Summary of Python crawler common libraries: requests, beatifulsoup, selenium, xpath summary

Remember to install fast third-party libraries. Python often needs to install third-party libraries. The original download speed is very slow, and it is very fast to use domestic images
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple package name
Official website:
- Requests: make HTTP service human
- Beautiful Soup 4.4.0 documentation
- Selenium official website
- lxml - XML and HTML with Python
requests
requests official document https://docs.python-requests.org/zh_CN/latest/

To crawl, we must first request the website. At this time, we need to use our requests module. Requests is an HTTP client library of python, similar to urllib and urllib 2. The requests module syntax is simpler than urllib and urllib 2. As his official website said:

Introduction to requests module
Send http request to get response data
The requests module is a third-party module that needs to be installed in your python (virtual) environment
pip/pip3 install requests
requests Basics
The requests module sends get requests
#https://beishan.blog.csdn.net/ import requests # Destination url url = 'https://www.baidu.com' # Send get request to target url response = requests.get(url) # Print response content print(response.text)
Response response object
Observe the running results of the above code and find that there are a lot of random codes; This is because the character sets used in encoding and decoding are different; We try to use the following methods to solve the problem of Chinese garbled code
import requests url = 'https://www.baidu.com' # Send get request to target url response = requests.get(url) # Print response content # print(response.text) print(response.content.decode()) # Pay attention here!
- response.text is the result of decoding by the requests module according to the encoded character set inferred by the chardet module
- All strings transmitted over the network are bytes, so response text = response. content. Decode ('inferred coded character set ')
- We can search charset in the web source code, try to refer to the coded character set, and pay attention to the inaccuracy
response.text and response Difference of content
- response.text
- Type: str
- Decoding type: the requests module automatically infers the encoding of the response according to the HTTP header, and infers the text encoding
- response.content
- Type: bytes
- Decoding type: not specified
Solve Chinese garbled code
Through the response Content is decode d to solve Chinese garbled code
- response.content.decode() default utf-8
- response.content.decode("GBK")
- Common coded character sets
- utf-8
- gbk
- gb2312
- ascii (pronunciation: ask code)
- iso-8859-1
Other common properties or methods of the response object
#https://beishan.blog.csdn.net/ # 1.2.3-response other common attributes import requests # Destination url url = 'https://www.baidu.com' # Send get request to target url response = requests.get(url) # Print response content # print(response.text) # print(response.content.decode()) # Pay attention here! print(response.url) # Print the url of the response print(response.status_code) # Print the status code of the response print(response.request.headers) # Print the request header of the response object print(response.headers) # Print response header print(response.request._cookies) # Print the cookies carried by the request print(response.cookies) # Print the cookies carried in the response
requests practice
The requests module sends requests
Send request with header
We first write a code to get Baidu home page
import requests url = 'https://www.baidu.com' response = requests.get(url) print(response.content.decode()) # Print the request header information in response to the corresponding request print(response.request.headers)
Copy the user agent from the browser and construct the headers dictionary; After completing the following code, run the code to see the results
import requests
url = 'https://www.baidu.com'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# Bring the user agent in the request header to simulate the browser to send the request
response = requests.get(url, headers=headers)
print(response.content)
# Print request header information
print(response.request.headers)
Send request with parameters
When we use Baidu search, we often find that there is one in the url address?, After the question mark is the request parameter, also known as the query string
Carry parameters in the url and directly initiate a request for the url containing parameters
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
url = 'https://www.baidu.com/s?wd=python'
response = requests.get(url, headers=headers)
Carry parameter dictionary through params
1. Build request parameter dictionary
2. When sending a request to the interface, bring the parameter dictionary, which is set to params
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# This is the target url
# url = 'https://www.baidu.com/s?wd=python'
# Is there a question mark in the end? The results are the same
url = 'https://www.baidu.com/s?'
# The request parameter is a dictionary, namely wd=python
kw = {'wd': 'python'}
# Initiate a request with request parameters and obtain a response
response = requests.get(url, headers=headers, params=kw)
print(response.content)
- Copy user agent and cookies from browser
- The request header fields and values in the browser must be consistent with those in the headers parameter
- The value corresponding to the Cookie key in the headers request parameter dictionary is a string
import requests
url = 'https://github.com/USER_NAME'
# Construct request header dictionary
headers = {
# User agent copied from browser
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
# Cookie s copied from the browser
'Cookie': 'xxx Here is a copy cookie character string'
}
# The cookie string is carried in the request header parameter dictionary
resp = requests.get(url, headers=headers)
print(resp.text)
Use of timeout parameter
In the process of surfing the Internet, we often encounter network fluctuations. At this time, a request waiting for a long time may still have no result.
In the crawler, if a request has no result for a long time, the efficiency of the whole project will become very low. At this time, we need to force the request to return the result within a specific time, otherwise it will report an error.
-
How to use the timeout parameter timeout
response = requests.get(url, timeout=3)
-
timeout=3 means that the response will be returned within 3 seconds after the request is sent, otherwise an exception will be thrown
import requests url = 'https://twitter.com' response = requests.get(url, timeout=3) # Set timeout
requests is the method to send a post request
-
response = requests.post(url, data)
-
The data parameter receives a dictionary
-
The other parameters of the post request function sent by the requests module are exactly the same as those of the get request
BeautifulSoup
Official documentation of beautiful soup https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
Beautiful Soup is a Python library that can extract data from HTML or XML files It can realize the usual way of document navigation, searching and modifying through your favorite converter Beautiful Soup will help you save hours or even days of working time

Advantages and disadvantages of common interpreters
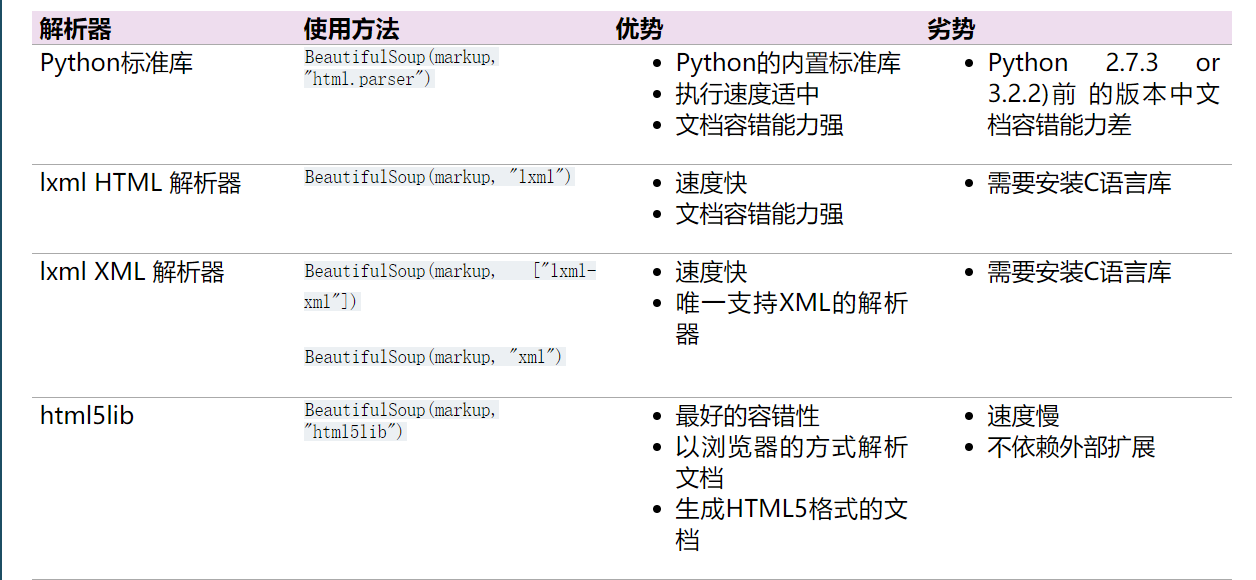
Common operation
Installation method
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple beautifulsoup4
Just import
from bs4 import BeautifulSoup
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """
soup = BeautifulSoup(html_doc,"lxml")
Several simple ways to browse structured data
soup.title
<title>The Dormouse's story</title>
soup.title.name
'title'
soup.title.string
"The Dormouse's story"
soup.title.text
"The Dormouse's story"
soup.title.parent.name
'head'
soup.p
<p class="title"><b>The Dormouse's story</b></p>
soup.p.name
'p'
soup.p["class"]
['title']
soup.a
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
soup.find("a")
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
soup.find_all("a")
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Find links to all < a > tags in the document
for link in soup.find_all("a"):
print(link.get("href"))
http://example.com/elsie http://example.com/lacie http://example.com/tillie
Get all text content in the document
print(soup.get_text())
The Dormouse's story The Dormouse's story Once upon a time there were three little sisters; and their names were Elsie, Lacie and Tillie; and they lived at the bottom of a well. ...
Get through tags and attributes
- Tag has many methods and properties, which are explained in detail in traversing the document tree and searching the document tree Now let's introduce the most important attributes in tag: name and attributes
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
tag = soup.b
tag
<b class="boldest">Extremely bold</b>
type(tag)
bs4.element.Tag
Name property
- Each tag has its own name, through Name to get:
tag.name
'b'
- If you change the name of the tag, it will affect all HTML documents generated through the current Beautiful Soup object
tag.name = "blockquote" tag
<blockquote class="boldest">Extremely bold</blockquote>
Multiple attributes
- A tag may have many attributes Tag has a "class" attribute with a value of "boldest" The operation method of tag attribute is the same as that of Dictionary:
tag["class"]
['boldest']
tag.attrs
{'class': ['boldest']}
- Tag properties can be added, deleted or modified Again, the tag attribute operates in the same way as a dictionary
tag["class"] = "verybold" tag["id"] = 1 tag
<blockquote class="verybold" id="1">Extremely bold</blockquote>
del tag["class"] tag
<blockquote id="1">Extremely bold</blockquote>
Multivalued attribute
css_soup = BeautifulSoup('<p class="body strikeout"></p>')
css_soup.p['class']
['body', 'strikeout']
css_soup = BeautifulSoup('<p class="body"></p>')
css_soup.p['class']
['body']
Traversable string
- Strings are often contained in tags Beautiful Soup wraps the string in tag with NavigableString class:
tag.string
'Extremely bold'
type(tag.string)
bs4.element.NavigableString
-
A NavigableString string is the same as the Unicode string in Python,
It also supports some features included in traversing and searching the document tree
The NavigableString object can be directly converted into a Unicode string through the unicode() method: -
The string contained in tag cannot be edited, but it can be replaced with other strings. Use replace_with() method
tag.string.replace_with("No longer bold")
tag
<blockquote id="1">No longer bold</blockquote>
Comments and special strings
- Comment section of the document
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>" soup = BeautifulSoup(markup) comment = soup.b.string comment
'Hey, buddy. Want to buy a used parser?'
type(comment)
bs4.element.Comment
- The Comment object is a special type of NavigableString object:
comment
'Hey, buddy. Want to buy a used parser?'
However, when it appears in an HTML document, the Comment object will output in a special format:
print(soup.prettify())
<html> <body> <b> <!--Hey, buddy. Want to buy a used parser?--> </b> </body> </html>
from bs4 import CData
cdata = CData("A CDATA block")
comment.replace_with(cdata)
print(soup.b.prettify())
<b> <![CDATA[A CDATA block]]> </b>
Traverse the document tree
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc,"html.parser")
Child node
A Tag may contain multiple strings or other tags, which are the child nodes of the Tag Beautiful Soup provides many operations and traversal properties of child nodes
soup.head
<head><title>The Dormouse's story</title></head>
soup.title
<title>The Dormouse's story</title>
This is a trick to get the tag. You can call this method multiple times in the tag of the document tree The following code can get the first tag in the tag:
soup.body.b
<b>The Dormouse's story</b>
Only the first tag of the current name can be obtained by clicking the attribute:
soup.a
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
find_all method
If you want to get all the tags or get more content than a tag by name, you need to use the method described in Searching the tree, such as find_all()
soup.find_all("a")
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
. contents and children
head_tag = soup.head head_tag
<head><title>The Dormouse's story</title></head>
head_tag.contents
[<title>The Dormouse's story</title>]
head_tag.contents[0]
<title>The Dormouse's story</title>
head_tag.contents[0].contents
["The Dormouse's story"]
selenium

selenium official documents https://www.selenium.dev/selenium/docs/api/py/api.html
selenium introduction
Running effect of chrome browser
After downloading the chrome driver and installing the selenium module, execute the following code and observe the running process
from selenium import webdriver
# If the driver is not added to the environment variable, you need to assign the absolute path of the driver to executable_path parameter
# driver = webdriver.Chrome(executable_path='/home/worker/Desktop/driver/chromedriver')
# If the driver adds an environment variable, you do not need to set executable_path
driver = webdriver.Chrome()
# Make a request to a url
driver.get("http://www.itcast.cn/")
# Save the web page as a picture, and Google browsers above 69 will not be able to use the screenshot function
# driver.save_screenshot("itcast.png")
print(driver.title) # Print page title
# Exit simulation browser
driver.quit() # Be sure to quit! If you don't quit, there will be residual processes!
The running effect of phantomjs no interface browser
Phantom JS is a Webkit based "headless" browser that loads websites into memory and executes JavaScript on pages. Download address: http://phantomjs.org/download.html
from selenium import webdriver
# Specifies the absolute path of the driver
driver = webdriver.PhantomJS(executable_path='/home/worker/Desktop/driver/phantomjs')
# driver = webdriver.Chrome(executable_path='/home/worker/Desktop/driver/chromedriver')
# Make a request to a url
driver.get("http://www.itcast.cn/")
# Save web pages as pictures
driver.save_screenshot("itcast.png")
# Exit simulation browser
driver.quit() # Be sure to quit! If you don't quit, there will be residual processes!
Usage scenarios of headless browser and headless browser
- Usually during the development process, we need to view various situations in the running process, so we usually use a header browser
- When the project is completed and deployed, the system usually adopted by the platform is the server version of the operating system. The server version of the operating system must use the headless browser to operate normally
Function and working principle of selenium
Using the browser's native API, it is encapsulated into a set of more object-oriented Selenium WebDriver API to directly operate the elements in the browser page and even the browser itself (screen capture, window size, start, close, install plug-ins, configure certificates, etc.)
selenium installation and simple use
Take edge browser as an example. See this blog. The same is true for driving chrome browser
selenium driven edge browser
- Configuration of chromedriver environment
- In windows environment, it is necessary to add chromedriver Set the directory where exe is located as the path in the path environment variable
- Under linux/mac environment, set the directory where the chromedriver is located to the PATH environment value of the system
Simple use of selenium
Next, we simulate Baidu search through code
import time
from selenium import webdriver
# Instantiate the driver object by specifying the path of the chromedriver, which is placed in the current directory.
# driver = webdriver.Chrome(executable_path='./chromedriver')
# chromedriver has added environment variables
driver = webdriver.Chrome()
# Control browser access url address
driver.get("https://www.baidu.com/")
# Search 'python' in Baidu search box
driver.find_element_by_id('kw').send_keys('python')
# Click 'Baidu search'
driver.find_element_by_id('su').click()
time.sleep(6)
# Exit browser
driver.quit()
- webdriver. The executable parameter in Chrome (executable_path = '. / chromedriver') specifies the path of the downloaded chromedriver file
- driver.find_element_by_id('kw').send_keys('python ') locates the tag whose ID attribute value is' kW' and enters the string 'Python' into it
- driver.find_element_by_id('su').click() locate the tag whose ID attribute value is Su, and click
- The click function is used to trigger the js click event of the tag
The value is the label of 'kw' and the string 'python' is entered into it
- driver.find_element_by_id('su').click() locate the tag whose ID attribute value is Su, and click
- The click function is used to trigger the js click event of the tag
Use xpath to extract data, a simple syntax for crawling data.
lxml

requests official document https://lxml.de/
pip install lxml
- Import module
from lxml import etree
- Use xpath to get text or href content
/li/a/@href This should be href Content of /li/a/text() This is text content
Use of etree
h=etree.HTML(response.text)#response.text is the source code of the web page
h.xpath('//IMG ') # find all img nodes,
h.xpath('//div').xpath('.//img') # finds all img nodes under all divs
Syntax of xpath
Symbol
XPath uses path expressions to select nodes in XML documents. Nodes are selected along the path or step.
| expression | describe |
|---|---|
| / | Select from root node |
| // | Selects nodes in the document from the current node that matches the selection, regardless of their location. |
| . | Select the current node. |
| . . | Select the parent node of the current node. |
| @ | Select properties. |
| | | Select from two nodes |
| () | Use () to include| |
| * | Include all elements |
| not | Reverse |
example
| Path expression | result |
|---|---|
| bookstore | Select all child nodes of the bookstore element. |
| /bookstore | Select the root element bookstore. Note: if the path starts with a forward slash (/), the path always represents the absolute path to an element! |
| bookstore/book | Select all book elements that belong to the child elements of the bookstore. |
| //book | Select all book child elements regardless of their location in the document. |
| bookstore//book | Select all book elements that are descendants of the bookstore element, regardless of where they are located under the bookstore. |
| //@lang | Select all properties named lang. |
| //*[@class] | Select all elements with the class attribute |
| //div[@*] | div element that matches any attribute |
| //a[not(@class)] | Matches an a element without a class attribute |
predicate
Path expression with predicate
| Path expression | result |
|---|---|
| /bookstore/book[1] | Select the first book element that belongs to the bookstore child element. |
| /bookstore/book[last()] | Select the last book element that belongs to the bookstore child element. |
| /bookstore/book[last()-1] | Select the penultimate book element that belongs to the bookstore child element. |
| /bookstore/book[position()< 3] | Select the first two book elements that belong to the child elements of the bookstore element. |
| //title[@lang] | Select all title elements that have an attribute named lang. |
| //title[@lang='eng'] | Select all title elements that have a lang attribute with a value of eng. |
| /bookstore/book[price>35.00] | Select all book elements of the bookstore element, and the value of the price element must be greater than 35.00. |
| /bookstore/book[price>35.00]/title | Select all title elements of the book element in the bookstore element, and the value of the price element must be greater than 35.00. |

It's over here, if it helps you. Of course, there is no end to learning. These are just the basis of reptiles. You need to explore more postures yourself. https://beishan.blog.csdn.net/