Reprint the original link of the article:
https://github.com/lyhue1991/eat_tensorflow2_in_30_days/blob/master/6-7%2C%E4%BD%BF%E7%94%A8spark-scala%E8%B0%83%E7%94%A8tensorflow%E6%A8%A1%E5%9E%8B.md
Use spark Scala to call tensorflow2 0 trained model
If you use pyspark, it will be relatively simple. You only need to load the model in Python on each executor and predict it separately.
But in engineering, for the sake of performance, we usually use the scala version of spark.
In this article, we use the TensorFlow for Java to invoke the trained tensorflow model in spark.
Using the distributed computing power of spark, the trained tensorflow model can execute model inference in distributed parallel on hundreds of machines.
Overview of spark Scala calling tensorflow model
To call the tensorflow model in spark(scala), we need to complete the following steps.
(1) Prepare protobuf model file
(2) Create a spark(scala) project and add the jar package dependency corresponding to the java version of tensorflow to the project
(3) In spark(scala) project, the driver side loads tensorflow model and debugging is successful
(4) In the spark(scala) project, load the tensorflow model on the executor through RDD, and the debugging is successful
(5) In the spark(scala) project, load the tensorflow model on the executor through DataFrame, and the debugging is successful
1, Prepare protobuf model file
We use TF Keras trains a simple linear regression model and saves it as a protobuf file.
import tensorflow as tf
from tensorflow.keras import models,layers,optimizers
## Number of samples
n = 800
## Generate test data set
X = tf.random.uniform([n,2],minval=-10,maxval=10)
w0 = tf.constant([[2.0],[-1.0]])
b0 = tf.constant(3.0)
Y = X@w0 + b0 + tf.random.normal([n,1],mean = 0.0,stddev= 2.0) # @Represents matrix multiplication and increases normal perturbation
## Model building
tf.keras.backend.clear_session()
inputs = layers.Input(shape = (2,),name ="inputs") #Set the input name to inputs
outputs = layers.Dense(1, name = "outputs")(inputs) #Set the output name to outputs
linear = models.Model(inputs = inputs,outputs = outputs)
linear.summary()
## Using fit method for training
linear.compile(optimizer="rmsprop",loss="mse",metrics=["mae"])
linear.fit(X,Y,batch_size = 8,epochs = 100)
tf.print("w = ",linear.layers[1].kernel)
tf.print("b = ",linear.layers[1].bias)
## Save the model to pb format file
export_path = "./data/linear_model/"
version = "1" #Later, model version iteration and management can be carried out through version number
linear.save(export_path+version, save_format="tf")
!ls {export_path+version}
# View model file related information
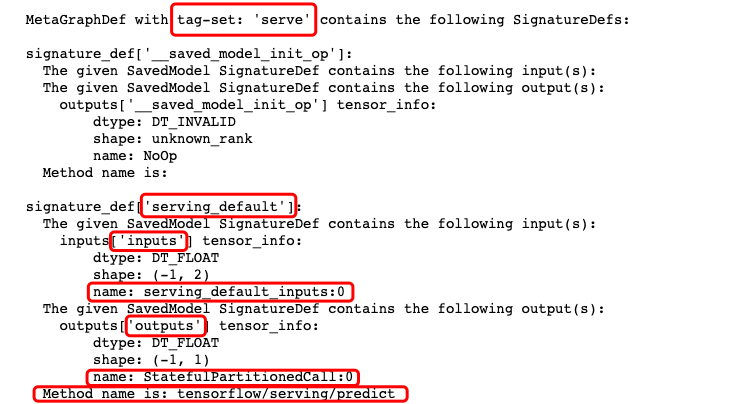
!saved_model_cli show --dir {export_path+str(version)} --all
The parts marked in red in the model file information may be used later.
2, Create a spark(scala) project and add the jar package dependency corresponding to the java version of tensorflow to the project
If you use maven to manage the project, you need to add the following jar package dependencies
<!-- https://mvnrepository.com/artifact/org.tensorflow/tensorflow -->
<dependency>
<groupId>org.tensorflow</groupId>
<artifactId>tensorflow</artifactId>
<version>1.15.0</version>
</dependency>
You can also download org.com directly from the following website tensorflow. jar package of tensorflow
And its dependent org tensorflow. Libtensorflow and org tensorflowlibtensorflow_ Put JNI's jar package into the project.
https://mvnrepository.com/artifact/org.tensorflow/tensorflow/1.15.0
3, In spark(scala) project, the driver side loads tensorflow model and debugging is successful
Our demonstration code is demonstrated in jupyter notebook. toree needs to be installed to support spark(scala).
import scala.collection.mutable.WrappedArray
import org.{tensorflow=>tf}
//Note: the second parameter of the load function is generally "serve", which can be found in the relevant information of the model file
val bundle = tf.SavedModelBundle
.load("/Users/liangyun/CodeFiles/eat_tensorflow2_in_30_days/data/linear_model/1","serve")
//Note: the java version of tensorflow is similar to tensorflow1 0, you need to create a Session, specify the data of the feed and the result of the fetch, and then run
//Note: if multiple data needs to be fed, multiple feed methods can be used continuously
//Note: the input must be of float type
val sess = bundle.session()
val x = tf.Tensor.create(Array(Array(1.0f,2.0f),Array(2.0f,3.0f)))
val y = sess.runner().feed("serving_default_inputs:0", x)
.fetch("StatefulPartitionedCall:0").run().get(0)
val result = Array.ofDim[Float](y.shape()(0).toInt,y.shape()(1).toInt)
y.copyTo(result)
if(x != null) x.close()
if(y != null) y.close()
if(sess != null) sess.close()
if(bundle != null) bundle.close()
result
The output is as follows:
Array(Array(3.019596), Array(3.9878292))
4, In the spark(scala) project, load the tensorflow model on the executor through RDD, and the debugging is successful
We call the TensorFlow executor and transfer the inference to each model of the distributed executor.
import org.apache.spark.sql.SparkSession
import scala.collection.mutable.WrappedArray
import org.{tensorflow=>tf}
val spark = SparkSession
.builder()
.appName("TfRDD")
.enableHiveSupport()
.getOrCreate()
val sc = spark.sparkContext
//Load the model on the Driver side
val bundle = tf.SavedModelBundle
.load("/Users/liangyun/CodeFiles/master_tensorflow2_in_20_hours/data/linear_model/1","serve")
//Broadcast the model to the executor
val broads = sc.broadcast(bundle)
//Construct dataset
val rdd_data = sc.makeRDD(List(Array(1.0f,2.0f),Array(3.0f,5.0f),Array(6.0f,7.0f),Array(8.0f,3.0f)))
//Batch inference through mapPartitions calling model
val rdd_result = rdd_data.mapPartitions(iter => {
val arr = iter.toArray
val model = broads.value
val sess = model.session()
val x = tf.Tensor.create(arr)
val y = sess.runner().feed("serving_default_inputs:0", x)
.fetch("StatefulPartitionedCall:0").run().get(0)
//Copy the prediction results to the Array of Float type of the same shape
val result = Array.ofDim[Float](y.shape()(0).toInt,y.shape()(1).toInt)
y.copyTo(result)
result.iterator
})
rdd_result.take(5)
bundle.close
The output is as follows:
Array(Array(3.019596), Array(3.9264367), Array(7.8607616), Array(15.974984))
5, In the spark(scala) project, load the tensorflow model on the executor through DataFrame, and the debugging is successful
In addition to calling tensorflow model on Spark's RDD data for distributed inference,
We can also call tensorflow model on DataFrame data for distributed inference.
The main idea is to register the inference method as a sparkSQL function.
import org.apache.spark.sql.SparkSession
import scala.collection.mutable.WrappedArray
import org.{tensorflow=>tf}
object TfDataFrame extends Serializable{
def main(args:Array[String]):Unit = {
val spark = SparkSession
.builder()
.appName("TfDataFrame")
.enableHiveSupport()
.getOrCreate()
val sc = spark.sparkContext
import spark.implicits._
val bundle = tf.SavedModelBundle
.load("/Users/liangyun/CodeFiles/master_tensorflow2_in_20_hours/data/linear_model/1","serve")
val broads = sc.broadcast(bundle)
//Construct the prediction function and register it as the udf of sparkSQL
val tfpredict = (features:WrappedArray[Float]) => {
val bund = broads.value
val sess = bund.session()
val x = tf.Tensor.create(Array(features.toArray))
val y = sess.runner().feed("serving_default_inputs:0", x)
.fetch("StatefulPartitionedCall:0").run().get(0)
val result = Array.ofDim[Float](y.shape()(0).toInt,y.shape()(1).toInt)
y.copyTo(result)
val y_pred = result(0)(0)
y_pred
}
spark.udf.register("tfpredict",tfpredict)
//Construct the DataFrame dataset and put the features in one column
val dfdata = sc.parallelize(List(Array(1.0f,2.0f),Array(3.0f,5.0f),Array(7.0f,8.0f))).toDF("features")
dfdata.show
//Call the sparkSQL prediction function and add a new column as y_preds
val dfresult = dfdata.selectExpr("features","tfpredict(features) as y_preds")
dfresult.show
bundle.close
}
}
TfDataFrame.main(Array())
+----------+ | features| +----------+ |[1.0, 2.0]| |[3.0, 5.0]| |[7.0, 8.0]| +----------+ +----------+---------+ | features| y_preds| +----------+---------+ |[1.0, 2.0]| 3.019596| |[3.0, 5.0]|3.9264367| |[7.0, 8.0]| 8.828995| +----------+---------+
Above, we call a TF on the RDD data structure and DataFrame data structure of spark respectively The linear regression model implemented by keras is used for distributed model inference.
With a little modification on the basis of this example, we can use spark to call various complex neural network models trained for distributed model inference.
But in fact, tensorflow is not only suitable for the implementation of neural network, its underlying computational graph language can express various numerical calculation processes.
Using its rich low-level API, we can 0 to implement any machine learning model,
Combined TF With the convenient encapsulation function provided by module, we can export any trained machine learning model into a model file and call and execute it distributed on spark.
This undoubtedly provides a huge imagination space for our engineering application.
Directly call the reference article in java: https://www.jianshu.com/p/0eb29e7302e6