Hello everyone, it's a new week. We usually use the Pandas module to further analyze and mine the key information of the data set, but when we encounter a particularly large data set, the memory will explode. Today I'll share some tips to help you avoid the situation mentioned above.
Note: technical exchange group is provided at the end of the text
read_ chunksize parameter in CSV () method
read_ As the name suggests, the chunksize parameter in the csv () method means that we can read large csv files in blocks. For example, there are 70 million lines of data in the file. We set the chunksize parameter to 1 million and read them in batches in 1 million each time. The code is as follows
# read the large csv file with specified chunksize df_chunk = pd.read_csv(r'data.csv', chunksize=1000000)
Then we get df_chunk is not a DataFrame object, but an iteratable object. Next, we use the for loop and apply the function method of data preprocessing created by ourselves to each DataFrame dataset. The code is as follows
chunk_list = [] # Create a list chunk_list
# for loop traversal DF_ Every DataFrame object in chunk
for chunk in df_chunk:
# Apply the data preprocessing method created by yourself to each DataFrame object
chunk_filter = chunk_preprocessing(chunk)
# append the processed results to the empty list created above
chunk_list.append(chunk_filter)
# Then concat the list together
df_concat = pd.concat(chunk_list)
Remove all unimportant columns
Of course, we can further remove unimportant columns. For example, if there is a large proportion of null values in a column, we can remove the column. The code is as follows
# Filter out unimportant columns df = df[['col_1','col_2', 'col_3', 'col_4', 'col_5', 'col_6','col_7', 'col_8', 'col_9', 'col_10']]
Of course, if we want to remove null values, we can call DF Dropna () method can also improve the accuracy of data and reduce memory consumption
Transform data format
Finally, we can compress the memory space by changing the data type. Generally, the Pandas module will automatically set the default data type for the data column. There are sub types in many data types, and these sub types can be represented by fewer bytes. The following table gives the number of bytes occupied by each sub type
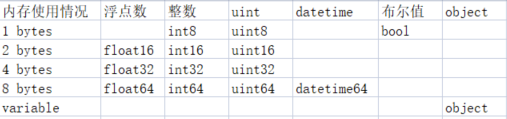
We can understand the data in memory in this way. Memory is equivalent to warehouse, while data is equivalent to goods. Goods need to be loaded into boxes before entering the warehouse. Now there are three kinds of boxes: large, medium and small,
Now, when Pandas reads data, it loads these data, regardless of its type, into large boxes, so the warehouse, that is, the memory will be full in a short time.
Therefore, our optimization idea is to traverse each column, and then find out the maximum and minimum values of the column. We compare these maximum and minimum values with the maximum and minimum values among subtypes, and select the subtype with the smallest number of bytes.
For example, Pandas defaults to a column of type int64. The maximum and minimum values are 0 and 100 respectively, while int8 can store values between - 128 and 127. Therefore, we can convert the column from type int64 to type int8, which saves a lot of memory space at the same time.
We put the above ideas into code, as shown below
def reduce_mem_usage(df):
""" ergodic DataFrame Each column in the dataset
And change their data types
"""
start_memory = df.memory_usage().sum() / 1024**2
print('DataFrame The data sets occupied are: {:.2f} MB'.format(start_memory))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
col_min = df[col].min()
col_max = df[col].max()
if str(col_type)[:3] == 'int':
if col_min > np.iinfo(np.int8).min and col_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif col_min > np.iinfo(np.int16).min and col_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif col_min > np.iinfo(np.int32).min and col_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif col_min > np.iinfo(np.int64).min and col_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if col_min > np.finfo(np.float16).min and col_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif col_min > np.finfo(np.float32).min and col_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_memory = df.memory_usage().sum() / 1024**2
print('Memory occupation of data set after optimization: {:.2f} MB'.format(end_memory))
print('Reduced by about: {:.1f}%'.format(100 * (start_memory - end_memory) / start_memory))
return df
You can try this function method written by Xiao to see the effect?
Technical exchange
Welcome to reprint, collect, gain, praise and support!

At present, a technical exchange group has been opened, with more than 2000 group friends. The best way to add notes is: source + Interest direction, which is convenient to find like-minded friends
- Method ① send the following pictures to wechat, long press identification, and the background replies: add group;
- Mode ②. Add micro signal: dkl88191, remarks: from CSDN
- WeChat search official account: Python learning and data mining, background reply: add group
