Summary
Strings in Python exist as a powerful set of processing tools, not as hard to use in class C. Because Python provides a series of string operation methods, from case conversion, slice operation to search and so on, which almost meet the daily use scenarios. Of course, if it can not meet the needs, it can also help more powerful third-party libraries such as string, re and so on. Here's a basic overview and a simple example of the 44 string built-in methods in Python 3.
If you want to learn from a python programmer, you can come to my Python to learn how to deduct qun: 835017344 and send a free Python video tutorial! At 8:00 p.m. every night, I will broadcast the python knowledge live in the group. Welcome to come to learn and exchange.
Overview of 44 string built-in methods

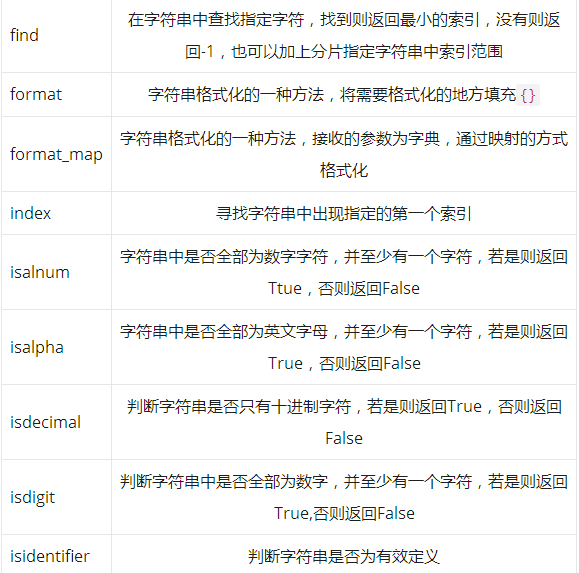
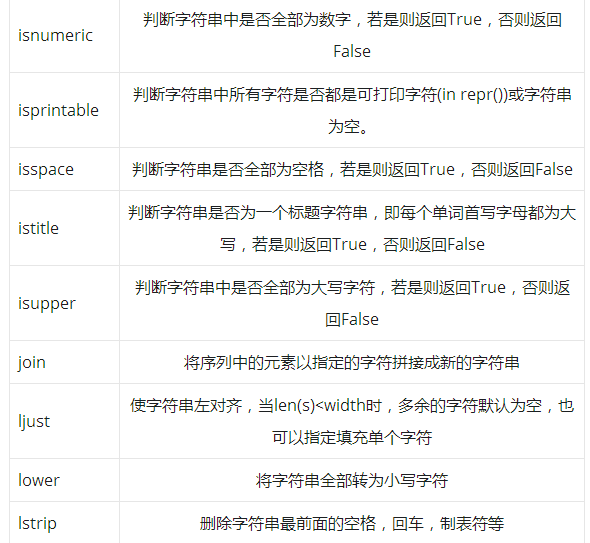

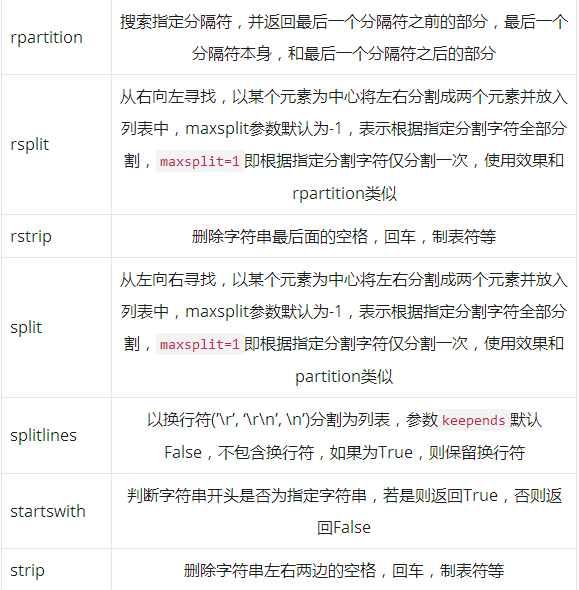
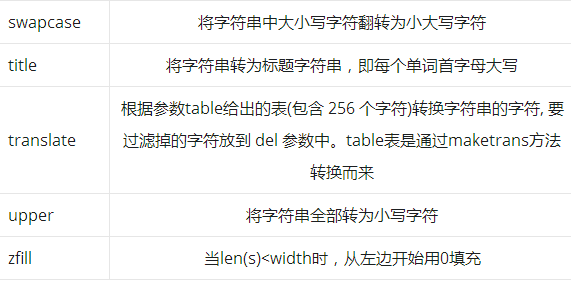
44 methods
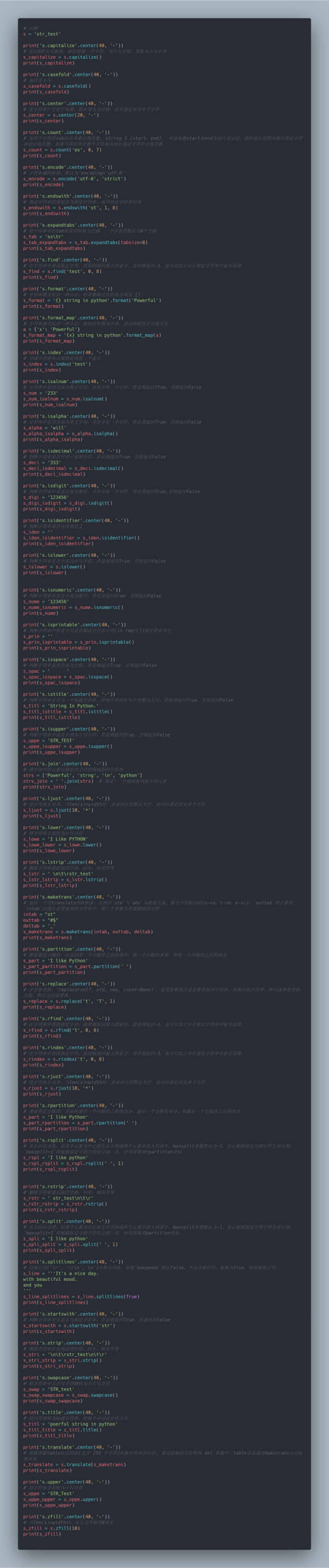
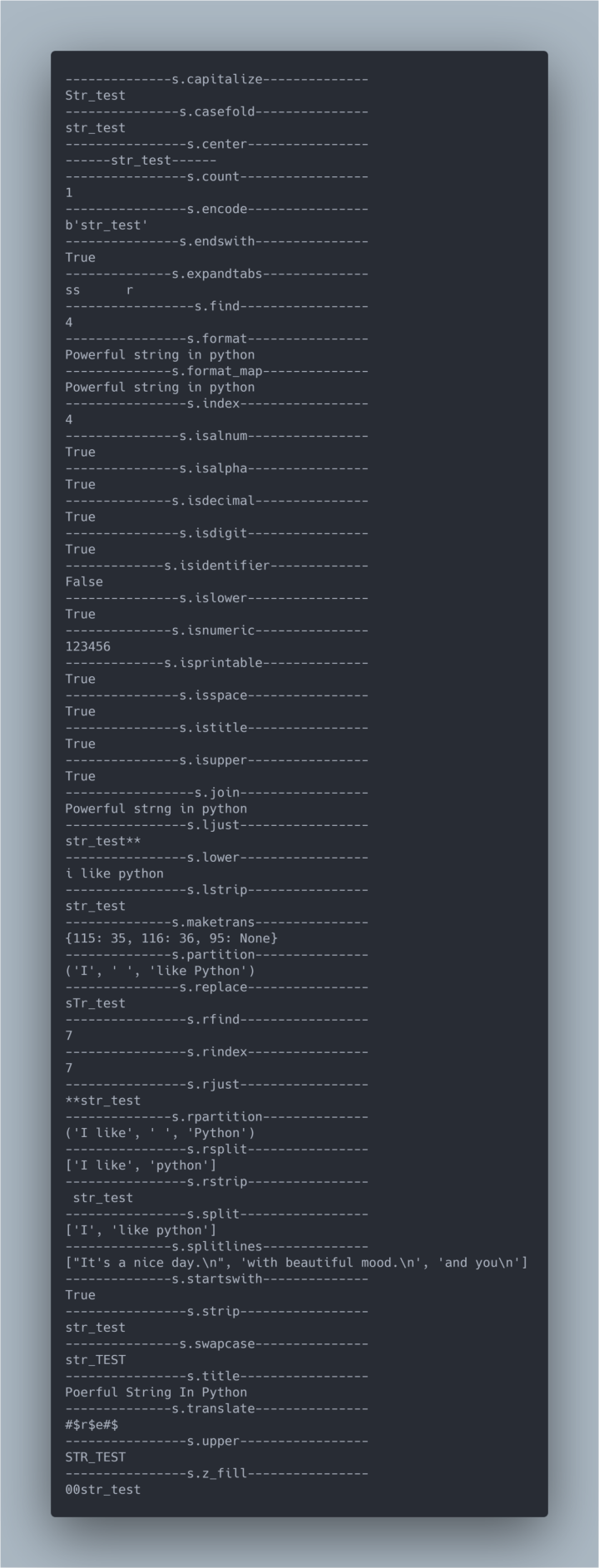
# Example
s = 'str_test'
print('s.capitalize'.center(40, '-'))
# Returns the uppercase version of S, that is, the first character is created, which is an uppercase letter and the others are lowercase letters
s_capitalize = s.capitalize()
print(s_capitalize)
print('s.casefold'.center(40, '-'))
# Return to all lowercase
s_casefold = s.casefold()
print(s_casefold)
print('s.center'.center(40, '-'))
# Center the string. The default padding is space. You can also specify a single character
s_center = s.center(20, '-')
print(s_center)
print('s.count'.center(40, '-'))
# Returns the number of non overlapping occurrences of sub string sub, string S [start: end] The optional parameters start and end are slice representation. That is, count the occurrence times of the specified string within the slice range. If not specified, count the occurrence times of the specified string within the whole string
s_count = s.count('es', 0, 7)
print(s_count)
print('s.encode'.center(40, '-'))
# String encoding conversion, default to 'encoding='utf-8'`
s_encode = s.encode('utf-8', 'strict')
print(s_encode)
print('s.endswith'.center(40, '-'))
# Test whether the end of the string is the specified string, or the end of the string
s_endswith = s.endswith('st', 1, 8)
print(s_endswith)
print('s.expandtabs'.center(40, '-'))
# Converts the tab tab in a string to a space. The default value for a character is 8 spaces
s_tab = 'ss\tr'
s_tab_expandtabs = s_tab.expandtabs(tabsize=8)
print(s_tab_expandtabs)
print('s.find'.center(40, '-'))
# Find the specified character in the string and return the smallest index if found, or - 1 if not found, or add the index range in the fragment specified string
s_find = s.find('test', 0, 8)
print(s_find)
print('s.format'.center(40, '-'))
# A method of string formatting that fills in '{}' where formatting is needed`
s_format = '{} string in python'.format('Powerful')
print(s_format)
print('s.format_map'.center(40, '-'))
# A method of string formatting in which the received parameters are dictionaries, formatted by mapping
a = {'x': 'Powerful'}
s_format_map = '{x} string in python'.format_map(a)
print(s_format_map)
print('s.index'.center(40, '-'))
# Finds the first index specified in the string
s_index = s.index('test')
print(s_index)
print('s.isalnum'.center(40, '-'))
# Whether all the characters in the string are numeric, and there is at least one character. If yes, then return Tute, otherwise return False
s_num = '233'
s_num_isalnum = s_num.isalnum()
print(s_num_isalnum)
print('s.isalpha'.center(40, '-'))
# Whether all characters in the string are English letters and at least one character. If yes, return True, otherwise return False
s_alpha = 'will'
s_alpha_isalpha = s_alpha.isalpha()
print(s_alpha_isalpha)
print('s.isdecimal'.center(40, '-'))
# Judge whether the string has only decimal characters. If yes, return True. Otherwise, return False
s_deci = '333'
s_deci_isdecimal = s_deci.isdecimal()
print(s_deci_isdecimal)
print('s.isdigit'.center(40, '-'))
# Determines whether all the characters in the string are numbers and at least one character. If yes, returns True. Otherwise, returns False
s_digi = '123456'
s_digi_isdigit = s_digi.isdigit()
print(s_digi_isdigit)
print('s.isidentifier'.center(40, '-'))
# Determine whether the string is a valid definition
s_iden = ''
s_iden_isidentifier = s_iden.isidentifier()
print(s_iden_isidentifier)
print('s.islower'.center(40, '-'))
# Determines whether the string is all lowercase characters. If yes, returns True. Otherwise, returns False
s_islower = s.islower()
print(s_islower)
print('s.isnumeric'.center(40, '-'))
# Judge whether all numbers in the string are numbers. If yes, return True. Otherwise, return False
s_nume = '123456'
s_nume_isnumeric = s_nume.isnumeric()
print(s_nume)
print('s.isprintable'.center(40, '-'))
# Determine whether all characters in the string are printable (in repr()) or the string is empty.
s_prin = ''
s_prin_isprintable = s_prin.isprintable()
print(s_prin_isprintable)
print('s.isspace'.center(40, '-'))
# Judge whether all strings are spaces. If yes, return True. Otherwise, return False
s_spac = ' '
s_spac_isspace = s_spac.isspace()
print(s_spac_isspace)
print('s.istitle'.center(40, '-'))
# Determine whether the string is a title string, i.e. the initial of each word is uppercase. If yes, return True, otherwise return False
s_titl = 'String In Python.'
s_titl_istitle = s_titl.istitle()
print(s_titl_istitle)
print('s.isupper'.center(40, '-'))
# Determines whether all uppercase characters are in the string. If yes, returns True. Otherwise, returns False
s_uppe = 'STR_TEST'
s_uppe_isupper = s_uppe.isupper()
print(s_uppe_isupper)
print('s.join'.center(40, '-'))
# Splices elements in a sequence into a new string with the specified characters
strs = ['Powerful', 'strng', 'in', 'python']
strs_join = ' '.join(strs) # Specify the elements in the 'space splicing list
print(strs_join)
print('s.ljust'.center(40, '-'))
# Align the string to the left. When len (s) < width, the extra characters are empty by default. You can also specify to fill a single character
s_ljust = s.ljust(10, '*')
print(s_ljust)
print('s.lower'.center(40, '-'))
# Convert all strings to lowercase characters
s_lowe = 'I Like PYTHON'
s_lowe_lower = s_lowe.lower()
print(s_lowe_lower)
print('s.lstrip'.center(40, '-'))
# Delete the leading space, carriage return, tab, etc
s_lstr = ' \n\t\rstr_test'
s_lstr_lstrip = s_lstr.lstrip()
print(s_lstr_lstrip)
print('s.maketrans'.center(40, '-'))
# Returns a conversion table using translate. In the example, 's t e' and 'a B C' are mapping relationships. Each character corresponds to (s - > A, T - > b, e - > C), 'outtab' is used to replace 'intab' in the string to be processed. The third parameter is the character to be deleted
intab = "st"
outtab = "#$"
deltab = '_'
s_maketrans = s.maketrans(intab, outtab, deltab)
print(s_maketrans)
print('s.partition'.center(40, '-'))
# Search for the specified separator and return the part before the first separator, the first separator itself, and the part after the first separator
s_part = 'I like Python'
s_part_partition = s_part.partition(' ')
print(s_part_partition)
print('s.replace'.center(40, '-'))
# String replacement, ` replace(self, old, new, count=None) ` accepts the string to be replaced, the string after replacement, and the number of optional parameter replacement times. The default is to replace all
s_replace = s.replace('t', 'T', 1)
print(s_replace)
print('s.rfind'.center(40, '-'))
# Find the specified character in the string and return the maximum index if found, or - 1 if not found, or add the index range in the fragment specified string
s_rfind = s.rfind('t', 0, 8)
print(s_rfind)
print('s.rindex'.center(40, '-'))
# Find the specified character in the string and return the maximum index if found, or - 1 if not found, or add the index range in the fragment specified string
s_rindex = s.rindex('t', 0, 8)
print(s_rindex)
print('s.rjust'.center(40, '-'))
# Align the string to the right. When len (s) < width, the extra characters are empty by default. You can also specify to fill a single character
s_rjust = s.rjust(10, '*')
print(s_rjust)
print('s.rpartition'.center(40, '-'))
# Search for the specified separator and return the part before the last separator, the last separator itself, and the part after the last separator
s_part = 'I like Python'
s_part_rpartition = s_part.rpartition(' ')
print(s_part_rpartition)
print('s.rsplit'.center(40, '-'))
# Search from right to left, divide left and right into two elements with an element as the center and put them into the list. The maxplit parameter defaults to - 1, which means that all the segmentation characters are divided according to the specified segmentation character, ` maxplit = 1 ', that is, only one segmentation is performed according to the specified segmentation character. The effect and rpartition class are similar
s_rspl = 'I like python'
s_rspl_rsplit = s_rspl.rsplit(' ', 1)
print(s_rspl_rsplit)
print('s.rstrip'.center(40, '-'))
# Delete the space, carriage return, tab, etc. at the end of the string
s_rstr = ' str_test\n\t\r'
s_rstr_rstrip = s_rstr.rstrip()
print(s_rstr_rstrip)
print('s.split'.center(40, '-'))
# Search from left to right, divide left and right into two elements with an element as the center and put them into the list. The maxplit parameter defaults to - 1, which means that all the segmentation characters are divided according to the specified segmentation character, ` maxplit = 1 ', that is, only one segmentation is made according to the specified segmentation character. The effect and partition class are similar
s_spli = 'I like python'
s_spli_split = s_spli.split(' ', 1)
print(s_spli_split)
print('s.splitlines'.center(40, '-'))
# The line break ('\ r', '\r\n', \n ') is used as the split list. The parameter' keeps' defaults to False, excluding the line break. If it is True, the line break is retained
s_line = '''It's a nice day.
with beautiful mood.
and you
'''
s_line_splitlines = s_line.splitlines(True)
print(s_line_splitlines)
print('s.startswith'.center(40, '-'))
# Determines whether the beginning of the string is the specified string, returns True if it is True, otherwise returns False
s_startswith = s.startswith('str')
print(s_startswith)
print('s.strip'.center(40, '-'))
# Delete the spaces, carriage returns, tabs, etc. on the left and right sides of the string
s_stri = '\n\t\rstr_test\n\t\r'
s_stri_strip = s_stri.strip()
print(s_stri_strip)
print('s.swapcase'.center(40, '-'))
# Flip case characters in a string to small uppercase characters
s_swap = 'STR_test'
s_swap_swapcase = s_swap.swapcase()
print(s_swap_swapcase)
print('s.title'.center(40, '-'))
# Converts a string to a title string, which is capitalized for each word
s_titl = 'poerful string in python'
s_titl_title = s_titl.title()
print(s_titl_title)
print('s.translate'.center(40, '-'))
# Convert the characters of the string according to the table (including 256 characters) given by the parameter table, and put the characters to be filtered into the del parameter. Table table is transformed by maketrans method
s_translate = s.translate(s_maketrans)
print(s_translate)
print('s.upper'.center(40, '-'))
# Convert all strings to lowercase characters
s_uppe = 'STR_Test'
s_uppe_upper = s_uppe.upper()
print(s_uppe_upper)
print('s.z_fill'.center(40, '-'))
# When len (s) < width, fill with 0 from the left
s_zfill = s.zfill(10)
print(s_zfill)