background
This paper mainly describes the troubleshooting ideas of import problems and the solutions to common problems. Here is a brief description of the processes of different import methods to facilitate everyone to understand the import process and troubleshoot problems. For details, please refer to the documents Import Chapter.
Troubleshooting process
Stream Load
Stream load internal call link
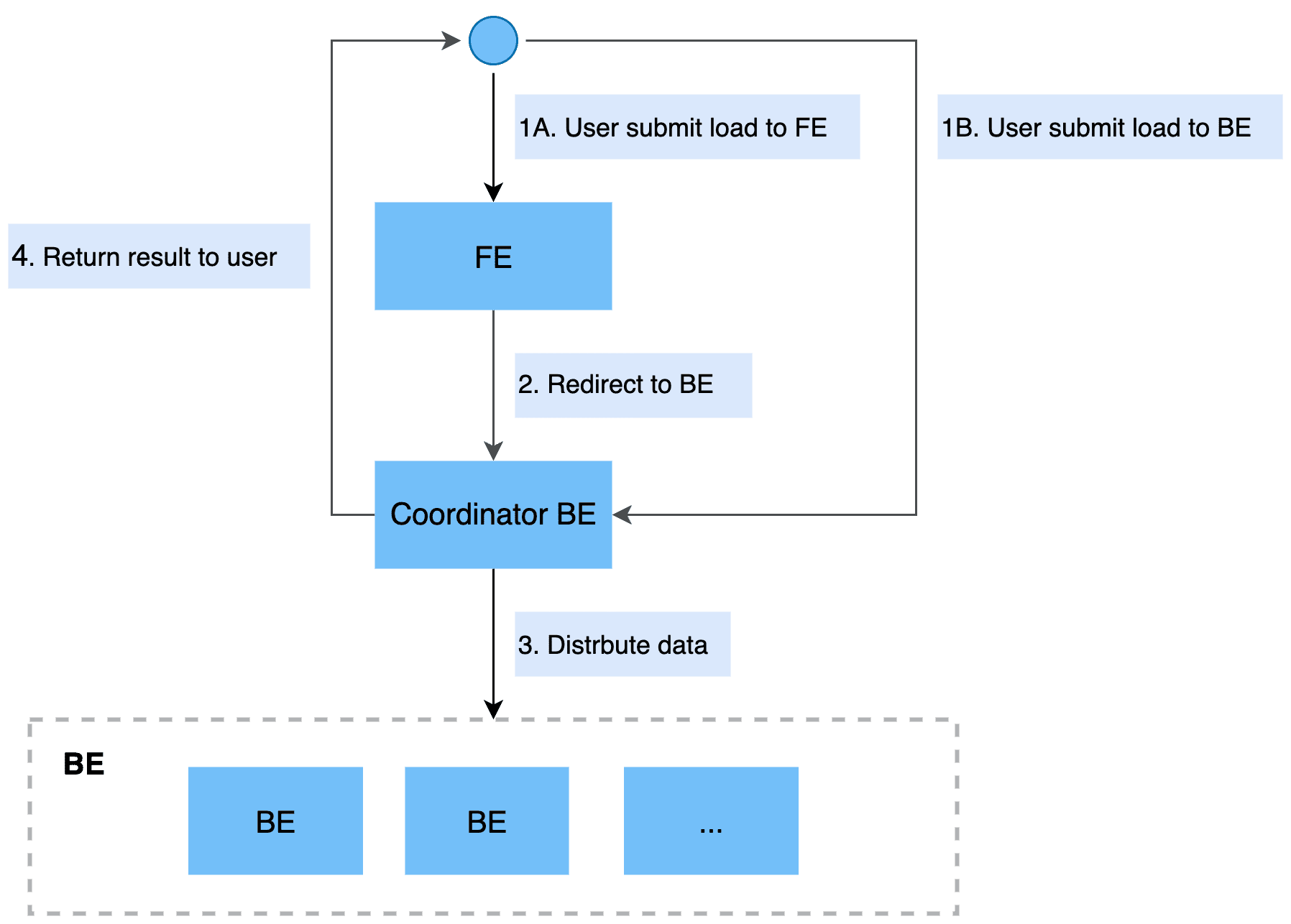
Stream Load is a synchronous import method. The user sends a request through HTTP protocol to import the local file or data stream into StarRocks, and waits for the system to return the import result status, so as to judge whether the import is successful.
Pasting block s outside Docs is not supported
- Judge by return value
{
"Status":"Fail",
"BeginTxnTimeMs":1,
"Message":"too many filtered rows",
"NumberUnselectedRows":0,
"CommitAndPublishTimeMs":0,
"Label":"4682d766-0e53-4fce-b111-56a8d8bef390",
"LoadBytes":69238389,
"StreamLoadPutTimeMs":4,
"NumberTotalRows":7077604,
"WriteDataTimeMs":4350,
"TxnId":33,
"LoadTimeMs":4356,
"ErrorURL":"http://192.168.10.142:8040/api/_load_error_log?file=__shard_2/error_log_insert_stmt_e44ae406-32c7-6d5c-a807-b05607a57cbf_e44ae40632c76d5c_a807b05607a57cbf",
"ReadDataTimeMs":1961,
"NumberLoadedRows":0,
"NumberFilteredRows":7077604
}
- Return value Status: non Success,
a. Error URL exists
Curl errourls, for example
curl "http://192.168.10.142:8040/api/_load_error_log?file=__shard_2/error_log_insert_stmt_e44ae406-32c7-6d5c-a807-b05607a57cbf_e44ae40632c76d5c_a807b05607a57cbf"
b. Error URL does not exist
{
"TxnId":2271727,
"Label":"4682d766-0e53-4fce-b111-56a8d8bef2340",
"Status":"Fail",
"Message":"Failed to commit txn 2271727. Tablet [159816] success replica num 1 is less then quorum replica num 2 while error backends 10012",
"NumberTotalRows":1,
"NumberLoadedRows":1,
"NumberFilteredRows":0,
"NumberUnselectedRows":0,
"LoadBytes":575,
"LoadTimeMs":26,
"BeginTxnTimeMs":0,
"StreamLoadPutTimeMs":0,
"ReadDataTimeMs":0,
"WriteDataTimeMs":21,
"CommitAndPublishTimeMs":0
}
View the imported load_id and scheduled be node
grep -w $TxnId fe.log|grep "load id" #Output example: 2021-12-20 20:48:50,169 INFO (thrift-server-pool-4|138) [FrontendServiceImpl.streamLoadPut():809] receive stream load put request. db:ssb, tbl: demo_test_1, txn id: 1580717, load id: 7a4d4384-1ad7-b798-f176-4ae9d7ea6b9d, backend: 172.26.92.155
Check the specific reason in the corresponding be node
grep $load_id be.WARNING|less
Broker Load
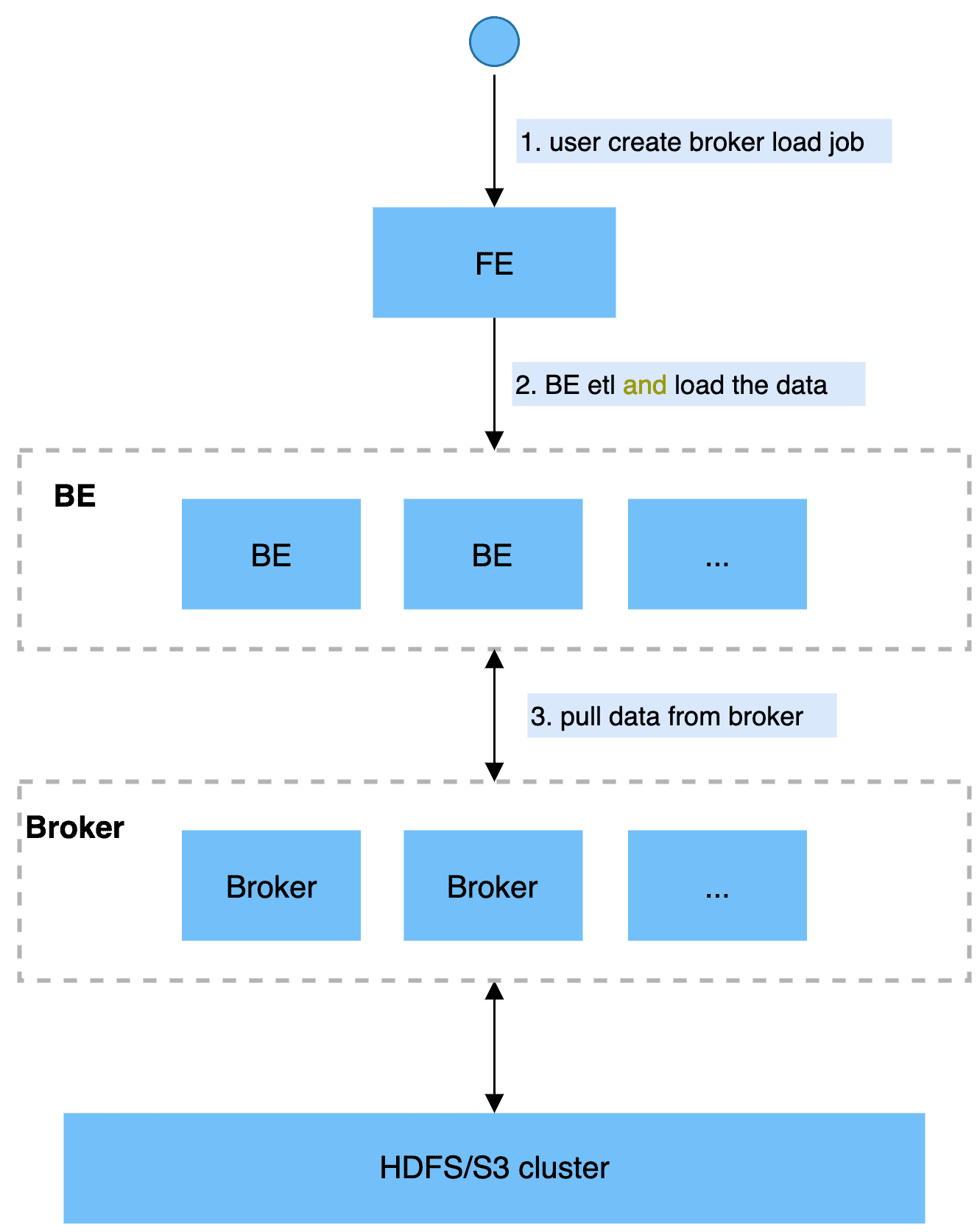
After the user submits the import task, the FE will generate the corresponding Plan and distribute the Plan to multiple BE for execution according to the current number of BE and the size of the file, and each BE will perform part of the import task. BE will pull data through the Broker during execution, and import the data into the system after data preprocessing. After all BE are imported, FE will finally judge whether the import is successful.
Pasting block s outside Docs is not supported
At present, the task process of a Broker Load will go through the process of PENDING – > loading – > finished (or canceled). When the status is canceled, it needs to be involved in troubleshooting.
- Show load check the task status, and follow up when the status is CANCELLED
- If the URL is not empty, use curl $URL to view the specific error information
- If the URL is empty, check the load id and be through the fe log
- Check whether the hdfs file path is specified correctly. It can be specified to specific files or all files in a directory
- hdfs import, please check whether there is k8s authentication and configure it
grep $JobnId fe.log
- View specific exceptions in be
grep $load_id be.INFO
Value of type in ErrorMsg:
-
USER-CANCEL: task cancelled by user
-
ETL-RUN-FAIL: import task failed in ETL phase
-
ETL-QUALITY-UNSATISFIED: the data quality is unqualified, that is, the error data rate exceeds the max filter ratio
-
LOAD-RUN-FAIL: import task failed in LOADING phase
-
TIMEOUT: the import task did not complete within the TIMEOUT
-
UNKNOWN: UNKNOWN import error
Routine Load
+-----------------+
fe schedule job | NEED_SCHEDULE | user resume job
+-----------+ | <---------+
| | | |
v +-----------------+ ^
| |
+------------+ user(system)pause job +-------+----+
| RUNNING | | PAUSED |
| +-----------------------> | |
+----+-------+ +-------+----+
| | |
| | +---------------+ |
| | | STOPPED | |
| +---------> | | <-----------+
| user stop job+---------------+ user stop job
|
|
| +---------------+
| | CANCELLED |
+-------------> | |
system error +---------------+
The figure above shows the task state machine of routine load
show routine load for db.job_name
MySQL [load_test]> SHOW ROUTINE LOAD\G;
*************************** 1. row ***************************
Id: 14093
Name: routine_load_wikipedia
CreateTime: 2020-05-16 16:00:48
PauseTime: 2020-05-16 16:03:39
EndTime: N/A
DbName: default_cluster:load_test
TableName: routine_wiki_edit
State: PAUSED
DataSourceType: KAFKA
CurrentTaskNum: 0
JobProperties: {"partitions":"*","columnToColumnExpr":"event_time,channel,user,is_anonymous,is_minor,is_new,is_robot,is_unpatrolled,delta,added,deleted","maxBatchIntervalS":"10","whereExpr":"*","maxBatchSizeBytes":"104857600","columnSeparator":"','","maxErrorNum":"1000","currentTaskConcurrentNum":"1","maxBatchRows":"200000"}
DataSourceProperties: {"topic":"starrocks-load","currentKafkaPartitions":"0","brokerList":"localhost:9092"}
CustomProperties: {}
Statistic: {"receivedBytes":162767220,"errorRows":132,"committedTaskNum":13,"loadedRows":2589972,"loadRowsRate":115000,"abortedTaskNum":7,"totalRows":2590104,"unselectedRows":0,"receivedBytesRate":7279000,"taskExecuteTimeMs":22359}
Progress: {"0":"13824771"}
ReasonOfStateChanged: ErrorReason{code=errCode = 100, msg='User root pauses routine load job'}
ErrorLogUrls: http://172.26.108.172:9122/api/_load_error_log?file=__shard_54/error_log_insert_stmt_e0c0c6b040c044fd-a162b16f6bad53e6_e0c0c6b040c044fd_a162b16f6bad53e6, http://172.26.108.172:9122/api/_load_error_log?file=__shard_55/error_log_insert_stmt_ce4c95f0c72440ef-a442bb300bd743c8_ce4c95f0c72440ef_a442bb300bd743c8, http://172.26.108.172:9122/api/_load_error_log?file=__shard_56/error_log_insert_stmt_8753041cd5fb42d0-b5150367a5175391_8753041cd5fb42d0_b5150367a5175391
OtherMsg:
1 row in set (0.01 sec)
When the task status is PAUSED or CANCELLED, it is necessary to intervene in the troubleshooting
When the task status is PAUSED:
- You can check ReasonOfStateChanged and locate the reason, such as "Offset out of range"
- If ReasonOfStateChanged is empty, check ErrorLogUrls to view the specific error information
curl ${ErrorLogUrls}
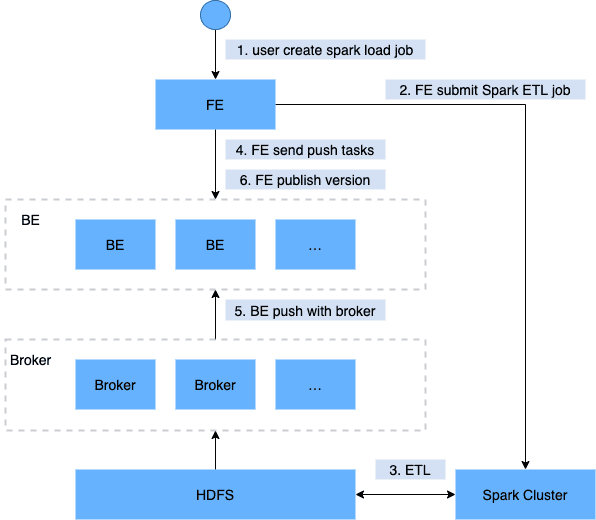
Spark Load
Insert Into
Insert into is also the import method that you encounter many problems at present. Currently, insert into supports the following two methods:
- Method 1: Insert into table values();
- Method 2: Insert into table1 xxx select xxx from table2
Method 1 is not recommended for online use
Since the insert into import method is synchronous, the result will be returned immediately after execution. The import success or failure can be judged by the returned results.
Flink-connector
Writing StarRocks is encapsulated stream load, and the internal process can refer to stream load import
Unable to copy content in load
Since the bottom layer of Flink connector adopts the way of stream load, you can refer to the way of stream load troubleshooting.
- First, search the keyword "_stream_load" from Flink log to confirm that the stream load task has been successfully initiated
- Then check and search the label corresponding to stream load, and search the import result of the label, as shown in the following figure
{
"Status":"Fail",
"BeginTxnTimeMs":1,
"Message":"too many filtered rows",
"NumberUnselectedRows":0,
"CommitAndPublishTimeMs":0,
"Label":"4682d766-0e53-4fce-b111-56a8d8bef390",
"LoadBytes":69238389,
"StreamLoadPutTimeMs":4,
"NumberTotalRows":7077604,
"WriteDataTimeMs":4350,
"TxnId":33,
"LoadTimeMs":4356,
"ErrorURL":"http://192.168.10.142:8040/api/_load_error_log?file=__shard_2/error_log_insert_stmt_e44ae406-32c7-6d5c-a807-b05607a57cbf_e44ae40632c76d5c_a807b05607a57cbf",
"ReadDataTimeMs":1961,
"NumberLoadedRows":0,
"NumberFilteredRows":7077604
}
- Next, refer to the stream load troubleshooting process
Flink-CDC
Writing StarRocks is encapsulated stream load, and the internal process can refer to stream load import
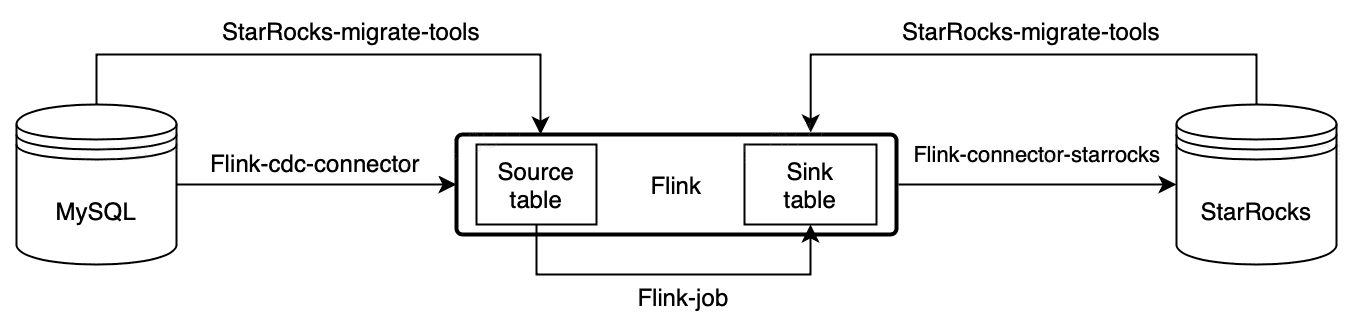
- When the Flink task doesn't report an error
Step 1: confirm whether binlog is enabled. You can use SHOW VARIABLES LIKE 'log_bin 'view;
Step 2: confirm whether the versions of flink, flink CDC, flink starrods connector and MySQL (MySQL version is 5.7 and 8.0.X) meet the requirements. The large versions of flink, flink CDC and flink starrods connector need to be consistent, for example, they are all version 1.13
Step 3: step by step determine whether to check the source table or write starlocks. Here, use the following sql file to demonstrate that the file is Flink-cdc The Flink create generated in step 7 of 1.sql
CREATE DATABASE IF NOT EXISTS `test_db`; CREATE TABLE IF NOT EXISTS `test_db`.`source_tb` ( `id` STRING NOT NULL, `score` STRING NULL, PRIMARY KEY(`id`) NOT ENFORCED ) with ( 'username' = 'root', 'password' = 'xxx', 'database-name' = 'test', 'table-name' = 'test_source', 'connector' = 'mysql-cdc', 'hostname' = '172.26.92.139', 'port' = '8306' ); CREATE TABLE IF NOT EXISTS `test_db`.`sink_tb` ( `id` STRING NOT NULL, `score` STRING NULL PRIMARY KEY(`id`) NOT ENFORCED ) with ( 'load-url' = 'sr_fe_host:8030', 'sink.properties.row_delimiter' = '\x02', 'username' = 'root', 'database-name' = 'test_db', 'sink.properties.column_separator' = '\x01', 'jdbc-url' = 'jdbc:mysql://sr_fe_host:9030', 'password' = '', 'sink.buffer-flush.interval-ms' = '15000', 'connector' = 'starrocks', 'table-name' = 'test_tb' ); INSERT INTO `test`.`sink_tb` SELECT * FROM `test_db`.`source_tb`;
Execute the following statement under the installed Flink directory to enter Flink SQL
bin/sql-client.sh
First, verify whether reading the source table is normal
#Paste in the above sql to determine whether it is the problem of querying the source table or writing to starrocks CREATE DATABASE IF NOT EXISTS `test_db`; CREATE TABLE IF NOT EXISTS `test_db`.`source` ( `id` STRING NOT NULL, `score` STRING NULL, PRIMARY KEY(`id`) NOT ENFORCED ) with ( 'username' = 'root', 'password' = 'xxx', 'database-name' = 'test', 'table-name' = 'test_source', 'connector' = 'mysql-cdc', 'hostname' = '172.26.92.139', 'port' = '8306' ); #Verify whether the source is normal select * from `test_db`.`source_tb`;
Then verify whether writing to starrocks is normal
CREATE TABLE IF NOT EXISTS `test_db`.`sink_tb` ( `id` STRING NOT NULL, `score` STRING NULL PRIMARY KEY(`id`) NOT ENFORCED ) with ( 'load-url' = 'sr_fe_host:8030', 'sink.properties.row_delimiter' = '\x02', 'username' = 'root', 'database-name' = 'test_db', 'sink.properties.column_separator' = '\x01', 'jdbc-url' = 'jdbc:mysql://sr_fe_host:9030', 'password' = '', 'sink.buffer-flush.interval-ms' = '15000', 'connector' = 'starrocks', 'table-name' = 'test_tb' ); INSERT INTO `test`.`sink_tb` SELECT * FROM `test_db`.`source_tb`;
- Flink task error
Step 1: confirm whether the flink cluster is started. Some students may not start the flink downloaded locally, so you need to/ bin/start-cluster.sh start the next flick
Step 2: make specific analysis according to specific error reports
DataX
Writing StarRocks is encapsulated stream load, and the internal process can refer to stream load import
Unable to copy content in load
Since the bottom layer of DataX also adopts the stream load method, you can refer to the stream load troubleshooting method.
- Start with dataX / log / yyyy MM DD / xxx Search the keyword "_stream_load" in the log to confirm that the stream load task has been successfully initiated
A. If no stream load is generated, please check dataX / log / yyyy MM DD / xxx Log, analyze and solve exceptions
B. If stream load is generated, it can be found in dataX / log / yyyy MM DD / xxx Log search the label corresponding to stream load, and search the import result of the label, as shown in the following figure
{
"Status":"Fail",
"BeginTxnTimeMs":1,
"Message":"too many filtered rows",
"NumberUnselectedRows":0,
"CommitAndPublishTimeMs":0,
"Label":"4682d766-0e53-4fce-b111-56a8d8bef390",
"LoadBytes":69238389,
"StreamLoadPutTimeMs":4,
"NumberTotalRows":7077604,
"WriteDataTimeMs":4350,
"TxnId":33,
"LoadTimeMs":4356,
"ErrorURL":"http://192.168.10.142:8040/api/_load_error_log?file=__shard_2/error_log_insert_stmt_e44ae406-32c7-6d5c-a807-b05607a57cbf_e44ae40632c76d5c_a807b05607a57cbf",
"ReadDataTimeMs":1961,
"NumberLoadedRows":0,
"NumberFilteredRows":7077604
}
- Next, refer to the stream load troubleshooting process
common problem
- "Failed to commit txn 2271727. Tablet [159816] success replica num 1 is less then quorum replica num 2 while error backends 10012",
The specific cause of this problem needs to follow the above troubleshooting process in be View specific exceptions in warning
- close index channel failed/too many tablet versions
The import frequency is too fast, and the compaction fails to merge in time, resulting in too many versions. The default version is 1000
Reduce the frequency, adjust the compaction strategy and speed up the merging (after adjusting, you need to observe the memory and io) Modify the following in conf
base_compaction_check_interval_seconds = 10 cumulative_compaction_num_threads_per_disk = 4 base_compaction_num_threads_per_disk = 2 cumulative_compaction_check_interval_seconds = 2
- Reason: invalid value '202123098432'.
The type of a column in the import file is inconsistent with that in the table
- the length of input is too long than schema
The length of a column in the import file is incorrect. For example, the fixed length string exceeds the length set by the table creation, and the int type field exceeds 4 bytes.
- actual column number is less than schema column number
After a line of the import file is divided according to the specified separator, the number of columns is less than the specified number of columns, which may be due to the incorrect separator.
- actual column number is more than schema column number
After a line of the import file is divided according to the specified separator, the number of columns is greater than the specified number of columns, which may be due to the incorrect separator.
- the frac part length longer than schema scale
The decimal part of a decimal column in the import file exceeds the specified length.
- the int part length longer than schema precision
The integer part of a decimal column in the import file exceeds the specified length.
- the length of decimal value is overflow
The length of a decimal column in the import file exceeds the specified length.
- There is no corresponding partition for this key
The value of the partition column of a row in the imported file is not within the partition range.
- Caused by: org.apache.http.ProtocolException: The server failed to respond with a valid HTTP response
The Stream load port is incorrectly configured. It should be http_port
- flink demo, the test library table is established as required, and then the program does not have any error log, and the data cannot sink in. What is the troubleshooting idea
It may be due to the inability to access be. The stream load encapsulated by the current flash, fe will redirect $be: $HTTP after receiving the request_ Port. Generally, when debugging locally, you can access fe+http_port, but be + HTTP cannot be accessed_ Port, need to open access be+http_port firewall
- Transaction commit successfully,But data will be visible later
This status also indicates that the import has been completed, but the data may be delayed from being visible. The reason is that some publish times out. You can also turn up fe to configure publish_version_timeout_second
- get database write lock timeout
It may be that the number of threads of fe exceeds. It is suggested to adjust the be configuration: thrift_rpc_timeout_ms=10000 (default: 5000ms)
- failed to send batch or TabletWriter add batch with unknown id
Please refer to the chapter import Overview / general system configuration / BE configuration and modify query appropriately_ Timeout and streaming_load_rpc_max_alive_time_sec
- LOAD-RUN-FAIL; msg:Invalid Column Name:xxx
- If the data is in Parquet or ORC format, it is necessary to keep the column name of the file header consistent with the column name in the StarRocks table, such as:
(tmp_c1,tmp_c2) SET ( id=tmp_c2, name=tmp_c1 )
Indicates that the column with (tmp_c1, tmp_c2) as the column name in Parquet or ORC file is mapped to the (id, name) column in StarRocks table. If set is not set, the column in column is used as the mapping.
Note: if you use ORC files directly generated by some Hive versions, the header in the ORC file is not Hive meta data, but
(_col0, _col1, _col2, ...) , which may lead to Invalid Column Name error, you need to use set for mapping.
- Can't get Kerberos realm
A: First, check whether all the machines of broker s are configured
/etc/krb5.conf file.
If an error is still reported after configuration, it needs to be in the startup script of the broker
JAVA_ At the end of the opts # variable, add
-Djava.security.krb5.conf:/etc/krb5.conf .
- orc data import failed ErrorMsg: type:ETL_RUN_FAIL; msg:Cannot cast ‘<slot 6>’ from VARCHAR to ARRAY<VARCHAR(30)>
The column names on both sides of the imported source file and the starlocks are inconsistent. When set, there will be a type inference in the system, and then the cast fails. If the field names on both sides are set to be the same, there will be no cast without set, and the import can succeed
- No source file in this table
There are no files in the table
- cause by: SIMPLE authentication is not enabled. Available:[TOKEN, KERBEROS]
kerberos authentication failed. klist checks whether the authentication has expired and whether the account has access to the source data
- Reason: there is a row couldn't find a partition. src line: [];
The imported data has no partition specified in the starrocks table