catalogue
Introduction to HashMap differences from other containers
The difference between HashMap and Hashtable
Hash values are calculated differently
Differences between HashMap and HashSet
Differences between HashMap and TreeMap
The difference between concurrent HashMap and Hashtable
Underlying implementation and data structure of HashMap
HashMap construction method, get, put summary
resize method and capacity expansion
jdk1. Differences between HashMap 8 and 1.7
Add data to HashMap (put key value pairs in pairs)
The process of adding data is as follows
putVal(hash(key), key, value, false, true);
How Hash tables resolve Hash conflicts
Multithreading and dead loop of Hashmap
Symptoms of concurrent problems
Why are wrapper classes such as String and Integer in HashMap suitable as key keys
If the {key} Object in HashMap is of type} Object, what methods should be implemented?
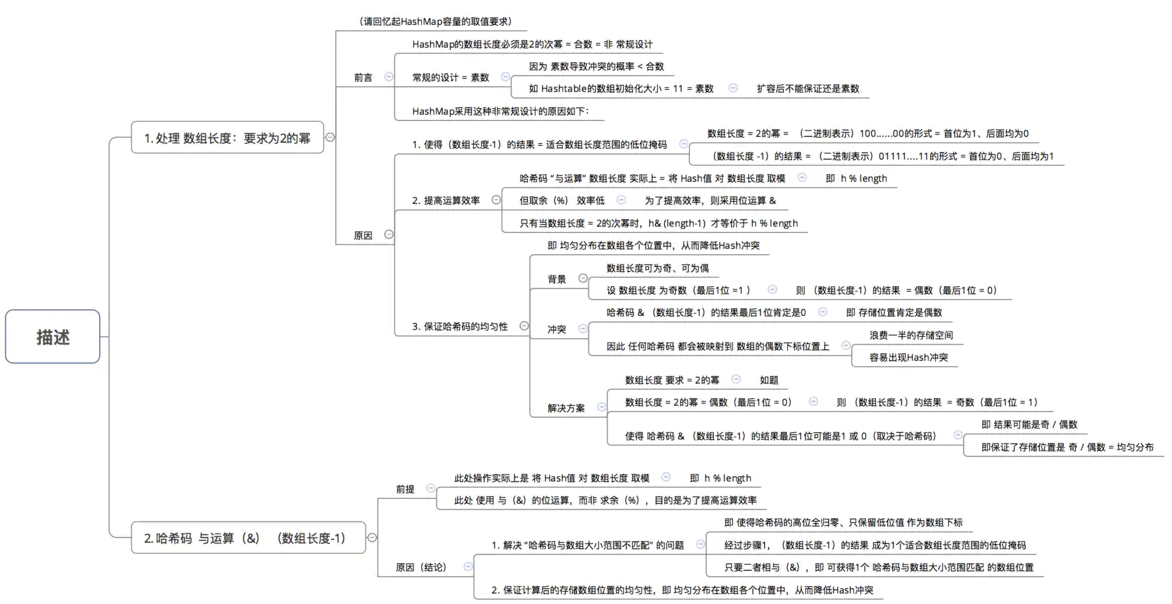
Why is the length of HashMap to the power of 2
Why is Hashmap a red black tree and why is the threshold 8
Why is 0.75 selected as the default load factor for HashMap
Fast failure mechanism of Hashmap
Fast failure mechanism and failure security mechanism
What are the common traversal methods of HashMap?
Article reference Basic knowledge of docs/java/collection/java collection framework & summary of interview questions md · SnailClimb/JavaGuide - Gitee.com
docs/java/collection/hashmap-source-code.md · SnailClimb/JavaGuide - Gitee.com
Introduction to HashMap differences from other containers
Introduction to HashMap
HashMap is mainly used to store key value pairs. It is implemented based on the Map interface of hash table. It is one of the commonly used Java collections and is non thread safe.
HashMap # can store null keys and values, but there can only be one null as a key and multiple null as a value
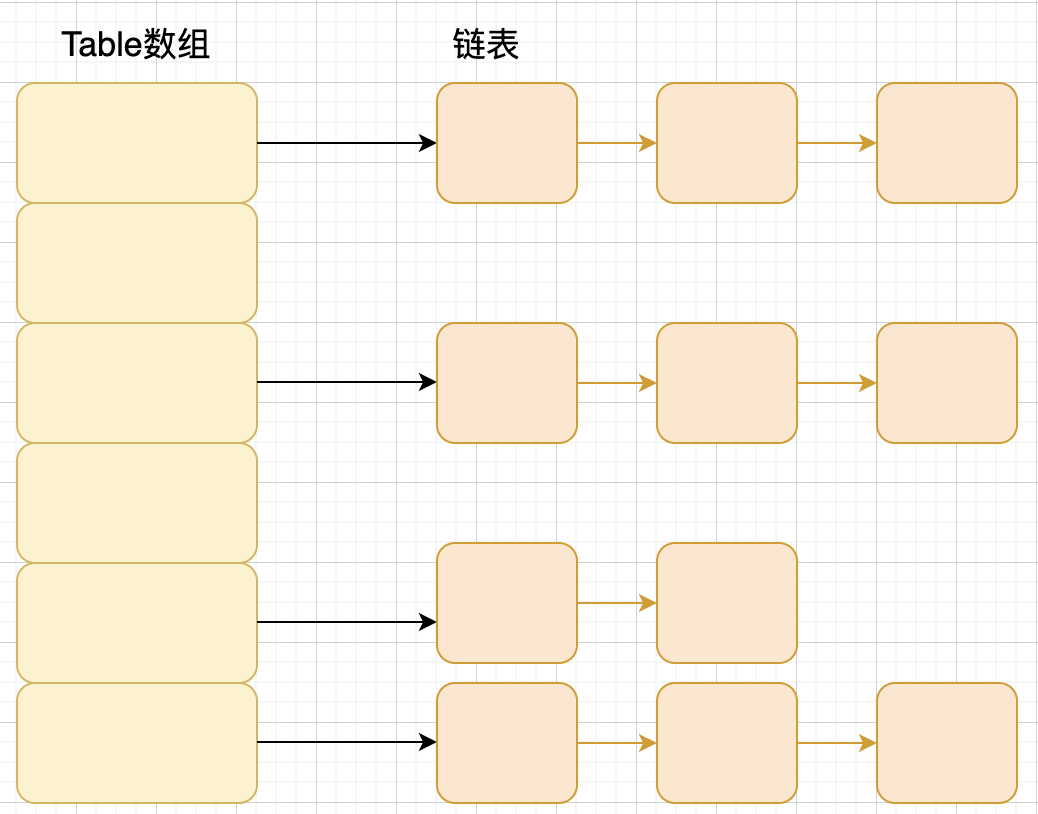
JDK1. Before 8, HashMap was composed of array + linked list. Array is the main body of HashMap, and linked list mainly exists to solve hash conflicts (zipper method to solve conflicts). JDK1. After 8, HashMap has made great changes in resolving hash conflicts. When the length of the linked list is greater than the threshold (the default is 8) (it will be judged before converting the linked list to a red black tree. If the length of the current array is less than 64, it will choose to expand the array first instead of converting to a red black tree), convert the linked list to a red black tree to reduce the search time.
HashMap} the default initialization size is 16. After each expansion, the capacity becomes twice the original. Moreover, HashMap # always uses the power of 2 as the size of the hash table.
The difference between HashMap and Hashtable
1. Thread safety: HashMap , is non thread safe, and Hashtable , is thread safe, because the internal methods of , Hashtable , are basically synchronized , modified. (if you want to ensure thread safety, use concurrent HashMap!);
2 efficiency: because of thread safety, HashMap is a little more efficient than Hashtable. In addition, Hashtable # is basically eliminated. Do not use it in code;
3. Support for Null key and Null value: HashMap can store Null key and value, but there can only be one null as a key and multiple null as a value; Hashtable does not allow null keys and null values, otherwise a null pointerexception will be thrown.
4. The difference between the initial capacity size and each expansion capacity size: ① if the initial capacity value is not specified during creation, the default initial size of Hashtable is 11. After each expansion, the capacity becomes the original 2n+1. HashMap} the default initialization size is 16. After each expansion, the capacity becomes twice the original. ② If the initial capacity value is given during creation, the Hashtable will directly use the size you give, and HashMap will expand it to the power of 2 (the tableSizeFor() method in HashMap is guaranteed, and the source code is given below). That is, HashMap always uses the power of 2 as the size of the hash table. Later, we will explain why it is the power of 2.
5. Underlying data structure: jdk1 After 8, HashMap has made great changes in resolving hash conflicts. When the length of the linked list is greater than the threshold (the default is 8) (it will be judged before converting the linked list to a red black tree. If the length of the current array is less than 64, it will choose to expand the array first instead of converting to a red black tree), convert the linked list to a red black tree to reduce the search time. Hashtable does not have such a mechanism.
Different parent class
HashMap inherits from AbstractMap class, while HashTable inherits from Dictionary (obsolete, see source code for details). However, they all implement map, Cloneable and Serializable interfaces at the same time.
Hashtable provides two more methods: elements () and contains() than HashMap.
The elements() method inherits from dictionary, the parent class of Hashtable. The elements() method is used to return an enumeration of value s in this Hashtable.
The contains() method determines whether the Hashtable contains the passed in value. Its function is consistent with containsValue(). In fact, contansValue() just calls the contains() method.
Null value problem
Hashtable supports neither Null key nor Null value. Hashtable's put() method is described in the comments.
In HashMap, null can be used as a key, and there is only one such key; One or more keys can have null values. When the get() method returns a null value, the key may not exist in the HashMap, or the value corresponding to the key may be null. Therefore, in the HashMap, the get() method cannot be used to judge whether there is a key in the HashMap, but the containsKey() method should be used to judge.
Thread safety
Hashtable is thread safe. It adds the Synchronize method to each method. In a multithreaded concurrent environment, you can directly use hashtable without having to Synchronize its methods
HashMap is not thread safe. In a multithreaded concurrent environment, it may cause problems such as life and death locks. The specific reasons will be analyzed in detail in the next article. When using HashMap, you must add synchronization processing yourself,
Although HashMap is not thread safe, its efficiency will be much better than Hashtable. This design is reasonable. In our daily use, most of the time is single thread operation. HashMap liberates this part of the operation. When multithreading is required, you can use thread safe ConcurrentHashMap. Although concurrent HashMap is thread safe, its efficiency is many times higher than Hashtable. Because ConcurrentHashMap uses a segmentation lock, it does not lock the entire data.
tip: HashMap is jdk1 2, and in jdk1 In 5, the great Doug Lea brought us the concurrent package, and Map has been secure since then. That is, with concurrent HashMap (the understanding of this can be written again next time, or Baidu itself)
Different traversal modes
Both Hashtable and HashMap use Iterator. For historical reasons, Hashtable also uses the Enumeration method.
The Iterator of HashMap is a fail fast Iterator. When other threads change the structure of the HashMap (add, delete, modify elements), a ConcurrentModificationException will be thrown. However, removing an element through the Iterator's remove() method does not throw a ConcurrentModificationException. But this is not an inevitable behavior, depending on the JVM.
In versions before JDK8, Hashtable does not have a fast fail mechanism. In JDK8 and later versions, Hashtable also uses fast fail. (here you can see the comparison of 1.5 and 1.8 JDK source codes)
Different initial capacity
The initial length of the Hashtable is 11. After that, the capacity of each expansion becomes 2n+1 (n is the last length)
The initial length of HashMap is 16, and then each expansion becomes twice the original length
When creating, if the initial capacity value is given, the Hashtable will directly use the size you give, and the HashMap will expand it to the power of 2.
Hash values are calculated differently
In order to get the position of the element, first calculate a hash value according to the KEY of the element, and then use this hash value to calculate the final position
Hashtable directly uses the hashCode of the object. hashCode is a numeric value of type int calculated by JDK according to the address or string or number of the object. Then use the remaining number of rounds to obtain the final position. However, division is very time-consuming. Low efficiency
In order to improve the calculation efficiency, HashMap fixes the size of the hash table to the power of 2. In this way, when taking the modulus budget, it does not need to do division, but only bit operation. Bit operations are much more efficient than division.
Differences between HashMap and HashSet
If you have seen the source code of HashSet, you should know that the bottom layer of HashSet is based on HashMap. (the source code of HashSet , is very, very few, because except that , clone(), writeObject(), and readObject() are implemented by , HashSet , itself, other methods call the methods in , HashMap , directly.
| HashMap | HashSet |
|---|---|
| The Map interface is implemented | Implement Set interface |
| Store key value pairs | Store objects only |
| Call put() to add elements to the map | Call the add() method to add elements to Set + |
| HashMap , use Key to calculate , hashcode | HashSet , uses member objects to calculate the , hashcode , value. For two objects, , hashcode , may be the same, so the equals() method is used to judge the equality of objects |
Differences between HashMap and TreeMap
Both TreeMap and HashMap inherit from AbstractMap, but it should be noted that TreeMap also implements NavigableMap interface and SortedMap interface.
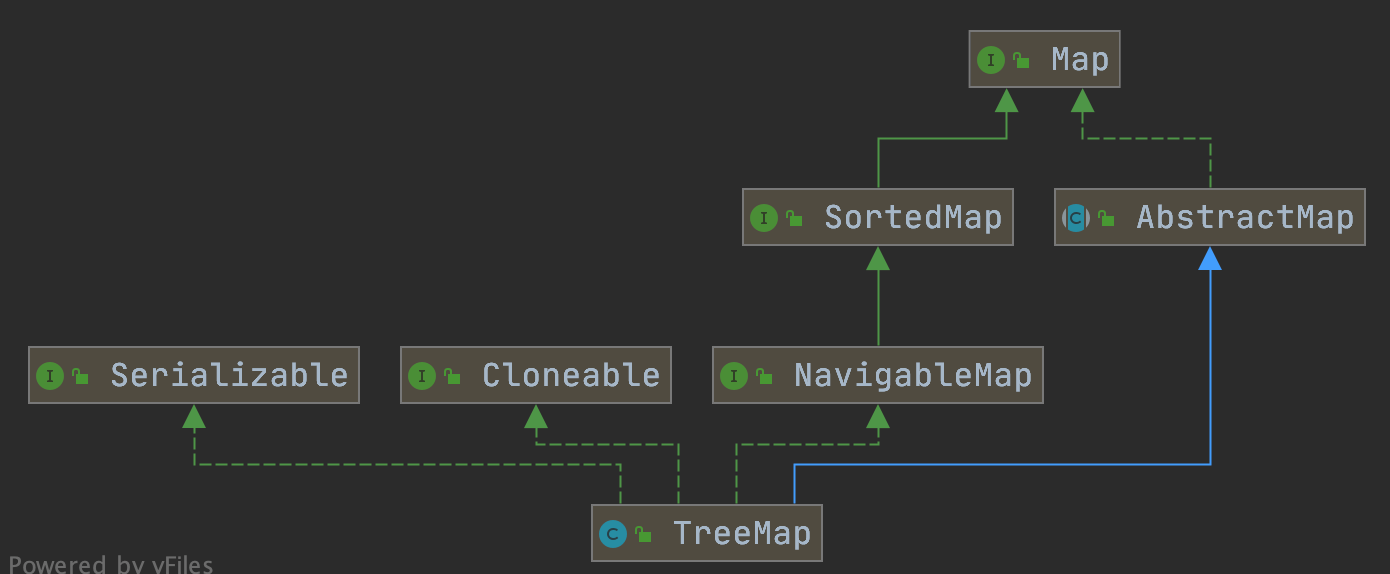
The implementation of the NavigableMap interface gives TreeMap the ability to search elements in the collection.
The implementation of SortedMap interface gives TreeMap the ability to sort the elements in the collection according to the key. The default is to sort by key in ascending order, but we can also specify the sorting comparator. The example code is as follows:
/**
* @author shuang.kou
* @createTime 2020 17:02:00, June 15
*/
public class Person {
private Integer age;
public Person(Integer age) {
this.age = age;
}
public Integer getAge() {
return age;
}
public static void main(String[] args) {
TreeMap<Person, String> treeMap = new TreeMap<>(new Comparator<Person>() {
@Override
public int compare(Person person1, Person person2) {
int num = person1.getAge() - person2.getAge();
return Integer.compare(num, 0);
}
});
treeMap.put(new Person(3), "person1");
treeMap.put(new Person(18), "person2");
treeMap.put(new Person(35), "person3");
treeMap.put(new Person(16), "person4");
treeMap.entrySet().stream().forEach(personStringEntry -> {
System.out.println(personStringEntry.getValue());
});
}
}
output:
person1
person4
person2
person3It can be seen that the elements in TreeMap , are already arranged in ascending order according to the age field of , Person ,.
The above is implemented by passing in anonymous inner classes. You can replace the code with Lambda expressions:
TreeMap<Person, String> treeMap = new TreeMap<>((person1, person2) -> {
int num = person1.getAge() - person2.getAge();
return Integer.compare(num, 0);
});
To sum up, compared with HashMap, TreeMap mainly has the ability to sort the elements in the set according to the key and the ability to search the elements in the set.
The difference between concurrent HashMap and Hashtable
The difference between ConcurrentHashMap and Hashtable is mainly reflected in the way of implementing thread safety.
Underlying data structure: jdk1 The bottom layer of {ConcurrentHashMap} of 7 is implemented by {segmented array + linked list}, jdk1 8. The adopted data structure is the same as hashmap1 8. The structure is the same as array + linked list / Red Black binary tree. Hashtable # and jdk1 8. The underlying data structure of the previous HashMap is similar. They all adopt the form of "array + linked list". The array is the main body of the HashMap, and the linked list mainly exists to solve hash conflicts;
Ways to achieve thread safety (important): ① in jdk1 7, the ConcurrentHashMap (Segment lock) divides the entire bucket array into segments. Each lock locks only part of the data in the container. If multiple threads access the data of different data segments in the container, there will be no lock competition and improve the concurrent access rate. To jdk1 At the time of 8, the concept of "Segment" has been abandoned. Instead, it is directly implemented with the data structure of "Node" array + linked list + red black tree. Concurrency control uses "synchronized" and CAS to operate. (JDK1.6 has made many optimizations on the synchronized lock) the whole looks like an optimized and thread safe} HashMap, although in JDK1.6 You can also see the data structure of {Segment} in 8, but the attributes have been simplified just to be compatible with the old version; ② Hashtable (same lock): using synchronized to ensure thread safety is very inefficient. When one thread accesses the synchronization method, other threads also access the synchronization method, which may enter the blocking or polling state. For example, if put is used to add elements, the other thread cannot use put to add elements or get. The competition will become more and more fierce and the efficiency will be lower.
Comparison of the two:
Hashtable:
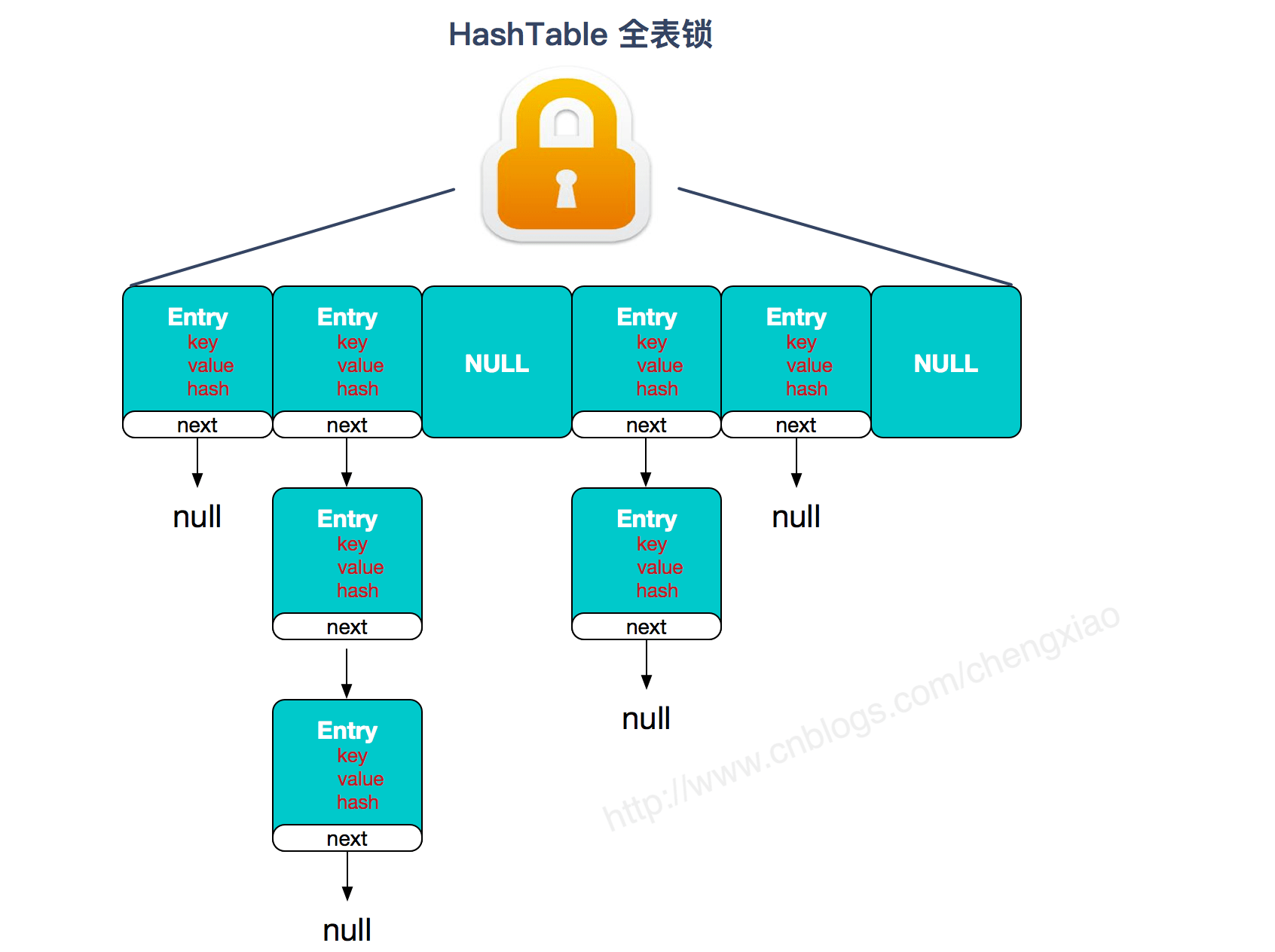
https://www.cnblogs.com/chengxiao/p/6842045.html>
JDK1.7's ConcurrentHashMap:
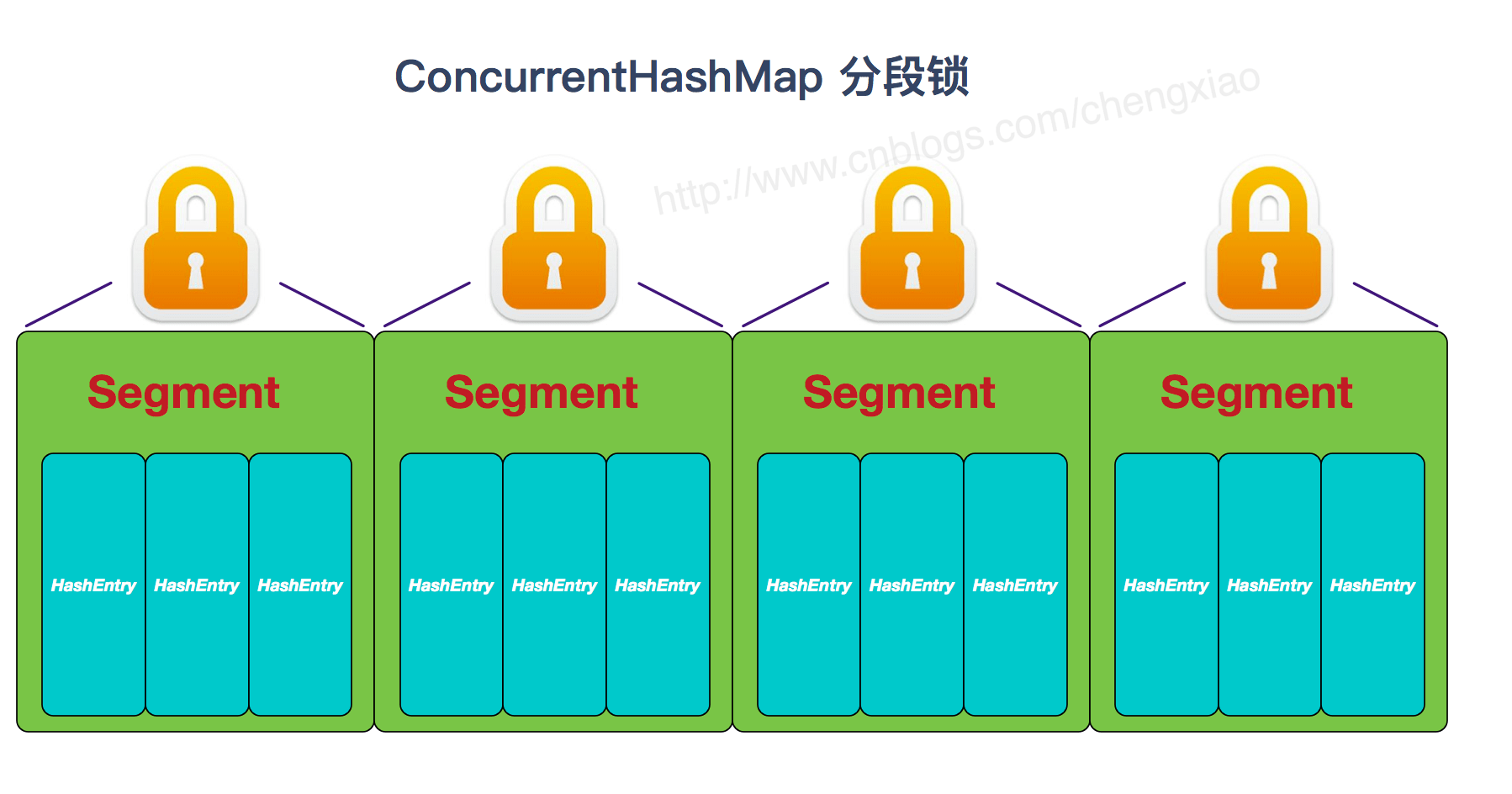
https://www.cnblogs.com/chengxiao/p/6842045.html>
JDK1.8's ConcurrentHashMap:
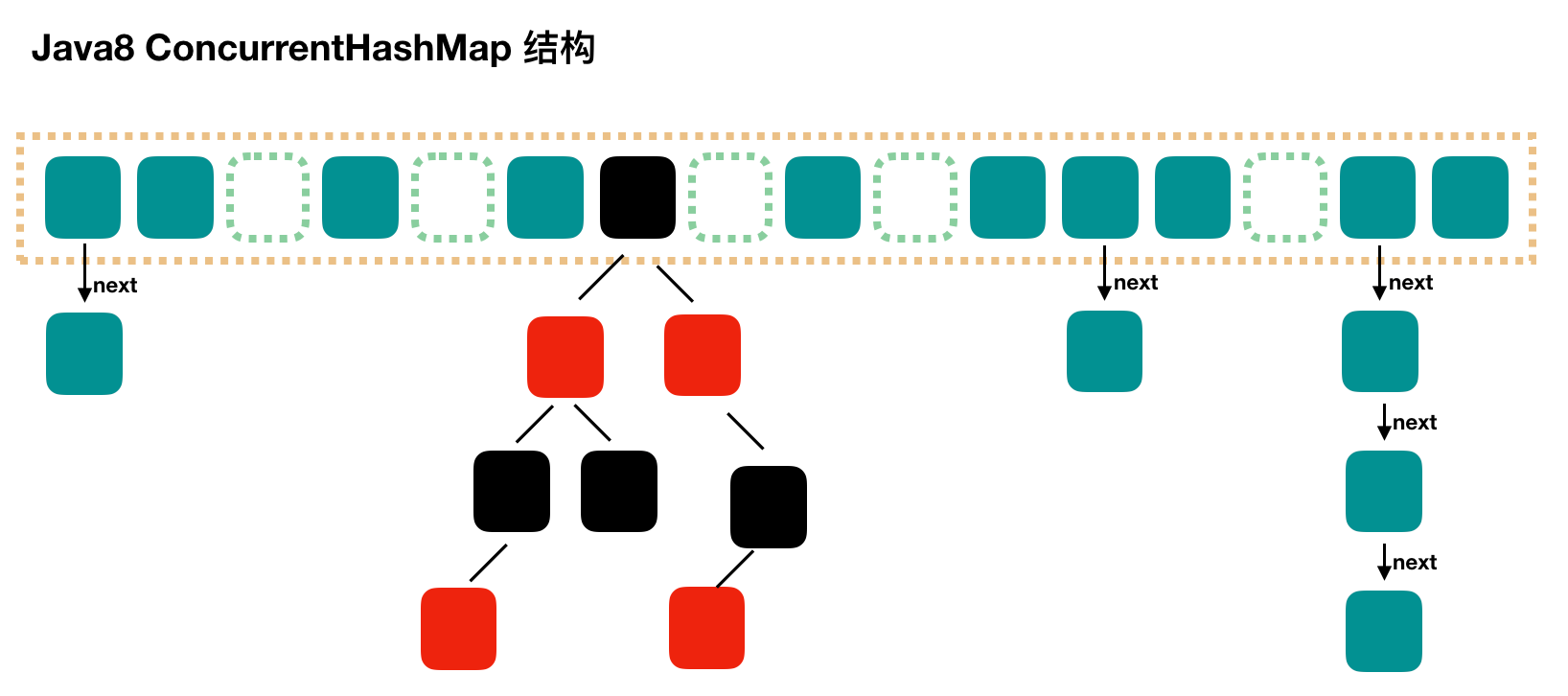
JDK1.8's , ConcurrentHashMap , is no longer a , Segment array + HashEntry array + linked list, but a , Node array + linked list / red black tree. However, Node can only be used in the case of linked list, and {TreeNode needs to be used in the case of red black tree. When the conflict chain is expressed to a certain length, the linked list will be converted into a red black tree.
HashMap specific code
Underlying implementation and data structure of HashMap
JDK1. Before 8
JDK1. Before 8, the bottom layer of the HashMap was the combination of the HashMap array and the linked list, that is, the linked list hash. HashMap obtains the hash value through the hashCode of the key after being processed by the perturbation function, and then judges the storage location of the current element through (n - 1) & hash (where n refers to the length of the array). If there is an element in the current location, it judges whether the hash value and key of the element to be stored are the same. If they are the same, they are directly overwritten, If not, the conflict is solved through the zipper method.
The so-called perturbation function refers to the hash method of HashMap. The hash method, that is, the perturbation function, is used to prevent some poorly implemented hashCode() methods. In other words, the collision can be reduced after using the perturbation function.
Source code of hash method of JDK 1.8 HashMap:
The hash method of JDK 1.8 is simpler than that of JDK 1.7, but the principle remains the same.
static final int hash(Object key) {
int h;
// key.hashCode(): returns the hash value, that is, hashcode
// ^: bitwise XOR
// >>>: move unsigned right, ignore the sign bit, and fill up the empty bits with 0
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}Compare jdk1 7 HashMap hash method source code
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}Compared with jdk1 The performance of 8 hash method and JDK 1.7 hash method will be slightly worse, because it has been disturbed four times after all.
The so-called "zipper method" is to combine linked lists and arrays. In other words, create a linked list array, and each cell in the array is a linked list. If hash conflicts are encountered, the conflicting values can be added to the linked list.
JDK1. After 8
Compared with previous versions, jdk1 After 8, there are great changes in resolving hash conflicts. When the length of the linked list is greater than the threshold (the default is 8) (it will be judged before converting the linked list to a red black tree. If the length of the current array is less than 64, the array expansion will be selected first instead of converting to a red black tree) to convert the linked list to a red black tree to reduce the search time.
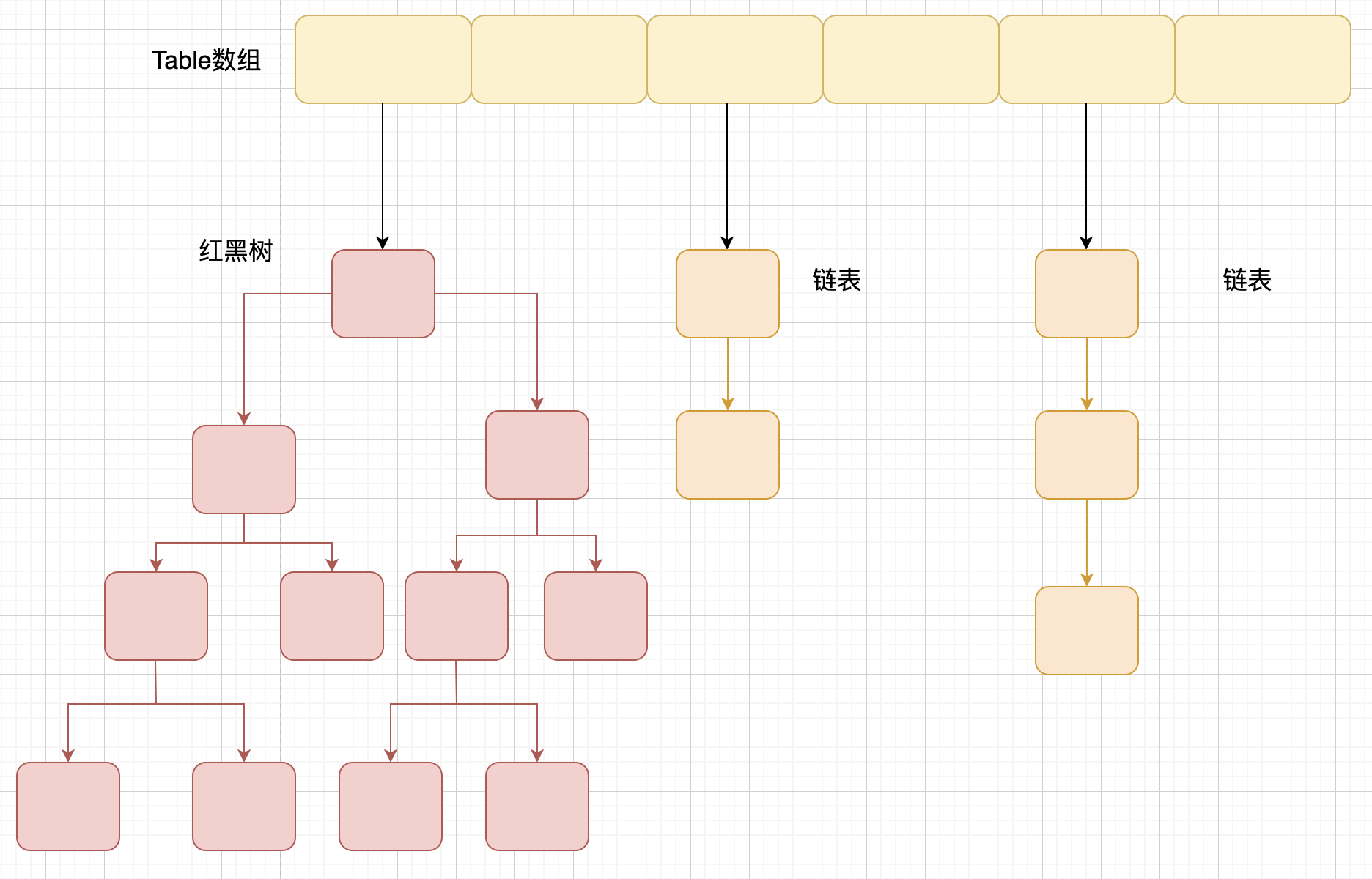
TreeMap, TreeSet and jdk1 Red and black trees are used at the bottom of HashMap after 8. Red black tree is to solve the defect of binary search tree, because binary search tree will degenerate into a linear structure in some cases.
/* ---------------- Fields -------------- */
/**
* Hash table. When used for the first time, it is initialized and resized as needed.
* When allocating space, the length is always a power of 2.
* (In some operations, we have a length of 0 to allow boot mechanisms that are not currently needed.
* Note: HashMap TreeNode<K,V> extends LinkedHashMap. Entry<K,V>
* LinkedHashMap.Entry<K,V> extends HashMap.Node<K,V>
* Therefore, TreeNode is a subclass of Node
*/
transient Node<K,V>[] table;
/**
* Save the cached entrySet()
* Note: the fields of AbstractMap are used for keySet() and values().
* (AbstractMap There are keySet and values fields, and Hashmap has entrySet field.)
*/
transient Set<Map.Entry<K,V>> entrySet;
/**
* map Number of key value mappings in.
*/
transient int size;
/**
* The number of times the Hashmap has been structurally changed.
* Structural changes are those that change the number of mappings in the Hashmap, or a way to change the internal structure (such as resizing, rehash)
* This field makes the iterator on the collection view of HashMap fail quickly.
*/
transient int modCount;
/**
* The size value of the next resizing. (capacity * load factor).
*
* @serial
*/
// (javadoc is described as true when serializing. In addition, if no table array is allocated, this field retains the initial array capacity, or zero
int threshold;
/**
* Load factor of the hash table.
* <p>capacity * load factor= size
* <p>size/load factor=capacity
* <p>size/capacity=load factor
* @serial
*/
final float loadFactor;HashMap construction method, get, put summary
HashMap(int initialCapacity, float loadFactor) assigns loadFactor, sets threshold =tableSizeFor(initialCapacity), that is, greater than or equal to the power of 2 of initialCapacity, and then assigns it to threshold without initializing table.
HashMap(int initialCapacity), call this(initialCapacity, DEFAULT_LOAD_FACTOR).
HashMap(), only set loadFactor = the default value of 0.75, do not set threshold, and the threshold is still 0.
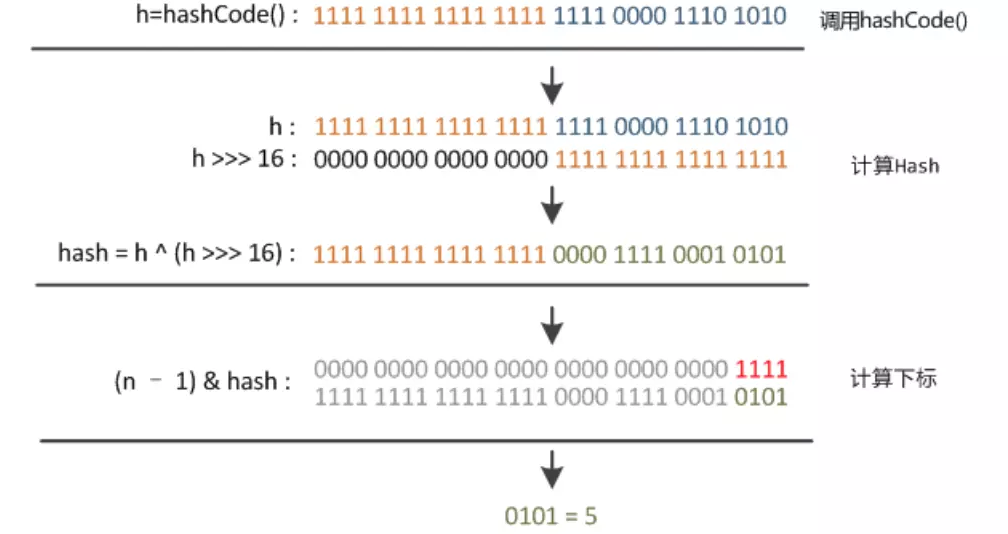
hash(Object key) method, null is 0, otherwise the result is hashcode ^ (hashcode > > > 16), that is, the high 16 bits remain unchanged, and the low 16 bits and the high 16 bits perform or operation.
The get method calls getNode(hash(key), key), and the index of the bucket in table is table Find at length-1 & hash. First check the tab[index] node. If not, if it is a tree bucket, return ((treenode < K, V >) first) getTreeNode(hash, key). Otherwise, keep checking along the linked list e = e.next (judge first)
hash, and then judge whether the key s are equal) until next is null.
getTreeNode method, call the root method on this node to get the root of this node, call find, and find h and k from the root.
The find method uses the given hash and key to find the node from root p (that is, the TreeNode itself). First compare the hash. If the hash is the same, compare the key. If the key is different, then get the comparable class corresponding to the key for comparison. If the comparison results are the same or cannot be compared, call the find method for the right child. If it is not found, let the left child enter the search cycle.
put method, call putVal method, where the resize() method is called first, and the index of the bucket in table is table At length-1 & hash, first check the tab[index] node. If it is null, place a new node. If it is a TreeNode, call the putTreeVal method to assign the return value to e. Otherwise, search along the linked list. If it is found, modify the value of the node. If it is not found at the end, add a node at the end. If the original number is > = 8 and there are 9 nodes after joining, the bucket will be tree and treeifyBin will be called. If a new node is added, the new size > threshold, call the resize method.
resize method, if table is null, if threshold > 0, newCap=threshold, newthreshold = newCap * loadactor. Otherwise, assign 16 to newCap and 12 to newThr. Then create a Node array with the size of newCap. If table is not null, if oldcap > = maximum_ CAPACITY,threshold = Integer.MAX_VALUE, return the old table. Otherwise, newCap = oldcap < < 1, that is, multiply by 2, newThr = newCap * loadactor. Then create a Node array with the size of newCap.
Migrate old data and traverse each bucket of oldTab. If there is only one node, newtab [e.hash & (newcap - 1)] = E. If e is a TreeNode, call the split method of E for reallocation. If there are multiple nodes, create two linked lists, (e.hash & oldcap) = = 0, that is, hash & 1000 = 0, hash & 1111 = hash & 111, indicating that it is still in the original bucket and placed at loTail, otherwise it is placed at hiTail. Then newTab[j] = loHead, and newTab[j + oldCap] = hiHead.
In the treeifyBin method, if tab is null or tab length < MIN_ TREEIFY_ Capacity = 64, resize instead of tree bucket; otherwise, tree bucket.
In the split method, the nodes of a tree bucket are divided into low-level and high-level tree buckets, or if the number of nodes of the new bucket is < = 6, tab[index] is the de tree result.
Construction method
There are four construction methods in HashMap, which are as follows:
// Default constructor.
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
// Constructor containing another "Map"
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);//This method will be analyzed below
}
// Specifies the constructor for capacity size
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// Specifies the constructor for capacity size and load factor
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}The following method ensures that HashMap always uses the power of 2 as the size of the hash table.
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}putMapEntries method:
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
// Determine whether the table has been initialized
if (table == null) { // pre-size
// Uninitialized, s is the actual number of elements of m
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// If the calculated t is greater than the threshold, the threshold is initialized
if (t > threshold)
threshold = tableSizeFor(t);
}
// It has been initialized and the number of m elements is greater than the threshold value. Capacity expansion is required
else if (s > threshold)
resize();
// Add all elements in m to HashMap
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}put method
HashMap only provides put for adding elements, and putVal method is only a method called for put method, which is not provided to users.
The analysis of the elements added to the putVal method is as follows:
If there is no element in the array position, it will be inserted directly.
If there are elements in the located array position, it will be compared with the key to be inserted. If the keys are the same, it will be directly overwritten. If the keys are different, judge whether p is a tree node. If so, call e = ((treenode < K, V >) p) Puttreeval (this, tab, hash, key, value) adds the element into the. If not, traverse the linked list (insert the tail of the linked list).
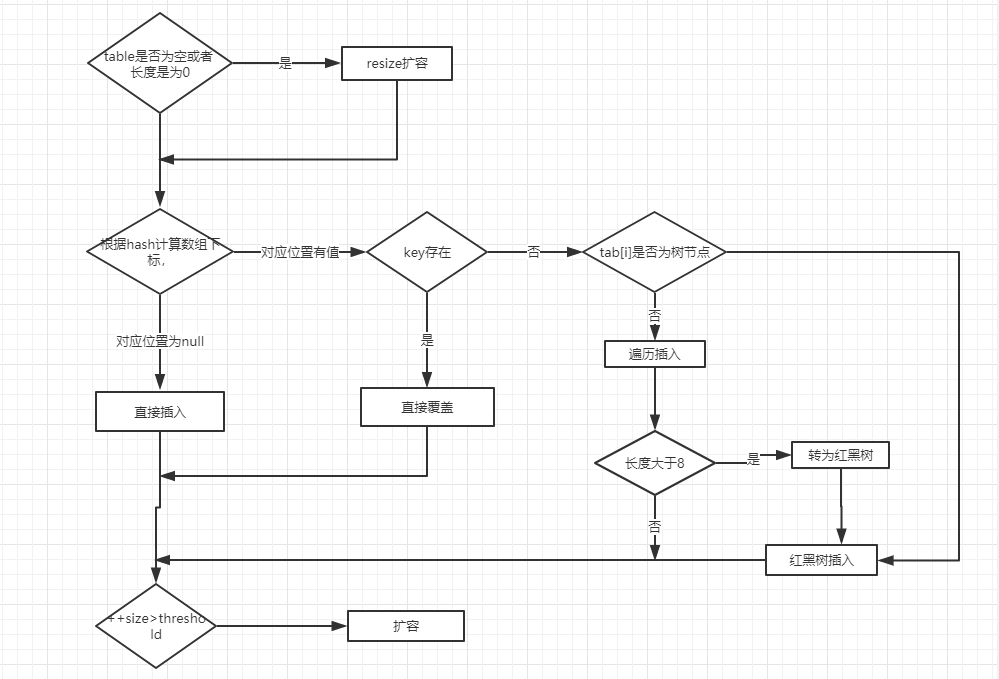
Note: there are two small problems in the figure above:
After direct overwrite, you should return. There will be no subsequent operation. Refer to jdk8 HashMap Java 658 lines( issue#608).
When the length of the linked list is greater than the threshold (8 by default) and the length of the HashMap array exceeds 64, the operation of converting the linked list to a red black tree will be executed. Otherwise, it will only expand the capacity of the array. Refer to the {treeifyBin() method of HashMap( issue#1087).
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// The table is uninitialized or has a length of 0. Capacity expansion is required
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// (n - 1) & hash determines the bucket in which the elements are stored. The bucket is empty, and the newly generated node is placed in the bucket (at this time, the node is placed in the array)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// Element already exists in bucket
else {
Node<K,V> e; K k;
// The hash value of the first element (node in the array) in the comparison bucket is equal, and the key is equal
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// Assign the first element to e and record it with E
e = p;
// hash values are not equal, that is, key s are not equal; Red black tree node
else if (p instanceof TreeNode)
// Put it in the tree
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// Is a linked list node
else {
// Insert a node at the end of the linked list
for (int binCount = 0; ; ++binCount) {
// Reach the end of the linked list
if ((e = p.next) == null) {
// Insert a new node at the end
p.next = newNode(hash, key, value, null);
// When the number of nodes reaches the threshold (8 by default), execute the treeifyBin method
// This method will determine whether to convert to red black tree according to HashMap array.
// Only when the array length is greater than or equal to 64, the red black tree conversion operation will be performed to reduce the search time. Otherwise, it is just an expansion of the array.
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// Jump out of loop
break;
}
// Judge whether the key value of the node in the linked list is equal to the key value of the inserted element
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// Equal, jump out of loop
break;
// Used to traverse the linked list in the bucket. Combined with the previous e = p.next, you can traverse the linked list
p = e;
}
}
// Indicates that a node whose key value and hash value are equal to the inserted element is found in the bucket
if (e != null) {
// Record the value of e
V oldValue = e.value;
// onlyIfAbsent is false or the old value is null
if (!onlyIfAbsent || oldValue == null)
//Replace old value with new value
e.value = value;
// Post access callback
afterNodeAccess(e);
// Return old value
return oldValue;
}
}
// Structural modification
++modCount;
// If the actual size is greater than the threshold, the capacity will be expanded
if (++size > threshold)
resize();
// Post insert callback
afterNodeInsertion(evict);
return null;
}Let's compare jdk1 7 code of the put method
The analysis of put method is as follows:
If there is no element in the array position, it will be inserted directly.
2 if there is an element in the position of the array, traverse the linked list with this element as the head node, and compare it with the inserted key in turn. If the key is the same, it will be directly overwritten. If the key is different, the head insertion method will be used to insert the element.
public V put(K key, V value)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) { // First traversal
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i); // Reinsert
return null;
}get method
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// Array elements are equal
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// More than one node in bucket
if ((e = first.next) != null) {
// get in tree
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// get in linked list
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}Complexity of put and get
Before JDK8
The single linked list HashMap is used as a bucket to store elements with hash collision. Whether it is get or put method, the steps can be divided into the first step to find the bucket (the bucket finding time is O(1), which can be ignored), and the second step to operate in the bucket (find or insert). First, the best case is that there is no hash collision, that is, all elements are allocated in different buckets, and the worst case is that all elements collide together, that is, they are allocated in the same bucket. Therefore, the complexity of the situation is as follows:
Best case:
O(1)
GET worst case:
O(N) (i.e. the time complexity of single linked list query)
average:
O(1)
PUT best case:
O(1)
PUT worst case:
O (1) (the header insertion method was used before jdk8, that is, the header of the single linked list was directly inserted without traversal)
average:
O(1)
After JDK8
When there are more than 6 elements in the bucket, the storage structure in the bucket will be transformed from a single linked list to a red black tree. The time complexity is as follows
Best case:
O(1)
GET worst case:
When there are no more than 6 elements in the bucket: O (n) (that is, the time complexity of single linked list query)
When there are no more than 6 elements in the bucket: O(logN) (the time complexity of red black tree query is O(logN), which is similar to binary search)
average:
O(1)
PUT best case:
O(1)
PUT worst case:
When there are no more than 6 elements in the bucket: O(N)(JDK8 only uses the tail insertion method, traverse to the tail and then insert)
When there are more than 6 elements in the bucket: O(logN) (the time complexity of red black tree insertion is O(logN), which is similar to binary insertion)
average:
O(1)
resize method and capacity expansion
HashMap has a capacity expansion mechanism, that is, it will be expanded when the capacity expansion conditions are met. The capacity expansion condition of HashMap is that when the number (size) of elements in HashMap exceeds the threshold, it will be expanded automatically.
In HashMap, threshold = loadFactor * capacity.
loadFactor is the load factor, which indicates the full degree of HashMap. The default value is 0.75f. Setting it to 0.75 has one advantage, that is, 0.75 is exactly 3 / 4, and capacity is the power of 2. Therefore, the product of two numbers is an integer.
For a default HashMap, by default, capacity expansion will be triggered when its size is greater than 12 (16 * 0.75).
Capacity expansion is divided into two steps
Capacity expansion: create a new empty Entry array, which is twice as long as the original array.
By ensuring that the initialization capacity is the power of 2, and the capacity is also expanded to twice the previous capacity, it is ensured that the capacity of HashMap is always the power of 2.
ReHash: traverse the original Entry array and ReHash all entries to the new array.
Why re Hash
Because after the length is expanded, the rules of Hash also change.
Hash formula -- > index = hashcode (Key) & (Length - 1)
The original Length is 8 bits and the calculated value is 2. The new Length is 16 bits. The calculated value is obviously different.
Before capacity expansion:
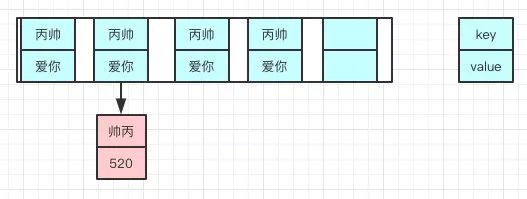
After capacity expansion:

final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// If you exceed the maximum value, you won't expand any more, so you have to collide with you
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// If the maximum value is not exceeded, it will be expanded to twice the original value
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// Calculate the new resize upper limit
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// Move each bucket to a new bucket
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// Original index
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// Original index + oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// Put the original index into the bucket
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// Put the original index + oldCap into the bucket
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
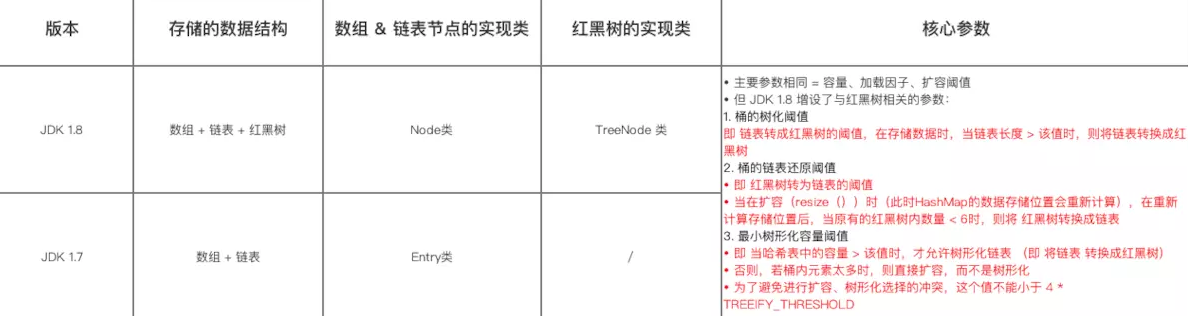
}jdk1. Differences between HashMap 8 and 1.7
data structure
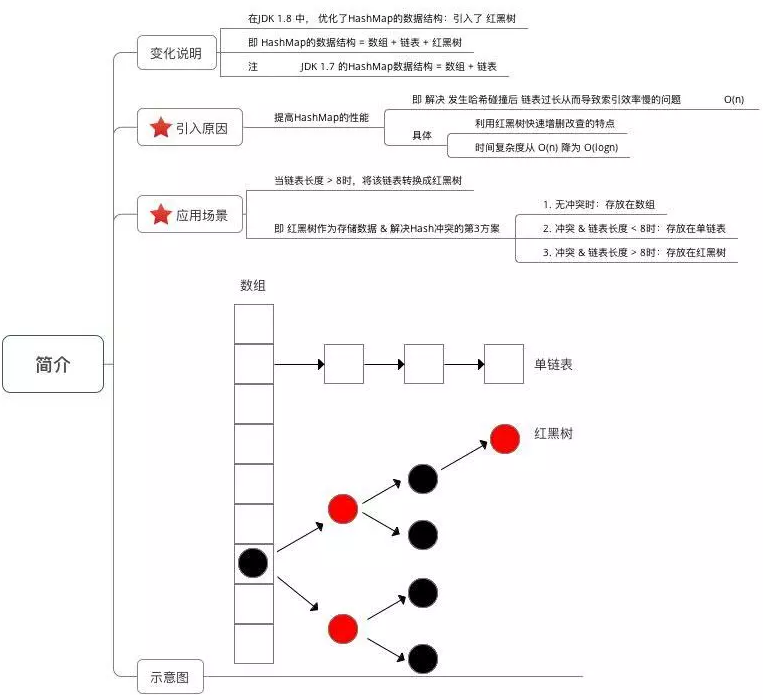
Important parameters
The main parameters in HashMap are the same as JDK 1.7, i.e. capacity, loading factor and capacity expansion threshold
However, due to the introduction of red black tree into the data structure, parameters related to red black tree are added.
/** * The main parameters are the same as JDK 1.7 * Namely: capacity, loading factor and capacity expansion threshold (requirements and scope are the same) */ // 1. Capacity: must be a power of 2 & < maximum capacity (the 30th power of 2) static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // Default capacity = 16 = 1 < < 4 = shift 1 in 00001 to the left 4 bits = 10000 = decimal 2 ^ 4 = 16 static final int MAXIMUM_CAPACITY = 1 << 30; // Maximum capacity = the 30th power of 2 (if the incoming capacity is too large, it will be replaced by the maximum value) // 2. Load factor: a measure of how full a HashMap can reach before its capacity automatically increases final float loadFactor; // Actual loading factor static final float DEFAULT_LOAD_FACTOR = 0.75f; // Default load factor = 0.75 // 3. Capacity expansion threshold: when the size of the hash table is greater than or equal to the capacity expansion threshold, the hash table will be expanded (that is, the capacity of the HashMap will be expanded) // a. Capacity expansion = resize the hash table (that is, rebuild the internal data structure), so that the hash table will have about twice the number of buckets // b. Capacity expansion threshold = capacity x loading factor int threshold; // 4. Others transient Node<K,V>[] table; // Node type array for storing data, length = power of 2; Each element of the array = 1 single linked list transient int size;// The size of the HashMap, that is, the number of key value pairs stored in the HashMap /** * Parameters related to red black tree */ // 1. Treelization threshold of bucket: that is, the threshold for converting the linked list into a red black tree. When storing data, when the len gt h of the linked list is > this value, the linked list will be converted into a red black tree static final int TREEIFY_THRESHOLD = 8; // 2. Linked list restore threshold of bucket: that is, the threshold for converting the red black tree into a linked list. When the capacity is expanded (resize ()) (at this time, the data storage location of HashMap will be recalculated). After recalculating the storage location, when the number in the original red black tree is < 6, the red black tree will be converted into a linked list static final int UNTREEIFY_THRESHOLD = 6; // 3. Minimum tree capacity threshold: that is, only when the capacity in the hash table is > this value can the tree linked list be allowed (that is, the linked list is converted into a red black tree) // Otherwise, if there are too many elements in the bucket, the capacity will be expanded directly instead of being tree shaped // In order to avoid the conflict between capacity expansion and tree selection, this value cannot be less than 4 * tree_ THRESHOLD static final int MIN_TREEIFY_CAPACITY = 64;
Declare 1 HashMap object
The constructor of 1.8 is similar to JDK 1.7, and the specific analysis can be seen above
Here, it is only used to receive the initial capacity and load factor, but there is still no real initialization hash table, that is, initialize the storage array table
Here is the conclusion: the real initialization of the hash table (initialization of the storage array table) is when the key value pair is added for the first time, that is, when put () is called for the first time. This will be described in detail below
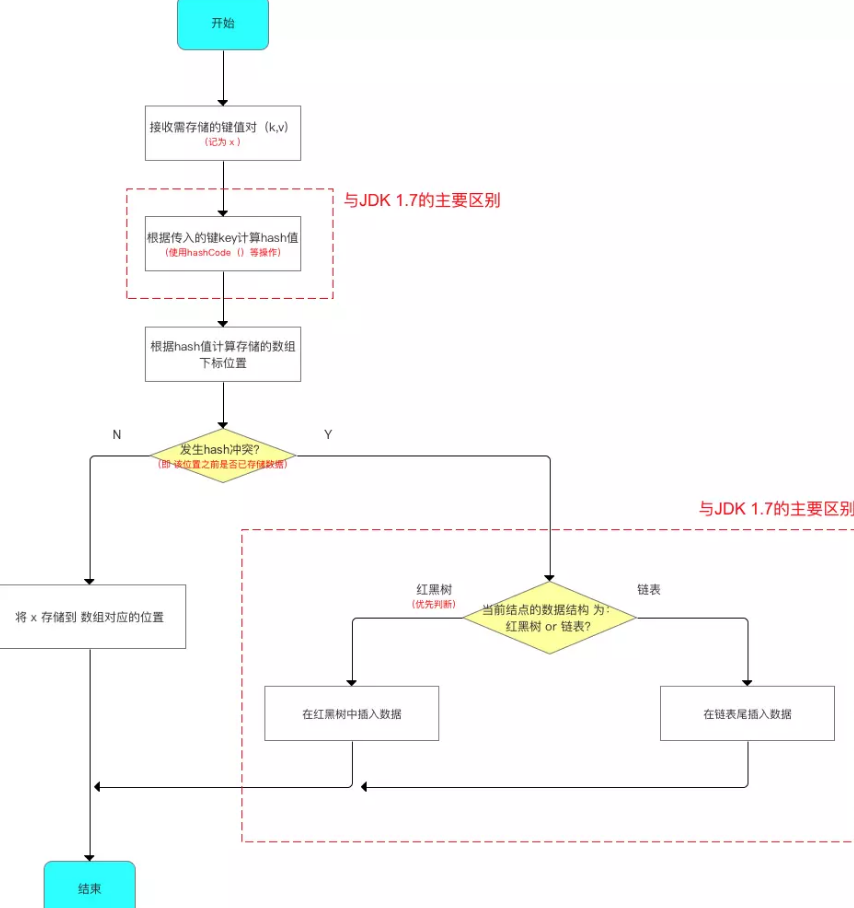
Add data to HashMap (put key value pairs in pairs)
In this step, it is quite different from JDK 1.7:

The process of adding data is as follows
/**
* Function use prototype
*/
map.put("Android", 1);
map.put("Java", 2);
map.put("iOS", 3);
map.put("data mining ", 4);
map.put("product manager", 5);
/**
* Source code analysis: mainly analyzes the put function of HashMap
*/
public V put(K key, V value) {
// 1. Calculate the Hash value of the Key key passed into the array - > > analysis 1
// 2. Call putVal() to add data - > > analysis 2
return putVal(hash(key), key, value, false, true);
}hash(key)
/**
* Analysis 1: hash(key)
* Function: calculate the Hash code (Hash value, Hash value) of incoming data
* The implementation of this function is different in JDK 1.7 and 1.8, but the principle is the same = perturbation function = make the distribution of hash codes (hash values) generated according to keys more uniform and random, and avoid hash value conflict (that is, different keys but generate the same hash value)
* JDK 1.7 9 times of perturbation processing = 4 times of bit operation + 5 times of XOR operation
* JDK 1.8 Simplified perturbation function = only 2 perturbations = 1 bit operation + 1 XOR operation
*/
// JDK 1.7 implementation: convert key to hash code (hash value) operation = use hashCode() + 4 bit operations + 5 XOR operations (9 perturbations)
static final int hash(int h) {
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// JDK 1.8 implementation: convert key to hash code (hash value) operation = use hashCode() + 1 bit operation + 1 XOR operation (2 disturbances)
// 1. Take the hashcode value: H = key hashCode()
// 2. High bit participates in low bit operation: H ^ (H > > > 16)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
// a. When key = null, the hash value = 0, so the key of HashMap can be null
// Note: compared with HashTable, HashTable directly hashCode () the key. If the key is null, an exception will be thrown, so the key of HashTable cannot be null
// b. When the key ≠ null, the hashCode() of the key is calculated first (recorded as h), and then the hash code is disturbed: the binary code after the bit XOR (^) hash code itself is shifted to the right by 16 bits
}
/**
* Function analysis for calculating storage location: indexFor(hash, table.length)
* Note: this function only exists in JDK 1.7. In fact, it does not exist in JDK 1.8 (write it directly with one statement), but the principle is the same
* In order to facilitate the explanation, I'm here in advance
*/
static int indexFor(int h, int length) {
return h & (length-1);
// The result of the hash code perturbation processing and the operation (&) (array length - 1) will finally get the position stored in the array table (i.e. array subscript and index)
}Summarize the process of calculating the position (i.e. array subscript and index) stored in the array table
The difference between JDK 1.7 and JDK 1.7 lies in the secondary processing method (perturbation processing) of hash code during the solution of hash value
hash value solving process

After knowing how to calculate the position stored in the array table, the so-called know it, but you need to know why. Next, I will explain why to calculate it in this way, that is, I mainly answer the following three questions:
Why not directly use the hash code processed by hashCode () as the subscript position of the storage array table?
Why use hash code and operation (&) (array length - 1) to calculate array subscript?
Why is it necessary to deal with the hash code twice before calculating the array subscript: perturbation?
Before answering these three questions, please remember a core idea:
The fundamental purpose of all processing is to improve the randomness of the subscript position of the array storing key value & distribution uniformity, and try to avoid hash value conflict. That is, for different keys, the stored array subscript positions should be as different as possible
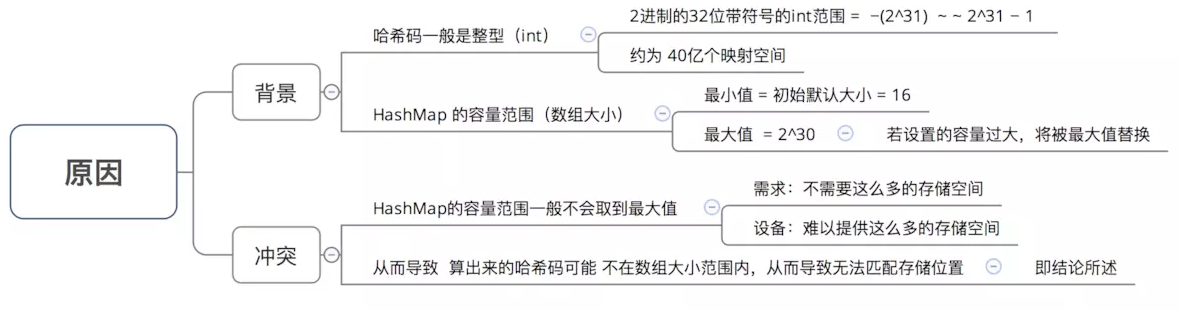
Question 1: why not directly use the hash code processed by hashCode () as the subscript position of the storage array table?
Conclusion: it is easy to find that the hash code does not match the size range of the array, that is, the calculated hash code may not be within the size range of the array, resulting in failure to match the storage location
Cause description
- In order to solve the problem of "mismatch between hash code and array size range", HashMap gives a solution: hash code and operation (&) (array length - 1), that is, problem 3
Question 2: why use hash code and operation (&) (array length - 1) to calculate array subscript?
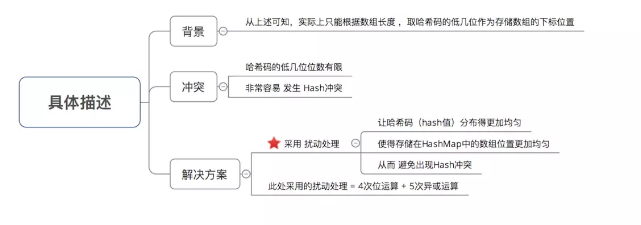
Conclusion: according to the capacity (array length) of HashMap, a certain number of low bits of hash code are taken as the stored array subscript position on demand, so as to solve the problem of "mismatch between hash code and array size range"
Question 3: why should the hash code be processed twice before calculating the array subscript: perturbation processing?
Conclusion: increase the randomness of the low order of Hash code to make the distribution more uniform, so as to improve the randomness & uniformity of the storage subscript position of the corresponding array, and finally reduce Hash conflict
putVal(hash(key), key, value, false, true);
Here are two main points:
After calculating the storage location, how to store the data in the hash table
Specifically, how to expand the capacity, that is, the capacity expansion mechanism
Main explanation point 1: after calculating the storage location, how to store the data in the hash table
Because the red black tree is added to the data structure, it is necessary to judge the data structure many times when storing the data in the hash table: array, red black tree and linked list
Difference from JDK 1.7: JDK 1.7 only needs to judge the array & linked list
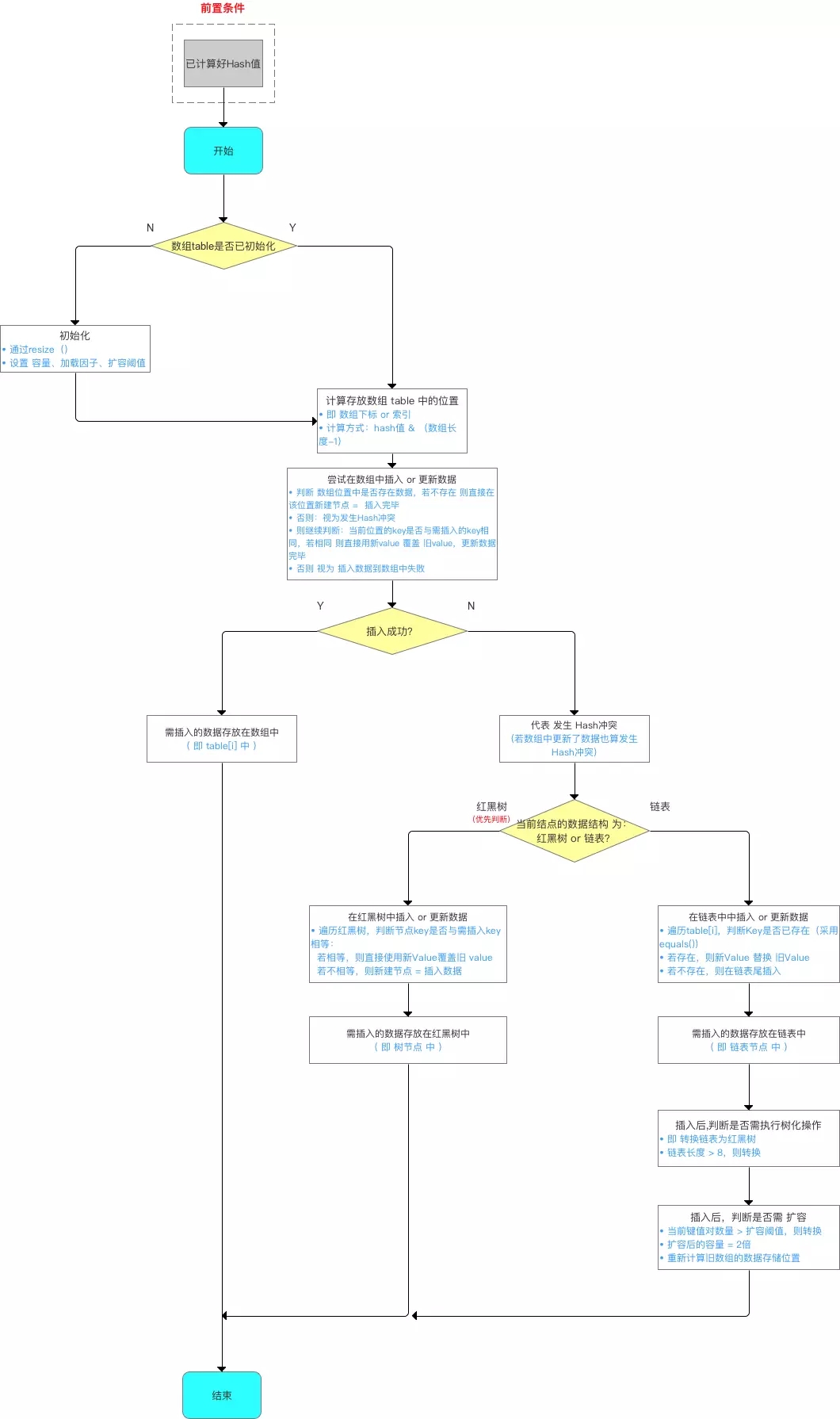
Main explanation point 2: capacity expansion mechanism (i.e. resize() function method)
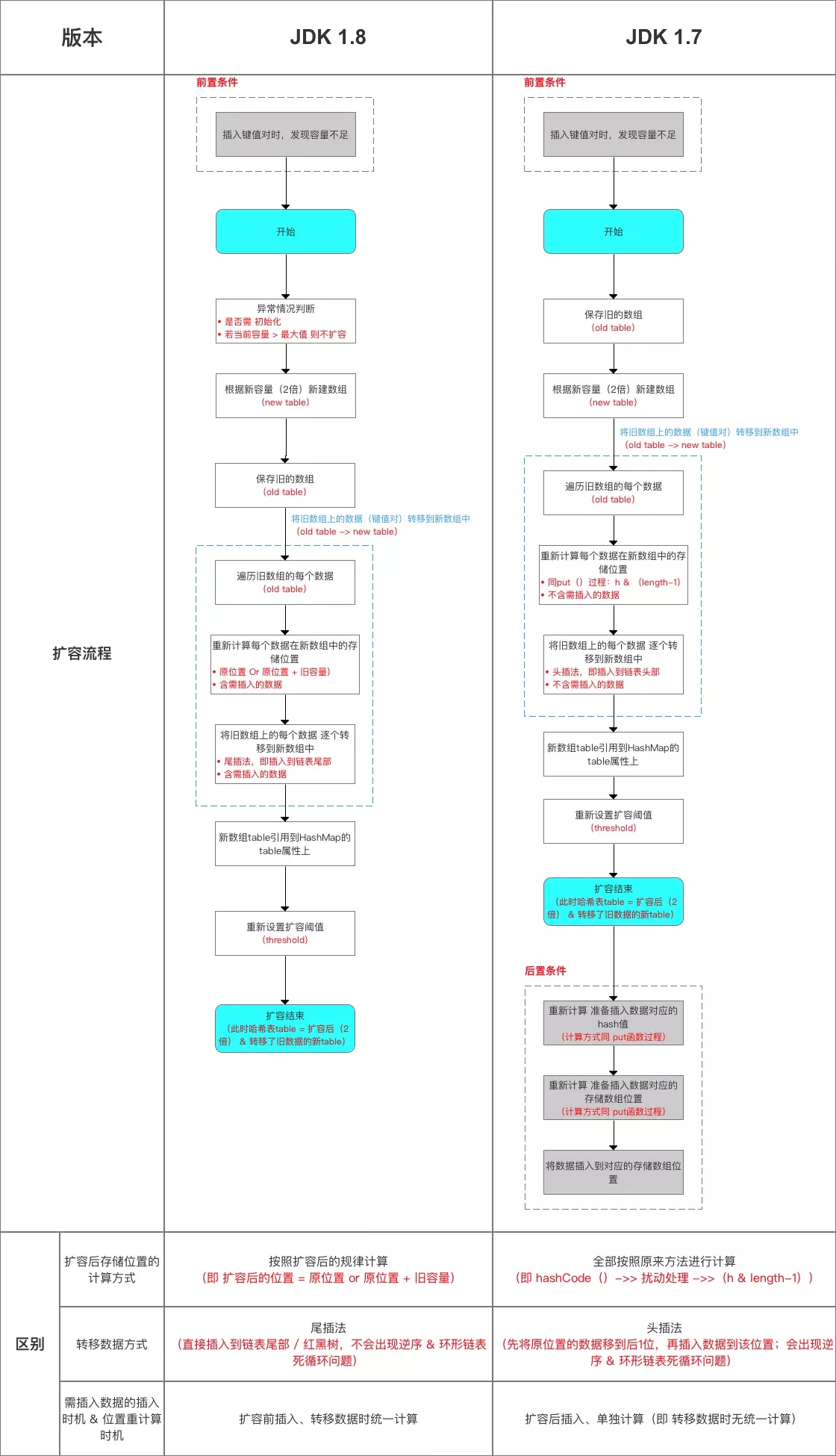
Here we mainly explain how to recalculate the data storage location during JDK 1.8 capacity expansion


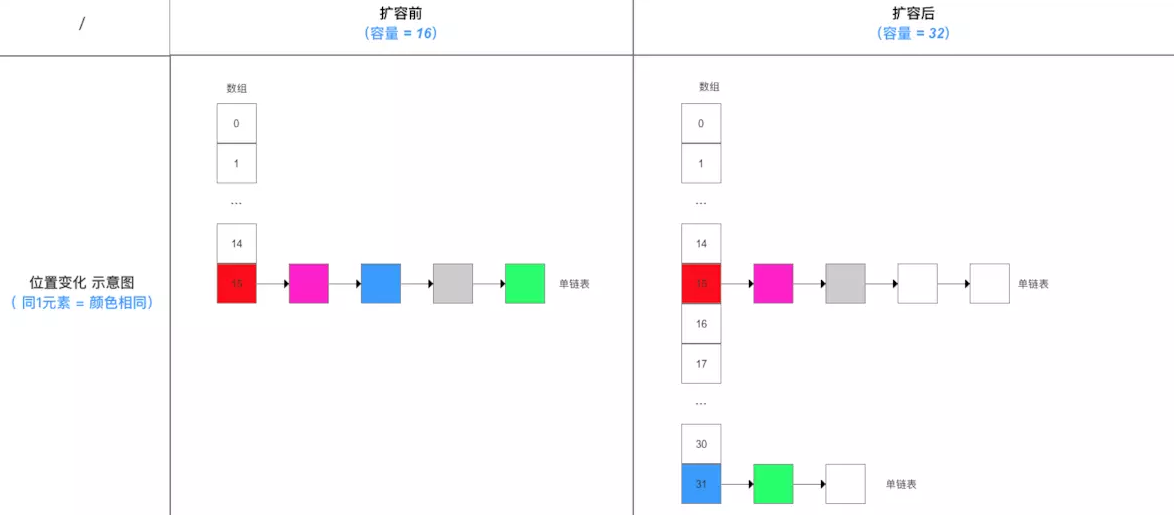
Schematic diagram of array position conversion
Differences with JDK 1.7

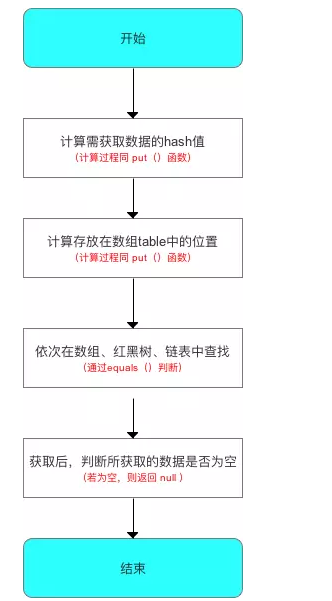
Get data from HashMap
If you understand the principle of the put () function above, the get () function is very easy to understand, because the process principles of the two are almost the same
The process of get() function is as follows:
Other operations on HashMap
The principle of the source code of the above method is the same as JDK 1.7, which will not be described here
Other questions about HashMap
How Hash tables resolve Hash conflicts
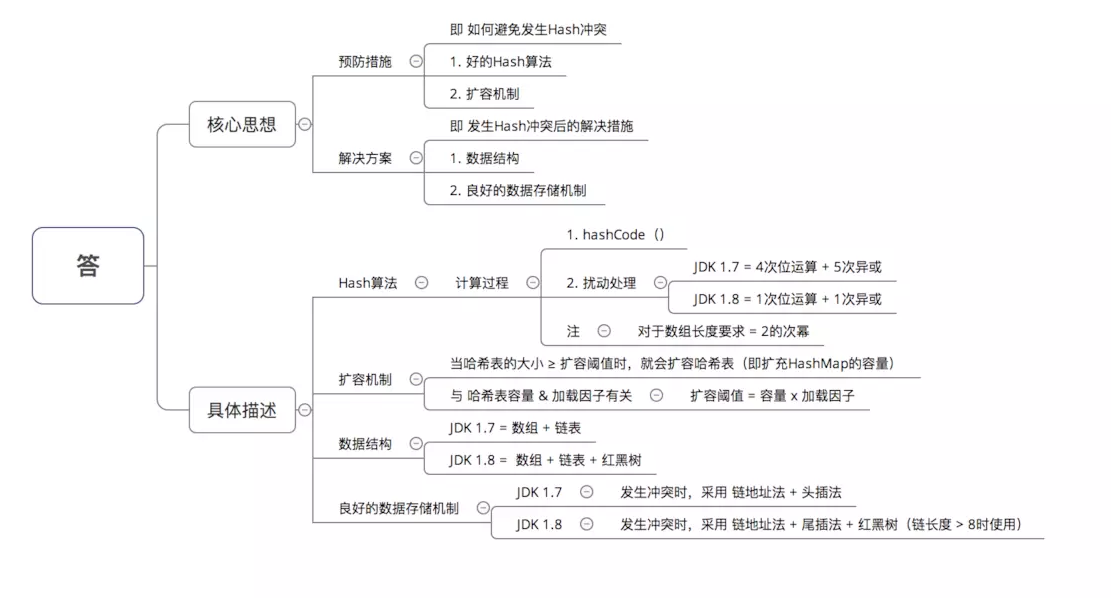
Why does HashMap have the following characteristics: key value is allowed to be empty, thread is unsafe, order is not guaranteed, and the storage location changes over time
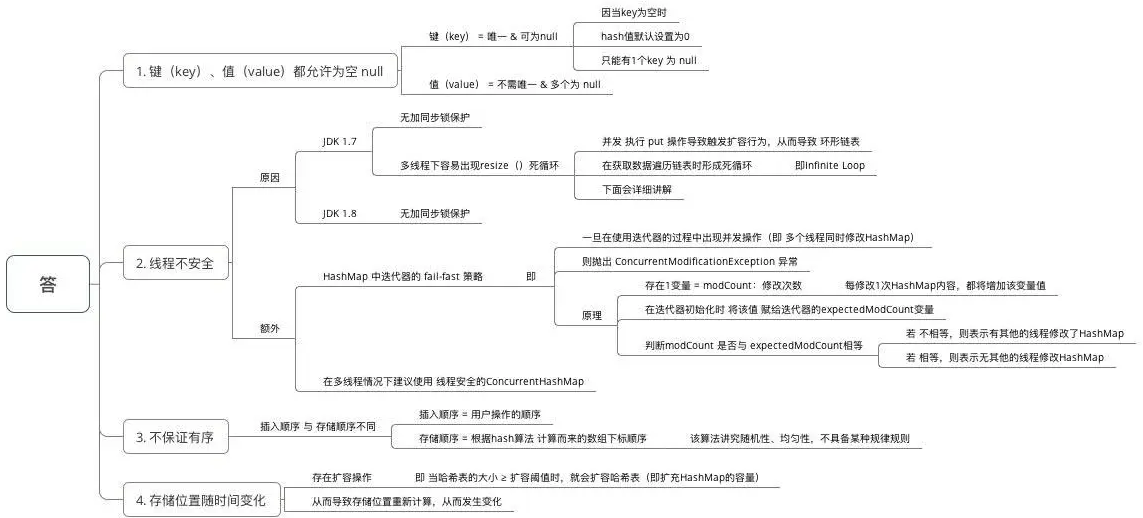
Multithreading and dead loop of Hashmap
The main reason is that Rehash under concurrency will cause a circular linked list between elements.
Because JDK 1.8 transfer data operation = traverse the linked list in the positive order of the old linked list and insert it successively at the tail of the new linked list, there will be no reverse order and inversion of the linked list, so it is not easy to have a ring linked list.
This is also the reason why hashmap is changed from ab initio interpolation to tail interpolation.
However, JDK 1.8 is still thread unsafe, because it is not protected by synchronization lock, there will still be other problems, such as data loss. ConcurrentHashMap is recommended for concurrent environments.
Symptoms of concurrent problems
Multithreaded put may lead to get deadlock
The root of this loop is the operation on an unprotected shared variable - a "HashMap" data structure. When "synchronized" is added to all operation methods, everything returns to normal. Is this a jvm bug? It should be said that this phenomenon was reported a long time ago. Sun engineers do not think this is a bug, but suggest that "concurrent HashMap" should be used in such a scenario,
The high CPU utilization is generally due to the dead cycle, which causes some threads to run all the time and occupy CPU time. The reason for the problem is that HashMap is non thread safe. When multiple threads put, it causes an endless loop of a key value Entry key List. This is the problem.
When another thread gets the key of the Entry List loop, the get will be executed all the time. The final result is more and more thread loops, which eventually leads to the server dang. We generally think that when HashMap repeatedly inserts a value, it will overwrite the previous value. That's right. However, for multithreaded access, due to its internal implementation mechanism (in the multithreaded environment and without synchronization, put ting on the same HashMap may cause two or more threads to rehash at the same time, which may lead to the occurrence of circular key table. Once the thread occurs, it will not be able to terminate and continue to occupy CPU, resulting in high CPU utilization), There may be security problems.
Multi thread put may result in element loss
The main problem lies in the new Entry (hash, key, value, e) of the addEntry method. If both threads obtain e at the same time, their next element is e. when assigning values to the table element, one succeeds and the other is lost.
After put ting a non null element, the get result is null
In the transfer method, the code is as follows:
void transfer(Entry[] newTable) {
Entry[] src = table; int newCapacity = newTable.length; for (int j = 0; j < src.length; j++) {
Entry e = src[j]; if (e != null) {
src[j] = null; do {
Entry next = e.next; int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}In this method, assign the old array to src and traverse src. When the element of src is not null, set the element in src to null, that is, set the element in the old array to null, that is, this sentence:
if (e != null) {
src[j] = null;
At this time, if a get method accesses the key, it will still get the old array, of course, it will not get its corresponding value.
Summary: when HashMap is not synchronized, many subtle problems will occur in concurrent programs, and it is difficult to find the reason from the surface. Therefore, the use of HashMap is counterintuitive, which may be caused by concurrency.
HashMap rehash source code
public V put(K key, V value)
{
......
//Calculate Hash value
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//If the key has been inserted, replace the old value (link operation)
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//The key does not exist. You need to add a node
addEntry(hash, key, value, i);
return null;
}Check whether the capacity exceeds the standard
void addEntry(int hash, K key, V value, int bucketIndex)
{
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//Check whether the current size exceeds the threshold set by us. If it exceeds the threshold, resize it
if (size++ >= threshold)
resize(2 * table.length);
} Create a larger hash table, and then migrate the data from the old hash table to the new hash table.
void resize(int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//Create a new Hash Table
Entry[] newTable = new Entry[newCapacity];
//Migrate data from Old Hash Table to New Hash Table
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}For the migrated source code, pay attention to the highlights:
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//The following code means:
// Pick an element from the OldTable and put it in the NewTable
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next; // important
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; // important
newTable[i] = e; // important
e = next; // important
} while (e != null);
}
}
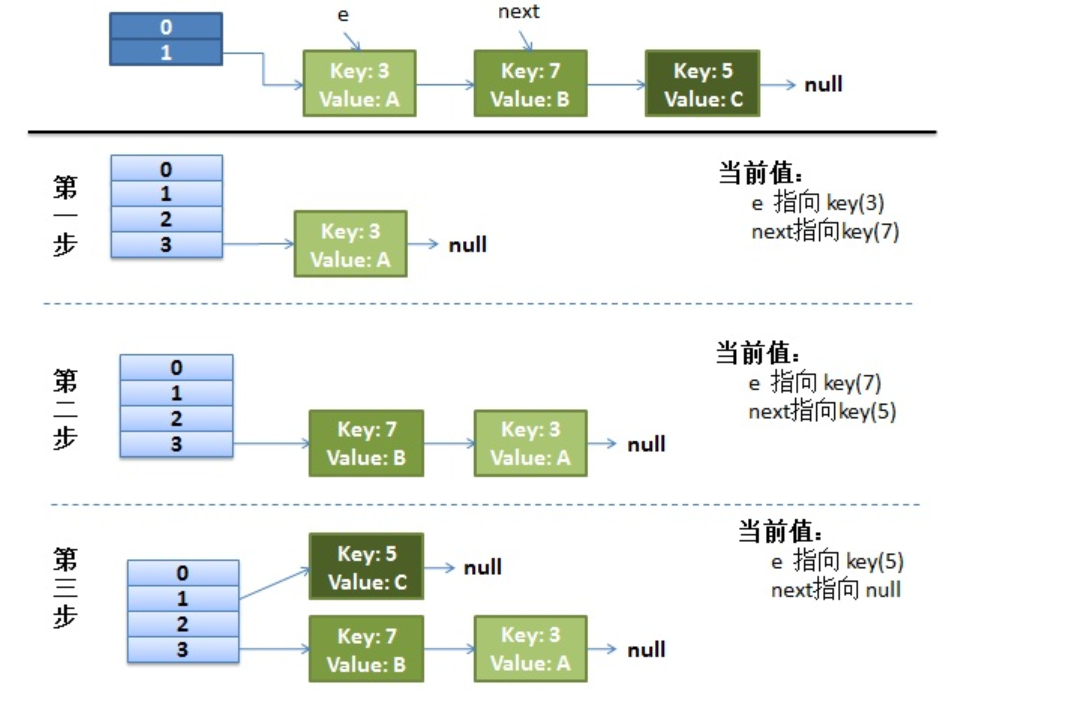
} Normal ReHash process
Drew a picture and made a demonstration.
I assumed that our hash algorithm simply uses key mod to check the size of the table (that is, the length of the array).
The top is the old hash table. The size of the Hash table is 2, so the key = 3, 7, 5. After mod 2, they all conflict in table[1].
The next three steps are to resize the Hash table to 4, and then rehash all < key, value >
Rehash under concurrent
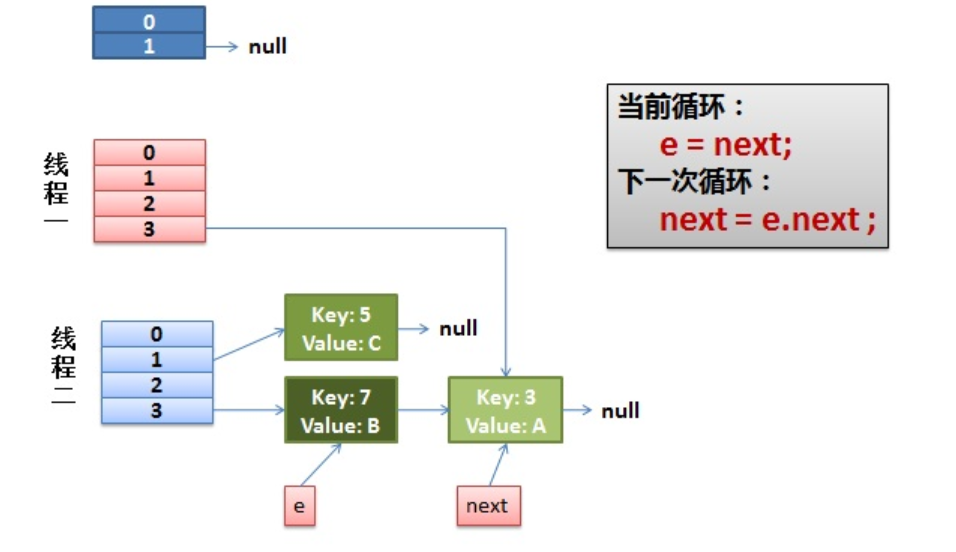
1) Suppose we have two threads. I marked it in red and light blue.
Let's look back at this detail in our transfer code:
do {
Entry<K,V> next = e.next; // < -- suppose that the thread is suspended by scheduling as soon as it executes here
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);And our thread 2 execution is complete. So we have the following appearance.
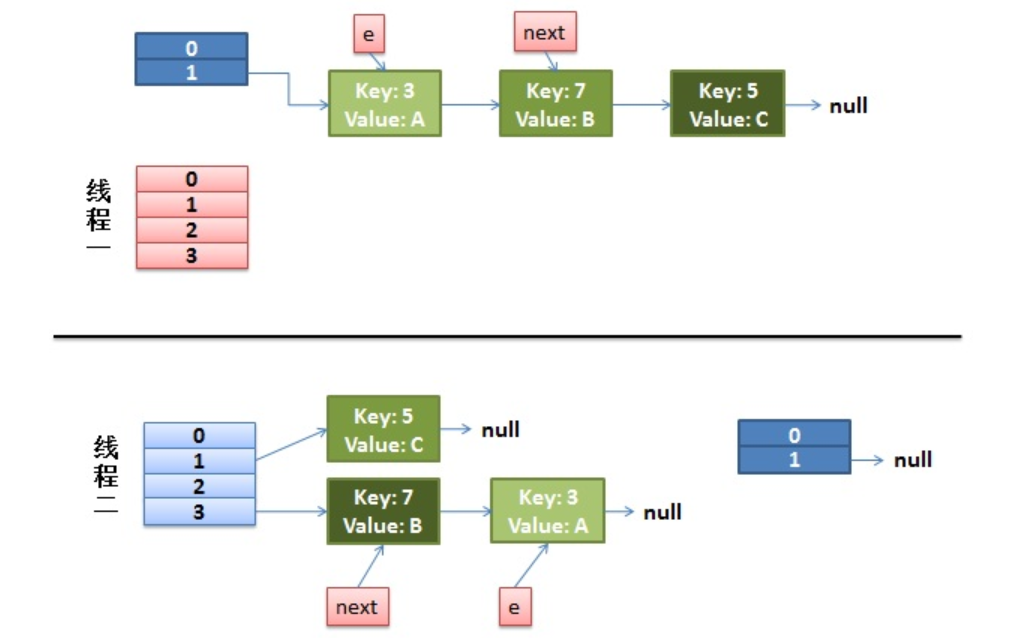
Note that e of Thread1 points to key(3) and next points to key(7). After rehash of thread 2, it points to the list reorganized by thread 2. We can see that the order of the linked list is reversed.
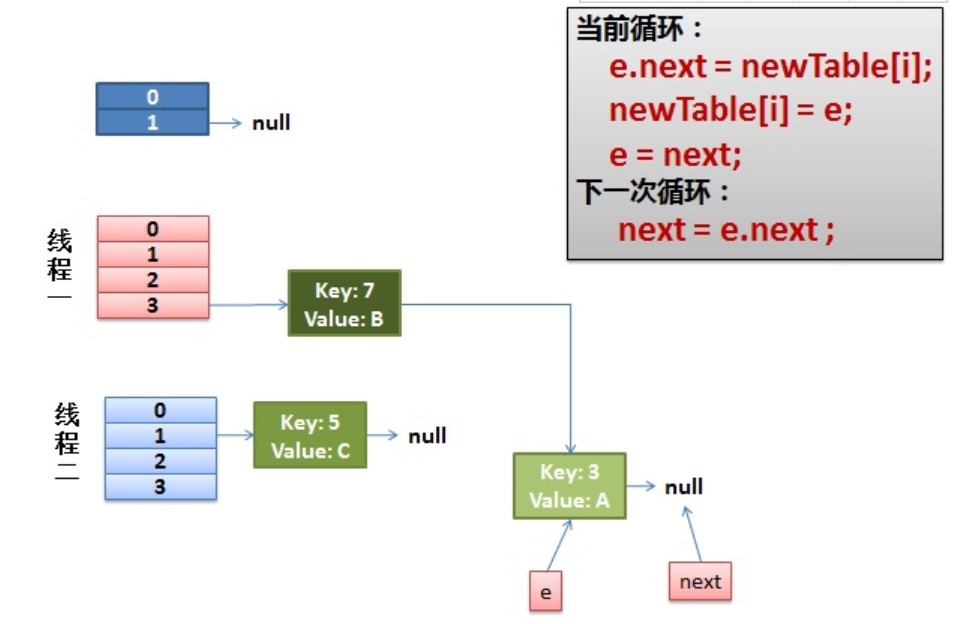
2) As soon as the thread is scheduled to execute.
First, execute newTalbe[i] = e;
Then e = next, resulting in e pointing to key(7),
next = e.next in the next cycle causes next to point to key(3)
3) Everything is fine.
The thread continues to work. Take off the key(7), put it in the first one of the newTable[i], and then move e and next down.
4) The ring link appears.
e.next = newTable[i] causes {key (3) Next points to key(7)
Note: the key (7) at this time Next has pointed to key(3), and the ring linked list appears.
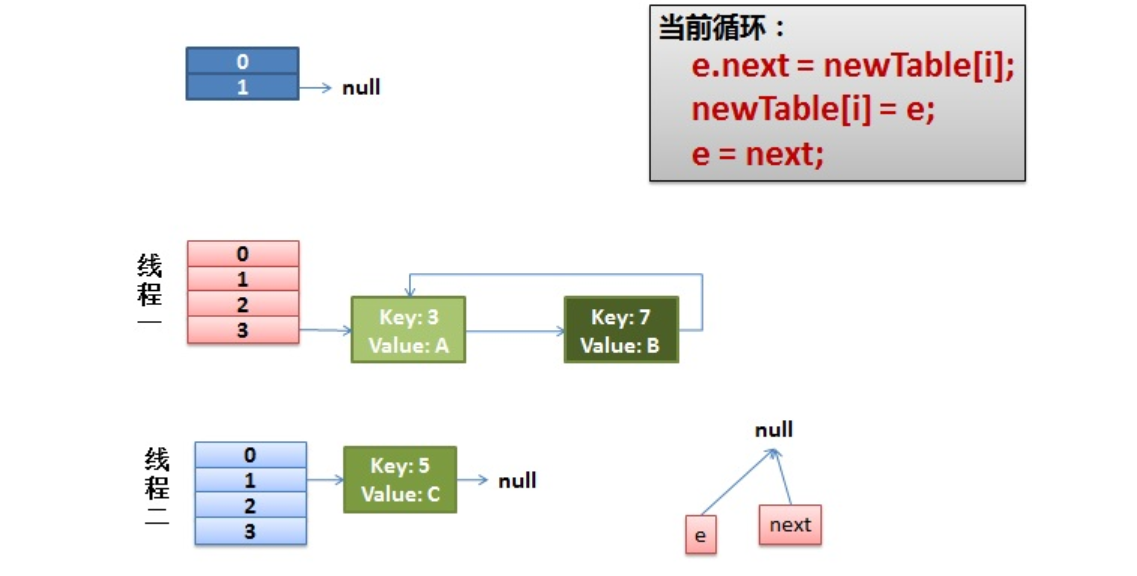
So, as soon as our thread calls hashtable When get (11), the tragedy appears - Infinite Loop.
Three solutions
Replace HashMap with Hashtable
Hashtables are synchronized, but the Iterator returned by the Iterator and the listIterator method of the Collection returned by the "Collection view method" of all hashtables fail quickly: after the Iterator is created, if the Hashtable is structurally modified, unless it is removed or added by the Iterator itself, Otherwise, if it is modified in any way at any time, the Iterator will throw a ConcurrentModificationException. Therefore, in the face of concurrent modifications, the Iterator will soon fail completely without risking arbitrary uncertain behavior at an uncertain time in the future. The Enumeration returned by the Hashtable's key and value methods is not a quick failure.
Note that the fast failure behavior of iterators cannot be guaranteed, because in general, it is impossible to make any hard guarantee whether asynchronous concurrent modifications occur. The fast failure iterator will try its best to throw a ConcurrentModificationException. Therefore, it is wrong to write a program that depends on this exception to improve the correctness of such iterators: the rapid failure behavior of iterators should only be used to detect program errors.
Collections.synchronizedMap wraps the HashMap
Returns a synchronous (thread safe) mapping supported by the specified mapping. In order to ensure sequential access, all access to the underlying mapping must be completed through the returned mapping. When iterating on the returned map or any of its collection views, force the user to manually synchronize on the returned map:
Map m = Collections.synchronizedMap(new HashMap());
... Set s = m.keySet(); // Needn't be in synchronized block ...
synchronized(m) { // Synchronizing on m, not s! Iterator i = s.iterator(); // Must be in synchronized block while (i.hasNext())
foo(i.next());
}Failure to comply with this recommendation will lead to uncertain behavior. If the specified mapping is serializable, the returned mapping will also be serializable.
Replace HashMap with ConcurrentHashMap
A hash table that supports full concurrency of retrieval and expected adjustable concurrency of updates. This class follows the same functional specification as Hashtable and includes the method version of each method corresponding to Hashtable. However, although all operations are thread safe, retrieval operations do not have to be locked, and locking the entire table in a way that prevents all access is not supported. This class can fully interoperate with Hashtable through the program, which depends on its thread safety, regardless of its synchronization details.
Retrieval operations (including get) are usually not blocked, so they may overlap with update operations (including put and remove). Retrieval affects the results of recently completed update operations. For some aggregation operations, such as putAll and clear, concurrent retrieval may only affect the insertion and removal of some items. Similarly, Iterators and Enumerations return elements that affect the state of the hash table at some point in time when or after the iterator / enumeration is created. They do not throw a ConcurrentModificationException. However, Iterators are designed to be used by only one thread at a time.
Why are wrapper classes such as String and Integer in HashMap suitable as key keys

If the {key} Object in HashMap is of type} Object, what methods should be implemented?
Why is the length of HashMap to the power of 2
In order to make HashMap access efficient and minimize collisions, that is, try to distribute data evenly. As we mentioned above, the range of Hash values - 2147483648 to 2147483647 adds up to about 4 billion mapping space. As long as the Hash function is mapped evenly and loosely, it is difficult to collide in general applications. But the problem is that there is no memory for an array with a length of 4 billion. Therefore, this Hash value cannot be used directly. Before using, you have to modulo the length of the array, and the remainder can be used to store the position, that is, the corresponding array subscript. The subscript of this array is evaluated as "(n - 1) & Hash". (n represents the length of the array). This explains why the length of HashMap is to the power of 2.
How should this algorithm be designed?
We may first think of using% remainder operation. However, the point comes: "in the remainder (%) operation, if the divisor is a power of 2, it is equivalent to the and (&) operation minus one from its divisor (that is, the premise of hash% length = = hash & (length-1) is that length is the nth power of 2;)." Moreover, &, using binary bit operation can improve the operation efficiency relative to%, which explains why the length of HashMap is the power of 2.
As the default capacity, too large and too small are not appropriate, so 16 is adopted as a more appropriate empirical value.
Why is Hashmap a red black tree and why is the threshold 8
8 this threshold is defined in the HashMap, as shown below. This comment only explains that 8 is the threshold for bin (bin is the bucket, that is, where elements with the same hashCode value in the HashMap are saved) to convert from a linked list to a tree, but does not explain why it is 8:
Both HashMap and ConcurrentHashMap in JDK 1.8 have this feature: the initial Map is empty because there are no elements in it. When you put elements in it, the hash value will be calculated. After calculation, the first value will first occupy the position of a bucket (also known as slot point). Later, if it is found that it needs to fall into the same bucket through calculation, Then it will be extended in the form of linked list, commonly known as "zipper method"
When the length of the linked list is greater than or equal to the threshold (8 by default), if the capacity is greater than or equal to min_ TREEIFY_ According to the requirements of capability (64 by default), the linked list will be converted into a red black tree.
Similarly, if the size is adjusted due to deletion or other reasons, when the number of nodes in the red black tree is less than or equal to 6, it will return to the linked list form.
Some slot points are empty, some are zippers, and some are red and black trees.
More often, we will pay attention to why it is converted to red black tree and some characteristics of red black tree. However, why should the threshold of conversion be set to 8 by default? To know why it is set to 8, we must first know why to convert, because conversion is the first step.
Each time we traverse a linked list, the average search time complexity is O(n), and N is the length of the linked list. The red black tree has different search performance from the linked list. Because the red black tree has the characteristics of self balancing, it can prevent the occurrence of imbalance, so the time complexity of search can always be controlled at O(log(n)).
At first, the linked list is not very long, so there may be little difference between O(n) and O(log(n)), but if the linked list becomes longer and longer, this difference will be reflected. Therefore, in order to improve the search performance, we need to convert the linked list into the form of red black tree.
Why not just use red and black trees
Why not use red black tree at the beginning, but go through a transformation process? In fact, this problem has been explained in the source code comments of JDK:
By looking at the source code, we can find that the default is that when the length of the linked list reaches 8, it will be converted into a red black tree, and when the length is reduced to 6, it will be converted back, which reflects the idea of time and space balance
At the beginning of using the linked list, the space occupation is relatively small, and because the linked list is short, the query time is not too big. However, when the linked list becomes longer and longer, we need to use the form of red and black tree to ensure the efficiency of query. When to convert from a linked list to a red black tree, you need to determine a threshold. This threshold is 8 by default, and the number of 8 is also described in the source code. The original text is as follows:
In usages with well-distributed user hashCodes, tree bins are rarely used. Ideally, under random hashCodes, the frequency of nodes in bins follows a Poisson distribution (http://en.wikipedia.org/wiki/Poisson_distribution) with a parameter of about 0.5 on average for the default resizing threshold of 0.75, although with a large variance because of resizing granularity. Ignoring variance, the expected occurrences of list size k are (exp(-0.5) * pow(0.5, k) / factorial(k)). The first values are: 0: 0.60653066 1: 0.30326533 2: 0.07581633 3: 0.01263606 4: 0.00157952 5: 0.00015795 6: 0.00001316 7: 0.00000094 8: 0.00000006 more: less than 1 in ten million
The above paragraph means that if the hashCode is well distributed, that is, the hash calculation results are well dispersed, the form of red black tree is rarely used, because the values are evenly distributed and the linked list is rarely very long. Ideally, the length of the linked list conforms to the Poisson distribution, and the hit probability of each length decreases in turn. When the length is 8, the probability is only 0.00000006. This is a probability of less than one in ten million. Usually, our Map will not store so much data, so generally, the conversion from linked list to red black tree will not occur.
In fact, the design of turning the linked list into a red black tree when the length of the linked list exceeds 8 is more to prevent the linked list from being too long when the user implements a bad hash algorithm, resulting in low query efficiency. At this time, turning into a red black tree is more of a minimum guarantee strategy to ensure the efficiency of query in extreme cases.
Generally, it is not necessary to convert to red black tree, so the probability is very small, less than one in ten million, that is, the probability of length 8, and length 8 is used as the default threshold for conversion.
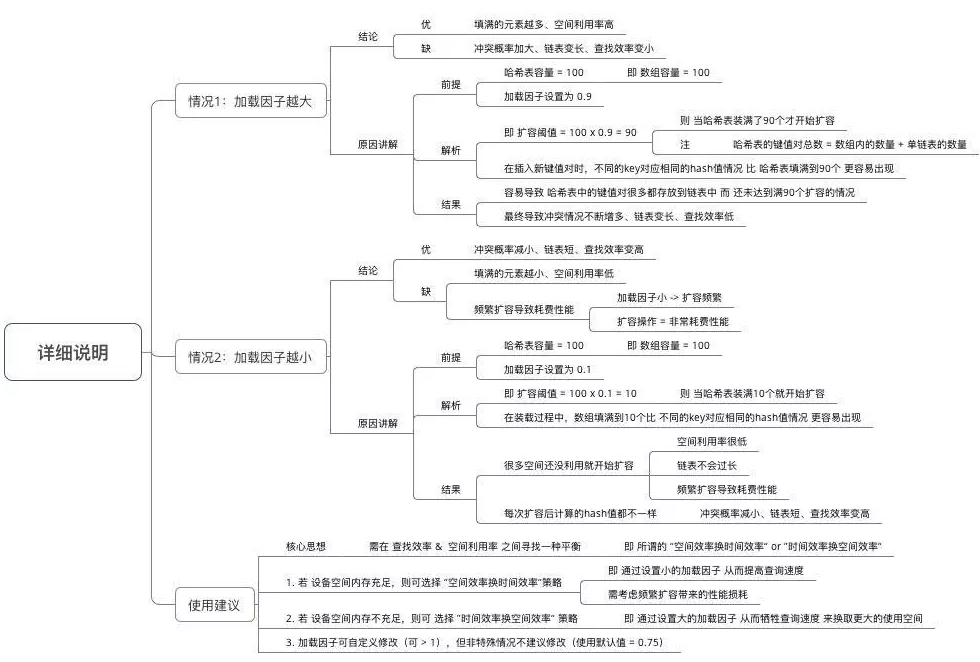
Why is 0.75 selected as the default load factor for HashMap
The initial capacity of Hashtable is 11, and the expansion method is 2N+1;
The initial capacity of HashMap is 16, and the expansion mode is 2N;
Ali's people suddenly asked me why the expansion factor was 0.75, and came back to summarize it; The tradeoff between improving space utilization and reducing query cost is mainly Poisson distribution. If it is 0.75, the collision is the smallest,
HashMap has two parameters that affect its performance: initial capacity and loading factor. The capacity is the number of buckets in the hash table. The initial capacity is only the capacity of the hash table when it is created. Load factor is a measure of how full a hash table can be before its capacity is automatically expanded. When the number of entries in the hash table exceeds the product of the loading factor and the current capacity, the hash table needs to be expanded and rehash (that is, rebuild the internal data structure). The expanded hash table will have twice the original capacity.
Usually, the loading factor needs to find a compromise between time and space cost.
The loading factor is too high, for example, 1, which reduces the space overhead and improves the space utilization, but also increases the query time cost;
The loading factor is too low, such as 0.5. Although it can reduce the query time cost, the space utilization is very low, and the number of rehash operations is increased.
When setting the initial capacity, the number of entries required in the mapping and its loading factor should be considered to minimize the number of rehash operations. Therefore, it is generally recommended to set the initial capacity according to the estimated value when using HashMap to reduce capacity expansion operations.
Hash conflicts are mainly related to two factors
(1) Filling factor refers to the ratio of the number of data elements stored in the hash table to the size of the hash address space, a = n / M; A the smaller the, the less likely the conflict is; on the contrary, the more likely the conflict is; However, the smaller A is, the smaller the space utilization is. The larger a is, the higher the space utilization is. In order to take into account hash conflict and storage space utilization, a is usually controlled between 0.6-0.9, while net directly defines the maximum value of a as 0.72 (although Microsoft's official MSDN states that the default filling factor of HashTable is 1.0, it is actually a multiple of 0.72)
(2) It is related to the hash function used. If the hash function is appropriate, the hash address can be evenly distributed in the hash address space as much as possible, so as to reduce the generation of conflicts. However, the acquisition of a good hash function largely depends on a lot of practice. Fortunately, predecessors have summarized and practiced many efficient hash functions, Please refer to Lucifer's article: data structure: HashTable:
Choosing 0.75 as the default loading factor is a compromise between time and space costs
But why must it be 0.75? Instead of 0.8, 0.6
In usages with well-distributed user hashCodes, tree bins are rarely used. Ideally, under random hashCodes, the frequency of nodes in bins follows a Poisson distribution (http://en.wikipedia.org/wiki/Poisson_distribution) with a parameter of about 0.5 on average for the default resizing threshold of 0.75, although with a large variance because of resizing granularity. Ignoring variance, the expected occurrences of list size k are (exp(-0.5) * pow(0.5, k) / factorial(k)). The first values are: 0: 0.60653066 1: 0.30326533 2: 0.07581633 3: 0.01263606 4: 0.00157952 5: 0.00015795 6: 0.00001316 7: 0.00000094 8: 0.00000006 more: less than 1 in ten million
This is also the description of Poisson distribution, which is based on the assumption of 0.75
Ideally, using random hash codes, the frequency of nodes in the hash bucket follows Poisson distribution, and a comparison table of the number and probability of elements in the bucket is given.
As can be seen from the above table, when the number of elements in the bucket reaches 8, the probability has become very small, that is, it is almost impossible to use 0.75 as the loading factor to have more than 8 linked lists at each collision position.
Fast failure mechanism of Hashmap
Why does HashMap avoid iterator failure through the remove or add method of the iterator itself?
The iterators returned by all collection class views in HashMap are fast fail.
In the HashMap, there is a variable modCount to indicate the number of times the collection has been modified. When the Iterator iterator is created, this variable is assigned to expectedModCount. When a collection method modifies a collection element, such as the remove() method of a collection, the modCount value will be modified, but the expectedModCount value will not be modified synchronously. When the Iterator is used to traverse the element operation, it will first compare whether expectedModCount and modCount are equal. If they are not equal, throw Java. Java immediately util. Concurrentmodificationexception exception. When the element is removed through the remove() method of Iterator, the value of expectedModCount will be updated at the same time, and the value of modCount will be re assigned to expectedModCount, so that java.com will not be thrown during the next traversal util. Concurrentmodificationexception exception.
Specifically from the code point of view.
First, look at the remove method of HashMap:
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
/**
* Implements Map.remove and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to match if matchValue, else ignored
* @param matchValue if true only remove if value is equal
* @param movable if false do not move other nodes while removing
* @return the node, or null if none
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
//When the node is actually removed, modify the value of modCount
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;//Indicates the number of times the HashMap has been modified
When an element in the HashMap is removed through remove, the modCount Value will be modified, and other methods to modify the HashMap collection will also modify the modCount Value. This Value will be assigned to expectedModCount when creating the iterator. When the iterator works, it will be determined whether the modCount Value has been modified. If the Value is modified, a ConcurrentModificationException is thrown. The Value iterator of HashMap is implemented as follows:
final class ValueIterator extends HashIterator
implements Iterator<V> {
public final V next() { return nextNode().value; }
}
abstract class HashIterator {
Node<K,V> next; // next entry to return
Node<K,V> current; // current entry
int expectedModCount; // for fast-fail
int index; // current slot
HashIterator() {
//When constructing the iterator, assign the value of modCount to expectedModCount
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}
public final boolean hasNext() {
return next != null;
}
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
//Before obtaining the next node, first determine whether the modCount value is modified. If it is modified, a ConcurrentModificationException will be thrown. As you can see from the above, when the HashMap is modified, the modCount value will be modified.
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
//The deletion operation of the iterator will re assign the value to exceptedModCount, so it will not lead to fast fail
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
//First determine whether the modCount value has been modified
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
//Reassign the modCount value to expectedModCount so that fast fail will not occur in the next iteration
expectedModCount = modCount;
}
}
You can see that removing an element through the iterator will change the modCount value, but it will re assign the modCount value to expectedModCount, so that fast fail will not occur in the next iteration. The remove method of HashMap will modify the modCount value, but will not update the expectedModCount value of the iterator, so the iterator will throw a ConcurrentModificationException during iterative operation.
If the mapping is modified structurally, the iterator will throw a ConcurrentModificationException at any time and in any way unless it is modified through the iterator's own remove or add method. Therefore, in the face of concurrent modifications, the iterator will soon fail completely. Note that the fast failure behavior of iterators cannot be guaranteed. Generally speaking, when there are asynchronous concurrent modifications, no firm guarantee can be made. The fast failure iterator does its best to throw a ConcurrentModificationException.
Fast failure mechanism and failure security mechanism
Java Collection - quick failure
Phenomenon: when traversing a collection object with an iterator, if the contents of the collection object are added, deleted or modified during traversal, a ConcurrentModificationException will be thrown.
Principle: the iterator directly accesses the contents of the collection during traversal, and uses a modCount variable during traversal. If the contents of the collection change during traversal, the value of modCount will change. Whenever the iterator uses hashNext()/next() to traverse the next element, it will detect whether the modCount variable is the expectedmodCount value. If so, it will return the traversal; Otherwise, a ConcurrentModificationException is thrown to terminate the traversal.
Note: the throw condition of the exception here is that modCount is detected= expectedmodCount this condition. If the modified modCount value is just set to the expectedmodCount value when the collection changes, the exception will not be thrown. Therefore, you cannot program concurrent operations depending on whether this exception is thrown or not. This exception is only recommended to detect concurrent modification bug s.
Scenario: Java The collection classes under the util package fail quickly and cannot be modified concurrently under multithreading (modified during iteration).
Java Collection - fail safe
Phenomenon: the collection container with failure security mechanism is not directly accessed on the collection content during traversal, but copies the original collection content first and traverses the copied collection.
Principle: since the copy of the original set is traversed during iteration, the changes made to the original set during traversal cannot be detected by the iterator, so the ConcurrentModificationException will not be triggered.
Disadvantages: the advantage of copying content is to avoid the ConcurrentModificationException, but similarly, the iterator cannot access the modified content, that is, the iterator traverses the set copy obtained at the moment when it starts traversing, and the iterator does not know the modification of the original set during traversal. This is also his disadvantage. At the same time, it needs to be copied, so it eats more memory.
Scenario: Java util. The containers under the concurrent package are all safe failures and can be used and modified concurrently under multithreading.
For example, CopyOnWriteArrayList