Introduction to basic concepts
Artificial intelligence: simple understanding is to make machines have human thinking and consciousness
Three schools of artificial intelligence:
- Behaviorism: constructing perception control system based on Cybernetics
- Symbolism: Based on arithmetic logic expression, to solve a problem, first describe the problem as an expression, and then solve the expression
- Connectionism: bionics, imitating neuronal connections
data type
tensorflow basic data types: int8/16/32/64, float16/32/64, bool, string
Tensor generation
Tensor: unlike arrays in numpy, lists in python are one thing, but they are called tensors in tensorflow
The method of generating data by using tensorflow is basically the same as that of numpy
You can see this article about the use of numpy
import tensorflow as tf import numpy as np # Create tensor directly a = tf.constant(value=[1, 2, 3, 4], dtype=tf.float32, shape=(2, 2), name="a") # value: data in tensor, required # dtype: the data type of tensor; optional; if it is not specified, the appropriate type will be automatically selected according to the data # Shape: shape of tensor, optional. If not set, the shape with tensor value # Name: tensor name, optional print(a) print(a.shape) print(a.dtype)

# Created through numpy and tf.convert_to_tensor implementation conversion # The converted shape is consistent with the shape of numpy b = np.linspace(1, 4, 5) print(b) a = tf.convert_to_tensor(value=b, dtype=tf.float32, name="aa") print(a)
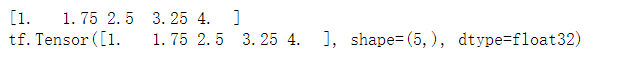
# Create tensors with all 0 tf.zeros(shape=(3, 4))

# Create tensor with all 1 tf.ones(shape=(3, 4))

# Creates a tensor with all specified values tf.fill(dims=(3, 4), value=9)

# Generate tensor with normal distribution tf.random.normal(shape=(20,), mean=0, stddev=1) # A standard normal distribution with a mean of 0 and a standard deviation of 1 is generated by default

# Generating truncated Zhentai distribution tf.random.truncated_normal(shape=(20,), mean=0, stddev=1) # The data generated by truncation is distributed between (u-2q, u+2q) # u: Mean, q: standard deviation

Common functions
# Force the tensor to the corresponding data type a = tf.constant(value=[1, 2, 3], dtype=tf.int32) print(a) b = tf.cast(x=a, dtype=tf.float64) print(b)
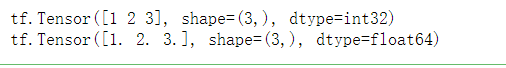
# tensor maximum and minimum a = tf.constant(value=[[1, 3, 4], [2, 2, 5]], dtype=tf.float32) print(a) tensor_min = tf.reduce_min(a) # The minimum value of the whole tensor is obtained by default print(tensor_min) tensor_max = tf.reduce_max(a) # The maximum value of the whole tensor is obtained by default print(tensor_max) # Specify the direction of the obtained maximum value through axis # axis=0 means to get the maximum value of each column, and axis=1 means to get the maximum value of each row tensor_col_min = tf.reduce_min(a, axis=0) print(tensor_col_min) # The same function also has reduce_mean, reduce_sum, I won't show it here

# Mark the variable as trainable, and the marked variable will record the gradient information in the back propagation # This method is often used to mark the parameters to be trained in neural network training w = tf.Variable(tf.random.normal(shape=(2, 2))) print(w)
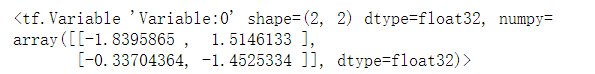
Calculation of tensor
The four operations require that the tensor s involved in the operation have the same shape
Matrix operation needs to meet the operation requirements of matrix (m,n) x (n,k)
# Addition operation a = tf.constant(value=[[1, 1], [1, 1]]) b = tf.constant(value=[[2, 2], [2, 2]]) tf.add(a, b)

# Subtraction operation tf.subtract(a, b)

# Multiplication tf.multiply(a, b)

# Division operation tf.divide(a, b)
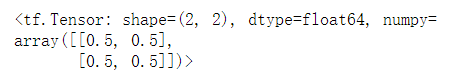
# Power operation tf.pow(b, 3)

# Open operation does not support the data type of int32, so data conversion is required tf.sqrt(tf.cast(b, dtype=tf.float32))

a = tf.constant(value=[[1,1], [1, 1]]) b = tf.constant(value=[[2,2,2], [2,2,2]]) tf.matmul(a, b)

Feature label combination
The incoming data of neural network is the data of feature label pairing. Therefore, feature labels need to be combined
feature = np.array([1, 2, 3, 4])
labels = np.array([0, 1, 1, 1])
# The parameters received by this method are applicable to both tensor format and numpy format data
data = tf.data.Dataset.from_tensor_slices((feature, labels))
print(data)
for ele in data :
print(ele)

Convert the output to a probability distribution that matches each category
softmax function is used to calculate the probability distribution of each category corresponding to each input data
s
o
f
t
m
a
x
(
y
i
)
=
e
y
i
∑
j
=
0
n
e
y
j
softmax(y_i) = \frac {e^{y_i}} {\sum^n_{j=0} e^{y_j}}
softmax(yi)=∑j=0neyjeyi
# For three classification data, the output values of neural network are 1, 2 and 3 # The probability of each category is calculated by softmax y = tf.constant([1, 2, 3], dtype=tf.float32) tf.nn.softmax(y) # <tf.Tensor: shape=(3,), dtype=float32, numpy=array([0.09003057, 0.24472848, 0.66524094], dtype=float32)>
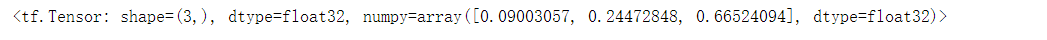
Calculation of gradient
Use loss = (w+1)^2 to show usage
The derivative of loss to w is 2*w + 2
# The initial parameter w is marked as trainable
# tf.GradientTape is used in the with structure to derive the specified parameters of a function
w = tf.Variable(tf.constant(value=5, dtype=tf.float32))
with tf.GradientTape() as tape :
loss = tf.square(w+1) # Set the objective function to be derived
grad = tape.gradient(loss, w) # Calculate the value of the derivative
print(grad) # tf.Tensor(12.0, shape=(), dtype=float32)
# Encapsulating the above process into a for loop is a gradient descent process
summary
This article introduces the commonly used functions of tensorflow. Is a basic introductory article. Many methods in this paper can be realized by other means, such as numpy, pandas and so on. The specific choice depends on personal preferences. My suggestion is to use his own method when learning tensorflow, which can deepen our memory of tensorflow.