and HardingSidecar. One of them, sidecar, is a repository and tabular plug-in for service mesh location and is currently under planning. What we're learning today is the ShardingSphere JDBC component. ShardingJDBC is used as a product for client-side repository tables, and ShardingProxy is used as a product for service-side repository tables. What is the difference between the two positions? Let's look at two important figures given in the official literature:
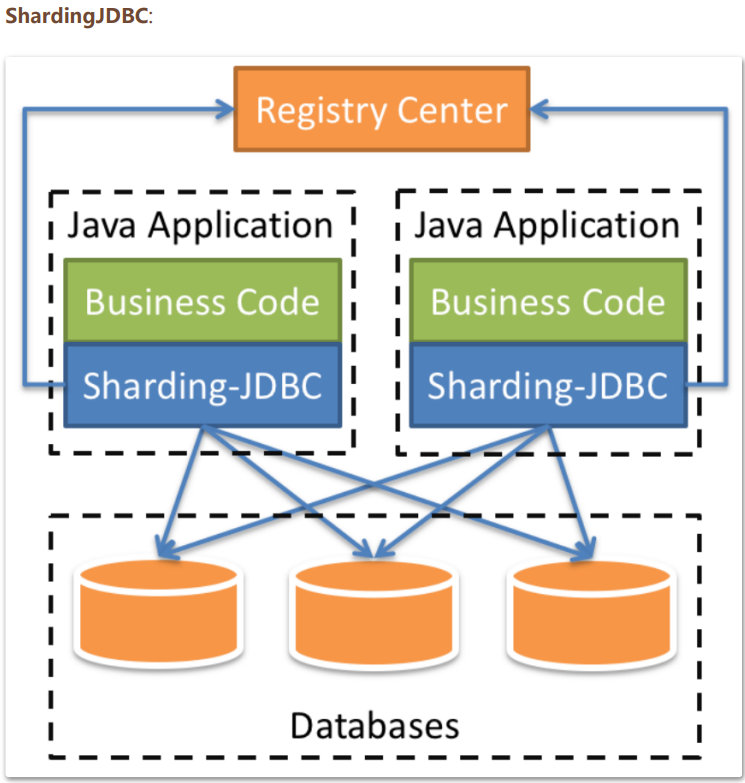
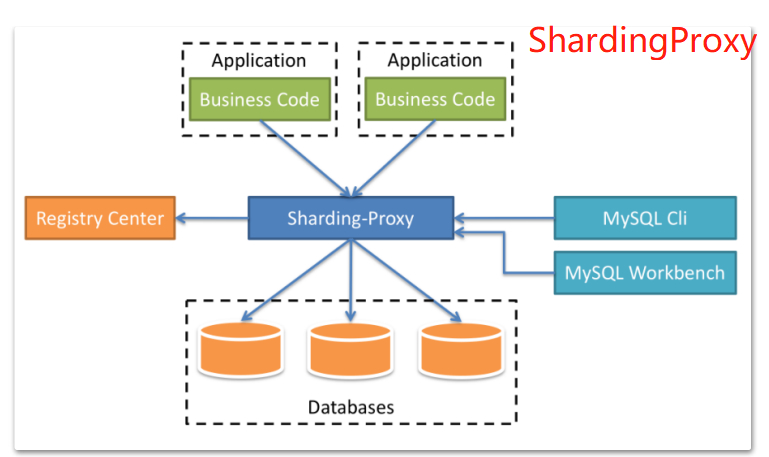 A comparison of the two methods:
A comparison of the two methods:

ShardingJDBC Actual
The core function of shardingjdbc is data fragmentation and read-write separation. With ShardingJDBC, applications can use JDBC transparently to access multiple data sources that have been separated from each other, regardless of the number of data sources and how the data is distributed.
Core concepts:
-
Logical table: General name for the same logical and data structure tables of a horizontally split database
-
Logical table: General name for the same logical and data structure tables of a horizontally split database
-
Data node: The smallest unit of data fragmentation. Composed of data source name and data table
-
Binding table: The primary and subtables with consistent slicing rules.
-
Broadcast table: Also known as a public table, refers to a table that exists in an existing fragmented data source. The structure of the table and the data in the table are identical in each database. For example, a dictionary table.
-
Slicing key: A database field used for splitting is a key field that splits a database (table) horizontally. Without a fragmented field in SQL, full routing will be performed and performance will be poor.
-
Partitioning algorithm: Partitioning data by a partitioning algorithm that supports partitioning by=, BETWEEN, and IN. The slicing algorithm needs to be implemented by the application developer himself and has a very high degree of flexibility.
-
Fragmentation strategy: The real use for fragmentation is the fragmentation key + fragmentation algorithm, which is the fragmentation strategy. Groovy expression-based inline fragmentation strategy is commonly used in HardingJDBC to formulate a fragmentation strategy through an algorithmic expression containing a fragmentation key, such as t_ User_$-> {u_id%8} Identity is based on u_ ID module 8, divided into eight tables with the name t_user_0 to t_user_7. *
Code description for project demo
Introduce related dependencies
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.1.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.22</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
</dependencies>Write startup classes
/**
*Startup Class
*/
@MapperScan("com.lxx.sharding.mapper")
@SpringBootApplication
public class ShardingJDBCApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingJDBCApplication.class,args);
}
}Write the application. Files for properties
spring.shardingsphere.datasource.names=m1
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/test?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=Password
#True table distribution, course_of m1 Library 1 or course_ Table of 2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course_$->{1..2}
#Primary Key Generation Policy
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.props.worker.id=1
#Use cid column of table as slicing rule
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
#Value of cid column%2+1, or equal to 1, select course_1 table, equal to 2 select course_2 tables
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid%2+1}
spring.shardingsphere.props.sql.show = true
spring.main.allow-bean-definition-overriding=trueWriting test classes
/**
* Increase course table data
*/
@Test
public void addCourse(){
for(int i = 0 ; i < 10 ; i ++){
Course c = new Course();
c.setCname("shardingsphere");
c.setUserId(Long.valueOf(""+(1000+i)));
c.setCstatus("1");
courseMapper.insert(c);
}
}Data course_after execution Data of 1 and course_2 Data
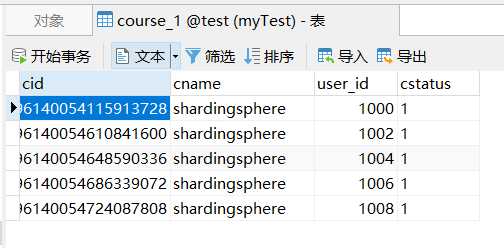
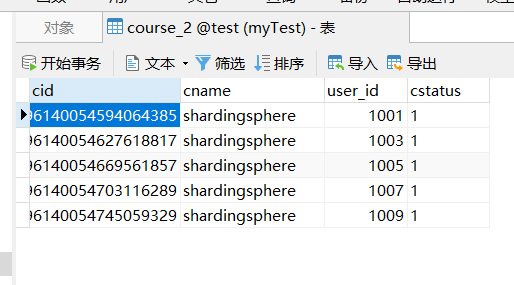
More complex query statements can use a slicing strategy
Four fragmentation strategies are supported: inline, standard, complex, hint. All four are in application. Properrties configuration implementation classes are: 1, table selection implementation class, 2, library selection implementation class. The main function of self-written implementation classes is to return which tables and libraries are involved in the query statement, return list <table name>, list <library name>. ShardingJDBC encapsulates queries based on returned table and library names.
Here is a profile of the strategies in these 4:
spring.shardingsphere.datasource.names=m1,m2
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/test?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=Password
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://localhost:3306/test2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=Password
#True table distribution, repository, sub-table
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{1..2}.course_$->{1..2}
#Primary Key Generation Policy
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.props.worker.id=1
#=================================================The above configuration is a regular configuration, and the following four fragmentation strategies are configured======================
#The fragmentation strategy supports inline, standard, complex, hint (mandatory routing)
# Complex queries can support multiple column conditions, such as: select * from course where cid in (?,?) and user_id =? Or IN.
#The main function of self-written implementation classes is to return which tables and libraries are involved in the query statement, return list <table name>, list <library name>,
#Sharing queries this table and Library Based on the returned table name and library name.
#inline slicing strategy
#table Tables Policy
#Use cid column of table as slicing rule
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
#Value of cid column%2+1, or equal to 1, select course_1 table, equal to 2 select course_2 tables
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid%2+1}
#A repository strategy means almost the same thing as a table strategy: which table to select and which library to select
spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=m$->{cid%2+1}
#Standard standard fragmentation strategy
#table Tables Policy
spring.shardingsphere.sharding.tables.course.table-strategy.standard.sharding-column=cid
#Define a precise class, which returns which table to select and which logical user to implement
spring.shardingsphere.sharding.tables.course.table-strategy.standard.precise-algorithm-class-name=com.roy.shardingDemo.algorithem.MyPreciseTableShardingAlgorithm
#Defines a class of range (range query), which returns which list <table> to select and which logical user to implement
spring.shardingsphere.sharding.tables.course.table-strategy.standard.range-algorithm-class-name=com.roy.shardingDemo.algorithem.MyRangeTableShardingAlgorithm
#database repository policy
spring.shardingsphere.sharding.tables.course.database-strategy.standard.sharding-column=cid
#Defines a precise class, which returns which library to select and which logical user to implement
spring.shardingsphere.sharding.tables.course.database-strategy.standard.precise-algorithm-class-name=com.roy.shardingDemo.algorithem.MyPreciseDSShardingAlgorithm
#Define a class of range (range query), which returns which list <library> to select and which logical user to implement
spring.shardingsphere.sharding.tables.course.database-strategy.standard.range-algorithm-class-name=com.roy.shardingDemo.algorithem.MyRangeDSShardingAlgorithm
#complex Complex Fragmentation Strategy
spring.shardingsphere.sharding.tables.course.table-strategy.complex.sharding-columns= cid, user_id
spring.shardingsphere.sharding.tables.course.table-strategy.complex.algorithm-class-name=com.roy.shardingDemo.algorithem.MyComplexTableShardingAlgorithm
#database repository policy
spring.shardingsphere.sharding.tables.course.database-strategy.complex.sharding-columns=cid, user_id
spring.shardingsphere.sharding.tables.course.database-strategy.complex.algorithm-class-name=com.roy.shardingDemo.algorithem.MyComplexDSShardingAlgorithm
#hint mandatory routing policy
spring.shardingsphere.sharding.tables.course.table-strategy.hint.algorithm-class-name=com.roy.shardingDemo.algorithem.MyHintTableShardingAlgorithm
spring.shardingsphere.props.sql.show = true
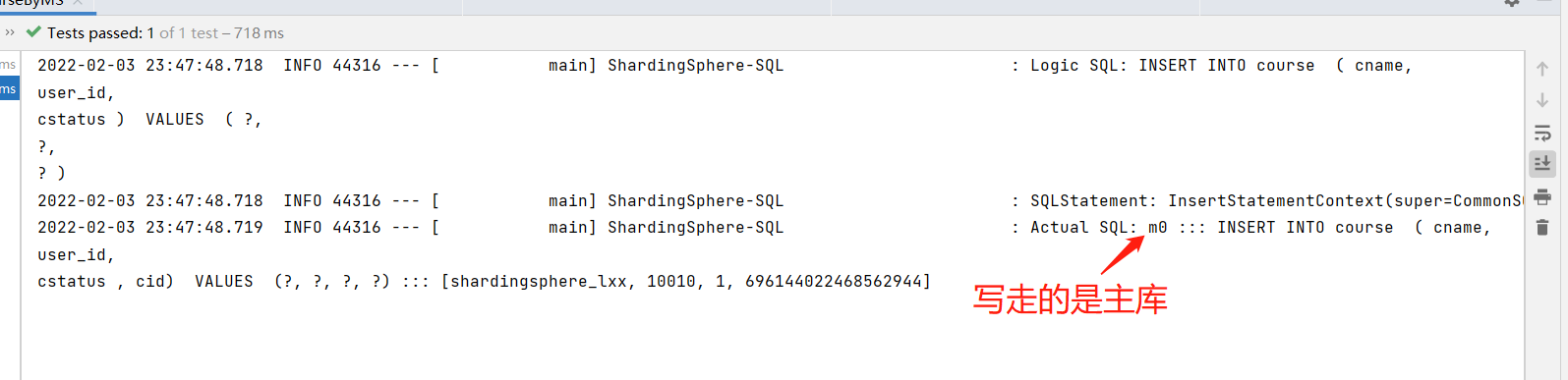
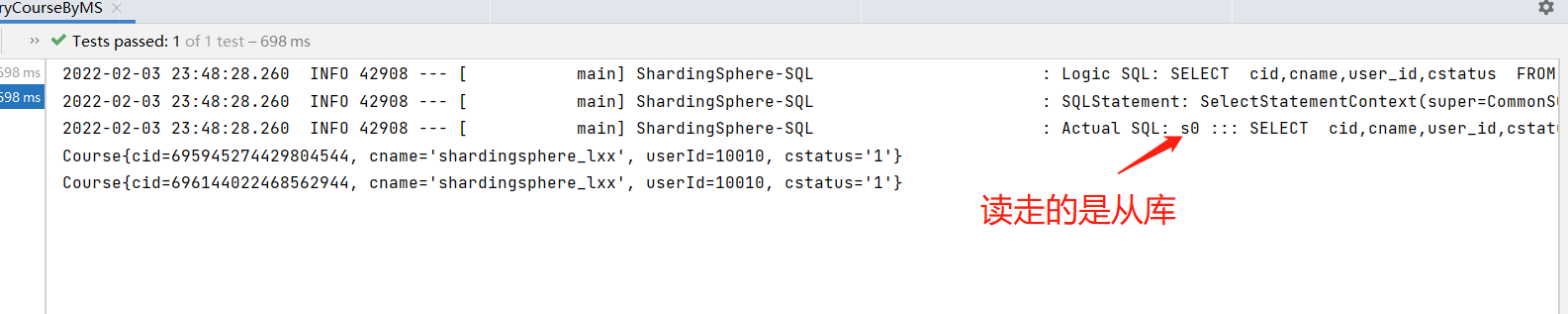
spring.main.allow-bean-definition-overriding=trueCode Interpretation with Separation of Read and Write
Write the application. Files for properties
#Configure master-slave data sources based on MySQL master-slave architecture. spring.shardingsphere.datasource.names=m0,s0 spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/test?serverTimezone=GMT%2B8 spring.shardingsphere.datasource.m0.username=root spring.shardingsphere.datasource.m0.password=Password spring.shardingsphere.datasource.s0.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.s0.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.s0.url=jdbc:mysql://192.168.1.128:3306/test?serverTimezone=GMT%2B8 spring.shardingsphere.datasource.s0.username=root spring.shardingsphere.datasource.s0.password=Password #Read-Write Separation Rules, m0 Master Library, s0 Slave Library spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0 spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names[0]=s0 #Table Slicing Based on read-write separation spring.shardingsphere.sharding.tables.course.actual-data-nodes=ds0.course #Primary Key Generation Policy spring.shardingsphere.sharding.tables.course.key-generator.column=cid spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE spring.shardingsphere.sharding.tables.course.key-generator.props.worker.id=1 spring.shardingsphere.props.sql.show = true spring.main.allow-bean-definition-overriding=true
Writing test classes
/**
* Read-Write Separation Test, this is Write
*/
@Test
public void addCourseByMS(){
Course c = new Course();
c.setCname("shardingsphere_lxx");
c.setUserId(Long.valueOf(""+(10010)));
c.setCstatus("1");
courseMapper.insert(c);
}
/**
* Read-Write Separation Test, this is read
*/
@Test
public void queryCourseByMS(){
List<Course> courses = courseMapper.selectList(null);
courses.forEach(course -> System.out.println(course));
}