1, Background introduction
1.1 introduction to data set
The Anime dataset used in this actual combat is PNG picture of "high definition animation character Avatar". The pictures are 64x64 color pictures, a total of 21551. The examples of the pictures are as follows:

1.2 model introduction
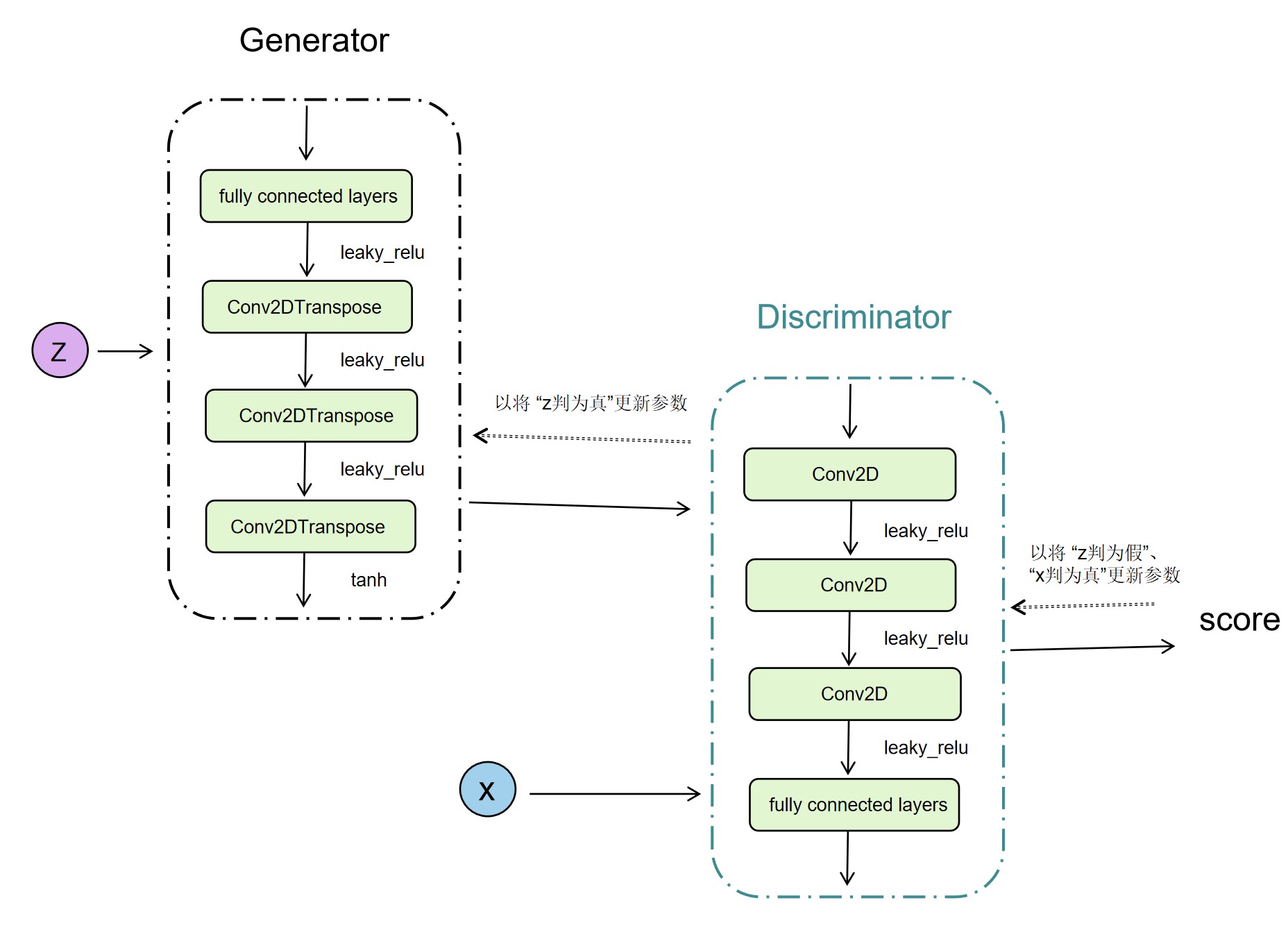
The "generation countermeasure network GAN/WGAN-GP" model in this actual battle includes two parts: Generator generator and Discriminator.
- Generator generator (used to generate images), which includes a fully connected layer and three convolution layers. The generated images are output through tanh. The input of this part is "randomly initialized z" and the output is the generated images.
- Discriminator discriminator (for image discrimination), which includes three convolution layers and a fully connected layer. The input of this part is "generated image" and "real image", and the output is logits.
The model generates images through the "Generator generator" and inputs them into the "discriminator discriminator" together with the "real image" for discrimination. "Discriminator discriminator" updates parameters with "true image and false generated image" through loss, while "Generator generator" updates parameters with "true generated image" through loss.
The difference between GAN and WGAN-GP in this actual battle is that WGAN-GP has changed the loss of "Discriminator". Wgan GP loss is as follows:
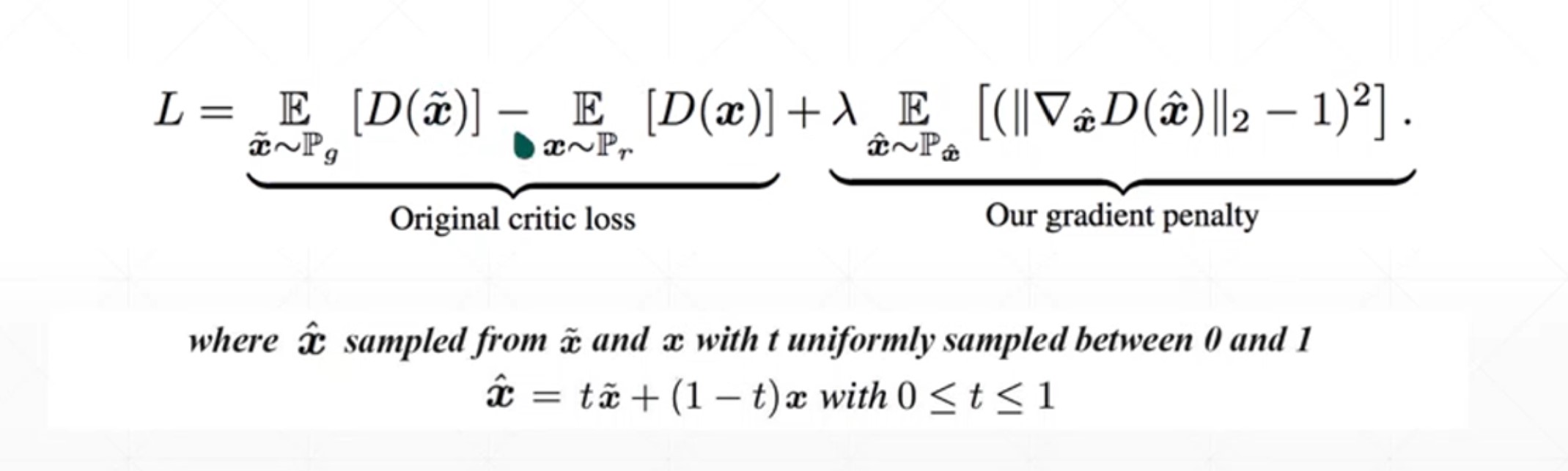
The actual GAN/WGAN-GP model structure is as follows:
Difference and connection between GAN and WGAN-GP:
Problems with the original GAN: if there is no overlap between PG (distribution of generated samples) and Pd (distribution of real samples), the use of "JS divergence" will lose its meaning.
WGAN-GP solution: WGAN-GP uses "wassertei distance" to measure the distance between two distributions, so as to better approximate PG (distribution of generated samples) to Pd (distribution of real samples).
(Reference) JS divergence, wassertei distance)
1.2. 1. Introduction to Gan principle (WGAN-GP is similar to "omitted")
1.2. 1.1 what can Gan do?
The original intention of generating the confrontation network GAN is to generate data that "does not exist in the real world (non real occurrence)", which is similar to making AI creative or imaginative (for example, AI painters make the fuzzy map clear, "rain, fog, jitter, mosaic", data enhancement, etc.).
1.2. 1.1 principle of GaN
GAN can be simply regarded as a game process of two networks. It has two networks:
- Generator generator (G for short): responsible for fabricating data out of thin air
- Discriminator discriminator (D for short): it is responsible for judging whether the data is true data
The whole process of GAN is unsupervised. The real picture has not been marked. D in the system does not know what the picture is. It only needs to distinguish the true from the false; G doesn't know what he generated. Anyway, he just cheated d d like a real picture. That is, let the "Generator generator" generate real pictures with the maximum probability, that is, find a distribution to make the generated pictures closer to the real pictures.
2, "GAN/WGAN-GP" actual combat code
2.1 code of GAN/WGAN-GP model
2.2 Gan train code
2.3 WGAN-GP-train code (different from Gan train: the loss of "Discriminator discriminator" is changed, and only the changed loss is commented in detail here)
2.4. Tool code - dataset loading
2.1. GAN/WGAN-GP model part code
# -*-coding:utf-8-*-
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
#Create a Generator network (generate image), including a full connection layer and three convolution layers, and get the output through tanh
class Generator(keras.Model):
def __init__(self):
super(Generator, self).__init__()
# z: [b, 100] => [b, 64, 64, 3]
#Dimension upgrading to facilitate subsequent image generation
self.fc = layers.Dense(3*3*512)
#Conv2drange (number of channels, step size, convolution kernel size, padding): deconvolution, used to expand the size of the image [output = (N − 1) * S − 2P+F]
# Input: NxN
# Convolution kernel size_ size: FxF
# Step strings: S
# Value of boundary expansion padding: P
# (3-1)*3 +3 =9
self.conv1 = layers.Conv2DTranspose(256, 3, 3, 'valid')
self.bn1 = layers.BatchNormalization()
# (9-1) * 2 + 5 =21
self.conv2 = layers.Conv2DTranspose(128, 5, 2, 'valid')
self.bn2 = layers.BatchNormalization()
# (23-1) * 3 + 4 =64
self.conv3 = layers.Conv2DTranspose(3, 4, 3, 'valid')
#Forward propagation (image generation)
def call(self, inputs, training=None):
# Upgrade the dimension and change its shape to meet the requirements of subsequent generated pictures [b, 100] = > [b, 3 * 3 * 512]
x = self.fc(inputs)
x = tf.reshape(x, [-1, 3, 3, 512])
#Because relu will cause gradient dispersion when x is less than 0, leaky is used here_ relu
x = tf.nn.leaky_relu(x)
#z: [b, 3*3*512] => [b, 64, 64, 3]
x = tf.nn.leaky_relu(self.bn1(self.conv1(x), training=training))
x = tf.nn.leaky_relu(self.bn2(self.conv2(x), training=training))
x = self.conv3(x)
#sigmoid function is easy to be unstable during training, Therefore, tanh is used here (when D generates 0 ~ 1, we compress the value of 0 ~ 255 to 0 ~ 1 during classification, and then "(0 ~ 1) * 2-1" reduces it to the interval of - 1 ~ 1; the range of pictures received by the network is - 1 ~ 1, so the interval of - 1 ~ 1 is also generated; if you want to view these pictures artificially, you need to raise - 1 ~ 1 to 0 ~ 1 and then 0 ~ 255 to meet the visual requirements)
x = tf.tanh(x)
return x
#Create Discriminator network (image discrimination), including three convolution layers and one full connection layer
class Discriminator(keras.Model):
def __init__(self):
super(Discriminator, self).__init__()
# [b, 64, 64, 3] => [b, 1, 1, 256]
#Conv2D (number of channels, step S, convolution kernel size F, padding), output = rounding down ((N-F) / s) + 1)
#(64-3)/5+1=13
self.conv1 = layers.Conv2D(64, 5, 3, 'valid')
#(13-3)/5+1=3
self.conv2 = layers.Conv2D(128, 5, 3, 'valid')
self.bn2 = layers.BatchNormalization()
#(3-3)/5+1=1
self.conv3 = layers.Conv2D(256, 5, 3, 'valid')
self.bn3 = layers.BatchNormalization()
# [b, h, w ,c] => [b, -1]
#Flatten: used to "flatten" the input (i.e. unidimensional input, commonly used in the transition from convolution layer to full connection layer)
self.flatten = layers.Flatten()
self.fc = layers.Dense(1)
#Forward propagation (image discrimination)
def call(self, inputs, training=None):
x = tf.nn.leaky_relu(self.conv1(inputs))
x = tf.nn.leaky_relu(self.bn2(self.conv2(x), training=training))
x = tf.nn.leaky_relu(self.bn3(self.conv3(x), training=training))
# [b, h, w, c] => [b, -1]
x = self.flatten(x)
# [b, -1] => [b, 1]
logits = self.fc(x)
return logits
# #Test Discriminator, Generator
# def main():
#
# d = Discriminator()
# g = Generator()
#
#
# x = tf.random.normal([2, 64, 64, 3])
# z = tf.random.normal([2, 100])
#
# prob = d(x)
# print(prob)
# x_hat = g(z)
# print(x_hat.shape)
if __name__ == '__main__':
pass
# main()
2.2. Gan train code
# -*-coding:utf-8-*-
import os
#Only warning and Error are displayed
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import numpy as np
import tensorflow as tf
from PIL import Image
import glob
from gan import Generator, Discriminator
from dataset import make_anime_dataset
#Put together multiple training pictures into one picture and save it
def save_result(val_out, val_block_size, image_path, color_mode):
def preprocess(img):
img = ((img + 1.0) * 127.5).astype(np.uint8)
return img
preprocesed = preprocess(val_out)
final_image = np.array([])
single_row = np.array([])
for b in range(val_out.shape[0]):
# concat image into a row
if single_row.size == 0:
single_row = preprocesed[b, :, :, :]
else:
single_row = np.concatenate((single_row, preprocesed[b, :, :, :]), axis=1)
# concat image row to final_image
if (b+1) % val_block_size == 0:
if final_image.size == 0:
final_image = single_row
else:
final_image = np.concatenate((final_image, single_row), axis=0)
# reset single row
single_row = np.array([])
if final_image.shape[2] == 1:
final_image = np.squeeze(final_image, axis=2)
Image.fromarray(final_image,mode=color_mode).save(image_path)
#Loss label is true
def celoss_ones(logits):
# [b, 1]
# [b] = [1, 1, 1, 1,]
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=logits,
labels=tf.ones_like(logits))
return tf.reduce_mean(loss)
#Loss label is false
def celoss_zeros(logits):
# [b, 1]
# [b] = [1, 1, 1, 1,]
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=logits,
labels=tf.zeros_like(logits))
return tf.reduce_mean(loss)
#Judge the real image as true and the generated image as false
def d_loss_fn(generator, discriminator, batch_z, batch_x, is_training):
#Generate image (input randomly initialized z into generator)
fake_image = generator(batch_z, is_training)
#Input the generated image into discriminator
d_fake_logits = discriminator(fake_image, is_training)
# Input real image into discriminator
d_real_logits = discriminator(batch_x, is_training)
#loss - real image, label is true
d_loss_real = celoss_ones(d_real_logits)
#loss - generates an image, and label is false
d_loss_fake = celoss_zeros(d_fake_logits)
#loss - true image - true, generate image - false
loss = d_loss_fake + d_loss_real
return loss
#Judge the generated image as true
def g_loss_fn(generator, discriminator, batch_z, is_training):
#Batch to be initialized randomly_ Z input Generator
fake_image = generator(batch_z, is_training)
#Input the generated image into Discriminator
d_fake_logits = discriminator(fake_image, is_training)
# loss - generates an image, and label is true
loss = celoss_ones(d_fake_logits)
return loss
def main():
#Random number seed
tf.random.set_seed(22)
np.random.seed(22)
# startwith('2. 'this function is used to judge TF__ version__ Whether the version information of starts with '2.0', and returns True or False
assert tf.__version__.startswith('2.')
# Super parameter
z_dim = 100
epochs = 3000000
batch_size = 256
learning_rate = 0.002
is_training = True
#Get all pictures in the specified directory
img_path = glob.glob(r'D:\PyCharmPro\shu_ju\anime-faces\*.png')
#Data loading
dataset, img_shape, _ = make_anime_dataset(img_path, batch_size)
print(dataset, img_shape)
sample = next(iter(dataset))
print(sample.shape, tf.reduce_max(sample).numpy(),
tf.reduce_min(sample).numpy())
#repeat() if the number is not filled in the brackets, it can be repeated without limit
dataset = dataset.repeat()
db_iter = iter(dataset)
#Instantiate the Generator, Discriminator, and customize the dimension of the weight of its network
generator = Generator()
generator.build(input_shape = (None, z_dim))
discriminator = Discriminator()
discriminator.build(input_shape=(None, 64, 64, 3))
#Set the optimizer for the Generator
g_optimizer = tf.optimizers.Adam(learning_rate=learning_rate, beta_1=0.5)
# Optimizer for setting optimizers
d_optimizer = tf.optimizers.Adam(learning_rate=learning_rate, beta_1=0.5)
#epoch cycle
for epoch in range(epochs):
#Random initialization z(-1~1)
batch_z = tf.random.uniform([batch_size, z_dim], minval=-1., maxval=1.)
batch_x = next(db_iter)
# Back propagation to update the Discriminator parameter for "judge generated image as false" and "judge real image as true"
with tf.GradientTape() as tape:
#Calculate discriminator loss
d_loss = d_loss_fn(generator, discriminator, batch_z, batch_x, is_training)
#Back propagation
grads = tape.gradient(d_loss, discriminator.trainable_variables)
#Update parameters using optimizer
d_optimizer.apply_gradients(zip(grads, discriminator.trainable_variables))
# Back propagation to update the Generator parameter with generate image true
with tf.GradientTape() as tape:
#Calculate generator loss
g_loss = g_loss_fn(generator, discriminator, batch_z, is_training)
#Back propagation
grads = tape.gradient(g_loss, generator.trainable_variables)
#Update parameters using optimizer
g_optimizer.apply_gradients(zip(grads, generator.trainable_variables))
if epoch % 100 == 0:
print(epoch, 'd-loss:',float(d_loss), 'g-loss:', float(g_loss))
#View the generated image effect (once every 100 epoch samples)
#Random initialization z
z = tf.random.uniform([100, z_dim])
#Generate image
fake_image = generator(z, training=False)
#Save image
img_path = os.path.join('images_gan', 'gan-%d.png'%epoch)
save_result(fake_image.numpy(), 10, img_path, color_mode='P')
if __name__ == '__main__':
main()
2.3. Wgan GP train code (different from GAN: the loss of "Discriminator discriminator" is changed, and only the changed loss part is commented in detail here)
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import numpy as np
import tensorflow as tf
from PIL import Image
import glob
from gan import Generator, Discriminator
from dataset import make_anime_dataset
def save_result(val_out, val_block_size, image_path, color_mode):
def preprocess(img):
img = ((img + 1.0) * 127.5).astype(np.uint8)
# img = img.astype(np.uint8)
return img
preprocesed = preprocess(val_out)
final_image = np.array([])
single_row = np.array([])
for b in range(val_out.shape[0]):
# concat image into a row
if single_row.size == 0:
single_row = preprocesed[b, :, :, :]
else:
single_row = np.concatenate((single_row, preprocesed[b, :, :, :]), axis=1)
# concat image row to final_image
if (b+1) % val_block_size == 0:
if final_image.size == 0:
final_image = single_row
else:
final_image = np.concatenate((final_image, single_row), axis=0)
# reset single row
single_row = np.array([])
if final_image.shape[2] == 1:
final_image = np.squeeze(final_image, axis=2)
Image.fromarray(final_image).save(image_path)
def celoss_ones(logits):
# [b, 1]
# [b] = [1, 1, 1, 1,]
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=logits,
labels=tf.ones_like(logits))
return tf.reduce_mean(loss)
def celoss_zeros(logits):
# [b, 1]
# [b] = [1, 1, 1, 1,]
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=logits,
labels=tf.zeros_like(logits))
return tf.reduce_mean(loss)
def gradient_penalty(discriminator, batch_x, fake_image):
batchsz = batch_x.shape[0]
#Random sample linear difference factor from uniform distribution (this t weight is used for the whole image)
# [b, h, w, c]
t = tf.random.uniform([batchsz, 1, 1, 1])
#broadcast_ The to function broadcasts the array to the new shape
# [b, 1, 1, 1] => [b, h, w, c]
t = tf.broadcast_to(t, batch_x.shape)
#Make a linear difference between "true image batch_x" and "false image fake_image" (t is the linear difference between 0 and 1)
interplate = t * batch_x + (1 - t) * fake_image
#Feed the "interplate" into the discriminator and solve the gradient
with tf.GradientTape() as tape:
tape.watch([interplate])
d_interplote_logits = discriminator(interplate)
grads = tape.gradient(d_interplote_logits, interplate)
#Get the second norm of each sample
# grads:[b, h, w, c] => [b, -1]
grads = tf.reshape(grads, [grads.shape[0], -1])
gp = tf.norm(grads, axis=1) #[b]
gp = tf.reduce_mean( (gp-1)**2 )
return gp
def d_loss_fn(generator, discriminator, batch_z, batch_x, is_training):
# 1. treat real image as real
# 2. treat generated image as fake
fake_image = generator(batch_z, is_training)
d_fake_logits = discriminator(fake_image, is_training)
d_real_logits = discriminator(batch_x, is_training)
d_loss_real = celoss_ones(d_real_logits)
d_loss_fake = celoss_zeros(d_fake_logits)
#Calculate gradient penalty term
gp = gradient_penalty(discriminator, batch_x, fake_image)
# “1.” Super parameter, adjustable
loss = d_loss_fake + d_loss_real + 1. * gp
return loss, gp
def g_loss_fn(generator, discriminator, batch_z, is_training):
fake_image = generator(batch_z, is_training)
d_fake_logits = discriminator(fake_image, is_training)
loss = celoss_ones(d_fake_logits)
return loss
def main():
tf.random.set_seed(22)
np.random.seed(22)
assert tf.__version__.startswith('2.')
# hyper parameters
z_dim = 100
epochs = 3000000
batch_size = 256
learning_rate = 0.002
is_training = True
img_path = glob.glob(r'D:\PyCharmPro\shu_ju\anime-faces\*.png')
dataset, img_shape, _ = make_anime_dataset(img_path, batch_size)
print(dataset, img_shape)
sample = next(iter(dataset))
print(sample.shape, tf.reduce_max(sample).numpy(),
tf.reduce_min(sample).numpy())
dataset = dataset.repeat()
db_iter = iter(dataset)
generator = Generator()
generator.build(input_shape = (None, z_dim))
discriminator = Discriminator()
discriminator.build(input_shape=(None, 64, 64, 3))
g_optimizer = tf.optimizers.Adam(learning_rate=learning_rate, beta_1=0.5)
d_optimizer = tf.optimizers.Adam(learning_rate=learning_rate, beta_1=0.5)
for epoch in range(epochs):
batch_z = tf.random.uniform([batch_size, z_dim], minval=-1., maxval=1.)
batch_x = next(db_iter)
# train D
with tf.GradientTape() as tape:
d_loss, gp = d_loss_fn(generator, discriminator, batch_z, batch_x, is_training)
grads = tape.gradient(d_loss, discriminator.trainable_variables)
d_optimizer.apply_gradients(zip(grads, discriminator.trainable_variables))
with tf.GradientTape() as tape:
g_loss = g_loss_fn(generator, discriminator, batch_z, is_training)
grads = tape.gradient(g_loss, generator.trainable_variables)
g_optimizer.apply_gradients(zip(grads, generator.trainable_variables))
if epoch % 100 == 0:
print(epoch, 'd-loss:',float(d_loss), 'g-loss:', float(g_loss),
'gp:', float(gp))
z = tf.random.uniform([100, z_dim])
fake_image = generator(z, training=False)
img_path = os.path.join('images', 'wgan-%d.png'%epoch)
save_result(fake_image.numpy(), 10, img_path, color_mode='P')
if __name__ == '__main__':
main()
2.4. Tool code - dataset loading
import multiprocessing
import tensorflow as tf
def make_anime_dataset(img_paths, batch_size, resize=64, drop_remainder=True, shuffle=True, repeat=1):
@tf.function
def _map_fn(img):
img = tf.image.resize(img, [resize, resize])
img = tf.clip_by_value(img, 0, 255)
img = img / 127.5 - 1
return img
dataset = disk_image_batch_dataset(img_paths,
batch_size,
drop_remainder=drop_remainder,
map_fn=_map_fn,
shuffle=shuffle,
repeat=repeat)
img_shape = (resize, resize, 3)
len_dataset = len(img_paths) // batch_size
return dataset, img_shape, len_dataset
def batch_dataset(dataset,
batch_size,
drop_remainder=True,
n_prefetch_batch=1,
filter_fn=None,
map_fn=None,
n_map_threads=None,
filter_after_map=False,
shuffle=True,
shuffle_buffer_size=None,
repeat=None):
# set defaults
if n_map_threads is None:
n_map_threads = multiprocessing.cpu_count()
if shuffle and shuffle_buffer_size is None:
shuffle_buffer_size = max(batch_size * 128, 2048) # set the minimum buffer size as 2048
# [*] it is efficient to conduct `shuffle` before `map`/`filter` because `map`/`filter` is sometimes costly
if shuffle:
dataset = dataset.shuffle(shuffle_buffer_size)
if not filter_after_map:
if filter_fn:
dataset = dataset.filter(filter_fn)
if map_fn:
dataset = dataset.map(map_fn, num_parallel_calls=n_map_threads)
else: # [*] this is slower
if map_fn:
dataset = dataset.map(map_fn, num_parallel_calls=n_map_threads)
if filter_fn:
dataset = dataset.filter(filter_fn)
dataset = dataset.batch(batch_size, drop_remainder=drop_remainder)
dataset = dataset.repeat(repeat).prefetch(n_prefetch_batch)
return dataset
def memory_data_batch_dataset(memory_data,
batch_size,
drop_remainder=True,
n_prefetch_batch=1,
filter_fn=None,
map_fn=None,
n_map_threads=None,
filter_after_map=False,
shuffle=True,
shuffle_buffer_size=None,
repeat=None):
"""Batch dataset of memory data.
Parameters
----------
memory_data : nested structure of tensors/ndarrays/lists
"""
dataset = tf.data.Dataset.from_tensor_slices(memory_data)
dataset = batch_dataset(dataset,
batch_size,
drop_remainder=drop_remainder,
n_prefetch_batch=n_prefetch_batch,
filter_fn=filter_fn,
map_fn=map_fn,
n_map_threads=n_map_threads,
filter_after_map=filter_after_map,
shuffle=shuffle,
shuffle_buffer_size=shuffle_buffer_size,
repeat=repeat)
return dataset
def disk_image_batch_dataset(img_paths,
batch_size,
labels=None,
drop_remainder=True,
n_prefetch_batch=1,
filter_fn=None,
map_fn=None,
n_map_threads=None,
filter_after_map=False,
shuffle=True,
shuffle_buffer_size=None,
repeat=None):
"""Batch dataset of disk image for PNG and JPEG.
Parameters
----------
img_paths : 1d-tensor/ndarray/list of str
labels : nested structure of tensors/ndarrays/lists
"""
if labels is None:
memory_data = img_paths
else:
memory_data = (img_paths, labels)
def parse_fn(path, *label):
img = tf.io.read_file(path)
img = tf.image.decode_png(img, 3) # fix channels to 3
return (img,) + label
if map_fn: # fuse `map_fn` and `parse_fn`
def map_fn_(*args):
return map_fn(*parse_fn(*args))
else:
map_fn_ = parse_fn
dataset = memory_data_batch_dataset(memory_data,
batch_size,
drop_remainder=drop_remainder,
n_prefetch_batch=n_prefetch_batch,
filter_fn=filter_fn,
map_fn=map_fn_,
n_map_threads=n_map_threads,
filter_after_map=filter_after_map,
shuffle=shuffle,
shuffle_buffer_size=shuffle_buffer_size,
repeat=repeat)
return dataset