1, Canal introduction
In the early days, Alibaba had the business requirement of cross machine room synchronization due to the deployment of dual machine rooms in Hangzhou and the United States. The implementation method was mainly to obtain incremental changes based on the business trigger. Since 2010, the business has gradually tried to obtain incremental changes through database log parsing for synchronization, resulting in a large number of database incremental subscriptions and consumption services.
Services based on log incremental subscription and consumption include
- database mirroring
- Real time database backup
- Index construction and real-time maintenance (splitting heterogeneous indexes, inverted indexes, etc.)
- Service cache refresh
- Incremental data processing with business logic
Current canal supports source MySQL versions, including 5.1. X, 5.5. X, 5.6. X, 5.7. X, and 8.0. X
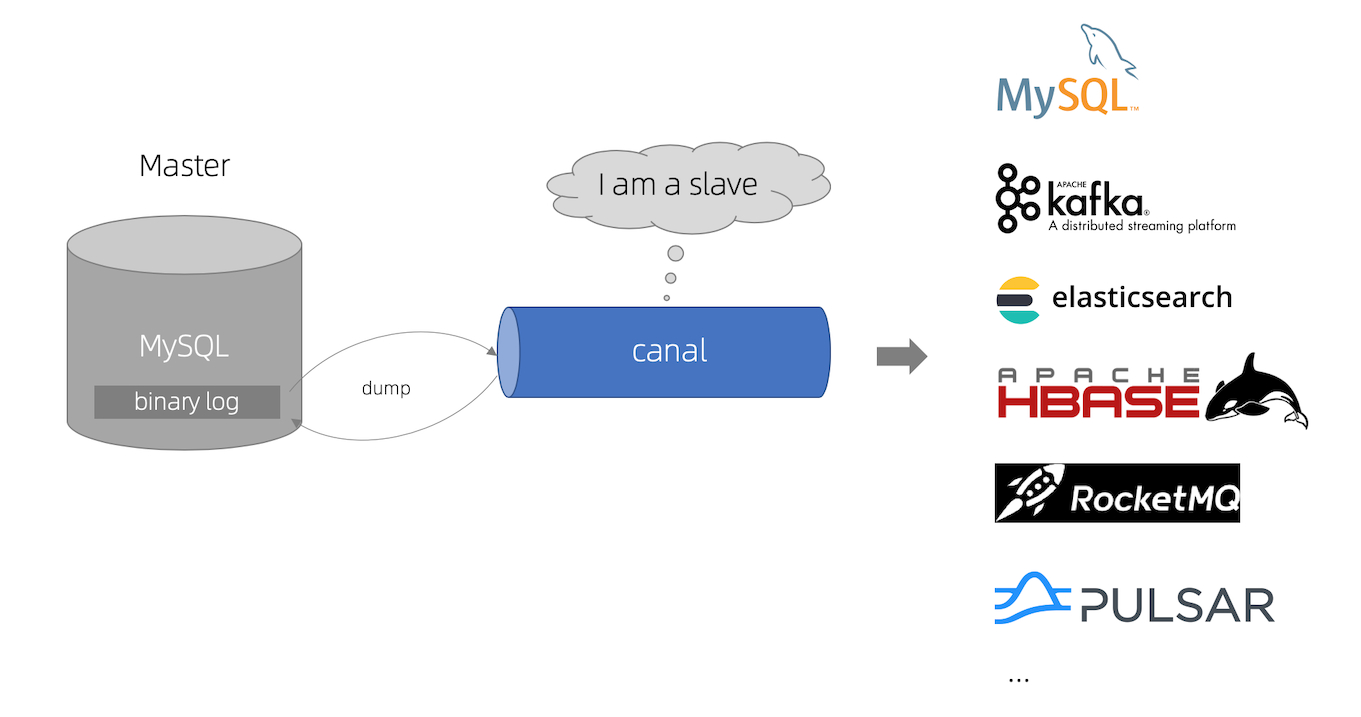
working principle
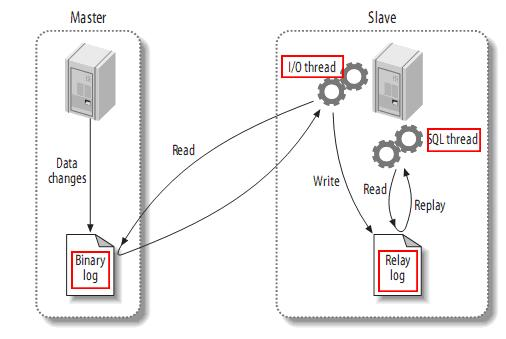
- MySQL master writes data changes to binary log (binary log, in which records are called binary log events, which can be viewed through show binlog events)
- MySQL slave copies the binary log events of the master to its relay log
- MySQL slave replays events in the relay log and reflects data changes to its own data
How canal works
- canal simulates the interaction protocol of MySQL slave, disguises itself as MySQL slave, and sends dump protocol to - MySQL master
- The MySQL master receives a dump request and starts pushing binary log s to slave (i.e. canal)
- canal parses binary log object (originally byte stream)
GitHub : https://github.com/alibaba/canal
2, Download
Download address: https://github.com/alibaba/canal/tags
Here we use v1.1.5, Click download
Network disk address: link: https://pan.baidu.com/s/1VjIzpb79d05CET5xEnwdEQ Extraction code: h0bk
3, Installation and use
Mysql preparation
- For self built MySQL, you need to turn on the Binlog write function and configure Binlog format to ROW mode. The configuration in my.cnf is as follows
[mysqld] log-bin=mysql-bin # Enable binlog binlog-format=ROW # Select ROW mode server_id=1 # MySQL replacement configuration needs to be defined. It should not duplicate the slaveId of canal
- Authorize the canal linked MySQL account to have the permission to act as a MySQL slave. If there is an existing account, you can grant it directly
CREATE USER canal IDENTIFIED BY 'canal'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; -- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ; FLUSH PRIVILEGES;
canal installation
Unzip the canal deployer
tar -zxvf canal.deployer-1.1.5.tar.gz
The directory structure after decompression is as follows
drwxr-xr-x 2 root root 76 Sep 18 16:58 bin drwxr-xr-x 5 root root 123 Sep 18 16:58 conf drwxr-xr-x 2 root root 4096 Sep 18 16:58 lib drwxrwxrwx 2 root root 6 Apr 19 16:15 logs drwxrwxrwx 2 root root 177 Apr 19 16:15 plugin
Configuration modification
################################################# ## mysql serverId , v1.0.26+ will autoGen ## slaveId will be automatically generated after v1.0.26, so you can not configure it # canal.instance.mysql.slaveId=0 # enable gtid use true/false canal.instance.gtidon=false # position info # Database address canal.instance.master.address=127.0.0.1:3306 # binlog log name canal.instance.master.journal.name= # Starting binlog offset when linking mysql main database canal.instance.master.position= # Timestamp of binlog starting when linking mysql main database canal.instance.master.timestamp= canal.instance.master.gtid= # rds oss binlog canal.instance.rds.accesskey= canal.instance.rds.secretkey= canal.instance.rds.instanceId= # table meta tsdb info canal.instance.tsdb.enable=true #canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb #canal.instance.tsdb.dbUsername=canal #canal.instance.tsdb.dbPassword=canal #canal.instance.standby.address = #canal.instance.standby.journal.name = #canal.instance.standby.position = #canal.instance.standby.timestamp = #canal.instance.standby.gtid= # username/password canal.instance.dbUsername=canal canal.instance.dbPassword=canal # canal.instance.connectionCharset represents the encoding method of the database corresponding to the encoding type in java, such as UTF-8, GBK, iso-8859-1 canal.instance.connectionCharset = UTF-8 # enable druid Decrypt database password canal.instance.enableDruid=false #canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== # table regex # Configure listening and support regular expressions canal.instance.filter.regex=.*\\..* # table black regex # The configuration does not listen and supports regular expressions canal.instance.filter.black.regex=mysql\\.slave_.* # table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch # table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch # mq config canal.mq.topic=example # dynamic topic route by schema or table regex #canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..* canal.mq.partition=0 # hash partition config #canal.mq.partitionsNum=3 #canal.mq.partitionHash=test.table:id^name,.*\\..* #canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6 #################################################
start-up
sh bin/startup.sh
View server logs
# tailf logs/canal/canal.log 2021-09-19 09:38:26.746 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## set default uncaught exception handler 2021-09-19 09:38:26.793 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## load canal configurations 2021-09-19 09:38:26.812 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## start the canal server. 2021-09-19 09:38:26.874 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[192.168.168.2(192.168.168.2):11111] 2021-09-19 09:38:28.240 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## the canal server is running now ......
View instance log
# tailf logs/example/example.log 2021-09-19 09:38:28.191 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example 2021-09-19 09:38:28.202 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table filter : ^.*\..*$ 2021-09-19 09:38:28.202 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table black filter : ^mysql\.slave_.*$ 2021-09-19 09:38:28.207 [main] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - start successful....
Service stop
sh bin/stop.sh
Canal client usage
- manve reference
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>
- ClientSample.java
import java.net.InetSocketAddress;
import java.util.List;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.common.utils.AddressUtils;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
/**
* @author Jast
* @description
* @date 2021-09-19 09:43
*/
public class ClientSample {
public static void main(String args[]) {
// create link
// CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),
// 11111), "example", "", "");
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("192.168.168.2",
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
int totalEmptyCount = 120;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // Gets the specified amount of data
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // Submit for confirmation
// connector.rollback(batchId); // Processing failed, rollback data
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
At this time, database related operations will be output on the console
================> binlog[mysql-bin.000003:834] , name[mysql,test] , eventType : CREATE
Canal Adapter
- Unzip the package
mkdir canal-adapter && tar -zxvf canal.adapter-1.1.5.tar.gz -C canal-adapter
Data synchronization Hbase
- 1. Modify initiator configuration: application.yml
server:
port: 8081
logging:
level:
com.alibaba.otter.canal.client.adapter: DEBUG
com.alibaba.otter.canal.client.adapter.hbase: DEBUG
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
# flatMessage: true
zookeeperHosts:
syncBatchSize: 1
retries: 0
timeout: 1000
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111
canal.tcp.zookeeper.hosts: 127.0.0.1:2181
canal.tcp.batch.size: 1
canal.tcp.username:
canal.tcp.password:
srcDataSources:
defaultDS:
url: jdbc:mysql://127.0.0.1:3306/test2?useUnicode=true
username: root
password: *****
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
# - name: rdb
# key: mysql1
# properties:
# jdbc.driverClassName: com.mysql.jdbc.Driver
# jdbc.url: jdbc:mysql://127.0.0.1:3306/mytest2?useUnicode=true
# jdbc.username: root
# jdbc.password: 121212
# - name: rdb
# key: oracle1
# properties:
# jdbc.driverClassName: oracle.jdbc.OracleDriver
# jdbc.url: jdbc:oracle:thin:@localhost:49161:XE
# jdbc.username: mytest
# jdbc.password: m121212
# - name: rdb
# key: postgres1
# properties:
# jdbc.driverClassName: org.postgresql.Driver
# jdbc.url: jdbc:postgresql://localhost:5432/postgres
# jdbc.username: postgres
# jdbc.password: 121212
# threads: 1
# commitSize: 3000
- name: hbase
properties:
hbase.zookeeper.quorum: sangfor.abdi.node3,sangfor.abdi.node2,sangfor.abdi.node1
hbase.zookeeper.property.clientPort: 2181
zookeeper.znode.parent: /hbase-unsecure # Here is the directory of hbase meta information in Zookeeper
# - name: es7
# hosts: 127.0.0.1:9300 # 127.0.0.1:9200 for rest mode
# properties:
# mode: transport # or rest
# # security.auth: test:123456 # only used for rest mode
# cluster.name: my_application
# - name: kudu
# key: kudu
# properties:
# kudu.master.address: 127.0.0.1 # ',' split multi address
Note: the adapter will automatically load all configuration files ending in. yml under conf/hbase
- 2.Hbase table mapping file
Modify conf/hbase/mytest_person.yml file:
dataSourceKey: defaultDS # Corresponds to the configuration under datasourceconfigures in application.yml
destination: example # It corresponds to the canal instance in tcp mode or topic in MQ mode
groupId: # !!! Note: when synchronizing Hbase data, do not fill in the content of groupId here. Only the data corresponding to groupId in MQ mode will be synchronized
hbaseMapping: # Single table mapping configuration of MySQL HBase
mode: STRING # HBase Storage type in, Default unified save as String, Optional: #PHOENIX #NATIVE #STRING
# NATIVE: mainly java type, Phoenix: convert the type to the type corresponding to Phoenix
destination: example # Name of corresponding canal destination/MQ topic
database: mytest # Database name / schema name
table: person # Table name
hbaseTable: MYTEST.PERSON # HBase table name
family: CF # Default unified Column Family name
uppercaseQualifier: true # The field name is capitalized. The default value is true
commitBatch: 3000 # The size of batch submission, which is used in ETL
#rowKey: id,type # The composite field rowKey cannot coexist with the rowKey in columns
# Composite rowkeys are separated by '|'
columns: # Field mapping. If not configured, all fields will be mapped automatically,
# The first field is rowkey, and the name of HBase field is mainly mysql field name
id: ROWKE
name: CF:NAME
email: EMAIL # If column family is the default CF, it can be omitted
type: # If the names of HBase field and mysql field are consistent, they can be omitted
c_time:
birthday:
Note: if type conversion is involved, it can be in the following form:
...
columns:
id: ROWKE$STRING
...
type: TYPE$BYTE
...
Type conversion involves Java type and Phoenix type, which are defined as follows:
#Java type conversion, corresponding configuration mode: NATIVE $DEFAULT $STRING $INTEGER $LONG $SHORT $BOOLEAN $FLOAT $DOUBLE $BIGDECIMAL $DATE $BYTE $BYTES
#Phoenix type conversion, corresponding configuration mode: PHOENIX $DEFAULT corresponding PHOENIX Inside VARCHAR $UNSIGNED_INT corresponding PHOENIX Inside UNSIGNED_INT 4 byte $UNSIGNED_LONG corresponding PHOENIX Inside UNSIGNED_LONG 8 byte $UNSIGNED_TINYINT corresponding PHOENIX Inside UNSIGNED_TINYINT 1 byte $UNSIGNED_SMALLINT corresponding PHOENIX Inside UNSIGNED_SMALLINT 2 byte $UNSIGNED_FLOAT corresponding PHOENIX Inside UNSIGNED_FLOAT 4 byte $UNSIGNED_DOUBLE corresponding PHOENIX Inside UNSIGNED_DOUBLE 8 byte $INTEGER corresponding PHOENIX Inside INTEGER 4 byte $BIGINT corresponding PHOENIX Inside BIGINT 8 byte $TINYINT corresponding PHOENIX Inside TINYINT 1 byte $SMALLINT corresponding PHOENIX Inside SMALLINT 2 byte $FLOAT corresponding PHOENIX Inside FLOAT 4 byte $DOUBLE corresponding PHOENIX Inside DOUBLE 8 byte $BOOLEAN corresponding PHOENIX Inside BOOLEAN 1 byte $TIME corresponding PHOENIX Inside TIME 8 byte $DATE corresponding PHOENIX Inside DATE 8 byte $TIMESTAMP corresponding PHOENIX Inside TIMESTAMP 12 byte $UNSIGNED_TIME corresponding PHOENIX Inside UNSIGNED_TIME 8 byte $UNSIGNED_DATE corresponding PHOENIX Inside UNSIGNED_DATE 8 byte $UNSIGNED_TIMESTAMP corresponding PHOENIX Inside UNSIGNED_TIMESTAMP 12 byte $VARCHAR corresponding PHOENIX Inside VARCHAR Dynamic length $VARBINARY corresponding PHOENIX Inside VARBINARY Dynamic length $DECIMAL corresponding PHOENIX Inside DECIMAL Dynamic length
If not configured, the default mapping transformation will be performed with the java object native type
- 3. Start service
Start: bin/startup.sh stop it: bin/stop.sh Restart: bin/restart.sh Log directory: logs/adapter/adapter.log
- 4. Verification services
Insert data into mysql
INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now()); INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now()); INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now()); INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now()); INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now()); INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now()); INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now()); INSERT INTO testsync(id,name,age,insert_time) values(UUID(),UUID(),2,now());
According to the log content, we can see that the data we wrote has been obtained
2021-09-20 12:35:09.682 [pool-1-thread-1] INFO c.a.o.canal.client.adapter.logger.LoggerAdapterExample - DML: {"data":[{"id":"2286ed67-19cc-11ec-bbe0-708cb6f5eaa6","name":"2286ed83-19cc-11ec-bbe0-708cb6f5eaa6","age":2,"age_2":null,"message":null,"insert_time":1632112508000}],"database":"test2","destination":"example","es":1632112508000,"groupId":"g1","isDdl":false,"old":null,"pkNames":["id"],"sql":"","table":"testsync","ts":1632112509680,"type":"INSERT"}
2021-09-20 12:35:09.689 [pool-1-thread-1] DEBUG c.a.o.c.client.adapter.hbase.service.HbaseSyncService - DML: {"data":[{"id":"2286ed67-19cc-11ec-bbe0-708cb6f5eaa6","name":"2286ed83-19cc-11ec-bbe0-708cb6f5eaa6","age":2,"age_2":null,"message":null,"insert_time":1632112508000}],"database":"test2","destination":"example","es":1632112508000,"groupId":"g1","isDdl":false,"old":null,"pkNames":["id"],"sql":"","table":"testsync","ts":1632112509680,"type":"INSERT"}
Check the data in the Hbase table and find that the write is successful
hbase(main):036:0> scan 'testsync',{LIMIT=>1}
ROW COLUMN+CELL
226ba6e8-19cc-11ec-bbe0-708c column=CF:AGE, timestamp=2021-09-20T12:35:08.548, value=2
b6f5eaa6
226ba6e8-19cc-11ec-bbe0-708c column=CF:INSERT_TIME, timestamp=2021-09-20T12:35:08.548, value=2021-09-20 12:35:08.0
b6f5eaa6
226ba6e8-19cc-11ec-bbe0-708c column=CF:NAME, timestamp=2021-09-20T12:35:08.548, value=226ba718-19cc-11ec-bbe0-708c
b6f5eaa6 b6f5eaa6
1 row(s)
Took 0.0347 seconds
PS: there is a problem in this link that has been stuck for a long time. The log prints out data, but the actual Hbase cannot be successfully written. The solution to the problem is uniformly described at the end of the paper.
Data synchronization ElasticSearch
We then directly modify the configuration based on the previous configuration of Hbase to synchronize ElasticSearch at the same time