Preface
The text and pictures of this article are from the Internet, only for learning and communication, not for any commercial purpose. The copyright belongs to the original author. If you have any questions, please contact us in time for handling.
When I was a child, I always had 100000 questions about why. Today, I take you to climb a question and answer website. In this lesson, I use regular expression to extract data of text class. Regular expression is a general method of data extraction.
Suitable for:
Python zero foundation, interested in reptile data collection students!
Environment introduction:
python 3.6
pycharm
requests
re
json
General thinking of reptiles
1. Determine the url path to crawl, and the headers parameter
2. Send request -- requests simulate browser to send request and get response data
3. Parsing data -- re module: provides all regular expression functions
4. Save data -- save data in json format
1. Determine the url path to crawl, and the headers parameter
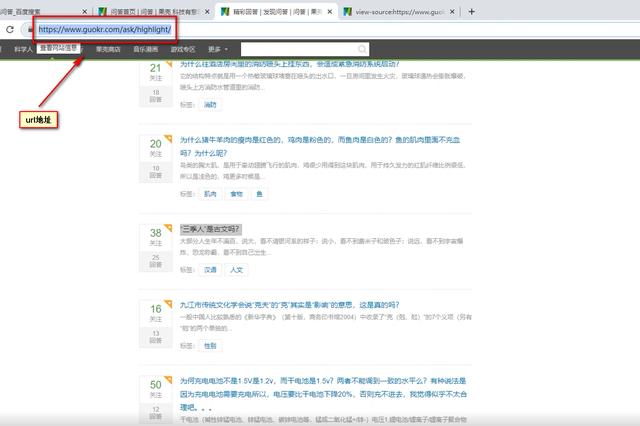
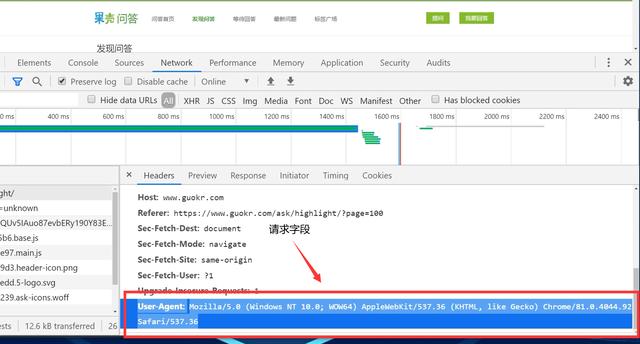
base_url = 'https://www.guokr.com/ask/highlight/?page={}'.format(str(page)) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
2. Send request -- requests simulate browser to send request and get response data
response = requests.get(base_url, headers=headers) data = response.text # print(data)
3, Parsing data -- re module: provides all regular expression functions
Compiling regular expression precompiled code objects is faster than using strings directly, because the interpreter recommends compiling strings into code objects before executing the code in the form of strings
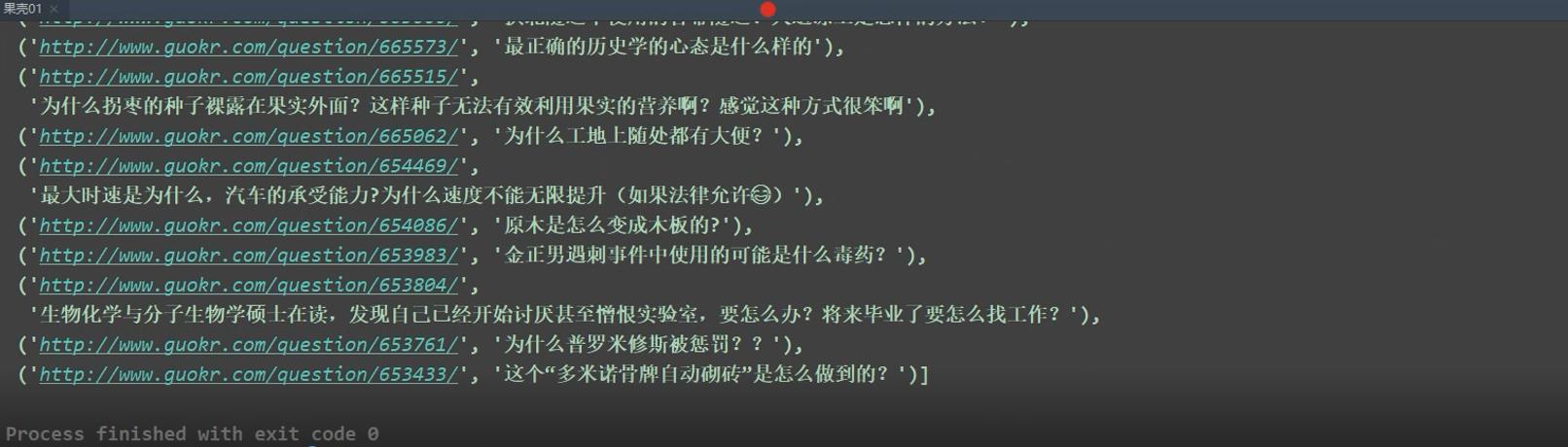
pattern = re.compile('<h2><a target="_blank" href="(.*?)">(.*?)</a></h2>', re.S) pattern_list = pattern.findall(data) # -->list # print(pattern_list) # json [{[]}]{} # structure json data format for i in pattern_list: data_dict = {} data_dict['title'] = i[1] data_dict['href'] = i[0] data_list.append(data_dict) # convert to json format # json.dumps Default for Chinese in serialization ascii Code.To output real Chinese, you need to specify ensure_ascii=False: json_data_list = json.dumps(data_list, ensure_ascii=False) # print(json_data_list) with open("guoke02.json", 'w', encoding='utf-8') as f: f.write(json_data_list)
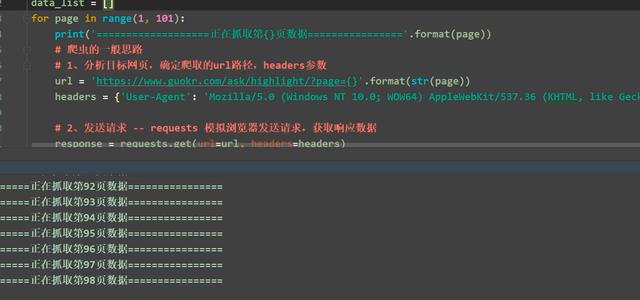
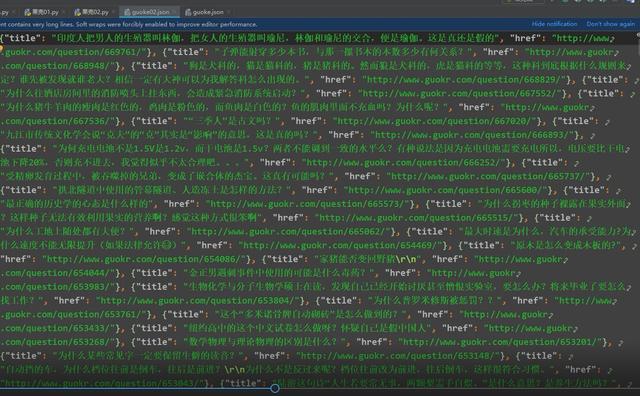
4. Save file in json format
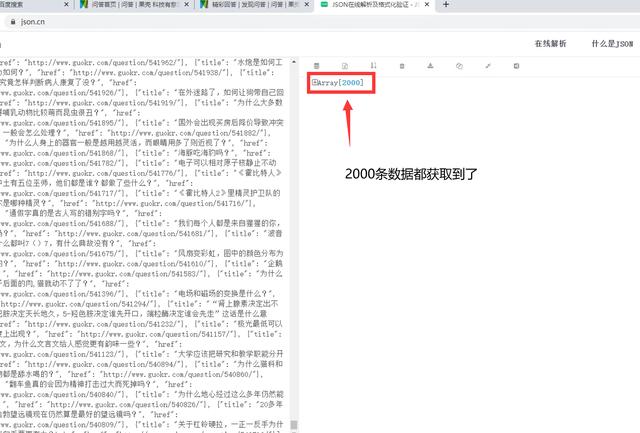
20 pieces of data per page, 100 pages in total, 2000 pieces of data~
If you want to learn Python or are learning python, there are many Python tutorials, but are they up to date? Maybe you have learned something that someone else probably learned two years ago. Share a wave of the latest Python tutorials in 2020 in this editor. Access to the way, private letter small "information", you can get free Oh!
The complete code is as follows:
# requests # re # json # General thinking of reptiles # 1,Determine the climbing url route, headers parameter # 2,Send request -- requests Simulate browser to send request and get response data # 3,Parse data -- re Module: provides all regular expression functions # 4,Save data -- Preservation json Data in format import requests # pip install requests import re import json data_list = [] for page in range(1, 101): print("====Climbing to the top{}Industry data====\n".format(page)) # 1,Determined to crawl url route, headers parameter base_url = 'https://www.guokr.com/ask/highlight/?page={}'.format(str(page)) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'} # 2,Send request -- requests Simulate browser to send request and get response data response = requests.get(base_url, headers=headers) data = response.text # print(data) # 3,Parse data -- re Module: provides all regular expression functions # <h2><a target="_blank" href="https://Www.guokr.com/question/669761/ "> Indians call men's genitals Linga and women's genitals Yuni. Yoga is the combination of Linga and Yuni. Is this true or not</a></h2> # 3,1 Compiling regular expression precompiled code objects is faster than using strings directly, because the interpreter recommends that you compile strings into code objects before executing the code in the form of strings pattern = re.compile('<h2><a target="_blank" href="(.*?)">(.*?)</a></h2>', re.S) pattern_list = pattern.findall(data) # -->list # print(pattern_list) # json [{[]}]{} # structure json data format for i in pattern_list: data_dict = {} data_dict['title'] = i[1] data_dict['href'] = i[0] data_list.append(data_dict) # convert to json format # json.dumps Default for Chinese in serialization ascii Code.To output real Chinese, you need to specify ensure_ascii=False: json_data_list = json.dumps(data_list, ensure_ascii=False) # print(json_data_list) # Preservation json Format file with open("guoke02.json", 'w', encoding='utf-8') as f: f.write(json_data_list)