In the previous article, we talked about the read-write separation based on Mysql8 (there is a link at the end of the article). This time, we talked about the implementation process of the sub database and sub table.
conceptual analysis
Vertical fragmentation
According to the way of business split, it is called vertical split, also known as vertical split. Its core idea is dedicated to the special library. Before splitting, a database consists of multiple data tables, each of which corresponds to different businesses. After splitting, tables are classified according to the business and distributed to different databases, thus spreading the pressure to different databases. The following figure shows the scheme of vertically slicing user tables and order tables into different databases according to business needs.
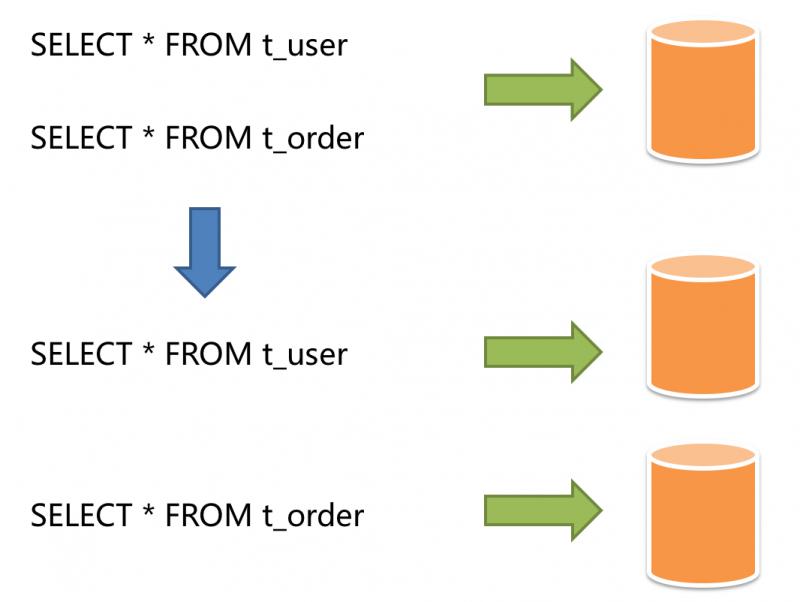
Vertical segmentation often needs to adjust the architecture and design. Generally speaking, it's too late to cope with the rapid change of Internet business demand; moreover, it can't really solve the single bottleneck. Vertical splitting can alleviate the problems caused by data volume and access volume, but it can not be cured. If the amount of data in the table still exceeds the threshold that a single node can carry after vertical splitting, horizontal splitting is needed for further processing.
Horizontal fragmentation
Horizontal segmentation is also called horizontal splitting. Compared with vertical segmentation, it no longer classifies data according to business logic, but disperses data into multiple databases or tables through a certain field (or several fields) according to a certain rule, and each segmentation only contains a part of data. For example: according to the partition of primary keys, the records of even primary keys are put into library 0 (or table), and the records of odd primary keys are put into library 1 (or table), as shown in the following figure.
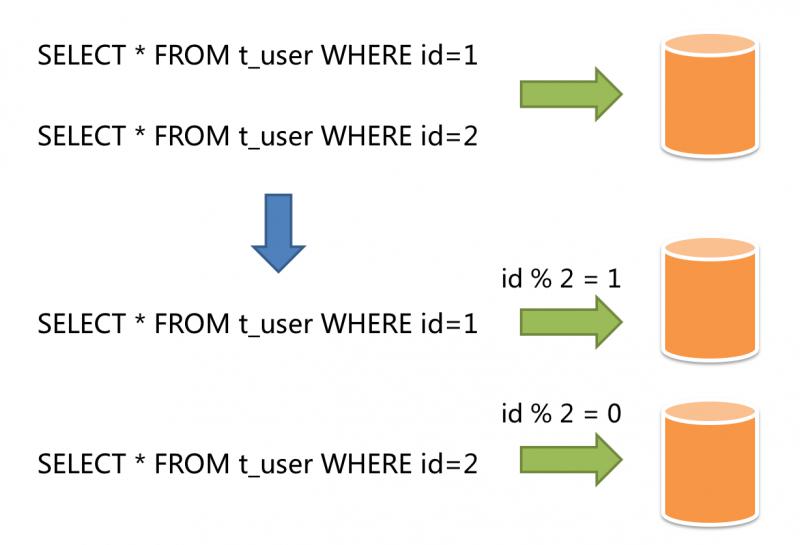
In theory, horizontal sharding breaks through the bottleneck of single machine data processing, and expands relatively freely, which is the standard solution of sub database and sub table.
Preparation for development
Shardingsphere is a common component of database and table splitting. It is already the top-level project of apache. This time, we use springboot2.1.9 + shardingsphere 4.0.0-rc2 (all the latest versions) to complete the operation of database and table splitting.
Suppose there is an order table, we need to divide it into two databases, three tables for each database, and determine the location of the final data according to the id field. The database environment is configured as follows:
- 172.31.0.129
- blog
- t_order_0
- t_order_1
- t_order_2
- blog
- 172.31.0.131
- blog
- t_order_0
- t_order_1
- t_order_2
- blog
The logical table of the three tables is t [order]. You can prepare all other data tables according to the table creation statement.
DROP TABLE IF EXISTS `t_order_0; CREATE TABLE `t_order_0` ( `id` bigint(20) NOT NULL, `name` varchar(255) DEFAULT NULL COMMENT 'Name', `type` varchar(255) DEFAULT NULL COMMENT 'type', `gmt_create` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Creation time', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
Note that you must not set the generation rule of primary key to self growth. You need to generate primary key according to certain rules. Here, we use SNOWFLAKE algorithm in shardingsphere to generate primary key.
code implementation
- Modify pom.xml and introduce related components
<properties>
<java.version>1.8</java.version>
<mybatis-plus.version>3.1.1</mybatis-plus.version>
<sharding-sphere.version>4.0.0-RC2</sharding-sphere.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>- Configure MySQL plus
@Configuration
@MapperScan("com.github.jianzh5.blog.mapper")
public class MybatisPlusConfig {
/**
* Attack SQL block resolver
*/
@Bean
public PaginationInterceptor paginationInterceptor(){
PaginationInterceptor paginationInterceptor = new PaginationInterceptor();
List<ISqlParser> sqlParserList = new ArrayList<>();
sqlParserList.add(new BlockAttackSqlParser());
paginationInterceptor.setSqlParserList(sqlParserList);
return new PaginationInterceptor();
}
/**
* SQL Execution efficiency plug-in
*/
@Bean
// @Profile({"dev","test"})
public PerformanceInterceptor performanceInterceptor() {
return new PerformanceInterceptor();
}
}- Write entity class Order
@Data
@TableName("t_order")
public class Order {
private Long id;
private String name;
private String type;
private Date gmtCreate;
}- Write DAO layer, OrderMapper
/**
* Order Dao layer
*/
public interface OrderMapper extends BaseMapper<Order> {
}- Programming interface and interface implementation
public interface OrderService extends IService<Order> {
}
/**
* Order fulfillment layer
* @author jianzh5
* @date 2019/10/15 17:05
*/
@Service
public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements OrderService {
}- Configuration file (see note for configuration description)
server.port=8080
# Configure ds0 and ds1 data sources
spring.shardingsphere.datasource.names = ds0,ds1
#ds0 configuration
spring.shardingsphere.datasource.ds0.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url = jdbc:mysql://192.168.249.129:3306/blog?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.shardingsphere.datasource.ds0.username = root
spring.shardingsphere.datasource.ds0.password = 000000
#ds1 configuration
spring.shardingsphere.datasource.ds1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url = jdbc:mysql://192.168.249.131:3306/blog?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.shardingsphere.datasource.ds1.username = root
spring.shardingsphere.datasource.ds1.password = 000000
# The sub database strategy determines which database the data enters according to the id modulus
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column = id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression = ds$->{id % 2}
# Specific tabulation strategy
# Nodes ds0.t-order-0, ds0.t-order-1, ds1.t-order-0, ds1.t-order-1
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = ds$->{0..1}.t_order_$->{0..2}
# Sub table field id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column = id
# The table splitting strategy takes the modulus according to the id to determine which table the data will ultimately fall in.
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression = t_order_$->{id % 3}
# Generate primary key using SNOWFLAKE algorithm
spring.shardingsphere.sharding.tables.t_order.key-generator.column = id
spring.shardingsphere.sharding.tables.t_order.key-generator.type = SNOWFLAKE
#spring.shardingsphere.sharding.binding-tables=t_order
spring.shardingsphere.props.sql.show = true- Write unit tests to see if the results are correct
public class OrderServiceImplTest extends BlogApplicationTests {
@Autowired
private OrderService orderService;
@Test
public void testSave(){
for (int i = 0 ; i< 100 ; i++){
Order order = new Order();
order.setName("Computer"+i);
order.setType("To work in an office");
orderService.save(order);
}
}
@Test
public void testGetById(){
long id = 1184489163202789377L;
Order order = orderService.getById(id);
System.out.println(order.toString());
}
}Check the data in the data table and confirm that the data is inserted normally.
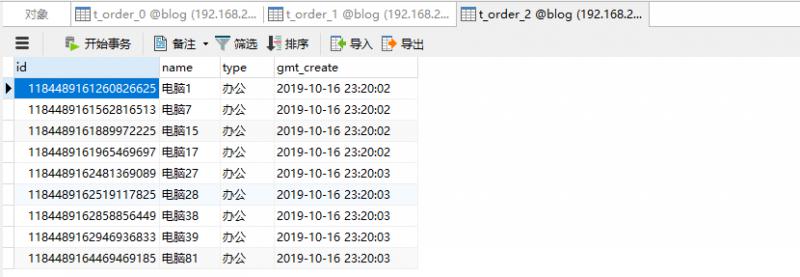
So far, the development of sub database and sub table has been completed.
Past review
Welcome to my personal public number: JAVA Nikki