1. Common current limiting algorithms
1.1 counter algorithm
Count the number of requests allowed to pass over a period of time. For example, qps is 100, that is, the number of requests allowed to pass in 1s is 100. Add 1 to each request counter. If the request is rejected more than 100, the counter will clear after 1s, and the counter will be counted again. This kind of flow restriction is violent. If there are 100 requests coming in the first 10 ms, the remaining 990 MS can only watch the requests filtered out, and it can't smooth these requests, so it's easy to appear the so-called "spike phenomenon".
The flow chart of counter algorithm is as follows
1.2 leaky bucket algorithm
When the request arrives, it will be put into the leaky bucket first, and then the leaky bucket will release the request at a constant speed. If the incoming request exceeds the capacity of the leaky bucket, the request will be rejected. Although this can avoid "stabbing phenomenon", too smooth can not cope with short-term sudden traffic.
Specific implementation can take the arrival of the request into the queue, and then another thread from the queue at a constant speed out of the request release.
1.3 token bucket algorithm
Suppose there is a bucket, and a token will be put into the bucket at a certain rate. Each time a request comes, it will go to the bucket to get the token. If it is obtained, it will be released. If it is not obtained, it will wait until the token is obtained. For example, the token will be put into the bucket at a speed of 100 per second. After the token bucket is initialized, there are 100 tokens in the bucket. If a large number of requests come, it will consume 100 tokens immediately. The rest of the requests wait and are eventually released in a uniform manner. The advantage of this algorithm is that it can deal with both transient traffic and smooth requests.
Flow chart of token bucket flow restriction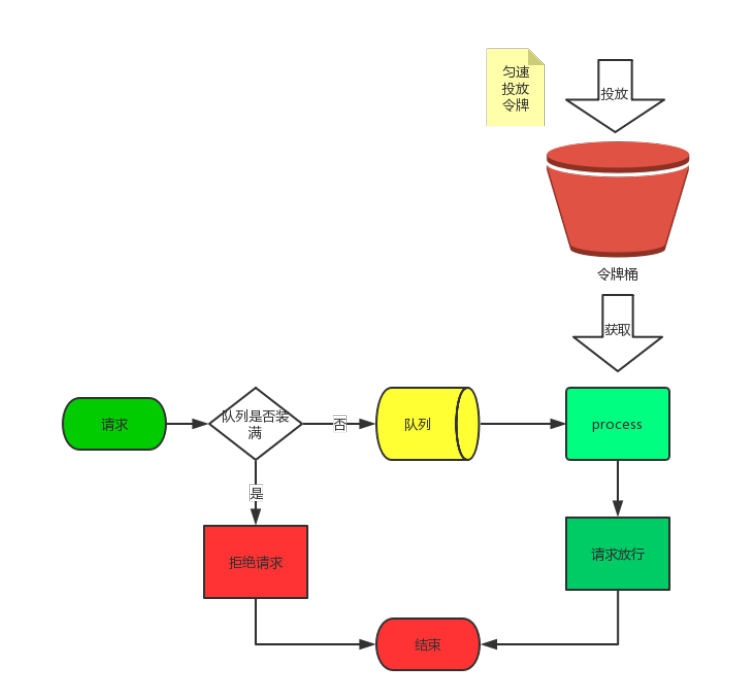
2. Analysis of current limiting principle of gateway
2.1 analysis of current limiting principle of sping cloud gateway
Core current limiting class: org.springframework.cloud.gateway.filter.ratelimit.redisratelimit
The core methods are as follows:
public Mono<Response> isAllowed(String routeId, String id) { if (!this.initialized.get()) { throw new IllegalStateException("RedisRateLimiter is not initialized"); } Config routeConfig = loadConfiguration(routeId); //Token bucket average delivery rate int replenishRate = routeConfig.getReplenishRate(); //Barrel capacity int burstCapacity = routeConfig.getBurstCapacity(); try { //Get current limit key List<String> keys = getKeys(id); //Assemble the execution parameters of lua script. The first parameter is the token release rate, the second parameter is the bucket capacity, the third parameter is the current timestamp, and the fourth parameter is the number of tokens to be obtained. List<String> scriptArgs = Arrays.asList(replenishRate + "", burstCapacity + "", Instant.now().getEpochSecond() + "", "1"); //Get the token through lua script and redis interaction, and return the array. The first element of the array represents whether to get success (1 succeeds and 0 fails), and the second parameter represents the number of remaining tokens. Flux<List<Long>> flux = this.redisTemplate.execute(this.script, keys, scriptArgs); //If the token acquisition is abnormal, the default setting is to obtain the results [1, - 1]. Considering that the token acquisition is successful by default and the remaining tokens - 1, current limiting control is not required. return flux.onErrorResume(throwable -> Flux.just(Arrays.asList(1L, -1L))) .reduce(new ArrayList<Long>(), (longs, l) -> { longs.addAll(l); return longs; }).map(results -> { boolean allowed = results.get(0) == 1L; Long tokensLeft = results.get(1); Response response = new Response(allowed, getHeaders(routeConfig, tokensLeft)); if (log.isDebugEnabled()) { log.debug("response: " + response); } return response; }); } catch (Exception e) { log.error("Error determining if user allowed from redis", e); } return Mono.just(new Response(true, getHeaders(routeConfig, -1L))); }
The gateway current limiting lua script is implemented as follows:
lua script analysis and remarks are as follows:
--Number of tokens left in token bucket key local tokens_key = KEYS[1] --Token bucket last fill time key local timestamp_key = KEYS[2] --Rate of token put into token bucket local rate = tonumber(ARGV[1]) --Token bucket size local capacity = tonumber(ARGV[2]) --Current data stamp local now = tonumber(ARGV[3]) --Number of tokens requested local requested = tonumber(ARGV[4]) --Calculate the time required for token bucket filling local fill_time = capacity/rate --Ensure sufficient time local ttl = math.floor(fill_time*2) --Obtain redis Number of tokens remaining in local last_tokens = tonumber(redis.call("get", tokens_key)) if last_tokens == nil then last_tokens = capacity end --Obtain redis Last token update time in local last_refreshed = tonumber(redis.call("get", timestamp_key)) if last_refreshed == nil then last_refreshed = 0 end local delta = math.max(0, now-last_refreshed) --Calculate that it needs to be updated redis Number of token buckets in (number of tokens that need to be released in the past time interval+Barrel remaining token) local filled_tokens = math.min(capacity, last_tokens+(delta*rate)) local allowed = filled_tokens >= requested local new_tokens = filled_tokens local allowed_num = 0 --After consuming the token, recalculate that it needs to be updated redis Number of tokens in cache if allowed then new_tokens = filled_tokens - requested allowed_num = 1 end --Exclusive update redis Number of tokens remaining in redis.call("setex", tokens_key, ttl, new_tokens) --Exclusive update redis Latest token update time in redis.call("setex", timestamp_key, ttl, now) return { allowed_num, new_tokens }
The flow chart of implementing token bucket algorithm through redis in spring cloud gateway is as follows
Conclusion: the token bucket algorithm is implemented by redis, which supports the cluster flow restriction, but the speed limit has an upper limit. After all, it takes a long time to interact with redis. Although the flow restriction without lock can improve the throughput of the gateway, it does not meet the thread safety in practice, and there is a problem, such as the bucket size of 10, the rate of putting tokens into the bucket is 100/1s, when the tokens in the bucket are consumed, this is the case. When two normal requests, q1 and q2, enter the gateway at the same time. If q1 just gets the new token to be released, q2 needs another 10ms to get the new token. Because the interval between the two requests is very short < 10ms, q2 can not get the token in the bucket and is blocked as an overspeed request. As a result, the gateway does not wait for the request after the bucket is consumed.
test
Set the token bucket size to 5 and the delivery rate to 10/s. The configuration is as follows
server: port: 8081 spring: cloud: gateway: routes: - id: limit_route uri: http://localhost:19090 predicates: - After=2017-01-20T17:42:47.789-07:00[America/Denver] filters: - name: RequestRateLimiter args: key-resolver: '#{@uriKeyResolver}' redis-rate-limiter.replenishRate: 10 redis-rate-limiter.burstCapacity: 5 application: name: gateway-limiter
Now use jmeter to simulate 10 concurrent requests, and check the number of requests that can pass normally.
Operation result:
According to the printing results, 10 requests were blocked by 5 requests. In practice, 10 requests may be normal requests, but not more than 10qps are intercepted.
2.2 analysis of zuul ratelimit principle of spring cloud zuul gateway
Zuul ratelimt supports memory and redis current limiting, which is realized by counter algorithm, that is, after consuming a specified number of tokens in the window time, the number of tokens consumed is 0 after refreshing the window time.
The core code is as follows:
public class RateLimitFilter extends ZuulFilter { public static final String LIMIT_HEADER = "X-RateLimit-Limit"; public static final String REMAINING_HEADER = "X-RateLimit-Remaining"; public static final String RESET_HEADER = "X-RateLimit-Reset"; private static final UrlPathHelper URL_PATH_HELPER = new UrlPathHelper(); private final RateLimiter rateLimiter; private final RateLimitProperties properties; private final RouteLocator routeLocator; private final RateLimitKeyGenerator rateLimitKeyGenerator; @Override public String filterType() { return "pre"; } @Override public int filterOrder() { return -1; } @Override public boolean shouldFilter() { return properties.isEnabled() && policy(route()).isPresent(); } public Object run() { final RequestContext ctx = RequestContext.getCurrentContext(); final HttpServletResponse response = ctx.getResponse(); final HttpServletRequest request = ctx.getRequest(); final Route route = route(); policy(route).ifPresent(policy -> //Generate current limiting key final String key = rateLimitKeyGenerator.key(request, route, policy); //Execute the core flow limiting method, and return the number of remaining available tokens. If rate.retaining < 0, the flow limit has been exceeded. final Rate rate = rateLimiter.consume(policy, key); response.setHeader(LIMIT_HEADER, policy.getLimit().toString()); response.setHeader(REMAINING_HEADER, String.valueOf(Math.max(rate.getRemaining(), 0))); response.setHeader(RESET_HEADER, rate.getReset().toString()); if (rate.getRemaining() < 0) { ctx.setResponseStatusCode(TOO_MANY_REQUESTS.value()); ctx.put("rateLimitExceeded", "true"); throw new ZuulRuntimeException(new ZuulException(TOO_MANY_REQUESTS.toString(), TOO_MANY_REQUESTS.value(), null)); } }); return null; } }
The core current limiting method ratelimiter.consumer (policy, key) code is as follows:
public abstract class AbstractCacheRateLimiter implements RateLimiter { @Override public synchronized Rate consume(Policy policy, String key, Long requestTime) { final Long refreshInterval = policy.getRefreshInterval(); final Long quota = policy.getQuota() != null ? SECONDS.toMillis(policy.getQuota()) : null; final Rate rate = new Rate(key, policy.getLimit(), quota, null, null); calcRemainingLimit(policy.getLimit(), refreshInterval, requestTime, key, rate); return rate; } protected abstract void calcRemainingLimit(Long limit, Long refreshInterval, Long requestTime, String key, Rate rate); } @Slf4j @RequiredArgsConstructor @SuppressWarnings("unchecked") public class RedisRateLimiter extends AbstractCacheRateLimiter { private final RateLimiterErrorHandler rateLimiterErrorHandler; private final RedisTemplate redisTemplate; @Override protected void calcRemainingLimit(final Long limit, final Long refreshInterval, final Long requestTime, final String key, final Rate rate) { if (Objects.nonNull(limit)) { long usage = requestTime == null ? 1L : 0L; Long remaining = calcRemaining(limit, refreshInterval, usage, key, rate); rate.setRemaining(remaining); } } private Long calcRemaining(Long limit, Long refreshInterval, long usage, String key, Rate rate) { rate.setReset(SECONDS.toMillis(refreshInterval)); Long current = 0L; try { current = redisTemplate.opsForValue().increment(key, usage); // Redis returns the value of key after the increment, check for the first increment, and the expiration time is set if (current != null && current.equals(usage)) { handleExpiration(key, refreshInterval); } } catch (RuntimeException e) { String msg = "Failed retrieving rate for " + key + ", will return the current value"; rateLimiterErrorHandler.handleError(msg, e); } return Math.max(-1, limit - current); } private void handleExpiration(String key, Long refreshInterval) { try { this.redisTemplate.expire(key, refreshInterval, SECONDS); } catch (RuntimeException e) { String msg = "Failed retrieving expiration for " + key + ", will reset now"; rateLimiterErrorHandler.handleError(msg, e); } } }
Summary: have you noticed that the synchronized lock is added in front of the current limiting method. Although thread safety is guaranteed, there is a problem here. If the current limiting method takes 2ms to execute, that is, the lock holding time is too long (mainly the interaction time with redis), the throughput of the whole network will not exceed 500qps. Therefore, when using redis as the current limiting method, it is recommended to do key lock by key. Each key lock is recommended. The current limiting keys do not affect each other, which not only ensures the security of current limiting, but also improves the throughput of gateway. It is not necessary to consider this problem when using memory as current limiter, because the local current limiter has a short holding time, that is, the current limiter method is serial, but it can also have a high throughput. Zuul ratelimt current limiter algorithm uses counter current limiter, which has a common problem and can not avoid "sudden stab".
2.3 Guava RateLimiter for smooth current limiting
Guava RateLimiter provides the implementation of token bucket algorithm: smooth burst and smooth warming up. The code implementation sequence is as follows:
test
Smooth preheating current limiting, qps is 10, take a look at the time-consuming situation of taking 10 tokens in turn
/** * Smooth preheating up */ public class SmoothWarmingUp { public static void main(String[] args) { RateLimiter limiter = RateLimiter.create(10, 1000, TimeUnit.MILLISECONDS); for(int i = 0; i < 10;i++) { //Get a token System.out.println(limiter.acquire(1)); } } }
Run result: returns the waiting time of the thread

Smooth burst current limiting
/* Smooth burst */ public class SmoothBurstyRateLimitTest { public static void main(String[] args) { //QPS = 5, 5 requests allowed per second RateLimiter limiter = RateLimiter.create(5); //Time taken by limiter.acquire() to get token, in seconds System.out.println(limiter.acquire()); System.out.println(limiter.acquire()); System.out.println(limiter.acquire()); System.out.println(limiter.acquire()); System.out.println(limiter.acquire()); System.out.println(limiter.acquire()); } }
Operation result:
Conclusion: the main idea of guava current limiting is to calculate the waiting time of the next available token, to de sleep the thread, and obtain the token successfully by default after the end of sleep. The smooth preheating algorithm SmoothWarmingUp is also similar, but the rate of obtaining the token at the beginning of calculation is lower than that of setting the current limiting rate, and finally tends to the current limiting rate slowly. SmoothWarmingUp current restriction is not suitable for medium and low frequency current restriction. In conventional application current restriction, for example, we set the speed limit of guava to 100qps, and three normal requests (q1, q2 and q3) come at the same time point, then q1 will be forced to wait for 10ms, q2 will be forced to wait for 20ms, q3 will be forced to wait for 30ms. This situation often occurs in the application scenarios except for high concurrency. Applications continue to have high concurrency. There are not many normal requests in a short time, but they are forced to wait for a certain time, which reduces the response speed of the request. In this scenario, the algorithm appears too smooth, or it is mainly suitable for high concurrent application scenarios such as seckill. Smoothburst does not limit the flow. It has the concept of "bucket". Before the token in the bucket is taken, the speed will not be limited. The bucket size limits the flow rate and does not support automatic bucket size adjustment.
3. Comparison of current limiting functions of gateway

Self write current restriction target: in order to ensure the thread safety of current restriction algorithm and improve the throughput of gateway, my ratelimit gateway uses key lock to limit current, and the current restriction between different keys does not affect each other. In order to meet the multi business scenarios, my ratelimit supports user-defined flow restriction dimensions, multi-dimensional flow restriction, multi-dimensional free arrangement and combination flow restriction, self selected flow restriction algorithm and warehouse type.
4. Self writing token bucket current limiting algorithm
4.1 the flow chart of current limiting algorithm based on memory token bucket is as follows:

Summary: the core idea of my ratelimit token bucket flow restriction algorithm: each request will be put in token first, and the number of put in is calculated by multiplying the current time period from the last time of putting in by the current rate limit. The number of put in may be 0, and then go to the bucket to get the token after putting in. If the token is obtained, the request will be released. If there is no token, the line will be opened. The program enters the AQS synchronization queue until a token is generated and then wakes the threads in the queue in turn to obtain the token. In the actual business scenario, there are not many high-frequency time periods, most of which are low-frequency requests. In order to improve the response speed of the request as much as possible and meet the low-frequency "unlimited flow" and high-frequency smooth flow limit indicators, the newly arrived request will not enter the AQS synchronization queue first, but go to get the token first. When the token cannot be obtained, it means that the flow in this period is relatively large, and then enter the queue to wait for obtaining. The token achieves the purpose of smooth current limiting. In addition, a judgment is added before the incoming request, that is, if the waiting queue size has reached the current limiting rate limit, it means that the request in this period has exceeded the speed limit, and the customer directly refuses the request.
4.2 test
In order to test the time-consuming situation of the current limiting algorithm itself, a single thread is used to test first, and the token generated per second is set to 10w, and the bucket size is 1. How long does it take to get these tokens smoothly?
Test code:
public static void singleCatfishLimit(long permitsRatelimit) throws InterruptedException { RateLimitPermit rateLimitPermit = RateLimitPermit.create(1,permitsRatelimit,1); int hastoken=0; long start =System.nanoTime(); for(int i=0 ; i < permitsRatelimit*1 ; i++){ if(rateLimitPermit.acquire()>=0){ hastoken++; } } System.out.println("catfishLimit use time:"+(NANOSECONDS.toMillis(System.nanoTime()-start-SECONDS.toNanos(1) ) ) + " ms" ); System.out.println("single thread hold Permit:"+hastoken); } public static void main(String[] args) throws Exception { singleCatfishLimit(100000); //guavaLimit(); //multCatfishLimit(2000,10000); }
Operation result:

Note: it took 115ms to get the 10w token smoothly, and the average execution time of current limiting logic was about 1 microsecond, almost negligible.
Next, test the multithreading situation, set 2000 concurrent requests, 10000 current limiting qps, and test time.
public static void multCatfishLimit(int threadCount ,long permitsRatelimit) throws InterruptedException { CountDownLatch countDownLatch=new CountDownLatch(threadCount); AtomicInteger hastoken= new AtomicInteger(0); CyclicBarrier cyclicBarrier= new CyclicBarrier(threadCount); RateLimitPermit rateLimitPermit = RateLimitPermit.create(1,permitsRatelimit,1); AtomicLong startTime= new AtomicLong(0); for (int i = 0; i < threadCount; i++) { Thread thread=new Thread(()->{ try { cyclicBarrier.await(); } catch (InterruptedException e) { e.printStackTrace(); } catch (BrokenBarrierException e) { e.printStackTrace(); } startTime.compareAndSet(0,System.nanoTime()); for (int j = 0; j < 1; j++) { if( rateLimitPermit.acquire()>=0){ hastoken.incrementAndGet(); } } countDownLatch.countDown(); },"ratelimit-"+i); thread.start(); } countDownLatch.await(); System.out.println("catfishLimit use time:"+ (long)( NANOSECONDS.toMillis( System.nanoTime()-startTime.get() ) -Math.min(hastoken.get()*1.0/permitsRatelimit*1000L, threadCount*1.0/permitsRatelimit * SECONDS.toMillis(1)) )+" ms"); System.out.println("mult thread hold Permit:"+hastoken.get()); } public static void main(String[] args) throws Exception { singleCatfishLimit(100000); //guavaLimit(); multCatfishLimit(2000,10000); }
Operation result:
Note: when the qps is 1w, it takes 127ms for 2000 threads to get the token. This is why. In fact, the concurrent requests are controlled by cyclicBarrier. When the number of requests does not reach 2000, they enter wait. When they reach 2000, they enter signalAll. There is a time difference in the wake-up thread. It is difficult to control multiple threads to execute at the same time point by program. The statistics show that There is an error in the time of.
When qps is 100, it takes 2000 requests to get tokens at the same time, and how many tokens can be obtained
public static void main(String[] args) throws Exception { // singleCatfishLimit(100000); //guavaLimit(); multCatfishLimit(2000,100); }
Operation result:
Note: 2000 threads got 155 tokens, which took 12 ms for token operation and 1550 MS + 12 ms for total time. Why didn't they get 100 tokens precisely? The reason is that 2000 threads didn't carry out token operation at the same time point. Through the wake-up time of printing thread, it was found that the maximum time difference of 2000 threads was 566 Ms.


Conclusion: the current limiting algorithm especially supports a small number of current limiters and high concurrent current limiting, because if the algorithm fails to obtain the token, it will circularly drop the token to the bucket. If the current limiter is more than one, it will lead to N circularly drop token operations, increasing cpu pressure.
4.3 improved token bucket current limiting algorithm
The algorithm flow chart is as follows:
5. Comparison of current limiting algorithms
