
Introduction to wechat panoramic monitoring platform
Wechat panoramic monitoring platform is a multi-dimensional indicator OLAP monitoring and data analysis platform of wechat. It supports user-defined multi-dimensional indicator reporting, real-time roll-up and drill down analysis of massive data, and provides second level anomaly detection and alarm capability.
The project has effectively supported the rapid iteration of video number, wechat payment, search and other businesses, and has covered all wechat product lines, with peak data reaching , 3 billion pieces / min and 3 trillion pieces / day. The architecture of wechat panoramic monitoring platform is shown in the figure below:
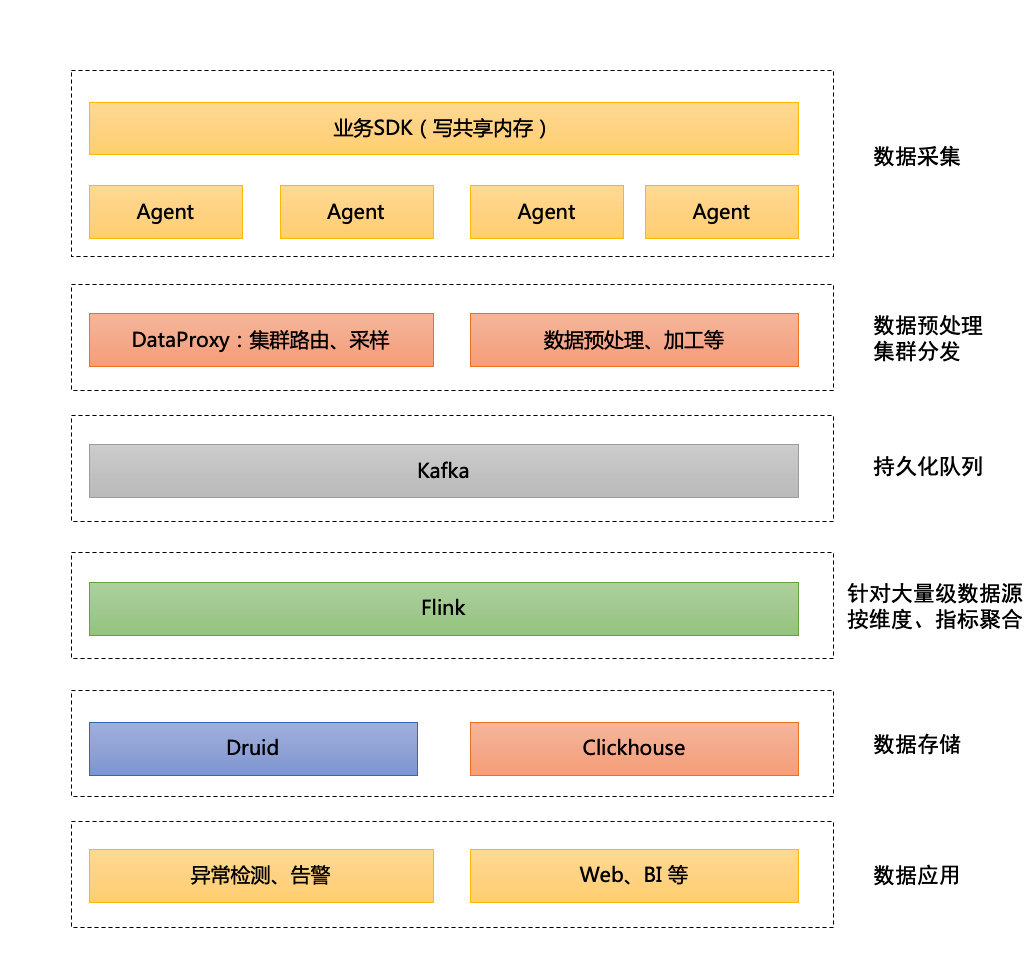
The indicator data of the panoramic monitoring platform uses Druid engine, which uses CHDFS as its deep storage for data storage and query.
What is Druid
Druid is a distributed data processing system that supports real-time multidimensional OLAP analysis. It supports not only high-speed data real-time processing, but also real-time and flexible multidimensional data analysis and query. Therefore, Druid's most common scenario is flexible and fast multidimensional OLAP analysis in the context of big data.
Druid nodes can be divided into the following categories:
- Master node: Overlord, Coordinator
- Real time data processing nodes: MiddleManager, Peon
- Storage nodes: historical (data slicing), HDFS (deep storage) (data slicing), metadatastorage (data table structure, etc.), Zookeeper(IndexingTask information)
- Data access nodes: Broker and Router

Druid and CHDFS combine perfectly
CHDFS (Cloud HDFS) is a high-performance distributed file system that provides standard HDFS access protocol and hierarchical namespace. It is a cloud native data storage product developed by Tencent cloud storage team. Through CHDFS, it can realize the separation of computing and storage, give full play to the flexibility of computing resources, realize the permanent preservation of stored data, and reduce the cost of big data analysis resources.
In the process of combining with Druid system, CHDFS plays two important roles:
1. Important transfer of data exchange between real-time nodes (Peon) and historical nodes.
2. Full data fragmentation is the cornerstone of Historical load balancing and disaster recovery.
- Overall data flow architecture:
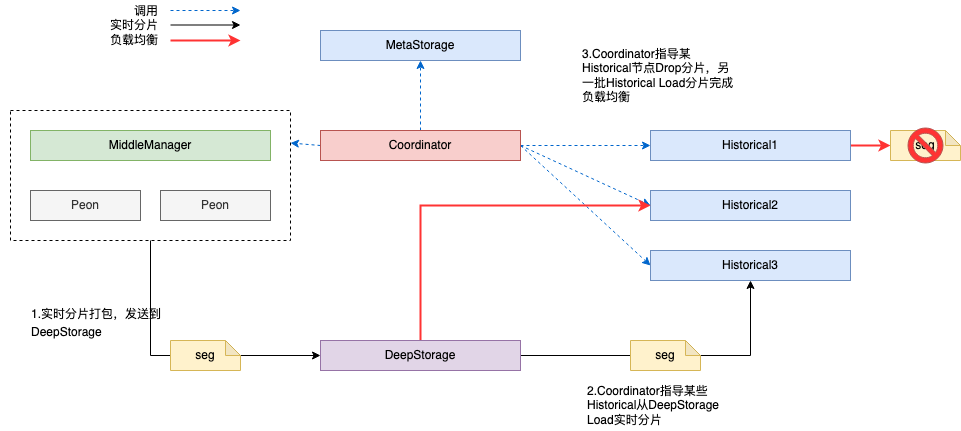
- The Overlord node assigns tasks to several MiddleManager nodes.
- The MiddleManager node creates a Peon node. The Peon node has an independent port and JVM, which is used as a basic Worker for data consumption and processing.
- The Peon node processes the data, packs the fragments, and publishes the fragments to DeepStorage after reaching the task cycle time.
- Coordinator coordinates the Historical node to download Segment from CHDFS.
- Historical download is completed, and a real-time partition task is completed. Historical takes over the data query of this partition, and Peon destroys it.
Real time task slicing is from peon - > chdfs (deep storage) - > historical. As the Master node of real-time tasks, Overlord is responsible for scheduling real-time tasks and issuing tasks to MiddleManager. MiddleManager, as its name suggests, receives the scheduling of Overlord, and acts as a "supervisor" to produce workers (peon) and synchronize the task status.
- Segment disaster recovery
If a Historical node is down or unavailable, the Coordinator will perceive and think that the data fragments in the Historical node are lost.
However, the Coordinator will not immediately ask other Historical to load these Segments from CHDFS. There will be a transitional data structure to store the lost Segments information. If the Historical returns, it will still provide external services without fragment transfer. If the Historical goes down for more than a certain time, The Coordinator will schedule other Historical to load fragments from DeepStorage.
- Segment load balancing
In order to ensure that segments are evenly distributed in Historical nodes, the Coordinator will automatically check the fragment distribution of all Historical nodes, schedule the Historical with the lowest utilization to load fragments from CHDFS, and let the Historical with the highest utilization discard fragments to complete load balancing.
Easily configure CHDFS as Druid DeepStorage
1. Create CHDFS, create permission groups, permission rules and mount points;
2. Download chdfs jar GitHub - tencentyun / chdfs Hadoop plugin: the Hadoop plugin for chdfs (download link: https://github.com/tencentyun/chdfs-hadoop-plugin );
3. Copy the above jar files to extensions / Druid HDFS storage and Hadoop dependencies / Hadoop client / x.x.x;
4. Conf / Druid in Druid/_ common/common. runtime. Under properties, add the CHDFS configuration:
// segment stores Druid storage. type=hdfsdruid. storage. storageDirectory= ofs://xxx.chdfs.ap-shanghai.myqcloud.com/usr/xxx/druid/segments // Indexer log Druid indexer. logs. type=hdfsdruid. indexer. logs. directory= ofs://xxx.chdfs.ap-shanghai.myqcloud.com/usr/xxx/druid/indexing-logs conf/druid/_common/ Add next core-site.xml and hdfs-site.xml
5. Configure hadoop environment and configure core site XML and HDFS site xml ;
// core-site. xml<? xml version="1.0" encoding="UTF-8"?><? xml-stylesheet type="text/xsl" href="configuration.xsl"?>< configuration><!-- Implementation class of chdfs -- > < property > < name > FS AbstractFileSystem. ofs. impl</name> <value>com. qcloud. chdfs. fs. CHDFSDelegateFSAdapter</value></property><property> <name>fs. ofs. impl</name> <value>com. qcloud. chdfs. fs. CHDFSHadoopFileSystemAdapter</value></property><property> <name>fs. ofs. tmp. cache. dir</name> <value>/home/xxx/data/chdfs_ tmp_ cache</value></property><!-- appId--><property> <name>fs. ofs. user. appid</name> <value>00000000</value></property></configuration> // hdfs-site. xml<? xml version="1.0" encoding="UTF-8"?><? xml-stylesheet type="text/xsl" href="configuration.xsl"?>< configuration><property> <name>fs. AbstractFileSystem. ofs. impl</name> <value>com. qcloud. chdfs. fs. CHDFSDelegateFSAdapter</value></property><property> <name>fs. ofs. impl</name> <value>com. qcloud. chdfs. fs. CHDFSHadoopFileSystemAdapter</value></property><!-- The temporary directory of the local cache. For read-write data, when the memory cache is insufficient, it will be written to the local hard disk. If this path does not exist, it will be automatically created -- > < property > < name > FS ofs. tmp. cache. dir</name> <value>/home/qspace/data/chdfs_ tmp_ cache</value></property><!-- Appid users need to change their appid to go to https://console.cloud.tencent.com/cam/capi < name -- > < property. FS > > ofs. user. appid</name> <value>00000</value></property></configuration>
6. It can be seen from the Indexer log that the data has been successfully written to HDFS and can be downloaded by the Historical node.

Overall effect
At present, wechat monitoring has stored hundreds of terabytes and millions of files through CHDFS, which operates stably without failure.
Compared with the original HDFS, which relies on manual deployment and maintenance of operation and maintenance, CHDFS can be used out of the box without problems such as operation and maintenance and abolition, which truly solves a major pain point of the business.
CHDFS products are very stable. Wechat monitoring uses a total of 100 TB of storage space and millions of files. Since its launch, it has operated stably without failure. Subsequently, wechat indicator monitoring will gradually migrate all storage DeepStorage to CHDFS, with a total amount of PB.
— END —

Click "read the original text" to learn more about CHDFS!