In the NLP task of automatic text understanding, named entity recognition (NER) is the primary task. The function of NER model is to identify named entities in text corpus, such as person name, organization, location, language and so on.
NER model can be used to understand the meaning of a text sentence / phrase. It can recognize the words that may represent who, what and who in the text, as well as other main entities referred to by the text data.
In this article, three techniques for performing NER on text data will be introduced. These techniques will involve pre trained and custom trained named entity recognition models.
- NLTK based pre training NER
- Sparcy based pre training NER
- Custom NER based on BERT
NLTK based pre training NER model:
The NLTK package provides an implementation of a pre trained ner model, which can implement the NER function with a few lines of Python code. The NLTK package provides a parameter option: either identify all named entities or identify named entities as their respective types, such as people, places, locations, etc.
If binary=True, the model will only assign a value when the word is named entity (NE) or unnamed entity (NE). Otherwise, for binary=False, all words will be assigned a label.
entities = []
tags = []
sentence = nltk.sent_tokenize(text)
for sent in sentence:
for chunk in nltk.ne_chunk(nltk.pos_tag(nltk.word_tokenize(sent)), binary=False):
if hasattr(chunk,'label'):
entities.append(' '.join(c[0] for c in chunk))
tags.append(chunk.label())
entities_tags = list(set(zip(entities,tags)))
entities_df = pd.DataFrame(entities_tags)
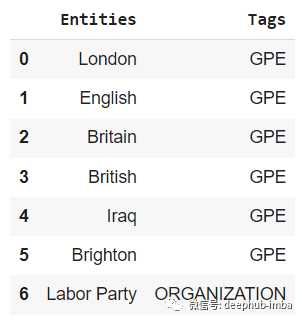
entities_df.columns = ["Entities","Tags"]Enter sample text:

The results are as follows:
Sparcy based pre training NER
Spacy package provides pre trained in-depth learning NER model and NER tasks with text data. Spacy provides three trained NER models: en_core_web_sm,en_core_web_md,en_core_web_lg.
The NER model can use Python - M spacedownload en_ core_ web_ SM download and use Spacey Load ("en_core_web_sm").
!python -m spacy download en_core_web_sm
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
entities, labels, position_start, position_end = [], [], [], []
for ent in doc.ents:
entities.append(ent)
labels.append(ent.label_)
position_start.append(ent.start_char)
position_end.append(ent.end_char)
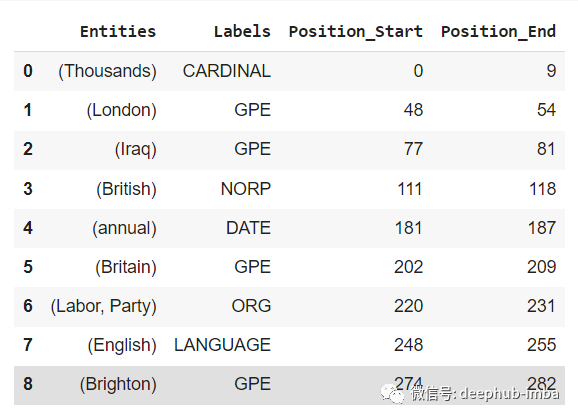
df = pd.DataFrame({'Entities':entities,'Labels':labels,'Position_Start':position_start, 'Position_End':position_end})Or the above text, the results are as follows:
NER based on BERT
The first two implementations of the NER model using NLTK and spacy are pre trained, and these packages provide API s to execute ner using Python functions.
For some custom fields, the pre training model may not perform well or may not be assigned relevant labels. At this time, transformer can be used to train the custom NER model based on BERT.
# Import necessary packages
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from simpletransformers.ner import NERModel, NERArgs
# Read sample training NER data
data = pd.read_csv("sample_ner_dataset.csv", encoding="latin1")
data = data.fillna(method ="ffill")
# Label Encode
data["Sentence #"] = LabelEncoder().fit_transform(data["Sentence #"] )
data.rename(columns={"Sentence #":"sentence_id","Word":"words","Tag":"labels"}, inplace =True)
data["labels"] = data["labels"].str.upper()
# Train test split
X = data[["sentence_id","words"]]
Y = data["labels"]
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size =0.2)
# Building up train data and test data
train_data = pd.DataFrame({"sentence_id":x_train["sentence_id"],"words":x_train["words"],"labels":y_train})
test_data = pd.DataFrame({"sentence_id":x_test["sentence_id"],"words":x_test["words"],"labels":y_test})
# Initializing NER model configurations
label = data["labels"].unique().tolist()
args = NERArgs()
args.num_train_epochs = 1
args.learning_rate = 1e-4
args.overwrite_output_dir =True
args.train_batch_size = 32
args.eval_batch_size = 32
# Train BERT based NER model
model = NERModel('bert', 'bert-base-cased', labels=label, args=args)
model.train_model(train_data, eval_data=test_data, acc=accuracy_score)
# Evaluate the performance of NER model
result, model_outputs, preds_list = model.eval_model(test_data)
# Perform NER for inference text
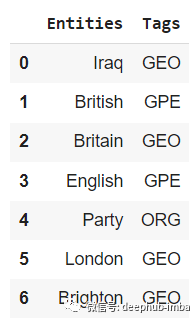
inference_text = "What is the new name of Bangalore"
prediction, model_output = model.predict([inference_text])The results are as follows:
summary
The performance of sparcy based pre trained NER model seems to be the best, in which the predicted labels are very close to the actual understanding of human beings. The Spacy NER model can be implemented in just a few lines of code and is easy to use.
The custom training ner model based on BERT provides similar performance. The NER model of customized training is also applicable to tasks in specific fields.
There are various other implementations of NER model, which are not discussed in this paper, such as the pre trained ner model of Stanford NLP. Those who are interested can have a look.
https://www.overfit.cn/post/b7a368f1282149338a1afc20a5a6afcc