1. Case conversion and filling of English letters
s = pd.Series(['lower', 'CAPITALS', 'this is a sentence', 'SwApCaSe'])
- Uppercase to lowercase: s.str.lower()
- Lowercase to uppercase: s.str.upper()
- Change to news title form: s.str.title()
- The first letter is uppercase, and the rest is lowercase: s.str.capitalize()
- Convert the original uppercase and lowercase to lowercase and uppercase respectively, that is, case exchange: s.str.swapcase()
- When the text content is filled to a fixed length with a certain character, it will be filled from both sides: s.str.center(4, '*')
- Fill the text content with a certain character to a fixed length. You can set the filling direction (left by default, left,right,both): s.str.pad(width=10, side ='right ', fillchar =' - ')
- When the text content is filled with a certain character to a fixed length, it will be filled from the right of the text, that is, the original string is on the left: s.str.ljust(4, '-')
- When the text content is filled with a certain character to a fixed length, it will be filled from the left of the text, that is, the original string is on the right: s.str.rjust(4, '-')
- Fill the text content with a certain character to a fixed length according to the specified direction (left,right,both): s.str.pad(3,side = 'left', fillchar = '*')
- Add 0 to the specified length before the string:
s = pd.Series(['-1', '1', '1000', 10, np.nan])
s.str.zfill(3)
2. String merging and splitting
2.1 multi column string merging
Note: when merging multi column strings, it is recommended to use the cat function, which is merged according to the index.
s=pd.DataFrame({'col1':['a', 'b', np.nan, 'd'],'col2':['A', 'B', 'C', 'D']})
# 1. Rows with one missing value will not be merged
s['col1'].str.cat([s['col2']])
# 2. Replace the missing values with fixed characters (*) and merge them
s['col1'].str.cat([s['col2']],na_rep='*')
# 3. Replace the missing values with fixed characters (*) and merge them with separators (,)
s['col1'].str.cat([s['col2']],na_rep='*',sep=',')
# 4. Consolidation of inconsistent indexes
#Create series
s = pd.Series(['a', 'b', np.nan, 'd'])
t = pd.Series(['d', 'a', 'e', 'c'], index=[3, 0, 4, 2])
#merge
s.str.cat(t, join='left', na_rep='-')
s.str.cat(t, join='right', na_rep='-')
s.str.cat(t, join='outer', na_rep='-')
s.str.cat(t, join='inner', na_rep='-')
2.2 text in the form of a list in one column is merged into one column
s = pd.Series([['lion', 'elephant', 'zebra'], [1.1, 2.2, 3.3], [
'cat', np.nan, 'dog'], ['cow', 4.5, 'goat'], ['duck', ['swan', 'fish'], 'guppy']])
#Splice with underline
s.str.join('_')
Before use:

After use:

2.3 a column of strings is merged with itself into a column
s = pd.Series(['a', 'b', 'c']) #Specify number s.str.repeat(repeats=2) #Specify list s.str.repeat(repeats=[1, 2, 3])
After using this function, the renderings are as follows:


2.4 splitting a string into multiple columns
2.4.1 partition function
The partition function splits a column string into 3 columns, where 2 columns are values and 1 column is a separator.
There are two parameters to set: Sep (separator, default is space) and expand (generate dataframe, default is True)
s = pd.Series(['Linda van der Berg', 'George Pitt-Rivers'])
#The default writing method is separated by spaces and will be split by the first separator
s.str.partition()
#In another way, it will be split with the last separator
s.str.rpartition()
#Use fixed symbol as separator
s.str.partition('-', expand=False)
#Split index
idx = pd.Index(['X 123', 'Y 999'])
idx.str.partition()
2.4.2 split function
The split function splits into multiple values according to the delimiter.
Parameters:
Pat (separator, the default is space);
N (limit delimited output, that is, find several delimiters, default - 1, indicating all);
Expand (whether to generate dataframe, the default is False).
s = pd.Series(["this is a regular sentence","https://docs.python.org/3/tutorial/index.html",np.nan]) #1. Split by space by default s.str.split() #2. Split according to spaces and limit the output of 2 separators s.str.split(n=2) #3. Split with the specified symbol and generate a new dataframe s.str.split(pat = "/",expend=True) #4. Use regular expression to split and generate a new dataframe s = pd.Series(["1+1=2"]) s.str.split(r"\+|=", expand=True)
2.4.3 rsplit function
If the value of n is not set, rsplit and split have the same effect. The difference is that split is restricted from the beginning and rsplit is restricted from the end.
s = pd.Series(["this is a regular sentence","https://docs.python.org/3/tutorial/index.html",np.nan]) #Different from split s.str.rsplit(n=2)
3. String statistics
3.1 count the number of strings in a column
#1. Ordinary characters
s = pd.Series(['A', 'B','Baca', np.nan])
s.str.count('a')
#2. Special characters
s = pd.Series(['$', 'B', 'Aab$', '$$ca', 'C$B$'])
s.str.count('\$')
#3. Make statistics in the index
s=pd.Index(['A', 'A', 'Aaba', 'cat'])
s.str.count('a')
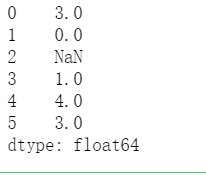
3.2 statistical string length
s = pd.Series(['dog', '', 5,{'foo' : 'bar'},[2, 3, 5, 7],('one', 'two', 'three')])
s.str.len()
The renderings are as follows:
4. String content search (including regular)
4.1 extract
The specified content can be extracted through regular expression, and the in parentheses will generate a column
s = pd.Series(['a1', 'b2', 'c3']) #Extract according to the in parentheses to generate two columns s.str.extract(r'([ab])(\d)') #After adding a question mark, you can continue to match if one doesn't match s.str.extract(r'([ab])?(\d)') #You can rename the generated new column s.str.extract(r'(?P<letter>[ab])(?P<digit>\d)') #Generate 1 column s.str.extract(r'[ab](\d)', expand=True)
4.2 extractall
Unlike extract, this function can extract all qualified elements
s = pd.Series(["a1a2", "b1", "c1"], index=["A", "B", "C"]) #Extract all qualified numbers, and the result is multiple index 1 column s.str.extractall(r"[ab](\d)") #Extract the qualified numbers and rename them to multiple index 1 column s.str.extractall(r"[ab](?P<digit>\d)") #Extract qualified a, b and numbers, and the results are multiple indexes and multiple columns s.str.extractall(r"(?P<letter>[ab])(?P<digit>\d)") #Extract the qualified a, b and numbers. After adding a question mark, if one does not match, you can continue to match backward. The result is multiple indexes and multiple columns s.str.extractall(r"(?P<letter>[ab])?(?P<digit>\d)")
4.3 find
The minimum index of the query fixed string in the target string.
If the string to be queried does not appear in the target string, it is displayed as - 1
s = pd.Series(['appoint', 'price', 'sleep','amount'])
s.str.find('p')
The display results are as follows:

4.4 rfind
The maximum index of the query fixed string in the target string.
If the string to be queried does not appear in the target string, it is displayed as - 1.
s = pd.Series(['appoint', 'price', 'sleep','amount'])
s.str.rfind('p',start=1)
The query results are as follows:

4.5 findall
Find all patterns or regular expressions that appear in the series / index
s = pd.Series(['appoint', 'price', 'sleep','amount']) s.str.findall(r'[ac]')
The display results are as follows:

4.6 get
Extracts the series / index of an element from each element in a list, tuple, or string.
s = pd.Series(["String",
(1, 2, 3),
["a", "b", "c"],
123,
-456,
{1: "Hello", "2": "World"}])
s.str.get(1)
The effect is as follows:

4.7 match
Determines whether each string matches the regular expression in the parameter.
s = pd.Series(['appoint', 'price', 'sleep','amount'])
s.str.match('^[ap].*t')
The matching effect diagram is as follows:

5. String logic judgment
5.1 contains function
Tests whether a pattern or regular expression is contained in a series or indexed string.
Parameters:
pat, string or regular expression;
Case, case sensitive. The default value is True, that is, case sensitive;
flags, whether to transfer to the re module. The default value is 0;
na, the processing method for missing values, which defaults to nan;
regex, whether to treat the pat parameter as a regular expression. The default is True.
s = pd.Series(['APpoint', 'Price', 'cap','approve',123])
s.str.contains('ap',case=True,na=False,regex=False)
The renderings are as follows:

5.2 endswitch function
Tests whether the end of each string element matches the string.
s = pd.Series(['APpoint', 'Price', 'cap','approve',123])
s.str.endswith('e')
The matching results are as follows:

Processing nan values
s = pd.Series(['APpoint', 'Price', 'cap','approve',123])
s.str.endswith('e',na=False)
The effects are as follows:

5.3 startswitch function
Tests whether the beginning of each string element matches the string.
s = pd.Series(['APpoint', 'Price', 'cap','approve',123])
s.str.startswith('a',na=False)
Match as follows:

5.4 isalnum function
Check that all characters in each string are alphanumeric.
s1 = pd.Series(['one', 'one1', '1', '']) s1.str.isalnum()
The effects are as follows:

5.5 isalpha function
Check that all characters in each string are letters.
s1 = pd.Series(['one', 'one1', '1', '']) s1.str.isalpha()
The effects are as follows:

5.6 isdecimal function
Check that all characters in each string are decimal.
s1 = pd.Series(['one', 'one1', '1','']) s1.str.isdecimal()
The effects are as follows:

5.7 isdigit function
Check that all characters in each string are numbers.
s1 = pd.Series(['one', 'one1', '1','']) s1.str.isdigit()
The effects are as follows:

5.8 islower function
Check that all characters in each string are lowercase.
s1 = pd.Series(['one', 'one1', '1','']) s1.str.islower()
The effects are as follows:

5.9 isnumeric function
Check that all characters in each string are numbers.
s1 = pd.Series(['one', 'one1', '1','','3.6']) s1.str.isnumeric()
The effects are as follows:

5.10 isspace function
Check that all characters in each string are spaces.
s1 = pd.Series([' one', '\t\r\n','1', '',' ']) s1.str.isspace()
The effects are as follows:

5.11 istitle function
Check that all characters in each string are in the case of a header.
s1 = pd.Series(['leopard', 'Golden Eagle', 'SNAKE', '']) s1.str.istitle()
The effects are as follows:

5.12 isupper function
Check that all characters in each string are capitalized.
s1 = pd.Series(['leopard', 'Golden Eagle', 'SNAKE', '']) s1.str.isupper()
The effects are as follows:

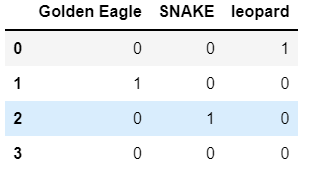
5.13 get_dummies function
Split each string in the series by sep and return a dataframe of virtual / indicator variables.
s1 = pd.Series(['leopard', 'Golden Eagle', 'SNAKE', '']) s1.str.get_dummies()
The effects are as follows:
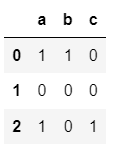
This function can also perform such matching, paying attention to the form of input
s1=pd.Series(['a|b', np.nan, 'a|c']) s1.str.get_dummies()
The effects are as follows:
6. Others
6.1 strip
Remove leading and trailing characters.
s1 = pd.Series(['1. Ant. ', '2. Bee!\n', '3. Cat?\t', np.nan]) s1.str.strip()
The effects are as follows:

6.2 lstrip
Removes the leading character from the series / index.
6.3 rstrip
Removes trailing characters from the series / index.