Introduction: ※ the classical LeNet deep learning network can complete the requirements of Intelligent Vision Group for the classification of moving items in smart car competition. Although there will be five vehicles in the actual competition, the identification and positioning of small categories can still be completed by using LeNet. Only using the standard database training samples can not meet the actual requirements. Later, we need to further increase the database to make the model adapt to the image data collected in the actual environment; Further simplify the network parameters of LeNet. After all, the modified model needs to be deployed in NXP MCU in the future. Too large neural network will reduce the recognition speed of MCU.
Key words: MNIST, NXP, smart car competition
§ 01 faMNIST picture library
1.1 background
in AI vision group of the 16th National College Student smart car competition In, the car model is required to complete the digital, Apriltag Identification of animals (five kinds) and fruits (five kinds). In the new smart car competition, it is required to identify the subclasses of animals and fruits (10 kinds in total), that is, which animals (cattle, dogs, pigs, cats, horses) and fruits (durian, orange, apple, grape and banana) are classified. As for In subclass The subdivision of is no longer required.


1.2 three "MNIST" data sets
1.2.1 MNIST
in deep learning, MNIST data set It is a basic picture set and a "Hello World" data set for pattern recognition and deep learning. Can be in YANN.LECUN : http://yann.lecun.com/exdb/mnist/ Website access. It includes training and testing samples, with a total of 60000.

1.2.2 Fashion-MNIST
Fashion-MNIST Is an alternative MNIST handwritten numeral set Image data set. It is provided by the research department of Zalando, a German fashion technology company. It covers front images of 70000 different products from 10 categories.
the size, format and division of training set / test set of FashionMNIST are completely consistent with the original MNIST. 60000 / 10000 training test data division, 28x28 gray images. You can directly use it to test the performance of your machine learning and deep learning algorithms without changing any code.

1.2.3 faMNIST
in AI visual component data set of the 16th intelligent automobile competition Contains 906 283 × The data set of 283 color animals and fruits was originally used for the training set of embedded recognition of Intelligent Vision Group in intelligent vehicle competition LeNet classifies fruits and animals The converted idiom has the same size format as MNIST. This can be used for beginners of neural network to learn the test set of CNN.
faMNIST10 picture library: Category: 10 categoriesColor: grayscale
Size: 32 × thirty-two
below are some picture samples in faMNIST10.

in Propeller AI Studio - artificial intelligence learning and training community : https://aistudio.baidu.com/aistudio/datasetdetail/121924 You can download the modified data set. There are five directories:
├─famnist-all : 283 × 283 color pictures
├─famnist10 : 32 × 32 color pictures
├─famnist10-64 : 64 × 64 color pictures
├─famnist10-64-gray : 64 × 64 grayscale picture
└─famnist10-gray : 32 × 32 grayscale picture
this collection will be gradually enriched with the collection of smart car competition students.
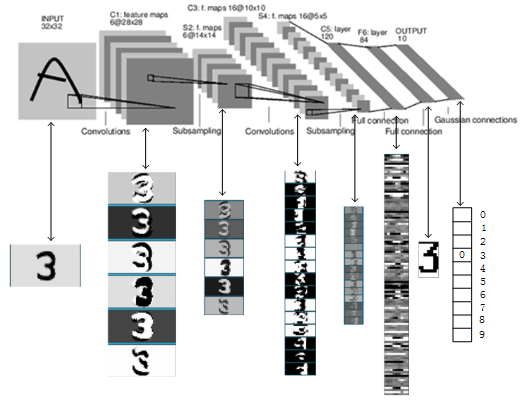
§ 02 LeNet network
2.1 background
LeNet neural network Proposed by Yan LeCun, one of the three giants of deep learning, who is also the father of convolutional neural networks (CNN). LeNet is mainly used for handwritten character recognition and classification, and has been used in American banks.
the implementation of LeNet establishes the structure of CNN. Now many contents in neural network can be seen in the network structure of LeNet, such as convolution layer, Pooling layer and ReLU layer. Although LeNet was put forward as early as the 1990s, due to the lack of large-scale training data and the low performance of computer hardware, the effect of LeNet neural network in dealing with complex problems is not ideal. Although the structure of LeNet network is relatively simple, it is just suitable for the introduction of neural network.
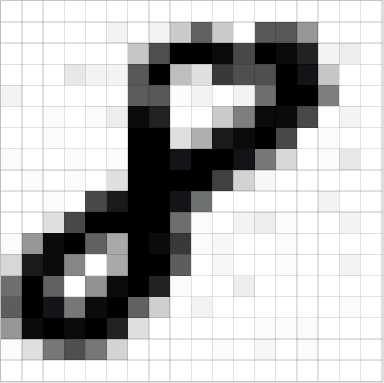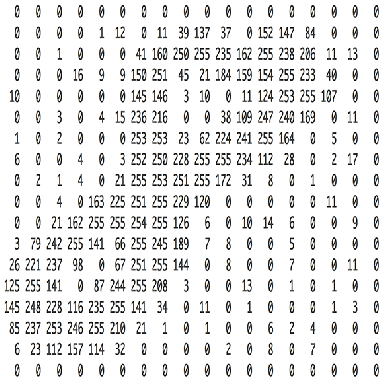
2.2 picture classification
whether handwritten characters or ordinary pictures, there is a matrix composed of numbers in the computer. Similarly, CNN networks can also be classified. Let's use LeNet to classify faMNIST data sets.
The classification environment is based on Baidu's PaddlePaddle. AI Studio , using AI Studio, you don't need to install a complex deep learning environment on your own computer. As long as the computer can be connected to the Internet, you can complete the construction and training of deep learning network at any access point. Baidu It is the third consecutive year to sponsor the national college student smart car competition In addition, free training and calculation cards help students inject more artificial intelligence into car model works.
2.2. 1 read in image data
read the gray image data from the subdirectory / home / Studio / data / famnist / famnist10 gray, and generate the label of the image according to the file name. The number corresponding to the first letter of the file name corresponds to animals and fruits. See the following python dictionary.
afname = {'cat':0, 'cow':1, 'dog':2, 'horse':3, 'pig':4,
'apple':5, 'banana':6, 'durian':7, 'grape':8, 'orange':9}
import cv2
import paddle
import paddle.nn.functional as F
from paddle import to_tensor as TT
from paddle.nn.functional import square_error_cost as sqrc
famnist = '/home/aistudio/data/famnist'
imgdir = 'famnist10-gray'
#------------------------------------------------------------
def loadimgdata(imgdir):
'''
loadimgdata: Load test image data into RAM
Param imgdir: Directory for storing the image picture .
Return: imgdata,imglabel
'''
imgfile = os.listdir(imgdir)
imgdata = []
imglabel = []
for f in imgfile:
img = cv2.imread(os.path.join(imgdir, f))
imgdata.append(img.T[0][newaxis,:])
imglabel.append(int(f[:1]))
return array(imgdata), array(imglabel)
imgdata,imglabel = loadimgdata(os.path.join(famnist,imgdir))
2.2. 2. Build training data loading function
in order to train the network later, build the following data loading function according to the description of the paddle technical document. It essentially needs to overload the following two functions:
- getitem: returns the image data and corresponding label in the following table specified by the parameter index. The data types are Tensor('float32 ') and Tensor('int64').
- len: returns the total number of training data.
class famnist(paddle.io.Dataset):
def __init__(self, num_samples):
super(famnist, self).__init__()
self.num_samples = num_samples
def __getitem__(self, index):
data = imgdata[index]/255
label = imglabel[index]
return TT(data, dtype='float32'), TT(label, dtype='int64')
def __len__(self):
return self.num_samples
_dataset = famnist(len(imglabel))
train_loader = paddle.io.DataLoader(_dataset, batch_size=100, shuffle=True)
eventually there is a pad io. The dataloader function is encapsulated to provide batch training data blocks and random scrambling of data.
2.2. 3. Building LeNet network
imageSize = 32
ks = 5
in_channel=1
L = ((imageSize-ks+1)//2-ks+1)//2
class mnist(paddle.nn.Layer):
def __init__(self, ):
super(mnist, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=in_channel, out_channels=6, kernel_size=ks, stride=1, padding=0)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=ks, stride=1, padding=0)
self.mp1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.mp2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.L1 = paddle.nn.Linear(in_features=16*L*L, out_features=120)
self.L2 = paddle.nn.Linear(in_features=120, out_features=86)
self.L3 = paddle.nn.Linear(in_features=86, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.mp1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.mp2(x)
x = paddle.flatten(x, start_axis=1, stop_axis=-1)
x = self.L1(x)
x = F.relu(x)
x = self.L2(x)
x = F.relu(x)
x = self.L3(x)
return x
this is the standard LeNet network structure. It is composed of two convolution Pooling layers and three fully connected layers. The convolution kernel size is 5.
the following is by paddle The basic network parameters given by the summary() function.
--------------------------------------------------------------------------- Layer (type) Input Shape Output Shape Param # =========================================================================== Conv2D-7 [[100, 1, 32, 32]] [100, 6, 28, 28] 156 MaxPool2D-7 [[100, 6, 28, 28]] [100, 6, 14, 14] 0 Conv2D-8 [[100, 6, 14, 14]] [100, 16, 10, 10] 2,416 MaxPool2D-8 [[100, 16, 10, 10]] [100, 16, 5, 5] 0 Linear-10 [[100, 400]] [100, 120] 48,120 Linear-11 [[100, 120]] [100, 86] 10,406 Linear-12 [[100, 86]] [100, 10] 870 =========================================================================== Total params: 61,968 Trainable params: 61,968 Non-trainable params: 0 --------------------------------------------------------------------------- Input size (MB): 0.39 Forward/backward pass size (MB): 6.18 Params size (MB): 0.24 Estimated Total Size (MB): 6.80 ---------------------------------------------------------------------------
the operation parameters of the network can be determined by pad The flops function is given. The following table shows the calculation amount of each layer when the convolution kernel size is 5. It can be seen that the convolution operation of the first two layers accounts for 86% of the total network operation. Reducing convolution operation is the key to improve the network speed.
+--------------+-------------------+-------------------+--------+----------+ | Layer Name | Input Shape | Output Shape | Params | Flops | +--------------+-------------------+-------------------+--------+----------+ | conv2d_6 | [100, 1, 32, 32] | [100, 6, 28, 28] | 156 | 12230400 | | conv2d_7 | [100, 6, 14, 14] | [100, 16, 10, 10] | 2416 | 24160000 | | max_pool2d_6 | [100, 6, 28, 28] | [100, 6, 14, 14] | 0 | 0 | | max_pool2d_7 | [100, 16, 10, 10] | [100, 16, 5, 5] | 0 | 0 | | linear_9 | [100, 400] | [100, 120] | 48120 | 4800000 | | linear_10 | [100, 120] | [100, 86] | 10406 | 1032000 | | linear_11 | [100, 86] | [100, 10] | 870 | 86000 | +--------------+-------------------+-------------------+--------+----------+ Total Flops: 42308400 Total Params: 61968
paddle.summary(net, input_size=(100,in_channel,imageSize,imageSize)) paddle.flops(net, input_size=(100, in_channel, imageSize, imageSize), print_detail=True)
2.2. 4 network training
the following is a 100 cycle training of the network.
net = mnist()
EPOCH_NUM = 100
optimizer = paddle.optimizer.Adam(learning_rate=0.01, parameters=net.parameters())
for epoch in range(EPOCH_NUM):
for batchid, data in enumerate(train_loader()):
out = net(data[0])
loss = F.cross_entropy(out, data[1])
acc = paddle.metric.accuracy(out, data[1])
loss.backward()
optimizer.step()
optimizer.clear_grad()
if batchid %100==0:
print("Pass:{}, Loss:{}, Acc:{}".format(epoch,loss.numpy(), acc.numpy()))
the loss function and classification accuracy change curve of the network during training are shown in the figure below. It can be seen that after 30 cycles of training, the network basically achieves 100% recognition performance.
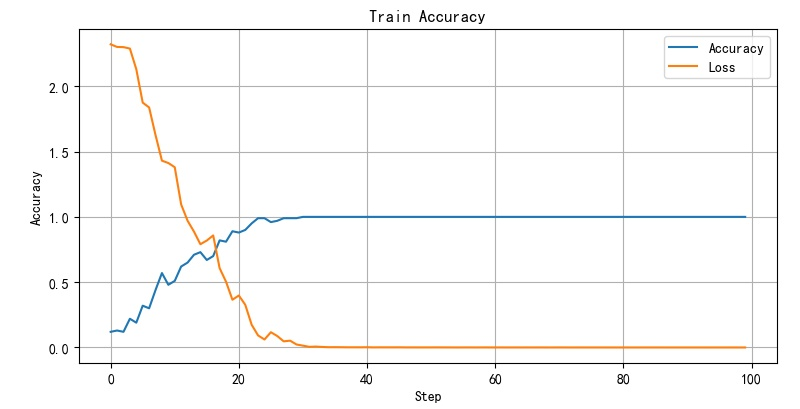
2.3 training comparison
as a simple CNN, LeNet has limited classification ability for complex problems. But for faMNIST data set, it still has strong recognition performance.
2.3. 1 convolution kernel size
in Ten animals and fruits in FAMNIST were identified The classification effects of different convolution kernel sizes on faMNIST data sets are compared. Except that the convolution kernel cannot be 1, the convolution kernel of other sizes has little effect on the recognition ability. The smaller the size of convolution kernel, the smaller the amount of computation of the network.
the following shows the convergence of network training when the size of convolution kernel is 2 and 7, and there is little difference between the two cases.
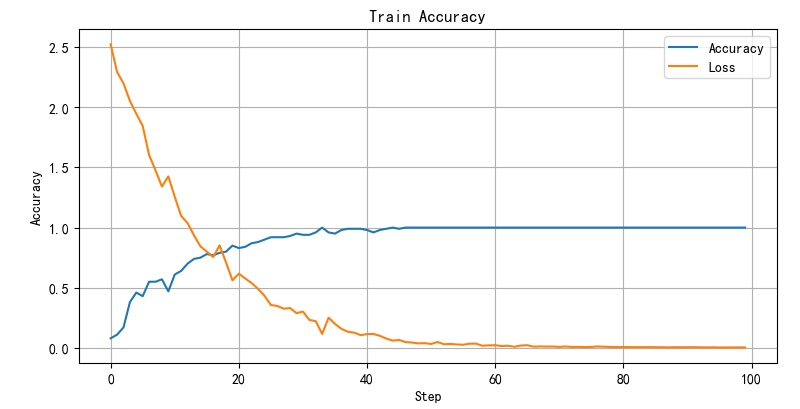
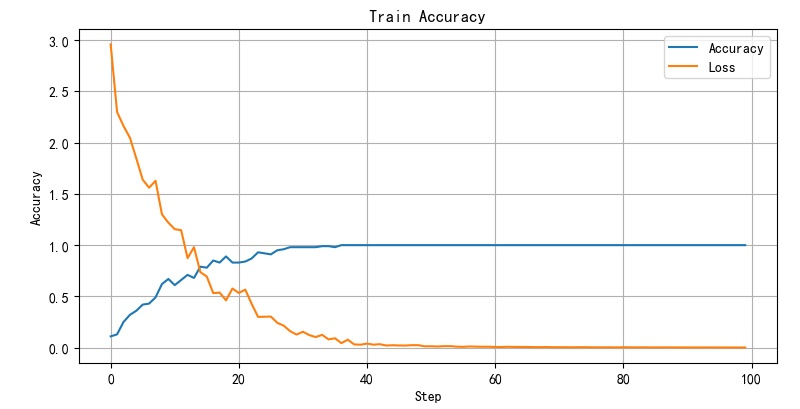
2.3. 2 learning rate
learning rate is the super parameters in the process of network training. On the training set of LeNet for faMNIST, the learning rate lr can make the network converge quickly when it is less than 0.05. Moreover, the larger lr, the faster the network converges.
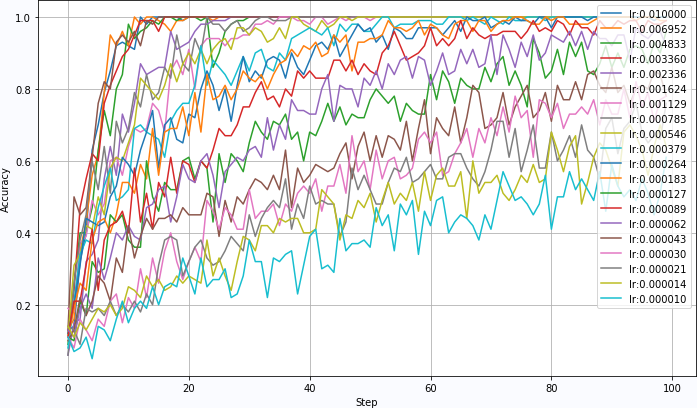
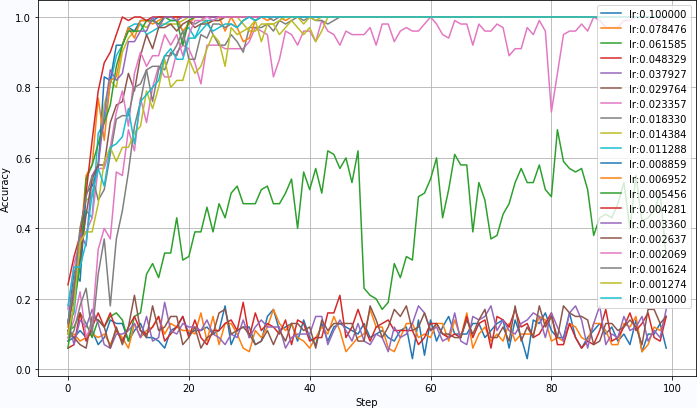
once the learning rate exceeds 0.05, the network training will not converge. The accuracy of network recognition has been very low.
2.3. 3 different training sets
LeNet network can well classify different specifications in faMNIST 5, whether black-and-white or color pictures, regardless of size 32 × 32 or 64 × 64. The recognition effect is similar. Even for the original 283 × 283 can also be well identified.
the main reasons for this are:
- The quality of the picture is relatively good and has not been affected by the actual ambient light;
- The number of samples is relatively small;
because in order to make the training model adapt to the image recognition collected in different environments, different perspectives and different distances in the future, it is necessary to expand the training set through certain data enhancement methods.
※ identification summary ※
using the classic LeNet deep learning network, we can complete the requirements of Intelligent Vision Group for the classification of moving items in intelligent vehicle competition. Although there will be five vehicles in the actual competition, the identification and positioning of small categories can still be completed by using LeNet.
only using the standard database training samples can not meet the actual requirements. Later, it is also necessary to:
- Further increase the database, so that the model can adapt to the image data collected in the actual environment;
- Further simplify the network parameters of LeNet. After all, the modified model needs to be deployed in NXP MCU in the future. Too large neural network will reduce the recognition speed of MCU.
■ links to relevant literature:
- Release of AI visual component data set of the 16th smart car competition
- How many of these animals do you know
- MNIST data set
- YANN.LECUN
- Fashion-MNIST
- MNIST handwritten numeral set
- The fourth assignment of artificial neural network in 2021 - question 1: LeNet classification of fruits and animals
- Propeller AI Studio - artificial intelligence learning and training community
- LeNet neural network
- Install PaddlePaddle - Install Guide
- Creative group of the 17th National College Student intelligent car competition - Baidu intelligent transportation "Silk Road" competition rules
- Ten animals and fruits in FAMNIST were identified
● relevant chart links:
- Figure 1.1 1 animals and fruits in Intelligent Vision Group
- Figure 1.1 image task recognition of intelligent vehicle model
- Figure 1.2 1 MNIST database
- Figure 1.2 2. Fashion MNIST data set
- Figure 1.2 3. Some picture samples in famnist10 gray
- Figure 2.1 1. Net neural network structure
- Figure 2.1 2 handwritten character data
- Figure 2.2 1. Convergence of lenet in faMNIST training
- Figure 2.3 1 training convergence curve corresponding to convolution kernel size 2
- Figure 2.3 2 training convergence curve corresponding to convolution kernel size 7
- Figure 2.3 3 network convergence corresponding to different learning rates
- Figure 2.3 4 the convergence of the network will suddenly change with the learning rate greater than 0.05