Text 3: swordsman and find
wildcard
Match file name
*: Match 0 or more characters
?: Match any character
[list]: matching list Any single character in
[c1-c2]: matching c1-c2 Any single character in
[^c1-c2]/[!c1-c2]: Mismatch c1-c2 Any character in
{string1,string2,...}: matching{}Any single string in
find file lookup
Complete the file search by traversing the file system under the specified path
find [option] [route] [Search criteria + Processing action] Find path: specify a specific directory path. The default is the current folder Search criteria: specified search criteria (file name)/size/type/Permissions, etc.), the default is to find all files Processing action: the default output screen is what to do with qualified files
Search criteria
Find by file name: -name "filename" support global -iname "filename" ignore case -regex "PATTERN" with Pattern Matches the entire file path string, not just the file name Find by owner and group: -user USERNAME: Find a file whose owner is the specified user -group GROUPNAME: Find files that belong to the specified group -uid UserID: Find the specified owner ID Document No -gid GroupID: Find the group with the specified GID Document No -nouser: Find files that do not belong to a master -nogroup: Find files that do not belong to a group Find by file type: -type Type: f/d/l/s/b/c/p Find by file size: -size [+|-]N[bcwkMG] According to timestamp: Days: -atime [+|-]N -mtime -ctime minute: -amin N -cmin N -mmin N Find by permission: -perm [+|-]MODE MODE: Exact permission matching /MODE: Any kind(u,g,o)Only one of the permissions of the object can match -MODE: Each type of object must have the specified permission standard at the same time Combination conditions: And:-a Or:-o Non:-not Related cases: find out/tmp Under the directory, the owner is not root,And the file name is not fstab File: find /tmp \( -not -user root -a -not -name 'fstab'\) -ls
Processing action
-print: The default processing action is displayed to the screen
-ls: Type of file found“ ls -l"command
-delete: Delete found files
-fls /path/to/somefile: Save the long format information of all found files to the specified file
-ok COMMAND {}\: Execute by for each file found COMMAND Specified command
For each file, the user will be asked to confirm it interchangeably before executing the command
-exec COMMAND {} \: Execute by for each file found COMMAND Specified command
[root@server1 ~]# find /etc/init.d/ -perm -111 -exec cp -r {} dir1/ \;
{}: Used to reference the found file name itself
be careful: find When transferring the found file to the command specified later, all qualified files found will be transferred to the command specified later at one time
Order; Another way to avoid this problem
find | xargs COMMAND
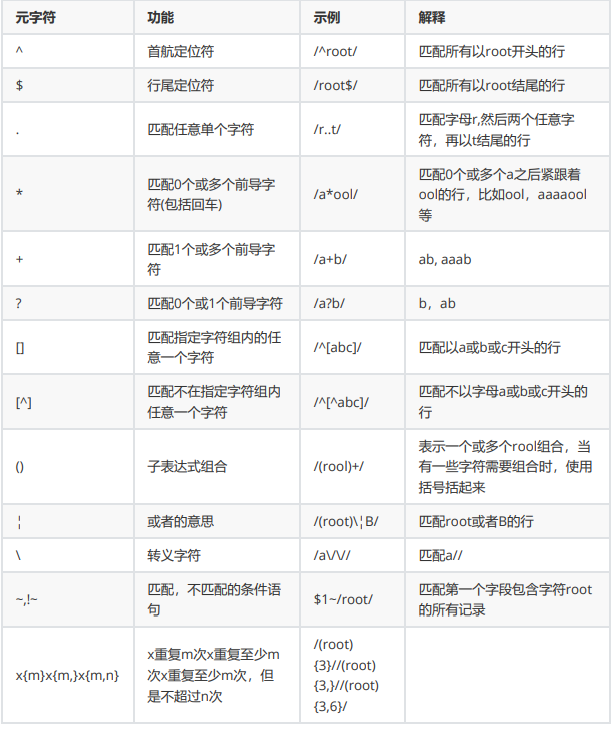
regular expression
Matching file content, matching string
##Character matching
.: Match any single character
[]: Matches any single character within the specified range
[^]: Matches any single character outside the specified range
[:alnum:]: Alphanumeric characters
[:alpha:]: letter
[:blank:]: Spaces or tabs
[:cntrl:]: ASCII Control character
[:digit:]: number
[:graph:]: Non control, non whitespace characters
[:lower:]: Lowercase letters
[:print:]: Printable character
[:punct:]: Punctuation character
[:space:]: White space characters, including vertical tabs
[:upper:]: capital
[:xdigit:]: Hexadecimal digit
##Matching times
*: Match the preceding character any number of times
.*: Match characters of any length
\?: Match the preceding character 0 or 1 times, that is, the preceding character is optional
\+: Match the character before it at least once
\{m\}: Match previous characters m second
\{m,n\}: Match previous characters at least m Times, at most n second
\{0,n\}: Match previous characters at most n second
\{m,\}: Match previous characters at least m second
##Position anchoring
^: The row head anchor is used for the leftmost side of the mode
$: End of line anchor, used for the rightmost side of the mode
^PATTERN$: Used for pattern matching the whole line;
^$: Empty line
\< or \b: Initial anchor for the left side of the word pattern
\> or \b: Suffix anchor for the right side of the word pattern
\<PATTERN\>: Match whole word
##grouping
\(\):Binding one or more characters together; As a character
\(xy\)*ab
Note: The content matched by the pattern in the grouping brackets will be recorded in the internal variables by the regular expression engine, and the commands of these variables
The method is:
\1,\2,\3......
\1: From the left, the characters matched by the first left parenthesis and the pattern between the matching right parentheses;
\(ab\+\(xy\)*\):
\1: ab\+\(xy\)*
\2: xy
Extended regular expression
##Character matching
.
[]
[^]
##Times matching
*
?: 0 Once or once
+: 1 One or more times
{m}:matching m second
{m,n}: at least m Times, at most n second
##Position anchoring
##grouping
()
##perhaps
a|b
C | cat : C or cat
(C|c)at : C or c
grep of Linux three swordsmen
Option description -E :--extended--regexp The pattern is an extended regular expression( ERE) -i :--ignore--case ignore case -n: --line--number Print line number -o:--only--matching Print only matching content -c:--count Print only the number of lines that match each file -B:--before--context=NUM Print the first few lines that match -A:--after--context=NUM Print the last few lines that match -C:--context=NUM Print the first and last lines of the match --color[=WHEN] Matching font color, alias defined -v:--invert--match Print mismatched lines -e Multipoint operation eg: grep -e "^s" -e "s$"
Regular expression (based on grep)
- The function is to retrieve and replace the text that conforms to a certain pattern (rule). Regular expressions are available in every language;
- Regular expression is a set of rules and methods defined to deal with a large number of text or strings
- With the help of these special symbols defined, the system administrator can quickly filter, replace or output the required string
- Linux regular expressions are generally handled in behavioral units
. Match any single character (must exist)
^ Match lines that begin with a character
$ A line ending with what character
* Match the previous character 0 or more times; eg: a*b
.* Represents any character of any length
[] Represents a character that matches within parentheses
[^] matching[^character]Any character other than
[] Non matching[^character]Line beginning with inner character
< Anchor word head; eg: <root
> Anchor the end of the word: eg: root>
{m,n} Indicates that at least one character appears before the match m Times, at most n second
() Indicates grouping a word;\1 Indicates that the first group is called
Remove all comments and blank lines when viewing the configuration file
[root@localhost ~]# grep -Ev "^#|^$" /etc/ssh/sshd_config
sed of Linux three swordsmen
grammar
sed Command format for: sed [option] 'sed command' filename sed Script format: sed [option] -f 'sed script' filename Common options: -n : Print only rows that match the pattern -e : Directly in command line mode sed Action editing, this is the default option -f : take sed The action of is written in a file–f filename implement filename Internal sed action -r : Support extended expressions -i : Directly modify the file content How to query text Use line number and line number range x: Line number x,y: from x Line to y that 's ok x,y!: x Line to y Outside the line /pattern: Query rows containing patterns /pattern/, /pattern/: The query contains rows of two patterns /pattern/,x: x In row queries contain rows of patterns x,/pattern/: x After the row, query the row matching the pattern
Action description
Common options:
p: Print matching lines(-n) a Can be followed by strings, which will appear on a new line
=: Display file line number
a\: Add new text after specifying line number
i\: Add new text before specifying line number
d: Delete positioning line
c\: Replace positioning text with new text c Can be followed by strings, which can replace n1,n2 Rows between
w filename: Write text to a file
r filename: Read text from another file
s/used/new/: replace
Replace tag:
g: Intra row global replacement
p: Displays the rows that have been replaced successfully p Meeting with parameters sed -n Run together
w: Save the result of successful replacement to the specified file
q: Exit immediately after the first pattern match
{}: The groups of commands executed on the positioning line are separated by commas
g: Paste mode 2 into/pattern n/
Add a line after the fourth line of the testfile file and output the result to standard output
[root@localhost ~]# sed -e 4a\newline test
List the contents of / etc/passwd and print the line number. At the same time, delete lines 2 ~ 5
[root@localhost ~]# nl /etc/passwd | sed '2,5d'
awk of Linux three swordsmen
awk '{pattern + action}' {filenames}
pattern represents the content that AWK finds in the data, while action is a series of commands executed when matching content is found
eg: when executing awk, it executes the print command on each line in / etc/passwd in turn.
[root@localhost ~]# awk -F: '{print $0}' /etc/passwd
Common awk built-in variables
$0 Current record n Current record's second n Fields FS The default input field delimiter is a space RS Enter the record separator and assume the line break by default NF The number of fields in the current record is the number of columns NR The number of records that have been read out is the line number, starting from 1 OFS The output field delimiter is also a space by default ORS The output record delimiter is assumed to be a line break by default
Print ip FS = "[" ":] +" print the third string on the second line with one or more spaces or: separating NR=2
[root@server1 ~]# ifconfig ens33 | awk -F[" ":]+ 'NR==2{print $3}'
192.168.211.100
awk regularity
[the external chain image transfer fails, and the source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-f9n7loqa-164602132450) (C: \ users \ HP \ appdata \ roaming \ typora \ typora user images \ image-202202281202257512. PNG)]
The number of records read out is the line number, starting from 1
OFS output field delimiters are also spaces by default
The record separator output by ORS is assumed to be a line break by default
Print ip FS="[" ":]+" Separated by one or more spaces or: NR=2 The second line prints the third string
```bash
[root@server1 ~]# ifconfig ens33 | awk -F[" ":]+ 'NR==2{print $3}'
192.168.211.100
awk regularity