1. Merge two rowsets
Tables may not have the same field columns, but their corresponding columns must have the same data type and the same number of columns,
select ename, deptno from emp union all select '-----', null from t1 union all select dname, deptno from dept;
Wrong writing, wrong type,
select deptno from emp union all select ename from emp;
Wrong number of columns,
select deptno, dname from dept union select deptno from emp;
The difference between UNION and UNION ALL is,
UNION ALL does not filter duplicates, UNION filters duplicates.
Therefore, UNION may perform a sort operation to remove duplicates. This consumption needs to be considered when dealing with large result sets.
UNION is equivalent to performing a DISTINCT on the result of UNION ALL,
select distinct deptno from ( select deptno from emp union all select deptno from dept);
Do not use DISTINCT unless required by the scene.
Do not use UNION instead of UNION ALL unless required by the scene.
2. Merge related lines
If there is no connection condition for table Association, all possible row combinations will be listed, that is, Cartesian product will be generated,
select a.ename, d.loc from emp a, dept d;
If it is not the special needs of the scene, the Cartesian product of table connection should be avoided.
Equal connections in inner connections,
select a.ename, d.loc from emp a, dept d where a.deptno = d.deptno;
The JOIN clause can be used explicitly, and INNER is optional,
select a.ename, d.loc
from emp a inner join dept d
on (a.deptno = d.deptno);Both styles comply with ANSI standards. If you are used to writing JOIN logic in the FROM clause instead of the WHERE clause, you can use the JOIN clause.
From the perspective of readability, it will be more understandable if the association conditions are written in the ON clause and the filter conditions are written in the WHERE clause when the table is associated.
3. Find the same row in two tables
WHERE Association,
select e.empno, e.ename from emp e, dept d where e.deptno = d.deptno and e.sal = d.sal;
JOIN Association,
select e.empno, e.ename from emp e join dept d on (e.deptno = d.deptno and e.sal = d.sal);
INTERSECT Association,
select empno, ename from emp where (deptno, sal) in ( select deptno, sal from emp interset select deptno, sal from dept );
Set operation INTERSECT returns the same part of two rowsets, but it must ensure that the number of columns compared between the two tables is the same and the data types are the same. When performing set operation, duplicate items will not be returned by default.
4. Find data that only exists in one table
DB2,PG,
select deptno from dept except select deptno from emp;
Oralce,
select deptno from dept minus select deptno from emp;
MySQL,SQL Server,
select deptno from dept where deptno not in (select deptno from emp);
The excel and MINUS functions do not return duplicates, and NULL values do not cause problems.
In the form of NOT IN, you will get emp all deptnos, and the outer query will return the deptno value in the "not present in" or "not included in" sub query result set in the dept table. You need to consider the filtering operation of duplicates. If deptno is the primary key, it does not need to be changed. If not, you need to use DISTINCT to ensure that each missing deptno value in the emp table appears only once, as shown below,
select distinct deptno from dept where deptno not in (select deptno from emp);
However, when using NOT IN, you may need to pay attention to NULL values, because IN and NOT IN are essentially OR operations. However, due to the different ways IN which NULL values participate IN OR logical operations, IN and NOT IN will produce different results.
Do an experiment and test the table. The records of t01 are 10, 20 and 30, and the records of t02 are 10, 50 and null,
SQL> select * from t01;
ID
----------
10
20
30
SQL> select * from t02;
ID
----------
10
50IN operation,
SQL> select * from t01 where id in (10, 50, null);
ID
----------
10
SQL> select * from t01 where (id=10 or id=50 or id=null);
ID
----------
10NOT IN operation,
SQL> select * from t01 where id not in (10, 50, null); no rows selected SQL> select * from t01 where not (id=10 or id=50 or id=null); no rows selected
Because TRUE or NULL returns TRUE, but FALSE or NULL returns NULL, you should pay attention to whether NULL value will be involved when using IN and OR.
In order to avoid the problems caused by NOT IN and NULL values, NOT EXISTS and associated subqueries can be used together. Associated sub query refers to that the result set of the outer query is referenced by the inner sub query.
SQL> select * from t01
where not exists (select null from t02 where t01.id = t02.id);
ID
----------
30
20His logic is,
(1) Execute a sub query to check whether the id of the current t01 exists in t02.
(2) If the result of the fruit query is returned to the outer query, the result of EXISTS is TRUE and NOT EXISTS is FALSE. In this way, the outer query will discard the current row.
(3) If the fruit query does not return any results, the result of NOT EXISTS is TRUE, so the outer query will return the current row (because it is a record that does not exist in t02).
When EXISTS/NOT EXISTS is used with associated subqueries, the columns in SELECT are not important. The reason why NULL is used is to focus attention on the join operation of subqueries rather than the columns of SELECT.
5. Retrieve rows from one table that are not related to another table
Connect the two tables based on the common column to return all rows of one table, regardless of whether there are matching rows in the other table. Then, only these mismatched rows can be stored.
select d.*
from dept d left outer join emp e
on (d.deptno = e.deptno)
where e.deptno is null;P. S. the keyword OUTER is optional.
For Oracle # 9i +, you can use the syntax of special external connection. For Oracle # 8i, you can only use this special syntax,
select d.* from dept d left outer join emp e on d.deptno = e.deptno (+) where e.deptno is null;
This operation is sometimes called anti join.
6. Add a connection query without affecting other connection queries
If it is DB2, MySQL, PG, SQL Server, Oracle 9i or above, it can be used,
select e.ename, d.loc, eb.received from emp e join dept d on (e.deptno = d.deptno) left join emp_bonus eb on (e.empno = eb.empno) order by 2;
In the case of Oracle 8i, you can use,
select e.ename, d.loc, eb.received from emp e, dept d, emp_bonus eb where e.deptno = d.deptno and e.empno = eb.empno(+) order by 2;
You can also use scalar subqueries (which are placed in the SELECT list) to imitate external connections. Scalar subqueries are suitable for all databases,
select e.ename, d.loc,
(select eb.received from emp_bonus eb
where eb.empno = e.empno) as received
from emp e, dept d
where e.deptno = d.deptno
order by 2;An outer join query returns all rows in one table and matching rows in another table. Scalar subquery does not need to change the correct join operation in the main query. It is the best scheme to add new data to the existing query. However, when using a scalar subquery, you must ensure that the scalar value (single value) is returned, and multiple rows cannot be returned.
7. Determine whether the two tables have the same data
You can use the difference set (MINUS or excel), and you can also compare the number of rows separately before comparing the data,
select count(*) from emp union select count(*) from dept;
Because the UNION clause will filter duplicates. If the number of rows in two tables is the same, only one row of data will be returned. If two rows are returned, it means that there is no exactly the same data in the two tables.
8. Identify and eliminate Cartesian product
In order to eliminate the Cartesian product, the n-1 rule is usually used, where n represents the number of tables in the FROM clause, and n-1 represents the minimum number of link queries necessary to eliminate the Cartesian product.
Cartesian product is often used to transform or expand (merge) result sets, generate a series of values, and simulate loop loops.
9. Combination of applicable join query and aggregate function
If the join query produces duplicate rows, there are usually two ways to use the aggregate function,
(1) When calling the aggregate function, the keyword DISTINCT is used, and each value will remove the duplicates before participating in the calculation.
(2) Perform aggregation operation (embedded view) before connection query to avoid wrong results, because aggregation operation occurs before connection query.
MySQL and PG, using DISTINCT to calculate payroll,
select deptno,
sum(distinct sal) as total_sal,
sum(bonus) as total_bonus
from (
select e.empno,
e.ename,
e.sql,
e.deptno,
e.sql * case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3
end as bonus
from emp e, emp_bonus eb
where e.empno = eb.empno
and e.deptno = 10
) x
group by deptno;In addition to the above operations, DB2, Oracle and SQL Server can also use the window function sum over,
select distinct deptno, total_sal, otal_bonus
from (
select e.empno,
e.ename,
sum(distinct e.sal) over
(partition by e.deptno) as total_sal,
e.deptno,
sum(e.sql * case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3) over
(partition by deptno) as total_bonus
from emp e, emp_bonus eb
where e.empno = eb.empno
and e.deptno = 10
) x;The second solution is to calculate the total salary of employees first, and then connect the table. The following statement applies to all databases,
select e.deptno,
d.total_sal,
sum(e.sal * case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3) as total_bonus
from emp e,
emp_bonus eb,
(
select deptno, sum(sal) as total_sal
from emp
where deptno = 10
group by deptno
) d
where e.deptno = d.deptno
and e.empno = eb.empno
group by d.deptno, d.total_sal;In addition to the above operations, DB2, Oracle and SQL Server can also use the window function sum over,
select e.deptno,
d.total_sal,
sum(distinct e.sal) over
(partition by e.deptno) as total_sal,
e.deptno,
sum(e.sal * case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3) over
(partition by deptno) as total_bonus
from emp e, emp_bonus eb,
where e.empno = eb.empno
and e.deptno = 10;10. Combine external join query and aggregate function
If only part of the employees with department number 10 have bonus, if they are only fully connected, the employees without bonus may be omitted. In this case, the external connection should be used to include all employees, and the duplicate items of the employee with department number 10 should be removed, as shown below,
select deptno,
sum(distinct sal) as total_sal,
sum(bonus) as total_bonus
from (
select e.empno,
e.ename,
e.sql,
e.deptno,
e.sql * case when eb.type is null then 0
when eb.type = 1 then .1
when eb.type = 2 then .2
else .3 end as bonus
from emp e left outer join emp_bonus eb
on (e.empno = eb.empno)
where e.deptno = 10
)
group by deptno;You can also use the window function sum over,
select distinct deptno, total_sal, otal_bonus
from (
select e.empno,
e.ename,
sum(distinct e.sal) over
(partition by e.deptno) as total_sal,
e.deptno,
sum(e.sql * case when eb.type is null then 0
when eb.type = 1 then .1
when eb.type = 2 then .2
else .3) over
(partition by deptno) as total_bonus
from emp e left outer join emp_bonus eb
on (e.empno = eb.empno)
where e.deptno = 10
) x;For Oracle, you can also use the proprietary external connection syntax,
select distinct deptno, total_sal, otal_bonus
from (
select e.empno,
e.ename,
sum(distinct e.sal) over
(partition by e.deptno) as total_sal,
e.deptno,
sum(e.sql * case when eb.type is null then 0
when eb.type = 1 then .1
when eb.type = 2 then .2
else .3) over
(partition by deptno) as total_bonus
from emp e, emp_bonus eb
where e.empno = eb.empno(+)
and e.deptno = 10
)
group by deptno;If you calculate the payroll of employee No. 10 and connect the two tables, you avoid using external connection, as shown below,
select e.deptno,
d.total_sal,
sum(e.sal * case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3) as total_bonus
from emp e,
emp_bonus eb,
(
select deptno, sum(sal) as total_sal
from emp
where deptno = 10
group by deptno
) d
where e.deptno = d.deptno
and e.empno = eb.empno
group by d.deptno, d.total_sal;11. Missing values returned from multiple tables
Using global join, the missing value is returned from two tables based on a common value. Global join query is to merge the result set of external join query of two tables.
DB2, MySQL, PG and SQL Server can be used,
select d.deptno, d.dname, e.ename
from dept d full outer join emp e
on (d.deptno = e.deptno);You can also merge the query results of two external connections,
select d.deptno, d.dname, e.ename from dept d right outer join emp e on (d.deptno = e.deptno) union select d.deptno, d.dname, e.ename from dept d left outer join emp e on (d.deptno = e.deptno);
If it is Oracle, you can use the proprietary outer connection syntax,
select d.deptno, d.dname, e.ename from dept d, emp e where d.deptno = e.deptno(+) union select d.deptno, d.dname, e.ename from dept d, emp e where d.deptno(+) = e.deptno;
12. Use NULL in operation comparison
NULL is not equal to any value and cannot even be compared with itself, but the data returned from the NULL column is evaluated as if it were a specific value.
The coalesce function can convert NULL into a specific value that can be used for standard evaluation. The coalesce function returns the first non NULL value in the parameter list,
select ename, comm, coalesce(comm, 0) from emp where coalesce(comm, 0) < (select comm from emp where ename = 'WARD');
Some friends may ask, what is the difference between coalesce function and nvl function?
(1) nvl(expr, 0) If the first parameter is null, the second parameter is returned. If the first parameter is non null, the first parameter is returned.
(2) coalesce(expr1, expr2, expr3 ... exprn) Count from left to right. If the first non null value is encountered, the non null value is returned.
It looks like it, but there are some differences,
(1) nvl is only suitable for two parameters, and coalesce is suitable for multiple parameters.
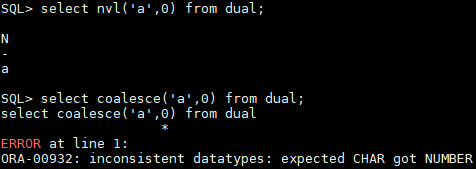
(2) All parameter types in coalesce must be consistent, nvl can be inconsistent, as shown below,
Historical articles in the reading notes of SQL Cookbook: