Troubleshooting process of MySQL master-slave replication
1, Overview
MySQL master-slave is one of the commonly used high availability architectures, and it is also the most widely used system architecture. In the production environment, MySQL master-slave replication sometimes has replication errors. Coordinator stopped beacause there were errors in the workers...)
2, Principle of mysql master-slave replication
mysql Master-slave replication is an asynchronous replication process (the overall feeling is real-time synchronous). The whole process of mysql Master-slave replication is completed by three threads. The slave end has two threads (SQL thread and IO thread), and the Master end has another thread (IO thread).
MYSQL master-slave replication process
-
Execute start slave on the Slave server and turn on the master-Slave copy switch.
-
At this time, the IO thread on the Slave server connects to the Master server through the request of the authorized replication user on the Master server. It also requests that the binlog log contents be sent from the specified location of the binlog log file.
(specify the log file name and location when executing the change master command when configuring the master-slave replication task) -
After the Master server receives the request from the IO thread of the Slave server, the IO thread on the Master server is based on the Slave.
The information requested by the IO thread of the server reads the binlog log information after specifying the specified location of the binlog log file, and then returns it to the IO thread on the Slave side. In addition to the binlog content, the Master server also has a new binlog after the log content is returned.
The file name in binlog and the next specified update location. -
When the IO thread of the Slave server obtains the log content, log file and location point sent by the IO thread from the Master server, add binlog. The log contents are written to the end of the Slave's own relay log file (mysql-relay-bin.xxxxxx). And record the new binlog file name and location in the Master info file, so that when reading the new binlog log on the Master side next time, you can tell the Master server which file to start from and where to request the new binlog content from the new binlog log
-
The SQL thread on the Slave server side detects the newly added log content in the local relay log in real time and updates the relay log in time.
The contents of the file are parsed into the contents of SQL statements executed on the Master side, and SQL applications are executed in the order of statements on the Slave server itself. -
After the above process, you can ensure that the same SQL statements are executed on the Master and Slave sides. When the replication status is normal, the Master
The data of the client and the lave client are completely consistent.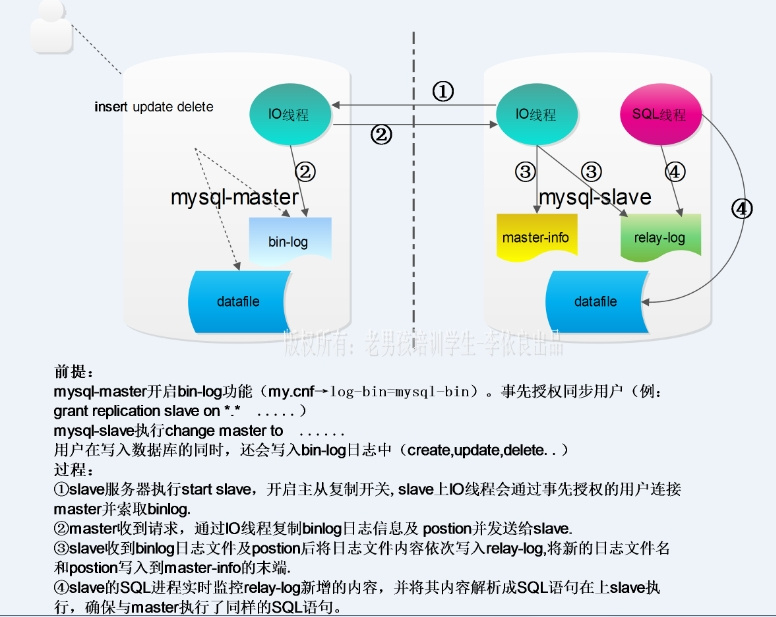
3, Problems and Solutions
1. show slave status \G displays the following error messages:
Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 1 failed executing transaction ...

2. Locate the error location according to the prompt information
Case 1: "Delete_rows"
select * from performance_schema.replication_applier_status_by_worker \G

Reason: a record is deleted on the master, but cannot be found on the slave.
Solution: because the master wants to delete a record, but the slave cannot find it, an error is reported. In this case, the master deletes it, and the slave can skip it directly.
stop slave; set global sql_slave_skip_counter=1; start slave;
If the above command reports an error: ERROR 1858 (HY000): sql_slave_skip_counter can not be set when the server is running with @@GLOBAL.GTID_MODE = ON. Instead, for each transaction that you want to skip, generate an empty transaction with the same GTID as the transaction, or use the following command instead:
STOP SLAVE; SET @@SESSION.GTID_NEXT= 'f396f867-d755-11xxx85-005xxxxxb5a:264261655' --stay session Inside setting gtid_next,That is, skip this GTID BEGIN; COMMIT; --Set empty things SET SESSION GTID_NEXT = AUTOMATIC; -- recovery GTID START SLAVE;xxxx
Case 2: "Duplicate"
Last_SQL_Error: Could not execute Write_rows event on table xxx; Duplicate entry 'xxx' for key 'PRIMARY',
Reason: the record already exists in the slave, and the same record is inserted in the master
Solution: delete the record from the library or skip the record. Then confirm on the master and slave respectively.
Case 3: "Update_rows"
Last_SQL_Error: Could not execute Update_rows event on table xxx; Can't find record in 'xxx',
Reference reason: a record is updated on the master, but cannot be found on the slave, and the data is lost.
Reference method: on the master, use mysqlbinlog to analyze what the error binlog is doing.
/usr/local/mysql/bin/mysqlbinlog --no-defaults -v -v --base64-output=DECODE-ROWS mysql-bin.000010 | grep -A '10' 794 #120302 12:08:36 server id 22 end_log_pos 794 Update_rows: table id 33 flags: STMT_END_F ### UPDATE hcy.t1 ### WHERE ### @1=2 /* INT meta=0 nullable=0 is_null=0 */ ### @2='bbc' /* STRING(4) meta=65028 nullable=1 is_null=0 */ ### SET ### @1=2 /* INT meta=0 nullable=0 is_null=0 */ ### @2='BTV' /* STRING(4) meta=65028 nullable=1 is_null=0 */ # at 794 #120302 12:08:36 server id 22 end_log_pos 821 Xid = 60 COMMIT/*!*/; DELIMITER ; # End of log file ROLLBACK /* added by mysqlbinlog */; /*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/;
On the slave, find the updated record. It should not exist.
mysql> select * from t1 where id=2;
Empty set (0.00 sec)
Then go to the master to check
ysql> select * from t1 where id=2; +----+------+ | id | name | +----+------+ | 2 | BTV | +----+------+ 1 row in set (0.00 sec)
Fill in the lost data on the slave, and then skip the error report.
mysql> insert into t1 values (2,'BTV'); Query OK, 1 row affected (0.00 sec) mysql> select * from t1 where id=2; +----+------+ | id | name | +----+------+ | 2 | BTV | +----+------+ 1 row in set (0.00 sec) mysql> stop slave ;set global sql_slave_skip_counter=1;start slave; Query OK, 0 rows affected (0.01 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) mysql> show slave status\G; ...... Slave_IO_Running: Yes Slave_SQL_Running: Yes
4, General solution
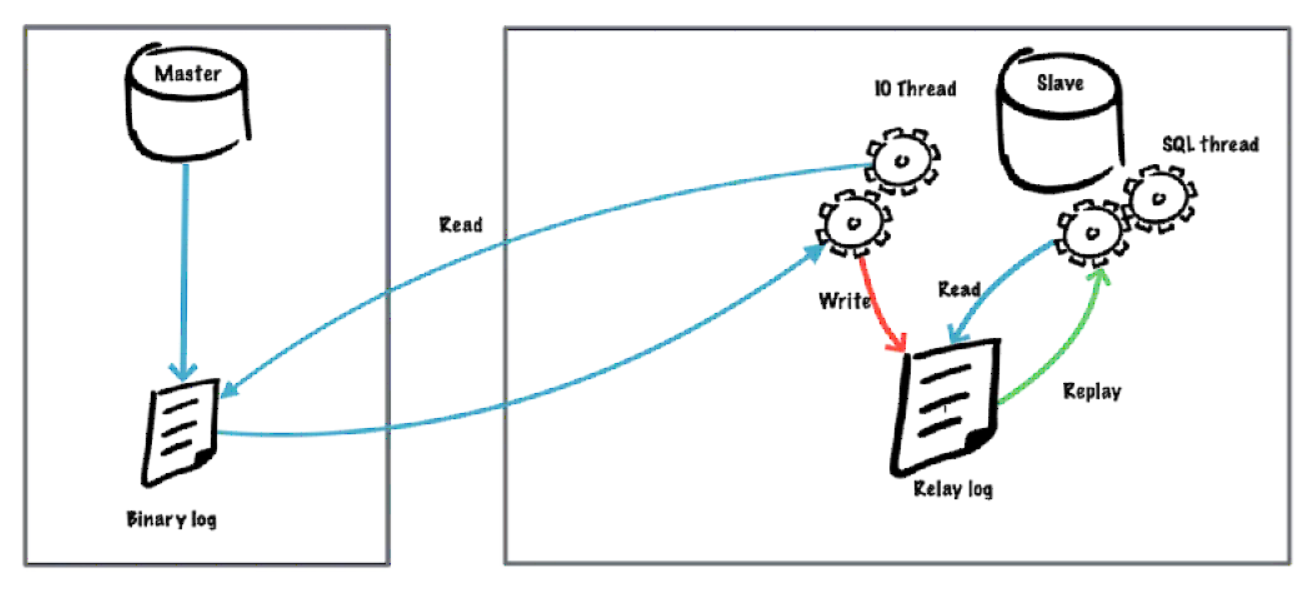
mysql master-slave replication often encounters errors, resulting in the interruption of slave replication. At this time, manual intervention is generally required to skip the errors before continuing
There are two ways to skip errors
4.1 skip a specified number of transactions
mysql>slave stop; mysql>SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1 #Skip a transaction mysql>slave start
4.2 skip all errors or specified types of errors
Modify the mysql configuration file through slave_ skip_ The errors parameter to skip all errors or errors of the specified type
vi /etc/my.cnf [mysqld] #slave-skip-errors=1062,1053,1146 #Skip errors of the specified error no type #slave-skip-errors=all #Skip all errors