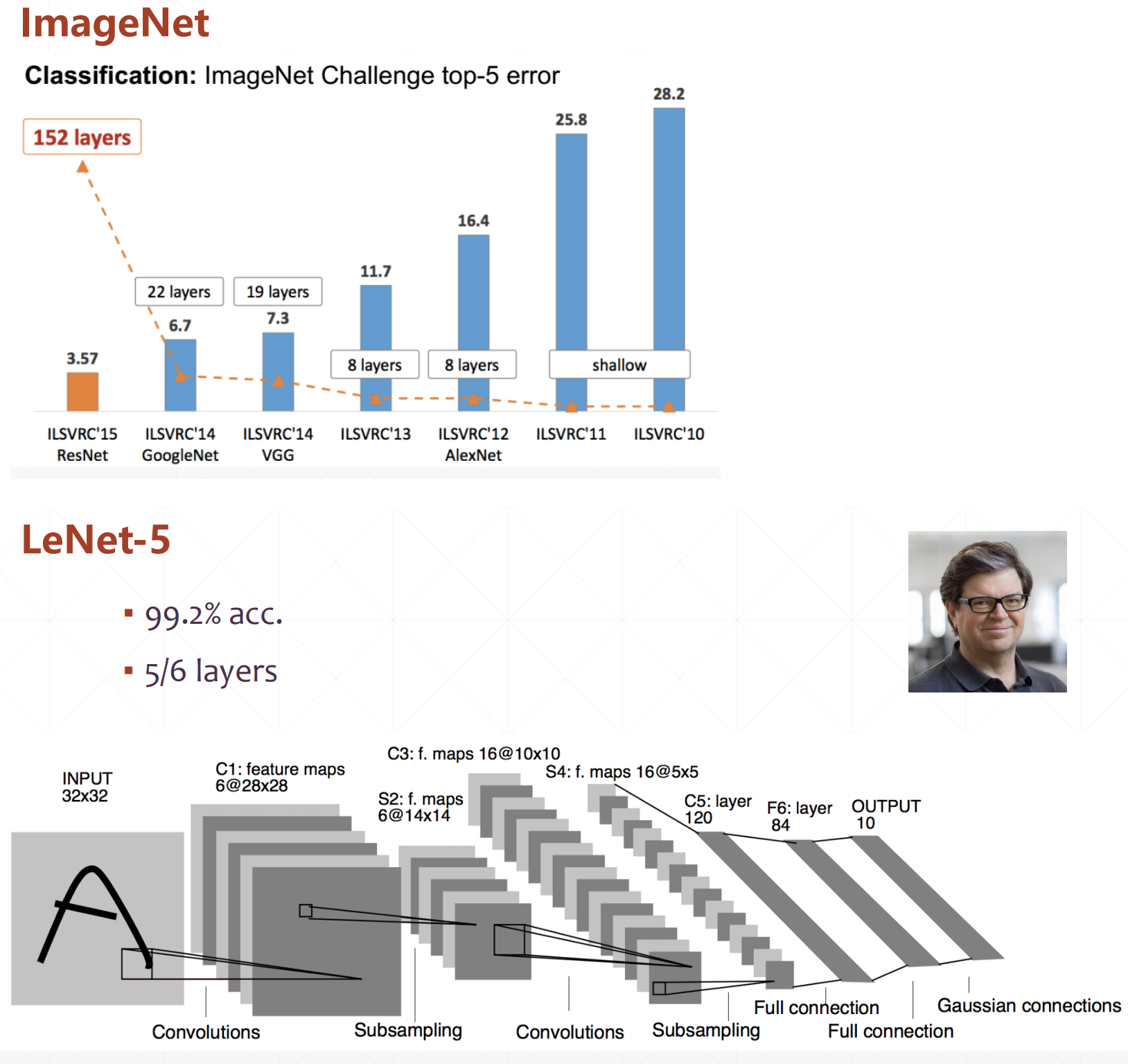
Various classical convolution networks
LeNet-5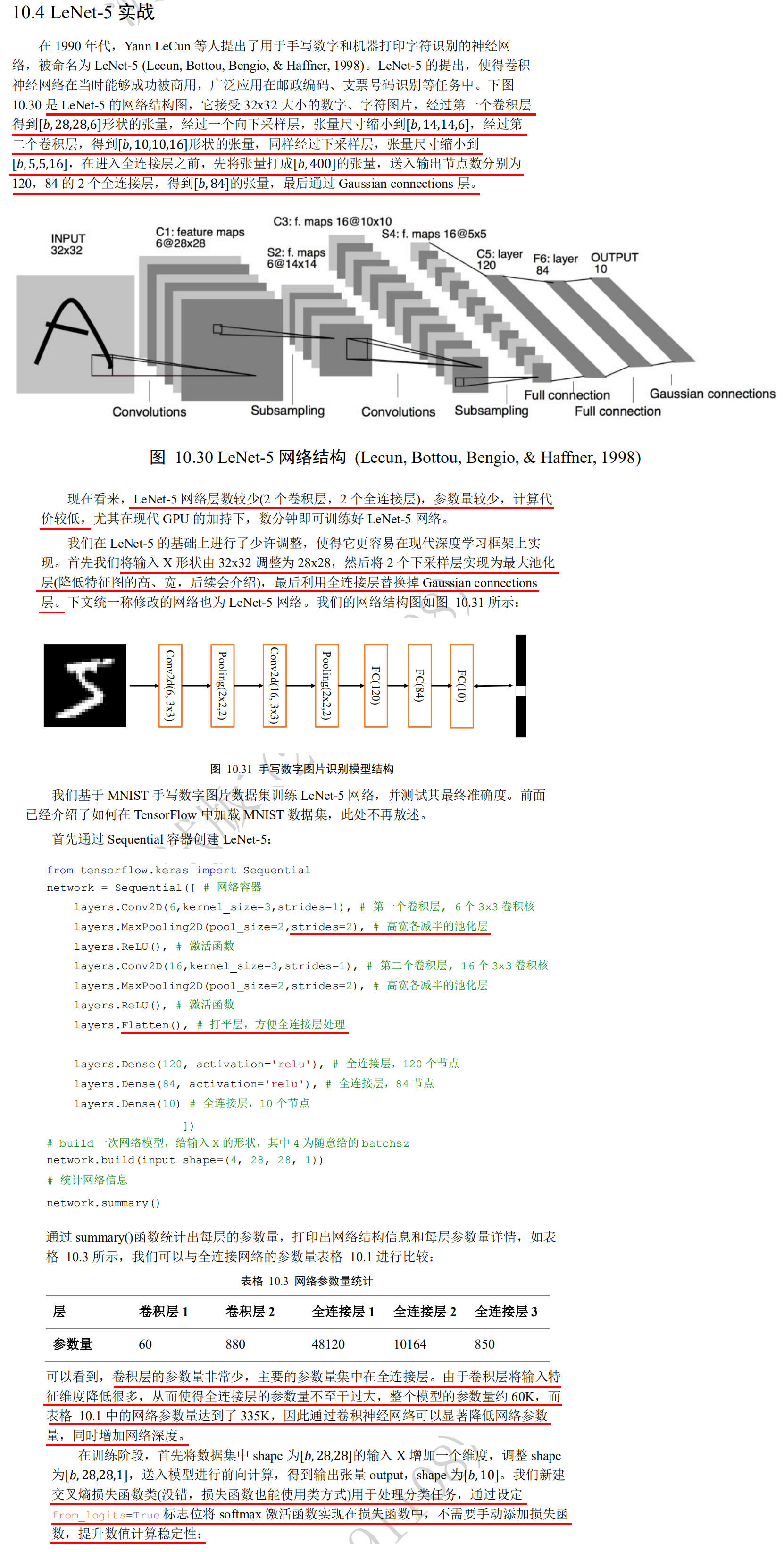
import tensorflow as tf
help(tf.losses.categorical_crossentropy)
//View the list of default parameters and the introduction to the usage of the category? Crossentropy function
//Where the parameter is from Logits = false by default, and the network prediction value y ﹤ PRED indicates that it must be the output value passing through the Softmax function.
//When from Logits is set to True, the network prediction value y ﹤ PRED indicates that it must be the variable z that has not passed the Softmax function.
from_logits=True Flag location will be softmax The activation function is implemented in the loss function, so there is no need to add it manually softmax Loss function improves the stability of numerical calculation.
Help on function categorical_crossentropy in module tensorflow.python.keras.losses:
categorical_crossentropy(y_true, y_pred, from_logits=False, label_smoothing=0)
Computes the categorical crossentropy loss.
Args:
y_true: tensor of true targets.
y_pred: tensor of predicted targets.
from_logits: Whether `y_pred` is expected to be a logits tensor. By default,
we assume that `y_pred` encodes a probability distribution.

AlexNet
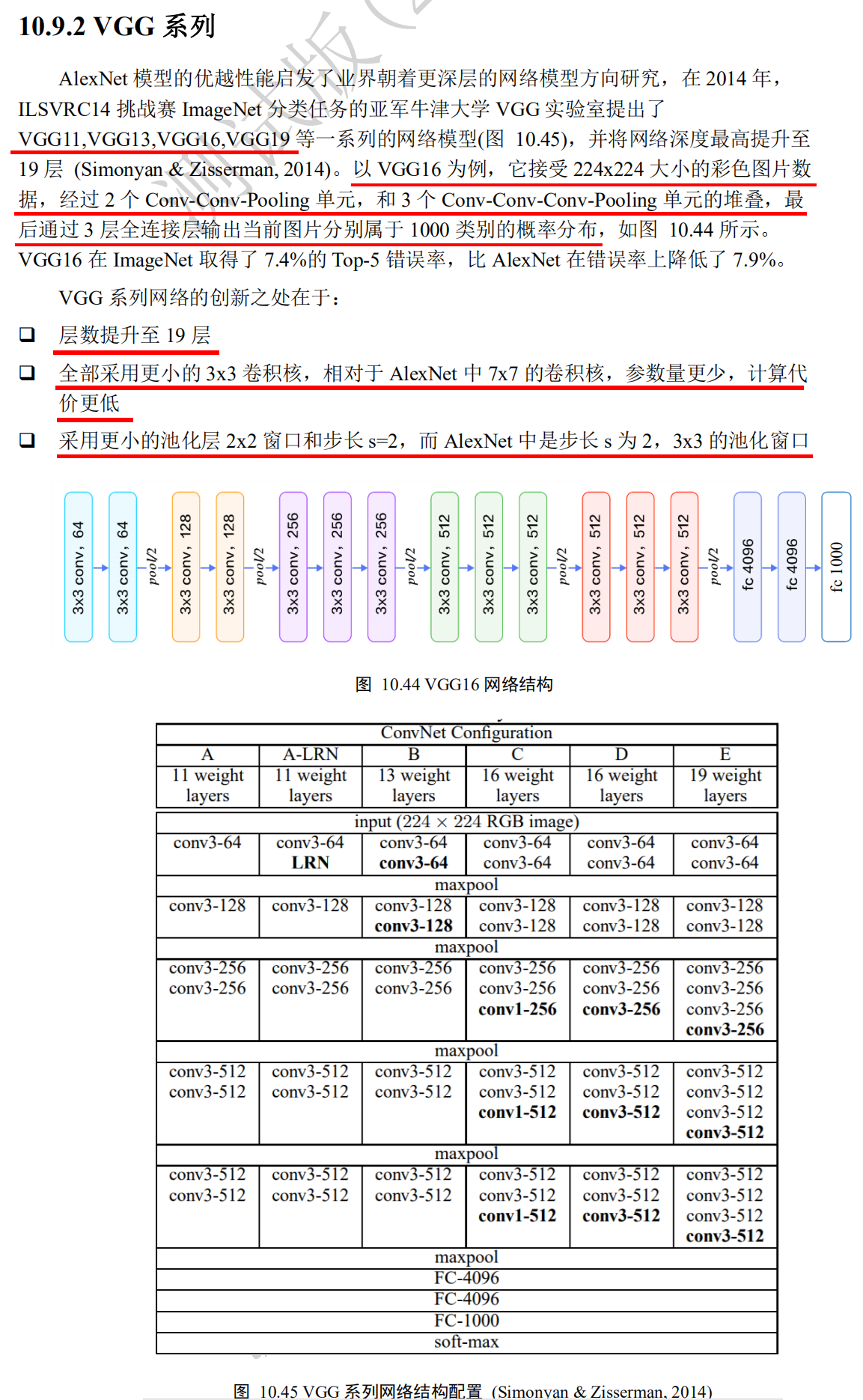
VGG
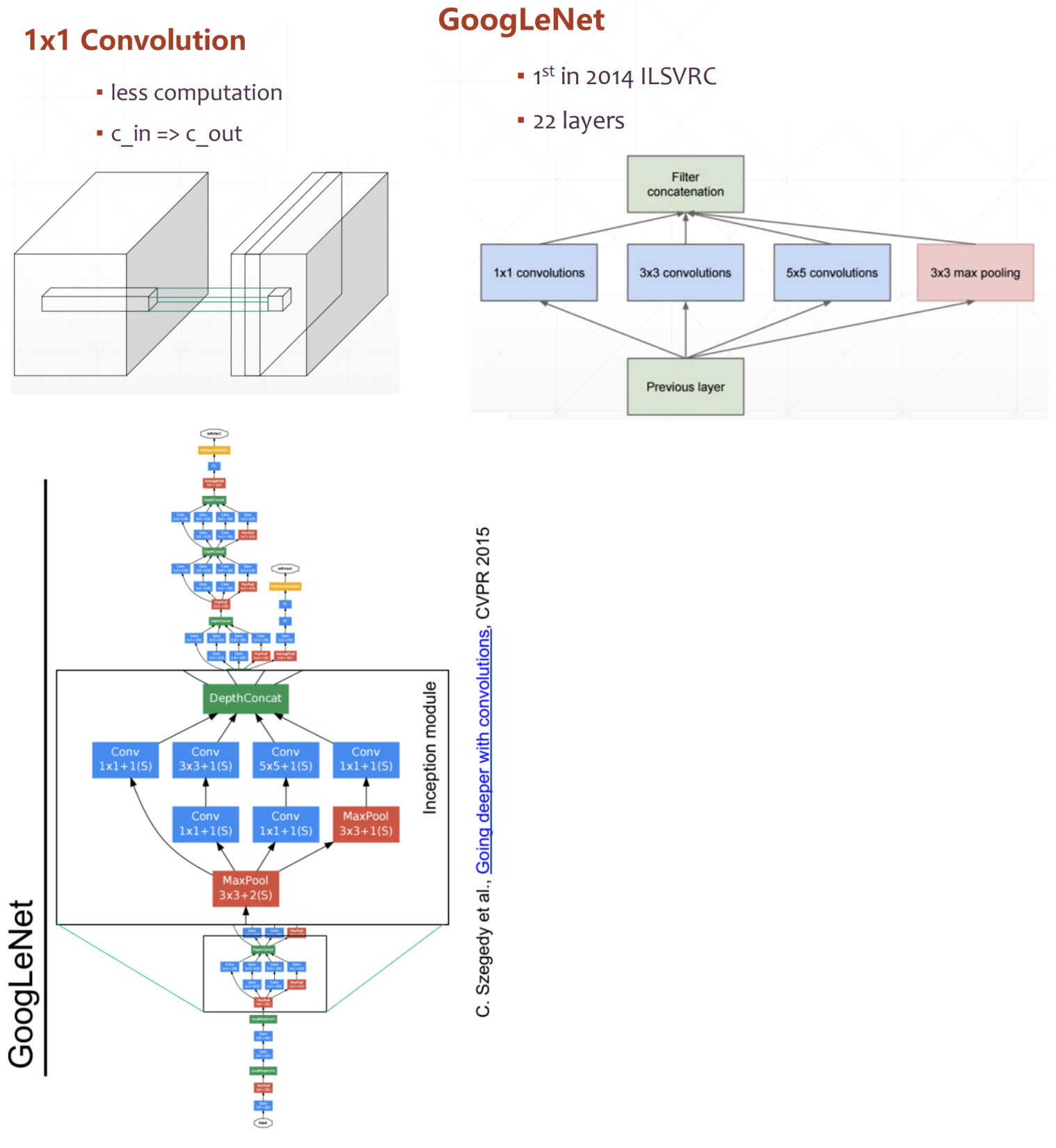
GoogLeNet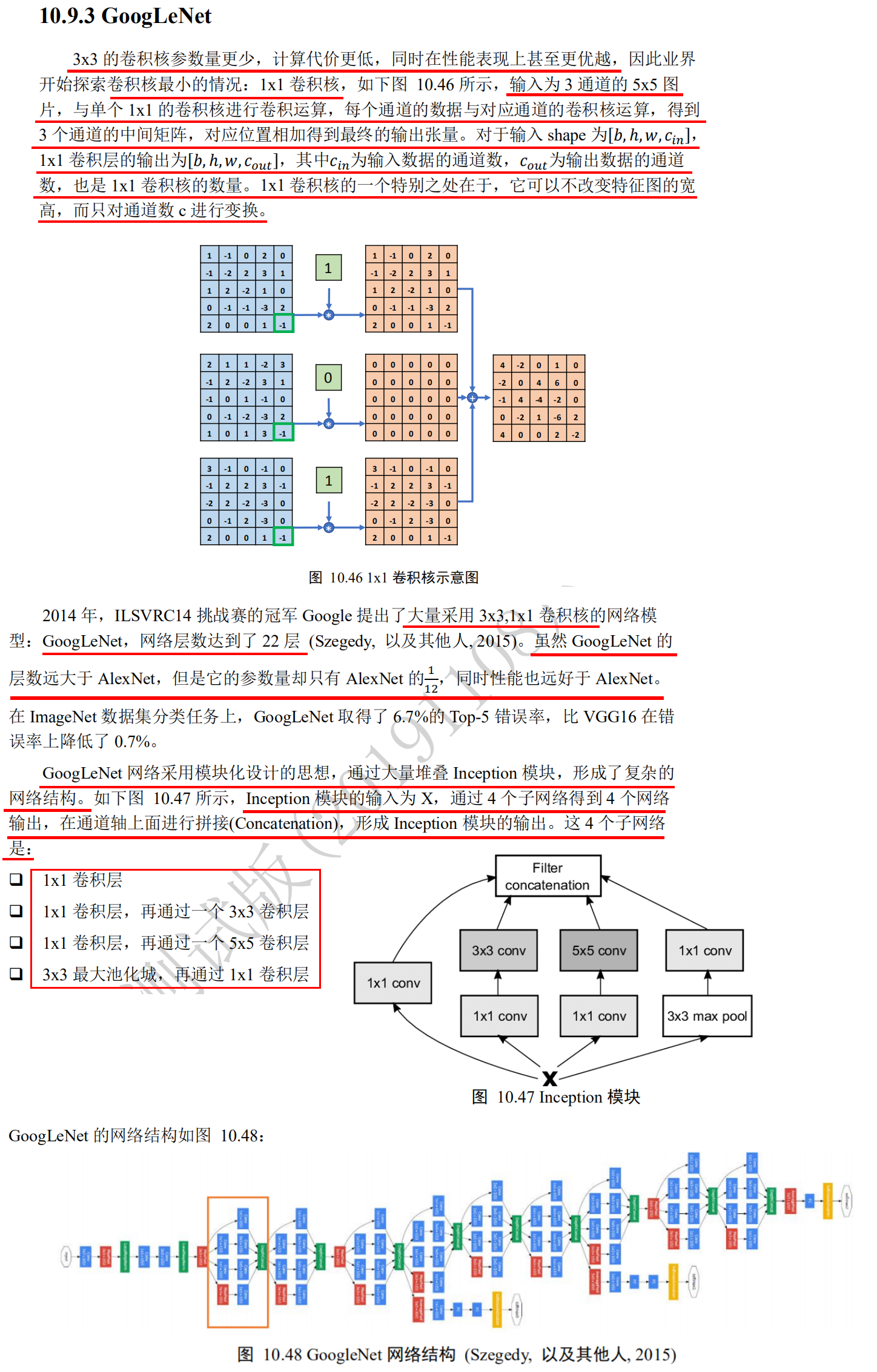
CIFAR10 vs. VGG13


def preprocess(x, y):
# Standardization: mapping data between - 1 and 1
x = 2*tf.cast(x, dtype=tf.float32) / 255.-1
y = tf.cast(y, dtype=tf.int32)
return x,y
# Download online, load CIFAR10 data set
(x,y), (x_test, y_test) = datasets.cifar100.load_data()
# Delete a dimension of y, [b, 1] = > [b]
y = tf.squeeze(y, axis=1)
y_test = tf.squeeze(y_test, axis=1)
# Print training and test set shapes
print(x.shape, y.shape, x_test.shape, y_test.shape)
# Building training set objects
train_db = tf.data.Dataset.from_tensor_slices((x,y))
train_db = train_db.shuffle(1000).map(preprocess).batch(128)
# Building test set objects
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_db = test_db.map(preprocess).batch(128)
# Sample a Batch from the training set and observe
sample = next(iter(train_db))
print('sample:', sample[0].shape, sample[1].shape, tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
# Create a list with multiple layers first
conv_layers = [
# Conv conv pooling unit 1
# 64 3 x 3 convolution cores of the same size of input and output
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
# Half height and half width
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# Conv conv pooling unit 2, the output channel is increased to 128, and the height and width are halved
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
# Half height and half width
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# Conv conv pooling unit 3, the output channel is increased to 256, and the height and width are halved
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
# Half height and half width
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# Conv conv pooling unit 4, the output channel is increased to 512, and the height and width are halved
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
# Half height and half width
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# Conv conv pooling unit 5, the output channel is increased to 512, and the height width is halved
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
# Half height and half width
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same')
]
# Using the layer list created earlier to build a network container
conv_net = Sequential(conv_layers)
# Create 3-layer full connection layer subnet
fc_net = Sequential([
layers.Dense(256, activation=tf.nn.relu),
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(100, activation=None),
])
# Build 2 subnetworks and print network parameter information
conv_net.build(input_shape=[4, 32, 32, 3])
fc_net.build(input_shape=[4, 512])
conv_net.summary()
fc_net.summary()
# List merging, merging parameters of 2 subnetworks
variables = conv_net.trainable_variables + fc_net.trainable_variables
# Gradient all parameters
grads = tape.gradient(loss, variables)
# Auto update
optimizer.apply_gradients(zip(grads, variables))
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
tf.random.set_seed(2345)
# 5 units of conv + max pooling
conv_layers = [
# unit 1
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 2
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 3
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 4
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 5
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same')
]
def preprocess(x, y):
# Standardization: data mapping between [- 1,1]
x = 2*tf.cast(x, dtype=tf.float32) / 255.-1
y = tf.cast(y, dtype=tf.int32)
return x,y
(x,y), (x_test, y_test) = datasets.cifar10.load_data()
y = tf.squeeze(y, axis=1)
y_test = tf.squeeze(y_test, axis=1)
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x,y))
train_db = train_db.shuffle(1000).map(preprocess).batch(128)
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_db = test_db.map(preprocess).batch(64)
sample = next(iter(train_db))
print('sample:', sample[0].shape, sample[1].shape,
tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
def main():
# [b, 32, 32, 3] => [b, 1, 1, 512]
conv_net = Sequential(conv_layers)
fc_net = Sequential([
layers.Dense(256, activation=tf.nn.relu),
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(10, activation=None),
])
conv_net.build(input_shape=[None, 32, 32, 3])
fc_net.build(input_shape=[None, 512])
conv_net.summary()
fc_net.summary()
optimizer = optimizers.Adam(lr=1e-4)
# [1, 2] + [3, 4] => [1, 2, 3, 4]
variables = conv_net.trainable_variables + fc_net.trainable_variables
for epoch in range(50):
for step, (x,y) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 1, 1, 512]
out = conv_net(x)
# flatten, => [b, 512]
out = tf.reshape(out, [-1, 512])
# [b, 512] => [b, 10]
logits = fc_net(out)
# [b] => [b, 10]
y_onehot = tf.one_hot(y, depth=10)
# compute loss
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(grads, variables))
if step %100 == 0:
print(epoch, step, 'loss:', float(loss))
total_num = 0
total_correct = 0
for x,y in test_db:
out = conv_net(x)
out = tf.reshape(out, [-1, 512])
logits = fc_net(out)
prob = tf.nn.softmax(logits, axis=1) #Convert output to probability
pred = tf.argmax(prob, axis=1) #Obtain the index value corresponding to the maximum probability value as the category number
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32) #Check whether the index value (category number) corresponding to the maximum probability value is consistent with the real label category number
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch, 'acc:', acc)
if __name__ == '__main__':
main()
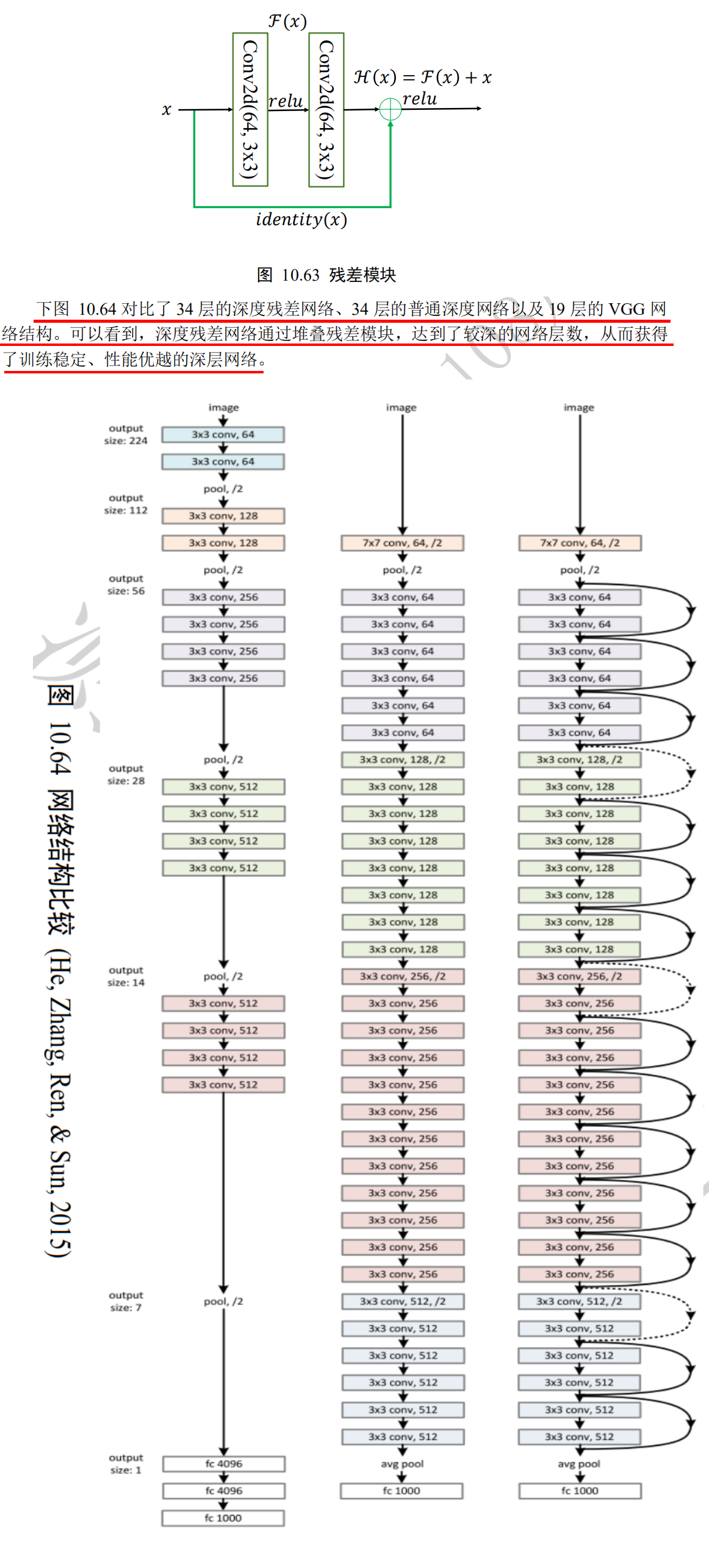
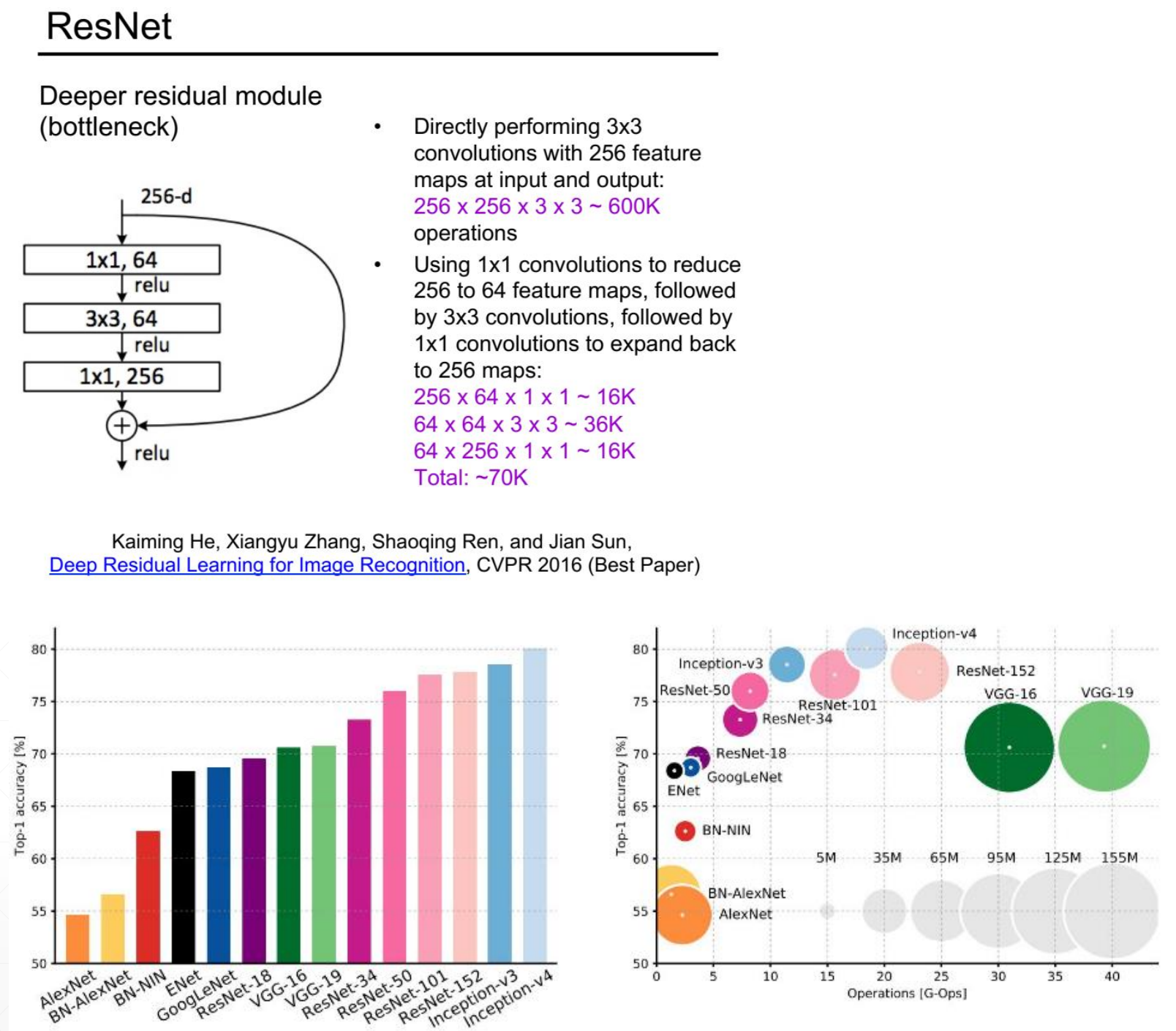
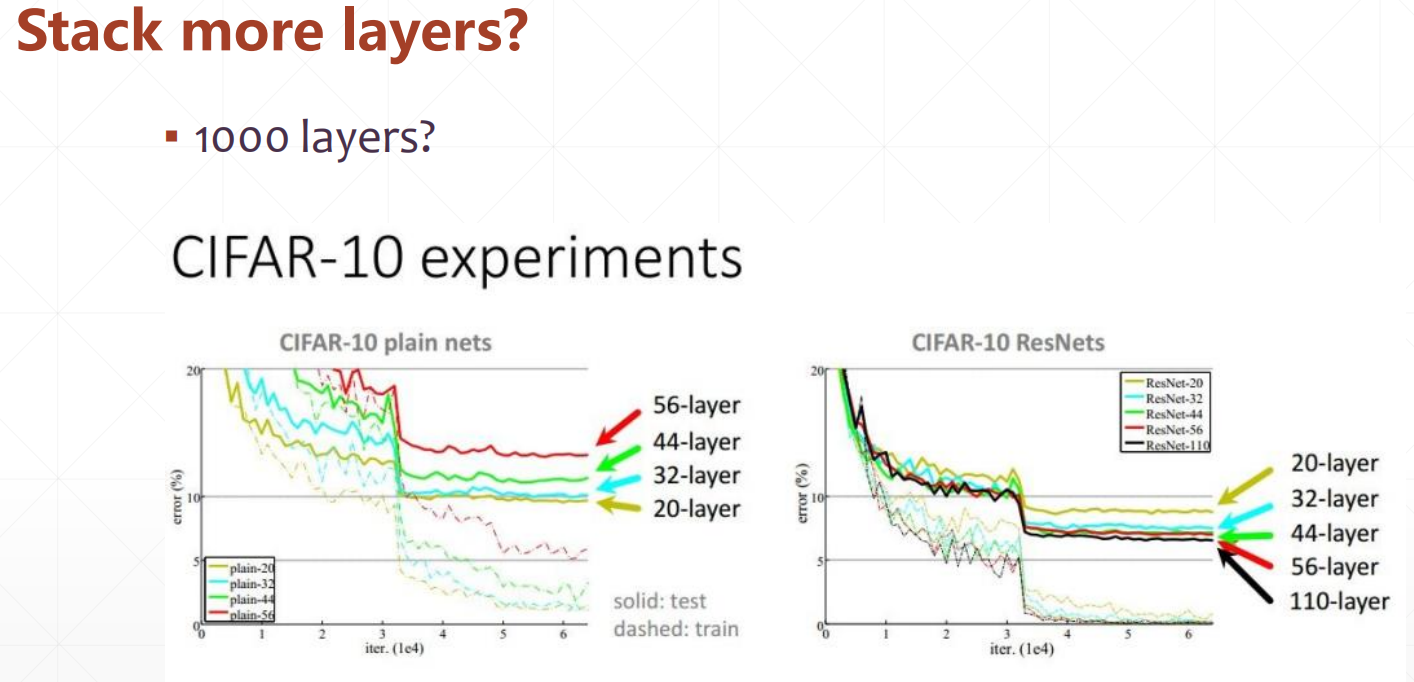
Deep residual network ResNet, DenseNet


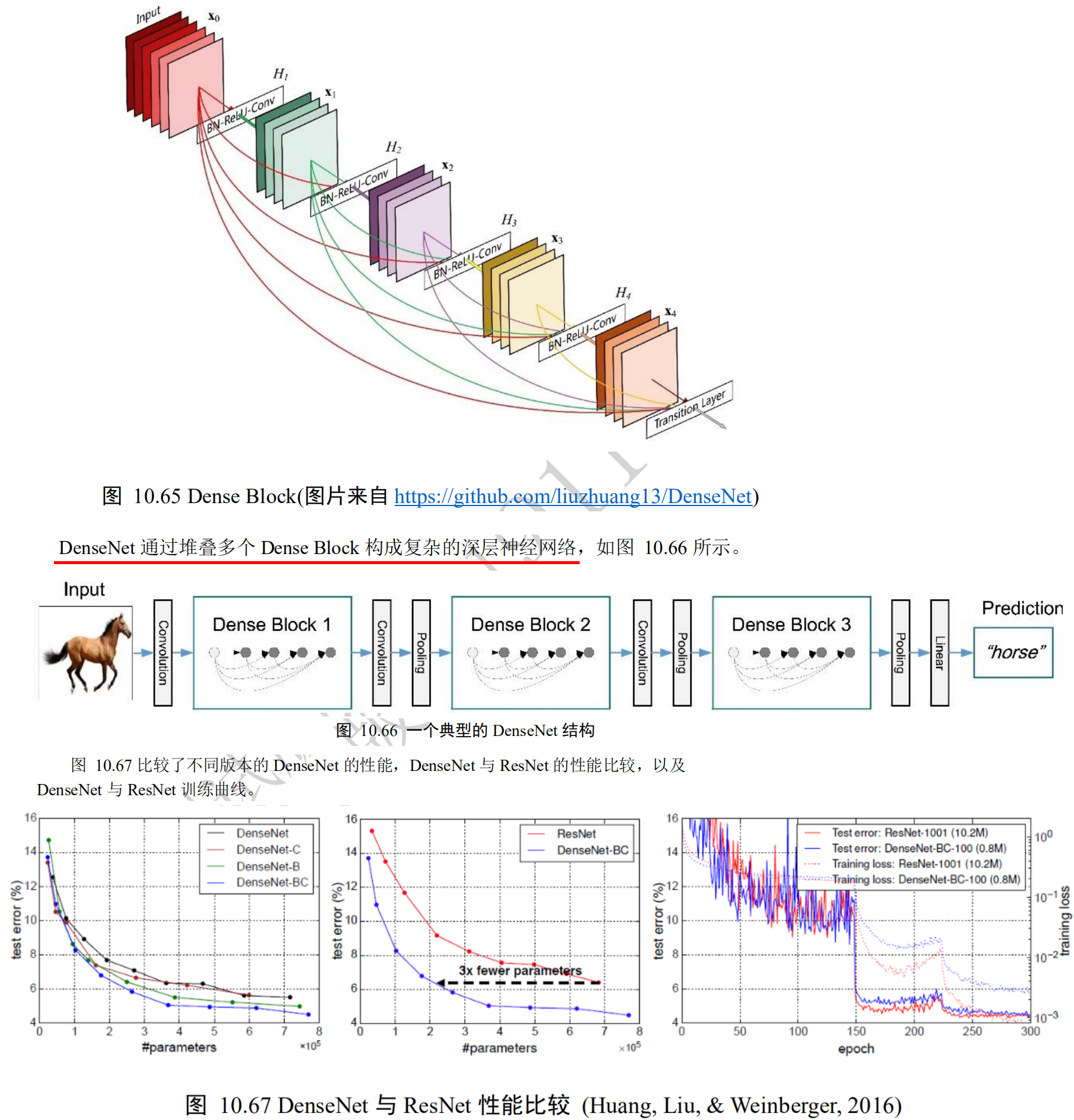
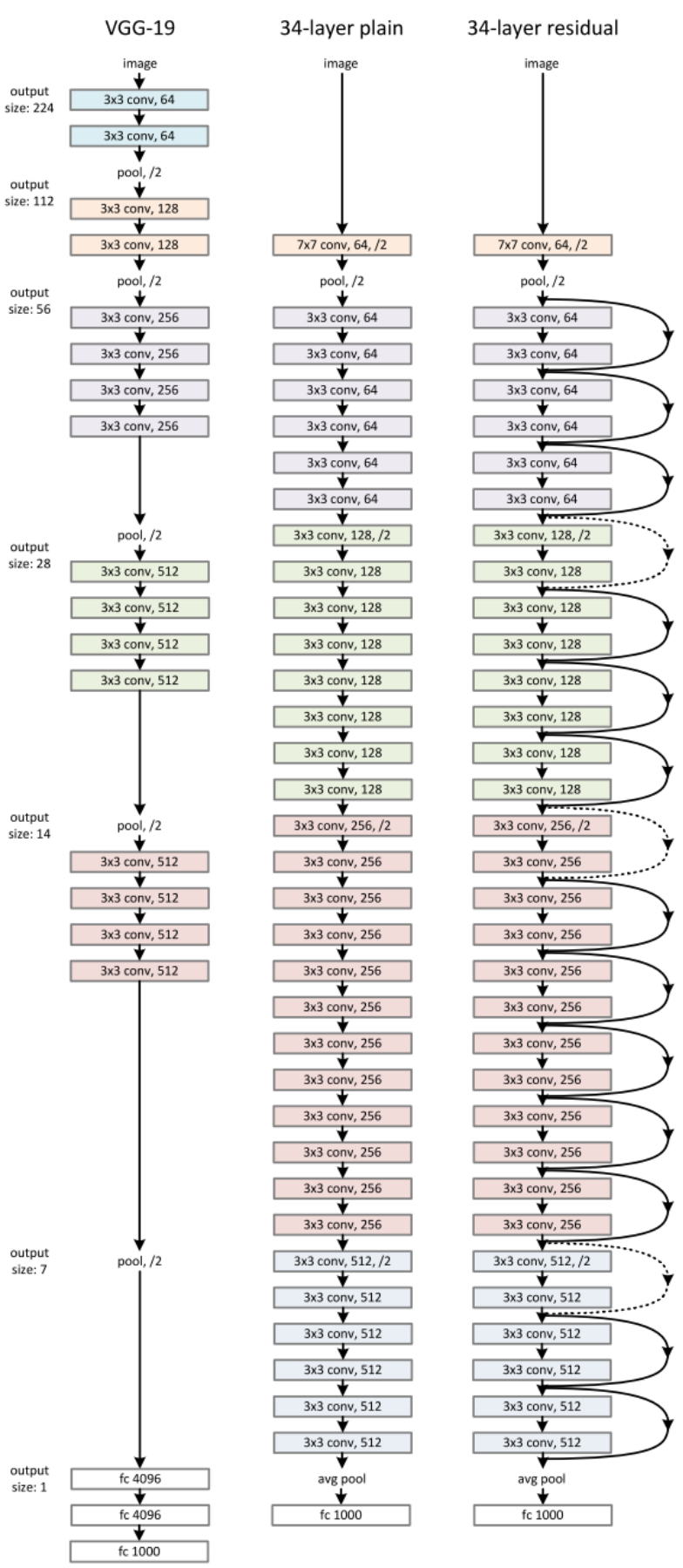
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
(x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
x_train, x_test = x_train.astype(np.float32)/255., x_test.astype(np.float32)/255.
# [b, 28, 28] => [b, 28, 28, 1]
x_train, x_test = np.expand_dims(x_train, axis=3), np.expand_dims(x_test, axis=3)
# one hot encode the labels. convert back to numpy as we cannot use a combination of numpy
# and tensors as input to keras
y_train_ohe = tf.one_hot(y_train, depth=10).numpy()
y_test_ohe = tf.one_hot(y_test, depth=10).numpy()
print(x_train.shape, y_train.shape) #(60000, 28, 28, 1) (60000,)
print(x_test.shape, y_test.shape) #(10000, 28, 28, 1) (10000,)
# 3x3 convolution
def conv3x3(channels, stride=1, kernel=(3, 3)):
return keras.layers.Conv2D(channels, kernel, strides=stride, padding='same', use_bias=False, kernel_initializer=tf.random_normal_initializer())
class ResnetBlock(keras.Model):
def __init__(self, channels, strides=1, residual_path=False):
super(ResnetBlock, self).__init__()
self.channels = channels
self.strides = strides
self.residual_path = residual_path
self.conv1 = conv3x3(channels, strides)
self.bn1 = keras.layers.BatchNormalization()
self.conv2 = conv3x3(channels)
self.bn2 = keras.layers.BatchNormalization()
if residual_path:
#In fact, the output of the last layer in the previous block is connected as a residual,
#Add the two elements to the output of the current layer in the current block
self.down_conv = conv3x3(channels, strides, kernel=(1, 1))
self.down_bn = tf.keras.layers.BatchNormalization()
def call(self, inputs, training=None):
residual = inputs
x = self.bn1(inputs, training=training)
x = tf.nn.relu(x)
x = self.conv1(x)
x = self.bn2(x, training=training)
x = tf.nn.relu(x)
x = self.conv2(x)
# this module can be added into self.
# however, module in for can not be added.
if self.residual_path:
residual = self.down_bn(inputs, training=training)
residual = tf.nn.relu(residual)
residual = self.down_conv(residual)
x = x + residual
return x
class ResNet(keras.Model):
def __init__(self, block_list, num_classes, initial_filters=16, **kwargs):
super(ResNet, self).__init__(**kwargs)
self.num_blocks = len(block_list)
self.block_list = block_list
self.in_channels = initial_filters
self.out_channels = initial_filters
self.conv_initial = conv3x3(self.out_channels)
self.blocks = keras.models.Sequential(name='dynamic-blocks')
# build all the blocks
#Traverse each block
for block_id in range(len(block_list)):
#Traverse the layer layer in each block
for layer_id in range(block_list[block_id]):
#Only when it is not the first block and the first layer of a block, that is, when the first layer of a new block is added, the following judgment will be performed
#The current program only performs the following judgment when the block ID is 1 and the layer ID is 0, or the block ID is 2 and the layer ID is 0, that is, as long as the first layer of a new block is added
if block_id != 0 and layer_id == 0:
#Because the number of out ﹣ channels * = 2 output channels is doubled at this time, set strings = 2 to halve the height and width of the output. At the same time, set reset ﹣ path = true,
#In fact, the output of the last layer in the previous block is connected as a residual,
#Add the two elements to the output of the current layer in the current block
block = ResnetBlock(self.out_channels, strides=2, residual_path=True)
#As long as it is any layer layer in the first block, or it is not the first layer in the first block, the following judgment will be performed
#The current program only performs the following judgment when the block ID is 0 and the layer ID is 0 or 1, or the block ID is 1 or 2 and the layer ID is 1
else:
#The current program will not execute the following judgment code
if self.in_channels != self.out_channels:
residual_path = True
#The current program only performs the following judgment when the block ID is 0 and the layer ID is 0 or 1, or the block ID is 1 or 2 and the layer ID is 1
else:
residual_path = False
#The parameter residual path of this code of the current program will only be False
block = ResnetBlock(self.out_channels, residual_path=residual_path)
self.in_channels = self.out_channels
self.blocks.add(block)
self.out_channels *= 2 #As long as you add a new block, the number of output channels for the new block will double
self.final_bn = keras.layers.BatchNormalization()
self.avg_pool = keras.layers.GlobalAveragePooling2D()
self.fc = keras.layers.Dense(num_classes)
def call(self, inputs, training=None):
out = self.conv_initial(inputs)
out = self.blocks(out, training=training)
out = self.final_bn(out, training=training)
out = tf.nn.relu(out)
out = self.avg_pool(out)
out = self.fc(out)
return out
def main():
num_classes = 10 #Class number
batch_size = 32
epochs = 1
# build model and optimizer
#Build 6 block blocks, and each block block has 2 layer layers
model = ResNet([2, 2, 2], num_classes)
model.compile(optimizer=keras.optimizers.Adam(0.001),
loss=keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.build(input_shape=(None, 28, 28, 1))
print("Number of variables in the model :", len(model.variables))
model.summary()
# train
model.fit(x_train, y_train_ohe, batch_size=batch_size, epochs=epochs, validation_data=(x_test, y_test_ohe), verbose=1)
# evaluate on test set
#evaluate output loss and accuracy when evaluating and verifying
scores = model.evaluate(x_test, y_test_ohe, batch_size, verbose=1)
print("Final test loss and accuracy :", scores)
if __name__ == '__main__':
main()

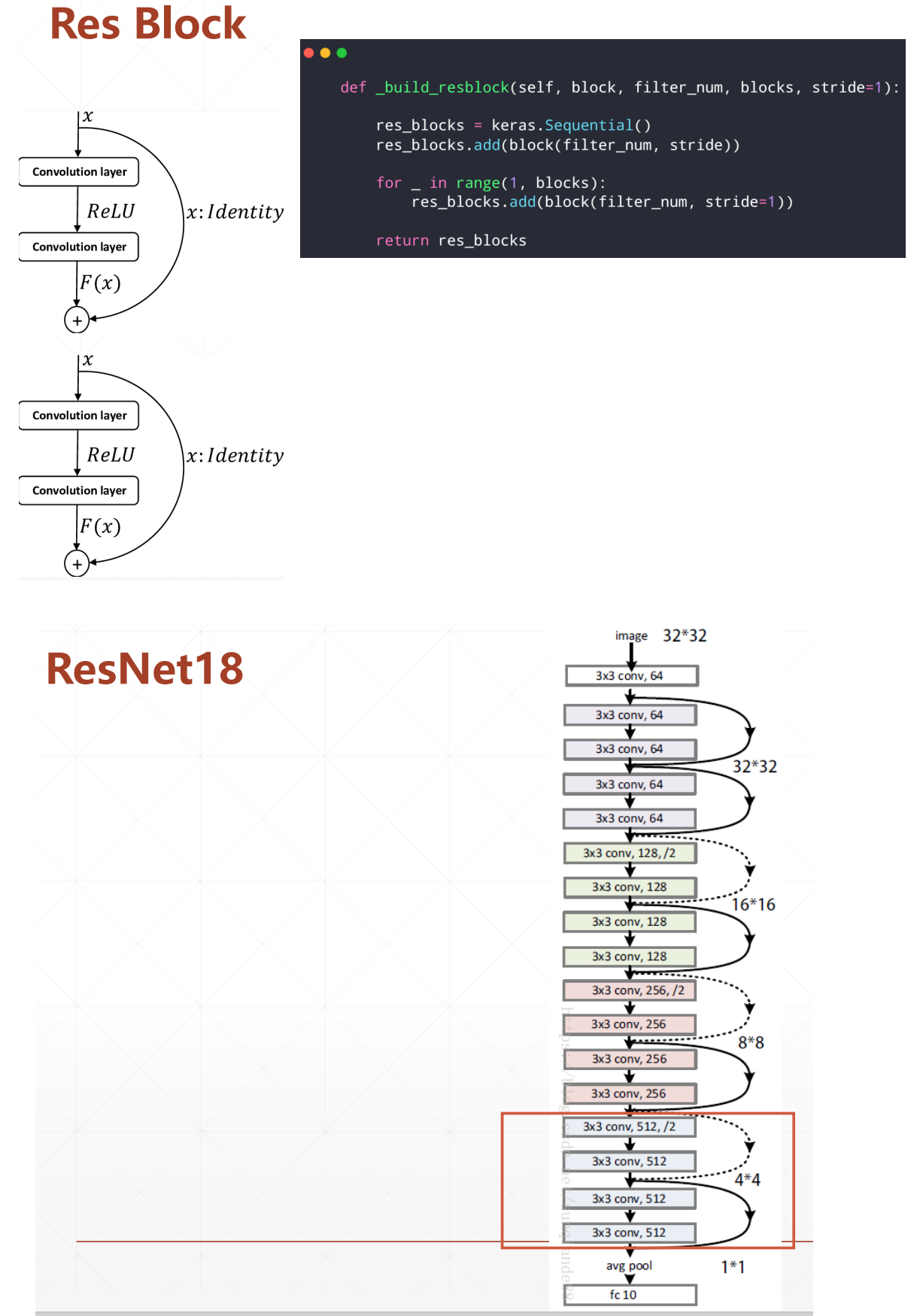
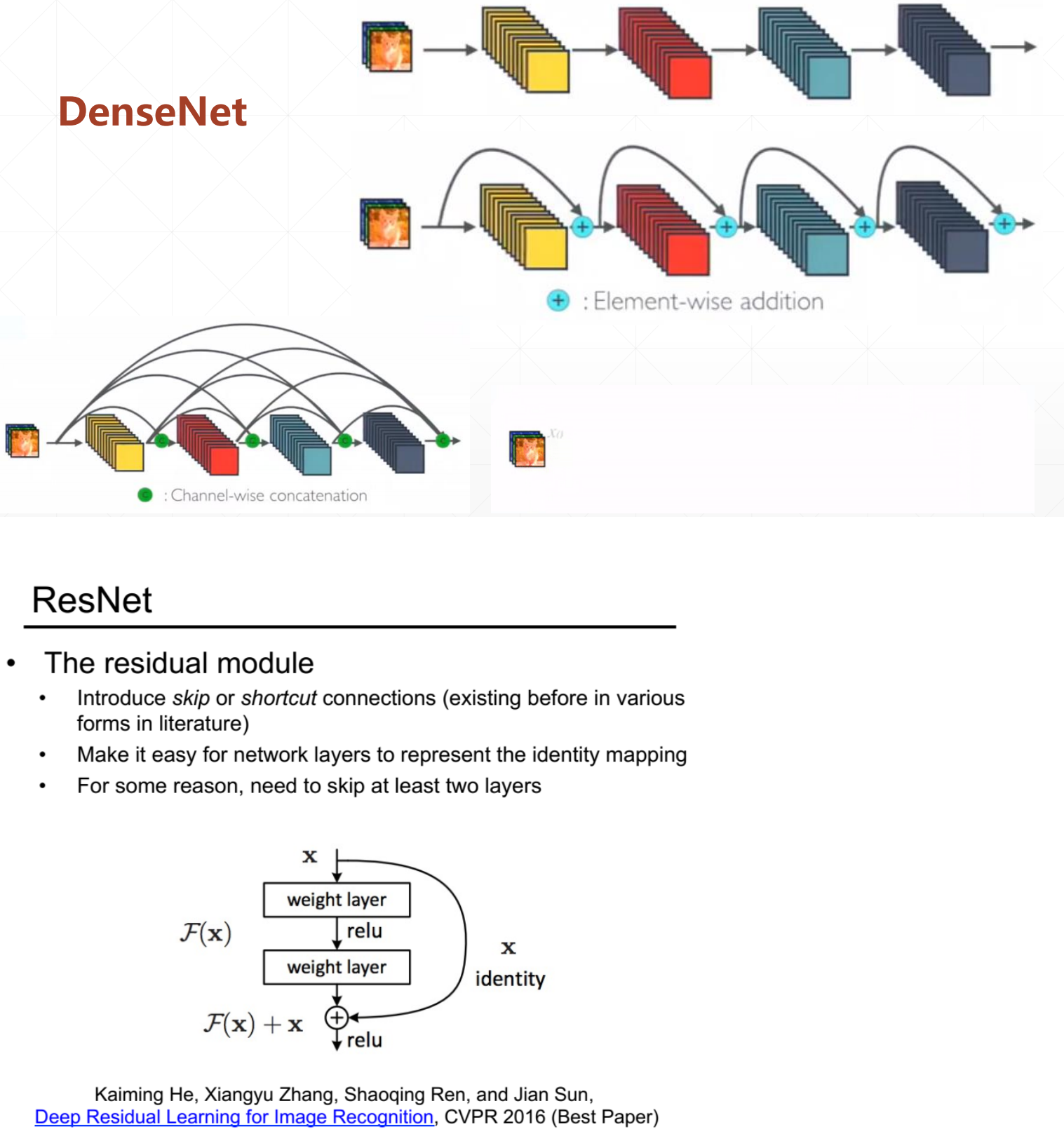
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, Sequential
class BasicBlock(layers.Layer):
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization()
if stride != 1:
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else:
self.downsample = lambda x:x
def call(self, inputs, training=None):
# [b, h, w, c]
out = self.conv1(inputs)
out = self.bn1(out,training=training)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out,training=training)
identity = self.downsample(inputs)
output = layers.add([out, identity])
output = tf.nn.relu(output)
return output
class ResNet(keras.Model):
def __init__(self, layer_dims, num_classes=100): # [2, 2, 2, 2]
super(ResNet, self).__init__()
self.stem = Sequential([layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# output: [b, 512, h, w],
self.avgpool = layers.GlobalAveragePooling2D()
self.fc = layers.Dense(num_classes)
def call(self, inputs, training=None):
x = self.stem(inputs,training=training)
x = self.layer1(x,training=training)
x = self.layer2(x,training=training)
x = self.layer3(x,training=training)
x = self.layer4(x,training=training)
# [b, c]
x = self.avgpool(x)
# [b, 100]
x = self.fc(x)
return x
def build_resblock(self, filter_num, blocks, stride=1):
res_blocks = Sequential()
# may down sample
res_blocks.add(BasicBlock(filter_num, stride))
for _ in range(1, blocks):
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocks
def resnet18():
return ResNet([2, 2, 2, 2])
def resnet34():
return ResNet([3, 4, 6, 3])
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
from resnet import resnet18
tf.random.set_seed(2345)
def preprocess(x, y):
# [-1~1]
x = tf.cast(x, dtype=tf.float32) / 255. - 0.5
y = tf.cast(y, dtype=tf.int32)
return x,y
(x,y), (x_test, y_test) = datasets.cifar100.load_data()
y = tf.squeeze(y, axis=1)
y_test = tf.squeeze(y_test, axis=1)
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x,y))
train_db = train_db.shuffle(1000).map(preprocess).batch(512)
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_db = test_db.map(preprocess).batch(512)
sample = next(iter(train_db))
print('sample:', sample[0].shape, sample[1].shape, tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
def main():
# [b, 32, 32, 3] => [b, 1, 1, 512]
model = resnet18()
model.build(input_shape=(None, 32, 32, 3))
model.summary()
optimizer = optimizers.Adam(lr=1e-3)
for epoch in range(500):
for step, (x,y) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 100]
logits = model(x,training=True)
# [b] => [b, 100]
y_onehot = tf.one_hot(y, depth=100)
# compute loss
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step %50 == 0:
print(epoch, step, 'loss:', float(loss))
total_num = 0
total_correct = 0
for x,y in test_db:
logits = model(x,training=False)
prob = tf.nn.softmax(logits, axis=1) #Convert output to probability
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch, 'acc:', acc)
if __name__ == '__main__':
main()
CIFAR10 and ResNet18



class BasicBlock(layers.Layer):
# Residual module class
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
# f(x) contains two ordinary convolution layers, creating convolution layer 1
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
# Create convolution layer 2
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization()
# Insert identity layer
if stride != 1:
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else:
# Otherwise, connect directly
self.downsample = lambda x:x
def call(self, inputs, training=None):
# Forward propagation function
out = self.conv1(inputs) # Through the first convolution layer
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out) # Through the second convolution layer
out = self.bn2(out)
# Input is converted by identity()
identity = self.downsample(inputs)
# f(x)+x operation
output = layers.add([out, identity])
# By activating the function and returning
output = tf.nn.relu(output)
return output
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, Sequential
class BasicBlock(layers.Layer):
# Residual module
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
# First convolution unit
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
# Second convolution unit
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization()
# shape matching by 1x1 convolution
if stride != 1:
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else:
# shape matching, direct shorting
self.downsample = lambda x:x
def call(self, inputs, training=None):
# [b, h, w, c], through the first convolution unit
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
# Through the second convolution unit
out = self.conv2(out)
out = self.bn2(out)
# Through identity module
identity = self.downsample(inputs)
# 2 paths output add directly
output = layers.add([out, identity])
output = tf.nn.relu(output) # Activation function
return output
class ResNet(keras.Model):
# Generic ResNet implementation class
def __init__(self, layer_dims, num_classes=10): # [2, 2, 2, 2]
super(ResNet, self).__init__()
# Root network, preprocessing
self.stem = Sequential([layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
# Stack 4 blocks, each block contains multiple basicblocks, with different setting steps
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# Reduce the height and width to 1x1 through the Pooling layer
self.avgpool = layers.GlobalAveragePooling2D()
# Finally, connect a full connection layer classification
self.fc = layers.Dense(num_classes)
def call(self, inputs, training=None):
# Through the root network
x = self.stem(inputs)
# 4 modules at a time
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# Through the pool layer
x = self.avgpool(x)
# Through full connection layer
x = self.fc(x)
return x
def build_resblock(self, filter_num, blocks, stride=1):
# Auxiliary functions, stacking filter ﹣ num basicblocks
res_blocks = Sequential()
# Only the step size of the first BasicBlock may not be 1, so lower sampling is implemented
res_blocks.add(BasicBlock(filter_num, stride))
for _ in range(1, blocks):
#The other BasicBlock steps are all 1
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocks
def resnet18():
# Realize different ResNet by adjusting the number and configuration of basicblocks in the module
return ResNet([2, 2, 2, 2])
def resnet34():
# Realize different ResNet by adjusting the number and configuration of basicblocks in the module
return ResNet([3, 4, 6, 3])
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
import os
from resnet import resnet18
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
tf.random.set_seed(2345)
def preprocess(x, y):
# Map data to - 1 ~ 1
x = 2*tf.cast(x, dtype=tf.float32) / 255. - 1
y = tf.cast(y, dtype=tf.int32) # Type conversion
return x,y
(x,y), (x_test, y_test) = datasets.cifar10.load_data() # Load dataset
y = tf.squeeze(y, axis=1) # Delete unnecessary dimensions
y_test = tf.squeeze(y_test, axis=1) # Delete unnecessary dimensions
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x,y)) # Build a training set
# Random break-up, pretreatment, batch
train_db = train_db.shuffle(1000).map(preprocess).batch(512)
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test)) #Build test set
# Random break-up, pretreatment, batch
test_db = test_db.map(preprocess).batch(512)
# Take a sample
sample = next(iter(train_db))
print('sample:', sample[0].shape, sample[1].shape, tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
def main():
# [b, 32, 32, 3] => [b, 1, 1, 512]
model = resnet18() # ResNet18 network
model.build(input_shape=(None, 32, 32, 3))
model.summary() # Statistical network parameters
optimizer = optimizers.Adam(lr=1e-4) # Build optimizer
for epoch in range(100): # Training epoch
for step, (x,y) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] = > [b, 10], forward propagation
logits = model(x)
# [b] = > [b, 10], one hot code
y_onehot = tf.one_hot(y, depth=10)
# Calculate cross entropy
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
# Calculate gradient information
grads = tape.gradient(loss, model.trainable_variables)
# Update network parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step %50 == 0:
print(epoch, step, 'loss:', float(loss))
total_num = 0
total_correct = 0
for x,y in test_db:
logits = model(x)
prob = tf.nn.softmax(logits, axis=1) #Convert output to probability
pred = tf.argmax(prob, axis=1) #Obtain the index value corresponding to the maximum probability value as the category number
pred = tf.cast(pred, dtype=tf.int32)
#Check whether the index value (category number) corresponding to the maximum probability value is consistent with the real label category number
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch, 'acc:', acc)
if __name__ == '__main__':
main()

import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
tf.random.set_seed(2345)
# 5 units of conv + max pooling
conv_layers = [
# unit 1
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 2
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 3
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 4
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 5
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same')
]
def preprocess(x, y):
# Standardize mapping data to [0 ~ 1]
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x,y
(x,y), (x_test, y_test) = datasets.cifar100.load_data()
y = tf.squeeze(y, axis=1)
y_test = tf.squeeze(y_test, axis=1)
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x,y))
train_db = train_db.shuffle(1000).map(preprocess).batch(128)
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_db = test_db.map(preprocess).batch(64)
sample = next(iter(train_db))
print('sample:', sample[0].shape, sample[1].shape, tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
def main():
# [b, 32, 32, 3] => [b, 1, 1, 512]
conv_net = Sequential(conv_layers)
fc_net = Sequential([
layers.Dense(256, activation=tf.nn.relu),
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(100, activation=None),
])
conv_net.build(input_shape=[None, 32, 32, 3])
fc_net.build(input_shape=[None, 512])
optimizer = optimizers.Adam(lr=1e-4)
# [1, 2] + [3, 4] => [1, 2, 3, 4]
variables = conv_net.trainable_variables + fc_net.trainable_variables
for epoch in range(50):
for step, (x,y) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 1, 1, 512]
out = conv_net(x)
# flatten, => [b, 512]
out = tf.reshape(out, [-1, 512])
# [b, 512] => [b, 100]
logits = fc_net(out)
# [b] => [b, 100]
y_onehot = tf.one_hot(y, depth=100)
# compute loss
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(grads, variables))
if step %100 == 0:
print(epoch, step, 'loss:', float(loss))
total_num = 0
total_correct = 0
for x,y in test_db:
out = conv_net(x)
out = tf.reshape(out, [-1, 512])
logits = fc_net(out)
prob = tf.nn.softmax(logits, axis=1) #softmax converts the output value to a probability value
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch, 'acc:', acc)
if __name__ == '__main__':
main()

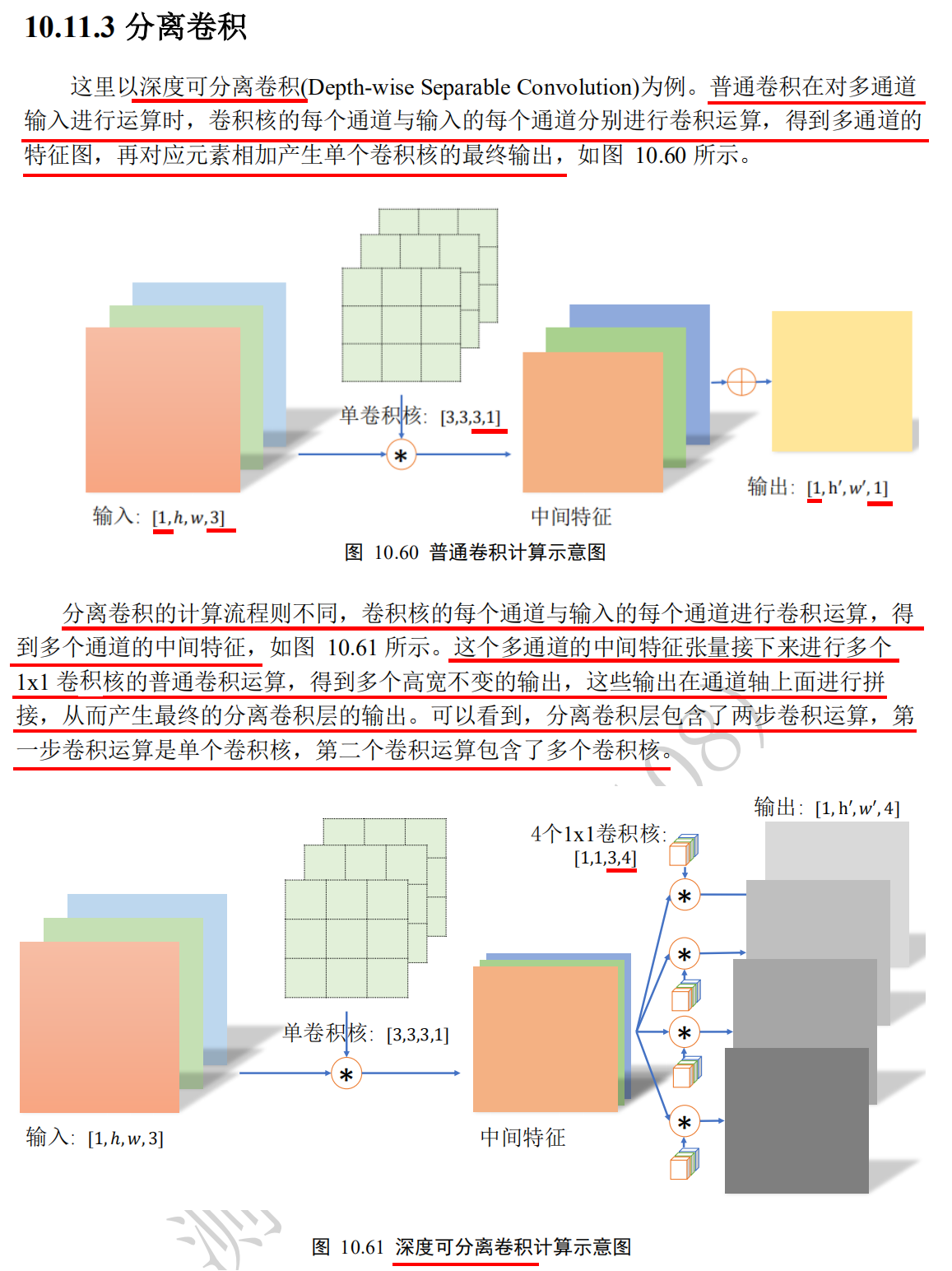
Convolution layers for different purposes
Cavity convolution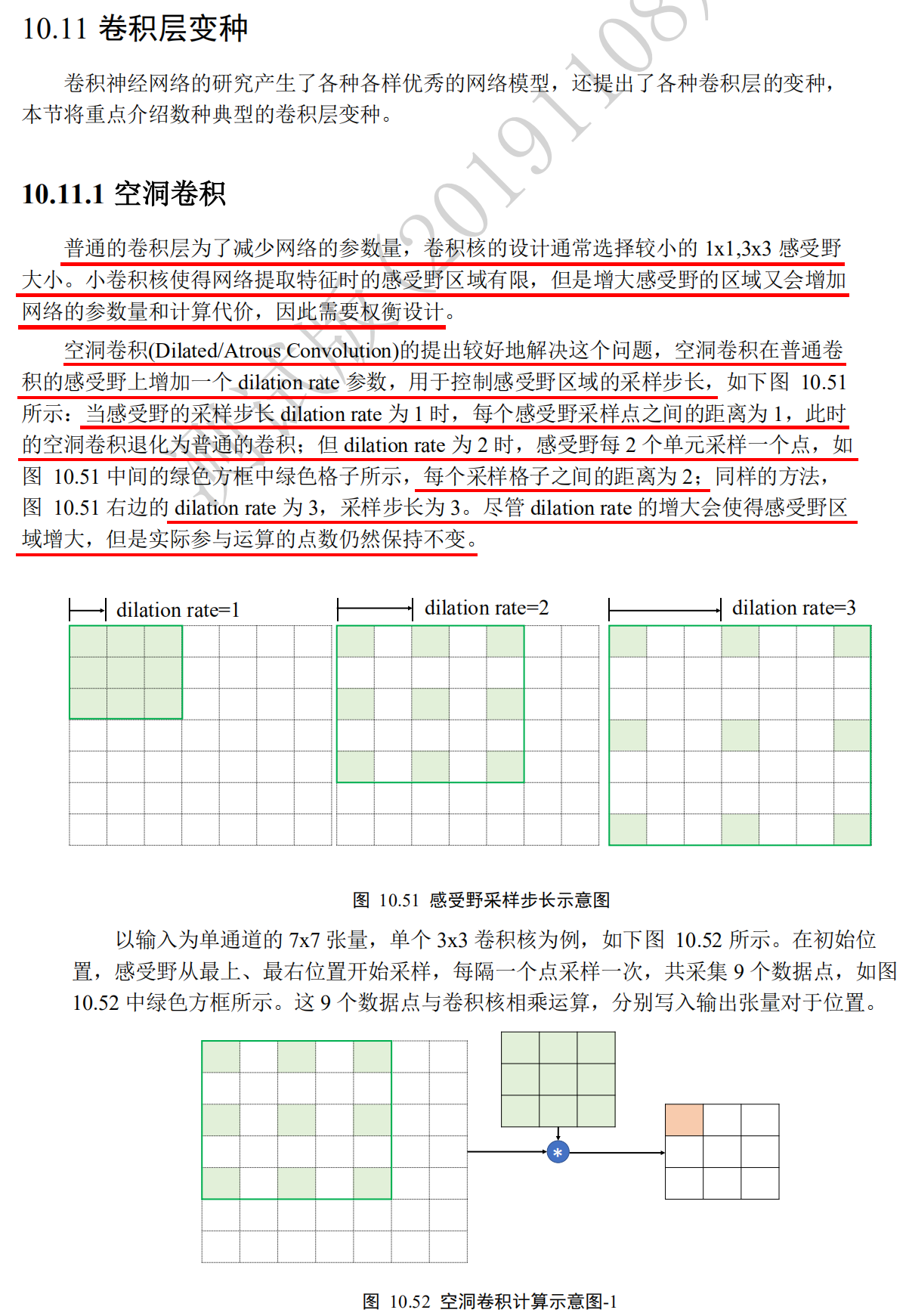

# Analog input x = tf.random.normal([1,7,7,1]) # Set the division rate parameter and a 3 x 3 convolution kernel. layer = layers.Conv2D(1,kernel_size=3,strides=1,dilation_rate=2) out = layer(x) # Forward computation out.shape
Transpose convolution conv2d transpose

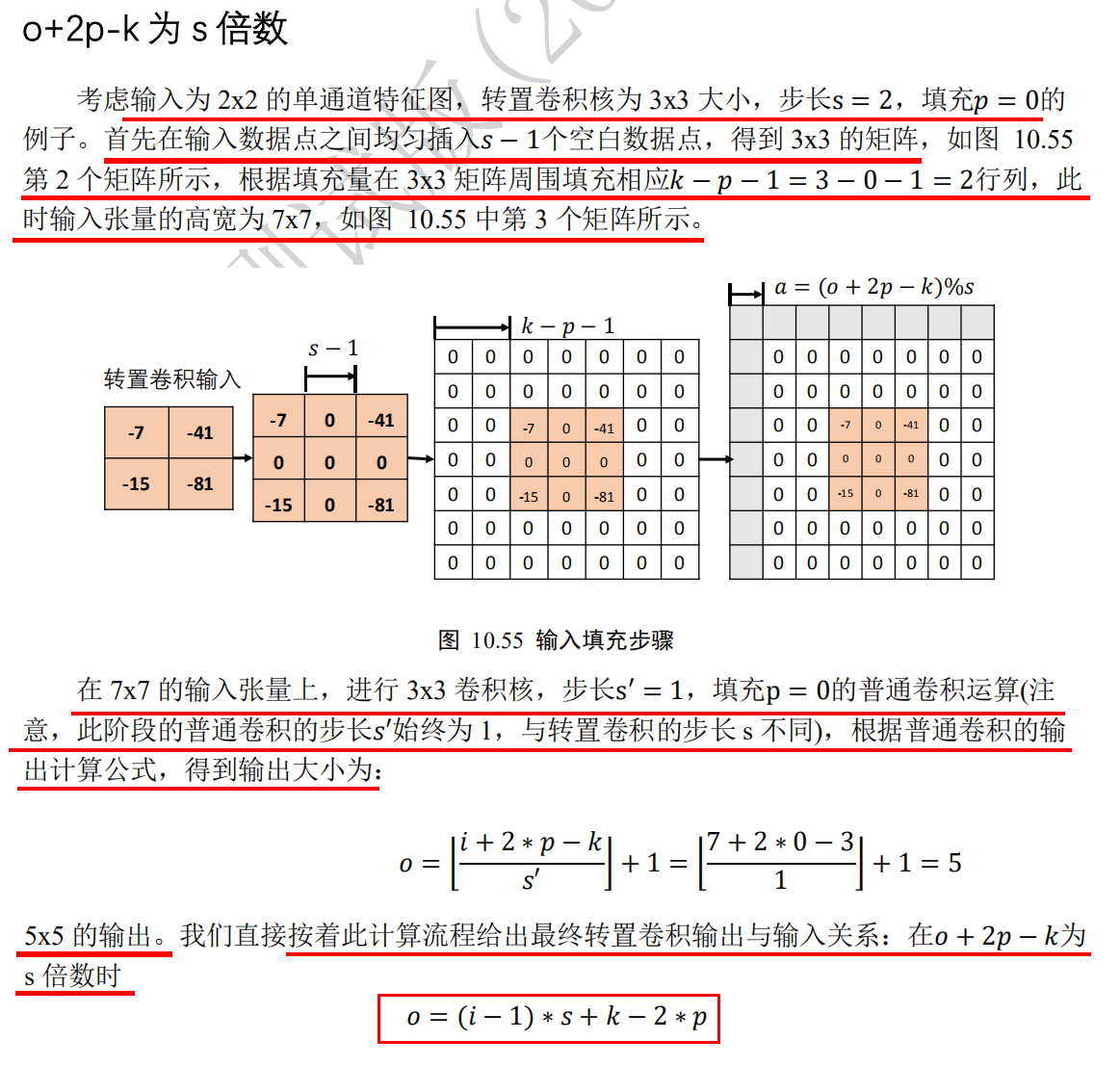
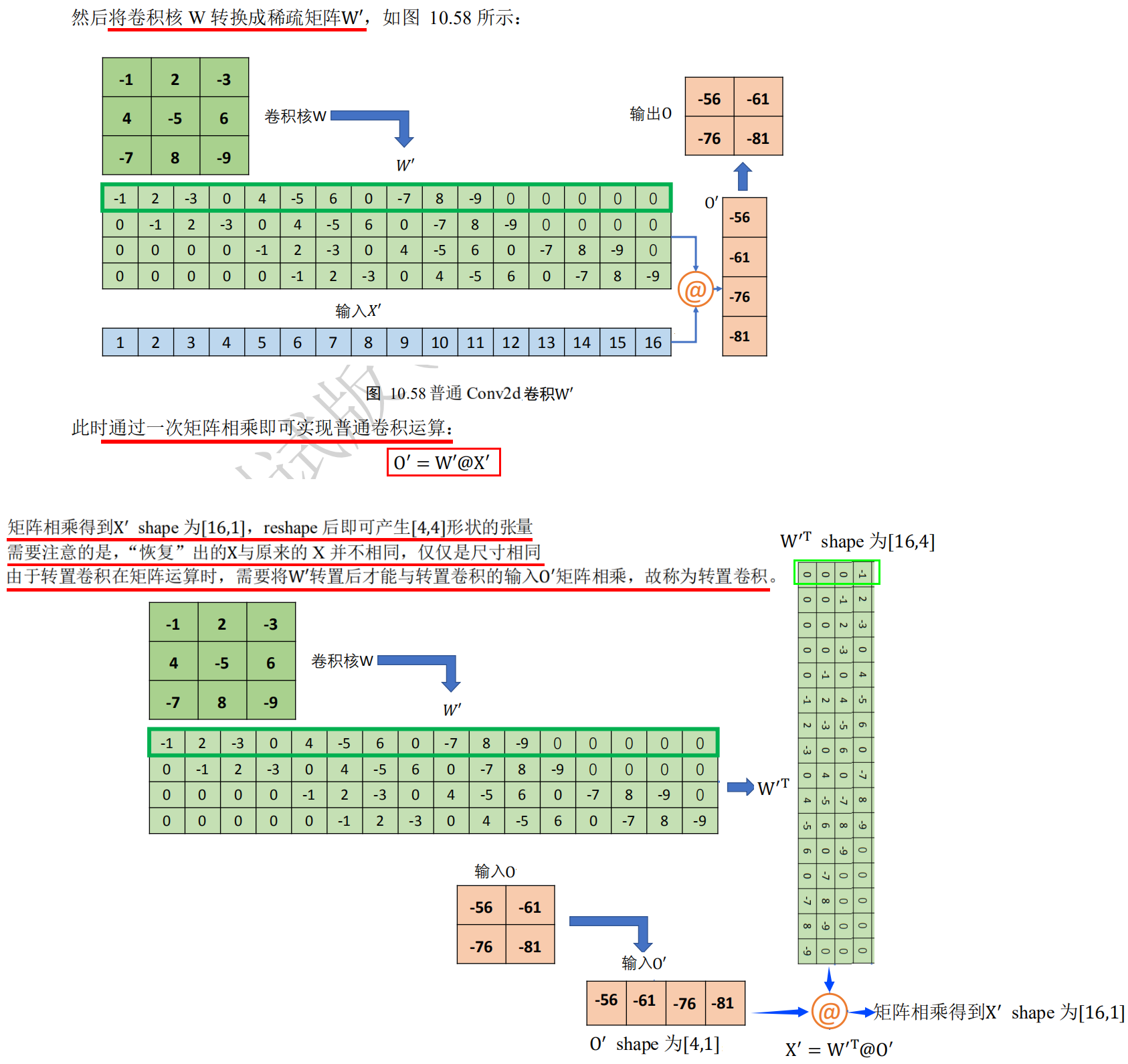
Principle of transposition convolution operation 1: o+2p-k is s multiple 1.o+2p-k is s multiple: o refers to the width / height of the output of the transposed convolution layer, P refers to the filling of the transposed convolution core, K refers to the width w / height h of the transposed convolution core, and s refers to the step length s of the transposed convolution core. 2. For example, for a single channel characteristic graph (i.e. transposed convolution input) with width w / height h of 2x2, the transposed convolution kernel has width w / height h of 3x3 (i.e. k), step s of 2, and fill p of 0. Then the transposed convolution calculation flow is as follows: 1. Step 1: evenly insert s-1 blank data points of transposed convolution kernel step size between data points in the input single channel characteristic graph, then change from 2x2 to 3x3 matrix. 2. Step 2: the k-p-1 corresponding to the transposition convolution kernel needs to be filled around the 3 x 3 matrix. It is concluded that the 3-0-1 = 2 rows and 2 columns should be filled around the 3 x 3 matrix, so the matrix will change from 3 x 3 to 7 x 7. 3. The third step is to perform the general convolution operation on the 7x7 matrix. The width w / height h of the convolution kernel is 3 x 3 (that is, k, which is the same as the width w / height h of the transposed convolution kernel), In this stage, the step s of the convolution kernel is always 1 (different from the step s of the transposition convolution), and the filling p is 0 (the same as the filling p of the transposition convolution kernel), According to the general convolution formula o = ⌊ (i+2*p-k)/s ⌋ + 1 (round up ⌈: the smallest integer larger than yourself, round down ⌊: the largest integer smaller than yourself), It is concluded that o = ⌊ (7 + 2 * 0-3) / 1 ⌋ + 1 = 5. 3. Conclusion: in the third step, the output 5x5 of the general convolution operation is the output of this transposition convolution operation, then the relationship between the input (2x2) and the output (5x5) of the transposition convolution operation is When o+2p-k i s s multiple, o=(i-1)*s+k-2*p, O refers to the width / height of the output of the transposed convolution layer, P refers to the filling of the transposed convolution core, K refers to the width / height h of the transposed convolution core, and S refers to the step length s of the transposed convolution core, i refers to the input of transposition convolution operation, then according to the above formula, when 5 + 2 * 0-3 = 2 is a multiple of 2, there is (2-1) × 2 + 3-2 * 0 = 5.

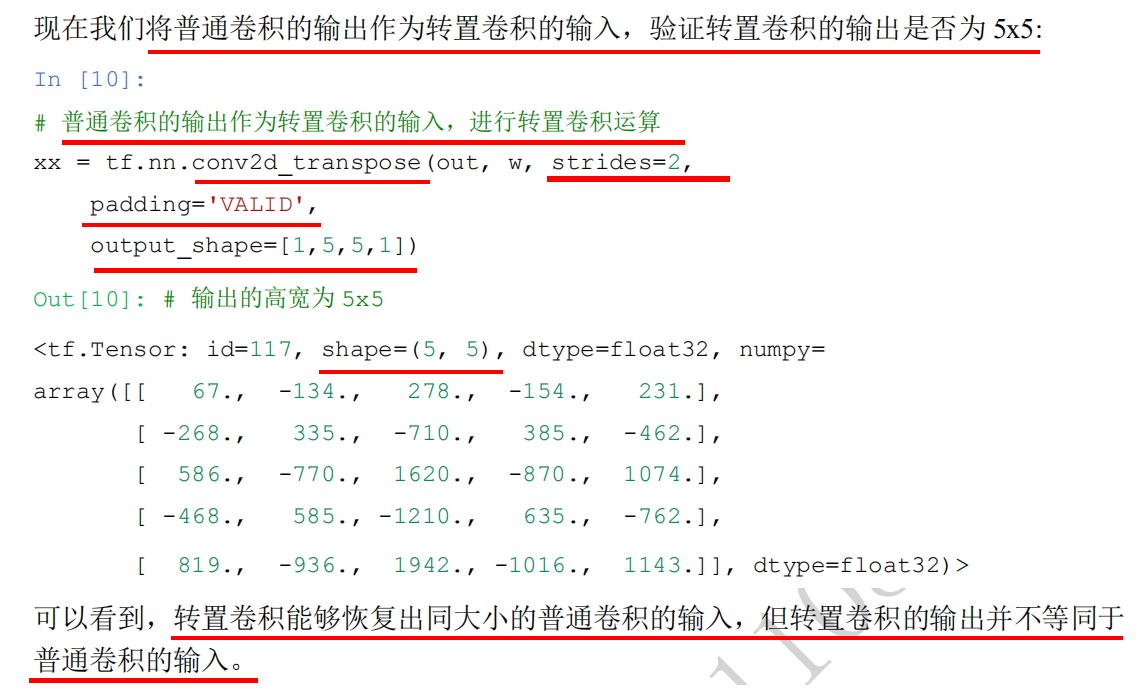
#Based on TensorFlow, the above example's transposition convolution operation is realized as follows: import tensorflow as tf # Create an X matrix with a height and width of 5x5 x = tf.range(25)+1 #<tf.Tensor: id=5, shape=(25,), dtype=int32, numpy= #array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, # 18, 19, 20, 21, 22, 23, 24, 25])> # Reshape is the tensor of legal dimension x = tf.reshape(x,[1,5,5,1]) x.shape #TensorShape([1, 5, 5, 1]) x = tf.cast(x, tf.float32) # Create a convolution kernel matrix with fixed content. The shape is [3, 3, 1, 1], i.e. [k,k, number of input channels, number of output channels] w = tf.constant([[-1,2,-3.],[4,-5,6],[-7,8,-9]]) w.shape #TensorShape([3, 3]) # Tensor adjusted to legal dimension w = tf.expand_dims(w,axis=2) w.shape #TensorShape([3, 3, 1]) w = tf.expand_dims(w,axis=3) w.shape #TensorShape([3, 3, 1, 1]), i.e. [k,k, number of input channels, number of output channels] #The padding parameter is used to set the padding. There are two values for this parameter: "valid" means no padding is used (only valid window position is used). The default value of padding parameter is "valid"; #"Same" means "the width and height of the output after filling is the same as the input". # Carry out general convolution operation out = tf.nn.conv2d(x,w,strides=2,padding='VALID') # Output height and width are 2x2 out #<tf.Tensor: id=14, shape=(1, 2, 2, 1), dtype=float32, numpy= #array([[[[ -67.], # [ -77.]], # [[-117.], # [-127.]]]], dtype=float32)> # Taking the output 2x2 ([1, 2, 2, 1]) of ordinary convolution as the input of transposition convolution, verify whether the output of transposition convolution is 5x5 ([1, 5, 5, 1]) # The output of general convolution is used as the input of transposition convolution to perform transposition convolution operation xx = tf.nn.conv2d_transpose(out, w, strides=2, padding='VALID', output_shape=[1,5,5,1]) # The output is 5x5 ([1,5,5,1]). Transposition convolution can restore the output of ordinary convolution to the input of ordinary convolution, but the output of transposition convolution is not equal to the input of ordinary convolution xx.shape #TensorShape([1, 5, 5, 1])

#When the input width of the general convolution operation is 5x5 or 6x6, the output is the same 2x2 import tensorflow as tf # Create a convolution kernel matrix with fixed content. The shape is [3, 3, 1, 1], i.e. [k,k, number of input channels, number of output channels] w = tf.constant([[-1,2,-3.],[4,-5,6],[-7,8,-9]]) # Tensor adjusted to legal dimension w = tf.expand_dims(w,axis=2) w.shape #TensorShape([3, 3, 1]) w = tf.expand_dims(w,axis=3) w.shape #TensorShape([3, 3, 1, 1]), i.e. [k,k, number of input channels, number of output channels] x = tf.random.normal([1,6,6,1]) #The padding parameter is used to set the padding. There are two values for this parameter: "valid" means no padding is used (only valid window position is used). The default value of padding parameter is "valid"; #"Same" means "the width and height of the output after filling is the same as the input". padding='SAME 'only when strings = 1 is the same size of output and input. # 6x6 input is convoluted out = tf.nn.conv2d(x,w, strides=2, padding='VALID') out.shape #TensorShape([1, 2, 2, 1]) #When the height and width of the input are 5x5 or 6x6, the output is the same 2x2 x = tf.random.normal([1,5,5,1]) # 6x6 input is convoluted out = tf.nn.conv2d(x,w, strides=2, padding='VALID') out.shape #TensorShape([1, 2, 2, 1]) #When the height and width of the input are 5x5 or 6x6, the output is the same 2x2
1. Ordinary convolution formula o = ⌊ (i+2*p-k)/s ⌋ + 1 (round up ⌈: the smallest integer larger than yourself, round down ⌊: the largest integer smaller than yourself) For example, a single channel characteristic graph (i.e. input I of ordinary convolution operation) with width w / height h of 5x5 or 6x6, convolution kernel with width w / height h of 3x3 (i.e. k), step s of 2 (step must be greater than 1), filling p of 0, output o of ordinary convolution operation are 2x2, When the step size s is greater than 1, the final rounding down will cause a variety of different input size i to correspond to the same convolution output size o. For example, if the input i of general convolution is 5, then⌊ (5 + 2 * 0-3) / 2 ⌋ + 1 = 2; if the input i of general convolution is 6, then⌊ (6 + 2 * 0-3) / 2 ⌋ + 1 = 2. 2. Principle of transposition convolution 2: o+2p-k is not s multiple 1.o+2p-k is not a multiple of S: o refers to the width / height of the output of the transposed convolution layer, P refers to the filling of the transposed convolution core, K refers to the width w / height h of the transposed convolution core, and s refers to the step length s of the transposed convolution core. 2. In the ordinary convolution operation, as long as the step size s is greater than 1, a variety of different input size i will correspond to the same convolution output size o after rounding down, Therefore, in the transposition convolution operation, we naturally hope that the same input size i can be used to get different output size o after the transposition convolution operation, Therefore, it is necessary to fill row a and column a to realize the output o of different size of transposition convolution, so as to recover the output o of the same size corresponding to the input i of different size in the ordinary convolution. 3. For example, the width w / height h of the current ordinary convolution operation i s 5x5 or 6x6 for the single channel characteristic graph (i.e. the input I of the ordinary convolution operation), the width w / height h of the convolution core is 3x3 (i.e., k), the step S is 2 (the step must be greater than 1), and the filling p is 0, The output o of ordinary convolution operation is 2x2. Now, we want to realize the customized output of the convolution by 2x2 transposition input, which is 5x5 or 6x6, the filling p of the transposition core is 0, and the width w / height h of the transposition core is 3x3, The step size s of the transposed convolution kernel is 2. The following two steps are needed to achieve the above purpose: 1. Step 1: a=(o+2p-k)%s, a row and a column need to be filled to realize the output o of transposition convolution of different sizes, so as to recover the output o of the same size corresponding to the input i of different sizes in the ordinary convolution. For example, when the output of the transposition convolution is 5x5(o is 5), (5 + 2 * 0-3)% 2 = 0, i.e. fill 0 rows and 0 columns to achieve the transposition convolution output size o is 5x5. For example, when the output of transposition convolution is 6x6(o is 6), the output size o of transposition convolution is 6x6 (6 + 2 * 0-3)% 2 = 1. 2. Step 2: o=(i-1)*s+k-2*p+a, according to the calculated a row and a column to be filled in step 1, transpose the desired size o of convolution output. For example, if you want to output 5x5(o = 5) by transposing convolution, the calculated 0 rows and 0 columns to be filled: (2-1) * 2 + 3-2 * 0 + 0 = 5. For example, if you want to convert the convolution output to 6x6(o = 6), you need to fill in one row and one column: (2-1) * 2 + 3-2 * 0 + 1 = 6.

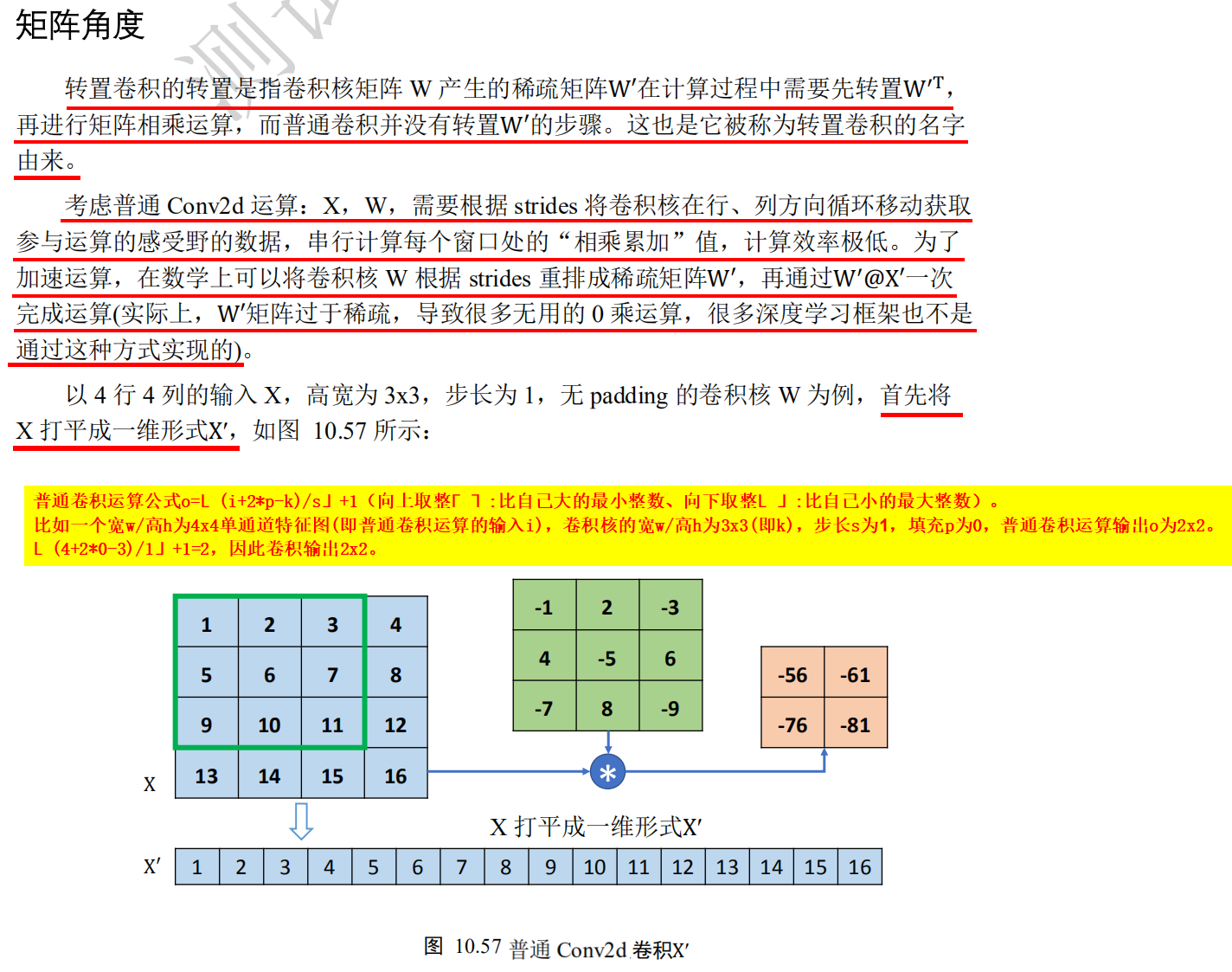
import tensorflow as tf # Create a convolution kernel matrix with fixed content. The shape is [3, 3, 1, 1], i.e. [k,k, number of input channels, number of output channels] w = tf.constant([[-1,2,-3.],[4,-5,6],[-7,8,-9]]) # Tensor adjusted to legal dimension w = tf.expand_dims(w,axis=2) w.shape #TensorShape([3, 3, 1]) w = tf.expand_dims(w,axis=3) w.shape #TensorShape([3, 3, 1, 1]), i.e. [k,k, number of input channels, number of output channels] x = tf.random.normal([1,6,6,1]) #The padding parameter is used to set the padding. There are two values for this parameter: "valid" means no padding is used (only valid window position is used). The default value of padding parameter is "valid"; #"Same" means "the width and height of the output after filling is the same as the input". padding='SAME 'only when strings = 1 is the same size of output and input. # 6x6 input is convoluted out = tf.nn.conv2d(x,w, strides=2, padding='VALID') out.shape #TensorShape([1, 2, 2, 1]) #When the height and width of the input are 5x5 or 6x6, the output is the same 2x2 x = tf.random.normal([1,5,5,1]) # 6x6 input is convoluted out = tf.nn.conv2d(x,w, strides=2, padding='VALID') out.shape #TensorShape([1, 2, 2, 1]) #When the height and width of the input are 5x5 or 6x6, the output is the same 2x2 #Just specify the output size, TensorFlow will automatically deduce the number of rows and columns to be filled xx = tf.nn.conv2d_transpose(out, w, strides=2, padding='VALID', output_shape=[1,6,6,1]) xx.shape #TensorShape([1, 6, 6, 1]) xx = tf.nn.conv2d_transpose(out, w, strides=2, padding='VALID', output_shape=[1,5,5,1]) xx.shape #TensorShape([1, 5, 5, 1])


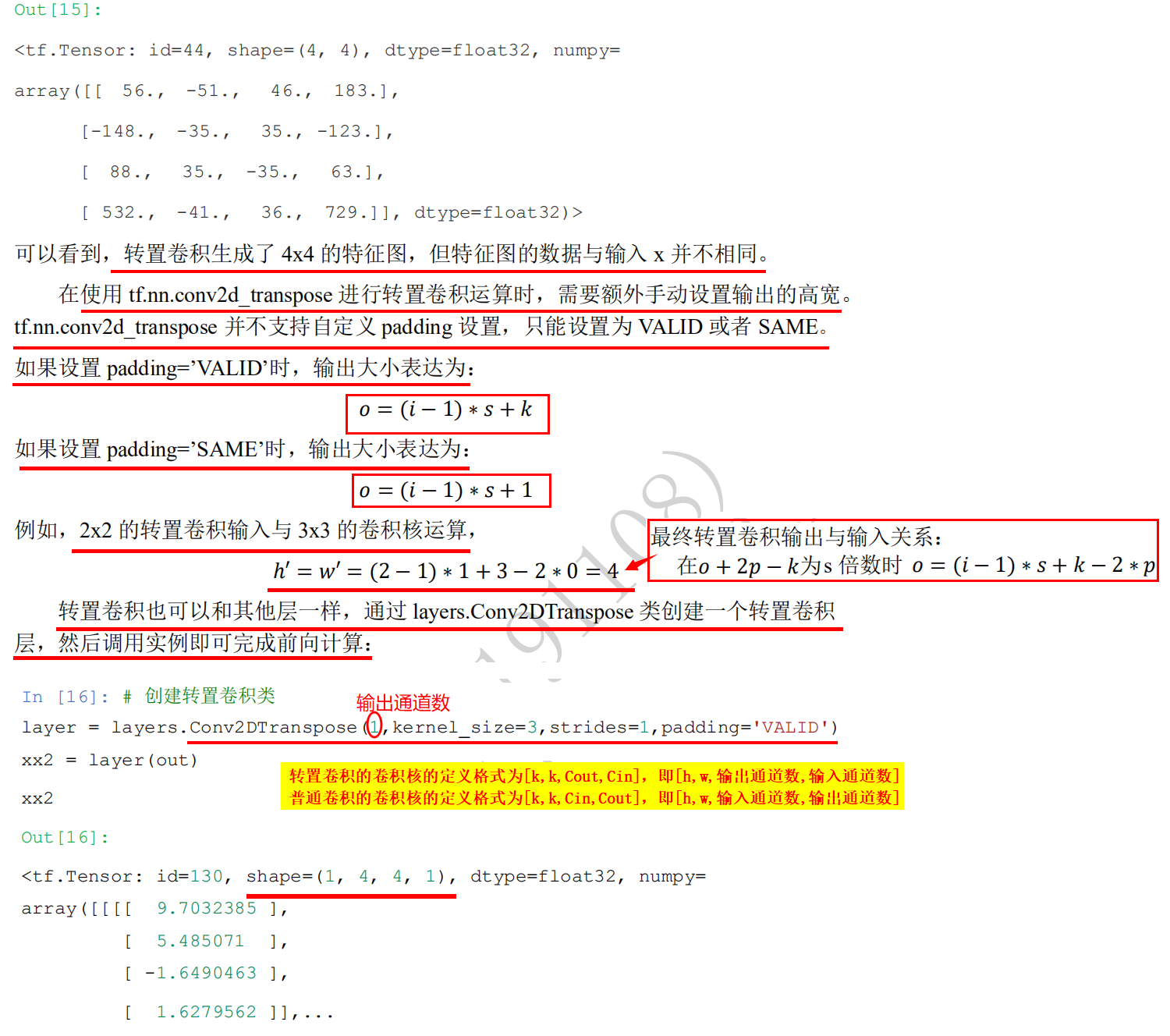
# Create X matrix x = tf.range(25)+1 # Reshape is the tensor of legal dimension x = tf.reshape(x,[1,5,5,1]) x = tf.cast(x, tf.float32) # Creating convolution kernel matrix with fixed content w = tf.constant([[-1,2,-3.],[4,-5,6],[-7,8,-9]]) # Tensor adjusted to legal dimension w = tf.expand_dims(w,axis=2) w = tf.expand_dims(w,axis=3) # Carry out general convolution operation out = tf.nn.conv2d(x,w,strides=2,padding='VALID') out # The output of general convolution is used as the input of transposition convolution to perform transposition convolution operation xx = tf.nn.conv2d_transpose(out, w, strides=2, padding='VALID', output_shape=[1,5,5,1]) #<tf.Tensor: id=117, shape=(5, 5), dtype=float32, numpy= #array([[ 67., -134., 278., -154., 231.], # [ -268., 335., -710., 385., -462.], # [ 586., -770., 1620., -870., 1074.], # [ -468., 585., -1210., 635., -762.], # [ 819., -936., 1942., -1016., 1143.]], dtype=float32)> x = tf.random.normal([1,6,6,1]) # 6x6 input is convoluted out = tf.nn.conv2d(x,w,strides=2,padding='VALID') out #<tf.Tensor: id=21, shape=(1, 2, 2, 1), dtype=float32, numpy= #array([[[[ 20.438847 ], # [ 19.160788 ]], # [[ 0.8098897], # [-28.30303 ]]]], dtype=float32)> # Restore 6x6 size xx = tf.nn.conv2d_transpose(out, w, strides=2, padding='VALID', output_shape=[1,6,6,1]) xx # Create a transpose convolution class layer = layers.Conv2DTranspose(1,kernel_size=3,strides=2,padding='VALID') xx2 = layer(out) xx2
Keras depth separable convolution
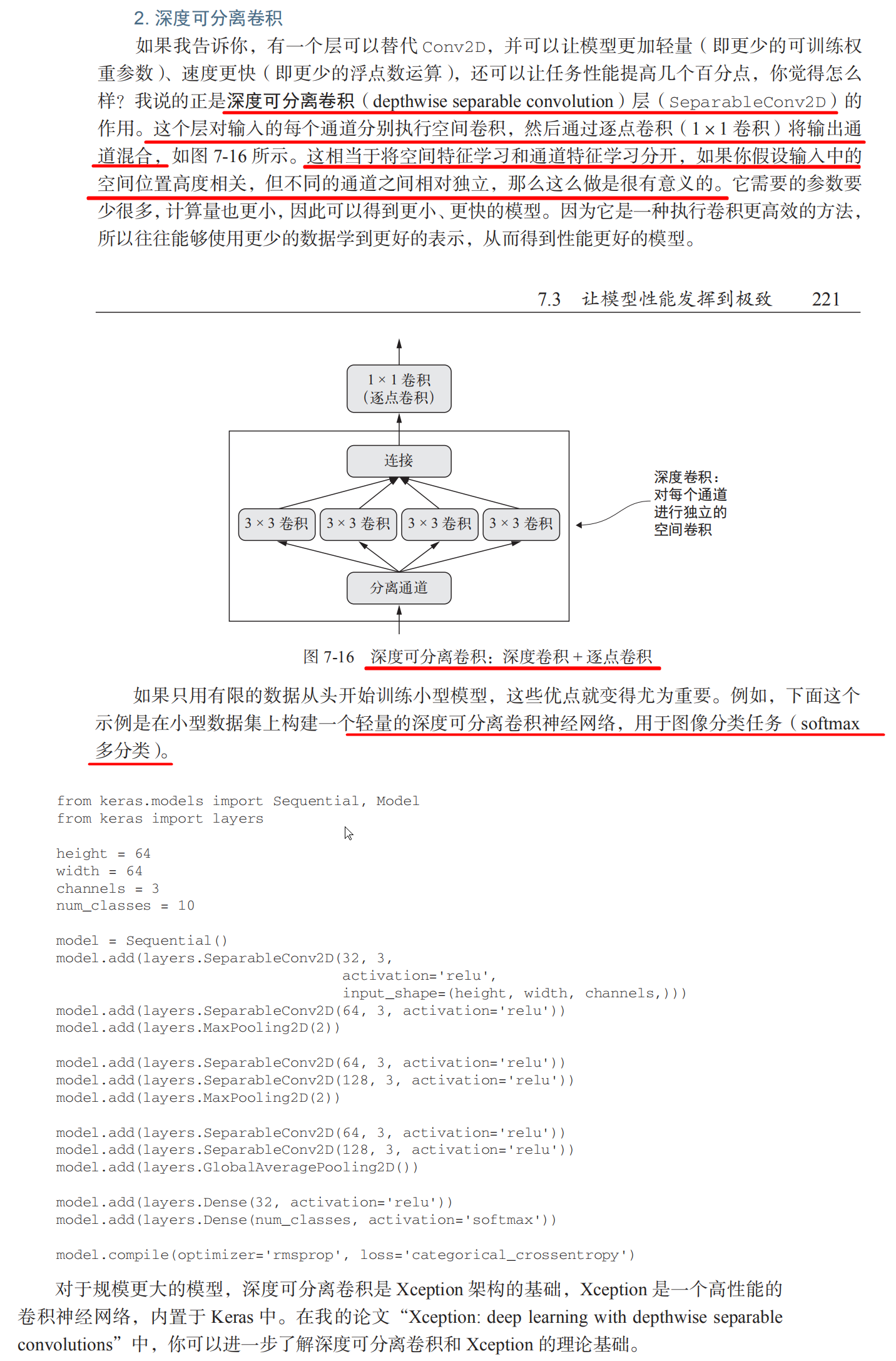
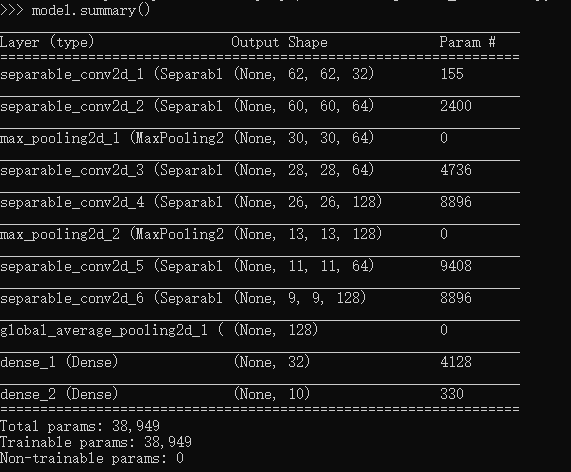
Depth separable convolution

Inception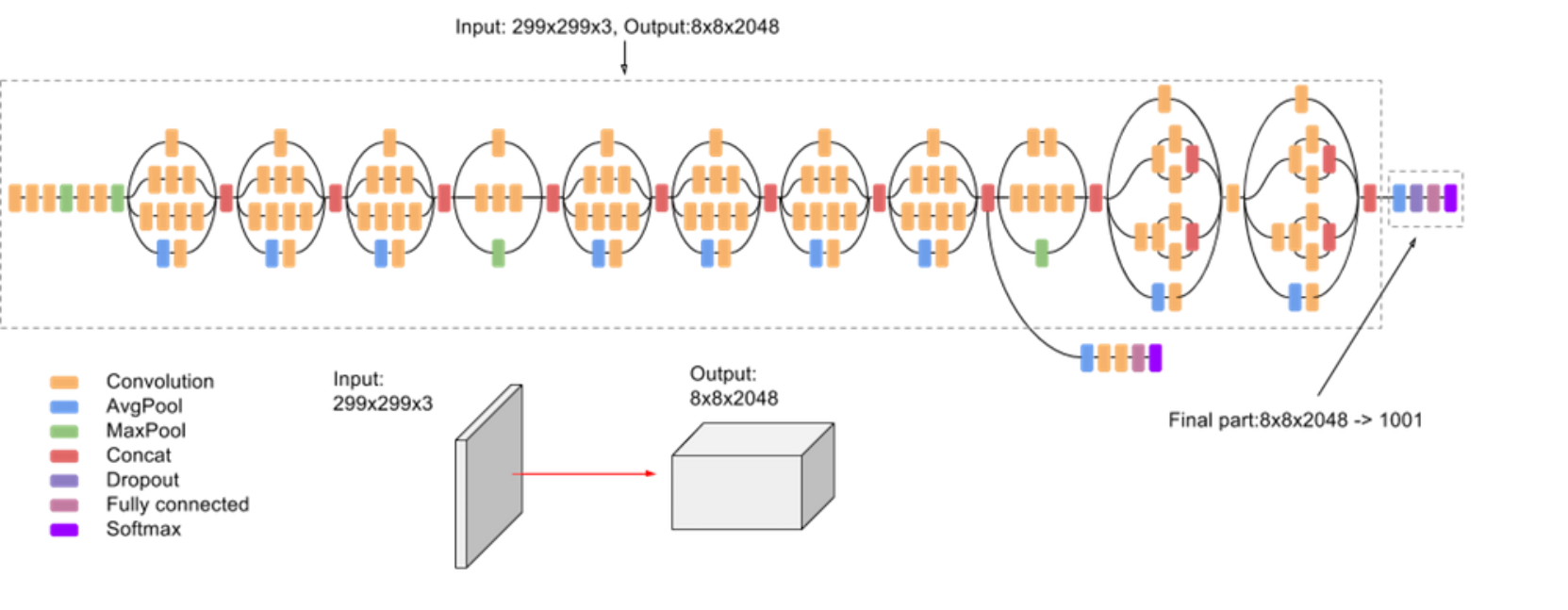
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train, x_test = x_train.astype(np.float32)/255., x_test.astype(np.float32)/255.
# [b, 28, 28] => [b, 28, 28, 1]
x_train, x_test = np.expand_dims(x_train, axis=3), np.expand_dims(x_test, axis=3)
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(256)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(256)
print(x_train.shape, y_train.shape) #(60000, 28, 28, 1) (60000,)
print(x_test.shape, y_test.shape) #(10000, 28, 28, 1) (10000,)
class ConvBNRelu(keras.Model):
def __init__(self, ch, kernelsz=3, strides=1, padding='same'):
super(ConvBNRelu, self).__init__()
self.model = keras.models.Sequential([
keras.layers.Conv2D(ch, kernelsz, strides=strides, padding=padding),
keras.layers.BatchNormalization(),
keras.layers.ReLU()
])
def call(self, x, training=None):
x = self.model(x, training=training)
return x
class InceptionBlk(keras.Model):
def __init__(self, ch, strides=1):
super(InceptionBlk, self).__init__()
self.ch = ch
self.strides = strides
self.conv1 = ConvBNRelu(ch, strides=strides)
self.conv2 = ConvBNRelu(ch, kernelsz=3, strides=strides)
self.conv3_1 = ConvBNRelu(ch, kernelsz=3, strides=strides)
self.conv3_2 = ConvBNRelu(ch, kernelsz=3, strides=1)
self.pool = keras.layers.MaxPooling2D(3, strides=1, padding='same')
self.pool_conv = ConvBNRelu(ch, strides=strides)
def call(self, x, training=None):
x1 = self.conv1(x, training=training)
x2 = self.conv2(x, training=training)
x3_1 = self.conv3_1(x, training=training)
x3_2 = self.conv3_2(x3_1, training=training)
x4 = self.pool(x)
x4 = self.pool_conv(x4, training=training)
# concat along axis=channel only connects on channel dimension
x = tf.concat([x1, x2, x3_2, x4], axis=3)
return x
class Inception(keras.Model):
def __init__(self, num_layers, num_classes, init_ch=16, **kwargs):
super(Inception, self).__init__(**kwargs)
self.in_channels = init_ch
self.out_channels = init_ch #After passing through each num layers layer, the number of out channels output channels will be doubled, and the height and width of the output will also be halved
self.num_layers = num_layers
self.init_ch = init_ch
self.conv1 = ConvBNRelu(init_ch)
self.blocks = keras.models.Sequential(name='dynamic-blocks')
for block_id in range(num_layers):
for layer_id in range(2):
if layer_id == 0:
#After each num layers layer, the height and width of the output of the first layer are halved
block = InceptionBlk(self.out_channels, strides=2) #Half width and height of output
else:
block = InceptionBlk(self.out_channels, strides=1)
self.blocks.add(block)
# enlarger out_channels per block
self.out_channels *= 2 #After each num layers layer, the number of out channels output channels will double
self.avg_pool = keras.layers.GlobalAveragePooling2D()
self.fc = keras.layers.Dense(num_classes)
def call(self, x, training=None):
out = self.conv1(x, training=training)
out = self.blocks(out, training=training)
out = self.avg_pool(out)
out = self.fc(out)
return out
# build model and optimizer
batch_size = 32
epochs = 100
model = Inception(2, 10)
# derive input shape for every layers.
model.build(input_shape=(None, 28, 28, 1))
model.summary()
#Model: "inception"
#_________________________________________________________________
#Layer (type) Output Shape Param #
#=================================================================
#conv_bn_relu (ConvBNRelu) multiple 224
#_________________________________________________________________
#dynamic-blocks (Sequential) multiple 292704
#_________________________________________________________________
#global_average_pooling2d (Gl multiple 0
#_________________________________________________________________
#dense (Dense) multiple 1290
#=================================================================
#Total params: 294,218
#Trainable params: 293,226
#Non-trainable params: 992
#_________________________________________________________________
optimizer = keras.optimizers.Adam(learning_rate=1e-3)
criteon = keras.losses.CategoricalCrossentropy(from_logits=True)
acc_meter = keras.metrics.Accuracy()
for epoch in range(100):
for step, (x, y) in enumerate(db_train):
with tf.GradientTape() as tape:
# print(x.shape, y.shape)
# [b, 10]
logits = model(x)
# [b] vs [b, 10]
loss = criteon(tf.one_hot(y, depth=10), logits)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 10 == 0:
print(epoch, step, 'loss:', loss.numpy())
acc_meter.reset_states() #Clear accuracy index
for x, y in db_test:
# [b, 10]
logits = model(x, training=False)
# [b, 10] => [b]
pred = tf.argmax(logits, axis=1)
print(x.shape, y.shape, pred.shape) #(256, 28, 28, 1) (256,) (256,)
# Comparative calculation of y's batch [b] and pred's batch [b]
acc_meter.update_state(y, pred) #Calculation accuracy index
print(epoch, 'evaluation acc:', acc_meter.result().numpy()) #Get accuracy index


230 original articles published, praised by 111, visited 160000+