General process:

Implement system call
Add two system calls on Linux 0.11
(1)iam()
The first system call is iam(), whose prototype is:
int iam(const char * name);
The completed function is to copy the content of the string parameter name to the kernel and save it. Name is required to be no longer than 23 characters. The return value is the number of characters copied. If the number of characters of name exceeds 23, return "- 1" and set errno to EINVAL.
At kernal / who C.
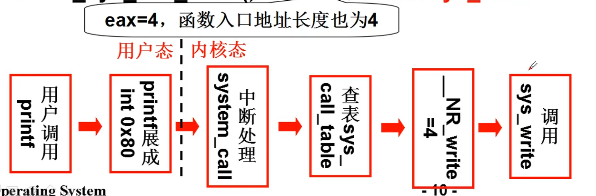
1. How does an application invoke a system call

Call the system call. The process is:
Store the system call number in EAX; Store the function parameters in other general registers; Trigger 0 x80 No. interrupt( int 0x80).
Let's take a look at lib / close c. Study the API of close():
#define __LIBRARY__ #include <unistd.h> _syscall1(int, close, int, fd)
Among them_ syscall1 is a macro in include / unistd Defined in H.
#define _syscall1(type,name,atype,a) \
type name(atype a) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(a))); \
if (__res >= 0) \
return (type) __res; \
errno = -__res; \
return -1; \
}
Will_ Expand syscall1(int,close,int,fd) to get:
int close(int fd)
{
long __res;
__asm__ volatile ("int $0x80"
: "=a" (__res)
: "0" (__NR_close),"b" ((long)(fd)));
if (__res >= 0)
return (int) __res;
errno = -__res;
return -1;
}
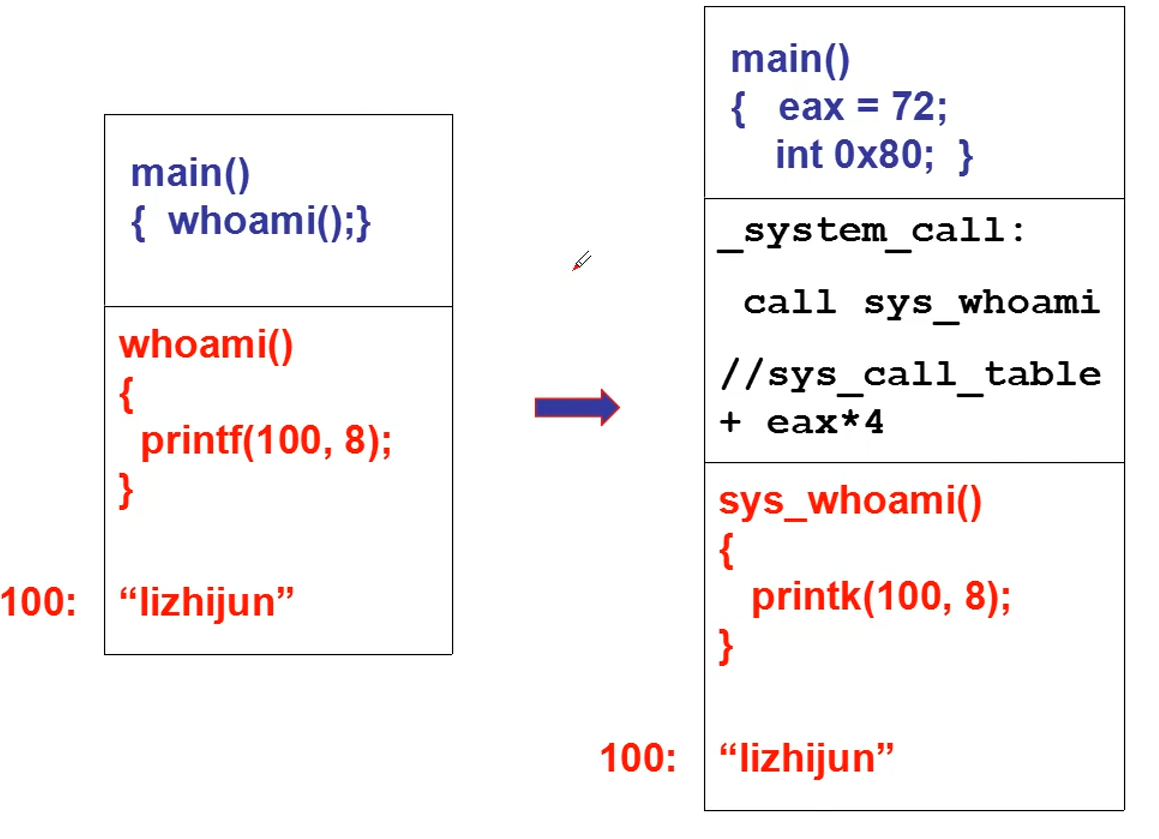
This is the definition of API. It first puts the macro__ NR_close is stored in EAX, the parameter fd is stored in EBX, and then 0x80 interrupt call is made. After the call returns, take the return value from EAX and store it in__ res, and then pass on__ res determines what return value is passed to the caller of the API.
Among them__ NR_close is the number of the system call, in include / unistd Defined in H:
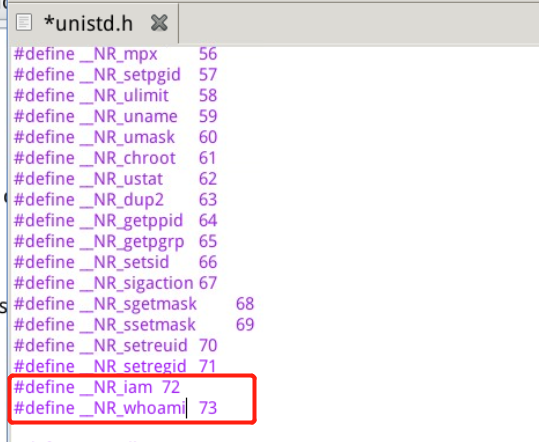
#define __NR_close 6 /* Therefore, when adding a system call, you need to modify include / unistd H documents, Make it include__ NR_whoami and__ NR_iam. */
/* In the application, there should be: */ /* With it_ syscall1 is valid. See unistd h */ #define __LIBRARY__ /* With it, the compiler can know the number of custom system calls */ #include "unistd.h" /* iam()Interface functions in user space */ _syscall1(int, iam, const char*, name); /* whoami()Interface functions in user space */ _syscall2(int, whoami,char*,name,unsigned int,size);
We first need to add our own implementation number:
2. Enter kernel function from "int 0x80"
After int 0x80 is triggered, the next step is the interrupt processing of the kernel. Let's first understand the process of 0.11 processing interrupt 0x80.
During kernel initialization, the main function (in init/main.c, main() in Linux experimental environment) calls sched_init() initialization function:
void main(void)
{
// ......
time_init();
sched_init();
buffer_init(buffer_memory_end);
// ......
}
sched_init() in kernel / sched C is defined as:
void sched_init(void)
{
// ......
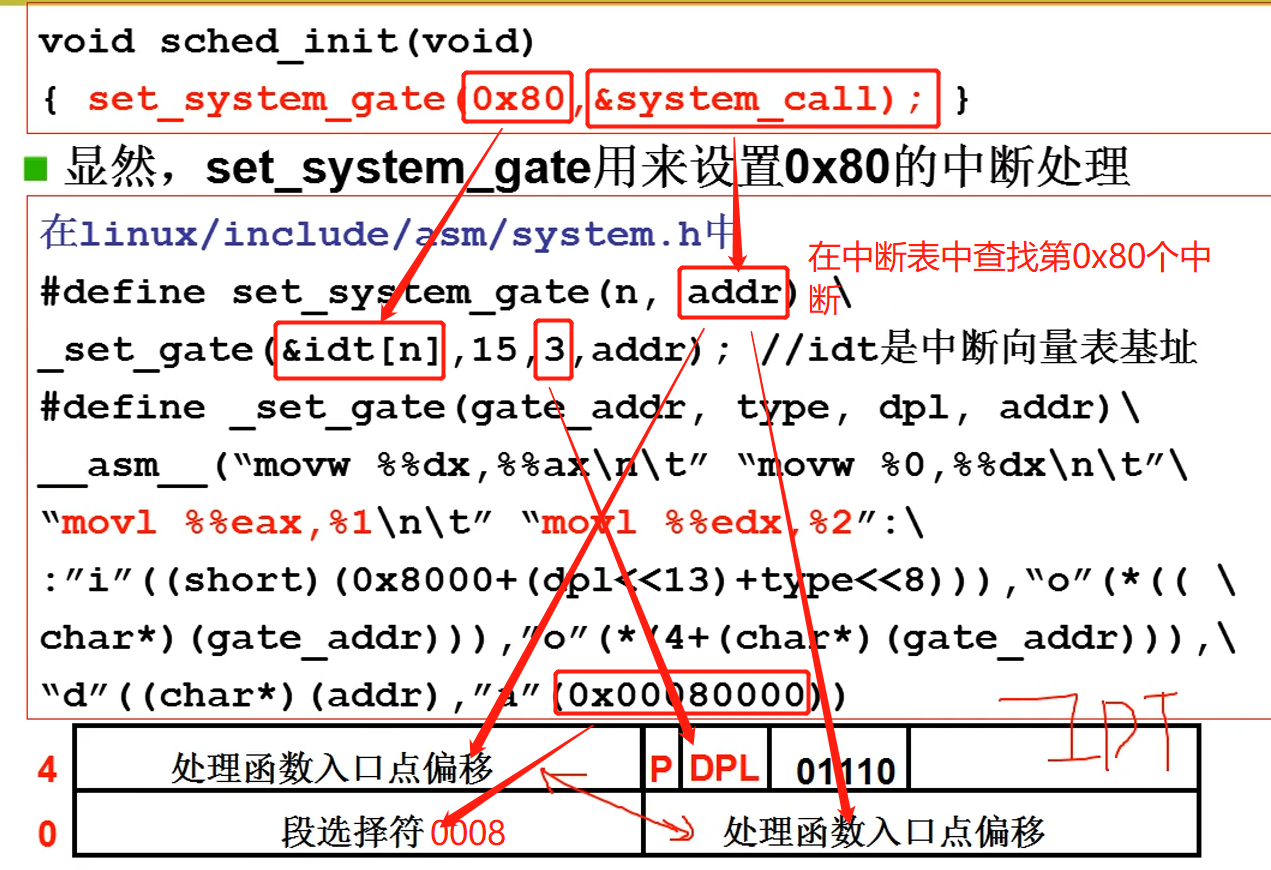
set_system_gate(0x80,&system_call);
}
set_system_gate is a macro in include / ASM / system H is defined as:
#define set_system_gate(n,addr) \
_set_gate(&idt[n],15,3,addr)
_ set_gate is defined as:
#define _set_gate(gate_addr,type,dpl,addr) \
__asm__ ("movw %%dx,%%ax\n\t" \
"movw %0,%%dx\n\t" \
"movl %%eax,%1\n\t" \
"movl %%edx,%2" \
: \
: "i" ((short) (0x8000+(dpl<<13)+(type<<8))), \
"o" (*((char *) (gate_addr))), \
"o" (*(4+(char *) (gate_addr))), \
"d" ((char *) (addr)),"a" (0x00080000))
Although it seems troublesome, it is actually very simple, that is, fill in the IDT (interrupt descriptor table) and set the system_ The call function address is written into the interrupt descriptor corresponding to 0x80, that is, after the interrupt 0x80 occurs, the function system is automatically called_ call. For details, please refer to Chapter 4 of the notes.
Students who can't understand can see the following figure:
 The process is as follows: assign values to variables one by one:
The process is as follows: assign values to variables one by one:

Next, look at the system_call. This function is made of pure assembly and is defined in kernel / system_call. In S:
!......
! # This is the total number of system calls. If the system call is added or deleted, it must be modified accordingly
nr_system_calls = 72
!......
.globl system_call
.align 2
system_call:
! # Check whether the system call number is within the legal range
cmpl \$nr_system_calls-1,%eax
ja bad_sys_call
push %ds
push %es
push %fs
pushl %edx
pushl %ecx
! # Push% ebx,% ECX,% EDX, are parameters passed to the system call
pushl %ebx
! # Let DS and ES point to GDT and kernel address space
movl $0x10,%edx
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx
! # Let fs point to LDT, user address space
mov %dx,%fs
call sys_call_table(,%eax,4)
pushl %eax
movl current,%eax
cmpl $0,state(%eax)
jne reschedule
cmpl $0,counter(%eax)
je reschedule
system_call globl is decorated to be visible to other functions.
call sys_ call_ Before table (,% eax, 4), there are some stack pressing protection. The modified segment selector is the kernel segment, call sys_call_table(,%eax,4) is followed by the need to reschedule. These are not directly related. Here we only care about call sys_call_table(,%eax,4).

According to the assembly addressing method, it is actually: call sys_ call_ Table + 4 *% eax, where the system call number is placed in eax, i.e__ NR_xxxxxx.
Obviously, sys_call_table must be the starting address of a function pointer array, which is defined in include / Linux / sys In H:
extern int sys_ssetmask();
extern int sys_setreuid();
extern int sys_setregid();
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,
sys_write, sys_open, sys_close, sys_waitpid, sys_creat, sys_link,
sys_unlink, sys_execve, sys_chdir, sys_time, sys_mknod, sys_chmod,
sys_chown, sys_break, sys_stat, sys_lseek, sys_getpid, sys_mount,
sys_umount, sys_setuid, sys_getuid, sys_stime, sys_ptrace, sys_alarm,
sys_fstat, sys_pause, sys_utime, sys_stty, sys_gtty, sys_access,
sys_nice, sys_ftime, sys_sync, sys_kill, sys_rename, sys_mkdir,
sys_rmdir, sys_dup, sys_pipe, sys_times, sys_prof, sys_brk, sys_setgid,
sys_getgid, sys_signal, sys_geteuid, sys_getegid, sys_acct, sys_phys,
sys_lock, sys_ioctl, sys_fcntl, sys_mpx, sys_setpgid, sys_ulimit,
sys_uname, sys_umask, sys_chroot, sys_ustat, sys_dup2, sys_getppid,
sys_getpgrp, sys_setsid, sys_sigaction, sys_sgetmask, sys_ssetmask,
sys_setreuid,sys_setregid };
To add the system call required by the experiment, you need to add two function references sys in this function table_ Iam and sys_whoami. Of course, the function is in sys_ call_ The position in the table array must be and__ NR_ The value of XXXXXX corresponds to.
At the same time, follow the writing method of the previous system calls in this file, and add:
extern int sys_ssetmask(); extern int sys_setreuid(); extern int sys_setregid(); extern int sys_whoami(); extern int sys_iam();
Otherwise, the compilation will go wrong.
3. Implement sys_iam() and sys_whoami()
The last step in adding a system call is to implement the function sys in the kernel_ Iam () and sys_whoami().
Each system call has a sys_xxxxxx() corresponds to it. They are good objects for us to learn and imitate.
For example, in FS / open Sys in C_ close(int fd):
int sys_close(unsigned int fd)
{
// ......
return (0);
}
It's nothing special. It really does what close() should do.
So just create a file: kernel / who c. Then implement the two functions and everything will be fine.
#define __LIBRARY__
#include <unistd.h>
#include <errno.h>
#include <asm/segment.h>
char temp[64]={0};
int sys_iam(const char* name)
{
int i=0;
while(get_fs_byte(name+i)!='\0')
i++;
if(i>23){
return -EINVAL;
}
printk("%d\n",i);
i=0;
while((temp[i]=get_fs_byte(name+i))!='\0'){
i++;
}
return i;
}
int sys_whoami(char* name,unsigned int size)
{
int i=0;
while (temp[i]!='\0')
i++;
if (size<i)
return -1;
i=0;
while(temp[i]!='\0'){
put_fs_byte(temp[i],(name+i));
i++;
}
return i;
}
Write who C put it in the linux-0.01/kernel directory and execute make all who C will be compiled into the kernel
4. Modify Makefile
If you want us to add kernel / who C can be linked with other Linux code compilation, and the Makefile file must be modified. The Makefile records the compilation and linking rules of all source program files, which are briefly introduced in section 3.6 of the notes. The reason why we can compile the whole code tree simply by running make is that make works exactly according to the instructions in the Makefile.
There are many makefiles in the code tree, which are responsible for compiling different modules. What we want to modify is the kernel/Makefile. Two modifications are required. One is:
- OBJS = sched.o system_call.o traps.o asm.o fork.o
panic.o printk.o vsprintf.o sys.o exit.o
signal.o mktime.o
Replace with:
- OBJS = sched.o system_call.o traps.o asm.o fork.o
panic.o printk.o vsprintf.o sys.o exit.o
signal.o mktime.o who.o
Another:
### Dependencies: exit.s exit.o: exit.c ../include/errno.h ../include/signal.h \ ../include/sys/types.h ../include/sys/wait.h ../include/linux/sched.h \ ../include/linux/head.h ../include/linux/fs.h ../include/linux/mm.h \ ../include/linux/kernel.h ../include/linux/tty.h ../include/termios.h \ ../include/asm/segment.h
Replace with:
### Dependencies: who.s who.o: who.c ../include/linux/kernel.h ../include/unistd.h exit.s exit.o: exit.c ../include/errno.h ../include/signal.h \ ../include/sys/types.h ../include/sys/wait.h ../include/linux/sched.h \ ../include/linux/head.h ../include/linux/fs.h ../include/linux/mm.h \ ../include/linux/kernel.h ../include/linux/tty.h ../include/termios.h \ ../include/asm/segment.h
After the Makefile is modified, as usual, "make all" can automatically change who C is added to the kernel. If the compiler prompts who C. if there is an error, the modification takes effect. Therefore, intentionally or unintentionally making one or two mistakes is not entirely a bad thing. At least it can prove that Makefile is right.