I Basic knowledge of Request Library
| method | explain | Return object |
|---|---|---|
| .request () | Construction request | |
| .get() | GET HTML web page, corresponding to HTTP GET | The returned response object contains all the resources of the server |
| .head() | Get the page header information, corresponding to HEAD | |
| .post() | Submit POST request | |
| .put() | Submit request PUT | |
| .patch() | Submit local modification request, corresponding to PATCH | |
| .delete() | Submit a DELETE request, corresponding to DELETE |
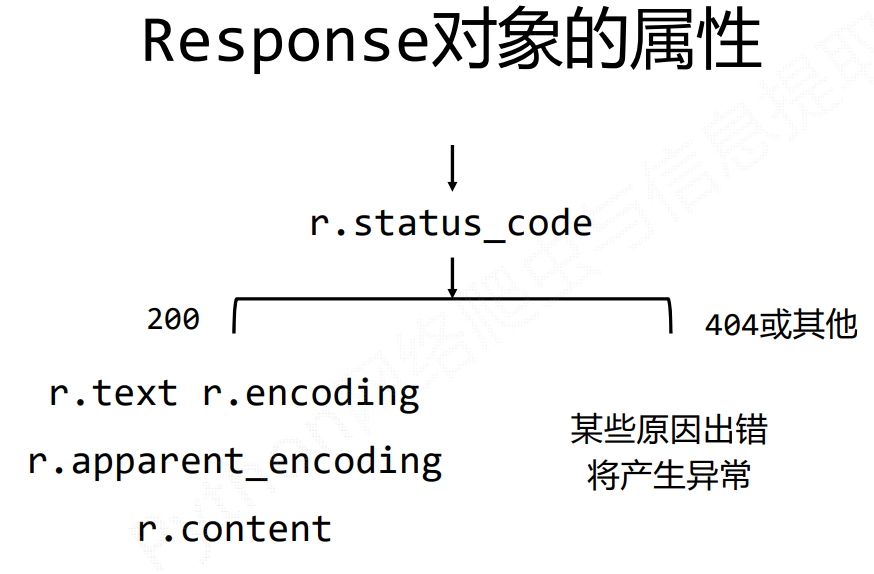
General framework for crawling pages:
try: r = requests.get(url,timeout = 30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "raise an exception"
II Loan data conversion and integration of Lending Club
1. Random sampling
loan.sample(frac=0.01) loan.sample(n=10,replace=True)
n specifies the quantity, frac specifies the proportional sampling, and axis can specify the column sampling
2. Data fusion
2.1 merge
left.merge(right,how='inner',on=None,left_on=None,right_on=None,left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), indicator=False)
give an example:
# 'user' based on user information data_ The variables' user 'and' outer 'are connected. test_user.merge(test_loan,how="inner",left_on="user_id",right_on="user")
Set the parameter indicator parameter to True, and the result is an additional column of merge.
2.2 join
left.join(right, on=None, how='left', lsuffix='', rsuffix='', sort=False)
Introduction to using join
data.sort_values(by='xxx') data.sort_index(by='xxx')
ascending defaults to the last missing value
2.3 data conversion
object type: str.strip('%') first, then PD to_ numeric(xxx)
3. Variable discretization
annual_inc=pd.cut(combine.annual_inc,bins=[np.min(combine.annual_inc)-1,np.percentile(combine.annual_inc,50),np.max(combine.annual_inc)+1],labels=['low','high'])
The bins parameter sets the split point
qcut is divided directly by frequency
4. Variable value replacement
Writing method 1:
combine['loan_status'].replace(to_replace=['Fully Paid','Current','Charged Off','In Grace Period','Late (31-120 days)'],value=[0,0,1,1,1],inplace=True)
Writing method 2:
test_loan.replace(to_replace={'loan_status':{'Fully Paid':0,'Charged Off':0,'In Grace Period':1}}
# You can also specify different variables
test_loan.replace(to_replace={'loan_status':'Fully Paid','grade':'A'},value='Good')
map
Numerical substitution only for a series
test_loan['loan_status'].map({'Fully Paid':0,'Charged Off':0,'In Grace Period':1})
Input function mapping
combine['int_rate'][:5]
def f(x):
if x < 12:
return 'Low'
else:
return 'High'
combine['int_rate'][:5].map(f)
5. Dummy variable (dummy variable) processing
Properties to be processed
cat_vars=['term','grade','emp_length','annual_inc','home_ownership','verification_stat us']
Cyclic processing
for var in cat_vars: car_list = pd.get_dummies(combine[var],prefix=var,drop_first=True) combine = combine.join(cat_list)
drop_ If first is set to True, the first dummy variable obtained will be deleted. This is because in modeling, k-1 variables are required to describe k-class classification variables. If K variables are used, there will be a problem of complete collinearity.
6. Add constant column
const = pd.Series([1]*combine.shape[0],name='const') X.reset_index(drop=True,inplace=True) X=pd.concat([const,X],axis=1) X.head()
Join is the method of DateFrame, X.join(const)
The object of concat is a list
III Planetary data grouping and aggregation
1. Data grouping
1.1 grouping method
Feature grouping
grouped = =planets.groupby('method')
array,list,series grouping
a=np.repeat([0,1],[500,535]) planets.groupby(a).mean()
Function grouping
new=plantes.set.index('year')
def test(x):
if x<2000:
return 'Before'2000
else:
return 'After 2000'
new.groupby(test).mean()
group_index=new.index.map(test)
new.groupby(group_index).mean()
1.2 group application
Get the required column grouped ['year']
View the median distance under different methods:
plants.groupby('method')['distance'].median()
The year becomes the corresponding year
decade = 10 * (planets['year'] // 10) decade = decade.astype(str) + 's' decade[:5]
Group by method and age
plants.groupby(['method',decade])['number'].sum()
Use unstack to split the hierarchical index into new column indexes, and use fillna to fill the missing values with 0.
planets.groupby(['method', decade])['number'].sum().unstack().fillna(0)
2. Analyze Planetary Data
2.1GroupBy.apply
grouped.apply(lambda x:.....) grouped.apply(func)
Relatively slow
2.2GroupBy.agg
Calculate the average distance of planets discovered by various methods and the sum of the number of planets discovered
grouped.agg({'distance':'mean','number':'sum'})
grouped.agg({'distance':['min','max','mean','median'],'number':'sum'})
You can also customize functions
apply is to perform an operation on each group of data and the entire DataFrame.
agg calculates each feature in each set of data.
① Perform a function on each column in each set of data
② Merge the returned results of each column
③ Merge the returned results of each set of data
2.3GroupBy.transform
Use transform to standardize grouped data (data with the same dimension of grouped data):
grouped.transform(lambda x:x(x-x.mean())/x.std()).head()
You cannot use dictionary style to specify features for function operations