development environment
System: windows 11
jdk: 1.8
Framework: spring boot 2.1 4 + maven
Tool: idea
Tesseract installation
Related links
Official website: https://github.com/tesseract-ocr/tesseract
Official documents: https://github.com/tesseract-ocr/tessdoc
Language pack address: https://github.com/tesseract-ocr/tessdata
Download address: https://digi.bib.uni-mannheim.de/tesseract/
I also submitted the 5.0 windows installation package in my resources (I think it's free. The official doesn't have this choice)
64 bit: https://download.csdn.net/download/qq_35885175/68236012
32-bit: https://download.csdn.net/download/qq_35885175/68235937
install
-
Double click to select the language and click OK
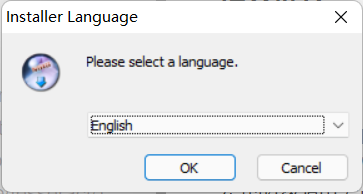
-
Direct next
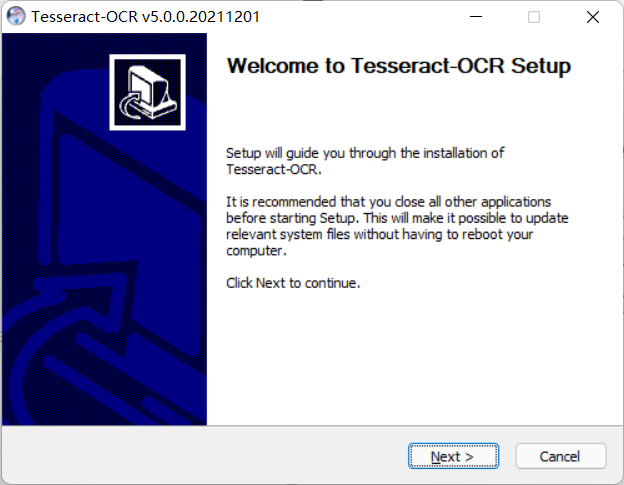
-
Daily consent agreement
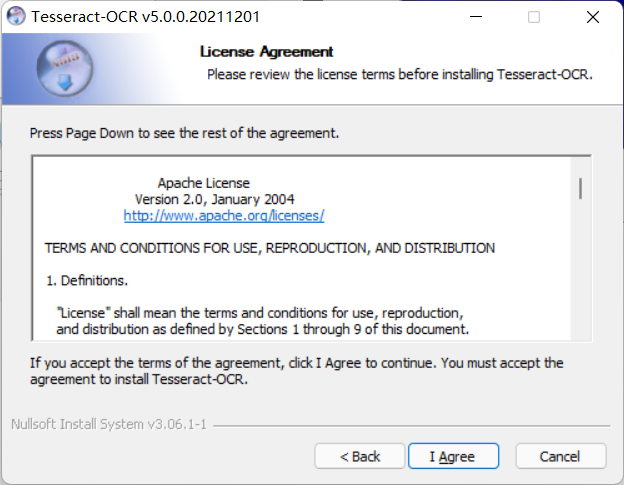
-
Choose who to install it for (depending on your needs, mine is a personal computer)
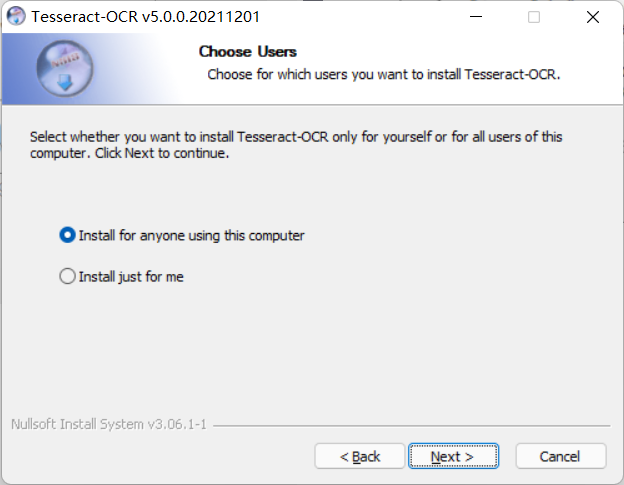
-
Next, select the language pack
The last two boxes are not recommended for downloading language packs (very slow, unless there is a ladder, there will be a tutorial to expand the language pack below)
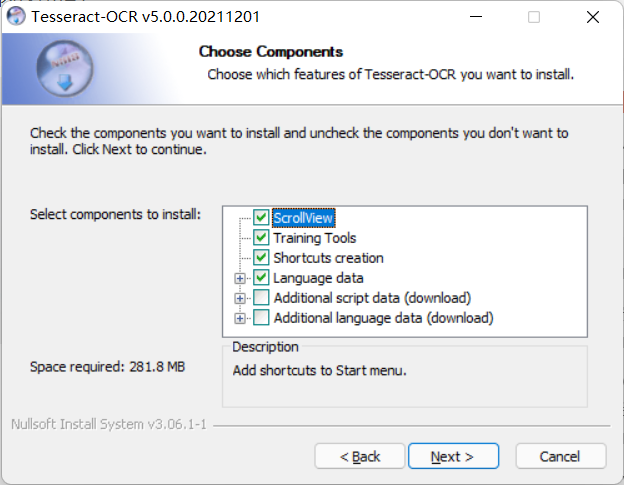
-
Select installation directory
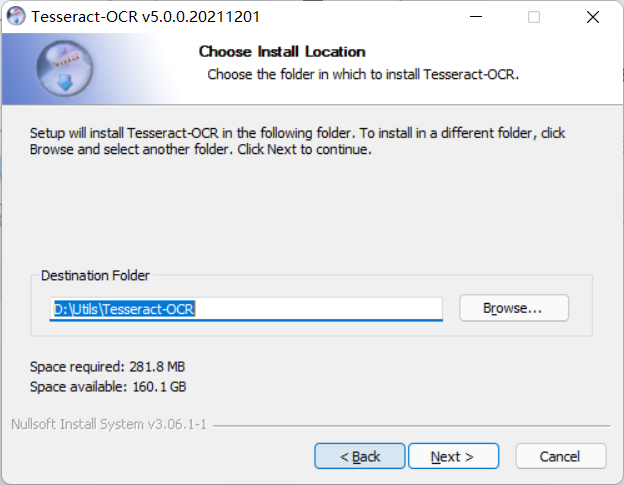
-
next, wait for the installation to complete
(there is one option to add the registry. I forgot the screenshot. By default, next is done.)
-
Installation complete (end)
Configure environment variables
This step is very simple for everyone
- Computer settings (advanced environment variables)
windows11
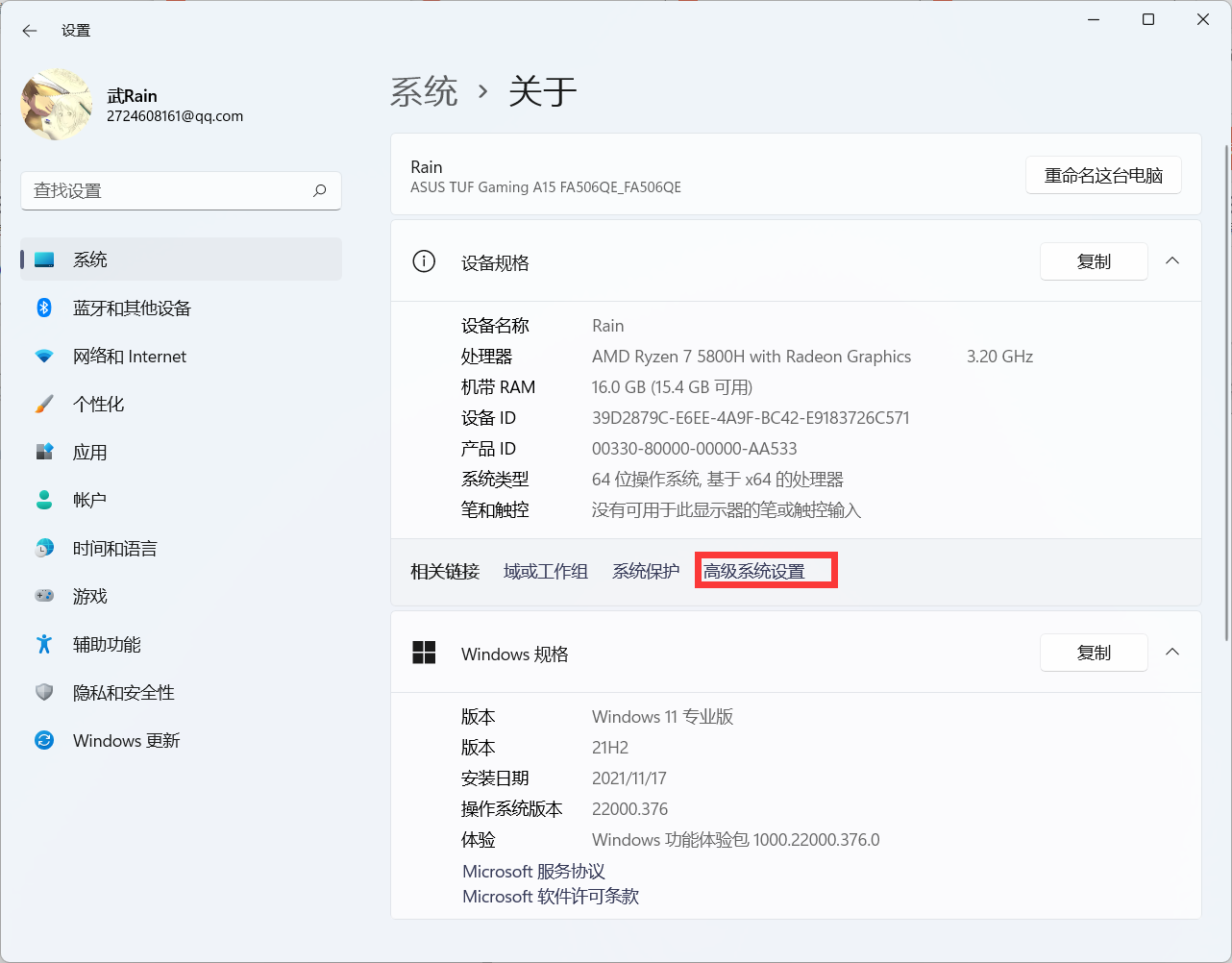
windows 10(windows server makes do)
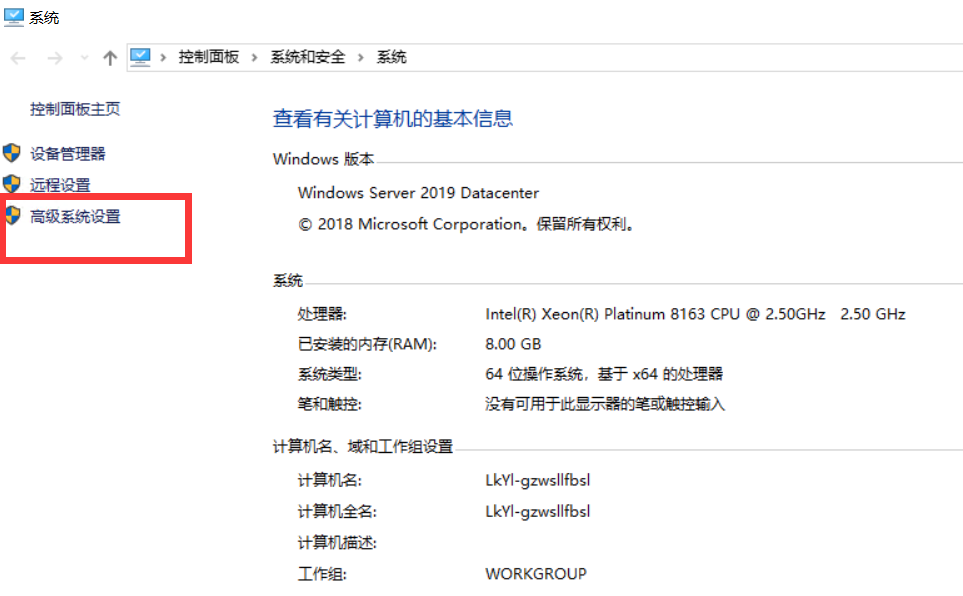
- Click environment variables
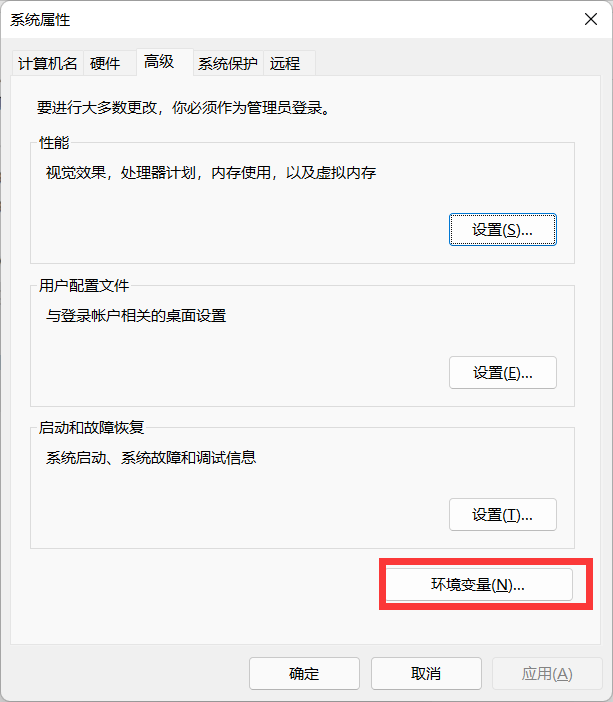
- PATH found in system variable
(user variables are also acceptable. If you can't use them, don't look for me)
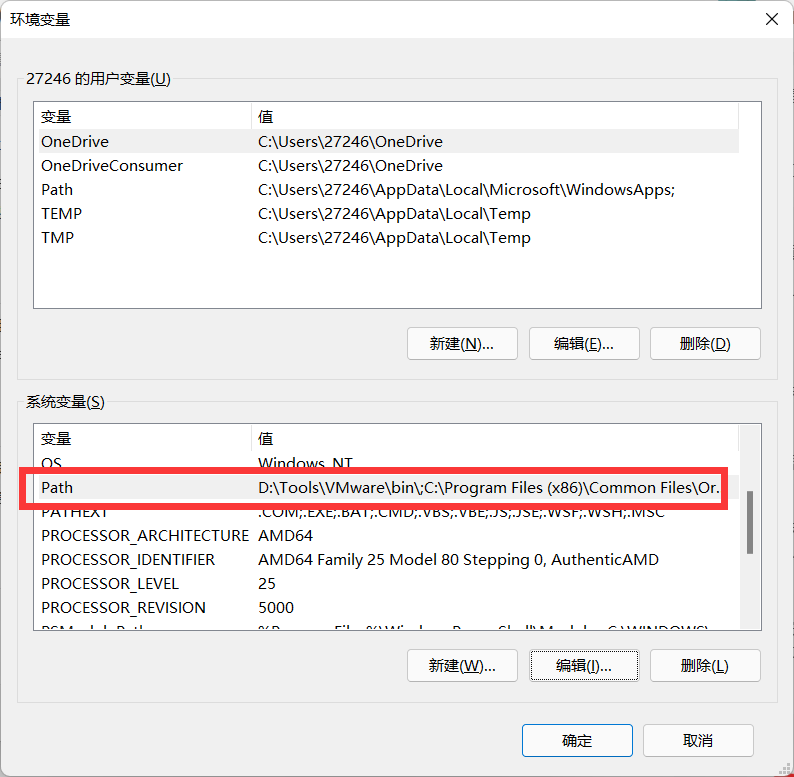
- Click new and select the path
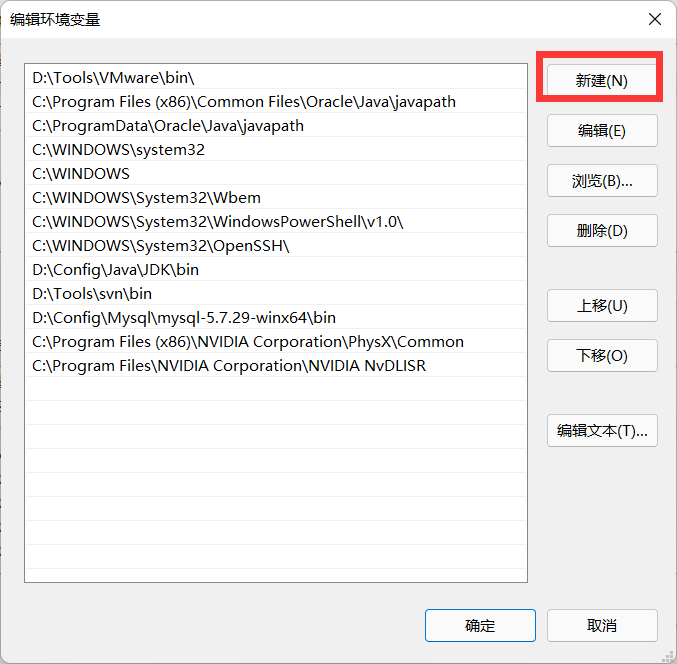
- That's about it. Just click OK
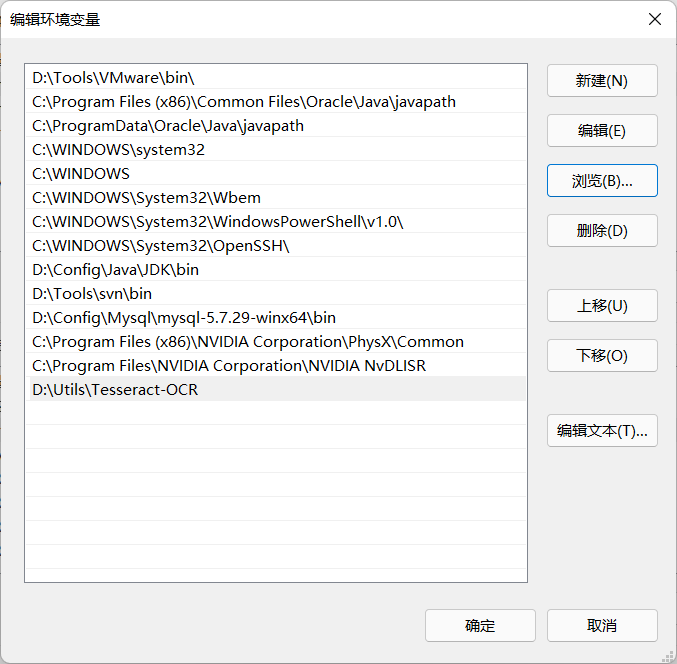
Check that the installation is successful
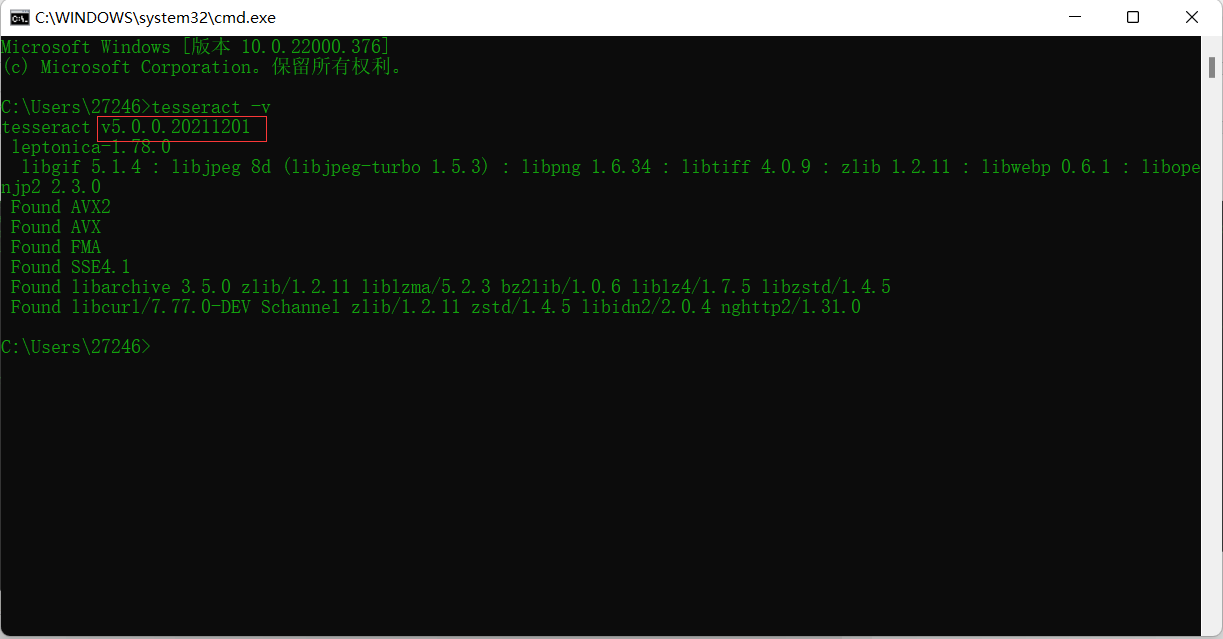
Here comes the omnipotent cmd
- win+R input cmd
- Enter tesseract -v in the small black box
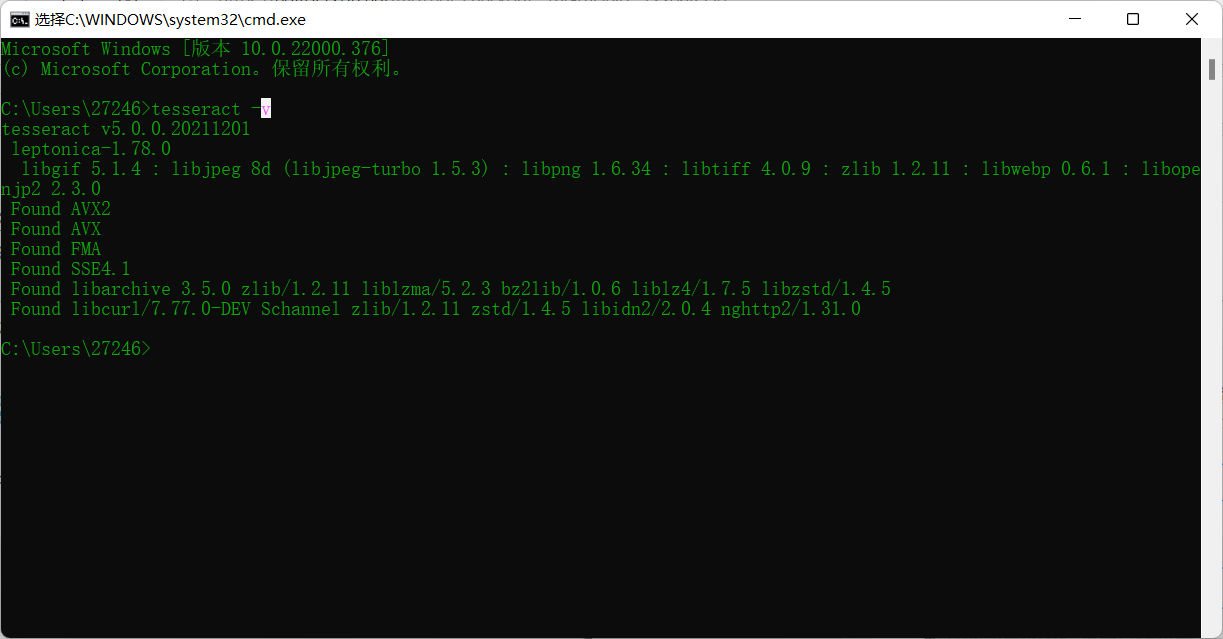
- See, the version we installed
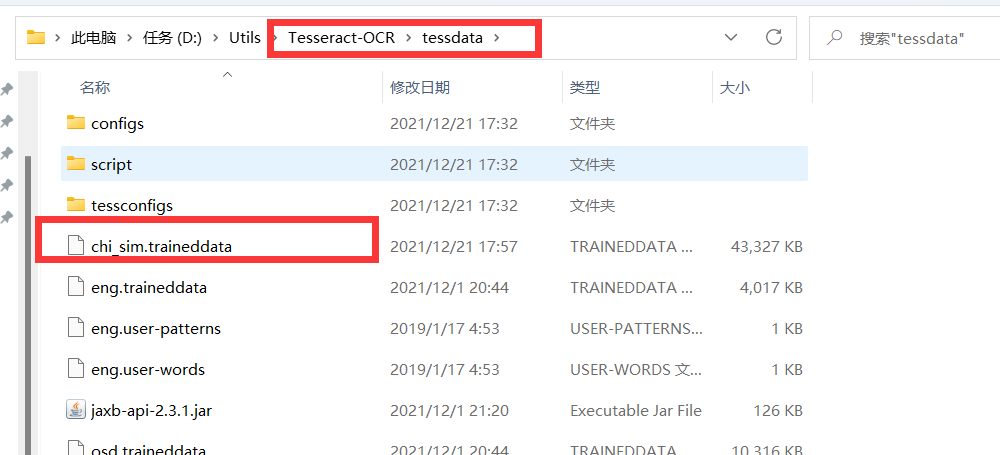
Extended language pack
The link above can be downloaded from github( Portal)
csdn I uploaded: https://download.csdn.net/download/qq_35885175/68245426
This thing is in simplified Chinese

go:
Put the downloaded file into the installation directory and it is finished
Test whether the extension is successful
Small black box (cmd) input: Tesseract -- List Langs
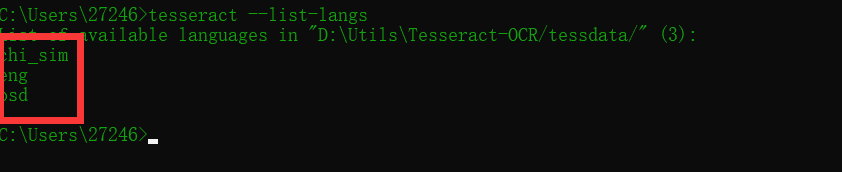
Done
Java code (a side dish)
1.POM file
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.0.0</version>
</dependency>
If the download is unsuccessful, switch several version s
jar package link: https://download.csdn.net/download/qq_35885175/68256292
Or download this I uploaded and throw it directly to the warehouse according to the directory
2.ImageIOHelper code
package com.lk.integutils.utils;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.Iterator;
import java.util.Locale;
import javax.imageio.IIOImage;
import javax.imageio.ImageIO;
import javax.imageio.ImageReader;
import javax.imageio.ImageWriteParam;
import javax.imageio.ImageWriter;
import javax.imageio.metadata.IIOMetadata;
import javax.imageio.stream.ImageInputStream;
import javax.imageio.stream.ImageOutputStream;
import com.github.jaiimageio.plugins.tiff.TIFFImageWriteParam;
public class ImageIOHelper {
//Set language
private Locale locale=Locale.CHINESE;
//Method of custom language construction
public ImageIOHelper(Locale locale){
this.locale=locale;
}
//Default constructor locale CHINESE
public ImageIOHelper(){
}
/**
* Create a temporary picture file to prevent damage to the original file
* @param imageFile
* @param imageFormat like png,jps .etc
* @return TempFile of Image
*/
public File createImage(File imageFile, String imageFormat) throws IOException {
//Read picture file
Iterator<ImageReader> readers = ImageIO.getImageReadersByFormatName(imageFormat);
ImageReader reader = readers.next();
//Get file stream
ImageInputStream iis = ImageIO.createImageInputStream(imageFile);
reader.setInput(iis);
IIOMetadata streamMetadata = reader.getStreamMetadata();
//Set writeParam
TIFFImageWriteParam tiffWriteParam = new TIFFImageWriteParam(Locale.CHINESE);
tiffWriteParam.setCompressionMode(ImageWriteParam.MODE_DISABLED);
//Set compressibility
//Get tiffWriter and set output
Iterator<ImageWriter> writers = ImageIO.getImageWritersByFormatName("tiff");
ImageWriter writer = writers.next();
BufferedImage bi = reader.read(0);
IIOImage image = new IIOImage(bi,null,reader.getImageMetadata(0));
File tempFile = tempImageFile(imageFile);
ImageOutputStream ios = ImageIO.createImageOutputStream(tempFile);
writer.setOutput(ios);
writer.write(streamMetadata, image, tiffWriteParam);
ios.close();
iis.close();
writer.dispose();
reader.dispose();
return tempFile;
}
/**
* Add suffix to tempfile
* @param imageFile
* @throws IOException
*/
private File tempImageFile(File imageFile) throws IOException {
String path = imageFile.getPath();
StringBuffer strB = new StringBuffer(path);
strB.insert(path.lastIndexOf('.'),"_text_recognize_temp");
String s=strB.toString().replaceFirst("(?<=//.)(//w+)$", "tif");
//Set file hiding
Runtime.getRuntime().exec("attrib "+"\""+s+"\""+" +H");
return new File(strB.toString());
}
}
3. OCRUtil code
package com.lk.integutils.utils;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Locale;
import org.jdesktop.swingx.util.OS;
public class OCRUtil {
private final String LANG_OPTION = "-l";
//English letter small l, not Arabic numeral 1
private final String EOL = System.getProperty("line.separator");
/**
* ocr Installation path for
*/
private String tessPath = "D:\\Utils\\Tesseract-OCR";
public OCRUtil(String tessPath,String transFileName){
this.tessPath=tessPath;
}
//The default path of OCRUtil is "C: / / program files (x86) / / Tesseract OCR"
public OCRUtil(){ }
public String getTessPath() {
return tessPath;
}
public void setTessPath(String tessPath) {
this.tessPath = tessPath;
}
public String getLANG_OPTION() {
return LANG_OPTION;
}
public String getEOL() {
return EOL;
}
/**
* @return Recognized text
*/
public String recognizeText(File imageFile,String imageFormat)throws Exception{
File tempImage = new ImageIOHelper().createImage(imageFile,imageFormat);
return ocrImages(tempImage, imageFile);
}
/**
* You can customize the language
*/
public String recognizeText(File imageFile,String imageFormat,Locale locale)throws Exception{
File tempImage = new ImageIOHelper(locale).createImage(imageFile,imageFormat);
return ocrImages(tempImage, imageFile);
}
/**
* @param
* @param
* @return Identified content
* @throws IOException
* @throws InterruptedException
*/
private String ocrImages(File tempImage,File imageFile) throws IOException, InterruptedException{
//Set the saved file directory and file name of the output file
File outputFile = new File(imageFile.getParentFile(),"test");
StringBuffer strB = new StringBuffer();
//Set command line content
List<String> cmd = new ArrayList<String>();
if(OS.isWindowsXP()){
cmd.add(tessPath+"//tesseract");
}else if(OS.isLinux()){
cmd.add("tesseract");
}else{
cmd.add(tessPath+"//tesseract");
}
cmd.add("");
cmd.add(outputFile.getName());
cmd.add(LANG_OPTION);
//Chinese bag
cmd.add("chi_sim");
//Common mathematical formula package
cmd.add("equ");
//English package
cmd.add("eng");
//Create operating system process
ProcessBuilder pb = new ProcessBuilder();
//Set the working directory for this process builder
pb.directory(imageFile.getParentFile());
cmd.set(1, tempImage.getName());
//Set cmd command to execute
pb.command(cmd);
//Set that the error output generated by subsequent sub processes will be merged with the standard output
pb.redirectErrorStream(true);
long startTime = System.currentTimeMillis();
System.out.println("Start time:" + startTime);
//Start execution and return the process instance
Process process = pb.start();
//The final execution command is: Tesseract 1 png test -l chi_ sim+equ+eng
// Input / output stream optimization
// printMessage(process.getInputStream());
// printMessage(process.getErrorStream());
int w = process.waitFor();
//Delete temporary working files
tempImage.delete();
if(w==0){
// 0 means normal exit
BufferedReader in = new BufferedReader(new InputStreamReader(new FileInputStream(outputFile.getAbsolutePath()+".txt"),"UTF-8"));
String str;
while((str = in.readLine())!=null){
strB.append(str).append(EOL);
}
in.close();
long endTime = System.currentTimeMillis();
System.out.println("End time:" + endTime);
System.out.println("Time consuming:" + (endTime - startTime) + "millisecond");
}else{
String msg;
switch(w){
case 1:
msg = "Errors accessing files.There may be spaces in your image's filename.";
break;
case 29:
msg = "Cannot recongnize the image or its selected region.";
break;
case 31:
msg = "Unsupported image format.";
break;
default:
msg = "Errors occurred.";
}
tempImage.delete();
throw new RuntimeException(msg);
}
// Delete temporary files extracted to text
new File(outputFile.getAbsolutePath()+".txt").delete();
return strB.toString().replaceAll("\\s*", "");
}
private static void printMessage(final InputStream input) {
new Thread(new Runnable() {
@Override
public void run() {
Reader reader = new InputStreamReader(input);
BufferedReader bf = new BufferedReader(reader);
String line = null;
try {
while ((line = bf.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
}
4.TestOcr test code
package com.lk.integutils.utils;
import java.io.File;
import java.io.IOException;
public class TestOcr {
/**
* @param args
*/
public static void main(String[] args) {
//Enter picture address
String path = "d://1640144341(1).png";
try {
String valCode = new OCRUtil().recognizeText(new File(path), "png");
System.out.println(valCode);
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
}
ending
The effect is not good. It needs to be adjusted
Reference articles
mall4j: https://segmentfault.com/a/1190000039362377
SyKay: https://www.jianshu.com/p/f7cb0b3f337a