0. Qianyan data set: introduction to text similarity competition
Text similarity aims to identify whether two texts are semantically similar. Text similarity is an important research direction in the field of natural language processing. At the same time, it plays an important role in the fields of information retrieval, news recommendation, intelligent customer service and so on.
Text similarity: https://aistudio.baidu.com/aistudio/competition/detail/45
At present, some open Chinese text similarity data sets in the academic community have comprehensively evaluated the existing open text similarity models with the support of relevant papers, which has high authority. Therefore, this open source project collects these authoritative data sets and expects to comprehensively evaluate the model effect. It aims to provide a platform for academic and technical communication for researchers and developers, further improve the research level of text similarity, and promote the application and development of text similarity in the field of natural language processing.
1. Dataset
The text similarity data set in this evaluation includes three published text similarity data sets, namely LCQMC [1] and BQ Coupus [2] of Harbin University of Technology (Shenzhen) and PAWS-X (Chinese) [3] of Google. An introduction to each data set is as follows:
a) LCQMC
LCQMC (A Large-scale Chinese Question Matching Corpus), Baidu knows the Chinese problem matching dataset in the field, in order to solve the lack of large-scale problem matching dataset in the Chinese field. The data set extracts construction data from user problems in different fields that Baidu knows.
b) BQ Corpus
BQ Corpus (Bank Question Corpus), the problem matching data in the banking and financial field, including the problem pair extracted from the online banking system log of one year, is the largest problem matching data in the banking field at present.
c) PAWS-X (Chinese)
PAWS (paraphrase advertisements from word scribbling), a data set released by Google containing interpretation pairs in seven languages, including PAWS (English) and PAWS-X (Multilingual). The data set contains interpretation pairs and non interpretation pairs, that is, to identify whether a pair of sentences have the same interpretation (meaning), which is characterized by highly overlapping words, which is very helpful to further improve the model and judge strong negative cases.
The tasks of each data set are consistent, that is, the binary classification task to judge whether the two texts are semantically similar. Take LCQMC as an example:
2. Submission method
# Text similarity task index prediction 0 1 1 0 2 1
2, Train of thought
- 1. Build a network
- 2. Replace the dataset
- 3. Finetune generates different models for different data sets
- 4. Forecast with different models
3, Environmental preparation
1. Package introduction
!python -m pip install --upgrade paddlenlp==2.0.2 -i https://mirror.baidu.com/pypi/simple
import time
import os
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.datasets import load_dataset
import paddlenlp
# One click loading Lcqmc training set and verification set
train_ds, dev_ds = load_dataset("lcqmc", splits=["train", "dev"])
2. Data download
# paddlenlp will automatically download the lcqmc dataset and unzip it to the "${HOME}/.paddlenlp/datasets/LCQMC/lcqmc/lcqmc /" directory
! ls ${HOME}/.paddlenlp/datasets/LCQMC/lcqmc/lcqmc
print(paddlenlp.__version__)
3. Data viewing
# Output the first 20 samples of the training set
for idx, example in enumerate(train_ds):
if idx <= 20:
print(example)
4. Data preprocessing
The LCQMC data set loaded through paddlenlp is the original plaintext data set. In this part, we implement group batch, tokenize and other preprocessing logic to convert the original plaintext data into the input data of network training
4.1 define sample conversion function
# Because it is based on the pre training model Ernie gram, you need to load Ernie Gram's tokenizer first,
# Subsequent sample conversion functions segment text based on tokenizer
tokenizer = paddlenlp.transformers.ErnieGramTokenizer.from_pretrained('ernie-gram-zh')
# Splice the query and title of one plaintext data, and convert the plaintext into ID data according to the tokenizer of the pre training model
# Return input_ids and token_type_ids
def convert_example(example, tokenizer, max_seq_length=512, is_test=False):
query, title = example["query"], example["title"]
encoded_inputs = tokenizer(
text=query, text_pair=title, max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
# In the prediction or evaluation phase, the label field is not returned
else:
return input_ids, token_type_ids
### Convert the first data of the training set input_ids, token_type_ids, label = convert_example(train_ds[0], tokenizer)
print(input_ids)
print(token_type_ids)
# For the convenience of subsequent use, we give convert_example gives some default parameters
from functools import partial
# Sample conversion function of training set and verification set
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=512)
4.2 assembling Batch data & padding
In the previous section, we completed the conversion of a single sample. In this section, we need to combine the samples into Batch data. For unequal length data, we also need to carry out Padding operation to facilitate GPU training.
PaddleNLP provides many common API s for building effective data pipeline s in NLP tasks
from paddlenlp.data import Stack, Pad, Tuple
# Our training data will return input_ids, token_type_ids, labels 3 fields
# Therefore, three group batch operations need to be defined for these three fields
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack(dtype="int64") # label
): [data for data in fn(samples)]
4.3 define Dataloader
Let's base on group batchify_fn function and sample conversion function trans_func to construct the DataLoader of the training set and support multi card training
# Define distributed Sampler: automatically segment training data and support multi card parallel training
batch_sampler = paddle.io.DistributedBatchSampler(train_ds, batch_size=400, shuffle=True) # batch_size=32
# Based on train_ds define train_data_loader
# Because we use the distributed batchsampler, train_ data_ The loader will automatically segment the training data
train_data_loader = paddle.io.DataLoader(
dataset=train_ds.map(trans_func),
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)
# For the loading of validation set data, we use a single card for evaluation, so we can use pad.io.batchsampler
# Define dev_data_loader
batch_sampler = paddle.io.BatchSampler(dev_ds, batch_size=400, shuffle=False)
dev_data_loader = paddle.io.DataLoader(
dataset=dev_ds.map(trans_func),
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)
4, Model training
1. Model construction
Since October 2018, NLP tasks in all fields have achieved significant improvement in effect compared with traditional DNN methods through the mode of Pretrain + Finetune. In this section, we build a point wise semantic matching network based on Baidu's open source pre training model Ernie gram.
import paddle.nn as nn
# We build a point wise semantic matching network based on Ernie gram model structure
# Therefore, the pretrained of Ernie gram is defined here_ model
# pretrained_model = paddlenlp.transformers.ErnieGramModel.from_pretrained('ernie-gram-zh')
pretrained_model = paddlenlp.transformers.ErnieModel.from_pretrained('ernie-1.0')
class PointwiseMatching(nn.Layer):
# Prepared here_ In this case, the model will be initialized by Ernie gram pre training model
def __init__(self, pretrained_model, dropout=None):
super().__init__()
self.ptm = pretrained_model
self.dropout = nn.Dropout(dropout if dropout is not None else 0.1)
# Semantic matching tasks: similar and dissimilar 2 classification tasks
self.classifier = nn.Linear(self.ptm.config["hidden_size"], 2)
def forward(self,
input_ids,
token_type_ids=None,
position_ids=None,
attention_mask=None):
# Input here_ IDS is composed of two text tokens
# token_type_ids represents the type encoding of two pieces of text
# Returned cls_embedding represents the semantic representation vector obtained after the calculation of the model
_, cls_embedding = self.ptm(input_ids, token_type_ids, position_ids,
attention_mask)
cls_embedding = self.dropout(cls_embedding)
# The semantic representation vector of text pair is used for 2 classification task
logits = self.classifier(cls_embedding)
probs = F.softmax(logits)
return probs
# Define point wise semantic matching network
model = PointwiseMatching(pretrained_model)
2. Model training (introducing visual dl)
from paddlenlp.transformers import LinearDecayWithWarmup
epochs = 10
num_training_steps = len(train_data_loader) * epochs
# Define learning_ rate_ The scheduler is responsible for scheduling lr during training
lr_scheduler = LinearDecayWithWarmup(5E-5, num_training_steps, 0.0)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
# Define Optimizer
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=0.0,
apply_decay_param_fun=lambda x: x in decay_params)
# Cross entropy loss function
criterion = paddle.nn.loss.CrossEntropyLoss()
# The accuracy index is used in the evaluation
metric = paddle.metric.Accuracy()
# Join log display
from visualdl import LogWriter
writer = LogWriter("./log")
# Because the model evaluation is performed in the validation set during the training process, we first define the evaluation function
@paddle.no_grad()
def evaluate(model, criterion, metric, data_loader, phase="dev"):
model.eval()
metric.reset()
losses = []
for batch in data_loader:
input_ids, token_type_ids, labels = batch
probs = model(input_ids=input_ids, token_type_ids=token_type_ids)
loss = criterion(probs, labels)
losses.append(loss.numpy())
correct = metric.compute(probs, labels)
metric.update(correct)
accu = metric.accumulate()
print("eval {} loss: {:.5}, accu: {:.5}".format(phase,
np.mean(losses), accu))
# Join eval log display
writer.add_scalar(tag="eval/loss", step=global_step, value=np.mean(losses))
writer.add_scalar(tag="eval/acc", step=global_step, value=accu)
model.train()
metric.reset()
# Next, start the formal training model
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
probs = model(input_ids=input_ids, token_type_ids=token_type_ids)
loss = criterion(probs, labels)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
# Output training index every 10 step s
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
# Every 100 step s are evaluated on the verification set and test set
if global_step % 100 == 0:
evaluate(model, criterion, metric, dev_data_loader, "dev")
# Join the train log display
writer.add_scalar(tag="train/loss", step=global_step, value=loss)
writer.add_scalar(tag="train/acc", step=global_step, value=acc)
save_dir = os.path.join("checkpoint", "model_%d" % global_step)
os.makedirs(save_dir)
# Add save
save_param_path = os.path.join(save_dir, 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
tokenizer.save_pretrained(save_dir)
# After the training, store the model parameters
save_dir = os.path.join("checkpoint_final", "model_%d" % global_step)
os.makedirs(save_dir)
save_param_path = os.path.join(save_dir, 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
tokenizer.save_pretrained(save_dir)
aistudio@jupyter-89263-2045895:~$ nvidia-smi
Mon Jun 7 20:58:20 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.67 Driver Version: 418.67 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:0C.0 Off | 0 |
| N/A 63C P0 286W / 300W | 30107MiB / 32480MiB | 99% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
eval dev loss: 0.4291, accu: 0.87548 global step 4010, epoch: 4, batch: 428, loss: 0.35052, accu: 0.93900, speed: 0.58 step/s global step 4020, epoch: 4, batch: 438, loss: 0.41507, accu: 0.92800, speed: 1.54 step/s global step 4030, epoch: 4, batch: 448, loss: 0.38232, accu: 0.93017, speed: 1.53 step/s global step 4040, epoch: 4, batch: 458, loss: 0.41443, accu: 0.92888, speed: 1.56 step/s global step 4050, epoch: 4, batch: 468, loss: 0.38452, accu: 0.93030, speed: 1.50 step/s global step 4070, epoch: 4, batch: 488, loss: 0.39084, accu: 0.92850, speed: 1.42 step/s global step 4080, epoch: 4, batch: 498, loss: 0.40689, accu: 0.92875, speed: 1.56 step/s global step 4090, epoch: 4, batch: 508, loss: 0.37768, accu: 0.92972, speed: 1.49 step/s global step 4100, epoch: 4, batch: 518, loss: 0.39479, accu: 0.92930, speed: 1.46 step/s
# After the training, store the model parameters
save_dir = os.path.join("checkpoint", "model_%d" % global_step)
os.makedirs(save_dir)
save_param_path = os.path.join(save_dir, 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
tokenizer.save_pretrained(save_dir)
5, Model prediction
Next, we use the trained semantic matching model to predict some prediction data. The data to be predicted is a tsv file in which each line is a text pair. We use the test set of Lcqmc data set as our prediction data to predict and submit the prediction results to the thousand word text similarity contest
Download the semantic matching model we have trained and unzip it
break
# Download our pre trained semantic matching model based on Lcqmc and decompress it ! wget https://paddlenlp.bj.bcebos.com/models/text_matching/ernie_gram_zh_pointwise_matching_model.tar ! tar -xvf ernie_gram_zh_pointwise_matching_model.tar
# The test data is separated by two columns of text
# Lcqmc is downloaded to the following path by default
! head -n10 "${HOME}/.paddlenlp/datasets/LCQMC/lcqmc/lcqmc/test.tsv"
1. Define prediction function
def predict(model, data_loader):
batch_probs = []
# In the prediction phase, the eval mode is turned on, and the dropout and other operations in the model will be turned off
model.eval()
with paddle.no_grad():
for batch_data in data_loader:
input_ids, token_type_ids = batch_data
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids)
# Obtain the matrix of prediction probability of each sample: [batch_size, 2]
batch_prob = model(
input_ids=input_ids, token_type_ids=token_type_ids).numpy()
batch_probs.append(batch_prob)
batch_probs = np.concatenate(batch_probs, axis=0)
return batch_probs
2. Define the data of forecast data_loader
!head paws-x-zh/test.tsv !head paws-x-zh/train.tsv
# Conversion function of prediction data
# The predict data has no label, so convert_exmaple is_ Set the test parameter to True
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=512,
is_test=True)
# batch operation of prediction data group
# predict data only returns input_ids and token_type_ids, so only two Pad objects are needed as batchify_fn
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment_ids
): [data for data in fn(samples)]
# Load forecast data
test_ds = load_dataset("lcqmc", splits=["test"])
# test_ds = load_dataset("lcqmc", data_files='paws-x-zh/test.tsv')
test_ds = load_dataset("lcqmc", data_files='bq_corpus/test.tsv')
batch_sampler = paddle.io.BatchSampler(test_ds, batch_size=32, shuffle=False)
# Generate forecast data_loader
predict_data_loader =paddle.io.DataLoader(
dataset=test_ds.map(trans_func),
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)
3. Define prediction model
# pretrained_model = paddlenlp.transformers.ErnieGramModel.from_pretrained('ernie-gram-zh')
pretrained_model = paddlenlp.transformers.ErnieModel.from_pretrained('ernie-1.0')
model = PointwiseMatching(pretrained_model)
4. Load the trained model parameters (here you can also directly load the pre training model for prediction, or load the checkpoint of the best training for training)
# After decompressing the downloaded model, the storage path is. / ernie_gram_zh_pointwise_matching_model/model_state.pdparams
# state_dict = paddle.load("./ernie_gram_zh_pointwise_matching_model/model_state.pdparams")
state_dict = paddle.load("checkpoint/model_19000/model_state.pdparams")
# After decompressing the downloaded model, the storage path is. / pointwise_matching_model/ernie1.0_base_pointwise_matching.pdparams
# state_dict = paddle.load("pointwise_matching_model/ernie1.0_base_pointwise_matching.pdparams")
model.set_dict(state_dict)
5. Start forecasting
for idx, batch in enumerate(predict_data_loader):
if idx < 1:
print(batch)
# Execute prediction function y_probs = predict(model, predict_data_loader) # Obtain the prediction label according to the prediction probability y_preds = np.argmax(y_probs, axis=1)
6. Output forecast results
# We store the prediction results in lcqmc.tsv according to the submission format of the thousand word text similarity contest for subsequent submission
# At the same time, the prediction results are output to the terminal, which is convenient for everyone to intuitively feel the prediction effect of the model
# test_ds = load_dataset("lcqmc", splits=["test"])
# with open("lcqmc.tsv", 'w', encoding="utf-8") as f:
# with open("paws-x.tsv", 'w', encoding="utf-8") as f:
with open("bq_corpus.tsv", 'w', encoding="utf-8") as f:
f.write("index\tprediction\n")
for idx, y_pred in enumerate(y_preds):
f.write("{}\t{}\n".format(idx, y_pred))
print("{}\t{}\n".format(idx, y_pred))
# text_pair = test_ds[idx]
# text_pair["id"] = test_ds[idx]
# text_pair["label"] = y_pred
# print(text_pair)
6, BQ Corpus, PAWS-X (Chinese) similarity prediction process
1. Decompress bq_corpus.zip, paws-x-zh.zip datasets
2. User defined data sets train the other two types of models
The code is as follows: customize the dataset. Note that one is the dataset type lcqmc, the other is the location of the folder, and splits prompts the dataset to be returned
from paddlenlp.datasets import load_dataset
train_ds, dev_ds = load_dataset("lcqmc", data_files='bq_corpus/', splits=("train", "dev"))
3. Replace the forecast dataset and start the forecast
Indicates the data format and file name
test_ds = load_dataset("lcqmc", data_files='bq_corpus/test.tsv')
!unzip -qa data/data52714/bq_corpus.zip !unzip -qa data/data52714/paws-x-zh.zip
4. Submit lcqmc prediction results in a thousand words text similarity contest
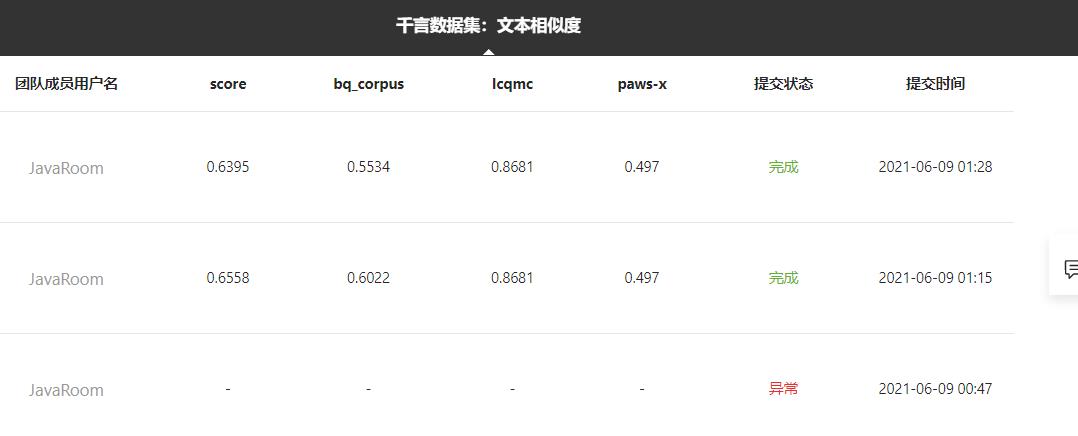
There are three data sets in the thousand words text similarity contest: lcqmc and bq_corpus and paws-x, we just generated the prediction result lcqmc.tsv of lcqmc, and we provided BQ in the project_ For the empty prediction results of corpus and paw-x data sets, we package and submit these three files to the thousand word text similarity competition to see the competition results of our model on lcqmc data set.
# Package forecast results a/data52714/bq_corpus.zip !unzip -qa data/data52714/paws-x-zh.zip
4. Submit lcqmc prediction results in a thousand words text similarity contest
There are three data sets in the thousand words text similarity contest: lcqmc and bq_corpus and paws-x, we just generated the prediction result lcqmc.tsv of lcqmc, and we provided BQ in the project_ For the empty prediction results of corpus and paw-x data sets, we package and submit these three files to the thousand word text similarity competition to see the competition results of our model on lcqmc data set.
# Package forecast results !zip submit.zip lcqmc.tsv paws-x.tsv bq_corpus.tsv
5. Run a demo
Have time to think and run
6. Join visual dl observation training
Write the train and val conditions into the log, and check the training progress with visual dl