Thread Pool is a tool for managing threads based on the idea of "pooling". The benefits are:
Reduce resource consumption: Reuse created threads through pooling technology to reduce thread creation and destruction.
Increase response speed: When a task arrives, it can be executed immediately without waiting for a thread to be created.
Improving thread manageability: Threads are scarce resources, and if created unrestrictedly, they will not only consume system resources, but also cause resource dispatch imbalances and reduce system stability due to the unreasonable distribution of threads. Thread pools can be used for uniform allocation, tuning, and monitoring.
Provides more powerful functionality: Thread pools are scalable, allowing developers to add more functionality to them. For example, a delayed timed thread pool, ScheduledThreadPoolExecutor, allows tasks to be deferred or executed on a regular basis.
overall design
Thread pools are represented in Java as the ThreadPoolExecutor class, with the ThreadPoolExecutor class diagram as follows:
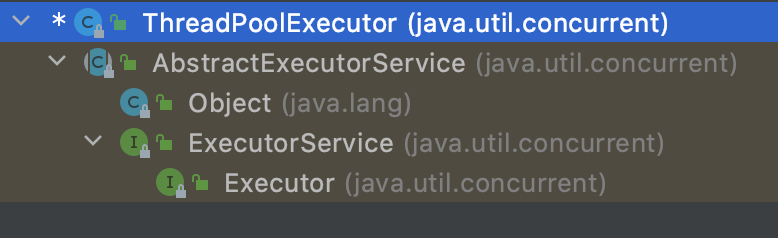
Executor --> ExecutorService --> AbstractExecutorService --> ThreadPoolExecutor
Executor
public interface Executor {
void execute(Runnable command);
}The top-level interface Executor provides an idea: decouple task Submission from task execution. Users do not need to care about how to create threads or how to schedule threads to perform tasks. Users only need to provide Runnable objects, submit the running logic of tasks to the Executor, and the Executor framework completes the allocation of threads and the execution of tasks.
ExecutorService
public interface ExecutorService extends Executor {
void shutdown();
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}The ExecutorService interface adds capabilities such as methods of thread pool management (such as stopping the running of a thread pool); thread pool status judgment; and expanded ability to perform tasks (methods for generating Future s for one or a batch of asynchronous tasks);
AbstractExecutorService
AbstractExecutorService is an abstract class of the upper layer that concatenates the processes of executing tasks, ensuring that the lower level implementation only needs to focus on one method of executing tasks.
ThreadPoolExecutor
ThreadPoolExecutor maintains its own (thread pool) lifecycle and manages both threads and tasks to perform parallel tasks. ThreadPoolExecutor runs as follows:
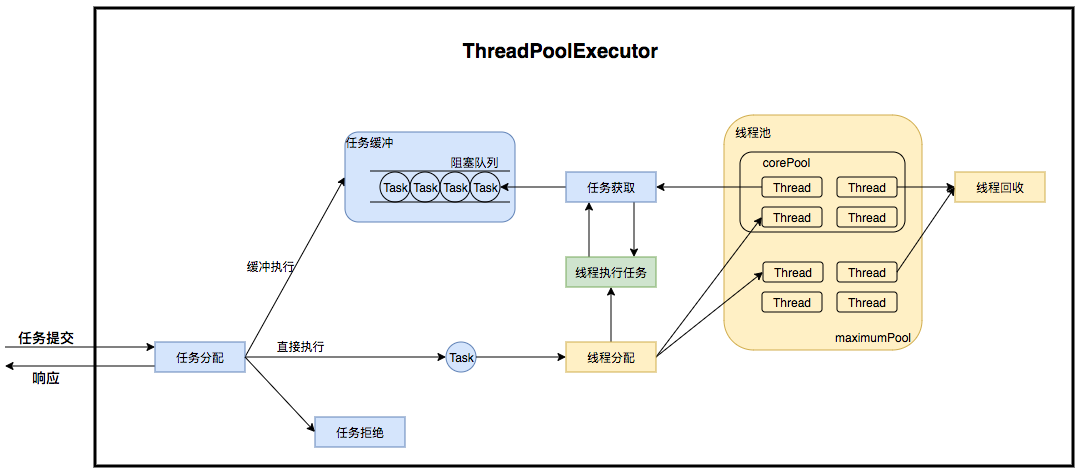
Thread pool actually builds a producer-consumer model internally that decouples threads from tasks and does not directly relate them to each other so as to buffer tasks and reuse threads. Thread pool operations are divided into two main parts: task management, thread management. Task management acts as a producer, and when a task is submitted, the thread pool determines the subsequent flow of the task.(1) Apply the thread directly to perform the task; (2) Buffer to the queue and wait for the thread to execute; (3)Reject this task. Thread management sections are consumers, and they are maintained in a pool of threads. Threads are assigned according to task requests. When a thread finishes executing a task, it continues to acquire new tasks to execute. Finally, when a thread cannot acquire a task, the thread is recycled.
Next, the ThreadPool mechanism will be explained in detail in the following three sections:
How does a thread pool maintain its state?
How does a thread pool manage tasks?
How does a thread pool manage threads?
Thread pool life cycle management
The running state of the thread pool is not explicitly set by the user, but is maintained internally with the running of the thread pool. In the implementation, the maintenance of two key parameters, runState and workerCount, is put together by the thread pool as follows:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int RUNNING = -1 << COUNT_BITS;
private static final int COUNT_BITS = Integer.SIZE - 3;//SIZE = 32;
private static int ctlOf(int rs, int wc) { return rs | wc; } //Generate ctl by state and number of threads
ctl, an AtomicInteger variable, is a field that controls the running state of the thread pool and the number of valid threads. It contains two parts of information: the running state of the thread pool and the number of valid threads in the thread pool (workerCount)., three bits high saves runState, 29 bits low saves workerCount, and the two variables do not interfere with each other. Storing two values in one variable avoids inconsistencies when making related decisions, and does not require lock resources to maintain consistency between the two. Reading the thread pool source code reveals that it is often necessary to simultaneously determine the running state of the thread pool and the number of threadsSituation.
The source code to get the running state and the number of threads in the thread pool is as follows:
// Calculate current running state
private static int runStateOf(int c) { return c & ~CAPACITY; }
// Calculate the current number of threads
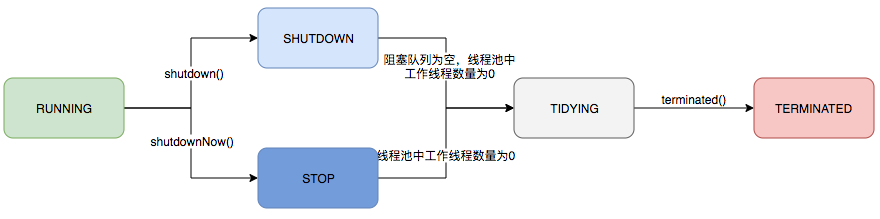
private static int workerCountOf(int c) { return c & CAPACITY; }ThreadPoolExecutor runs in five states:

Their life cycle transitions are as follows:
Task Execution Mechanism for Thread Pool
task scheduling
Task scheduling is the main entry into a thread pool, and when a user submits a task, how the task will be performed is determined by this phase. Understanding this part is equivalent to understanding the core operating mechanism of the thread pool.
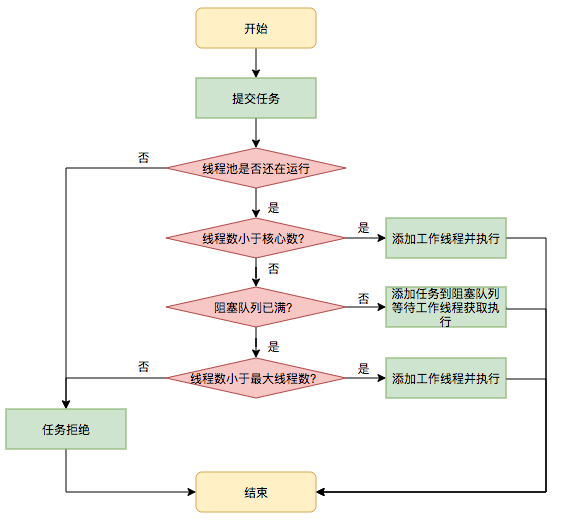
Scheduling of all tasks is done by the execute method, which checks the running status of the thread pool, the number of running threads, the running policy, and decides on the next process to execute. It either requests thread execution directly, buffers it to the queue, or rejects the task directly. The following processes are performed:
First detect the running state of the thread pool. If it is not RUNNING, reject it directly. The thread pool should ensure that tasks are executed in the RUNNING state.
If workerCount < corePoolSize, a thread is created and started to perform the newly submitted task.
If workerCount >= corePoolSize and the blocking queue in the thread pool is not full, add a task to the blocking queue.
If workerCount >= corePoolSize && workerCount < maximumPoolSize and the blocking queue in the thread pool is full, create and start a thread to perform the newly submitted task.
If workerCount >= maximumPoolSize and the blocking queue in the thread pool is full, the task is handled according to the rejection policy, with the default being to throw an exception directly.
Its execution process is as follows:
Task Buffering
The Task Buffer module is the core part of a thread pool that manages tasks. The essence of a thread pool is to manage tasks and threads. The key idea to do this is to decouple tasks from threads without directly associating them for subsequent assignments. Thread pools are implemented in producer-consumer mode through a blocking queue.Queue caching task, the worker thread gets the task from the blocked queue.
A blocking queue is a queue that supports two additional operations: when the queue is empty, the thread that gets the element waits for the queue to become non-empty. When the queue is full, the thread that stores the element waits for the queue to become available.
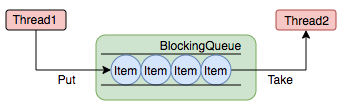
All blocking queues:

Task Request
There are two possibilities for task execution: one is that the task is executed directly by the newly created thread. The other is that the thread gets the task from the task queue and executes it. The idle thread that executes the task requests the task from the queue again to execute it. The first only occurs when the thread is initially created, and the second is when the thread acquires the vast majority of tasks.
Threads need to continuously fetch tasks from the task cache module to help them get tasks from the blocked queue and communicate between the thread management module and the task management module. This part of the strategy is implemented by the getTask method and its execution process is shown in the following figure:
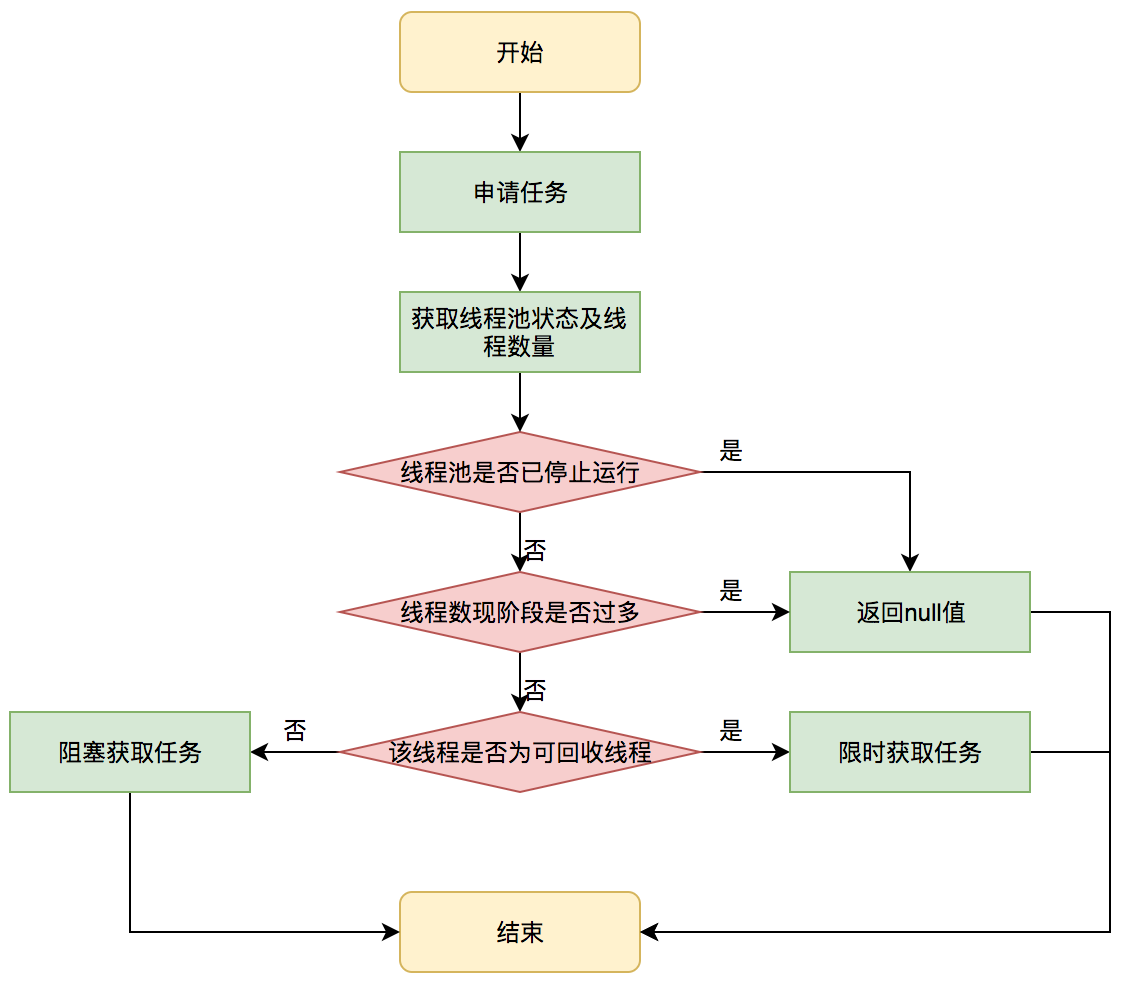
This part of getTask makes several judgments to control the number of threads to make them conform to the state of the thread pool. If the thread pool should not hold so many threads now, a null value will be returned. The worker thread Worker will continue to receive new tasks to execute, and it will start to be recycled when the worker thread Worker cannot receive tasks.
Task Rejection
The task rejection module is the protection part of the thread pool, which has a maximum capacity. When the task cache queue of the thread pool is full and the number of threads in the thread pool reaches maximumPoolSize, you need to reject the task and adopt a task rejection policy to protect the thread pool.
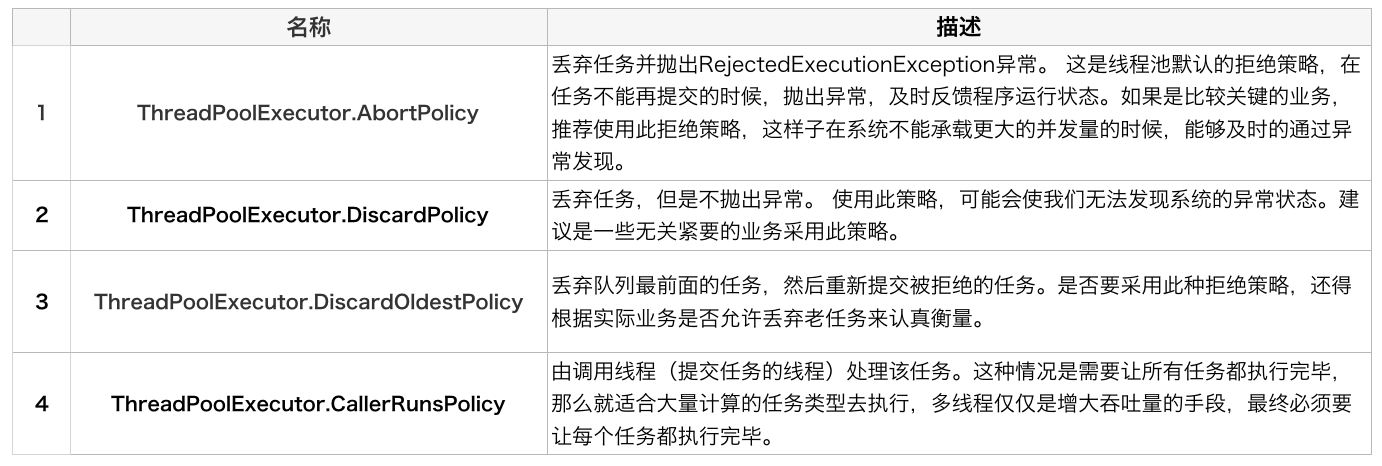
Four existing rejection strategies provided by JDK:
Worker Thread Management
Worker Threads
A Worker thread Worker in a thread pool is designed to understand the state of a thread and maintain its lifecycle. Let's take a look at some of its code:
private final class Worker extends AbstractQueuedSynchronizer implements Runnable{
final Thread thread;//Threads Holded by Worker
Runnable firstTask;//Initialized task, null able
}Worker is a worker thread that implements the Runnable interface and holds a thread, an initialized task firstTask. A threads is a thread created through ThreadFactory when the construction method is called to execute the task; the first Task uses it to save the first task that is passed in, and if the value is non-null, the thread executes the task immediately after it is createdTasks, which correspond to the case when the core thread was created; if this value is null, a thread is created to retrieve the execution of tasks in the workQueue, which corresponds to the creation of non-core threads.
The model Worker performs the task is as follows:
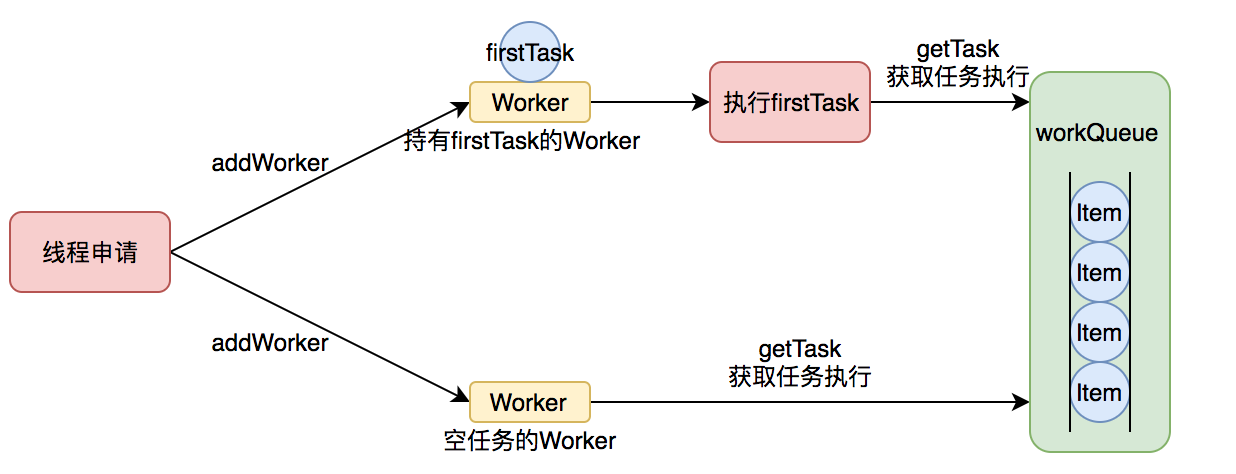
Thread pools manage the lifecycle of threads and recycle them when they are not running for a long time. Thread pools use a Hash table to hold references to threads, so that they can control the lifecycle of threads by adding and removing references. It is important at this point to determine if a thread is running.
Worker implements exclusive locking by inheriting AQS and using AQS. Instead of using ReentrantLock, it uses AQS to reflect the thread's current state of execution with non-reentrant features.
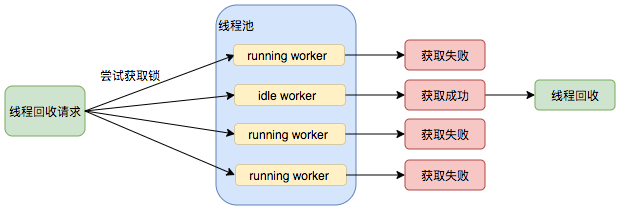
The interruptIdleWorkers method is called by the thread pool to interrupt idle threads when the shutdown or tryTerminate methods are executed. The interruptIdleWorkers method uses tryLock() to attempt to obtain a reentrant lock to determine if the threads in the thread pool are idle or to safely recycle if the threads are idle.
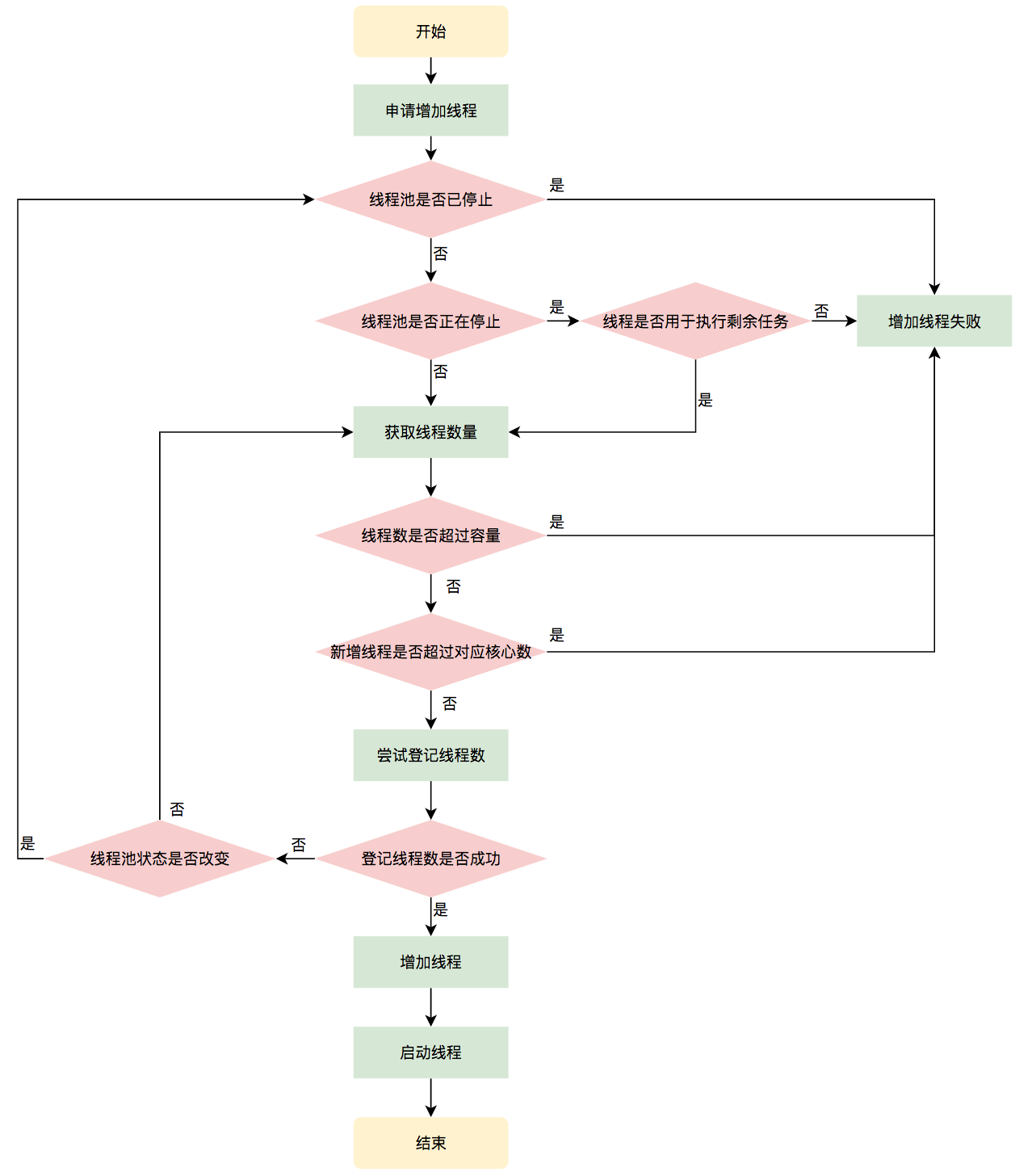
Worker thread addWorker()
The method addWorker method has two parameters: firstTask, core. The first Task parameter specifies the first task performed by the new thread, which can be null; the core parameter indicates whether it is a core thread, and the true parameter determines whether the current number of active threads is less than the corePoolSize before the new thread, and the false parameter specifies whether the new thread is performing the first task.The current number of active threads is determined to be less than maximumPoolSize, and the execution process is as follows:
Source code:
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (; ; ) {
int c = ctl.get();
int rs = runStateOf(c);
// 1. Validity judgment of thread pool state
if (rs >= SHUTDOWN &&
!(rs == SHUTDOWN &&
firstTask == null &&
!workQueue.isEmpty())) {
return false;
}
// 2. Validity of the current number of worker threads in the thread pool
for (; ; ) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize)) {
return false;
}
// 3. Try to increase the number of threads
if (compareAndIncrementWorkerCount(c)) {
break retry;
}
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs) {
continue retry;
}
}
}
// 3.1 Threads Increased Successfully
boolean workerStarted = false; //Worker Thread Open Result
boolean workerAdded = false;
Worker w = null;
try {
// 4. Create a Worker Thread
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
{
throw new IllegalThreadStateException();
}
workers.add(w);
int s = workers.size();
if (s > largestPoolSize) {
largestPoolSize = s;
}
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 5. Start Thread maintained within Worker thread
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (!workerStarted) {
addWorkerFailed(w);
}
}
return workerStarted;
}Worker Thread Recycle
Thread destruction in thread pool depends on JVMGC's automatic recycling. What the thread pool does is to maintain a certain number of thread references based on the current state of the thread pool to prevent this part of the thread from being recycled by the JVM. When the thread pool decides which threads need recycling, it simply eliminates the references. When the Worker is created, it polls constantly, then gets the task to execute, and the core thread can wait indefinitelyTasks are acquired by non-core threads within a time limit. When Worker cannot acquire a task, that is, when the acquired task is empty, the loop ends and Worker actively eliminates its own references to the thread pool.
try {
while (task != null || (task = getTask()) != null) {
//Execute Tasks
}
} finally {
processWorkerExit(w, completedAbruptly);//Recycle yourself when you can't get a task
}Thread recycling is done in the processWorkerExit method:

In fact, moving a thread reference out of the thread pool has already ended the thread destruction portion of the method. However, since there are many possibilities for thread destruction, the thread pool also has to decide what caused the destruction, whether to change the current state of the thread pool, and whether to reassign the thread according to the new state.
Worker Threads Execute Tasks
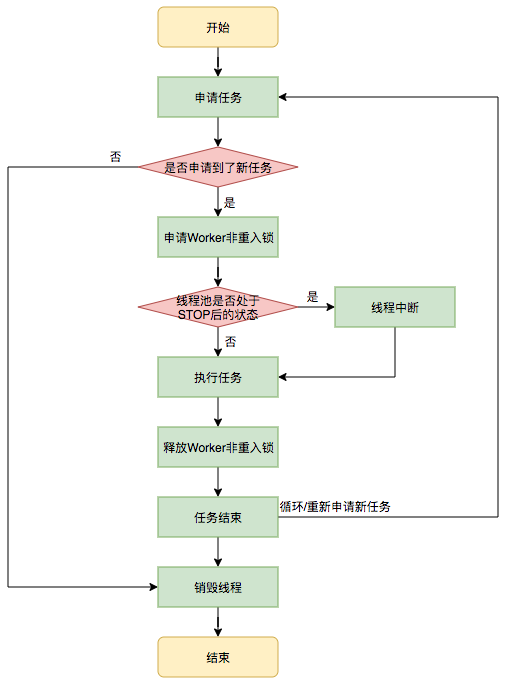
The run method in the Worker class calls the runWorker method to execute the task, and the runWorker method executes as follows:
1. The while loop continuously obtains tasks through the getTask() method.
2. The getTask () method fetches tasks from the blocked queue.
3. If the thread pool is stopping, make sure that the current thread is in the interrupted state, otherwise make sure that the current thread is not in the interrupted state.
4. Perform tasks.
5. If getTask results in null, jump out of the loop, execute the processWorkerExit() method, and destroy the thread.
Execution Flow Chart: