Ten thousand fans, I climbed all my fans, just to verify one thing
preface
The growth of fans and visits to CSDN blog sites is a very strange thing.
If you don't blog, there will be almost no growth in fans. One or two days after you post a blog with a sufficient number of words, there will be a sudden change in the number of fans and visits, and then there will be zero growth again. You think these mutations are caused by your single blog post, but I observed that this article has almost no traffic. Will this article increase the traffic of other articles? Weird!
Once every n fans were added, k people interacted with you. However, the 100N fans recommended by station C are not enough k to interact with you. Does not conform to the law of large numbers. Fans are weird!
The original daily reading volume was s. suddenly one day, the reading volume suddenly became less than S/2. This mutation is not in line with the natural market law under the background of the Internet. It is very strange!
......
Based on the above bizarre events, I dare to make the following prediction:
-
Station C officially "made" a lot of machine zombie powder or directly used the semi zombie powder that the owner hasn't been on the number for a long time to stimulate bloggers to actively send articles, long articles and high-quality articles. The actual amount of attention is not as high as the data, and the official magnified the value. Stimulated by the so-called "hot list", "fans" and other vanity, everyone rolled up. Of course, most popular bloggers rely on love to generate electricity and don't care much about it. There are also many people who are happy to pursue it. This is exactly what station C officials want to see. The almost free labor force is right in the heart.
-
The official daily reading volume and other data are artificially controllable by the official of station C and can be subjective rather than objective access. That is, he wants your traffic to drop sharply. It's just a matter of modifying a parameter in the background. Of course, the modification is also based on the weight modification of objective data, not random. For each data of the blog, they have a threshhold parameter for each blogger to control the outflow of "water". There seems to be no correlation between the data.
-
The hot list algorithm, based on its own interests, has been modified. For example, the support for new people to send good articles and the cultivation of volume king.
The above ideas are pure speculation. If you are offended, please do not delete the text. A good enterprise can always stand criticism. Only in this way can it develop in a better direction. A narrow enterprise will always be wary of what others say.
Based on the above ideas, when the number of fans is tens of thousands, let's climb to get fans and make a wave analysis to see if they are "robot zombie powder".
Crawl the fans of station C and their traffic and number of fans
The code is relatively simple. I won't explain it. Just post it. Among them, several lines of code are referenced.
Climb all fans
# -*- coding: utf-8 -*-
import requests
import random
import json
import pandas as pd
from lxml import etree
import math
n = 10000;#It needs to be modified to the number of fans you want to crawl. The value should be less than your own number of fans
page_num = math.ceil(n/20);
uas = [
"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
]
ua = random.choice(uas)
headers = {
"user-agent": ua,
'cookie': 'UserName=lusongno1; UserInfo=f332fa86de644360b04f896a8a46f7d4; UserToken=f332fa86de644360b04f896a8a46f7d4;',
"referer": "https://blog.csdn.net/qing_gee?type=sub&subType=fans"
}
url_format = "https://blog.csdn.net/community/home-api/v1/get-fans-list?page={}&size=20&noMore=true&blogUsername=lusongno1"
dfs = pd.DataFrame();
for i in range(1,page_num+1):
print("get page:"+str(i))
url = url_format.format(i);
response = requests.get(url,headers=headers)
content = json.loads(response.text)
tmp=content.get("data")
data=tmp.get("list")
df=pd.DataFrame(data)
dfs = pd.concat([dfs,df],axis=0)
dfs = dfs.reset_index()
dfs.to_csv("fans.csv",encoding='utf_8_sig')#, index_label="index_label")
Get the basic information such as the number of visits of fans
dfs['visit'] = None
dfs['fans'] = None
dfs['original'] = None
dfs['Weekly ranking'] = None
dfs['Total ranking'] = None
for i in range(0,len(dfs)):
print("get fan:"+str(i))
link = dfs.iloc[i]['blogUrl']
res = requests.get(link,headers=headers)
html = res.text;
tree=etree.HTML(html)
yuanchuang = tree.xpath('//*[@id="asideProfile"]/div[2]/dl[1]/a/dt/span')
fangwen = tree.xpath('//*[@id="asideProfile"]/div[2]/dl[4]/dt/span')
fensi = tree.xpath('//*[@id="fan"]')
zhoupaiming = tree.xpath('//*[@id="asideProfile"]/div[2]/dl[2]/a/dt/span')
zongpaiming = tree.xpath('//*[@id="asideProfile"]/div[2]/dl[3]/a/dt/span')
yc = yuanchuang[0].text
fw = fangwen[0].text
fs = fensi[0].text
zpm = zhoupaiming[0].text
zongpm = zongpaiming[0].text
dfs.loc[i:i,('visit','fans','original','Weekly ranking','Total ranking')]=[fw,fs,yc,zpm,zongpm]
del dfs['userAvatar']
del dfs['briefIntroduction']
del dfs['index']
dfs.to_csv("myFans.csv",encoding='utf_8_sig')
Discussion on fans
After running the program, I climbed down two watches. A list includes the ID, nickname, avatar, blog link, cross-correlation, blog expert and personal signature of all fans. Another table contains the number of original articles, visits, number of fans, ranking, etc.
Basic information of fans
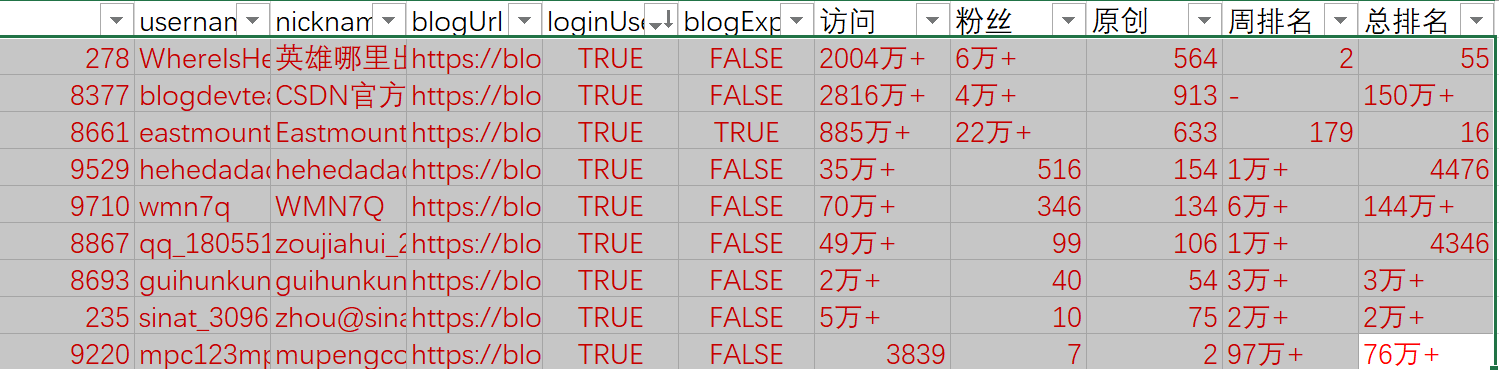
As can be seen from the fans, there are 9 people related to me. They are several of my graduate students, as well as front row bloggers such as Mr. Yang and brother hero, including CSDN's official blog. Among them, there are 4 + blog experts. They are teacher xiuzhang, brother Tianya, big cake and Xiaoxin. Because there are bug s in the results returned by get, many blog experts are marked as No. for example, brother Tianya, so I wrote 4 + here.
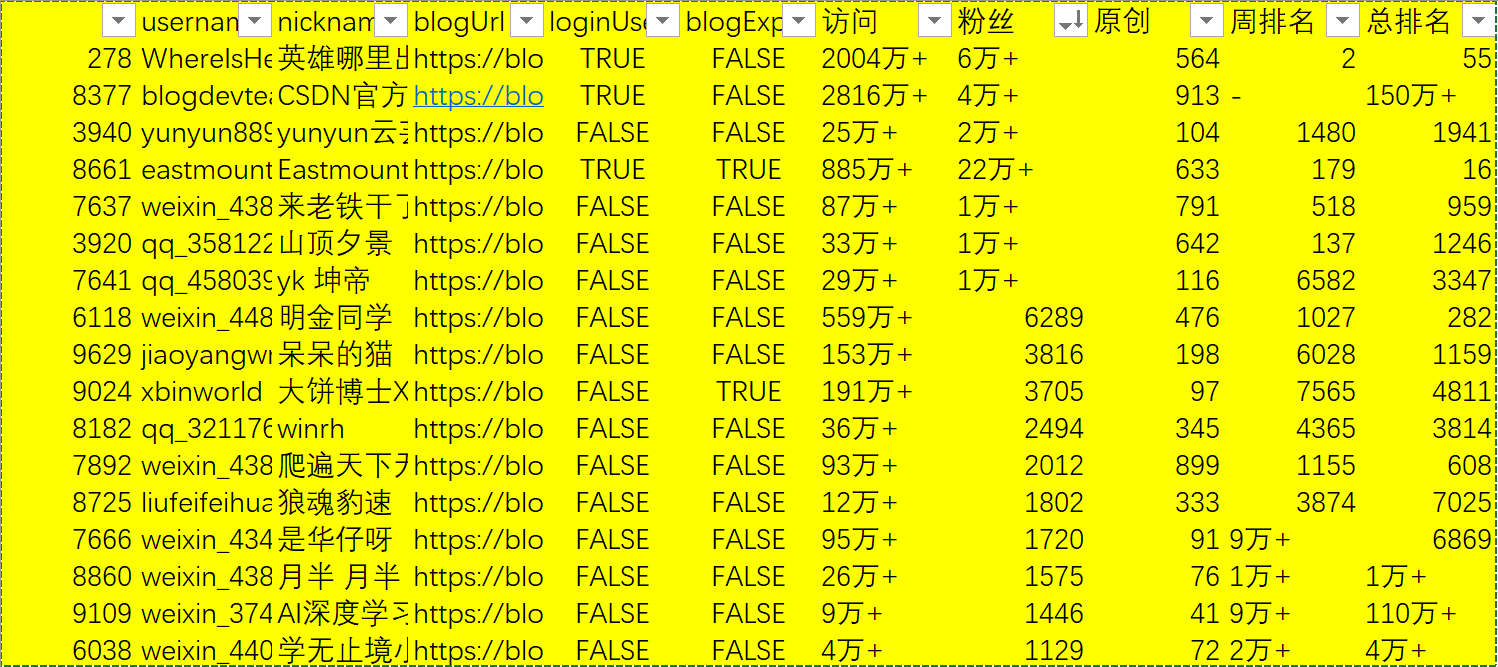
Among them, there are 17 fans with more than 1000 fans. The number of original articles reached 100, a total of 68 people.
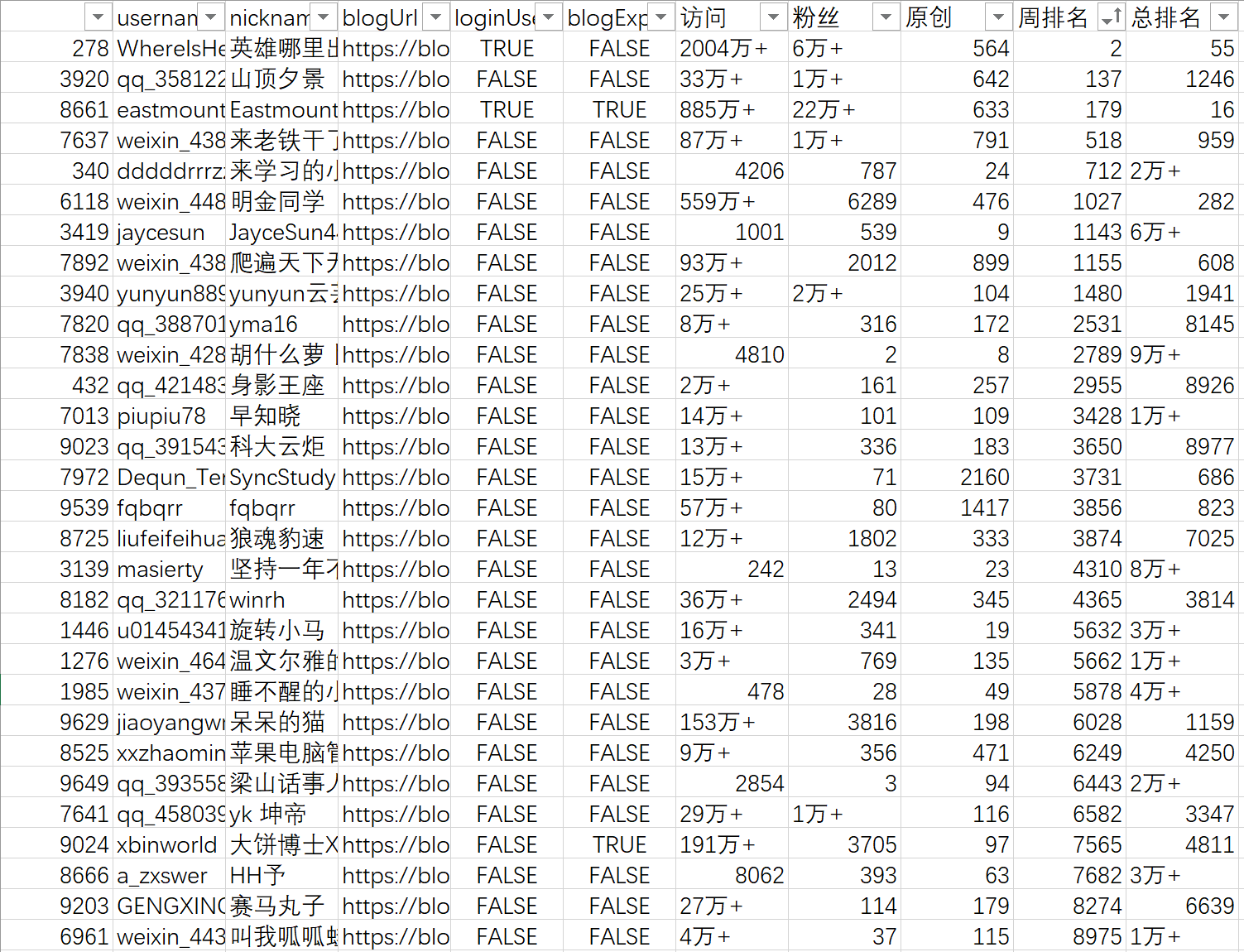
A total of 30 people ranked within 10000 in the week. 371 people visited more than 10000. There are 42 people with a total ranking of less than 10000.
Whether fans are zombie powder
Now the point is, are there any "zombie machine powder" among the 10000 fans that are officially recommended? How to distinguish? This is a little difficult. I have found many papers and no useful methods.
Second, I analyzed my fan data, but I still couldn't conclude that they were machine fans. It is mainly that the fans with zero access, zero fans, no articles and no ranking are too real after batch analysis, whether from avatar, ID or nickname. If it's random, I can't help it.
In line with the attitude of no doubt, I announce that station C did not use zombie powder to induce us to write articles. It's still the big brother we used to be.
Even so, the data of various dimensions of blog posts must be controlled by the government, rather than natural development. They are a company. They have a group of people to support and the server needs money. No matter what they do, even if they put a lot of advertisements, we should understand. Now that you have enjoyed your rights, you must perform certain obligations. There is no reason in the world to whore others without paying.
Python 3 web page capture basic template
Paste a basic template of climbing data for reference.
Differences and relations among urllib, urllib 2 and requests Libraries
- Urllib and urllib 2 are Python 2's own libraries, which complement each other.
- In Python 3, there is only urllib, but urllib 2 no longer exists. In Python 3, urllib and urllib 2 are merged. Now there is only one urllib module. The contents of urllib and urllib 2 are integrated into urllib.request, and urlparse is integrated into urllib.parse.
- Requests is a third-party library, and its slot is "requests is the only non GMO HTTP library for Python, safe for human consumption". Because urllib and urllib 2 are too messy, coding needs to be considered when using them.
- requests is a higher layer encapsulation of urllib, which is more convenient to use.
A basic framework used by requests
GET mode
import requests
stuID = "xxxxxxxxxxxxxxx"
url = "xxx"+stuID
r = requests.get(url)
# requests provides params keyword parameters to pass parameters
parameter = {
"key1":"value1",
"key2":"value2"
}
response = requests.get("http://httpbin.org/get",params = parameter)
print(response.url)
# Output http://httpbin.org/get?key1=value1&key2=value2
POST mode
import requests
payload = {
"key1":"value1",
"key2":"value2"
}
response = requests.post("http://httpbin.org/post",data = payload)
print(response.text)
import requests
postdata = { 'name':'aaa' }
r = requests.post("http://xxxxx",data=postdata)
print(r.text)
#If you want to use the crawler, it is generally recommended to bring the session session and header information. The session session can automatically record cookie s
s = requests.Session()
headers = { 'Host':'www.xxx.com'}
postdata = { 'name':'aaa' }
url = "http://xxxxx"
s.headers.update(headers)
r = s.post(url,data=postdata)
print(r.text)
#You can bring the header directly
import requests
#import json
data = {'some': 'data'}
headers = {'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'}
r = requests.post('https://api.github.com/some/endpoint', data=data, headers=headers)
print(r.text)
A basic framework used by urllib
GET mode
from urllib.request import urlopen
myURL = urlopen("https://www.runoob.com/")
f = open("runoob_urllib_test.html", "wb")
content = myURL.read() # Read web content
f.write(content)
f.close()
POST mode
import urllib.request
import urllib.parse
url = 'https://www.runoob.com/try/py3/py3_urllib_test.php '# submit to the form page
data = {'name':'RUNOOB', 'tag' : 'xx course'} # Submit data
header = {
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
} #Header information
data = urllib.parse.urlencode(data).encode('utf8') # Encode the parameters, and use urllib.parse.urldecode for decoding
request=urllib.request.Request(url, data, header) # Request processing
reponse=urllib.request.urlopen(request).read() # Read results
fh = open("./urllib_test_post_runoob.html","wb") # Writes files to the current directory
fh.write(reponse)
fh.close()