The knowledge points involved in HBase are shown in the figure below. This paper will explain them one by one:
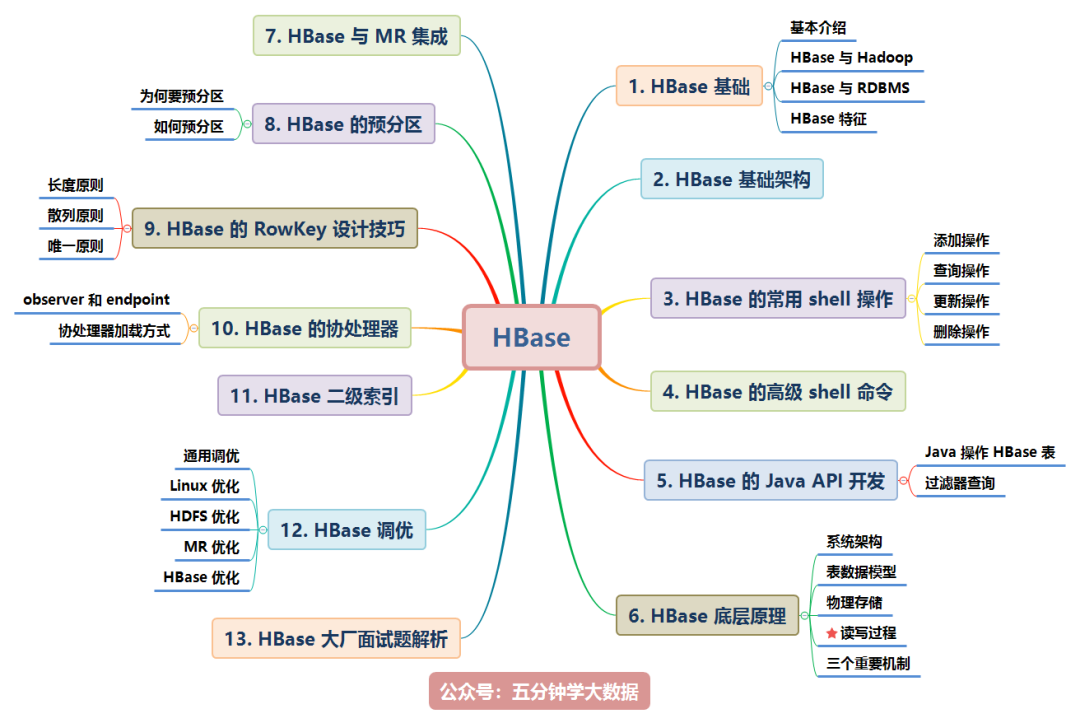
The contents of this article are shown in the figure above
This document is compiled with reference to the official website of HBase and many other materials
1, HBase Foundation
1. Basic introduction to HBase
brief introduction
HBase is an open source Java version of BigTable. It is a database system based on HDFS, which provides high reliability, high performance, column storage, scalability and real-time reading and writing NoSql.
It is between NoSql and RDBMS. It can only retrieve data through the row key and the range of the primary key, and only supports single line transactions (complex operations such as multi table join can be realized through hive support).
It is mainly used to store structured and semi-structured loose data.
The data query function of Hbase is very simple. It does not support complex operations such as join and complex transactions (row level transactions). The data types supported in Hbase: byte [] like hadoop, the target of Hbase mainly depends on horizontal expansion to increase the computing and storage capacity by continuously adding cheap commercial servers.
Tables in HBase generally have the following characteristics:
- Large: a table can have billions of rows and millions of columns
- Column oriented: storage and permission control of columns (families) are oriented, and columns (families) are retrieved independently.
- Sparse: for empty (null) columns, it does not occupy storage space. Therefore, the table can be designed very sparse.
Development of HBase
The prototype of HBase is Google's BigTable paper. Inspired by the idea of this paper, HBase is currently developed and maintained as a sub project of Hadoop to support structured data storage.
Official website: http://hbase.apache.org
- In 2006, Google published BigTable white paper
- HBase was developed in 2006
- In 2008, HBase became a sub project of Hadoop
- In 2010, HBase became the top project of Apache
2. Relationship between HBase and Hadoop
HDFS
- Provide file systems for distributed storage
- It is optimized for storing large files, and there is no need to read and write files on HDFS randomly
- Direct use of files
- Inflexible data model
- Using file systems and processing frameworks
- Optimize write once and read many times
HBase
- Provide tabular column oriented data storage
- Optimize the random reading and writing of tabular data
- Using key value to manipulate data
- Provide flexible data model
- Use table storage, support MapReduce, and rely on HDFS
- Optimized multiple reads and multiple writes
3. Comparison between RDBMS and HBase
Relational database
Structure:
- The database exists as a table
- Support FAT, NTFS, EXT and file system
- Use Commit log to store logs
- The reference system is a coordinate system
- Use primary key (PK)
- Support partition
- Use rows, columns, cells
Function:
- Support upward expansion
- Using SQL queries
- Row oriented, that is, each row is a continuous unit
- The total amount of data depends on the server configuration
- With ACID support
- Suitable for structured data
- Traditional relational databases are generally centralized
- Support transactions
- Support Join
HBase
Structure:
- The database exists in the form of region
- HDFS file system support
- Use WAL (write ahead logs) to store logs
- The reference system is Zookeeper
- Use the row key
- Support fragmentation
- Working with rows, columns, column families, and cells
Function:
- Support outward expansion
- Use API and MapReduce to access HBase table data
- Column oriented, that is, each column is a continuous cell
- The total amount of data does not depend on a specific machine, but on the number of machines
- HBase does not support ACID (Atomicity, Consistency, Isolation, Durability)
- Suitable for structured and unstructured data
- They are generally distributed
- HBase does not support transactions
- Join is not supported
4. Brief features of HBase
- Mass storage
Hbase is suitable for storing PB level massive data. In the case of PB level data and low-cost PC storage, it can return data within tens to hundreds of milliseconds. This is closely related to the extremely easy scalability of Hbase. Because of the good scalability of Hbase, it provides convenience for the storage of massive data.
- Column storage
Column storage here actually refers to column family storage, and Hbase stores data according to column family. There can be many columns under the column family, which must be specified when creating a table.
- Easy to expand
The scalability of Hbase is mainly reflected in two aspects: one is based on the upper layer processing capacity (RegionServer) and the other is based on storage (HDFS). By adding RegionSever machines horizontally, horizontal expansion is carried out to improve the processing capacity of the upper layer of Hbase and the ability of hbae to serve more regions. Note: the role of RegionServer is to manage regions and undertake business access. This will be described in detail later. By adding Datanode machines horizontally, the storage layer capacity will be expanded to improve the data storage capacity of Hbase and the reading and writing capacity of back-end storage.
- High concurrency
At present, most of the architectures using Hbase are low-cost PC s, so the delay of a single IO is not small, generally between tens and hundreds of ms. The high concurrency mentioned here mainly means that in the case of concurrency, the single IO latency of Hbase does not decrease much. It can obtain high concurrency and low latency services.
- sparse
Sparse is mainly aimed at the flexibility of Hbase columns. In the column family, you can specify any number of columns. When the column data is empty, it will not occupy storage space.
2, HBase infrastructure
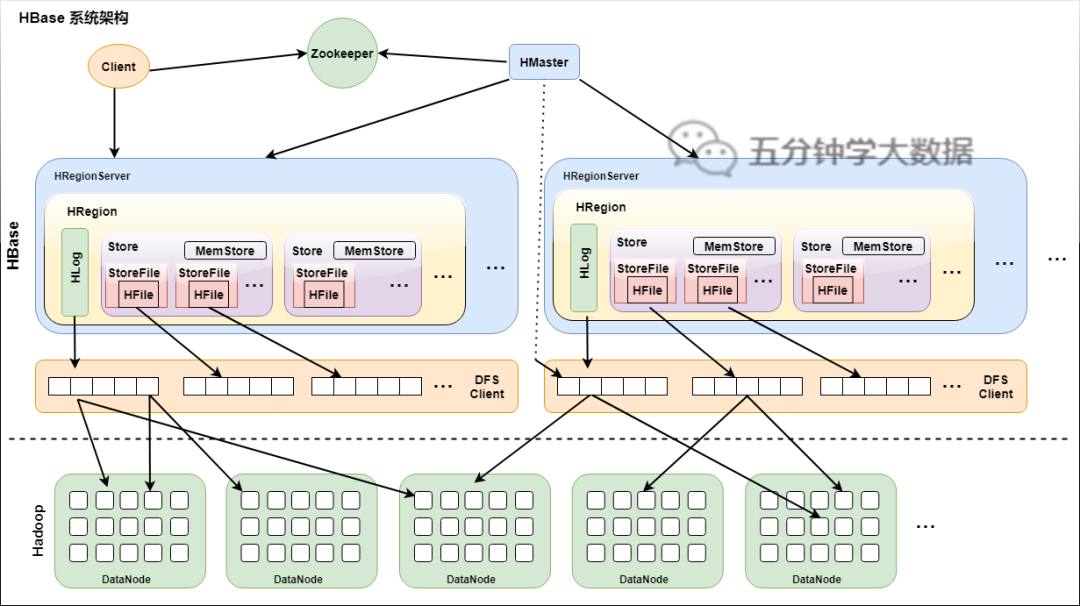
- HMaster
Function:
- Monitoring RegionServer
- Handling RegionServer failover
- Handling changes to metadata
- Handle the allocation or removal of region s
- Load balancing of data in idle time
- Publish your location to the client through Zookeeper
- RegionServer
Function:
- Responsible for storing the actual data of HBase
- Process the Region assigned to it
- Flush cache to HDFS
- Maintain HLog
- Perform compression
- Handle Region fragmentation
Components:
- Write-Ahead logs
The modification record of HBase. When reading and writing data to HBase, the data is not directly written to the disk, but will be retained in memory for a period of time (the time and data volume threshold can be set). However, saving data in memory may have a higher probability of data loss. In order to solve this problem, the data will be written in a file called write ahead logfile, and then written into memory. Therefore, in case of system failure, the data can be reconstructed through this log file.
- HFile
This is the actual physical file that saves the original data on the disk. It is the actual storage file.
- Store
HFile is stored in a Store, and a Store corresponds to a column family in the HBase table.
- MemStore
As the name suggests, it is memory storage, which is located in memory and used to save the current data operation. Therefore, when the data is saved in WAL, regsonserver will store key value pairs in memory.
- Region
The HBase table is divided into different regions according to the RowKey value and stored in the RegionServer. There can be multiple different regions in a RegionServer.
3, HBase common shell operations
1) Add operation
- Enter HBase client command operation interface
$ bin/hbase shell
- View help commands
hbase(main):001:0> help
- View which tables are in the current database
hbase(main):002:0> list
- Create a table
Create a user table that contains two column families: info and data
hbase(main):010:0> create 'user', 'info', 'data'
perhaps
hbase(main):010:0> create 'user', {NAME => 'info', VERSIONS => '3'},{NAME => 'data'}
- Add data operation
Insert information into the user table. The row key is rk0001. Add the name column indicator in the column family info. The value is zhangsan
hbase(main):011:0> put 'user', 'rk0001', 'info:name', 'zhangsan'
Insert information into the user table. The row key is rk0001. Add the gender column indicator in the column family info. The value is female
hbase(main):012:0> put 'user', 'rk0001', 'info:gender', 'female'
Insert information into the user table. The row key is rk0001. The age column indicator is added to the column family info. The value is 20
hbase(main):013:0> put 'user', 'rk0001', 'info:age', 20
Insert information into the user table. The row key is rk0001. Add a pic column indicator to the column family data. The value is picture
hbase(main):014:0> put 'user', 'rk0001', 'data:pic', 'picture'
2) Query operation
- Query through rowkey
Get all the information in the user table where the row key is rk0001
hbase(main):015:0> get 'user', 'rk0001'
- View the information of a column family under rowkey
Get all the information of row key rk0001 and info column family in user table
hbase(main):016:0> get 'user', 'rk0001', 'info'
- View the value of the specified field of the column family specified by rowkey
Get the information of the name and age column identifiers of the info column family with row key rk0001 in the user table
hbase(main):017:0> get 'user', 'rk0001', 'info:name', 'info:age'
- View the information of multiple column families specified by rowkey
Get the information of row key rk0001, info and data column families in the user table
hbase(main):018:0> get 'user', 'rk0001', 'info', 'data'
Or write it like this
hbase(main):019:0> get 'user', 'rk0001', {COLUMN => ['info', 'data']}
Or write it like this
hbase(main):020:0> get 'user', 'rk0001', {COLUMN => ['info:name', 'data:pic']}
- Specify rowkey and column value query
Get the information that the row key in the user table is rk0001 and the cell value is zhangsan
hbase(main):030:0> get 'user', 'rk0001', {FILTER => "ValueFilter(=, 'binary:zhangsan')"}
- Specify rowkey and column value fuzzy query
Get the information that the row key in the user table is rk0001 and the column indicator contains a
hbase(main):031:0> get 'user', 'rk0001', {FILTER => "(QualifierFilter(=,'substring:a'))"}
Continue to insert a batch of data
hbase(main):032:0> put 'user', 'rk0002', 'info:name', 'fanbingbing'
hbase(main):033:0> put 'user', 'rk0002', 'info:gender', 'female'
hbase(main):034:0> put 'user', 'rk0002', 'info:nationality', 'China'
hbase(main):035:0> get 'user', 'rk0002', {FILTER => "ValueFilter(=, 'binary:China')"}
- Query all data
Query all information in the user table
scan 'user'
- Column family query
Query the information listed as info in the user table
scan 'user', {COLUMNS => 'info'}
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 5}
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 3}
- Multi column family query
Query the information with info and data columns in the user table
scan 'user', {COLUMNS => ['info', 'data']}
scan 'user', {COLUMNS => ['info:name', 'data:pic']}
- Specify a column family and a column name query
Query the information in the user table where the column family is info and the column indicator is name
scan 'user', {COLUMNS => 'info:name'}
- Specify column families and column names, and qualified version queries
Query the information in the user table with the column family as info and the column identifier as name, and the 5 latest versions
scan 'user', {COLUMNS => 'info:name', VERSIONS => 5}
- Specifying multiple column families and fuzzy queries by data values
Query the information that the column family in the user table is info and data and the column identifier contains the a character
scan 'user', {COLUMNS => ['info', 'data'], FILTER => "(QualifierFilter(=,'substring:a'))"}
- Range value query of rowkey
Query the data whose column family in the user table is info and the range of rk is (rk0001, rk0003)
scan 'user', {COLUMNS => 'info', STARTROW => 'rk0001', ENDROW => 'rk0003'}
- Specify rowkey fuzzy query
Query the row key in the user table that starts with the rk character
scan 'user',{FILTER=>"PrefixFilter('rk')"}
- Specify data range value query
Query the data of the specified range in the user table
scan 'user', {TIMERANGE => [1392368783980, 1392380169184]}
- Count how many rows of data there are in a table
count 'user'
3) Update operation
- Update data values
The update operation is as like as two peas in the insert operation, but only data is updated, and no data is added.
- Update version number
Change the f1 column family version number of the user table to 5
hbase(main):050:0> alter 'user', NAME => 'info', VERSIONS => 5
4) Delete operation
- Specify rowkey and column name to delete
Delete the data with row key rk0001 and column identifier info:name in the user table
hbase(main):045:0> delete 'user', 'rk0001', 'info:name'
- Specify rowkey, column name and field value to delete
Delete the data with row key rk0001, column identifier info:name and timestamp 1392383705316 in the user table
delete 'user', 'rk0001', 'info:name', 1392383705316
- Delete a column family
Delete a column family
alter 'user', NAME => 'info', METHOD => 'delete'
perhaps
alter 'user', NAME => 'info', METHOD => 'delete'
- Clear table data
hbase(main):017:0> truncate 'user'
- Delete table
First, you need to make the table in disable state, and use the command:
hbase(main):049:0> disable 'user
Then you can drop this table and use the command:
hbase(main):050:0> drop 'user'
Note: if you directly drop the table, an error will be reported: Drop the named table. Table must first be disabled
4, Advanced shell management commands for HBase
- status
For example: display server status
hbase(main):058:0> status 'node01'
- whoami
Displays the current HBase user, for example:
hbase> whoami
- list
Show all current tables
hbase> list
- count
Count the number of records in the specified table, for example:
hbase> count 'user'
- describe
Display table structure information
hbase> describe 'user'
- exists
Check whether the table exists, which is applicable to the situation with a large number of tables
hbase> exists 'user'
- is_enabled,is_disabled
Check whether the table is enabled or disabled
hbase> is_enabled 'user'
- alter
This command can change the mode of table and column families, for example:
Add a column family to the current table:
hbase> alter 'user', NAME => 'CF2', VERSIONS => 2
To delete a column family for the current table:
hbase(main):002:0> alter 'user', 'delete' => 'CF2'
- disable/enable
Disable a table / enable a table
- drop
To delete a table, remember to disable it before deleting the table
- truncate
Empty table
5, Java API development of HBase
1. Develop Java API to operate HBase table data
- Create table myuser
@Test
public void createTable() throws IOException {
//Create a profile object and specify the connection address of zookeeper
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.property.clientPort", "2181");
configuration.set("hbase.zookeeper.quorum", "node01,node02,node03");
//Cluster configuration ↓
//configuration.set("hbase.zookeeper.quorum", "101.236.39.141,101.236.46.114,101.236.46.113");
configuration.set("hbase.master", "node01:60000");
Connection connection = ConnectionFactory.createConnection(configuration);
Admin admin = connection.getAdmin();
//HTableDescriptor is used to set the parameters of our table, including table name, column family and so on
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("myuser"));
//Add column family
hTableDescriptor.addFamily(new HColumnDescriptor("f1"));
//Add column family
hTableDescriptor.addFamily(new HColumnDescriptor("f2"));
//Create table
boolean myuser = admin.tableExists(TableName.valueOf("myuser"));
if(!myuser){
admin.createTable(hTableDescriptor);
}
//Close client connection
admin.close();
}
- Adding data to a table
@Test
public void addDatas() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "node01:2181,node02:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
//Get table
Table myuser = connection.getTable(TableName.valueOf("myuser"));
//Create a put object and specify rowkey
Put put = new Put("0001".getBytes());
put.addColumn("f1".getBytes(),"id".getBytes(), Bytes.toBytes(1));
put.addColumn("f1".getBytes(),"name".getBytes(), Bytes.toBytes("Zhang San"));
put.addColumn("f1".getBytes(),"age".getBytes(), Bytes.toBytes(18));
put.addColumn("f2".getBytes(),"address".getBytes(), Bytes.toBytes("Earthman"));
put.addColumn("f2".getBytes(),"phone".getBytes(), Bytes.toBytes("15874102589"));
//insert data
myuser.put(put);
//Close table
myuser.close();
}
- Query data
Initialize a batch of data into HBase for query
@Test
public void insertBatchData() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "node01:2181,node02:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
//Get table
Table myuser = connection.getTable(TableName.valueOf("myuser"));
//Create a put object and specify rowkey
Put put = new Put("0002".getBytes());
put.addColumn("f1".getBytes(),"id".getBytes(),Bytes.toBytes(1));
put.addColumn("f1".getBytes(),"name".getBytes(),Bytes.toBytes("Cao Cao"));
put.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(30));
put.addColumn("f2".getBytes(),"sex".getBytes(),Bytes.toBytes("1"));
put.addColumn("f2".getBytes(),"address".getBytes(),Bytes.toBytes("Peiguoqiao County"));
put.addColumn("f2".getBytes(),"phone".getBytes(),Bytes.toBytes("16888888888"));
put.addColumn("f2".getBytes(),"say".getBytes(),Bytes.toBytes("helloworld"));
Put put2 = new Put("0003".getBytes());
put2.addColumn("f1".getBytes(),"id".getBytes(),Bytes.toBytes(2));
put2.addColumn("f1".getBytes(),"name".getBytes(),Bytes.toBytes("Liu Bei"));
put2.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(32));
put2.addColumn("f2".getBytes(),"sex".getBytes(),Bytes.toBytes("1"));
put2.addColumn("f2".getBytes(),"address".getBytes(),Bytes.toBytes("Zhuo County, Zhuo County, Youzhou"));
put2.addColumn("f2".getBytes(),"phone".getBytes(),Bytes.toBytes("17888888888"));
put2.addColumn("f2".getBytes(),"say".getBytes(),Bytes.toBytes("talk is cheap , show me the code"));
Put put3 = new Put("0004".getBytes());
put3.addColumn("f1".getBytes(),"id".getBytes(),Bytes.toBytes(3));
put3.addColumn("f1".getBytes(),"name".getBytes(),Bytes.toBytes("Sun Quan"));
put3.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(35));
put3.addColumn("f2".getBytes(),"sex".getBytes(),Bytes.toBytes("1"));
put3.addColumn("f2".getBytes(),"address".getBytes(),Bytes.toBytes("Xiapi"));
put3.addColumn("f2".getBytes(),"phone".getBytes(),Bytes.toBytes("12888888888"));
put3.addColumn("f2".getBytes(),"say".getBytes(),Bytes.toBytes("what are you What are you doing!"));
Put put4 = new Put("0005".getBytes());
put4.addColumn("f1".getBytes(),"id".getBytes(),Bytes.toBytes(4));
put4.addColumn("f1".getBytes(),"name".getBytes(),Bytes.toBytes("Zhuge Liang"));
put4.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(28));
put4.addColumn("f2".getBytes(),"sex".getBytes(),Bytes.toBytes("1"));
put4.addColumn("f2".getBytes(),"address".getBytes(),Bytes.toBytes("Longzhong, Sichuan"));
put4.addColumn("f2".getBytes(),"phone".getBytes(),Bytes.toBytes("14888888888"));
put4.addColumn("f2".getBytes(),"say".getBytes(),Bytes.toBytes("Did you recite it"));
Put put5 = new Put("0005".getBytes());
put5.addColumn("f1".getBytes(),"id".getBytes(),Bytes.toBytes(5));
put5.addColumn("f1".getBytes(),"name".getBytes(),Bytes.toBytes("Sima Yi"));
put5.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(27));
put5.addColumn("f2".getBytes(),"sex".getBytes(),Bytes.toBytes("1"));
put5.addColumn("f2".getBytes(),"address".getBytes(),Bytes.toBytes("Where people need to be studied"));
put5.addColumn("f2".getBytes(),"phone".getBytes(),Bytes.toBytes("15888888888"));
put5.addColumn("f2".getBytes(),"say".getBytes(),Bytes.toBytes("Strangle Zhuge Liang"));
Put put6 = new Put("0006".getBytes());
put6.addColumn("f1".getBytes(),"id".getBytes(),Bytes.toBytes(5));
put6.addColumn("f1".getBytes(),"name".getBytes(),Bytes.toBytes("xiaobubu—Lv Bu"));
put6.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(28));
put6.addColumn("f2".getBytes(),"sex".getBytes(),Bytes.toBytes("1"));
put6.addColumn("f2".getBytes(),"address".getBytes(),Bytes.toBytes("Inner Mongolian"));
put6.addColumn("f2".getBytes(),"phone".getBytes(),Bytes.toBytes("15788888888"));
put6.addColumn("f2".getBytes(),"say".getBytes(),Bytes.toBytes("Where's Diao Chan"));
List<Put> listPut = new ArrayList<Put>();
listPut.add(put);
listPut.add(put2);
listPut.add(put3);
listPut.add(put4);
listPut.add(put5);
listPut.add(put6);
myuser.put(listPut);
myuser.close();
}
Query by rowkey to obtain all values of all columns
Query the person whose primary key rowkey is 0003:
@Test
public void searchData() throws IOException {
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf("myuser"));
Get get = new Get(Bytes.toBytes("0003"));
Result result = myuser.get(get);
Cell[] cells = result.rawCells();
//Get all column names and column values
for (Cell cell : cells) {
//Note that if the column attribute is of type int, it will not be displayed here
System.out.println(Bytes.toString(cell.getQualifierArray(),cell.getQualifierOffset(),cell.getQualifierLength()));
System.out.println(Bytes.toString(cell.getValueArray(),cell.getValueOffset(),cell.getValueLength()));
}
myuser.close();
}
Query the value of the specified column below the specified column family by rowkey:
@Test
public void searchData2() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf("myuser"));
//Query through rowKey
Get get = new Get("0003".getBytes());
get.addColumn("f1".getBytes(),"id".getBytes());
Result result = myuser.get(get);
System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "id".getBytes())));
System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "age".getBytes())));
System.out.println(Bytes.toString(result.getValue("f1".getBytes(), "name".getBytes())));
myuser.close();
}
Scan through startRowKey and endRowKey:
@Test
public void scanRowKey() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf("myuser"));
Scan scan = new Scan();
scan.setStartRow("0004".getBytes());
scan.setStopRow("0006".getBytes());
ResultScanner resultScanner = myuser.getScanner(scan);
for (Result result : resultScanner) {
//Get rowkey
System.out.println(Bytes.toString(result.getRow()));
//Traverse to get the names of all column families and all columns
KeyValue[] raw = result.raw();
for (KeyValue keyValue : raw) {
//Get the column family
System.out.println(Bytes.toString(keyValue.getFamilyArray(),keyValue.getFamilyOffset(),keyValue.getFamilyLength()));
System.out.println(Bytes.toString(keyValue.getQualifierArray(),keyValue.getQualifierOffset(),keyValue.getQualifierLength()));
}
//Specify the column family and column, and print the data in the column
System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "id".getBytes())));
System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "age".getBytes())));
System.out.println(Bytes.toString(result.getValue("f1".getBytes(), "name".getBytes())));
}
myuser.close();
}
Scan the whole table through scan:
@Test
public void scanAllData() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf("myuser"));
Scan scan = new Scan();
ResultScanner resultScanner = myuser.getScanner(scan);
for (Result result : resultScanner) {
//Get rowkey
System.out.println(Bytes.toString(result.getRow()));
//Specify the column family and column, and print the data in the column
System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "id".getBytes())));
System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "age".getBytes())));
System.out.println(Bytes.toString(result.getValue("f1".getBytes(), "name".getBytes())));
}
myuser.close();
}
2. Filter query
There are many types of filters, but they can be divided into two categories - comparison filters and special filters.
The function of the filter is to judge whether the data meets the conditions at the server, and then only return the data that meets the conditions to the client;
Comparison operator for hbase filter:
LESS < LESS_OR_EQUAL <= EQUAL = NOT_EQUAL <> GREATER_OR_EQUAL >= GREATER > NO_OP Exclude all
Comparator for Hbase filter (specify comparison mechanism):
BinaryComparator Compares the specified byte array in byte index order, using Bytes.compareTo(byte[]) BinaryPrefixComparator Same as before, just compare whether the data at the left end is the same NullComparator Judge whether the given is empty BitComparator Bitwise comparison RegexStringComparator Provides a regular comparator that only supports EQUAL He Fei EQUAL SubstringComparator Determine whether the supplied substring appears in the value Yes.
1) Comparison filter
- rowKey filterowfilter
Filter all values smaller than rowKey 0003 through RowFilter
@Test
public void rowKeyFilter() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf("myuser"));
Scan scan = new Scan();
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes("0003")));
scan.setFilter(rowFilter);
ResultScanner resultScanner = myuser.getScanner(scan);
for (Result result : resultScanner) {
//Get rowkey
System.out.println(Bytes.toString(result.getRow()));
//Specify the column family and column, and print the data in the column
System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "id".getBytes())));
System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "age".getBytes())));
System.out.println(Bytes.toString(result.getValue("f1".getBytes(), "name".getBytes())));
}
myuser.close();
}
- Column family filter FamilyFilter
Query the data in all column families smaller than f2 column family
@Test
public void familyFilter() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf("myuser"));
Scan scan = new Scan();
FamilyFilter familyFilter = new FamilyFilter(CompareFilter.CompareOp.LESS, new SubstringComparator("f2"));
scan.setFilter(familyFilter);
ResultScanner resultScanner = myuser.getScanner(scan);
for (Result result : resultScanner) {
//Get rowkey
System.out.println(Bytes.toString(result.getRow()));
//Specify the column family and column, and print the data in the column
System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "id".getBytes())));
System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "age".getBytes())));
System.out.println(Bytes.toString(result.getValue("f1".getBytes(), "name".getBytes())));
}
myuser.close();
}
- Column filter QualifierFilter
Query only the value of the name column
@Test
public void qualifierFilter() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf("myuser"));
Scan scan = new Scan();
QualifierFilter qualifierFilter = new QualifierFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator("name"));
scan.setFilter(qualifierFilter);
ResultScanner resultScanner = myuser.getScanner(scan);
for (Result result : resultScanner) {
//Get rowkey
System.out.println(Bytes.toString(result.getRow()));
//Specify the column family and column, and print the data in the column
// System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "id".getBytes())));
System.out.println(Bytes.toString(result.getValue("f1".getBytes(), "name".getBytes())));
}
myuser.close();
}
- Column value filtervaluefilter
Query data containing 8 in all columns
@Test
public void valueFilter() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf("myuser"));
Scan scan = new Scan();
ValueFilter valueFilter = new ValueFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator("8"));
scan.setFilter(valueFilter);
ResultScanner resultScanner = myuser.getScanner(scan);
for (Result result : resultScanner) {
//Get rowkey
System.out.println(Bytes.toString(result.getRow()));
//Specify the column family and column, and print the data in the column
// System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "id".getBytes())));
System.out.println(Bytes.toString(result.getValue("f2".getBytes(), "phone".getBytes())));
}
myuser.close();
}
2) Special filter
- Single column value filtersinglecolumnvaluefilter
SingleColumnValueFilter returns all fields that meet the criteria for the entire column value
@Test
public void singleColumnFilter() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf("myuser"));
Scan scan = new Scan();
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter("f1".getBytes(), "name".getBytes(), CompareFilter.CompareOp.EQUAL, "Liu Bei".getBytes());
scan.setFilter(singleColumnValueFilter);
ResultScanner resultScanner = myuser.getScanner(scan);
for (Result result : resultScanner) {
//Get rowkey
System.out.println(Bytes.toString(result.getRow()));
//Specify the column family and column, and print the data in the column
System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "id".getBytes())));
System.out.println(Bytes.toString(result.getValue("f1".getBytes(), "name".getBytes())));
System.out.println(Bytes.toString(result.getValue("f2".getBytes(), "phone".getBytes())));
}
myuser.close();
}
- Column value exclusion filter SingleColumnValueExcludeFilter
Contrary to SingleColumnValueFilter, the specified column is excluded and all other columns are returned
- rowkey prefix filterprefixfilter
Query the rowkey s of all prefixes starting with 00
@Test
public void preFilter() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf("myuser"));
Scan scan = new Scan();
PrefixFilter prefixFilter = new PrefixFilter("00".getBytes());
scan.setFilter(prefixFilter);
ResultScanner resultScanner = myuser.getScanner(scan);
for (Result result : resultScanner) {
//Get rowkey
System.out.println(Bytes.toString(result.getRow()));
//Specify the column family and column, and print the data in the column
System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "id".getBytes())));
System.out.println(Bytes.toString(result.getValue("f1".getBytes(), "name".getBytes())));
System.out.println(Bytes.toString(result.getValue("f2".getBytes(), "phone".getBytes())));
}
myuser.close();
}
- Page filter
Page filter
@Test
public void pageFilter2() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf("myuser"));
int pageNum = 3;
int pageSize = 2;
Scan scan = new Scan();
if (pageNum == 1) {
PageFilter filter = new PageFilter(pageSize);
scan.setStartRow(Bytes.toBytes(""));
scan.setFilter(filter);
scan.setMaxResultSize(pageSize);
ResultScanner scanner = myuser.getScanner(scan);
for (Result result : scanner) {
//Get rowkey
System.out.println(Bytes.toString(result.getRow()));
//Specify the column family and column, and print the data in the column
// System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "id".getBytes())));
System.out.println(Bytes.toString(result.getValue("f1".getBytes(), "name".getBytes())));
//System.out.println(Bytes.toString(result.getValue("f2".getBytes(), "phone".getBytes())));
}
}else{
String startRowKey ="";
PageFilter filter = new PageFilter((pageNum - 1) * pageSize + 1 );
scan.setStartRow(startRowKey.getBytes());
scan.setMaxResultSize((pageNum - 1) * pageSize + 1);
scan.setFilter(filter);
ResultScanner scanner = myuser.getScanner(scan);
for (Result result : scanner) {
byte[] row = result.getRow();
startRowKey = new String(row);
}
Scan scan2 = new Scan();
scan2.setStartRow(startRowKey.getBytes());
scan2.setMaxResultSize(Long.valueOf(pageSize));
PageFilter filter2 = new PageFilter(pageSize);
scan2.setFilter(filter2);
ResultScanner scanner1 = myuser.getScanner(scan2);
for (Result result : scanner1) {
byte[] row = result.getRow();
System.out.println(new String(row));
}
}
myuser.close();
}
3) Multi filter comprehensive query FilterList
Requirements: use SingleColumnValueFilter to query the data of f1 column family with name Liu Bei, and meet the data with rowkey prefix starting with 00 (PrefixFilter)
@Test
public void manyFilter() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf("myuser"));
Scan scan = new Scan();
FilterList filterList = new FilterList();
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter("f1".getBytes(), "name".getBytes(), CompareFilter.CompareOp.EQUAL, "Liu Bei".getBytes());
PrefixFilter prefixFilter = new PrefixFilter("00".getBytes());
filterList.addFilter(singleColumnValueFilter);
filterList.addFilter(prefixFilter);
scan.setFilter(filterList);
ResultScanner scanner = myuser.getScanner(scan);
for (Result result : scanner) {
//Get rowkey
System.out.println(Bytes.toString(result.getRow()));
//Specify the column family and column, and print the data in the column
// System.out.println(Bytes.toInt(result.getValue("f1".getBytes(), "id".getBytes())));
System.out.println(Bytes.toString(result.getValue("f1".getBytes(), "name".getBytes())));
//System.out.println(Bytes.toString(result.getValue("f2".getBytes(), "phone".getBytes())));
}
myuser.close();
}
3. Delete data according to rowkey
@Test
public void deleteByRowKey() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf("myuser"));
Delete delete = new Delete("0001".getBytes());
myuser.delete(delete);
myuser.close();
}
4. Delete table
@Test
public void deleteTable() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Admin admin = connection.getAdmin();
admin.disableTable(TableName.valueOf("myuser"));
admin.deleteTable(TableName.valueOf("myuser"));
admin.close();
}
6, HBase underlying principle
1. System architecture
HBase system architecture
According to this figure, explain the components in HBase
1) Client
- It contains the interface to access hbase. The Client maintains some cache s to speed up access to hbase, such as the location information of region
2) Zookeeper
HBase can use built-in Zookeeper or external Zookeeper. In the actual production environment, in order to maintain consistency, external Zookeeper is generally used.
Role of Zookeeper in HBase:
- Ensure that there is only one master in the cluster at any time
- Address entry for storing all regions
- Monitor the status of the region server in real time and notify the Master of the online and offline information of the region server in real time
3) HMaster
- Assign region to Region server
- Responsible for load balancing of region server
- Discover the failed region server and reallocate the region on it
- Garbage file collection on HDFS
- Processing schema update requests
4) HRegion Server
- The HRegion server maintains the regions allocated to it by HMaster and processes IO requests for these regions
- The hregon server is responsible for segmenting region s that become too large during operation. As can be seen from the figure, the Client does not need HMaster to participate in the process of accessing data on HBase (addressing access to Zookeeper and hregon server, data reading and writing access to hregon server)
HMaster only maintains the metadata information of the user table and hregon, and the load is very low.
2. Table data model of HBase
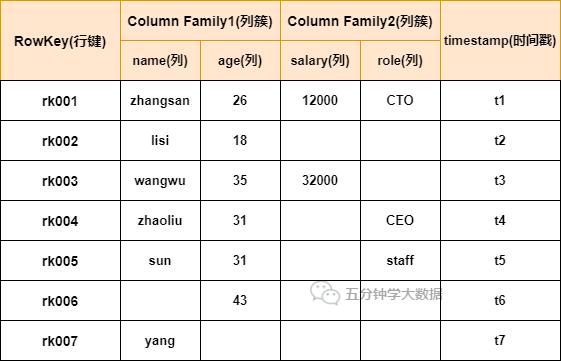
Table structure of HBase
1) Row Key
Like nosql database, row key is the primary key used to retrieve records. There are only three ways to access rows in hbase table:
- Accessed through a single row key
- range through row key
- Full table scan
The row key can be any string (the maximum length is 64KB, which is generally 10-100bytes in practical application). In hbase, the row key is saved as a byte array.
Hbase will sort the data in the table by rowkey (dictionary order)
During storage, the data is sorted and stored according to the byte order of Row key. When designing keys, you should fully sort and store this feature, and store the rows that are often read together. (location dependency).
Note: the result of sorting int by dictionary order is 1,10100,11,12,13,14,15,16,17,18,19,2,20,21. To maintain the natural order of shaping, the row key must be left filled with 0.
One read and write of a row is an atomic operation (no matter how many columns are read and written at a time). This design decision can make it easy for users to understand the behavior of the program when performing concurrent update operations on the same row.
2) Column Family
Each column in the HBase table belongs to a column family. Column families are part of a table's schema (not columns) and must be defined before using the table.
Column names are prefixed with column families. For example, courses:history and courses:math belong to the courses column family.
Access control, disk and memory usage statistics are all performed at the column family level. The more column families, the more files to participate in IO and search when fetching a row of data. Therefore, if it is not necessary, do not set too many column families.
3) Column column
The specific columns under the column family belong to a ColumnFamily, which is similar to the specific columns created in mysql.
4) Timestamp
In HBase, a storage unit determined by row and columns is called cell. Each cell stores multiple versions of the same data. Versions are indexed by timestamp. The timestamp type is a 64 bit integer. The timestamp can be assigned by HBase (automatically when data is written). At this time, the timestamp is the current system time accurate to milliseconds. The timestamp can also be explicitly assigned by the customer. If the application wants to avoid data version conflict, it must generate a unique timestamp by itself. In each cell, the data of different versions are sorted in reverse chronological order, that is, the latest data is at the top.
In order to avoid the burden of management (including storage and indexing) caused by too many versions of data, hbase provides two data version recovery methods:
- Save the last n versions of data
- Save the latest version (set the life cycle TTL of the data).
You can set for each column family.
5) Cell
The unit uniquely determined by {row key, column (= < family > + < label >), version}. The data in the cell has no type, and is stored in bytecode form.
6) Version number VersionNum
The version number of the data. Each data can have multiple version numbers. The default value is the system timestamp and the type is Long.
3. Physical storage
1) Overall structure
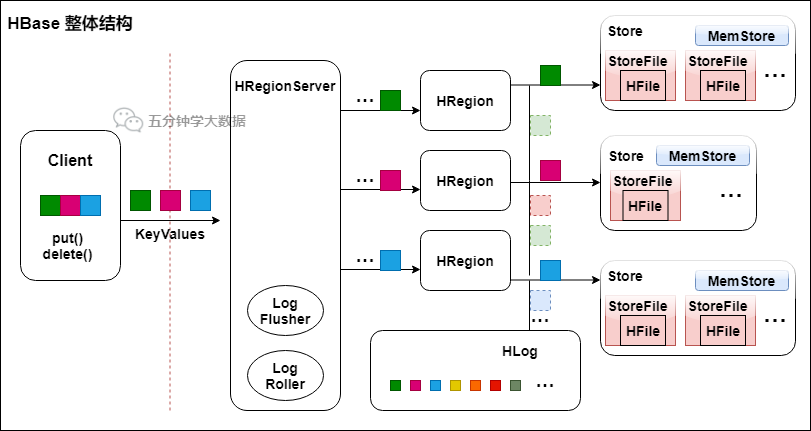
Overall structure of HBase
- All rows in the Table are arranged in the dictionary order of the Row Key.
- The Table is divided into multiple hregs in the direction of the row.
- Hregon is divided by size (10g by default). Each Table has only one hregon at the beginning. With the continuous insertion of data into the Table, the hregon continues to increase. When it increases to a threshold value, the hregon will divide two new hregon equally. When the number of rows in the Table increases, there will be more and more hregs.
- Hregon is the smallest unit of distributed storage and load balancing in HBase. The smallest cell means that different hregs can be distributed on different hregs servers. However, an hregon will not be split into multiple servers.
- Although hregon is the smallest unit of load balancing, it is not the smallest unit of physical storage. In fact, HRegion consists of one or more stores, and each Store stores a Column Family. Each Strore consists of one MemStore and 0 multiple storefiles. As shown above.
2) StoreFile and HFile structures
StoreFile is saved on HDFS in HFile format.
The format of HFile is:
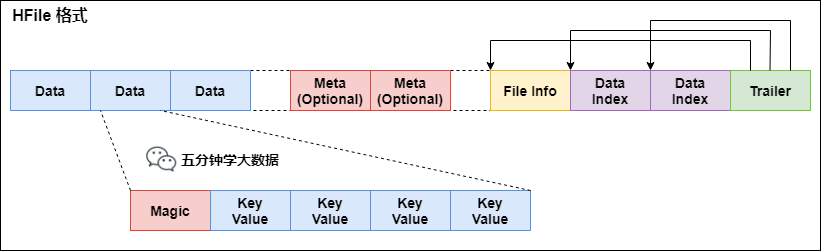
HFile format
First of all, HFile files are of variable length and have a fixed length. There are only two of them: tracker and FileInfo. As shown in the figure, there are pointers in the tracker to the starting points of other data blocks.
File Info records some Meta information of the file, such as AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY, etc.
The Data Index and Meta Index blocks record the starting point of each Data block and Meta block.
Data Block is the basic unit of HBase I/O. in order to improve efficiency, HRegionServer has LRU based Block Cache mechanism. The size of each data Block can be specified by parameters when creating a Table. Large blocks are conducive to sequential Scan and small blocks are conducive to random query. In addition to the Magic at the beginning, each data Block is spliced by KeyValue pairs. The Magic content is some random numbers to prevent data damage.
Each KeyValue pair in HFile is a simple byte array. But this byte array contains many items and has a fixed structure. Let's take a look at the specific structure:

HFile specific structure
Start with two fixed length values, representing the length of Key and Value respectively. Then comes the Key, starting with a fixed length Value, indicating the length of RowKey, followed by RowKey, then a fixed length Value, indicating the length of Family, then Family, then Qualifier, and then two fixed length values, indicating Time Stamp and Key Type (Put/Delete). The Value part does not have such a complex structure, but is pure binary data.
HFile is divided into six parts:
- Data Block section – saves the data in the table, which can be compressed
- Meta Block segment (optional) – saves user-defined kv pairs, which can be compressed.
- File Info section – the meta information of Hfile, which is not compressed. Users can also add their own meta information in this section.
- Data Block Index section – the index of the Data Block. The key of each index is the key of the first record of the indexed block.
- Meta Block Index segment (optional) – the index of the Meta Block.
- Trainer – this section is fixed length. The offset of each segment is saved. When reading an HFile, the tracker will first read. The tracker saves the starting position of each segment (the Magic Number of the segment is used for security check), and then the DataBlock Index will be read into memory. In this way, when retrieving a key, you don't need to scan the whole HFile, but just find the block where the key is located from memory, Read the whole block into memory through disk io once, and then find the required key. DataBlock Index is eliminated by LRU mechanism.
HFile's Data Block and Meta Block are usually stored in compression. After compression, network IO and disk IO can be greatly reduced. Of course, the attendant overhead is that cpu is required for compression and decompression. At present, HFile supports two compression methods: Gzip and Lzo.
3) Memory and StoreFile
An HRegion consists of multiple stores, each of which contains all the data of a column family, including Memstore in memory and StoreFile in hard disk.
The write operation first writes to the memory. When the amount of data in the memory reaches a certain threshold, HRegionServer starts the FlashCache process to write to the StoreFile. Each write forms a separate StoreFile
When the size of the StoreFile exceeds a certain threshold, the current hregon will be divided into two and distributed by HMaster to the corresponding hregon server to achieve load balancing
When the client retrieves data, it first finds it in the memstore, and then finds the storefile if it cannot be found.
4) HLog(WAL log)
WAL means Write ahead log, similar to binlog in mysql. It is used for disaster recovery. Hlog records all changes in data. Once the data is modified, it can be recovered from the log.
Each region server maintains one Hlog instead of one for each region. In this way, logs from different regions (from different tables) will be mixed. The purpose of this is to continuously append a single file. Compared with writing multiple files at the same time, it can reduce the number of disk addressing, so it can improve the writing performance of tables. The trouble is that if a region server goes offline, in order to recover the region on it, you need to split the log on the region server and distribute it to other region servers for recovery.
The HLog file is an ordinary Hadoop Sequence File:
- The Key of the HLog Sequence File is the HLogKey object. The HLogKey records the ownership information of the written data. In addition to the names of table and region, it also includes sequence number and timestamp. Timestamp is the "write time", and the starting value of sequence number is 0, or the sequence number last stored in the file system.
- The Value of the Hlog sequence file is the KeyValue object of HBase, that is, the KeyValue in the corresponding HFile, as described above.
4. Reading and writing process
1) Read request process:
HRegionServer saves the meta table and table data. To access the table data, the Client first accesses zookeeper to obtain the location information of the meta table from zookeeper, that is, find the HRegionServer on which the meta table is saved.
Then, the Client accesses the HRegionServer where the Meta table is located through the IP of the HRegionServer just obtained, so as to read the Meta and then obtain the metadata stored in the Meta table.
The Client accesses the corresponding HRegionServer through the information stored in the metadata, and then scans the Memstore and Storefile of the HRegionServer to query the data.
Finally, HRegionServer responds the queried data to the Client.
View meta table information
hbase(main):011:0> scan 'hbase:meta'
2) Write request process:
The Client also accesses zookeeper first, finds the Meta table, and obtains the Meta table metadata.
Determine the HRegion and HRegionServer servers corresponding to the data to be written.
The Client initiates a write data request to the HRegionServer server, and then the HRegionServer receives the request and responds.
The Client writes the data to the HLog first to prevent data loss.
Then write the data to the memory.
If both HLog and Memstore are written successfully, this data is written successfully
If the memory reaches the threshold, the data in the memory will be flush ed into the Storefile.
When there are more and more storefiles, the Compact merge operation will be triggered to merge too many storefiles into a large Storefile.
When the Storefile becomes larger and larger, the Region becomes larger and larger. When the threshold is reached, the Split operation will be triggered to Split the Region into two.
Detailed description:
HBase uses MemStore and StoreFile to store updates to tables. When updating, the data is first written to the Log(WAL log) and memory (MemStore). The data in the MemStore is sorted. When the MemStore accumulates to a certain threshold, a new MemStore will be created, and the old MemStore will be added to the flush queue, which will be flushed to the disk by a separate thread to become a StoreFile. At the same time, the system will record a redo point in zookeeper, indicating that the changes before this time have been persisted. When the system encounters an accident, the data in the memory (MemStore) may be lost. At this time, Log(WAL log) is used to recover the data after the checkpoint.
The StoreFile is read-only and cannot be modified once it is created. Therefore, the update of HBase is actually a continuous addition operation. When the StoreFile in a Store reaches a certain threshold, a merge (minor_compact, major_compact) will be performed to merge the modifications to the same key to form a large StoreFile. When the size of the StoreFile reaches a certain threshold, the StoreFile will be split into two storefiles.
Because the table is updated continuously, when compact, you need to access all storefiles and memstores in the Store and merge them according to row key. Because both storefiles and memstores are sorted and storefiles have in memory indexes, the merging process is faster than.
5. Hregon management
1) Hregon allocation
At any time, an hregon can only be assigned to one hregon server. HMaster records which HRegion servers are currently available. And which hregs are currently assigned to which hregs server and which hregs have not been assigned. When a new hregon needs to be allocated and there is free space on an hregon server, HMaster sends a load request to the hregon server to allocate the hregon to the hregon server. After the hregon server receives the request, it starts to provide services for this hregon.
2) Hregon server online
HMaster uses zookeeper to track the status of the hregon server. When an hregon server starts, it will first create a znode representing itself in the server directory on zookeeper. Since HMaster subscribes to the change message on the server directory, HMaster can get a real-time notification from zookeeper when files in the server directory are added or deleted. Therefore, once the hregon server goes online, HMaster can get the message immediately.
3) Hregon server offline
When the hregon server goes offline, it disconnects its session with zookeeper, which automatically releases the exclusive lock on the file representing the server. HMaster can determine:
- The network between hregon server and zookeeper is down.
- Hregon server hung up.
In either case, the hregon server cannot continue to provide services for its hregon. At this time, HMaster will delete the znode data representing the hregon server in the server directory and assign the hregon of the hregon server to other living nodes.
6. HMaster working mechanism
1) master online
To start the master, perform the following steps:
- Obtain the only lock representing the active master from zookeeper to prevent other hmasters from becoming masters.
- Scan the server parent node on zookeeper to obtain the list of currently available hregon servers.
- Communicate with each hregon server to obtain the corresponding relationship between the currently allocated hregon and hregon server.
- Scan the set of. META.region, calculate the currently unassigned hregs, and put them into the list of hregs to be allocated.
2) master offline
Since HMaster only maintains the metadata of tables and region s and does not participate in the process of table data IO, the offline of HMaster only causes the modification of all metadata to be frozen (the deletion table cannot be created, the schema of the table cannot be modified, the load balancing of hregon cannot be performed, the upstream and downstream of hregon cannot be processed, and the merging of hregon cannot be performed. The only exception is that the split of hregon can be performed normally, because only hregon server participates in it.) , the data reading and writing of the table can be carried out normally. Therefore, the HMaster offline has no impact on the whole HBase cluster in a short time.
It can be seen from the online process that the information saved by HMaster is all redundant information (which can be collected or calculated from other parts of the system)
Therefore, in a general HBase cluster, there is always one HMaster providing services, and more than one 'HMaster' is waiting for the opportunity to seize its position.
7. Three important mechanisms of HBase
1) flush mechanism
1. (HBase. Regionserver. Global. Memory. Size) default; 40% of the heap size is the size of the global memstore of the regionserver. Exceeding this size will trigger the flush to disk operation. The default is 40% of the heap size, and the flush at the regionserver level will block the client's reading and writing
2. (HBase. Hregon. memstore. Flush. Size) default: 128M memory store cache size in a single region. If it exceeds, the entire hregon will flush,
3. (HBase. Regionserver. Optionalcacheflushing interval) default: the longest time that files in 1h memory can survive before automatic refresh
4. (hbase.regionserver.global.memstore.size.lower.limit) default: heap size * 0.4 * 0.95. Sometimes the "write load" of the cluster is very high, and the write volume always exceeds the flush. At this time, we hope that the memstore does not exceed a certain security setting. In this case, the write operation will be blocked until the memstore is restored to a "manageable" size. The default value is heap size * 0.4 * 0.95, that is, after the flush operation at the regionserver level is sent, the client write will be blocked until the size of the memstore at the entire regionserver level is heap size * 0.4 * 0.95
5. (HBase. Hierarchy. Preclose. Flush. Size) the default value is 5M. When the size of the memstore in a region is greater than this value and we trigger the closing of the region, we will first run the "pre flush" operation to clean up the memstore to be closed, and then offline the region. When a region goes offline, we can no longer perform any write operations. If a memstore is large, the flush operation will consume a lot of time. The "pre flush" operation means that the memstore will be cleared before the region goes offline. In this way, the flush operation will be fast when the close operation is finally executed.
6. (HBase. Hsstore. Compactionthreshold) default: the number of hfiles allowed to be stored in more than three stores. If the number exceeds this number, it will be written to a new hfile, that is, when the flush is hfile, these files will be merged and rewritten into a new file by default, The larger the number, the less time it takes to trigger a merge, but the longer the time it takes for each merge
2) compact mechanism
Merge small storeFile files into large HFile files. Clean up expired data, including deleted data, and save the version number of the data as 1.
3) split mechanism
When the hregon reaches the threshold, it will divide the oversized hregon into two. By default, a HFile will be segmented when it reaches 10Gb.
7, Integration of HBase and MapReduce
The data in HBase is ultimately stored on HDFS. HBase naturally supports Mr operation. We can directly process the data in HBase through Mr, and MR can directly store the processed results in HBase.
Requirement: read the data of one table in HBase, and then write the data to another table in HBase.
Note: we can use TableMapper and TableReducer to read and write data from HBase.
Here, we write the name and age fields of the f1 column family in the myuser table into the f1 column family in the myuser2 table.
Requirement 1: read the data in the myuser table and write it to another table in HBase:
Step 1: create the myuser2 table
Note: the name of the column family should be the same as that of the column family in the myuser table
hbase(main):010:0> create 'myuser2','f1'
Step 2: develop MR program
public class HBaseMR extends Configured implements Tool{
public static class HBaseMapper extends TableMapper<Text,Put>{
/**
*
* @param key Our primary key rowkey
* @param value The values of all columns in a row of data are encapsulated in value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
byte[] bytes = key.get();
String rowKey = Bytes.toString(bytes);
Put put = new Put(key.get());
Cell[] cells = value.rawCells();
for (Cell cell : cells) {
if("f1".equals(Bytes.toString(CellUtil.cloneFamily(cell)))){
if("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){
put.add(cell);
}
if("age".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){
put.add(cell);
}
}
}
if(!put.isEmpty()){
context.write(new Text(rowKey),put);
}
}
}
public static class HBaseReducer extends TableReducer<Text,Put,ImmutableBytesWritable>{
@Override
protected void reduce(Text key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
for (Put value : values) {
context.write(null,value);
}
}
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf(), "hbaseMr");
job.setJarByClass(this.getClass());
Scan scan = new Scan();
scan.setCaching(500);
scan.setCacheBlocks(false);
//Use the TableMapReduceUtil tool class to initialize our mapper
TableMapReduceUtil.initTableMapperJob(TableName.valueOf("myuser"),scan,HBaseMapper.class,Text.class,Put.class,job);
//Use the TableMapReduceUtil tool class to initialize our reducer
TableMapReduceUtil.initTableReducerJob("myuser2",HBaseReducer.class,job);
job.setNumReduceTasks(1);
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
//Create HBaseConfiguration configuration
Configuration configuration = HBaseConfiguration.create();
int run = ToolRunner.run(configuration, new HBaseMR(), args);
System.exit(run);
}
}
Step 3: package and run
Put the jar package we typed on the server and execute:
yarn jar hbaseStudy-1.0-SNAPSHOT.jar cn.yuan_more.hbasemr.HBaseMR
Requirement 2: read the HDFS file and write it into the HBase table
Step 1: prepare data files
Prepare data files and upload them to HDFS.
Step 2: develop MR program
public class Hdfs2Hbase extends Configured implements Tool{
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf(), "hdfs2Hbase");
job.setJarByClass(Hdfs2Hbase.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/hbase/input"));
job.setMapperClass(HdfsMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
TableMapReduceUtil.initTableReducerJob("myuser2",HBaseReducer.class,job);
job.setNumReduceTasks(1);
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
int run = ToolRunner.run(configuration, new Hdfs2Hbase(), args);
System.exit(run);
}
public static class HdfsMapper extends Mapper<LongWritable,Text,Text,NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value,NullWritable.get());
}
}
public static class HBaseReducer extends TableReducer<Text,NullWritable,ImmutableBytesWritable>{
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
String[] split = key.toString().split("\t");
Put put = new Put(Bytes.toBytes(split[0]));
put.addColumn("f1".getBytes(),"name".getBytes(),split[1].getBytes());
put.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(Integer.parseInt(split[2])));
context.write(new ImmutableBytesWritable(Bytes.toBytes(split[0])),put);
}
}
}
Requirement 4: bulk load data into HBase
There are many ways to load data into HBase. We can use the Java API of HBase or sqoop to write or import our data into HBase, but these methods are either slow or occupy the Region data in the import process, resulting in low efficiency. We can also use the MR program, Directly convert our data into the final storage format HFile of HBase, and then directly load the data into HBase.
Each Table in HBase is stored in a folder under the root directory (/ HBase). The Table name is the folder name. Under the Table folder, each Region is also stored in a folder. Each column family under each Region folder is also stored in a folder, and some HFile files are stored under each column family. HFile is the storage format of HBase data under HFDS, Therefore, the final expression of HBase storage files on hdfs is HFile. If we can directly convert the data to HFile format, our HBase can directly read the files loaded in HFile format.
advantage:
- The import process does not occupy Region resources
- It can quickly import massive data
- Save memory
Step 1: define mapper class
public class LoadMapper extends Mapper<LongWritable,Text,ImmutableBytesWritable,Put>{
@Override
protected void map(LongWritable key, Text value, Mapper.Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
Put put = new Put(Bytes.toBytes(split[0]));
put.addColumn("f1".getBytes(),"name".getBytes(),split[1].getBytes());
put.addColumn("f1".getBytes(),"age".getBytes(),Bytes.toBytes(Integer.parseInt(split[2])));
context.write(new ImmutableBytesWritable(Bytes.toBytes(split[0])),put);
}
}
Step 2: develop the main program entry class
public class HBaseLoad extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
final String INPUT_PATH= "hdfs://node01:8020/hbase/input";
final String OUTPUT_PATH= "hdfs://node01:8020/hbase/output_hfile";
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Table table = connection.getTable(TableName.valueOf("myuser2"));
Job job= Job.getInstance(conf);
job.setJarByClass(HBaseLoad.class);
job.setMapperClass(LoadMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
job.setOutputFormatClass(HFileOutputFormat2.class);
HFileOutputFormat2.configureIncrementalLoad(job,table,connection.getRegionLocator(TableName.valueOf("myuser2")));
FileInputFormat.addInputPath(job,new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job,new Path(OUTPUT_PATH));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
int run = ToolRunner.run(configuration, new HBaseLoad(), args);
System.exit(run);
}
}
Step 3: type the code into a jar package and run it
yarn jar original-hbaseStudy-1.0-SNAPSHOT.jar cn.yuan_more.hbasemr.HBaseLoad
Step 4: develop code and load data
Load the HFile file under the output path into the hbase table
public class LoadData {
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.property.clientPort", "2181");
configuration.set("hbase.zookeeper.quorum", "node01,node02,node03");
Connection connection = ConnectionFactory.createConnection(configuration);
Admin admin = connection.getAdmin();
Table table = connection.getTable(TableName.valueOf("myuser2"));
LoadIncrementalHFiles load = new LoadIncrementalHFiles(configuration);
load.doBulkLoad(new Path("hdfs://node01:8020/hbase/output_hfile"), admin,table,connection.getRegionLocator(TableName.valueOf("myuser2")));
}
}
Or we can load data through the command line.
First, add the jar package of hbase to the classpath of hadoop
export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`
Then execute the following command to import the HFile of hbase directly into the table myuser2
yarn jar /servers/hbase/lib/hbase-server-1.2.0.jar completebulkload /hbase/output_hfile myuser2
8, Pre partition of HBase
1. Why pre zoning?
- Increase data reading and writing efficiency
- Load balancing to prevent data skew
- Convenient cluster disaster recovery scheduling region
- Optimize the number of maps
2. How to pre partition?
Each region maintains startRow and endRowKey. If the added data meets the rowKey range maintained by a region, the data will be handed over to the region for maintenance.
3. How to set the pre partition?
1) Manually specify pre partition
hbase(main):001:0> create 'staff','info','partition1',SPLITS => ['1000','2000','3000','4000']
After completion, as shown in the figure:

2) Generate pre partition using hexadecimal algorithm
hbase(main):003:0> create 'staff2','info','partition2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
After completion, as shown in the figure:
3) Partition rules are created in files
Create the splits.txt file as follows:
vim splits.txt
aaaa bbbb cccc dddd
Then execute:
Then execute: hbase(main):004:0> create 'staff3','partition2',SPLITS_FILE => '/export/servers/splits.txt'
After completion, as shown in the figure:
4) Creating pre partitions using java APIs
The code is as follows:
@Test
public void hbaseSplit() throws IOException {
//Get connection
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Admin admin = connection.getAdmin();
//Customize the algorithm to generate a series of Hash hash values, which are stored in a two-dimensional array
byte[][] splitKeys = {{1,2,3,4,5},{'a','b','c','d','e'}};
//HTableDescriptor is used to set the parameters of our table, including table name, column family and so on
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("stuff4"));
//Add column family
hTableDescriptor.addFamily(new HColumnDescriptor("f1"));
//Add column family
hTableDescriptor.addFamily(new HColumnDescriptor("f2"));
admin.createTable(hTableDescriptor,splitKeys);
admin.close();
}
9, rowKey design skills of HBase
HBase is stored in three-dimensional order. The data in HBase can be quickly located through three dimensions: rowkey (row key), column key (column family and qualifier) and TimeStamp (TimeStamp).
rowkey in HBase can uniquely identify a row of records. There are several ways to query in HBase:
- Through the get method, specify rowkey to obtain a unique record;
- Set the startRow and stopRow parameters for range matching through scan mode;
- Full table scan, that is, directly scan all row records in the whole table.
1. rowkey length principle
rowkey is a binary code stream, which can be any string with a maximum length of 64kb. In practical application, it is generally 10-100bytes, which is saved in the form of byte [] and is generally designed to have a fixed length.
It is recommended to be as short as possible, not more than 16 bytes, for the following reasons:
- The data persistence file HFile is stored according to the KeyValue. If the rowkey is too long, such as more than 100 bytes and 1000w lines of data, the rowkey alone will occupy 100 * 1000w = 1 billion bytes, nearly 1G of data, which will greatly affect the storage efficiency of HFile;
- MemStore caches some data into memory. If the rowkey field is too long, the effective utilization of memory will be reduced. The system cannot cache more data, which will reduce the retrieval efficiency.
2. rowkey hash principle
If the rowkey is incremented by timestamp, do not put the time in front of the binary code. It is recommended to use the high bit of the rowkey as a hash field, which is randomly generated by the program, and the low bit as a time field. This will improve the probability of data balanced distribution in each RegionServer to achieve load balancing.
If there is no hash field, the first field is the time information directly, and all data will be concentrated on one RegionServer. In this way, the load will be concentrated on individual regionservers during data retrieval, causing hot issues and reducing the query efficiency.
3. rowkey's sole principle
Its uniqueness must be guaranteed in design. Rowkeys are stored in dictionary order. Therefore, when designing rowkey s, we should make full use of the sorting characteristics, store frequently read data in one piece, and put recently accessed data in one piece.
4. What are hot spots
The rows in HBase are sorted according to the dictionary order of rowkey. This design optimizes the scan operation and can access the relevant rows and the rows that will be read together in a nearby position for scan. However, poor rowkey design is the source of hot spots.
Hot spots occur when a large number of client s directly access one or a few nodes of the cluster (access may be read, write or other operations). A large number of accesses will cause the single machine where the hot region is located to exceed its capacity, resulting in performance degradation and even unavailability of the region, which will also affect other regions on the same RegionServer because the host cannot serve the requests of other regions.
A good data access mode is designed to make full and balanced use of the cluster. In order to avoid write hotspots, rowkey s are designed so that different rows are in the same region, but in the case of more data, the data should be written to multiple regions of the cluster instead of one.
Here are some common ways to avoid hot spots and their advantages and disadvantages:
1) Add salt
The salt adding here is not salt adding in cryptography, but adding a random number in front of the rowkey, specifically assigning a random prefix to the rowkey to make it different from the beginning of the previous rowkey. The number of prefix types allocated should be consistent with the number of data you want to use scattered to different regions. After adding salt, the rowkeys will be scattered to each region according to the randomly generated prefix to avoid hot spots.
2) Hash
Hashing will always salt the same line with a prefix. Hashing can also spread the load across the cluster, but reads are predictable. Using the determined hash allows the client to reconstruct the complete rowkey, and use the get operation to accurately obtain a row data.
3) Reverse
The third way to prevent hot spots is to reverse the rowkey in fixed length or digital format. This allows the parts of the rowkey that change frequently (the most meaningless part) to be placed first. This can effectively random rowkeys, but at the expense of the orderliness of rowkeys.
The example of reversing rowkey takes the mobile phone number as the rowkey, and the string after reversing the mobile phone number can be used as the rowkey, so as to avoid hot issues caused by starting with a fixed mobile phone number.
3) Timestamp reversal
A common data processing problem is to quickly obtain the latest version of data. Using the inverted timestamp as part of rowkey is very useful for this problem. You can use Long.Max_Value - timestamp is appended to the end of the key. For example, [key] [reverse_timestamp], the latest value of [key] can obtain the first record of [key] through scan [key], because rowkeys in HBase are ordered and the first record is the last entered data.
Other suggestions:
- Minimize the size of row keys and column families. In HBase, value is always transmitted with its key. When a specific value is transmitted between systems, its rowkey, column name and timestamp will also be transmitted together. If your rowkey and column name are large, they will take up a lot of storage space at this time.
- The column family should be as short as possible, preferably one character.
- Long attribute names are readable, but shorter attribute names are better stored in HBase.
10, HBase coprocessor
http://hbase.apache.org/book.html#cp
1. Origin
The most frequently criticized features of Hbase as a column family database include: it is difficult to easily establish a "secondary index", and it is difficult to perform operations such as summation, counting and sorting.
For example, in the old version (< 0.92) HBase, the total number of rows in the statistics table can be obtained only by using the Counter method and executing MapReduce Job once.
Although HBase integrates MapReduce in the data storage layer, it can be effectively used for distributed computing of data tables. However, in many cases, when doing some simple addition or aggregation calculations, if the calculation process is directly placed on the server side, the communication overhead can be reduced and a good performance improvement can be obtained. Therefore, HBase introduced coprocessors after 0.92 to realize some exciting new features: easy to establish secondary index, complex filter (predicate push down) and access control.
2. There are two coprocessors: observer and endpoint
1) observer coprocessor
Observer is similar to the trigger in traditional database. When some events occur, this kind of coprocessor will be called by the Server side.
Observer Coprocessor is some hook hooks scattered in HBase Server-side code, which are called when fixed events occur.
For example, there is a hook function prePut before the put operation, which will be called by the Region Server before the put operation is executed; After the put operation, there is a postPut hook function.
Taking HBase version 0.92 as an example, it provides three observer interfaces:
- RegionObserver: provides data manipulation event hooks of the client: Get, Put, Delete, Scan, etc.
- WALObserver: provides WAL related operation hooks.
- MasterObserver: provide DDL type operation hook. Such as creating, deleting and modifying data tables.
To version 0.96, another regionserver observer is added
The following figure illustrates the principle of this coprocessor with RegionObserver as an example:
2) endpoint coprocessor
Endpoint coprocessors are similar to stored procedures in traditional databases. Clients can call these endpoint coprocessors to execute a section of Server-side code and return the results of Server-side code to clients for further processing. The most common usage is aggregation.
If there is no coprocessor, when users need to find the maximum data in a table, that is, the max aggregation operation, they must scan the whole table, traverse the scanning results in the Client code, and perform the operation of finding the maximum value. Such a method can not make use of the concurrency of the underlying cluster, but centralize all calculations to the Client for unified execution, which is bound to be inefficient.
Using Coprocessor, users can deploy the code for maximum value to HBase Server, and HBase will use multiple nodes of the underlying cluster to perform the operation of maximum value concurrently. That is, execute the code to calculate the maximum value within each Region, calculate the maximum value of each Region on the Region Server side, and only return the max value to the client. Further process the maximum values of multiple regions at the client to find the maximum value. In this way, the overall implementation efficiency will be greatly improved.
The following figure shows how EndPoint works:
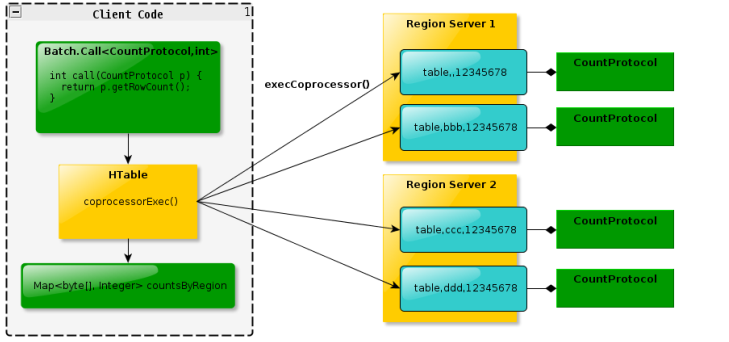
3. Coprocessor loading mode
There are two loading methods for coprocessors, which we call Static Load and Dynamic Load.
Statically loaded coprocessors are called system coprocessors
The dynamically loaded coprocessor is called a Table Coprocessor.
1) Static loading
By modifying the hbase-site.xml file, you can start the global aggregation and manipulate the data on all tables. Just add the following code:
<property> <name>hbase.coprocessor.user.region.classes</name> <value>org.apache.hadoop.hbase.coprocessor.AggregateImplementation</value> </property>
2) Dynamic loading
Enable table aggregation to take effect only for specific tables. It is implemented through HBase Shell.
disable specifies the table
hbase> disable 'mytable'
Add aggregation
hbase> alter 'mytable', METHOD => 'table_att','coprocessor'=> '|org.apache.Hadoop.hbase.coprocessor.AggregateImplementation||'
Restart specified table
hbase> enable 'mytable'
Coprocessor uninstall
disable 'mytable' alter 'mytable', METHOD => 'table_att_unset',NAME=>'coprocessor$1' enable 'test'
11, A brief introduction to the secondary index in HBase
Since the query of HBase is relatively weak, it is basically impossible or difficult to implement complex statistical requirements such as select name,salary,count(1),max(salary) from user group by name,salary order by salary, etc. when we use HBase, we generally use the secondary index scheme.
The primary index of HBase is rowkey. We can only retrieve it through rowkey. If we perform some combined queries on the columns of the column family in HBase, we need to use the secondary index scheme of HBase for multi condition queries.
1. MapReduce scheme 2. ITHBASE (indexed transitional HBase) scheme 3. IHBASE (Index HBase) scheme 4. HBase coprocessor scheme 5. Solr+hbase scheme 6. CCIndex (comprehensive clustering index) scheme
Common secondary indexes can be implemented in various other ways, such as Phoenix, solr or ES.
12, HBase tuning
1. General optimization
- The metadata backup of NameNode uses SSD.
- The metadata on the NameNode is backed up regularly, hourly or daily. If the data is extremely important, it can be backed up every 5 ~ 10 minutes. The backup can copy the metadata directory through the scheduled task.
- Specify multiple metadata directories for NameNode, using dfs.name.dir or dfs.namenode.name.dir. One specifies the local disk and one specifies the network disk. This can provide redundancy and robustness of metadata to avoid failure.
- Set dfs.namenode.name.dir.restore to true to allow you to attempt to restore the dfs.namenode.name.dir directory that failed before. Do this when creating a checkpoint. If multiple disks are set, it is recommended to allow it.
- The NameNode node must be configured as a RAID1 (mirror disk) structure.
- Keep enough space in the NameNode log directory to help you find problems.
- Because Hadoop is an IO intensive framework, try to improve the storage speed and throughput (similar to bit width).
2. Linux optimization
- Enabling the read ahead cache of the file system can improve the reading speed
$ sudo blockdev --setra 32768 /dev/sda
Tip: ra is the abbreviation of readahead
- Turn off process sleep pool
$ sudo sysctl -w vm.swappiness=0
- Adjust the ulimit upper limit. The default value is a relatively small number
$ulimit -n view the maximum number of processes allowed
$ulimit -u view the maximum number of files allowed to open
Modification:
$sudo vi /etc/security/limits.conf modify the limit on the number of open files
Add at the end:
* soft nofile 1024000 * hard nofile 1024000 Hive - nofile 1024000 hive - nproc 1024000
$sudo vi /etc/security/limits.d/20-nproc.conf modify the limit on the number of processes opened by the user
Amend to read:
#* soft nproc 4096 #root soft nproc unlimited * soft nproc 40960 root soft nproc unlimited
- Turn on the time synchronization NTP of the cluster.
- Update the system patch (Note: before updating the patch, please test the compatibility of the new version patch to the cluster nodes)
3. HDFS optimization (HDFS site. XML)
- Ensure that RPC calls will have a large number of threads
Attribute: dfs.namenode.handler.count
Explanation: this attribute is the default number of threads of NameNode service. The default value is 10. It can be adjusted to 50 ~ 100 according to the available memory of the machine
Attribute: dfs.datanode.handler.count
Explanation: the default value of this attribute is 10, which is the number of processing threads of the DataNode. If the HDFS client program has many read-write requests, it can be adjusted to 15 ~ 20. The larger the set value, the more memory consumption. Do not adjust it too high. In general business, it can be 5 ~ 10.
- Adjustment of the number of copies
Attribute: dfs.replication
Explanation: if the amount of data is huge and not very important, it can be adjusted to 2 ~ 3. If the data is very important, it can be adjusted to 3 ~ 5.
- Adjustment of file block size
Attribute: dfs.blocksize
Explanation: for block size definition, this attribute should be set according to the size of a large number of single files stored. If a large number of single files are less than 100M, it is recommended to set it to 64M block size. For cases greater than 100M or reaching GB, it is recommended to set it to 256M. Generally, the setting range fluctuates between 64M and 256M.
4. MapReduce optimization (mapred site. XML)
- Adjust the number of Job task service threads
mapreduce.jobtracker.handler.count
This attribute is the number of Job task threads. The default value is 10. It can be adjusted to 50 ~ 100 according to the available memory of the machine
- Number of Http server worker threads
Attribute: mapreduce.tasktracker.http.threads
Explanation: define the number of HTTP server working threads. The default value is 40. For large clusters, it can be adjusted to 80 ~ 100
- File sorting merge optimization
Attribute: mapreduce.task.io.sort.factor
Explanation: the number of data streams merged simultaneously during file sorting, which also defines the number of files opened at the same time. The default value is 10. If you increase this parameter, you can significantly reduce disk IO, that is, reduce the number of file reads.
- Set task concurrency
Attribute: mapreduce.map.special
Explanation: this attribute can set whether tasks can be executed concurrently. If there are many but small tasks, setting this attribute to true can significantly speed up task execution efficiency. However, for tasks with very high delay, it is recommended to change it to false, which is similar to thunderbolt download.
- Compression of MR output data
Properties: mapreduce.map.output.compress, mapreduce.output.fileoutputformat.compress
Explanation: for large clusters, it is recommended to set the output of map reduce to compressed data, but not for small clusters.
- Number of optimized Mapper and Reducer
Properties:
mapreduce.tasktracker.map.tasks.maximum
mapreduce.tasktracker.reduce.tasks.maximum
Explanation: the above two attributes are the number of maps and Reduce that a single Job task can run simultaneously.
When setting the above two parameters, you need to consider the number of CPU cores, disk and memory capacity. Suppose an 8-core CPU, and the business content consumes CPU very much, then the number of maps can be set to 4. If the business does not particularly consume CPU, then the number of maps can be set to 40 and the number of reduce can be set to 20. After modifying the values of these parameters, you must observe whether there are tasks waiting for a long time. If so, you can reduce the number to speed up task execution. If you set a large value, it will cause a lot of context switching and data exchange between memory and disk. There is no standard configuration value here, Choices need to be made based on business and hardware configuration and experience.
At the same time, do not run too many MapReduce at the same time, which will consume too much memory, and the task will execute very slowly. We need to set a maximum value of MR task concurrency according to the number of CPU cores and memory capacity, so that the task with a fixed amount of data can be fully loaded into memory, so as to avoid frequent memory and disk data exchange, so as to reduce disk IO and improve performance.
Approximate estimation formula: map = 2 + 2/3cpu_core reduce = 2 + 1/3cpu_core
5. HBase optimization
- Append content to HDFS file
Isn't HDFS not allowed to add content? Yes, look at the background story:

Attribute: dfs.support.append
Files: hdfs-site.xml, hbase-site.xml
Explanation: enabling HDFS additional synchronization can cooperate with HBase data synchronization and persistence. The default value is true.
- Optimize the maximum number of file openings allowed for DataNode
Attribute: dfs.datanode.max.transfer.threads
File: hdfs-site.xml
Explanation: HBase generally operates a large number of files at one time. It is set to 4096 or higher according to the number and scale of clusters and data actions. Default: 4096
- **Optimize latency for data operations with high latency
Attribute: dfs.image.transfer.timeout
File: hdfs-site.xml
Explanation: if the delay is very high for a data operation and the socket needs to wait longer, it is recommended to set this value to a larger value (60000 milliseconds by default) to ensure that the socket will not be timed out.
- Optimize data write efficiency
Properties:
mapreduce.map.output.compress
mapreduce.map.output.compress.codec
File: mapred-site.xml
Explanation: opening these two data can greatly improve the file writing efficiency and reduce the writing time. The first attribute value is modified to true, and the second attribute value is modified to org.apache.hadoop.io.compress.GzipCodec
- Optimize DataNode storage
Attribute: dfs.datanode.failed.volumes.summarized
File: hdfs-site.xml
Explanation: the default value is 0, which means that when a disk in a DataNode fails, it will be considered that the DataNode has been shut down. If it is changed to 1, when a disk fails, the data will be copied to other normal datanodes, and the current DataNode will continue to work.
- Set the number of RPC listeners
Attribute: hbase.regionserver.handler.count
File: hbase-site.xml
Explanation: the default value is 30. It is used to specify the number of RPC listeners. It can be adjusted according to the number of requests from the client. This value is increased when there are many read-write requests.
- Optimize hsstore file size
Attribute: hbase.hregion.max.filesize
File: hbase-site.xml
Explanation: the default value is 10737418240 (10GB). If you need to run the MR task of HBase, you can reduce this value because a region corresponds to a map task. If a single region is too large, the execution time of the map task will be too long. This value means that if the size of hfile reaches this value, the region will be divided into two hfiles.
- Optimize hbase client cache
Attribute: hbase.client.write.buffer
File: hbase-site.xml
Explanation: it is used to specify the HBase client cache. Increasing this value can reduce the number of RPC calls, but it will consume more memory. Otherwise, it will be the opposite. Generally, we need to set a certain cache size to reduce the number of RPCs.
- Specifies the number of rows obtained by scan.next scanning HBase
Attribute: hbase.client.scanner.caching
File: hbase-site.xml
Explanation: used to specify the default number of rows obtained by the scan.next method. The larger the value, the greater the memory consumption.
6. Memory optimization
HBase operation requires a lot of memory overhead. After all, tables can be cached in memory. Generally, 70% of the whole available memory will be allocated to the Java heap of HBase. However, it is not recommended to allocate very large heap memory, because if the GC process lasts too long, the RegionServer will be unavailable for a long time. Generally, 16~48G memory is enough. If the system memory is insufficient because the framework occupies too much memory, the framework will also be dragged to death by the system service.
7. JVM optimization
File involved: hbase-env.sh
- Parallel GC
Parameters: · - XX:+UseParallelGC·
Explanation: turn on parallel GC
- Number of threads simultaneously processing garbage collection
Parameter: - XX:ParallelGCThreads=cpu_core – 1
Explanation: this property sets the number of threads that process garbage collection at the same time.
- Disable manual GC
Parameter: - XX:DisableExplicitGC
Explanation: prevents developers from manually invoking GC
8. Zookeeper optimization
- Optimize Zookeeper session timeout
Parameter: zookeeper.session.timeout
File: hbase-site.xml
Explanation: In hbase-site.xml, set zookeeper.session.timeout to 30 seconds or less to bound failure detection (20-30 seconds is a good start).
This value is directly related to the maximum cycle of server downtime discovered by the master. The default value is 30 seconds. If this value is too small, the RegionServer will be temporarily unavailable when HBase writes a large amount of data and GC occurs, so that no heartbeat packet is sent to ZK, and finally the slave node is considered to be shut down. Generally, about 20 clusters need to be equipped with 5 zookeeper s.
13, Analysis of interview questions in HBase large factory
1. How does HBase write data?
Client write - > store in MemStore until MemStore is full - > flush into a StoreFile until it grows to a certain threshold - > trigger Compact merge - > merge multiple storefiles into a StoreFile, and merge versions and delete data at the same time - > gradually form larger and larger storefiles after storefiles are Compact - > when the size of a single StoreFile exceeds a certain threshold (10G by default) , trigger the Split operation, Split the current Region into two regions, the regions will be offline, and the two child regions from the new Split will be assigned to the corresponding HRegionServer by HMaster, so that the pressure of the original Region can be diverted to two regions
From this process, it can be seen that HBase only adds data without updating and deleting. Users' updating and deleting are logical. At the physical level, updating is only adding, and deleting is only marking.
User write operations only need to enter the memory and return immediately, so as to ensure high I/O performance.
2. Use scenarios of HDFS and HBase
First of all, we need to understand that Hbase is stored based on HDFS.
HDFS:
- Write once, read many times.
- Ensure data consistency.
- It can be deployed in many cheap machines, improve reliability through multiple copies, and provide fault tolerance and recovery mechanism.
HBase:
- Scenarios with large instantaneous write volume, poor database support or high cost support.
- The data needs to be saved for a long time, and the volume will grow to a relatively large scene.
- HBase is not suitable for data models with join, multi-level index and complex table relationship.
- Large amount of data (100s TB data) and the demand for fast random access. For example, the transaction history of Taobao. There is no doubt that the amount of data is huge. Requests for ordinary users must be responded immediately.
- The business scenario is simple and does not require many features in the relational database (such as cross columns, cross tables, transactions, connections, etc.).
3. Storage structure of HBase
Each table in Hbase is divided into multiple sub tables (hregs) according to a certain range through row keys. By default, if an hreg exceeds 256M, it will be divided into two, which are managed by the HRegionServer, which manages which hregs are allocated by the Hmaster. When an hregon accesses a sub table, it will create an hregon object, and then create a store instance for each Column Family of the table. Each store will have 0 or more storefiles corresponding to it, and each StoreFile will correspond to an HFile. HFile is the actual storage file, and an hregon also has a MemStore instance.
4. How does the hot spot phenomenon (data skew) occur and what are the solutions
Hot spots:
In a small period of time, the read and write requests to HBase are concentrated in a very small number of regions, resulting in a sharp increase in the processing requests of the RegionServer where these regions are located, the load is obviously too large, and other rgionservers are obviously idle.
Causes of hot spots:
The rows in HBase are sorted according to the dictionary order of rowkey. This design optimizes the scan operation and can access the relevant rows and the rows that will be read together in a nearby position for scan. However, poor rowkey design is the source of hot spots.
Hot spots occur when a large number of client s directly access one or a few nodes of the cluster (access may be read, write or other operations). A large number of accesses will cause the single machine where the hot region is located to exceed its capacity, resulting in performance degradation and even unavailability of the region, which will also affect other regions on the same RegionServer because the host cannot serve the requests of other regions.
Solutions to hot spots:
In order to avoid write hotspots, rowkey s are designed so that different rows are in the same region, but in the case of more data, the data should be written to multiple regions of the cluster instead of one. Common methods are as follows:
- Salt: add a random number in front of the rowkey to make it different from the beginning of the previous rowkey. The number of prefix types allocated should be consistent with the number of data you want to use scattered to different regions. After adding salt, the rowkeys will be scattered to each region according to the randomly generated prefix to avoid hot spots.
- Hashing: hashing can spread the load across the cluster, but reads are predictable. Using the determined hash allows the client to reconstruct the complete rowkey, and use the get operation to accurately obtain a row data
- Reverse: the third way to prevent hot spots is to reverse rowkeys of fixed length or digital format. This allows the parts of the rowkey that change frequently (the most meaningless part) to be placed first. This can effectively random rowkeys, but at the expense of the orderliness of rowkeys. The example of reversing the rowkey takes the mobile phone number as the rowkey, and the string after reversing the mobile phone number can be used as the rowkey, so as to avoid hot issues caused by starting with a fixed mobile phone number
- Timestamp inversion: a common data processing problem is to quickly obtain the latest version of data. Using the inverted timestamp as a part of rowkey is very useful for this problem. You can use Long.Max_Value - timestamp is appended to the end of the key. For example, [key] [reverse_timestamp], the latest value of [key] can obtain the first record of [key] through scan [key], because rowkeys in HBase are ordered and the first record is the last entered data.
- For example, you need to save a user's operation records and sort them in reverse order according to the operation time. When designing rowkey, you can design [userId inversion] [long. Max_value - timestamp]. When querying all the user's operation record data, you can directly specify the reversed userId. startRow is [userId inversion] [000000000000], and stoprow is [userId inversion] [Long.Max_Value - timestamp]
- If you need to query operation records for a certain period of time, startRow is [user inversion] [Long.Max_Value - start time], and stopRow is [userId inversion] [Long.Max_Value - end time]
- HBase table pre partition: when creating an HBase table, multiple regions are divided in advance according to the possible RowKey instead of the default one, so that the load of subsequent read and write operations can be balanced to different regions to avoid hot spots.
5. rowkey design principle of HBase
Length principle: within 100 bytes, the multiple of 8 is the best. If possible, the shorter the better. Because HFile is stored according to keyvalue, too long rowkey will affect the storage efficiency; secondly, too long rowkey is large in the memory, which will affect the buffer effect and reduce the retrieval efficiency. Finally, most operating systems are 64 bits and the multiple of 8, making full use of the best performance of the operating system.
Hashing principle: high hash, low time field. Avoid hot issues.
The only principle: make use of the sorting feature to store the frequently read data in one piece and the recently accessed data in one piece.
6. Column cluster design of HBase
Principle: if you can reduce column clusters as little as possible within a reasonable range, you can reduce column clusters as much as possible, because column clusters share a region, and the data difference of each column cluster is too large, resulting in low query efficiency.
Optimal: put all key values with strong correlation under the same column cluster, which can not only achieve the highest query efficiency, but also keep accessing different disk files as little as possible. Taking user information as an example, you can store the necessary basic information in one column family, and some additional information in another column family.
7. What is the purpose of compact in HBase, when it is triggered, what are the two types and what are the differences
In hbase, a storefile is formed every time the memstore data is flush ed to the disk. When the number of storefiles reaches a certain level, the storefile needs to be compiled.
Compact's role:
- Merge files
- Clear expired and redundant versions of data
- Improve the efficiency of reading and writing data. 4 HBase implements two compaction modes: minor and major. The difference between the two compaction modes is:
- Minor operation is only used to merge some files and clean up expired versions including minVersion=0 and ttl setting. It does not clean up deleted data or multi version data.
- Major operation is to merge all storefiles under hsstore under Region. The final result is to sort and merge one file.