introduction
In development, we often encounter some requirements for delayed tasks. for example
- If the order has not been paid for 30 minutes, it will be automatically cancelled
- Send a text message to the user 60 seconds after the order is generated
For the above tasks, we give a professional name to describe, that is, delayed tasks. Then a question arises here. What is the difference between delayed tasks and scheduled tasks? There are the following differences
- Timed tasks have a clear trigger time, and delayed tasks do not
- A scheduled task has an execution cycle, while a delayed task executes within a period of time after an event is triggered, and there is no execution cycle
- Scheduled tasks generally perform batch operations, which are multiple tasks, while delayed tasks are generally single tasks
Next, let's take judging whether the order times out as an example to analyze the scheme
Scheme analysis
(1) Database polling
thinking
This scheme is usually used in small projects, that is, a thread scans the database regularly, judges whether there are overtime orders through the order time, and then performs operations such as update or delete
realization
The blogger used quartz in the early years of that year (about the internship meeting). Briefly introduce the maven project and introduce a dependency, as shown below
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.2.2</version>
</dependency>
Call Demo class MyJob as follows
package com.rjzheng.delay1;
import org.quartz.JobBuilder;
import org.quartz.JobDetail;
import org.quartz.Scheduler;
import org.quartz.SchedulerException;
import org.quartz.SchedulerFactory;
import org.quartz.SimpleScheduleBuilder;
import org.quartz.Trigger;
import org.quartz.TriggerBuilder;
import org.quartz.impl.StdSchedulerFactory;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
public class MyJob implements Job {
public void execute(JobExecutionContext context)
throws JobExecutionException {
System.out.println("I'm going to scan the database...");
}
public static void main(String[] args) throws Exception {
// Create task
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
.withIdentity("job1", "group1").build();
// The create trigger is executed every 3 seconds
Trigger trigger = TriggerBuilder
.newTrigger()
.withIdentity("trigger1", "group3")
.withSchedule(
SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(3).repeatForever())
.build();
Scheduler scheduler = new StdSchedulerFactory().getScheduler();
// Put the task and its trigger into the scheduler
scheduler.scheduleJob(jobDetail, trigger);
// The scheduler starts scheduling tasks
scheduler.start();
}
}
Run the code and find that the output is as follows every 3 seconds
I'm going to scan the database...
Advantages and disadvantages
Advantages: it is easy to operate and supports cluster operation
Disadvantages:
- (1) High memory consumption on the server
- (2) There is a delay. For example, if you scan every 3 minutes, the worst delay is 3 minutes
- (3) Suppose you have tens of millions of orders and scan them every few minutes, which will cause great loss of the database
(2) Delay queue for JDK
thinking
This scheme is implemented by using the DelayQueue of JDK, which is an unbounded blocking queue. The queue can get elements from it only when the delay expires. The objects put into the DelayQueue must implement the Delayed interface.
The workflow of DelayedQueue implementation is shown in the figure below
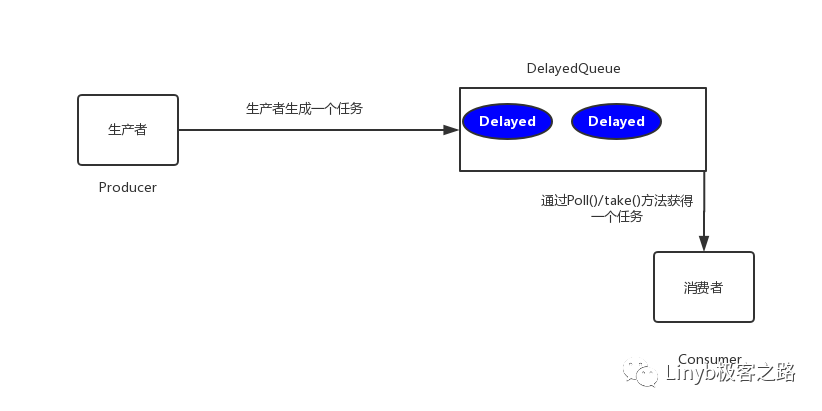
among
- poll(): get and remove the timeout element of the queue. If not, return null
- take(): get and remove the timeout element of the queue. If not, wait for the current thread until an element meets the timeout condition and return the result.
realization
Define a class OrderDelay to implement Delayed. The code is as follows
package com.rjzheng.delay2;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
public class OrderDelay implements Delayed {
private String orderId;
private long timeout;
OrderDelay(String orderId, long timeout) {
this.orderId = orderId;
this.timeout = timeout + System.nanoTime();
}
public int compareTo(Delayed other) {
if (other == this)
return 0;
OrderDelay t = (OrderDelay) other;
long d = (getDelay(TimeUnit.NANOSECONDS) - t
.getDelay(TimeUnit.NANOSECONDS));
return (d == 0) ? 0 : ((d < 0) ? -1 : 1);
}
// Returns how much time is left before your custom timeout
public long getDelay(TimeUnit unit) {
return unit.convert(timeout - System.nanoTime(), TimeUnit.NANOSECONDS);
}
void print() {
System.out.println(orderId+"The order number is to be deleted....");
}
}
The running test Demo is, and we set the delay time to 3 seconds
package com.rjzheng.delay2;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.DelayQueue;
import java.util.concurrent.TimeUnit;
public class DelayQueueDemo {
public static void main(String[] args) {
// TODO Auto-generated method stub
List<String> list = new ArrayList<String>();
list.add("00000001");
list.add("00000002");
list.add("00000003");
list.add("00000004");
list.add("00000005");
DelayQueue<OrderDelay> queue = new DelayQueue<OrderDelay>();
long start = System.currentTimeMillis();
for(int i = 0;i<5;i++){
//Take out with three seconds delay
queue.put(new OrderDelay(list.get(i),
TimeUnit.NANOSECONDS.convert(3, TimeUnit.SECONDS)));
try {
queue.take().print();
System.out.println("After " +
(System.currentTimeMillis()-start) + " MilliSeconds");
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
The output is as follows
00000001 The order number is to be deleted.... After 3003 MilliSeconds 00000002 The order number is to be deleted.... After 6006 MilliSeconds 00000003 The order number is to be deleted.... After 9006 MilliSeconds 00000004 The order number is to be deleted.... After 12008 MilliSeconds 00000005 The order number is to be deleted.... After 15009 MilliSeconds
It can be seen that the delay is 3 seconds and the order is deleted
Advantages and disadvantages
Advantages: high efficiency and low task trigger time delay. Disadvantages: (1) after the server restarts, all the data disappears for fear of downtime; (2) cluster expansion is quite troublesome; (3) due to memory constraints, such as too many unpaid orders, it is easy to have OOM exceptions; (4) the code complexity is high
(3) Time wheel algorithm
thinking
Let's start with a picture of the time wheel (this picture is everywhere)
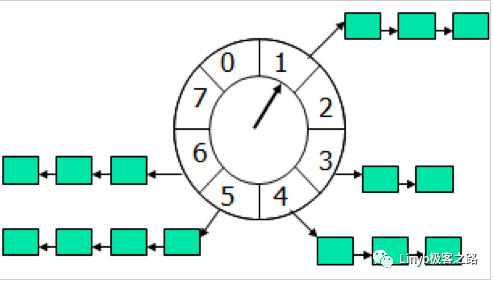
The time wheel algorithm can be similar to a clock, As shown in the figure above, the arrow (pointer) rotates at a fixed frequency in a certain direction, and each jump is called a tick. In this way, it can be seen that the timing wheel consists of three important attribute parameters, tickesperwheel (number of ticks in a round), tickeduration (duration of a tick) and timeUnit (time unit), for example, when tickesperwheel = 60, tickeduration = 1, timeUnit = seconds, this is exactly similar to the constant second hand walking in reality.
If the current pointer is above 1 and I have a task that needs to be executed in 4 seconds, the thread callback or message will be placed on 5. What if it needs to be executed after 20 seconds? Because the number of slots in this ring structure is only 8, if it takes 20 seconds, the pointer needs to rotate 2 more turns. Position is above 5 after 2 turns (20% 8 + 1)
realization
We use Netty's HashedWheelTimer to implement Pom and add the following dependencies
<dependency> <groupId>io.netty</groupId> <artifactId>netty-all</artifactId> <version>4.1.24.Final</version> </dependency>
The test code HashedWheelTimerTest is shown below
package com.rjzheng.delay3;
import io.netty.util.HashedWheelTimer;
import io.netty.util.Timeout;
import io.netty.util.Timer;
import io.netty.util.TimerTask;
import java.util.concurrent.TimeUnit;
public class HashedWheelTimerTest {
static class MyTimerTask implements TimerTask{
boolean flag;
public MyTimerTask(boolean flag){
this.flag = flag;
}
public void run(Timeout timeout) throws Exception {
// TODO Auto-generated method stub
System.out.println("I'm going to delete the order in the database....");
this.flag =false;
}
}
public static void main(String[] argv) {
MyTimerTask timerTask = new MyTimerTask(true);
Timer timer = new HashedWheelTimer();
timer.newTimeout(timerTask, 5, TimeUnit.SECONDS);
int i = 1;
while(timerTask.flag){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(i+"Seconds have passed");
i++;
}
}
}
The output is as follows
1 Seconds have passed 2 Seconds have passed 3 Seconds have passed 4 Seconds have passed 5 Seconds have passed I'm going to delete the order in the database.... 6 Seconds have passed
Advantages and disadvantages
Advantages: high efficiency, lower task trigger time delay time than delayQueue, and lower code complexity than delayQueue.
Disadvantages:
- (1) After the server restarts, all data disappears for fear of downtime
- (2) Cluster expansion is quite troublesome
- (3) Due to memory constraints, such as too many unpaid orders, OOM exceptions are easy to occur
(4)redis cache
Train of thought I
Using the Zset of redis, Zset is an ordered set. Each element (member) is associated with a score, and the values in the set are obtained through score sorting
zset common commands
- Add element: ZADD key score member [[score member] [score member]...]
- Query elements in order: zrange key start stop [with scores]
- Query element score:ZSCORE key member
- Remove element: ZREM key member [member...]
The tests are as follows
> Recommend your own Spring Cloud Practical projects: > > <https://github.com/YunaiV/onemall> # Add a single element redis> ZADD page_rank 10 google.com (integer) 1 # Add multiple elements redis> ZADD page_rank 9 baidu.com 8 bing.com (integer) 2 redis> ZRANGE page_rank 0 -1 WITHSCORES 1) "bing.com" 2) "8" 3) "baidu.com" 4) "9" 5) "google.com" 6) "10" # The score value of the query element redis> ZSCORE page_rank bing.com "8" # Remove a single element redis> ZREM page_rank google.com (integer) 1 redis> ZRANGE page_rank 0 -1 WITHSCORES 1) "bing.com" 2) "8" 3) "baidu.com" 4) "9"
So how to achieve it? We set the order timeout timestamp and order number as score and member respectively, and the system scans the first element to determine whether the timeout occurs, as shown in the following figure
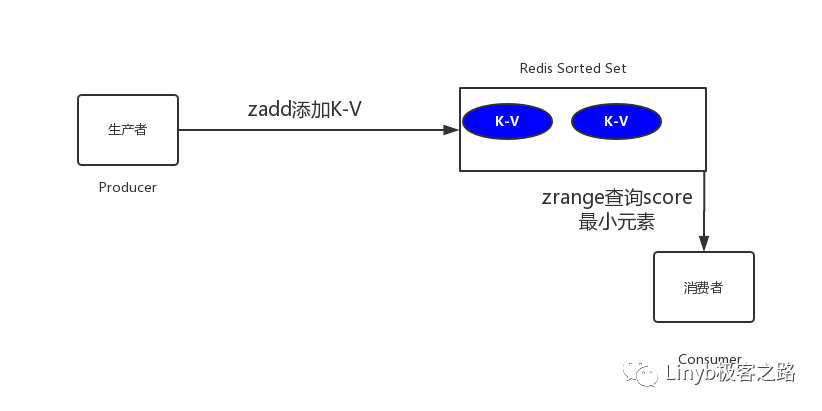
Realize one
package com.rjzheng.delay4;
import java.util.Calendar;
import java.util.Set;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.Tuple;
public class AppTest {
private static final String ADDR = "127.0.0.1";
private static final int PORT = 6379;
private static JedisPool jedisPool = new JedisPool(ADDR, PORT);
public static Jedis getJedis() {
return jedisPool.getResource();
}
//Producer, generate 5 orders and put them in
public void productionDelayMessage(){
for(int i=0;i<5;i++){
//Delay 3 seconds
Calendar cal1 = Calendar.getInstance();
cal1.add(Calendar.SECOND, 3);
int second3later = (int) (cal1.getTimeInMillis() / 1000);
AppTest.getJedis().zadd("OrderId", second3later,"OID0000001"+i);
System.out.println(System.currentTimeMillis()+"ms:redis An order task was generated: ID by"+"OID0000001"+i);
}
}
//Consumer, take order
public void consumerDelayMessage(){
Jedis jedis = AppTest.getJedis();
while(true){
Set<Tuple> items = jedis.zrangeWithScores("OrderId", 0, 1);
if(items == null || items.isEmpty()){
System.out.println("There are currently no tasks waiting");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
continue;
}
int score = (int) ((Tuple)items.toArray()[0]).getScore();
Calendar cal = Calendar.getInstance();
int nowSecond = (int) (cal.getTimeInMillis() / 1000);
if(nowSecond >= score){
String orderId = ((Tuple)items.toArray()[0]).getElement();
jedis.zrem("OrderId", orderId);
System.out.println(System.currentTimeMillis() +"ms:redis Consume a task: consume orders OrderId by"+orderId);
}
}
}
public static void main(String[] args) {
AppTest appTest =new AppTest();
appTest.productionDelayMessage();
appTest.consumerDelayMessage();
}
}
At this time, the corresponding output is as follows
1525086085261ms:redis An order task was generated: ID by OID00000010 1525086085263ms:redis An order task was generated: ID by OID00000011 1525086085266ms:redis An order task was generated: ID by OID00000012 1525086085268ms:redis An order task was generated: ID by OID00000013 1525086085270ms:redis An order task was generated: ID by OID00000014 1525086088000ms:redis Consume a task: consume orders OrderId by OID00000010 1525086088001ms:redis Consume a task: consume orders OrderId by OID00000011 1525086088002ms:redis Consume a task: consume orders OrderId by OID00000012 1525086088003ms:redis Consume a task: consume orders OrderId by OID00000013 1525086088004ms:redis Consume a task: consume orders OrderId by OID00000014 There are currently no tasks waiting There are currently no tasks waiting There are currently no tasks waiting
You can see that almost all of them are consumer orders after 3 seconds.
However, there is a fatal flaw in this version. Under the condition of high concurrency, multiple consumers will get the same order number. We tested the code ThreadTest on
package com.rjzheng.delay4;
import java.util.concurrent.CountDownLatch;
public class ThreadTest {
private static final int threadNum = 10;
private static CountDownLatch cdl = new CountDownLatch(threadNum);
static class DelayMessage implements Runnable{
public void run() {
try {
cdl.await();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
AppTest appTest =new AppTest();
appTest.consumerDelayMessage();
}
}
public static void main(String[] args) {
AppTest appTest =new AppTest();
appTest.productionDelayMessage();
for(int i=0;i<threadNum;i++){
new Thread(new DelayMessage()).start();
cdl.countDown();
}
}
}
The output is shown below
1525087157727ms:redis An order task was generated: ID by OID00000010 1525087157734ms:redis An order task was generated: ID by OID00000011 1525087157738ms:redis An order task was generated: ID by OID00000012 1525087157747ms:redis An order task was generated: ID by OID00000013 1525087157753ms:redis An order task was generated: ID by OID00000014 1525087160009ms:redis Consume a task: consume orders OrderId by OID00000010 1525087160011ms:redis Consume a task: consume orders OrderId by OID00000010 1525087160012ms:redis Consume a task: consume orders OrderId by OID00000010 1525087160022ms:redis Consume a task: consume orders OrderId by OID00000011 1525087160023ms:redis Consume a task: consume orders OrderId by OID00000011 1525087160029ms:redis Consume a task: consume orders OrderId by OID00000011 1525087160038ms:redis Consume a task: consume orders OrderId by OID00000012 1525087160045ms:redis Consume a task: consume orders OrderId by OID00000012 1525087160048ms:redis Consume a task: consume orders OrderId by OID00000012 1525087160053ms:redis Consume a task: consume orders OrderId by OID00000013 1525087160064ms:redis Consume a task: consume orders OrderId by OID00000013 1525087160065ms:redis Consume a task: consume orders OrderId by OID00000014 1525087160069ms:redis Consume a task: consume orders OrderId by OID00000014 There are currently no tasks waiting There are currently no tasks waiting There are currently no tasks waiting There are currently no tasks waiting
Obviously, multiple threads consume the same resource.
Solution
- (1) With distributed locks, but with distributed locks, the performance decreases. This scheme will not be described in detail.
- (2) Judge the return value of ZREM, and consume data only when it is greater than 0, so use the data in the consumerDelayMessage() method
if(nowSecond >= score){
String orderId = ((Tuple)items.toArray()[0]).getElement();
jedis.zrem("OrderId", orderId);
System.out.println(System.currentTimeMillis()+"ms:redis Consume a task: consume orders OrderId by"+orderId);
}
Change to
if(nowSecond >= score){
String orderId = ((Tuple)items.toArray()[0]).getElement();
Long num = jedis.zrem("OrderId", orderId);
if( num != null && num>0){
System.out.println(System.currentTimeMillis()+"ms:redis Consume a task: consume orders OrderId by"+orderId);
}
}
After this modification, rerun the ThreadTest class and find that the output is normal
Train of thought II
This scheme uses redis's Keyspace Notifications. The Chinese translation is the key space mechanism, which can provide a callback after the key fails. In fact, redis will send a message to the client. Yes, redis version 2.8 or above is required.
Implementation II
On redis Conf, add a configuration
notify-keyspace-events Ex
The operation code is as follows
package com.rjzheng.delay5;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPubSub;
public class RedisTest {
private static final String ADDR = "127.0.0.1";
private static final int PORT = 6379;
private static JedisPool jedis = new JedisPool(ADDR, PORT);
private static RedisSub sub = new RedisSub();
public static void init() {
new Thread(new Runnable() {
public void run() {
jedis.getResource().subscribe(sub, "__keyevent@0__:expired");
}
}).start();
}
public static void main(String[] args) throws InterruptedException {
init();
for(int i =0;i<10;i++){
String orderId = "OID000000"+i;
jedis.getResource().setex(orderId, 3, orderId);
System.out.println(System.currentTimeMillis()+"ms:"+orderId+"Order generation");
}
}
static class RedisSub extends JedisPubSub {
@Override
public void onMessage(String channel, String message) {
System.out.println(System.currentTimeMillis()+"ms:"+message+"Order cancellation");
}
}
}
The output is as follows
1525096202813ms:OID0000000 Order generation 1525096202818ms:OID0000001 Order generation 1525096202824ms:OID0000002 Order generation 1525096202826ms:OID0000003 Order generation 1525096202830ms:OID0000004 Order generation 1525096202834ms:OID0000005 Order generation 1525096202839ms:OID0000006 Order generation 1525096205819ms:OID0000000 Order cancellation 1525096205920ms:OID0000005 Order cancellation 1525096205920ms:OID0000004 Order cancellation 1525096205920ms:OID0000001 Order cancellation 1525096205920ms:OID0000003 Order cancellation 1525096205920ms:OID0000006 Order cancellation 1525096205920ms:OID0000002 Order cancellation
It is obvious that the order was cancelled after 3 seconds
PS: the pub/sub mechanism of redis has a hard injury. The official website is as follows
Original: Because Redis Pub/Sub is fire and forget currently there is no way to use this feature if your application demands reliable notification of events, that is, if your Pub/Sub client disconnects, and reconnects later, all the events delivered during the time the client was disconnected are lost
Redis's publish / subscribe mode is fire and forget at present, so reliable notification of events cannot be realized. That is, if the publish / subscribe client is disconnected and reconnected, all events during the client disconnection are lost. Therefore, option 2 is not recommended. Of course, if you don't require high reliability, you can use it.
Advantages and disadvantages
advantage:
- (1) Because Redis is used as the message channel, all messages are stored in Redis. If the sender or task handler hangs, it is possible to reprocess the data after restarting.
- (2) Cluster expansion is quite convenient
- (3) High time accuracy
Disadvantages: (1) additional redis maintenance is required
(5) Using message queuing
We can use rabbitmq's delay queue. Rabbitmq has the following two features to implement delay queues
- RabbitMQ can set x-message-tt for Queue and Message to control the Message lifetime. If it times out, the Message becomes dead letter
- lRabbitMQ's Queue can be configured with x-dead-letter-exchange and x-dead-letter-routing-key (optional) parameters to control the rerouting of deadletter s in the Queue according to these two parameters. Combined with the above two characteristics, the function of delayed messages can be simulated. Specifically, I'll write another article another day. It's too long to talk about it here.
Advantages and disadvantages
Advantages: high efficiency, easy horizontal expansion by using the distributed characteristics of rabbitMq, message persistence support and increased reliability. Disadvantages: its ease of use depends on rabbitMq's operation and maintenance Because rabbitMq is referenced, the complexity and cost become higher
summary
This paper summarizes the implementation schemes of most delayed tasks in the Internet. I hope you can gain something from your work.
In fact, 90% of people still focus on business logic in their work, and there are few opportunities for scheme design. Therefore, bloggers do not recommend spending too much time in distributed. However, in view of the fact that the interview is making rockets and the screw tightening phenomenon is too serious, finally, let's have a little cartoon for entertainment.

Author: lonely smoke Source: http://rjzheng.cnblogs.com/