struct page
Page is the smallest unit of physical memory managed by the linux kernel. The kernel divides the whole physical memory into thousands of pages according to page alignment. In order to manage these pages, the kernel abstracts each page into a struct page structure and manages each page state and other attributes. For a 4GB memory, there will be millions of struct page structures. The struct page structure itself occupies a certain amount of memory. If the design of the struct page structure is too large, it will occupy more memory and less memory available to the system or users. Therefore, it is very sensitive to the size of the strcut page structure. Even adding a byte will have a great impact on the system. Therefore, the community has made a strict design for the structure of the struct page, Fields will not be added easily:
One of these structures exists for every physical page in the system; on a 4GB system, there will be one million page structures. Given that every byte added to struct page is amplified a million times, it is not surprising that there is a strong motivation to avoid growing this structure at any cost. So struct page contains no less than three unions and is surrounded by complicated rules describing which fields are valid at which times. Changes to how this structure is accessed must be made with great care.
In order to reduce the space occupied by the struct page, many techniques were used at the beginning of the design, including the union structure. In version 5.8.10, the whole struct page uses two larger union structures to save memory. The page structure is divided into the following blocks:

It can be seen that in a 64 bit system, struct page mainly contains two union structures, 40 bytes and 4 bytes respectively. The purpose of this design is to reduce the occupied space.
In addition to using union technology to reduce the occupied space, two other technologies are used, one of which is the use of flags flag:
Unions are not the only technique used to shoehorn as much information as possible into this small structure. Non-uniform memory access (NUMA) systems need to track information on which node each page belongs to, and which zone within the node as well. Rather than add fields to struct page
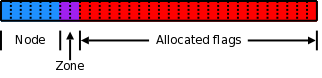
In NUMA system, in order to save space, the flags page flag bit is divided into a part for node id and zone, as follows:
Another important technology is reuse. The most typical application is list_ The head LRU linked list points to different linked lists at different times and for different purposes to save space.
The struct page structure definition is located in include\linux\mm_types.h file, version 5.8.10 is defined as follows:
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
/*
* Five words (20/40 bytes) are available in this union.
* WARNING: bit 0 of the first word is used for PageTail(). That
* means the other users of this union MUST NOT use the bit to
* avoid collision and false-positive PageTail().
*/
union {
struct { /* Page cache and anonymous pages */
/**
* @lru: Pageout list, eg. active_list protected by
* pgdat->lru_lock. Sometimes used as a generic list
* by the page owner.
*/
struct list_head lru;
/* See page-flags.h for PAGE_MAPPING_FLAGS */
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
/**
* @private: Mapping-private opaque data.
* Usually used for buffer_heads if PagePrivate.
* Used for swp_entry_t if PageSwapCache.
* Indicates order in the buddy system if PageBuddy.
*/
unsigned long private;
};
struct { /* page_pool used by netstack */
/**
* @dma_addr: might require a 64-bit value even on
* 32-bit architectures.
*/
dma_addr_t dma_addr;
};
struct { /* slab, slob and slub */
union {
struct list_head slab_list;
struct { /* Partial pages */
struct page *next;
#ifdef CONFIG_64BIT
int pages; /* Nr of pages left */
int pobjects; /* Approximate count */
#else
short int pages;
short int pobjects;
#endif
};
};
struct kmem_cache *slab_cache; /* not slob */
/* Double-word boundary */
void *freelist; /* first free object */
union {
void *s_mem; /* slab: first object */
unsigned long counters; /* SLUB */
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
};
struct { /* Tail pages of compound page */
unsigned long compound_head; /* Bit zero is set */
/* First tail page only */
unsigned char compound_dtor;
unsigned char compound_order;
atomic_t compound_mapcount;
};
struct { /* Second tail page of compound page */
unsigned long _compound_pad_1; /* compound_head */
atomic_t hpage_pinned_refcount;
/* For both global and memcg */
struct list_head deferred_list;
};
struct { /* Page table pages */
unsigned long _pt_pad_1; /* compound_head */
pgtable_t pmd_huge_pte; /* protected by page->ptl */
unsigned long _pt_pad_2; /* mapping */
union {
struct mm_struct *pt_mm; /* x86 pgds only */
atomic_t pt_frag_refcount; /* powerpc */
};
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl;
#else
spinlock_t ptl;
#endif
};
struct { /* ZONE_DEVICE pages */
/** @pgmap: Points to the hosting device page map. */
struct dev_pagemap *pgmap;
void *zone_device_data;
/*
* ZONE_DEVICE private pages are counted as being
* mapped so the next 3 words hold the mapping, index,
* and private fields from the source anonymous or
* page cache page while the page is migrated to device
* private memory.
* ZONE_DEVICE MEMORY_DEVICE_FS_DAX pages also
* use the mapping, index, and private fields when
* pmem backed DAX files are mapped.
*/
};
/** @rcu_head: You can use this to free a page by RCU. */
struct rcu_head rcu_head;
};
union { /* This union is 4 bytes in size. */
/*
* If the page can be mapped to userspace, encodes the number
* of times this page is referenced by a page table.
*/
atomic_t _mapcount;
/*
* If the page is neither PageSlab nor mappable to userspace,
* the value stored here may help determine what this page
* is used for. See page-flags.h for a list of page types
* which are currently stored here.
*/
unsigned int page_type;
unsigned int active; /* SLAB */
int units; /* SLOB */
};
/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */
atomic_t _refcount;
#ifdef CONFIG_MEMCG
struct mem_cgroup *mem_cgroup;
#endif
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
} _struct_page_alignment;
The structure is large and needs to be analyzed in four blocks according to the above.
page flags
The page flags flag bit mainly adopts the bit mode to describe the status information of a physical page:
"Page flags" are simple bit flags describing the state of a page of physical memory. They are defined in <linux/page-flags.h>. Flags exist to mark "reserved" pages (kernel memory, I/O memory, or simply nonexistent), locked pages, those under writeback I/O, those which are part of a compound page, pages managed by the slab allocator, and more. Depending on the target architecture and kernel configuration options selected, there can be as many as 24 individual flags defined.
Page flags are not only divided into flag bits, but also divided into section s, node IDs and zone s. The division form is related to the memory model and kernel configuration. See include \ Linux \ page flags layout H document describes its five main division forms:
The first type is non spark memory mode or spark vmemmap memory mode, as follows:

The above forms are common page flags, in which the highest bits from 0 to 63 are the FLAGS bit (the real page status flag bit), the middle remaining reservation, and the zone and NODE parts, in which the zone represents the zone area to which the page belongs, and the NODE in the NUMA system represents the NODE node id to which the page belongs. If it is a non NUMA system, it is 0. The remaining part in the middle is reserved.
In the first form above, if last is enabled_ Cpupid, last will be enabled_ Cpupid field, as follows:

If you want to enable the spark memory mode of non vmemmap, you need to add a section field to indicate the MEM where the page is located_ section:

Of course, if last is enabled for the above form_ Cpupid is divided as follows:

In addition to the above four forms, spark does not support non NUMA systems in the form of node id:

The size and offset of the fields in the above forms are different in each architecture. The kernel provides PGOFF macro for each field to facilitate unified calculation. The macro definition is located in the (include\linux\mm.h) file:
/* Page flags: | [SECTION] | [NODE] | ZONE | [LAST_CPUPID] | ... | FLAGS | */ #define SECTIONS_PGOFF ((sizeof(unsigned long)*8) - SECTIONS_WIDTH) #define NODES_PGOFF (SECTIONS_PGOFF - NODES_WIDTH) #define ZONES_PGOFF (NODES_PGOFF - ZONES_WIDTH) #define LAST_CPUPID_PGOFF (ZONES_PGOFF - LAST_CPUPID_WIDTH) #define KASAN_TAG_PGOFF (LAST_CPUPID_PGOFF - KASAN_TAG_WIDTH)
In addition to PGOFF, it also provides the definition of shitfs. If a field bit is 0, PGSHIFT is 0:
#define SECTIONS_PGSHIFT (SECTIONS_PGOFF * (SECTIONS_WIDTH != 0)) #define NODES_PGSHIFT (NODES_PGOFF * (NODES_WIDTH != 0)) #define ZONES_PGSHIFT (ZONES_PGOFF * (ZONES_WIDTH != 0)) #define LAST_CPUPID_PGSHIFT (LAST_CPUPID_PGOFF * (LAST_CPUPID_WIDTH != 0)) #define KASAN_TAG_PGSHIFT (KASAN_TAG_PGOFF * (KASAN_TAG_WIDTH != 0))
The MASK of each field is defined as follows:
#define ZONEID_PGSHIFT (ZONEID_PGOFF * (ZONEID_SHIFT != 0)) #define ZONES_MASK ((1UL << ZONES_WIDTH) - 1) #define NODES_MASK ((1UL << NODES_WIDTH) - 1) #define SECTIONS_MASK ((1UL << SECTIONS_WIDTH) - 1) #define LAST_CPUPID_MASK ((1UL << LAST_CPUPID_SHIFT) - 1) #define KASAN_TAG_MASK ((1UL << KASAN_TAG_WIDTH) - 1) #define ZONEID_MASK ((1UL << ZONEID_SHIFT) - 1)
It can be seen that the above macros ultimately depend on the WIDTH of each section. The macro represents how many bits each field occupies. If a field does not exist, set the WIDTH of the field to 0:
SECTIONS field operation
section field width SECTIONS_WIDTH is defined as follows:
#if defined(CONFIG_SPARSEMEM) && !defined(CONFIG_SPARSEMEM_VMEMMAP) #define SECTIONS_WIDTH SECTIONS_SHIFT #else #define SECTIONS_WIDTH 0 #endif
Section is only available when the configuration memory model is sparse and vememap is not supported_ Width is non-zero, which depends on SECTIONS_SHIFT:
#define SECTIONS_SHIFT (MAX_PHYSMEM_BITS - SECTION_SIZE_BITS)
MAX_PHYSMEM_BITS and SECTION_SIZE_BITS is related to the specific chip architecture
The kernel also encapsulates the function of obtaining or setting page section. Set the page section function as:
static inline void set_page_section(struct page *page, unsigned long section)
{
page->flags &= ~(SECTIONS_MASK << SECTIONS_PGSHIFT);
page->flags |= (section & SECTIONS_MASK) << SECTIONS_PGSHIFT;
}
Get section from page:
static inline unsigned long page_to_section(const struct page *page)
{
return (page->flags >> SECTIONS_PGSHIFT) & SECTIONS_MASK;
}ZONES field
ZONES_WIDTH is defined as follows:
#define ZONES_WIDTH ZONES_SHIFT
ZONES_SHIFT definition and specific zone Max_ NR_ About zone:
#if MAX_NR_ZONES < 2 #define ZONES_SHIFT 0 #elif MAX_NR_ZONES <= 2 #define ZONES_SHIFT 1 #elif MAX_NR_ZONES <= 4 #define ZONES_SHIFT 2 #elif MAX_NR_ZONES <= 8 #define ZONES_SHIFT 3 #else #error ZONES_SHIFT -- too many zones configured adjust calculation #endif
Set the zone operation function in page as follows:
static inline void set_page_zone(struct page *page, enum zone_type zone)
{
page->flags &= ~(ZONES_MASK << ZONES_PGSHIFT);
page->flags |= (zone & ZONES_MASK) << ZONES_PGSHIFT;
}
The zone function obtained from page is as follows:
static inline struct zone *page_zone(const struct page *page)
{
return &NODE_DATA(page_to_nid(page))->node_zones[page_zonenum(page)];
}
And get the zone id interface:
static inline int page_zone_id(struct page *page)
{
return (page->flags >> ZONEID_PGSHIFT) & ZONEID_MASK;
}NODES field operation
Node node width NODES_WIDTH is defined as follows:
#if SECTIONS_WIDTH+ZONES_WIDTH+NODES_SHIFT <= BITS_PER_LONG - NR_PAGEFLAGS #define NODES_WIDTH NODES_SHIFT #else #ifdef CONFIG_SPARSEMEM_VMEMMAP #error "Vmemmap: No space for nodes field in page flags" #endif #define NODES_WIDTH 0 #endif
A check is made here to prevent the bit used from exceeding the unsigned long BITS_PER_LONG size. If it does not exceed, node is used_ Shift configuration:
#ifdef CONFIG_NODES_SHIFT #define NODES_SHIFT CONFIG_NODES_SHIFT #else #define NODES_SHIFT 0 #endif
NODE_ The size of shift can be determined by kernel CONFIG_NODES_SHIFT to configure.
Set the node field in the page as follows:
static inline void set_page_node(struct page *page, unsigned long node)
{
page->flags &= ~(NODES_MASK << NODES_PGSHIFT);
page->flags |= (node & NODES_MASK) << NODES_PGSHIFT;
}Get the node field in the page as follows:
static inline int page_to_nid(const struct page *page)
{
struct page *p = (struct page *)page;
return (PF_POISONED_CHECK(p)->flags >> NODES_PGSHIFT) & NODES_MASK;
}LAST__CPU_SHIFT
last cpu pid has no special width macro, only LAST_CPUPID_SHIFT, as defined below:
#ifdef CONFIG_NUMA_BALANCING #define LAST__PID_SHIFT 8 #define LAST__PID_MASK ((1 << LAST__PID_SHIFT)-1) #define LAST__CPU_SHIFT NR_CPUS_BITS #define LAST__CPU_MASK ((1 << LAST__CPU_SHIFT)-1) #define LAST_CPUPID_SHIFT (LAST__PID_SHIFT+LAST__CPU_SHIFT) #else #define LAST_CPUPID_SHIFT 0 #endif
Config needs to be turned on_ NUMA_ Balancing macro is only supported. And LAST_CPUID_SHIFT depends on NR_CPUS_BITS.
Get last cpu pid:
static inline int page_cpupid_last(struct page *page)
{
return (page->flags >> LAST_CPUPID_PGSHIFT) & LAST_CPUPID_MASK;
}reset last cpu pid:
static inline void page_cpupid_reset_last(struct page *page)
{
page->flags |= LAST_CPUPID_MASK << LAST_CPUPID_PGSHIFT;
}flags field
The flags field is basically fixed, and each flag occupies a bit, which is specially located in include \ Linux \ page flags H. the flag bits are managed uniformly. In this header file, there is a detailed description of page flags, including a paragraph:
* The page flags field is split into two parts, the main flags area * which extends from the low bits upwards, and the fields area which * extends from the high bits downwards. * * | FIELD | ... | FLAGS | * N-1 ^ 0 * (NR_PAGEFLAGS) *
page flags are mainly divided into two ends, of which NR_PAGEFLAGS is the watershed, Nr_ The above pageflags are called extensible parts:
| page flag | explain |
| PG_locked | If the kernel has been locked, the other modules cannot access the page again |
| PG_referenced | If the page has been accessed recently, set if it has been accessed. Algorithm for LRU |
| PG_uptodate | The page has been successfully read from the hard disk |
| PG_dirty | This page is a dirty page, and the data of this page needs to be refreshed to the hard disk. When the page data is modified, it will not be refreshed to the hard disk immediately. Instead, it will be guaranteed to the memory for the time being and wait for it to be refreshed to the hard disk later. Setting this page as a dirty page means that the page must not be - released before it is replaced |
| PG_lru | Indicates that the page is in the LRU linked list. LRU linked list refers to the least used linked list |
| PG_active | Indicates that the page is active |
| PG_workingset | Set this page as the woring set of a process. For working set, see the following article: https://www.brendangregg.com/blog/2018-01-17/measure-working-set-size.html |
| PG_waiters | A process is waiting for this page |
| PG_error | This page encountered an error during IO operation |
| PG_slab | This page is used by slab |
| PG_owner_priv_1 | It is used by the owner of the page. If it is used as a pagecache page, the file system may use it |
| PG_arch_1 | A status bit related to the architecture, |
| PG_reserved | This page is reserved and cannot be swapped out. In the system, kernel image (including vDSO) and BIOS, initrd, hw table and vememap need to be reserved during system initialization, and common pages that need to be reserved, such as DAM, need to set the page status bit to reserved |
| PG_private | If the private member in the page is not empty, you need to set this flag. Pages used for I/O can use this field to subdivide the page into multi-core buffers |
| PG_private_2 | In PG_ The extension based on private is often used for aux data |
| PG_writeback | Page's memory is writing to disk |
| PG_head | This page is a head page. In the kernel, it is sometimes necessary to form multiple pages into a compound pages, and setting this state indicates that this page is the first page of the compound pages |
| PG_mappedtodisk | The page is mapped to the hard disk |
| PG_reclaim | This page can be recycled |
| PG_swapbacked | The backup memory of this page is swap/ram. Generally, only anonymous pages can write back swap points |
| PG_unevictable | The page is locked, cannot be recycled, and will appear in the LRU_ In the invictable linked list |
| PG_mlocked | The vma corresponding to this page is locked. Generally, it is locked for a period of time through the system call mlock() |
| PG_uncached | This page is set as non cacheable, and config needs to be configured_ ARCH_ USES_ PG_ UNCACHED |
| PG_hwpoison | hardware poisoned page. Don't touch, configure CONFIG_MEMORY_FAILURE |
| PG_young | Config required_ IDLE_ PAGE_ Tracking and config_ Only 64bit is supported |
| PG_idle | Config required_ IDLE_ PAGE_ Tracking and config_ Only 64bit is supported |
In order to facilitate operations such as marking, zeroing and checking whether it is set, the kernel has made a series of macro definitions, which looks complex:
/*
* Macros to create function definitions for page flags
*/
#define TESTPAGEFLAG(uname, lname, policy) \
static __always_inline int Page##uname(struct page *page) \
{ return test_bit(PG_##lname, &policy(page, 0)->flags); }
#define SETPAGEFLAG(uname, lname, policy) \
static __always_inline void SetPage##uname(struct page *page) \
{ set_bit(PG_##lname, &policy(page, 1)->flags); }
#define CLEARPAGEFLAG(uname, lname, policy) \
static __always_inline void ClearPage##uname(struct page *page) \
{ clear_bit(PG_##lname, &policy(page, 1)->flags); }
#define __SETPAGEFLAG(uname, lname, policy) \
static __always_inline void __SetPage##uname(struct page *page) \
{ __set_bit(PG_##lname, &policy(page, 1)->flags); }
#define __CLEARPAGEFLAG(uname, lname, policy) \
static __always_inline void __ClearPage##uname(struct page *page) \
{ __clear_bit(PG_##lname, &policy(page, 1)->flags); }
#define TESTSETFLAG(uname, lname, policy) \
static __always_inline int TestSetPage##uname(struct page *page) \
{ return test_and_set_bit(PG_##lname, &policy(page, 1)->flags); }
#define TESTCLEARFLAG(uname, lname, policy) \
static __always_inline int TestClearPage##uname(struct page *page) \
{ return test_and_clear_bit(PG_##lname, &policy(page, 1)->flags); }
#define PAGEFLAG(uname, lname, policy) \
TESTPAGEFLAG(uname, lname, policy) \
SETPAGEFLAG(uname, lname, policy) \
CLEARPAGEFLAG(uname, lname, policy)
#define __PAGEFLAG(uname, lname, policy) \
TESTPAGEFLAG(uname, lname, policy) \
__SETPAGEFLAG(uname, lname, policy) \
__CLEARPAGEFLAG(uname, lname, policy)
#define TESTSCFLAG(uname, lname, policy) \
TESTSETFLAG(uname, lname, policy) \
TESTCLEARFLAG(uname, lname, policy)
#define TESTPAGEFLAG_FALSE(uname) \
static inline int Page##uname(const struct page *page) { return 0; }
#define SETPAGEFLAG_NOOP(uname) \
static inline void SetPage##uname(struct page *page) { }
#define CLEARPAGEFLAG_NOOP(uname) \
static inline void ClearPage##uname(struct page *page) { }
#define __CLEARPAGEFLAG_NOOP(uname) \
static inline void __ClearPage##uname(struct page *page) { }
#define TESTSETFLAG_FALSE(uname) \
static inline int TestSetPage##uname(struct page *page) { return 0; }
#define TESTCLEARFLAG_FALSE(uname) \
static inline int TestClearPage##uname(struct page *page) { return 0; }
#define PAGEFLAG_FALSE(uname) TESTPAGEFLAG_FALSE(uname) \
SETPAGEFLAG_NOOP(uname) CLEARPAGEFLAG_NOOP(uname)
#define TESTSCFLAG_FALSE(uname) \
TESTSETFLAG_FALSE(uname) TESTCLEARFLAG_FALSE(uname)
__PAGEFLAG(Locked, locked, PF_NO_TAIL)
PAGEFLAG(Waiters, waiters, PF_ONLY_HEAD) __CLEARPAGEFLAG(Waiters, waiters, PF_ONLY_HEAD)
PAGEFLAG(Error, error, PF_NO_TAIL) TESTCLEARFLAG(Error, error, PF_NO_TAIL)
PAGEFLAG(Referenced, referenced, PF_HEAD)
TESTCLEARFLAG(Referenced, referenced, PF_HEAD)
__SETPAGEFLAG(Referenced, referenced, PF_HEAD)
PAGEFLAG(Dirty, dirty, PF_HEAD) TESTSCFLAG(Dirty, dirty, PF_HEAD)
__CLEARPAGEFLAG(Dirty, dirty, PF_HEAD)
PAGEFLAG(LRU, lru, PF_HEAD) __CLEARPAGEFLAG(LRU, lru, PF_HEAD)
PAGEFLAG(Active, active, PF_HEAD) __CLEARPAGEFLAG(Active, active, PF_HEAD)
TESTCLEARFLAG(Active, active, PF_HEAD)
PAGEFLAG(Workingset, workingset, PF_HEAD)
TESTCLEARFLAG(Workingset, workingset, PF_HEAD)
__PAGEFLAG(Slab, slab, PF_NO_TAIL)
__PAGEFLAG(SlobFree, slob_free, PF_NO_TAIL)
PAGEFLAG(Checked, checked, PF_NO_COMPOUND) /* Used by some filesystems */
/* Xen */
PAGEFLAG(Pinned, pinned, PF_NO_COMPOUND)
TESTSCFLAG(Pinned, pinned, PF_NO_COMPOUND)
PAGEFLAG(SavePinned, savepinned, PF_NO_COMPOUND);
PAGEFLAG(Foreign, foreign, PF_NO_COMPOUND);
PAGEFLAG(XenRemapped, xen_remapped, PF_NO_COMPOUND)
TESTCLEARFLAG(XenRemapped, xen_remapped, PF_NO_COMPOUND)
PAGEFLAG(Reserved, reserved, PF_NO_COMPOUND)
__CLEARPAGEFLAG(Reserved, reserved, PF_NO_COMPOUND)
__SETPAGEFLAG(Reserved, reserved, PF_NO_COMPOUND)
PAGEFLAG(SwapBacked, swapbacked, PF_NO_TAIL)
__CLEARPAGEFLAG(SwapBacked, swapbacked, PF_NO_TAIL)
__SETPAGEFLAG(SwapBacked, swapbacked, PF_NO_TAIL)
/*
* Private page markings that may be used by the filesystem that owns the page
* for its own purposes.
* - PG_private and PG_private_2 cause releasepage() and co to be invoked
*/
PAGEFLAG(Private, private, PF_ANY) __SETPAGEFLAG(Private, private, PF_ANY)
__CLEARPAGEFLAG(Private, private, PF_ANY)
PAGEFLAG(Private2, private_2, PF_ANY) TESTSCFLAG(Private2, private_2, PF_ANY)
PAGEFLAG(OwnerPriv1, owner_priv_1, PF_ANY)
TESTCLEARFLAG(OwnerPriv1, owner_priv_1, PF_ANY)
/*
* Only test-and-set exist for PG_writeback. The unconditional operators are
* risky: they bypass page accounting.
*/
TESTPAGEFLAG(Writeback, writeback, PF_NO_TAIL)
TESTSCFLAG(Writeback, writeback, PF_NO_TAIL)
PAGEFLAG(MappedToDisk, mappedtodisk, PF_NO_TAIL)
/* PG_readahead is only used for reads; PG_reclaim is only for writes */
PAGEFLAG(Reclaim, reclaim, PF_NO_TAIL)
TESTCLEARFLAG(Reclaim, reclaim, PF_NO_TAIL)
PAGEFLAG(Readahead, reclaim, PF_NO_COMPOUND)
TESTCLEARFLAG(Readahead, reclaim, PF_NO_COMPOUND)Expand the above series of macros, mainly including the following three types:
- Set the page to the unified name bit SetPageXXX, where XXX is the lower case part after the flag bit, such as SetPageLRU, and PG is set_ LRU flag bit, SetPageDirty} is set to PG_dirty flag bit
- ClearPageXXX is to clear the corresponding flag bit
- PageXXX, used to check whether the flag bit is set on the page.
First Union
The first union of struct page is a 40 byte union under 64 bit system, which contains 8 parts. It records the main functional data of page, and each part has a structure for description
Page cache and anonymous pages
The first structure is mainly the main function data of anonymous pages and page cache. The main structure members are as follows:
struct { /* Page cache and anonymous pages */
/**
* @lru: Pageout list, eg. active_list protected by
* pgdat->lru_lock. Sometimes used as a generic list
* by the page owner.
*/
struct list_head lru;
/* See page-flags.h for PAGE_MAPPING_FLAGS */
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
/**
* @private: Mapping-private opaque data.
* Usually used for buffer_heads if PagePrivate.
* Used for swp_entry_t if PageSwapCache.
* Indicates order in the buddy system if PageBuddy.
*/
unsigned long private;
};Description of key members:
- struct list_head lru: LRU linked list, which will be attached to different linked lists according to different purposes of the page. For example, when it is managed by buddy system at idle time, it will be attached to buffy's free linked list. If the page is assigned, it will be linked to the active list according to the activation status of the page.
- struct address_space *mapping: points to the mapped address space when the page is mapped.
- pgoff_t index: represents the offset when the page is mapped by a file
- unsigned long private: private data
page_pool used by netstack
If the page is used as a DMA map, dma_addr_t represents a mapped bus address:
struct { /* page_pool used by netstack */
/**
* @dma_addr: might require a 64-bit value even on
* 32-bit architectures.
*/
dma_addr_t dma_addr;
};slab, slob and slub
This page is managed and allocated by slab/slob/slub, that is, it has been allocated by buffy to further manage small memory allocation:
struct { /* slab, slob and slub */
union {
struct list_head slab_list;
struct { /* Partial pages */
struct page *next;
#ifdef CONFIG_64BIT
int pages; /* Nr of pages left */
int pobjects; /* Approximate count */
#else
short int pages;
short int pobjects;
#endif
};
};
struct kmem_cache *slab_cache; /* not slob */
/* Double-word boundary */
void *freelist; /* first free object */
union {
void *s_mem; /* slab: first object */
unsigned long counters; /* SLUB */
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
};Main structure description:
- struct list_head slab_list: refers to the slab list
- struct page *next: allocate and use in slub
- struct kmem_cache *slab_cache: refers to the slab cache descriptor
- void *freelist:: points to the kobject of the first space. When a page is allocated by buddy and managed by slab, the memory will be divided into equal arrays of corresponding size, that is, object for allocation management. Freelist points to the first free location
- void *s_mem: point to the starting address of the first slab object
- unsigned long counters: used by slub as count
Tail pages of compound page
This structure indicates that it is the last page of compound pages. The main functions of compound pages are described in a paragraph:
A compound page is simply a grouping of two or more physically contiguous pages into a unit that can, in many ways, be treated as a single, larger page. They are most commonly used to create huge pages
compound page combines multiple consecutive physical pages to form a larger page. Its biggest purpose is to create a huge page. For details, please refer to: https://lwn.net/Articles/619514/
This result mainly describes the tail page of compound page:
struct { /* Tail pages of compound page */
unsigned long compound_head; /* Bit zero is set */
/* First tail page only */
unsigned char compound_dtor;
unsigned char compound_order;
atomic_t compound_mapcount;
};Main structure members:
- unsigned long compound_head: points to the first page of compound pages
- unsigned char compound_dtor: only set in the first tail page
- unsigned char compound_order: page order is set only in the first tail page
- atomic_ t compound_ Mapcount: number of compound mappings
Second tail page of compound page
Second, the structure of compound tail page:
struct { /* Second tail page of compound page */
unsigned long _compound_pad_1; /* compound_head */
atomic_t hpage_pinned_refcount;
/* For both global and memcg */
struct list_head deferred_list;
};Page table pages
This structure is mainly used for page table. The structure members are as follows:
struct { /* Page table pages */
unsigned long _pt_pad_1; /* compound_head */
pgtable_t pmd_huge_pte; /* protected by page->ptl */
unsigned long _pt_pad_2; /* mapping */
union {
struct mm_struct *pt_mm; /* x86 pgds only */
atomic_t pt_frag_refcount; /* powerpc */
};
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl;
#else
spinlock_t ptl;
#endifZONE_DEVICE pages
When this page belongs to ZONE_DEVICE:
struct { /* ZONE_DEVICE pages */
/** @pgmap: Points to the hosting device page map. */
struct dev_pagemap *pgmap;
void *zone_device_data;
/*
* ZONE_DEVICE private pages are counted as being
* mapped so the next 3 words hold the mapping, index,
* and private fields from the source anonymous or
* page cache page while the page is migrated to device
* private memory.
* ZONE_DEVICE MEMORY_DEVICE_FS_DAX pages also
* use the mapping, index, and private fields when
* pmem backed DAX files are mapped.
*/
};
rcu_head
rcu_head is mainly used as RCU lock
struct rcu_head rcu_head;
Second Union
The size of the second union of struct page is 4 bytes, and the main members are as follows:
union { /* This union is 4 bytes in size. */
/*
* If the page can be mapped to userspace, encodes the number
* of times this page is referenced by a page table.
*/
atomic_t _mapcount;
/*
* If the page is neither PageSlab nor mappable to userspace,
* the value stored here may help determine what this page
* is used for. See page-flags.h for a list of page types
* which are currently stored here.
*/
unsigned int page_type;
unsigned int active; /* SLAB */
int units; /* SLOB */
};- atomic_t _mapcount: if the page is mapped to the count of user layer processes, that is, how many user processes are mapped_ When mapcount is - 1, it means that it is not mapped by PTE. when mapcount is equal to 0, it means that only one parent process uses the mapped page. When mapcount is greater than 0, it means that other processes besides the parent process use this page.
- unsigned int page_type: if the page does not belong to page slab or user space, it represents the page type, i.e. use purpose
- unsigned int active: indicates the active object in the slab
- int units: used by slob
_refcount
_ refcount is used as reference count management to track memory usage. When initialized to idle state, the count is 0. When it is allocated to reference, the count will be + 1.
reference material
https://lwn.net/Articles/335768/